




一直都是对依存句法分析只有一个模模糊糊的概念,最近看了一些相关的文章以及视频,在这里做一个小结。
依存句法 分析( Dependency Parsing, DP) 通过分析语言单位内成分之间的依存关系揭示其句法结构。
使用语义依存刻画句子语义,好处在于不需要去明白词汇本身的意思,而是通过词汇所承受的语义框架来描述该词汇,而其数目相对词汇来说数量是小很多的。这样一来,大部分的句子都可以用这个框架来表示,同时,我们又能总结出这句话大概讲了些什么。
首先,句子中的核心动词是支配其他成分的中心成分,它本身不受支配。其次,其它成分间也存在支配关系。
关于如何支配的问题,具体可以总结为以下五条规律(在20世纪70年代,Robinson提出依存语法中关于依存关系的四条公理,在处理中文信息的研究中,中国学者提出了依存关系的第五条公理):
一个句子中只有一个成分是独立的,即核心成分;
句子的其他成分都从属于某一成分,即除了核心成分外的部分;
任何一个成分都不能依存于两个及以上的成分;
如果成分A直接从属成分B,而成分C在句子中位于A和B之间,那么,成分C或者从属于A,或者从属于B,或者从属于A和B之间的某一成分(如果将从属关系用线条表示出来的话,那么这些线条不会发生交交错);
核心成分左右两边的其他成分相互不发生关系,相当于核心成分是一条界线,左右两边的部分不再发生支配关系
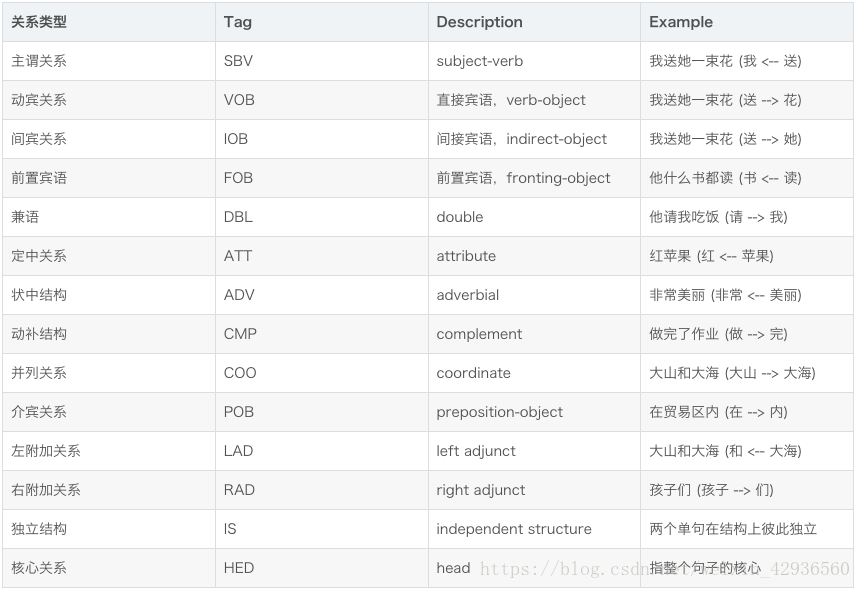
下面的列表列出了主要存在哪些关系以及相应的例子,箭头的方向为由从属词指向支配词:
那依存句法分析有哪些应用呢?
可对相应树库构建体系的正确性和完善性进行验证;
直接服务于各种上层应用,比如搜索引擎用户日志分析和关键词识别,比如信息抽取、自动问答、机器翻译等
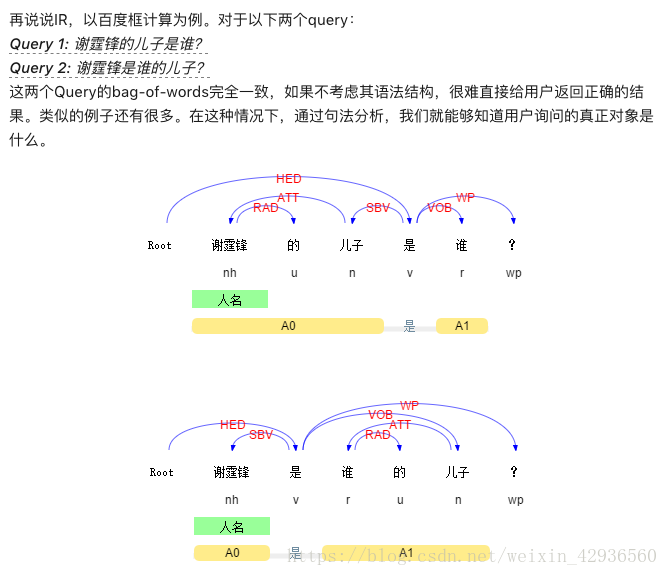
下面列举一个知乎上的例子(https://www.zhihu.com/question/39034550):
讲了这么多,还没说具体怎么实现依存句法分析呢?总不可能人工地去进行标注吧。
和很多问题一样,有两个方向来解决问题:基于规则和基于统计。现在的主流是基于统计的方法。
那具体地说,基于统计的有哪些方法呢?
一种是基于图的方法(Graph Based),一种是基于决策(Transition Based)的方法。
具体解释看这里(https://blog.youkuaiyun.com/sinat_26917383/article/details/55682996):

目前在开源中文句法分析器中比较具有代表性有Stanford parser和 Berkeley parser。

















 316
316

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









