







 本文讨论了分布式系统中如何解决id一致性问题,介绍了数据库自增id、UUID直接生成和号段模式的优缺点,强调高可用性、性能和业务可读性的重要性。
本文讨论了分布式系统中如何解决id一致性问题,介绍了数据库自增id、UUID直接生成和号段模式的优缺点,强调高可用性、性能和业务可读性的重要性。

前言
过去在单体架构的时候,数据库也是单库单表的时候,id可以随意设置数据库自增或者本地生成之类的都可以, 但是在分布式系统下,存在分库分表的情况,你单表的自增id是无法保证全局系统数据的id的一致性问题,所有引入分布式id的概念。在一些电商APP后者网站中,会有各种的订单id,退款id之类的,是可以直接看出来一些业务信息的,比如下单时间之类的。估分布式id的生成方案最好是要具备一定的业务性和可读性的
总结来说分布式id最好具备以下特性:
1.高可用
2.高性能
3.可读性,具备一定的业务信息
4.全局唯一(最核心重要的)
5.信息安全
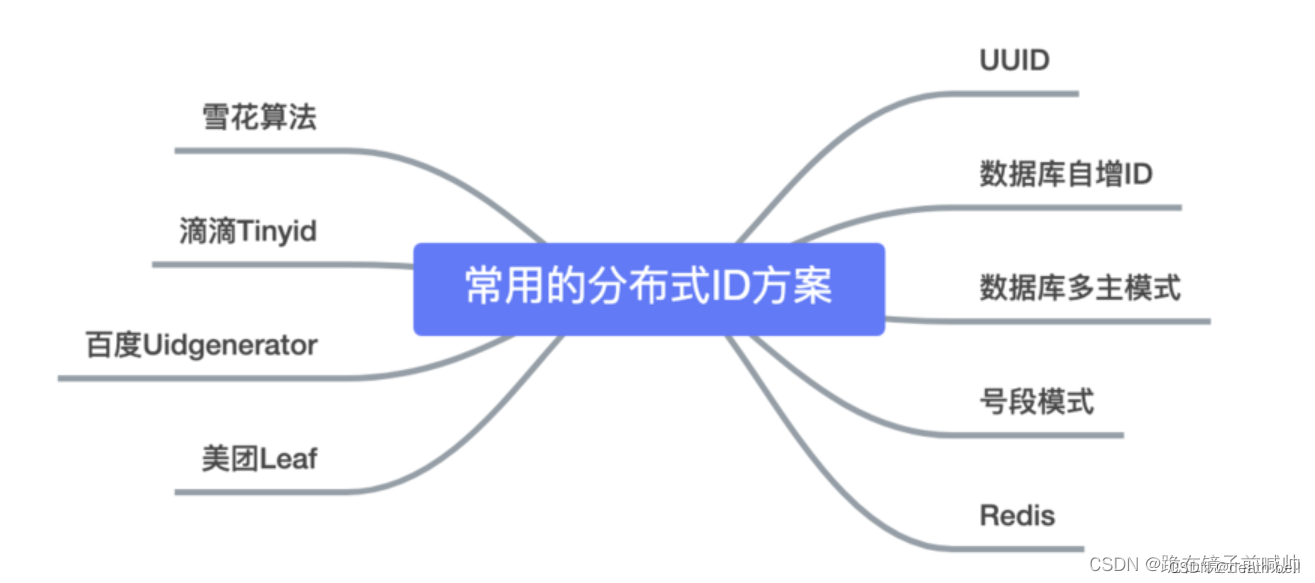
一、数据库自增id
不同表的id如果都是从一样的数字开始递增,势必会发生id重复,这时候需要设置每个表的步长和初始值
优点:
1.实现简单 可排序
缺点:
1.机器拓展麻烦
2.性能依赖数据库,有性能瓶颈
3.暴露商业信息,例如可以推断出来订单量
二、UUID直接生成
优点:
1.速度快
2.本地服务器直接生成
3,不同服务器不重复
缺点:
1.可读性差,不体现业务信息
2.存储空间高
3.无序无规律,无法排序
三、号段模式
号段模式是生成id的时候是直接去数据库生成批量的id到本地,下次要生成id的时候就不需要再次去数据库获取id,而是直接用本地的id直到本地的Id号码段用完才再次申请,提高id的生成效率
优点:
1.速度快
2.高可用 如果生成id的服务器宕机,也可以用本地id支撑一段时间 该时间可以去处理服务器宕机情况
缺点:
1.如果生成id的服务器宕机,且本地id用尽 会出现id大量空的情况
2.存储空间高
3.无序无规律,无法排序


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









