










前言
在“数字重庆”建设持续深入推进的时代背景下,生态环境管理正迈向精细化、智能化新阶段。危险废物作为固体废物管理的重中之重,其全生命周期管理日益精细,大量关键信息已接入“巴渝治废”等数字化管理平台,涵盖企业的危废产生量、类别等核心数据。面对海量的基础数据,如何深入挖掘其潜在价值,赋能精准监管,成为当前亟待解决的课题。本文旨在探索企业用电数据与危险废物产生数据之间的内在关联,并基于此构建智能分析模型,以期精准识别潜在的异常情况,为危废监管提供新的视角与技术支撑。
以下观点也是对于环保数据不成熟的思考和尝试,如果读者有更好的想法和实现路径也请留言讨论,关注交流。
目的
本研究的核心目标是利用企业用电量这一高频、实时且具有生产活动指示性的数据,结合危险废物产生量数据,构建多维度分析模型,从而有效识别危废产生量中可能存在的异常波动或数据偏差,为生态环境部门实现精准监管、风险预警及资源优化配置提供数据驱动的决策依据。
技术路线
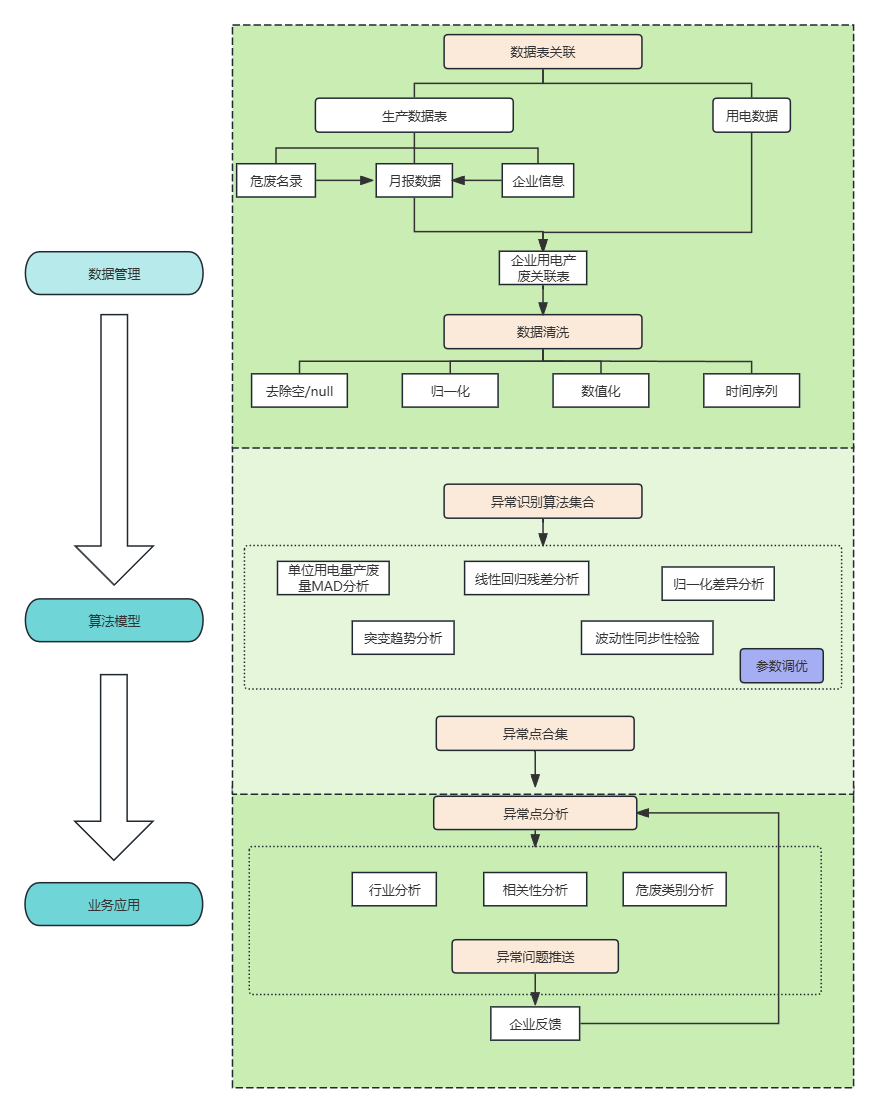
基础数据分析
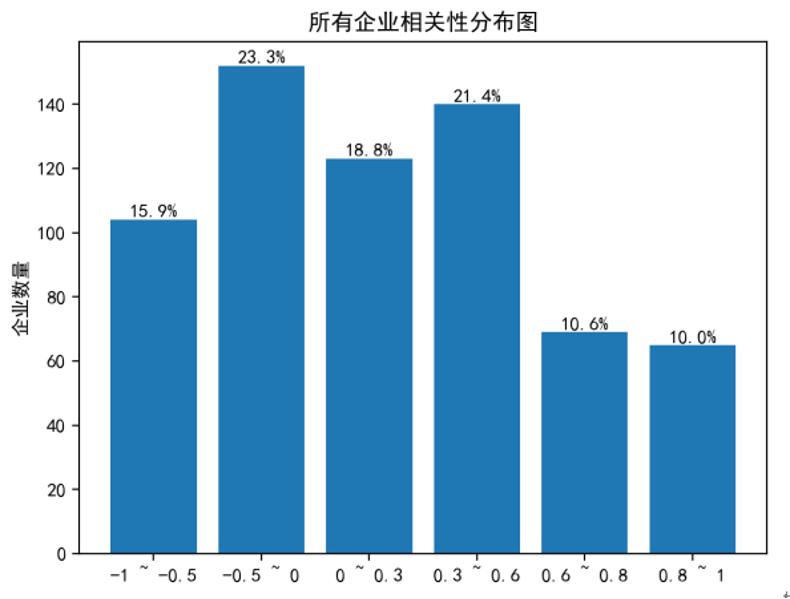
纳入分析的企业共计 718 家,涵盖 43 个不同行业,涉及 224 个不同危废类别。其中,年产废量大于 50 吨的企业有 490 家。在全部企业中,用电量与产废量相关性达到 0.6 以上的企业占比为 20.6%。
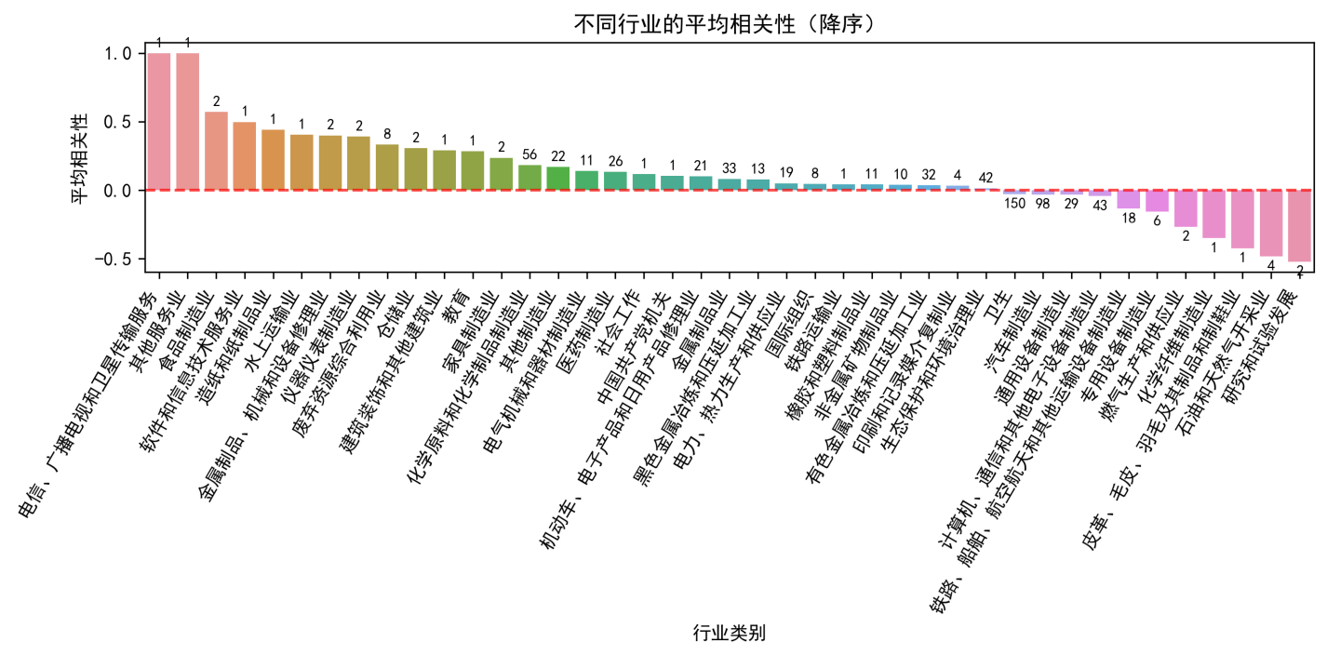
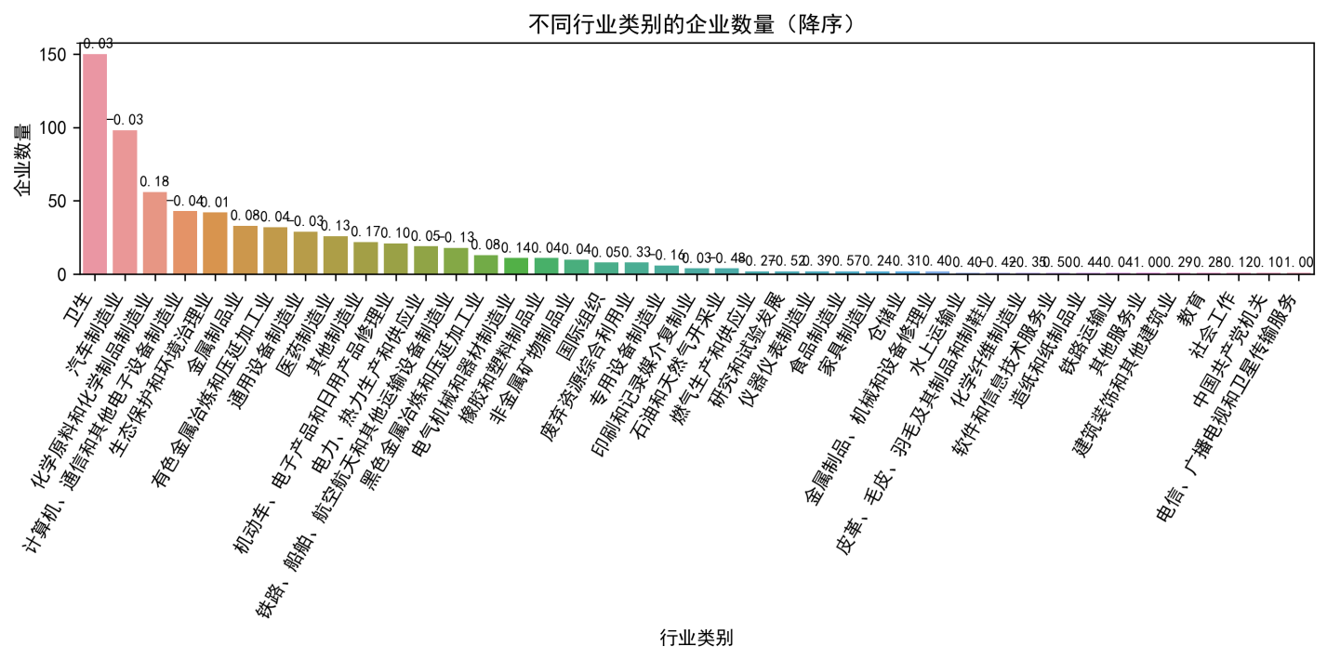
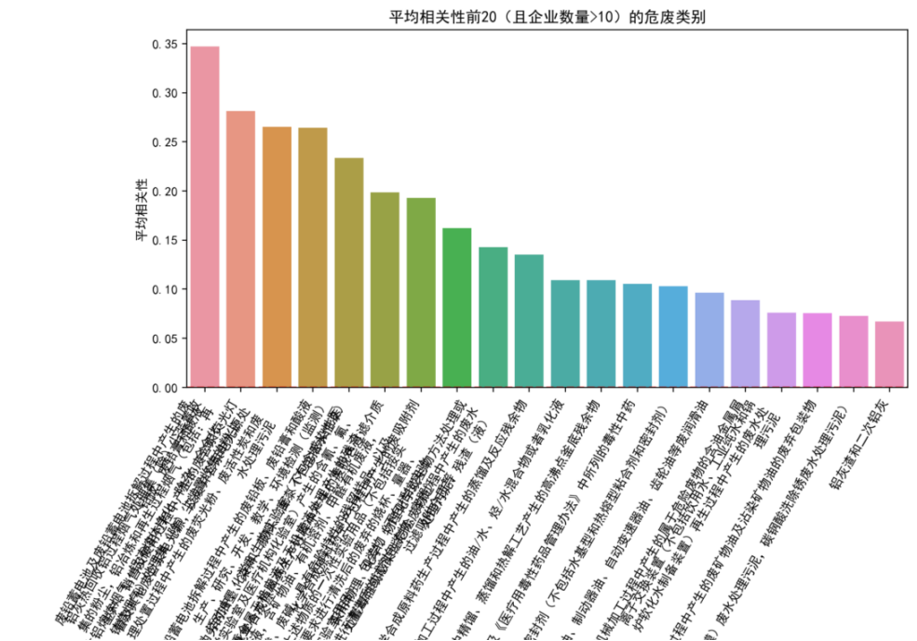
在对纳入分析的 718 家企业(涵盖 43 个不同行业、涉及 224 个危废类别)进行基础数据分析时,我们发现,尽管年产废量大于 50 吨的企业占比高达 490 家,但整体而言,用电量与产废量相关性达到 0.6 以上的企业仅占 20.6%。进一步从行业和产废类别维度进行聚合分析,我们观察到,当行业或产废类别数量增多时,整体相关性趋于弱化甚至不相关。这与实际生产经验相符,即不同企业在生产效率和废物产出模式上存在显著差异。这一发现也明确指出,简单地从宏观行业或产废类别层面推导单个企业的用电量与产废量关联性是不可行的。因此,本研究的重点必须聚焦于单个企业自身的历史数据分析,以捕捉其独特的生产规律和异常模式。
算法概述
鉴于企业生产模式的复杂性和数据特征的多样性,本研究并未采用单一的异常检测方法,而是根据不同的业务场景和数据特性,综合运用了五种核心算法,以期从多维度、多视角捕捉潜在的异常行为。这些算法包括:单位用电量产废量 MAD 分析、线性回归残差分析、归一化差异分析、突变趋势分析以及波动性同步性检验。

1. 单位用电量产废量 MAD 分析 (FeatureEngineeringDetector)
-
核心思路:
该方法关注企业的生产效率。它假设在正常生产状态下,单位用电量所对应的产废量(即生产效率)应保持相对稳定。通过计算“单位用电量产废量”这一比率,并应用对异常值鲁棒的 MAD(中位数绝对偏差)方法,来识别那些生产效率显著偏离历史水平的异常点。例如,一个企业突然出现“高耗电、低产出”或“低耗电、高产出”的情况,可能预示着数据问题或生产状态异常。 -
核心公式:
- 归一化 (避免除零):
waste_norm_1_2 = normalize_series(waste) + 1.0(归一化到 [1,2][1, 2][1,2])elec_norm_1_2 = normalize_series(elec) + 1.0(归一化到 [1,2][1, 2][1,2])
- 计算单位用电量产废量:
unit_waste = waste_norm_1_2 / elec_norm_1_2
- MAD 异常检测:
median = median(unit_waste)mad = median(|unit_waste - median|)mad_score = |unit_waste - median| / mad(若mad!= 0)- 异常判定:
mad_score > threshold(默认阈值为 3.0)
- 归一化 (避免除零):
-
主要特点:
- 适用场景:适用于产废量和用电量均有一定规模,且历史效率相对稳定的企业。
2. 线性回归残差分析 (LinearRegressionDetector & RegressionDetector)
-
核心思路:
该方法基于历史数据建立数学模型。它假设企业的产废量(W)与用电量(E)之间存在一个稳定的线性关系W = β₀ + β₁E。对于新的数据点,模型会预测其“应有的”产废量,实际值与预测值之间的差值(残差)即为分析对象。如果残差过大,说明该点严重偏离了历史规律,应被标记为异常。 -
核心公式:
- 模型拟合:
W_pred = β₀ + β₁ * E(使用最小二乘法估计β₀和β₁)
- 计算残差:
residual = W_actual - W_pred
- 异常判定:
LinearRegressionDetector:|residual| > k * sese是回归模型的标准误差,衡量模型预测的平均精度。k是置信系数(默认 0.8)。
RegressionDetector:|residual| > threshold * std_residualsstd_residuals是残差序列自身的标准差。threshold为 3.0,即经典的3σ原则。
- 模型拟合:
-
主要特点:
- 模型驱动:拥有明确的统计学模型基础,理论严谨。
- 预测性强:不仅能判断异常,还能给出“正常值”应该是多少(预测值)。
- 两种策略:
LinearRegressionDetector更关注模型的预测能力(se),并具备数据不足时的回退机制(比率法),鲁棒性更强。RegressionDetector遵循经典统计学原则(3σ),逻辑简洁明了。
- 适用场景:适用于产废量与用电量有明显线性相关性的企业,且历史数据点充足(通常>=3 个)。
3. 归一化差异分析 (NormalizedDifferenceDetector)
-
核心思路:
该方法采用最直观的比较方式。它认为,在正常情况下,企业的产废量和用电量的变化趋势应当是同步的。通过将两个指标分别归一化到 [0,1][0,1][0,1] 区间,消除了量纲和企业规模的影响,然后直接计算它们在同一时间点的数值差异。如果这个差异超过了预设的阈值,就认为两者的变化趋势出现了严重脱节,该点为异常。 -
核心公式:
- 归一化:
waste_norm = (waste - min(waste)) / (max(waste) - min(waste))elec_norm = (elec - min(elec)) / (max(elec) - min(elec))
- 计算差异:
normalized_diff = |waste_norm - elec_norm|
- 异常判定:
normalized_diff > diff_threshold(默认阈值为 0.35)
- 归一化:
-
主要特点:
- 适用场景:作为一种快速、基础的筛查工具,适用于所有企业,尤其适合对趋势同步性要求高的场景。
4. 突变趋势分析 (TrendCrossDetector)
-
核心思路:
该方法具有前瞻性,它不直接分析当前值,而是监测两者变化趋势的“交叉”。当产废量的趋势(上升/下降)与用电量的趋势发生逆转(即一个在上升而另一个在下降)时,系统认为企业的生产模式可能正在发生转变。这种转变本身可能不是异常,但它预示着后续的数据点可能不稳定。因此,该方法会检查趋势交叉发生后的下一个时间点,如果此时的归一化差异也很大,则将该后续点标记为异常。 -
核心公式:
- 归一化:
waste_norm = normalize_series(waste)elec_norm = normalize_series(elec)
- 计算趋势符号:
waste_trend = sign(waste_norm.diff())(上升=1, 下降=-1, 不变=0)elec_trend = sign(elec_norm.diff())
- 识别交叉点:
cross_point[i] = (waste_trend[i] != elec_trend[i])
- 标记异常点:
- 如果
cross_point[i]为True,则检查i+1时刻的归一化差异。 - 异常判定:
|waste_norm[i+1] - elec_norm[i+1]| > diff_threshold(默认阈值为 0.4)
- 如果
- 归一化:
-
主要特点:
- 适用场景:适用于生产流程可能发生调整、或数据可能存在滞后性问题的企业,用于发现模式切换的信号。
5. 波动性同步性检验 (VolatilityDetector)
-
核心思路:
该方法关注的是剧烈变化的同步性。它认为,在正常生产中,重大的生产活动(如开/停机、批次生产)会同时导致用电量和产废量的剧烈波动。如果一个指标发生了剧烈变化(变化率超过 50%),而另一个指标没有相应的响应(变化方向相反或变化极小),则这种“不同步”的剧烈波动很可能是数据异常或生产问题的信号。 -
核心公式:
- 归一化:
waste_norm = normalize_series (waste)elec_norm = normalize_series (elec)
- 计算变化率:
elec_change = elec_norm. Pct_change ()(百分比变化)waste_change = waste_norm. Pct_change ()
- 定义异常条件:
- 条件 1 (电变废不变):
elec_big = |elec_change| > 0.5waste_unsync = (sign (elec_change) != sign (waste_change)) OR (|waste_change| < 0.01)condition 1 = elec_big AND waste_unsync
- 条件 2 (废变电不变):
waste_big = |waste_change| > 0.5elec_unsync = (sign (waste_change) != sign (elec_change)) OR (|elec_change| < 0.01)condition 2 = waste_big AND elec_unsync
- 条件 1 (电变废不变):
- 综合判定与过滤:
is_outlier = (condition 1 OR condition 2) AND (original_waste_value > 50.0)
- 归一化:
-
主要特点:
- 适用场景:特别适用于生产活动具有间歇性、波动性大的企业,用于发现数据录入错误或生产计划外的活动。
模型结果
通过上述多算法模型的构建与应用,我们成功识别出历史月份中用电量与产废量可能存在异常的月份,并进行了直观的可视化呈现。从分析结果来看,对于用电量与产废量具有较高相关性的企业,不同算法识别出的异常点往往具有高度一致性,这印证了模型在捕捉稳定生产模式下异常的有效性。然而,对于相关性较差的企业,模型识别出的异常点则呈现出数量更多且算法间差异显著的特点。这并非模型失效,而是恰恰反映了这类企业用电量与产废量之间可能不存在显著的线性或稳定关联,其生产模式更为复杂或数据本身存在更多不确定性。在这种情况下,不同算法从各自的侧重点(如效率、趋势、波动性等)出发,自然会捕捉到不同的“异常”表现,甚至可能将大部分数据点标记为异常,这提示我们在解释和应用模型结果时,必须充分考虑企业自身的生产特性和数据质量。
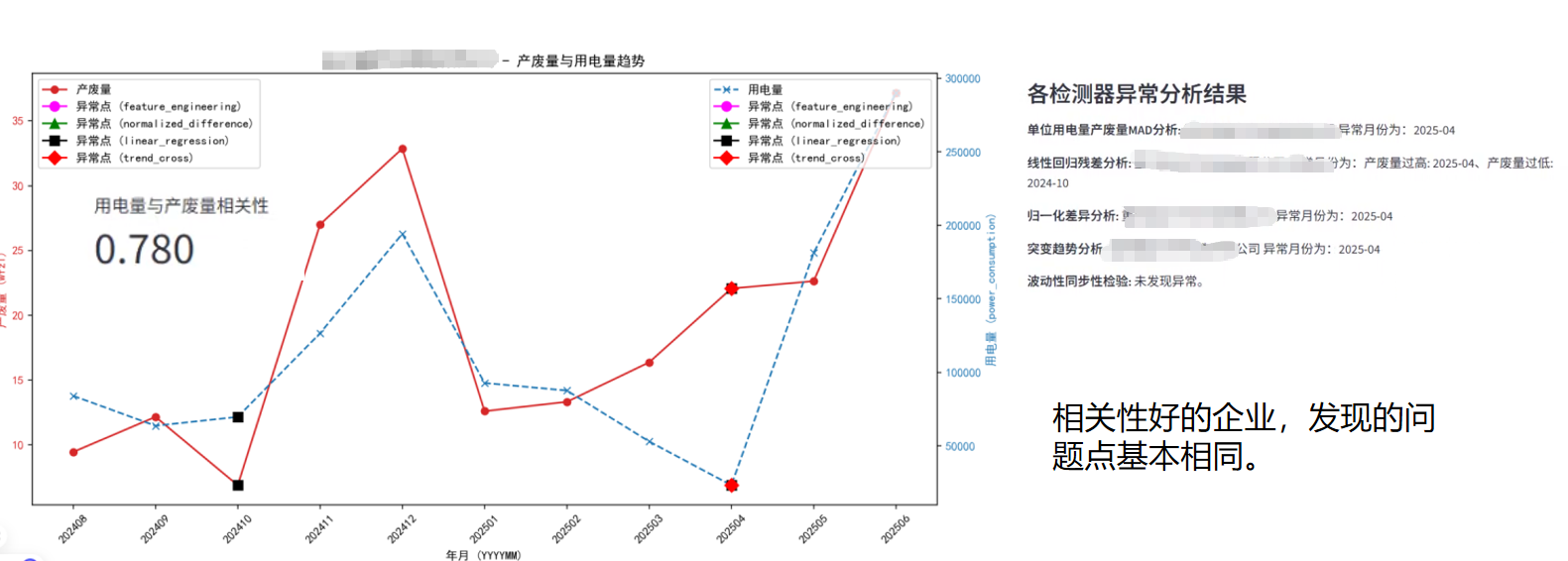
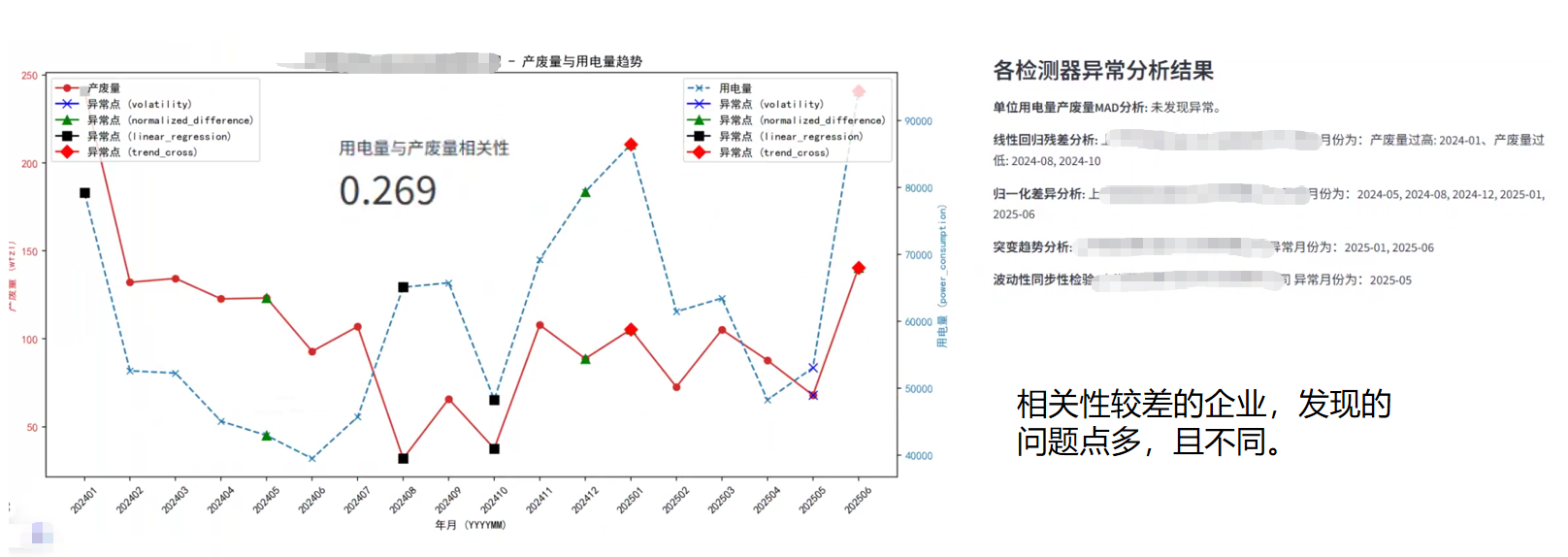
企业反馈
为了验证模型的实际效用并获取业务层面的反馈,我们选取了部分被识别为异常的企业进行问题推送。企业反馈为模型优化提供了宝贵的洞察,主要集中在以下几个方面,这些反馈也揭示了模型在实际应用中面临的挑战与局限性:
- 生产状态异常影响数据可比性: 如设备检修、停产、搬迁或生产线调整等非正常生产状态,导致用电量与产废量在特定时期内失去可比性。
- 生产运行模式影响用电与产废的匹配性: 间歇性生产、季节性生产、或产废环节与主要用电环节不完全同步等,使得用电量与产废量之间的时间匹配性变差。
- 总用电数据颗粒度不足: 企业总用电量数据未能区分生产用电与非生产用电,或未能细化到具体产废工艺环节,导致关联分析的精度受限。
- 产废与填报信息不匹配: 实际产废量与平台填报数据之间存在滞后、偏差或统计口径不一致等问题,影响了数据真实性与模型判断的准确性。

反思与总结
本次研究的实践深刻揭示了一个核心洞察:任何数据模型,其“失效”并非必然源于算法本身的缺陷,而更多是由于数据质量、企业生产模式的复杂性与模型预设假设之间存在不匹配。这再次印证了“放之四海而皆准”的单一模型在复杂工业场景中难以奏效。因此,在未来的智能监管实践中,我们必须坚持结合企业生产实际、明确模型边界、审慎评估适用条件的原则,进行分场景、精细化的分析与应用。这不仅要求技术层面的持续迭代,更需要业务与技术深度融合,共同构建更贴合实际、更具韧性的智能监管体系。
下一步完善思路
为进一步提升模型的准确性与实用性,未来的完善工作将聚焦于以下几个关键方向:
- 多源数据融合与交叉验证: 积极探索并整合更多自动化监测数据,如水、气污染物排放数据等,作为用电量与产废量关联分析的佐证,通过多维度数据交叉验证,对识别出的异常点进行二次筛选,提高预警的精准度。
- 构建“业务问题池”与精准推送: 结合企业反馈和专家经验,构建结构化的“业务问题池”,针对性地根据企业实际情况,将异常报告精准推送至试点企业,要求其进行自查自纠并反馈原因。
- 建立“识别-反馈-优化”闭环机制: 基于企业真实的反馈信息,深入分析模型误报(False Positives)和漏报(False Negatives)的原因,针对性地调整算法参数、优化模型结构或引入新的特征工程方法,形成持续迭代优化的智能监管闭环,不断提升模型的适应性和预测能力。
BY
个人经验分享,如有收获,欢迎收藏、点赞!
尊重原创,如需转载,请注明出处。
欢迎留言评论,交流心得,共同进步!
📬 联系方式:
- 微信公众号:环境猫 er
- 优快云 博客:细节处有神明
- 个人博客:
https://wenmao.xyzhttps://wenmaochen.netlify.apphttps://maoyu92.github.io
感谢阅读,我们下次再见! 🌟



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











