







【Java SE】SE语法备忘(2)
https://mp.youkuaiyun.com/postedit/90038581
JDK 8 以往版本
————————————————————————————————
零散笔记
——————————
- if代码块中的
continue;
for(){
XXXX;
if(){
...
}
continue;
}
continue表示终止当前操作,回到上面继续执行;
——————————
——————————
——————————
——————————
——————————
——————————
——————————
——————————
————————————————————————————————
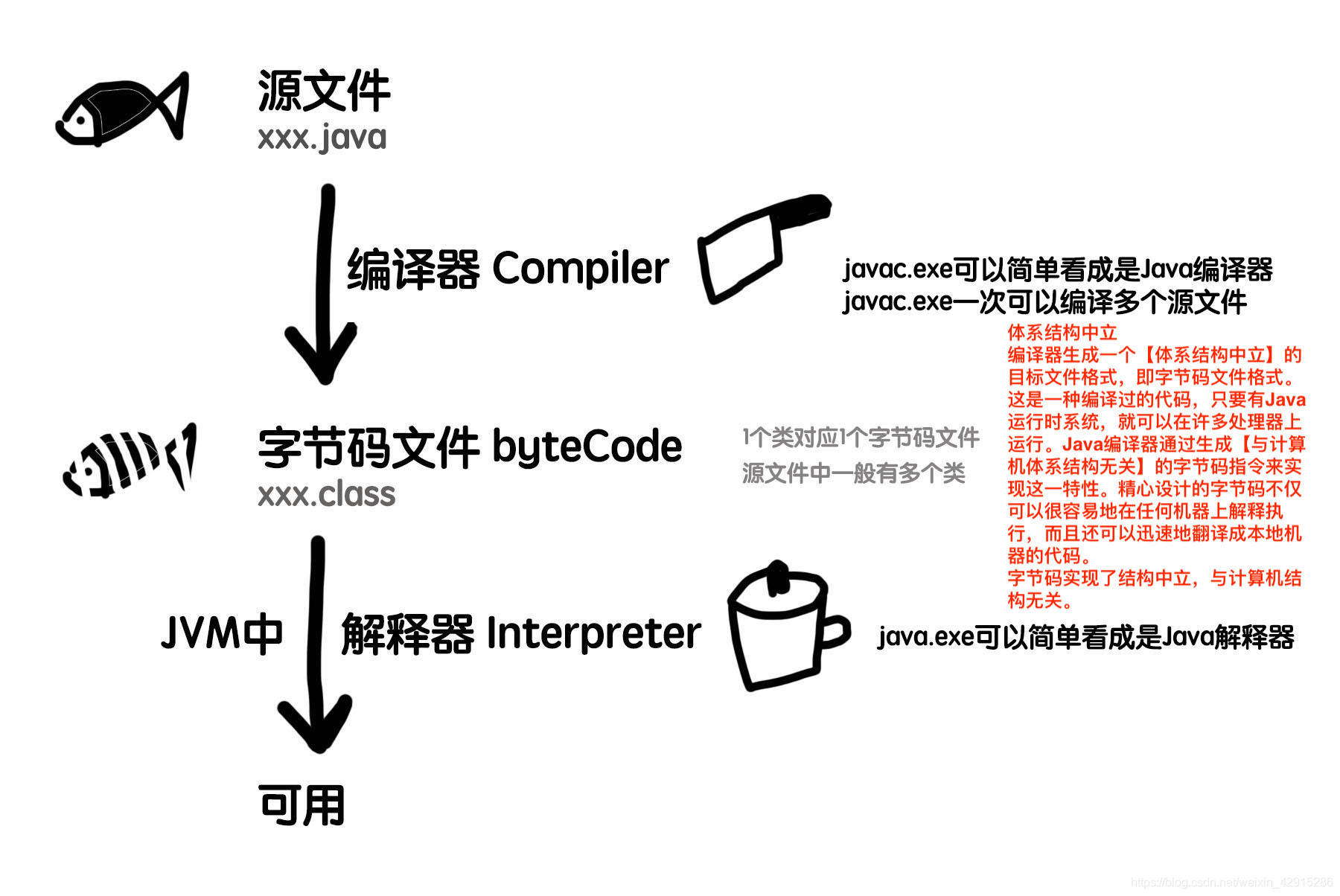
JAVAC JAVA JAR命令
平时运行编译,打包和运行程序都是由IDE或Maven这些打包工具来完成,应用上线部署都是由其他人来写Shell或bat启动停止脚本;
有一天让我把一个后台应用打包jar在Linxu部署运行我竟然懵了,好半天才想起来javac、java和jar命令;
Javac 命令
作用:把源文件(.java)文件编译为字节码文件(.class);
用法:javac <options> <source files>
options为命令选项。
source files为需要编译的java文件或所在的目录,多个java文件或目录用空格分隔。
Java 命令
作用:运行字节码文件;
用法:
执行类java [-options] class [args...]
执行jar文件java [-options] -jar jarfile [args...]
options表示命令选项。
class表需要执行的class文件
args…表示需要给执行的class文件main方法传递的参数,多个参数使用空格分隔;
Jar命令
作用:把编译好的程序打包成JAR包;
————————————————————————————————
ClassLoader 类加载器
- 提问:什么是ClassLoader?
写好一个Java程序之后,不是管是CS还是BS,都是由若干个字节码文件(.class)组织而成的一个完整的Java应用程序;
当程序运行时,会调用该程序的一个入口函数来启动调用,而这些功能都被封装在不同的字节码文件中,所以字节码文件要互相调用;
若调用的另一个文件不存在时,会引发系统异常;
程序启动时,并不会一次性加载所有字节码文件,而是根据程序的需要,通过Java的类加载机制(ClassLoader)来动态加载某个class文件到内存当中;
只当字节码文件被载入到了内存之后,才能被其它字节码文件所引用;
所以ClassLoader就是用来动态加载字节码文件到内存当中的;
- 白话:
ClassLoader翻译过来就是类加载器;
普通的java开发者其实用到的不多,但对于某些框架开发者来说却非常常见,理解ClassLoader的加载机制,也有利于我们编写出更高效的代码;
ClassLoader的具体作用就是将class文件加载到JVM中,程序就可以正确运行了;
但是,JVM启动的时候,并不会一次性加载所有的class文件,而是根据需要去动态加载;
想想也是,一次性加载那么多jar包那么多class,那内存不崩溃吗?
- 一句话:
根据一个指定的类的全限定名,找到对应的字节码文件,就可以把他转化成java.lang.Class类的一个实例;
————————————————
Java默认提供的三个ClassLoader
-
BootStrap ClassLoader:
启动类加载器,最顶层的类加载器,负责加载JDK中的核心类库,如:rt.jar、resources.jar、charsets.jar等; -
Extension ClassLoader:
称为扩展类加载器,负责加载Java的扩展类库,默认加载JAVA_HOME/jre/lib/ext/目下的所有jar; -
App ClassLoader:
称为系统类加载器,负责加载应用程序classpath目录下的所有jar和class文件;
————————————————
在项目中的应用:
ClassLoader cl = Thread.currentThread().getContextClassLoader();
————————————————
————————————————
————————————————————————————————
备注:
若Java项目中带了包地址如:package com.xxx;,如何用javac打包他?
javac后要加上-d和.表示directer和当前;
javac -d . 项目名.java
不加的话会运行失败;
Java基础
提问:Java中创建对象的5种方式
https://www.cnblogs.com/wxd0108/p/5685817.html
- 1.使用new关键字
调用了构造函数 - 2.使用Class类的newInstance方法 (这些用到了Java的反射原理)
调用了构造函数 - 3.使用Constructor类的newInstance方法
调用了构造函数 - 4.使用clone方法
没有调用构造函数 - 5.使用反序列化
没有调用构造函数
————————
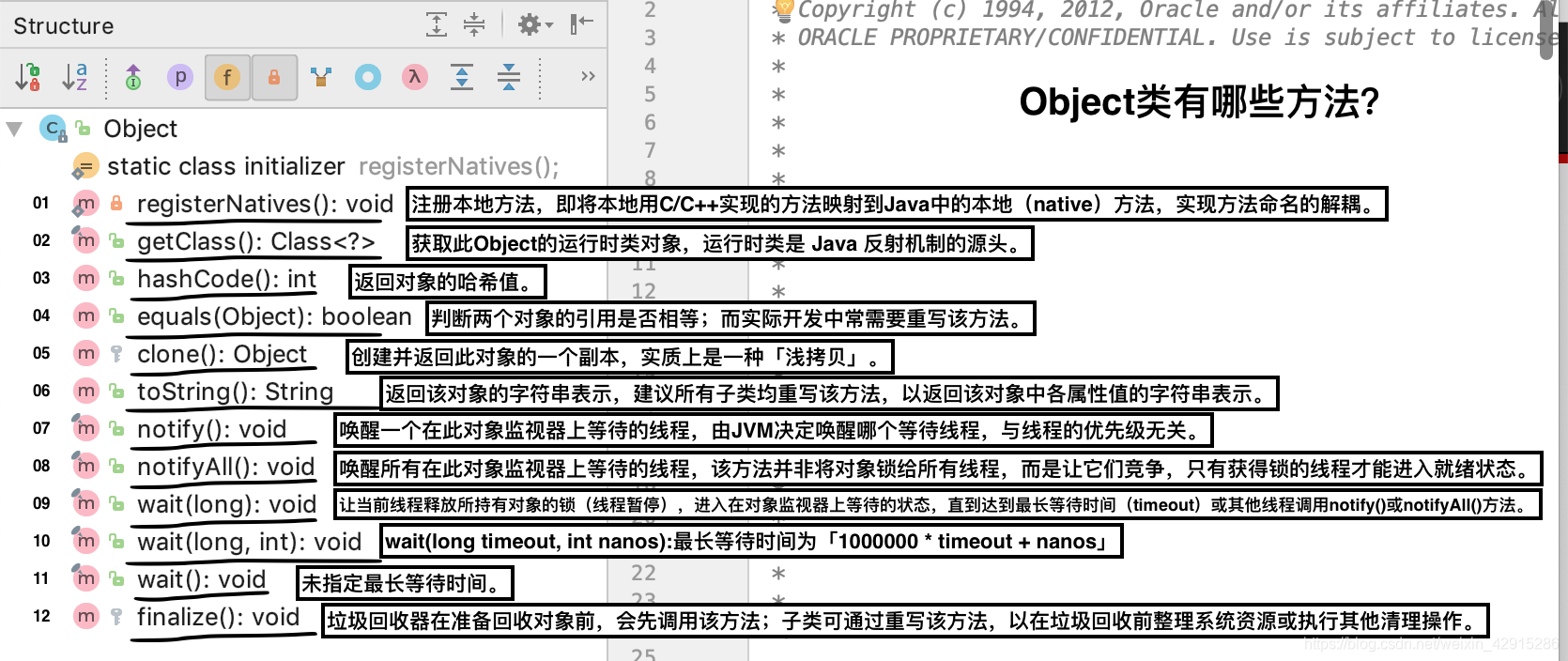
- 提问:Object类有哪些方法?
12个:
记忆方式:Rghect nn www f(*ck)
————————
Java标识符
开头:字母、下划线、美元符开头(A _ $)
之后:字母、下划线、美元符或数字(a/A _ $ 123)
大小写敏感,长度无限制,不能以数字开头。
1.java中能用作标识符的有:26个英文字母(大、小写),数字,下划线,美元符号$。
2.类名首个字母必须大写,多个单词组成的,每个单词首字母都要大写。
3.方法名一般首个字母小写(构造方法例外),多个单词组成方法名,后面单词首字母大写。
4.变量命名规则同方法名名。
注意:不能使用java中的关键字做标识符。
提问:下列标识符中,合理的是?
A._sys1_lll
B.2mail
C.$change
D.class
答:AC
提问:下列标识符中,合理的是?
A.2variable
B.variable2
C._whatever
D._3_
E.$another
F.#myvar
答:BCDE
————————
包
为了更好地组织类,Java 提供了包机制,用于区别类名的命名空间。
作用
1、把功能相似或相关的类或接口组织在同一个包中,方便类的查找和使用。
2、如同文件夹一样,包也采用了树形目录的存储方式。同一个包中的类名字是不同的,不同的包中的类的名字是可以相同的,当同时调用两个不同包中相同类名的类时,应该加上包名加以区别。因此,包可以避免名字冲突。
3、包也限定了访问权限,拥有包访问权限的类才能访问某个包中的类。
Java 使用包(package)这种机制是为了 防止命名冲突,访问控制,提供搜索和定位类(class)、接口、枚举(enumerations)和注释(annotation) 等。
java.long : 提供利用 Java 编程语言进行程序设计的基础类。
java.util: 包含 collection 框架、遗留的 collection 类、事件模型、日期和时间设施、国际化和各种实用工具类(字符串标记生成器、随机数生成器和位数组)。
包括java.util.List、java.util.Set、java.util.Map;
java.io: 通过数据流、序列化和文件系统提供系统输入和输出。
java.lang:提供Java程序设计的基础类(基础数据类型的封装类、Class、math、线程类)。lang包中的类的应用不需要手动import。
————————
Java的数据类型分两种:基本数据类型 + 符合数据类型(对象类型/包装类)
基本数据类型
记忆方法:
SBB LIC FD
沙比比 你是 FrD
字节 范围
boolean 1 true或false
char 2 从字符型对应的整型数来划分,其表示范围是0~65535
byte 1 -128~127
short 2 -32768~32767
int 4 -2147483648~2147483647 (-2^31 ~ 2^31-1)
long 8 -9223372036854775808 ~ 9223372036854775807
float 4 -3.4E38~3.4E38
double 8 -1.7E308~1.7E308
例子:
boolean :boolean a = true/false; 默认false
char : char a='d' char表示字符,定义的时候用单引号,只能存储单字符
byte :byte a = 127 (取值范围[-128,127] 不能超过!!!)默认0
short :如short s = 1000 如 short r = -20000 有符号
int :=
long :long a = 0xfffl; 整数字面量可以用八进制,十六进制和二进制格式表示;结果超出int数据类型的范围时使用
float :float a = 111.111f; 数字结尾必须写一个f!!!!!!!!默认0.0f
double :double d1 = 123.4 默认:0.0d
float和double都不是精确的,如果要储存钱一类的必须精确的,用java.math.BigDecimal!!!(注意下:算钱时,BigDecimal如何配置)
默认值:
int byte short long:0
float double:0.0
char:(空格)
boolean:false
基础数据类型之外:对象类型:
String:String a = "aaa" 字符串,定义的时候用双引号,可存储一个或者多个字符
- 1.
int类型定义的数组,初始化默认是0 - 2.
String类型定义的数组,默认值是null - 3.
char类型定义的数组,默认值是[0]对应的字符 - 4.
double类型定义的数组,默认值是0.0 - 5.
float类型定义的数组,默认值是0.0
————————
提问:下列表达式正确的是?
A. float f = 11.1;
B. double d = 5.3E12;
C. double d = 3.14159;
D. double d = 3.13D;
答:
BCD
————————
提问:long i = 1; int g = 1;double a = 1.0; float j = 1.0; 谁错了?
答:
最后一个应该写float j = 1.0f
————————
提问:存在使i + 1 < i的数吗?
答:存在
解析:如果 i 为 int 型,那么当 i 为 int 能表示的最大整数时, i+1 就溢出变成负数了,此时不就 <i 了吗。
————————
复合数据类型(包装类)
Long
Integer
Byte
Float
Double :Double a =1.0 或 Double a = 1.0d 都可以;
Char
String
其它一切java提供的,或者你自己创建的类。
复合数据类型都在java.lang包中!!!
提问:判断:Double对象在java.lang包中?
答:
对
————————
提问:Java程序初始化的顺序是怎样的?
若有父类与子类;
首先统一运行他们的静态方法(先父后子);
再运行父类中的:变量,代码块;
在运行子类中的:变量,代码块;
static{
静态方法
}
{
变量
}
public xxx(){
代码块
}
提问:下列代码的运行结果是?
class B extends Object{
static{
System.out.println("B1");
}
public xxx(){
System.out.println("B2");
}
static{
System.out.println("B3");
}
}
class A extends B{
static{
System.out.println("A1");
}
public xxx(){
System.out.println("A2");
}
}
public class Test{
public static void main(String[] args){
new A();
}
}
答:
B1 B3 A1 B2 A2
————————
Java变量的命名使用规则
可以以字母、下划线或者美元符开头;
不能以数字开头,后面跟字母、下划线、美元符、数字,变量名对大小写敏感,无长度限制;
class Base{
static{
System.out.println("Base static block");
}
{
System.out.println("Base block"); //这是变量
}
public Base(){
System.out.println("Base constructor"); //这是代码块
}
}
public class Derived extends Base{
static{
System.out.println("Derived static block");
}
{
System.out.println("Derived block");
}
public Derived(){
System.out.println("Derived constructor");
}
public static void main(String[] args){
new Derived();
}
}
______
答案:
Base static block
Derived static block
Base block
Base constructor
Derived block
Derived contructor
————————
提问:一个Java文件中是否可以定义多个类?
一个Java文件中可以定义多个类,但最多只能有一个被public修饰,且这个类名必须和文件名相同;
————————
提问:下列语句正确的是?
A. Java程序经过编译后会产生machine code
B. Java程序经过编译后会产生byte code
C. Java程序经过编译后会产生DLL
D. 都不对
答案B
byteCode即字节码文件 .class
————————
提问:Java创建对象的方式有几种?
4种:
1.new语句实例化一个对象;
2.反射机制创建对象;
3.clone()方法创建一个对象;
4.反序列化方式创建对象;
————————
Clone()方法:
什么是Clone
在实际编程过程中,我们常常要遇到这种情况:有一个对象A,在某一时刻A中已经包含了一些有效值,此时可能会需要一个和A完全相同新对象B,并且此后对B 任何改动都不会影响到A中的值,也就是说,A与B是两个独立的对象,但B的初始值是由A对象确定的。在Java语言中,用简单的赋值语句是不能满足这种需 求的。要满足这种需求虽然有很多途径,但实现clone()方法是其中最简单,也是最高效的手段。
有三个值得注意的地方:
- 1.实现了
Cloneable接口; - 2.重载了
clone()方法; - 3.最后在
clone()方法中调用了super.clone(),这也意味着无论clone类的继承结构是什么样的,super.clone()直接或间接调用了java.lang.Object类的clone()方法;第三点是最重要的;
【一道面试题】写clone()方法时,通常都有一行代码,是什么?
super.clone()
构造函数
Java中,构造函数 = 构造器 = 构造方法
构造函数与方法的区别是:构造函数没有返回值,但不用void修饰;
构造函数总是伴着new操作一起调用,必须由系统调用;构造函数在对象实例化时会被自动调用,且只运行一次;
构造函数作用:完成对象的初始化工作;
构造函数不能被继承,因此他不能被override,但能被overload;
构造其本质是static方法,虽然修饰符没有被表明;
提问:构造器和方法的区别:
1.功能不同:构造器创建对象,给属性初始化;方法是功能函数,仅仅执行Java代码;
2.修饰符、返回值、命名不同:构造器不能有下列访问性质的修饰:abstract,final,static,synchronized
构造器不能被这些修饰符修饰的原因:
abstract: 因为一个抽象的构造器将永远不会被实现,所以不用加abstract;
final: final指该方法不可被覆盖,隐含子类包含该父类方法的意思;但实际上子类不会继承父类的构造方法,此处矛盾;
static: 构造器总是关联一个对象而被调用,所以把它声明为static是没有意义的;
synchronized:没有实际的需要把构造器定义成同步的,因为它将会在构造的时候锁住该对象,直到所有的构造器完成它们的工作,这个构造的过程对其它线程来说,通常是不可访问的;
3.调用:构造器在创建对象时才调用,且只有一次;方法在创建对象后调用,随便用几次;
4.this的用法:
构造器中:指相同一个类中,不同参数列表的另一个构造器;
public class C entends P{
public C(int add){}
public C(){
this(10);
}
}
方法中:指向正执行方法的类的实例,静态方法不可以用this,因其不属于类的实例;
提问:正确的是?
A.类中的构造器不能省略
B.构造器必须和类同名,但方法不能和类同名
C.构造器在一个对象被new时执行
D.一个类只能定义一个构造器
答:C
A 构造器可省略,程序会默认加载
B 方法可以和类同名
D 构造器可以被重载,而重载在同类中,所以一个类可以定义多个构造器
————————————
提问:构造方法的描述中,错误的是?
A) Java 语言规定构造方法名与类名必须相同
B) Java 语言规定构造方法没有返回值,但不可用void 声明
C) Java 语言规定构造方法不可重载
D) Java 语言规定构造方法只能通过new自动调用
答:
C
————————————
提问:构造器中,为什么只能在第一行写this()或者super()?
比如有这么一个实体类:
public class User {
private String name;
private int age;
public User(String name, int age) {
super();
this.name = name;
this.age = age;
}
...
他没有父类,但他仍然写了一个super()???
可以理解为:他继承的是Object类,加不加这一行都无所谓;
为什么一定要在第一行?
super()在第一行的原因就是:
子类有可能访问了父类对象, 比如在构造函数中使用父类对象的成员函数和变量, 在成员初始化使用了父类, 在代码块中使用了父类等, 所以为保证在子类可以访问父类对象之前,要完成对父类对象的初始化。
this()在第一行的原因就是:
为保证父类对象初始化的唯一性. 我们假设一种情况, 类B是类A的子类, 如果this()可以在构造函数的任意行使用, 那么会出现什么情况呢? 首先程序运行到构造函数B()的第一行, 发现没有调用this()和super(), 就自动在第一行补齐了super() , 完成了对父类对象的初始化, 然后返回子类的构造函数继续执行, 当运行到构造函数B()的"this(2) ;"时, 调用B类对象的B(int) 构造函数, 在B(int)中, 还会对父类对象再次初始化! 这就造成了对资源的浪费, 当然也有可能造成某些意想不到的结果, 不管怎样, 总之是不合理的, 所以this() 不能出现在除第一行以外的其他行!
变量:
- 1.类变量(静态变量):独立于方法之外,有static修饰;
- 2.实例变量(成员变量):独立于方法以外,无static修饰;
- 3.局部变量:类的方法中的变量;
public class Variable{
static int allClicks=0; // 类变量
String str="hello world"; // 实例变量
public void method(){ * 执行 局部变量
int i =0; // 局部变量
} * 销毁 局部变量
}
3.局部变量
1.)局部变量声明在方法、构造方法或者语句块中;
2.)局部变量在方法…被执行的时候创建,当它们执行完成后,变量将会被销毁;
3.)访问修饰符不能用于局部变量;
4.)局部变量是在栈上分配的。
5.)局部变量没有默认值,所以局部变量被声明后,必须经过初始化!!! 才可以使用。
局部变量被初始化:
public class Test{
public void pupAge(){
int age = 0; //定义局部变量为0 - 初始化
age = age + 7;
System.out.println("小狗的年龄是: " + age);
}
public static void main(String[] args){
Test test = new Test();
test.pupAge();
}
}
局部变量未被初始化:
public class Test{
public void pupAge(){
int age; //局部变量没有被初始化
age = age + 7;
System.out.println("小狗的年龄是 : " + age);
}
public static void main(String[] args){
Test test = new Test();
test.pupAge();
}
}
2.实例变量(成员变量)
1.)实例变量声明在一个类中,但在方法、构造方法和语句块之外;
2.)当一个对象被实例化之后,每个实例变量的值就跟着确定;
3.)实例变量在对象创建的时候创建,在对象被销毁的时候销毁;
4.)实例变量的值应该至少被一个方法、构造方法或者语句块引用,使得外部能够通过这些方式获取实例变量信息;
5.)实例变量可以声明在使用前或者使用后;
6.)访问修饰符可以修饰实例变量;
7.)实例变量对于类中的方法、构造方法或者语句块是可见的。一般情况下应该把实例变量设为私有。通过使用访问修饰符可以使实例变量对子类可见;
8.)实例变量具有默认值。数值型变量的默认值是0,布尔型变量的默认值是false,引用类型变量的默认值是null。变量的值可以在声明时指定,也可以在构造方法中指定;
9.)实例变量可以直接通过变量名访问。但在静态方法以及其他类中,就应该使用完全限定名:ObejectReference.VariableName。
1.类变量(静态变量)
1.)类变量也称为静态变量,在类中以 static 关键字声明,但必须在方法之外。
2.)无论一个类创建了多少个对象,类只拥有类变量的一份拷贝。
3.)静态变量除了被声明为常量外很少使用。常量是指声明为public/private,final和static类型的变量。常量初始化后不可改变。
4.)静态变量储存在静态存储区。经常被声明为常量,很少单独使用static声明变量。
5.)静态变量在第一次被访问时创建,在程序结束时销毁。
6.)与实例变量具有相似的可见性。但为了对类的使用者可见,大多数静态变量声明为public类型。
7.)默认值和实例变量相似。数值型变量默认值是0,布尔型默认值是false,引用类型默认值是null。变量的值可以在声明的时候指定,也可以在构造方法中指定。此外,静态变量还可以在静态语句块中初始化。
8.)静态变量可以通过:ClassName.VariableName的方式访问。
9.)类变量被声明为public static final类型时,类变量名称一般建议使用大写字母。如果静态变量不是public和final类型,其命名方式与实例变量以及局部变量的命名方式一致。
static float max(float x, float y) { // 类方法
return x <= y ? y : x;
}
float min(float x, float y) { // 实例方法
return x <= y ? x : y;
}
类
类方法就是静态方法!!!
类方法不能调用实例方法!因为类方法最先开始加载,而这个时候实例方法还没被加载,类方法无法使用实例方法!!
静态方法中可用this来调用本类的类方法?
不可以,因为静态方法中可以不用实例化该类的实例,所以会不存在相应的实例,而this是只当前实例,所以不能用this。
内部类
在Java中,可以将一个类定义在另一个类里面或者一个方法里面,这样的类称为内部类。
分成:
成员内部类:最普通
局部内部类:定义在一个方法/作用域中的类
匿名内部类:【重点】最常用,无构造器
静态内部类:
——————————————
成员内部类:最普通
class Circle {
double radius = 0;
public Circle(double radius) {
this.radius = radius;
}
class Draw { //内部类
public void drawSahpe() {
System.out.println("drawshape");
}
}
}
——————————————
局部内部类:定义在一个方法/作用域中的类
class People{
public People() {
}
}
class Man{
public Man(){
}
public People getWoman(){
class Woman extends People{ //局部内部类
int age =0;
}
return new Woman();
}
}
——————————————
匿名内部类:最常用
内部类:一个类中定义另一个类,好理解;
而匿名内部类是什么?
一般定义一个类的时候都要显式地写:public class XXX(内部类也是这样);
但有一种方法,不需要显式地写类名,也能新建一个类,比如:
abstract class Person {
public abstract void eat();
}
public class Demo {
public static void main(String[] args) {
Person p = new Person() { // 匿名内部类
public void eat() {
System.out.println("eat something");
}
};
p.eat();
}
}
他的新建方式是引用一个抽象类new XX(){ ... };
这个类没有名字,所以被叫做匿名;
匿名内部类的实现方式:
。。。
在匿名内部类中使用外界属性?
外界属性必须定义为final,否则报错;
本质:
是内部类的简化写法;
是一个带具体实现的,父类或者父接口的,匿名的,子类对象。在开发的过程中,最常用到的就是匿名内部类。
前提:
匿名内部类必须是继承一个父类(具体或抽象皆可)或实现一个父接口。
步骤:
1.定义子类;2.重写接口中的方法;3.创建 子类对象;4.调用重写后的方法
格式:
两种方式,(1).接口,(2).抽象类;
对于实现接口,由于接口是没有构造函数的,注意这里一定是空参数。
对于父级抽象类,调用父类的构造器,注意此处可以是空参数,也可以传入参数。
其实这整体就相当于是new出来的一个对象;
(1).接口
new 父接口名()
{
...
}; //注意此处为分号
(2).抽象类
new 父类构造器(实参列表) //参数可写可不写
{
...
}; //注意此处为分号
举例实现:继承父类接口
interface D{
void ShowContext();
}
——————————————————————————————
class B {
public void show() {
new D() { //匿名内部类的实现
@Override
public void ShowContext() {
System.out.println("hello");
}
};
}
}
Button button = new Button();
button.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
...
}
});
——————————————
静态内部类
public class OuterClass {
static class StaticInnerClass {
...
}
}
提问:定义一个名为MyClass.java的类,并且该类可被一个工程中所有类访问,如何定义他?
A.private class MyClass extends Object
B.class MyClass extends Object
C.public class MyClass
D.public class MyClass extends Object
答:
CD
静态方法(类方法)
类方法就是静态方法!!!
用static修饰的方法。
由于类方法是属于整个类的,类方法不依赖对象而存在,所以类方法的方法体中不能有与类的对象有关的内容;
类方法在类被加载的时候就完成,此时还没有任何实例化对象被初始化;
类方法可以直接调用本类的类方法;
类方法可以调用任何类的类方法,前提要有权限;
不推荐类方法调用实例方法,但是也不是绝对不能;
类方法体有如下限制:
- 1.类方法中不能引用对象变量;
- 2.类方法中不能调用类的对象方法;
- 3.在类方法中不能调使用super,this关键字;(因为this是对当前类对象的引用)
- 4.类方法不能被覆盖;
- 5.类方法在该类被加载到内存时,就分配了相应的入口地址;从而类方法不仅可以被类创建的任何对象调用执行,也可以直接通过类名调用;类方法的入口地址直到程序退出时才被取消。
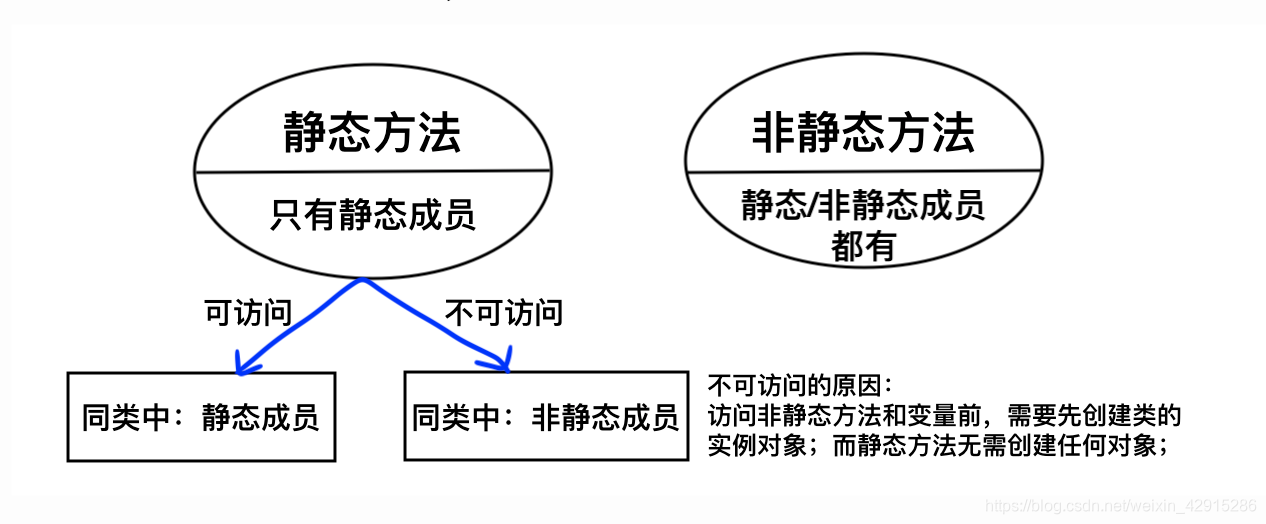
静态方法不能引用任何this super关键字!!!
因为静态方法使用前不许创建任何对象,所以this引用的对象不存在;
————————
提问:为什么需要main方法?
public static void main(String[] args)
他是Java程序的入口方法;
必须要有public和static修饰,返回值为void,且方法的参数为字符串数组;
1.JVM运行时,会首先找main()方法;
2.public 是权限修饰符,任何类和对象都可以访问他;
3.static表明main方法是一个静态方法,方法中的代码是存储在静态存储区的,只要类被加载后,就能直接通过类名 + main()直接访问,而不需要通过实例化对象来访问;
4.void表明方法没有返回值;
5.字符串数组参数args为开发人员在命令行状态下与程序交互提供了一种手段;
public和static必须有,同时可以调换顺序;
main方法可以为final;
main方法可以被synchronized修饰;
不能被abstract关键字修饰;
无论怎样,main方法都必须返回值为void;
实例方法
当一个类创建了一个对象后,这个对象就可以调用该类的方法(对象方法)。
- 1.实例方法中可以引用对象变量,也可以引用类变量;
- 2.实例方法中可以调用类方法;(父类实例方法/类方法可以被子类调用,除非private)
- 3.对象方法中可以使用super,this关键字;
- 4.当类的字节码文件被加载到内存时,类的实例方法不会被分配入口地址;当该类创建对象后,类中的实例方法才分配入口地址,从而实例方法可以被类创建的任何对象调用执行;
注意:
当我们创建第一个对象时,类中的实例方法就分配了入口地址,当再创建对象时,不再分配入口地址。
也就是说,方法的入口地址被所有的对象共享,当所有的对象都不存在时,方法的入口地址才被取消。
在Java语言中,类中的类方法不可以操作实例变量,也不可以调用实例方法;
这是因为在类创建对象之前,实例成员变量还没有分配内存,而且实例方法也没有入口地址。
提问:类方法中可不可以调用实例方法?
答案是可以,但是不推荐;
实际应用角度出发:类方法属于整个类,所有对象公用。而实例方法只提供实例化对象来使用。所以类方法调用实例方法没有意义;
语法角度出发:被static修饰的类是在类被加载时完成的,此时还没有任何实例化对象被初始化,实例的方法还不存在,所以无法调用;
但不是说绝对不可以调用,若有对象被实例化了,此时实例化对象就存在了,可以通过类方法调用实例方法:
public class Test{
public void print(String str){
System.out.println(str);
}
public static void main(String[] args){
String a = "hello";
print(a); //无实例化对象,错误
}
}
public class Test{
public void print(String str){
System.out.println(str);
}
public static void main(String[] args){
String a = "hello";
Test t = new test(); 有实例化对象,成功
t.print(a);
}
}
谈谈final、finally、finalize 有什么不同?
Final 可以用来修饰类、方法、变量,分别有不同的意义:final 修饰的 class 代表不可以继承扩展, final 的方法不可以重写(override),final 的变量不可以修改。
Finally 则是 Java 保证重点代码一定要被执行的一种机制。我们可以使用try-finally 或者 try- catch-finally来进行类似关闭JDBC 连接、保证unlock 锁等动作。
Finalize 是基础类java.lang.Object 的一个方法,它的设计目的是保证对象在被垃圾收集前完成特定资源的回收。finalize 机制现在已经不推荐使用,并且在 JDK 9 开始被标记为 deprecated。(此方法会在垃圾回收器 启动前 调用;另外,调用了此方法不一定会销毁垃圾,而C++中,调用了析构函数后,一定会销毁垃圾;所以finalize和析构函数不是一回事)
数组
数组是一种对象
数组一般指实例化、被分配空间的类,不属于原生类(原生类指未被实例化的类)
一维数组
- (1).
int[] a = new int[10](推荐:定义了一个数字实例a,并给其分配了10个int变量大小的存储空间) - (2).
int a[] = new int[10](沿用C语言格式) - (3).
int[] a = {1,2,3,4}或new int[] {1,2,3,4}(后面的格式中[]内必须为空)
备注:数组的格式乍看上去懂,但是放在实际环境中可能会蒙圈;
比如:int arr[] = new int[10]; 能理解吗?
————————
二维数组 :3种格式
- (1).
int a[][] = {{1,2,3,4},{5,6,7,}}或new int[行][列] - (2).
int [][]a = 右边同上 - (3).
int []a[] = 右边同上
注:左边括号内不能写数字;而右边的话,因为Java第二维长度可以不同,所以可以写比如
int[][]a=new int[2][]
a[0]=new int[]{1,2}
a[1]=new int[]{3,4,5}
有两行,第一行2列,第二行3列
————————
一维数组也可以拆分开来写:
int[]a;
a=new int[5];
int[]a;
a=new int[]{1,2,3,4};
————————
数组输出的问题(易错):
String[] a = {"haha","hoho"};
System.out.println(a);
————————————
输出:
[Ljava.lang.String;@65ab7765
String[] a = {"haha","hoho"};
for (String arg:a){
System.out.println(arg);
}
————————————
输出:
haha
hoho
————————
length(易错)
若有个数组如下:
int [] s = new int[10]
说明有10个元素:[0][1][2][3][4][5][6][7][8][9]
而s.length = 10,而不是等于9(易错!!)
————————
数组不同属性的默认值(易错)!!!!!!!!!!!!!!!!!!!
例题:String[] s = new String[10];,下面描述正确的是?
A.s[10]为“”
B.s[9]为null
C.s[0]为未定义
答案是B
如果只写int [] a;
那么a的值肯定是null
如果写int [] a=new int [10];
每个值a[0] a[1] a[2]...默认值都是0,而不是未定义或者null!!!
那么就要注意!!!
数组所有元素都有默认值!!!
不同的类型的默认值有不同!!!
- 1.
int类型定义的数组,初始化默认是0 - 2.
String类型定义的数组,默认值是null - 3.
char类型定义的数组,默认值是[0]对应的字符 - 4.
double类型定义的数组,默认值是0.0 - 5.
float类型定义的数组,默认值是0.0
提问:编译运行以下程序后,输出结果是?
A.输出结果为:value is 99.99
B.输出结果为:value is 9
C.输出结果为:value is 9.0
D.编译错误
易错!!
答案为:C
因为若遇到int类型和double类型比较取值时,程序会自动把int类型编译成doublel类型;
所以虽然会取值9,但是9会转换成9.0
提问:编译运行以下程序后,输出结果是?
public class foo{
public static void main(String[] args){
String s;
System.out.println("s=" + s);
}
}
A.代码得到编译,并输出 s=
B.代码得到编译,并输出 s=null
C.由于String s没有初始化,代码不能编译通过;
D.代码得到编译,但补货到NullPointerException
答:
没有初始化,不能编译通过;
数组的转换!!!
String转Set:
Collections.asSet(XXX);
Map转List:
(Map的value)
Map<Integer,实体类>初始化。。。
Collection<实体类> collection = map.values();
List<实体类> list = new ArrayList<>(collection);
数字直接转成List:Arrays.asList(2,3,1);
———————————————
提问:Set转List?
因为Set的元素不可重复,所以Set转成List是容易的;
假如有个Set集合的实例为S;
转化成List:
List list = new ArrayList(S);
还有一种方法,还没验证过:
Set转List
String[] staffs = new String[]{"Tom", "Bob", "Jane"};
Set<String> staffsSet = new HashSet<>(Arrays.asList(staffs));
List<String> result = new ArrayList<>(staffsSet);
———————————————
提问:数组转List?
String[] staffs = new String[]{"Tom", "Bob", "Jane"};
List staffsList = Arrays.asList(staffs);
需要注意的是, Arrays.asList()返回一个受指定数组决定的固定大小的列表。所以不能做add 、 remove 等操作,否则会报错UnsupportedOperationException。
如果想再做增删操作呢?将数组中的元素一个一个添加到列表,这样列表的长度就不固定了,可以进行增删操作。
List staffsList = new ArrayList<String>();
for(String temp: staffs){
staffsList.add(temp);
}
staffsList.add("Mary"); // ok
staffsList.remove(0); // ok
———————————————
提问:数组转Set?
String[] staffs = new String[]{"Tom", "Bob", "Jane"};
Set<String> staffsSet = new HashSet<>(Arrays.asList(staffs));
staffsSet.add("Mary"); // ok
staffsSet.remove("Tom"); // ok
———————————————
提问:List转数组?
String[] staffs = new String[]{"Tom", "Bob", "Jane"};
List staffsList = Arrays.asList(staffs);
Object[] result = staffsList.toArray();
———————————————
提问:List转Set?
String[] staffs = new String[]{"Tom", "Bob", "Jane"};
List staffsList = Arrays.asList(staffs);
Set result = new HashSet(staffsList);
———————————————
提问:Set转数组?
String[] staffs = new String[]{"Tom", "Bob", "Jane"};
Set<String> staffsSet = new HashSet<>(Arrays.asList(staffs));
Object[] result = staffsSet.toArray();
———————————————
提问:字符串转List?
麻烦,建议字符串转Char
———————————————
提问:字符串转Char?
char[] 新实例 = 字符串.toCharArray();
———————————————
个人心得:
综上所述,这些方法除了提供:集合之间和数组之间的正常转换,还有一个作用:
例子:需要写一个List,同时往里面添加元素,本来是这么写的:
List<Integer> list = new ArrayList();
list.add(2);
list.add(3);
list.add(1);
但有了List和数组间的转换,我们就可以把上述代码简化成一句话:
List<Integer> list = Arrays.asList(2,3,1);
String StringBuffer StringBuilder 字符串
日常使用的字符串,别看它似乎很简单,但其实字符串几乎在所有编程语言里都是个特殊的存在,因为不管是数量还是体积,字符串都是大多数应用中的重要组成。
字符串分成3大类:
- String 字符串常量(线程安全):不可变类
- StringBuffer 字符串变量(线程安全)字符串缓存区
- StringBuilder 字符串变量(非线程安全)字符串缓存区
若在共享场合中使用,而当一个字符串需要被修改时,最好用StringBuffer;
若用String保存经常需要修改的字符串,字符串修改时会比StringBuffer多了很多附加的操作,同时也会生成很多无用的对象,由于这些无用的对象会被垃圾回收器回收,所以大大规模项目中会对程序运行效率带来负面影响。
————————
提问:int和Integer的区别?
Integer是引用类型,是int的包装类;
Integer默认为null;
int默认为0,不可为null;
————————
提问:System.out.println("5" + 2);的输出结果是?
int类型的2在这里会被转化为String类型的2;
而5本来就是String类型;
这里的结果会是:52;
————————
String… args的用法
String... args是一个字符串数组,好处是可以填入无限个数的参数;
public static void haha(String...args){
StringBuilder result = new StringBuilder("eh...");
for (String arg:args){
result.append(arg);
}
System.out.println(result.toString());
}
public static void main(String[] args) {
haha("oh?","ouch!");
}
————————————
输出:
eh...oh?ouch!
错误经验:
参数写错了,haha方法的for循环中写成了:result.append(args);
导致输出结果为:eh...[Ljava.lang.String;@65ab7765[Ljava.lang.String;@65ab7765
————————
- 提问:
String... args和String[] args的区别?
String... args是JDK5之后的新特性,为可变参数;之前用 String[] args 来定义,两者没本质区别;
其实main函数也能这么写:public static void main(String... args) {};
但它毕竟不是官方推荐的写法,所以main函数避免这么写;
String... args的意思是:可以传无限参数,是一个字符串数组;
————————
提问:++在字符前后有什么区别?
几乎所有有++写法的语言关于它的用法都一样,包括C;
++ a 在前:先自增,后使用(符合一般人类的逻辑)
a ++ 在后:先使用,后自增
自增:指在内存中增加数量,此步骤肉眼看不到;
使用:指输出来的数量,此步骤肉眼看得到;
int age = 6;
System.out.println("age=" + ++age); // 前:先自增后使用;先内存中自加1等于7,再使用他,输出7
System.out.println("age=" + age++); // 后:先使用再自加;先打印7,然后自加变成8,此时age在内存中的值已经是8了
System.out.println("age=" + age); // 这个时候再输出a,就等于内存中的值:8了
System.out.println(++age); // 前:输出9
System.out.println(age++); // 后:输出9,然后内存变成10
System.out.println(age); // 输出10
提问:执行下列代码后的结果是什么?
int x,a = 2,b =3,c =4; x = ++a+b++ +c++
答:
++a = 3
b++ = 3
C++ = 4
3+3 +4 = 10
————————
提问:执行下列代码后的结果是什么?
public static void main(String[] args) {
int c = 2;
System.out.print(c);
System.out.print(c++);
System.out.print(c);
}
答:
223
————————
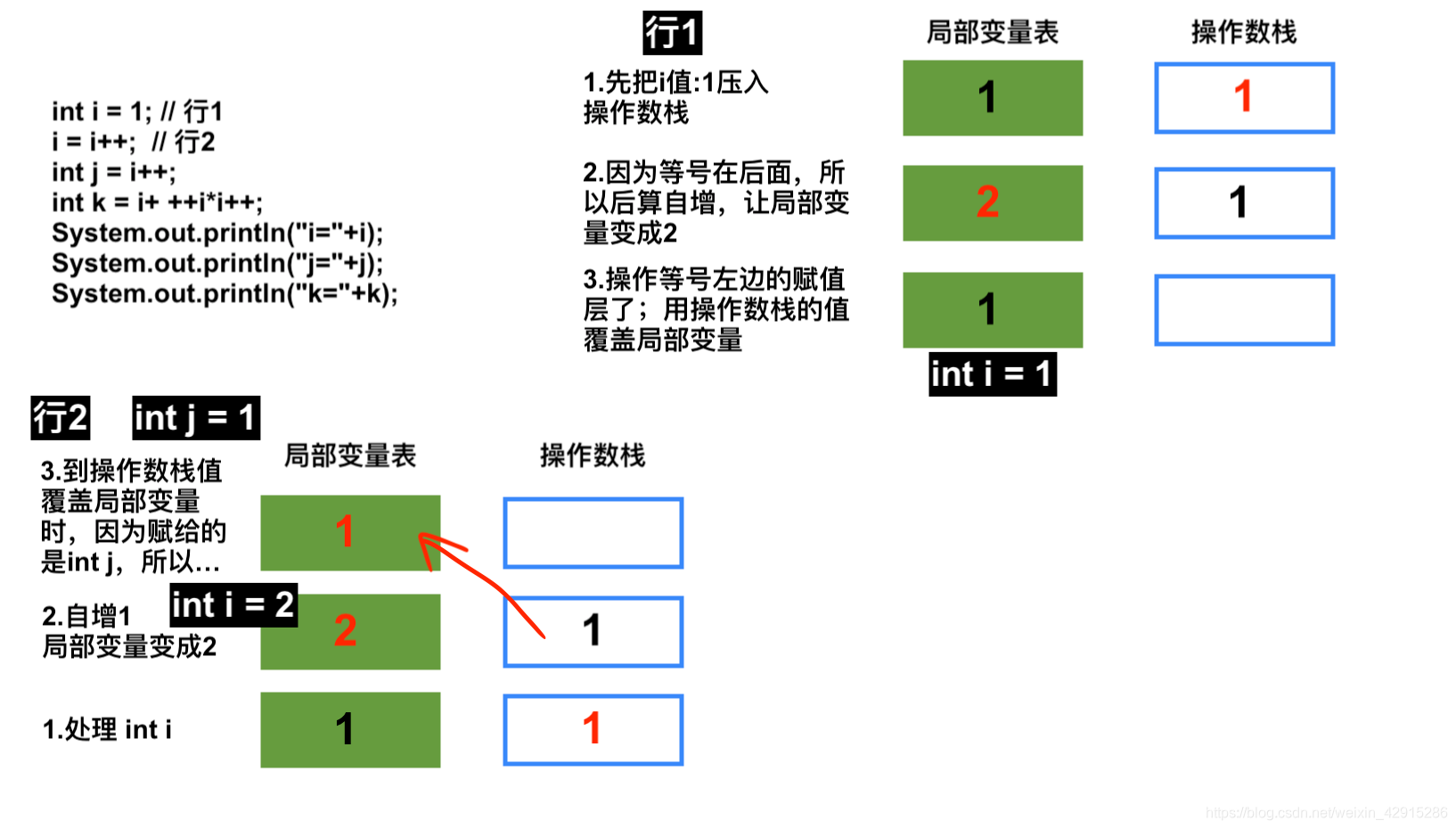
提问:结果是?
int i = 1;
i = i++;
int j = i++;
int k = i+ ++i*i++;
System.out.println("i="+i);
System.out.println("j="+j);
System.out.println("k="+k);
————————
输出:
i=4
j=1
k=11
这道题和一般的题目思路不一样,我的理解是:
因为普通题目都把++写在输出语句里,这样就好理解;
而这道题把++定义在了若干变量中,定义在了变量中就会带来很多问题;
https://www.bilibili.com/video/av37602130?from=search&seid=16364675964322398701
————————
提问:String s = new String("xyz"); 创建了几个字符串对象?
2个:“xyz” 和new String(“xyz”)
new String(“xyz”)这个对象在堆中分配内存,只不过这个对象的内容是指向字符串常量"xyz" ;
提问:这几行代码分别创建了几个String对象?
String str = "abc"; // 1个
String a = "ab"+"cd"; // 3个
——————————————————
String.format()
从 Java 5.0 开始,String 类新增了一个强大的字符串格式化方法 format();
这个方法到现在用的人还是不多,实在是一种浪费,若掌握得好,可能就不需要再借用第三方类库或自己去实现了;
————————
- 提问:为什么要用到他?
开发中经常要用到一种字符串格式,比如 姓名:A,年龄:20;
同时通常伴随着一串名单,每个人的属性都要填进去,难道每一行都硬编码吗?
用 String.format 就可以灵活返回满足格式的字符串们;
————————
占位符类型
(有小写大写之分)
常用:
| 字母 | 适用参数类型 | 说明 |
|---|---|---|
| %s / %S | 字符串 | 对字符串进行格式化输出 |
| %d | 整数 | 对整数进行格式化输出 |
| %f | 浮点数 | 对浮点数进行格式化输出 |
| %t | 日期时间 | (偶尔用)对日期时间进行格式化输出 |
完整表格:
| 字母 | 适用参数类型 | 说明 |
|---|---|---|
| %a | 浮点数 | 以16进制输出浮点数 |
| %b / %B | 任意值 | 如果参数为 null 则输出 false,否则输出 true |
| %c / %C | 字符或整数 | 输出对应的 Unicode 字符 |
| %d | 整数 | 对整数进行格式化输出 |
| %e / %E | 浮点数 | 以科学记数法输出浮点数 |
| %f | 浮点数 | 对浮点数进行格式化输出 |
| %g / %G | 浮点数 | 以条件来决定是否以科学记数法方式输出浮点数 |
| %h / %H | 任意值 | 以 16 进制输出参数的 hashCode() 返回值 |
| %o | 整数 | 以8进制输出整数 |
| %s / %S | 字符串 | 对字符串进行格式化输出 |
| %t | 日期时间 | 对日期时间进行格式化输出 |
| %x / %X | 整数 | 以16进制输出整数 |
| %n | 无 | 换行符 |
| %% | 无 | 百分号本身 |
————————
例子:
String str = String.format("%s今年%d岁。", "小李", 30);
System.out.println(str);
————————————
输出:
小李今年30岁。
String.format("%s, world", "Hello"); // 输出 "Hello, world"
String.format("%10s, world", "Hello"); // 输出 " Hello, world"
String.format("%-10s, world", "Hello"); // 输出 "Hello , world"

类似地:
String.format("%-8d", 123); // 输出 "123 "
String.format("%-08d", 123); // 错误!不允许在右边补齐 0
String.format("%.5s", "Hello, world"); // 输出 "Hello"
String.format("%.5s...", "Hello, world"); // 输出 "Hello..."
String.format("%10.5s...", "Hello, world"); // 输出 " Hello..."
String.format("%,d", 1234567); // 输出 "1,234,567"
String.format("%s%s","haha","xixi"); // 输出 "hahaxixi"
————————
————————
————————
——————————————————
String[] split = str.split("");
把一长串字符串分割成【单个】的【字符串数组】;
String str1 = "中国&&广东&&广州";
String[] strlist1 = str1.split("&&");
for (String s:strlist1){
System.out.println(s);
}
————————————————
输出:
中国
广东
广州
但是!若要分隔|符的话,需要在splitl里写\\|;
例子:
String str2 = "中国||广东||广州";
String[] strlist2 = str2.split("||");
for (String s:strlist2){
System.out.println(s);
}
————————————————
输出:
中国
|
|
广东
|
|
广州
String str2 = "中国||广东||广州";
String[] strlist2 = str2.split("\\|\\|");
for (String s:strlist2){
System.out.println(s);
}
————————————————
输出:
中国
广东
广州
————————
Integer.parseInt()
parseInt()方法用于将【字符串参数】作为有符号的【十进制整数】进行解析。
如果方法有两个参数, 使用第二个参数指定的基数,将字符串参数解析为有符号的整数。 (若无第二个参数,则默认为10,即十进制)
int x =Integer.parseInt("9");
//输出:9
int b = Integer.parseInt("444",16);
//输出:1092(444的16进制)
double c = Double.parseDouble("5");
//输出:5.0
————————
Math.Random()
random()方法可返回介于 0 ~ 1 之间的一个随机数;这个数可能为0,但会小于1。
random() ....后 接乘法符:*
random.next()后 接除法符:%
random() ....后 接乘法符:*
random.next()后 接除法符:%
random() ....后 接乘法符:*
random.next()后 接除法符:%
random() ....后 接乘法符:*
random.next()后 接除法符:%
Math.random()*(n-m)+m,生成 >=m 且 <n 的随机数:[m,n);
例:设置一个随机1到3([1,3))的变量
答:int num = (int)(Math.random()*2+1);

例:math.random()*26代表什么意思?
答:[0,26)
例:int i= (int)(math.random()*26+97)代表什么意思?
答:[97,123)
例:Random rand = new Random(47);
括号中是种子数,他只是随机算法的起源数字,和生成的随机数字的区间无关!
47是一个神奇的数字,参数为47时,随机率最高;
这个问题到现在都没人能够解释,只是经过很多次试验得到的,包括《Thinking in java》的作者布鲁斯.艾克尔也这么提到:由47做种后,产生的随机数更加体现了随机性;
它没有什么具体的意义,只要理解随机数如果有一个种子,哪么出现了比较随即的随机数;
而当种子是47的时候,随即率是最大的。
(1)java.util.Random类中实现的随机算法是伪随机,也就是有规则的随机,所谓有规则的就是在给定种(seed)的区间内随机生成数字;
(2)相同种子数的Random对象,相同次数生成的随机数字是完全相同的;
(3)Random类中各方法生成的随机数字都是均匀分布的,也就是说区间内部的数字生成的几率均等;
——————————————
Random.nextInt()方法
random() ....后 接乘法符:*
random.next()后 接除法符:%
random() ....后 接乘法符:*
random.next()后 接除法符:%
random() ....后 接乘法符:*
random.next()后 接除法符:%
random() ....后 接乘法符:*
random.next()后 接除法符:%
例:Random().nextInt()
1、 不带参数的nextInt() 会生成所有有效的整数(包含正数,负数,0)
2、 带参的nextInt(int x) 则会生成一个范围在[0,x)内的任意正整数
例如:int x=new Random.nextInt(100);
则x为一个[0,99)的任意整数
3、生成一个指定范围内的整数
/*
* 生成[min, max]之间的随机整数
* @param min 最小整数
* @param max 最大整数
*/
private static int randomInt(int min, int max){
return new Random().nextInt(max)%(max-min+1) + min;
}
int i = (int)(Math.random()%171) + 30;
意思是:生成范围在[30,201)的随机数字;
(random.nextInt())%26+97;
意思是:生成范围在([97,124))[97,123]的随机数字:查询ASCII,即a-z
Math.abs(random.nextInt())%26+97;
加上一个绝对值;
————————
提问:为什么String要被设计成不可变量?
- 1.节省空间:把字符串常量存储在常量池中,这些字符串可以被共享;为保证用户间String修改不会乱套,String被设计成不可变量;
- 2.提高效率:因为String 会被不同用户共享,所以亦有可能被不同线程共享,为保证线程安全,String被设计成不可变量;另外,String常被当作
HashMap的key值使用,String不可变就可以让每次hash值不用每次都计算一次; - 3.安全因素:因String常被当作参数使用(如
用户名、密码),为保证黑客不能通过特定手段对这些参数进行修改,造成安全隐患,String被设计成不可变量;
————————
新建一个String对象的过程?
由于String在Java世界中使用过于频繁,Java为了避免在一个系统中产生大量的String对象, 引入了字符串常量池。
其运行机制是:创建一个字符串时,首先检查池中是否有值相同的字符串对象,如果有,则不需要创建,直接引用池中刚查找到的对象;如果没有,则新建字符串对象,返回对象引用,并且将新创建的对象放入池中。
但是,通过new方法创建的String对象是不检查字符串池的,而是直接在堆区或栈区创建一个新的对象,也不会把对象放入池中。这些原则只适用于通过直接量给String对象引用赋值的情况。
举例:String str1 = "123"; 通过直接量赋值方式,放入字符串常量池;
String str2 = new String(“123”); 通过new方式赋值方式,不放入字符串常量池;
注意:String提供了inter()方法。调用该方法时,如果常量池中包括了一个等于此String对象的字符串(由equals方法确定),则返回池中的字符串。否则,将此String对象添加到池中,并且返回此池中对象的引用。
————————
修改String字符串的实现原理:
首先创建一个StringBuffer,然后调用StringBuffer的append方法,最后调用StringBuffer的toString方法把结果返回;
String s = "Hello";
StringBuffer sb = new StringBuffer(s);
s.append("World");
s = sb.toString();
另外:
public static void link(String a){
a += "World";
}
public static void main(String[] args) {
String a = "Hello";
link(a);
System.out.println(a);
}
输出:
Hello
public static String link(String a){
a+="World";
return a;
}
public static void main(String[] args) {
String a = "Hello";
a = link(a);
System.out.println(a);
}
输出:
HelloWorld
————————
String、StringBuffer和StringBuilder的关系?
各自的含义:
1.String含义为引用数据类型,是字符串常量.是不可变的对象,(显然线程安全)在每次对string类型进行改变的时候其实都等同与生成了一个新的String对象;
然后指针指向新的String对象,所以经常改变内容的字符串最好不使用String,因为每次生成对象都会对系统性能产生影响,特别当内存中无引用对象多了之后.JVM的垃圾回收(GC)就会开始工作,对系统的性能会产生影响
2.StringBuffer 线程安全的可变字符序列;
对StringBuffer对象本身进行操作,而不是生成新的对象.所所以在改变对象引用条件下,一般推荐使用StringBuffer.同时主要是使用append和insert方法,
3.StringBuilder 线程不安全的可变字符序列;
提供一个与StringBuffer兼容的API,但不同步.设计作为StringBuffer的一个简易替换,用在字符缓冲区被单个线程使用的时候.效率比StringBuffer更快
————————
提问:String、StringBuffer和StringBuilder的区别?
执行速度:StringBuilder> StringBuffer > String
线程安全:StringBuffer线程安全.StringBuilder线程不安全
String适用与少量字符串操作;
StringBuffer使用多线程下在字符缓冲区进行大量操作的情况;
StringBuilder适用单线程下在字符缓冲区下进行大量操作的情况;
组织文字:
String 是 Java 语言非常基础和重要的类,提供了构造和管理字符串的各种基本逻辑。它是典型的Immutable 类,被声明成为 final class,所有属性也都是final的。也由于它的不可变性, 类似拼接、裁剪字符串等动作,都会产生新的 String 对象。由于字符串操作的普遍性,所以相关操作的效率往往对应用性能有明显影响。
StringBuffer 是为解决上面提到拼接产生太多中间对象的问题而提供的一个类,它是 Java 1.5 中新增的,我们可以用 append ()或者 add() 方法,把字符串添加到已有序列的末尾或者指定位置。StringBuffer 本质是一个线程安全的可修改字符序列,它保证了线程安全,也随之带来了额外的性能开销,所以除非有线程安全的需要,不然还是推荐使用它的后继者,也就是 StringBuilder。
StringBuilder 在能力上和 StringBuffer 没有本质区别,但是它去掉了线程安全的部分,有效减小了开销,是绝大部分情况下进行字符串拼接的首选。
————————
他们的适用环境?
[A]在字符串内容不经常发生变化的业务场景优先使用 String 类。例如:常量声明、少量的字符串拼接操作等。
如果有大量的字符串内容拼接,避免使用String与String之间的+操作,因为这样会产生大量无用的中间对象,耗费空间且执行效率低下(新建对象、回收对象花费大量时间)。
[B]在频繁进行字符串的运算(如拼接、替换、删除等),并且运行在多线程环境下,建议使 用 StringBuffer ,例如XML解析、HTTP参数解析与封装。
[C]在频繁进行字符串的运算(如拼接、替换、删除等),并且运行在单线程环境下,建议使 用 StringBuilder,例如SQL语句拼装、JSON封装等。
————————
提问:对于敏感数据(如密码),为什么使用“字符数组”存储比用“Stirng”存储安全?
Java中,String是不可变类,他存储在常量字符串池中,从而实现了字符串的共享,减少内存开支;
所以,即使这个字符串(如密码)不再被使用,他仍然会存在于常量池中一段时间;
只有垃圾回收器可以将其收回,但Java程序员无法主动操作垃圾回收器;
因此此时有权限访问memory dump(存储器转储)的程序都可能会访问到这个字符串,从而把敏感的数据暴露出去,这是个非常大的安全隐患;
但,若使用字符数组,一旦程序不再使用这个程序,程序员可以把字符数组内容设置为空,此时数据在内存中就不存在了。
综上,与String相比,字符数组对数据的生命周期有更好的控制,从而增强安全性。
字符数组指 char数组 即 char[]
————————
不可变类 Immutable Class
创建了这个类的实例后,就不允许修改他的值的类;
Java中,所有基本类型的包装类都是不可变类,如Integer、Float等,String也是;
————————
提问:String str=“hello world” 和 String str=new String(“hello world”) 的区别
此处还涉及此下部分:
页面搜索:提问:== 和 .equals() 的区别?
public class Main {
public static void main(String[] args) {
String str1 = "hello world";
String str2 = new String("hello world");
String str3 = "hello world";
String str4 = new String("hello world");
System.out.println(str1==str2);
System.out.println(str1==str3);
System.out.println(str2==str4);
}
}
false
true
false
在前面一篇讲解关于JVM内存机制的一篇博文中提到 ,在class文件中有一部分来存储编译期间生成的字面常量以及符号引用,这部分叫做class文件常量池,在运行期间对应着方法区的运行时常量池。
因此在上述代码中,String str1 = "hello world";和String str3 = "hello world"; 都在编译期间生成了 字面常量和符号引用,运行期间字面常量"hello world"被存储在运行时常量池(当然只保存了一份)。通过这种方式来将String对象跟引用绑定的话,JVM执行引擎会先在运行时常量池查找是否存在相同的字面常量,如果存在,则直接将引用指向已经存在的字面常量;否则在运行时常量池开辟一个空间来存储该字面常量,并将引用指向该字面常量。
通过new关键字来生成对象是在堆区进行的,而在堆区进行对象生成的过程是不会去检测该对象是否已经存在的。因此通过new来创建对象,创建出的一定是不同的对象,即使字符串的内容是相同的。
————————————————————————————————————
提问:== 和 .equals() 的区别?
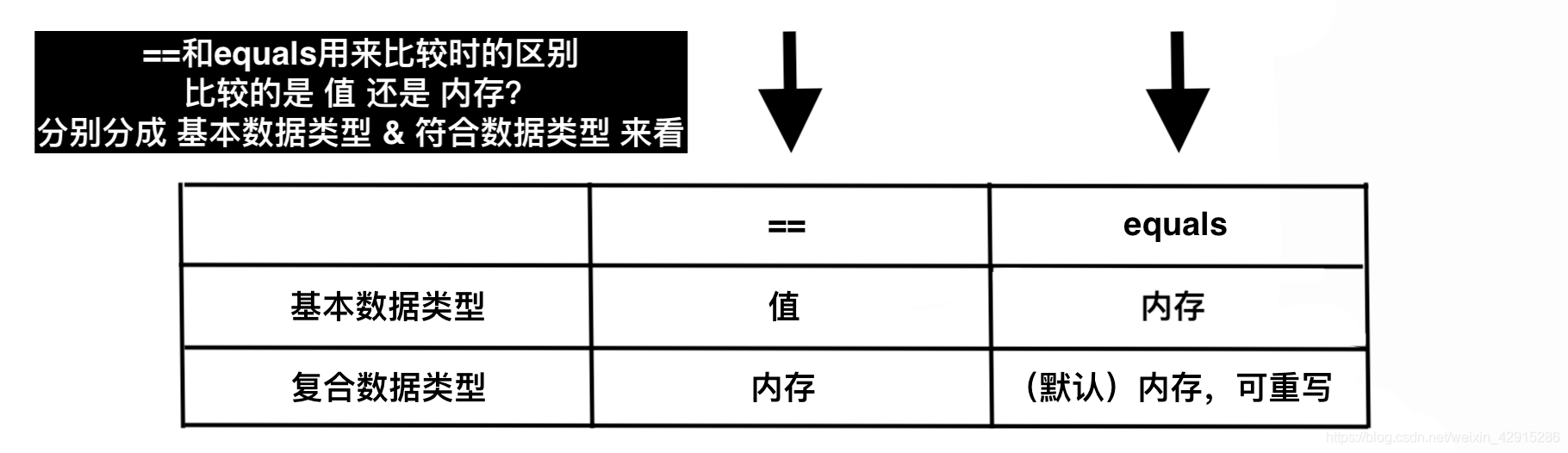
一.判等运算符== :
若比较两个基本内容是否相等,可直接用;若比较两个数据类型不相等,无法实现;
- 1.基本数据类型(原始数据类型):
byte,short,char,int,long,float,double,boolean
比较值是否相同; - 2.复合数据类型(类)
比较内存存放地址是否相同;(确切的说,是堆内存地址)
二.equals
源码:默认行为是比较对象的内存地址值,一般来说,意义不大。
public boolean equals(Object obj) {
//this - s1
//obj - s2
return (this == obj);
}
但在一些类库当中这个方法被覆盖掉了,如String,Integer,Date在这些类当中equals有其自身的实现,而不再是比较类在堆内存中的存放地址了。
在没有覆写equals方法的情况下,他们之间的比较还是内存中的存放位置的地址值,跟双等号 == 在符合数据类型中的作用结果相同;如果被复写,就按照复写的要求来。
————————————————————————————
提问:字符串中,== 和 .equals() 的区别?
- String
String类中被复写的equals()方法比较的是两个字符串的内容。
1 public boolean equals(Object anObject) {
2 if (this == anObject) {
3 return true;
4 }
5 if (anObject instanceof String) {
6 String anotherString = (String)anObject;
7 int n = value.length;
8 if (n == anotherString.value.length) {
9 char v1[] = value;
10 char v2[] = anotherString.value;
11 int i = 0;
12 while (n-- != 0) {
13 if (v1[i] != v2[i])
14 return false;
15 i++;
16 }
17 return true;
18 }
19 }
20 return false;
21 }
答:字符串中:
==:比较的是两个字符串内存地址(堆内存)的数值是否相等,属于数值比较;
equals():比较的是两个字符串的内容,属于内容比较。
以后进行字符串相等判断的时候都使用equals()。
——————————————
提问:下列纯Integer之间的比较,会输出什么?
Integer f1 = 100,f2 = 100,f3 = 200,f4 = 200;
System.out.println(f1 == f2);
System.out.println(f3 == f4);
答:
true
false
因为如果整型字面量的值在-128到127之间,那么不会new新的Integer对象,而是直接引用常量池中的Integer对象;
所以上面的面试题中f1==f2的结果是true,而f3==f4的结果是false;
——————————————
提问:下列Integer与int之间的比较,会输出什么?
Integer a = new Integer(3);
Integer b = 3;
int c = 3;
System.out.println(a == b);
System.out.println(a == c);
答:
false
true
Integer b = 3; 自动调用Integer.valueOf(3) 返回一个Integer的对象,这个对象存放到cache中;
而 Integer a = new Integer(3);这里创建了一个新的对象Integer 所以 a == b 返回的是false;
一个Integer 与 int比较,先将Integer转换成int类型,再做值比较,所以返回的是true;
——————————————
.intern()
表面上看加了他和没加他没有任何区别,但其实它的作用是:
把堆中的数值转换成线程池中;
但有一个例外,如果字符串相加的时,如果其中含有变量则不会进入字符串池中。(查看第一个例子)
比如:
String b = new String("b");
若b加上intern():b.intern()
此时的b就相当于这条:
String b = "b";
b从堆中转移到了常量池中;
例1:
String a = new String("ab");
String b = new String("ab");
String c = "ab";
String d = "a" + "b";
String e = "b";
String f = "a" + e;
System.out.println(b.intern() == a); // 加了intern后,b相当于 String b = "ab";
System.out.println(b.intern() == c); // 两个值都在常量池中,且值相等
System.out.println(b.intern() == d); //
System.out.println(b.intern() == f); // 因为f中有个变量e,包含变量的话,intern的作用就会失效
System.out.println(b.intern() == a.intern()); // 两个值都在常量池中,且值相等
——————————————————————
输出:
false
true
true
false
true
例2:
String str1 = "a";
String str2 = "b";
String str3 = "ab";
String str4 = str1 + str2;
String str5 = new String("ab");
System.out.println(str5.equals(str3));
System.out.println(str5 == str3);
System.out.println(str5.intern() == str3);
System.out.println(str5.intern() == str4);
——————————————————————
输出:
true
false
true
false // 同样的理由,str4包括了变量,而且有两个
——————————————
JAVA当中所有的类都是继承于Object这个基类的,在Object中的基类中定义了一个equals的方法,
对于复合数据类型之间进行equals比较,在没有覆写equals方法的情况下,他们之间的比较还是基于他们在内存存放地址的,因为Object的equals方法也是用双等号==进行比较的,所以比较后的结果跟双等号==的结果相同。
因为String属于符合数据类型,所以应该是使用equals,假如我们使用==比较,肯定是比较它们的内存地址了,所以\1 \2 的结果显而易见了
String str1 = new String("hello");
String str2 = "hello";
System.out.println("str1==str2: " + (str1==str2)); \\1
System.out.println("str1.equals(str2): " + str1.equals(str2)); \\2
输出结果:
str1==str2: false
str1.equals(str2): true
————————————————
String str2 = "hello";
String str3 = "hello";
System.out.println("str3==str2: " + (str3==str2)); \\3
System.out.println("str3.equals(str2): " + str3.equals(str2)); \\4
输出结果:
str3==str2: true
str3.equals(str2): true
————————————————
提问:运行结果是?
String str1 = "hello";
String str2 = "he" + new String("llo");
System.out.println(str1 == str2);
答:
false
—————————————————————————————————————
形参和实参
形参:用来接收 调用该方法时 传递的参数;只有在被调用的时候才分配内存空间,一旦调用结束,就释放内存空间;因此仅仅在方法内有效。
实参:传递给被调用方法的值,预先创建并赋予确定值。
1.基础数据类型(传值调用)
当传值调用时,改变的是形参的值,并没有改变实参的值,实参的值可以传递给形参,但是,这个传递是单向的,形参不能传递回实参
public class Test1{
public void test(int a){ //此处a为形参
a = a + 1;
System.out.println("形参传值调用"+"形参a的修改值"+a);
}
public static void main(String[] args){
Test1 t = new Test1();
int a = 100;
System.out.println("形参传值调用"+"形参a的初始值"+a);
t.test(a); //此处a为实参
System.out.println("形参传值调用"+"形参a的最终值"+a);
}
}
输出:
初始值:100 //形参默认为实参的值
修改值:101 //形参的值被改变了(仅在方法中)
最终值:100 //最终值还是为实参的初始化值,经过方法调用后还是没有被修改;这就是传值调用,值改变的是形参,不会作用到实参
2.引用数据类型(引用调用)
如果参数是对象,无论对对象做了何种操作,都不会改变实参对象的引用;但是如果改变了对象的内容,就会改变实参对象的内容;
举两个例子:
(1)方法体内改变形参引用,但不会改变实参引用 ,实参值不变。
public class TestFun2 {
public static void testStr(String str){
str="hello";//形参指向字符串 “hello”
}
public static void main(String[] args) {
String s="1" ;
TestFun2.testStr(s);
System.out.println("s="+s); //实参s引用没变,值也不变
}
}
输出:s=1
(2)方法体内,通过引用改变了实际参数对象的内容,注意是“内容”,引用还是不变的。
public class TestFun4 {
public static void testStringBuffer(StringBuffer sb){
sb.append("java");//改变了实参的内容,但引用不变
}
public static void main(String[] args) {
StringBuffer sb= new StringBuffer("my ");
new TestFun4().testStringBuffer(sb);
System.out.println("sb="+sb.toString());//内容变化了
}
}
输出:sb = my java
public class Test{
public static void main(String[]args){
String str = new String("good");
char[] ch = {'a','b','c'};
Test ex = new Test();
ex.change(str,ch);
System.out.println(str + "and");
System.out.println(ch);
}
public void change(String str,char ch[]){
str = "test OK";
ch[0] = 'g';
}
}
输出:
goodandgbc
注意!!!
形参和实参可能有多个,但是引用类型的变量(例如数组,对象),他们其实是把传进来的值直接放在引用地址,即 ch[0] 始终只有一 个,并且指向堆空间,参数传进来也是在堆空间里面。
public class Test{
public static void stringReplace(String text){
test = test + "C";
}
public static void bufferReplace(StringBuffer text){
text = text.append("C");
}
public static void main(String[] args){
String textString = new String("ab");
StringBuffer textBuffer = new StringBuffer("ab");
stringReplace(textString);
bufferReplace(textBuffer);
System.out.println(textString + textBuffer);
}
}
输出:
ab abc
String s = "hello";
String t = "hello";
char c[] = {'h','e','l','l','o'};
A. s.equals(t); true
B. t.equals(c); false
C. t.equals(new String("hello)); true
D. s == t true
B中,t是String的对象,c是字符数组的引用;
equals方法的参数是String类型,因此默认调用c的toString方法;
此方法会返回c的信息,而不是“hello”;
总结:
- 1.java的基本数据类型是传值调用,对象引用类型是传引用;
- 2.当传值调用时,改变的是形参的值,并没有改变实参的值,实参的值可以传递给形参,但是,这个传递是单向的,形参不能传递回实参;
- 3.当引用调用时,如果参数是对象,无论对对象做了何种操作,都不会改变实参对象的引用,但是如果改变了对象的内容,就会改变实参对象的内容;
————————
提问:结果是?
public static void main(String[] args) {
StringBuffer a = new StringBuffer("A");
StringBuffer b = new StringBuffer("B");
operate(a,b);
System.out.println(a+","+b);
}
public static void operate(StringBuffer x,StringBuffer y){
x.append(y);
y = x;
}
答:
AB,B
————————
提问:String s = "Hello!" 代表什么意思?
如果简单回答一句:声明一个字符串,则不够严谨;
应该分两个方面来看:
- 1.若之前未定义过此字符串常量
实际上等于两句代码:声明一个字符串对象引用String s;让s指向字符串常量“Hello!”; - 2.若之前已经定义过此字符串常量
那么这句代码不会创建新的字符串,只创建一个字符串对象的引用s,让
s指向常量去中已经存在的字符串常量"Hello!"
————————
请写出String的常用方法
方法名 返回值 描述
startsWith(String prefix) boolean 判断字符串是否以指定前缀开始
substring(int beginIndex) String 返回一个新字符串,他是此字符串的一个子字符串
trim() String 返回字符串的副本,忽略前部空白和尾部空白
valueOf(char[] data) static String 返回char数组参数的字符串表示形式
charAt(int index) char 返回字符串在index位置处的字符
concat(String str) String 将指定字符串连到此字符串的结尾
contains(CharSequence s) boolean 当且仅当此字符串包含char值指定序列时,返true
endsWith(String suffix) boolean 判断字符串是否以指定后缀结束
getBytes() byte[] 使用平台默认的字符集将此Strig解码为字节序列,并将结果存储到一个新的字节数组中
indexOf(int ch) int 返回指定字符在此字符串中第一次出现处的索引
length() int 返回该字符串的长度
split(String regex) String[] 根据给定的正则表达式的匹配来拆分此字符串
————————
substring()

————————
字符串 实例对象.charAt( fromIndex )
实例对象.charAt( 数字 ):查看数字所在的位置是哪个字符
模版:
.charAt( fromIndex )
例子:
public class tutorial {
public static void main(String[] args) {
String s = "www.runoob.com";
char result = s.charAt(4);
System.out.println(result);
}
}
返回:
r
例题1:这段代码返回什么?
String s = "xbcde";
Sustem.out.println(s.charA.t(4));
答:编译错误,只有charAt,无charA.t
————————
deleteCharAt()
该方法只存在于StringBuilder中
StringBuilder str = new StringBuilder("abc");
str.deleteCharAt(str.length()-1);
System.out.println(str.toString());
————————————
输出:
ab
该例子逻辑上容易犯错:
deleteCharAt的索引值是从0开始计,所以c的索引值为2;
但字符串的.length()是自然数,从1开始计,本字符串长度为3;
所以若要锁定c,索引值的计算方法则为.length()-1(即:3-1 = 2);
————————
Math.abs()
返回绝对值;
返回负数的特殊情况:https://www.jianshu.com/p/4b4ae81cb44f
————————
&和&&的区别、|和 ||的区别、~和~|的区别

&、|、~都是位操作符 ;
而&&、||、~|都是逻辑操作;
&&和&都是表示and,当运算符两边的表达式的结果都为true时,整个运算结果才为true,否则,只要有一方为false,则结果为false。
区别是:
使用&&时,只要第一个条件不满足,后面条件就不再判断;
使用&时,当第一个条件为假的时候,程序依旧会继续执行第二个条件,然后再得出FALSE的结果;
例1:
若str==null
if( str != null && !str.equals(“xxx”))
当str为null时,后面的表达式不会执行;
如果将&&改为&,则可能会抛出NullPointerException异常。
例2:
x == 0 ; y == 0 ;
if(x == 33 && ++ y > 0)
y不会增长;
x == 0 ; y == 0 ;
If(x == 33 & ++ y > 0)
y会增长,返回false;
2.|与||的区别
||作为逻辑或运算符,表示逻辑或(or),当运算符有一边为true时,整个运算结果为true!
a.当使用|时,若前面的表达式为真时,程序会继续执行后面的表达式,然后在得出TRUE的结果,代码如下:
public class Test {
public static void main(String[] args) {
int i = 0;
if( 10 == 10 | (i++) != 0 ){
System.out.print("结果为真 "+i);
}else{
}
}
}
输出:结果为真:1
当使用||(短路或)时,若前面的表达式结果为真,则程序不会再执行后面的表达式,直接得出TRUE的结果,代码如下:
public class Test {
public static void main(String[] args) {
int i = 0;
if( 10 == 10 || (i++) != 0 ){
System.out.print("结果为真 "+i);
}else{
}
}
}
输出:结果为真:0
————————
字符串 instanceOf
instanceof 运算符是Java中的一个二元运算符,用来在运行时指出对象是否是特定类的一个实例。左边的对象是否是右边的类的实例,返回一个Boolean类型的数据。
如:
result = object instanceof class;
如果 object 是 class 的一个实例,则 instanceof 运算符返回 true。如果 object 不是指定类的一个实例,或者 object 是 null,则返回 false。
如:
"hello" instanceOf Object;
返true
因为Object是所有类的父类;左边是String类型,String是Object子类,所以返true;
————————
String的length()方法 和 数组的length属性(易错)
String的length()方法可以用来求解字符串的长度;
数组的length属性可以用来求解数组的大小;
比如:
public class Test{
public static void main(String[] args){
int a[] = {1};
System.out.println(a.length);
String s = "Hello";
System.out.println(s.length());
}
}
输出:
1
5
提问:说法正确的是?
A. 数组有length()方法;
B. String有length()方法;
C. 数组有length属性;
D. String有length属性;
答:
BC
————————
Math.pow()
Math.pow(x,y)方法可返回x的y 次幂的值。
x 必需,底数,必须是数字;
y 必需,幂数,必须是数字;
比如:double sumB = Math.pow(c, a);
Math.round()
Java中的Math.round()关于 正数的计算 和普通四舍五入一模一样;
不同的是 关于负数的计算;
比如-9.5,不保留小数,普通四舍五入得出 -10,而round(-9.5)得出 -9;
比如-9.6,不保留小数,普通四舍五入得出 -10,而round(-9.6)得出 -10;
这个原因是Java对round()的定义造成的;
Case1:小数点后第一位 = 5
- 正数:
Math.round(11.5) = 12 - 负数:
Math.round(-11.5) = -11
Case2:小数点后第一位 < 5 - 正数:
Math.round(11.49) = 11 - 负数:
Math.round(-11.49) = -11
Case3:小数点后第一位 > 5 - 正数:
Math.round(11.69) = 12 - 负数:
Math.round(-11.69) = -12
结论:正数小数点后大于5则进位;负数小数点后小于以及等于5都舍去,大于5的则进位
也就是说:小数点后大于5全部加,等于5正数加,小于5全不加
我的理解:
正数:普通的四舍五入;
负数:最后一位数 <= 5时,最后一位数不用变化;最后一位数 =6 或更大时,(先别管负号)最后一位数字 +1;
————————————
提问:Math.round(11.5)和Math.round(-11.5)分别等于多少?
答:
12和-11;
BigDecimal.setScale 用法总结
http://www.bdqn.cn/news/201311/11834.shtml
round_down 砍掉后面,最后一位不变
round_up 砍掉后面,最后一位+1
round_ceiling 若正数 = round_up ;若负数 = round_down
round_floor 若正数 = round_down ;若负数 = round_up
round_half_up 四舍五入
round_half_down 五舍六入
- ROUND_DOWN
保留?位小数;
把舍弃的部分直接砍掉,且始终保持最后保留的数字不变(如:2.224 变成 2.22;2.225 变成 2.22)
所以始终不会增加数值,即DOWN;
BigDecimal b = new BigDecimal("2.225667").setScale(2, BigDecimal.ROUND_DOWN);
System.out.println(b); //输出:2.22
- ROUND_UP
保留?位小数;
且始终在最后保留的数字上+1,即UP(如:2.224 变成 2.23;2.225 变成 2.23)
所以始终不会减少数值;这不是四舍五入!!
BigDecimal c = new BigDecimal("2.224667").setScale(2, BigDecimal.ROUND_UP);
System.out.println(c); //输出:2.23
- ROUND_CEILING
如果 BigDecimal 为正,则舍入行为与ROUND_UP相同;(始终增加值)
如果 BigDecimal 为负,则舍入行为与ROUND_DOWN相同;(始终增加值)
所以,此舍入模式始终会增加计算值。
BigDecimal f = new BigDecimal("2.224667").setScale(2, BigDecimal.ROUND_CEILING);
System.out.println(f);//2.23 如果是正数,相当于BigDecimal.ROUND_UP
BigDecimal g = new BigDecimal("-2.225667").setScale(2, BigDecimal.ROUND_CEILING);
System.out.println(g);//-2.22 如果是负数,相当于BigDecimal.ROUND_DOWN
- ROUND_FLOOR
如果 BigDecimal 为正,则舍入行为与ROUND_DOWN相同;
如果 BigDecimal 为负,则舍入行为与ROUND_UP相同。
所以,此舍入模式始终会减少计算值。
BigDecimal h = new BigDecimal("2.225667").setScale(2, BigDecimal.ROUND_FLOOR);
System.out.println(h);//2.22 如果是正数,相当于BigDecimal.ROUND_DOWN
BigDecimal i = new BigDecimal("-2.224667").setScale(2, BigDecimal.ROUND_FLOOR);
System.out.println(i);//-2.23 如果是负数,相当于BigDecimal.ROUND_HALF_UP
//输出:
- ROUND_HALF_UP
这就是经典的四舍五入了
BigDecimal d = new BigDecimal("2.225").setScale(2, BigDecimal.ROUND_HALF_UP);
System.out.println("ROUND_HALF_UP"+d); //2.23 四舍五入(若舍弃部分>=.5,就进位)
//输出:
换一种写法:
BigDecimal A = new BigDecimal("xxx").setScale(2,BigDecimal.ROUND_HALF_UP);
等价于
BigDecimal A = new BigDecimal("xxx");
BigDecimal a = A.setScale(2,BigDecimal.ROUND_HALF_UP);
- ROUND_HALF_DOWN
五舍六入
BigDecimal e = new BigDecimal("2.225").setScale(2, BigDecimal.ROUND_HALF_DOWN);
System.out.println("ROUND_HALF_DOWN"+e);//2.22 四舍五入(若舍弃部分>.5,就进位)
//输出:
- ROUND_HALF_EVEN
//输出:
- ROUND_UNNECESSARY
BigDecimal l = new BigDecimal("2.215").setScale(3, BigDecimal.ROUND_UNNECESSARY);
System.out.println(l);
//断言请求的操作具有精确的结果,因此不需要舍入。
//如果对获得精确结果的操作指定此舍入模式,则抛出ArithmeticException。
//输出:
NumberFormat
java.text.NumberFormat类有三个方法可以产生下列数据的标准格式化器:
数字;货币;百分数
创建格式化器(默认地区Local格式):
NumberFormat.getNumberInstance();
NumberFormat.getCurrencyInstance();
括号内可填国家名,下方有例子;不填表示默认当前系统国家;
NumberFormat.getCurrencyInstance(Locale.US)NumberFormat.getCurrencyInstance(Locale.CHINA);
NumberFormat.getPercentInstance();
例:
double dbl=10000.0/3;
NumberFormat formatter=NumberFormat.getNumberInstance();
String s=formatter.format(x);
System.out.println(s);
public static void main(String[] args){
NumberFormat a = NumberFormat.getCurrencyInstance();
a.setMaxiumFractionDigits(2);
System.out.println("\t书籍价格:" +
formatter.format(32) + “元”);
}
输出:
书籍价格:¥32.00元
Java 把小数格式化成固定小数位数的几种方法
https://blog.youkuaiyun.com/lucherr/article/details/7454661
compareTo() 比较两个数字参数大小
模版:
public int 指定数 compareTo( NumberSubClass referenceName 参数 )
可以是一个 Integer, Byte, Double, Float, Long 或 Short 类型的参数;
可为Integer;不可为int!!!!会报错。
返回:
- 若
指定数 = 参数返0; - 若
指定数 < 参数返-1; - 若
指定数 > 参数返1。
———————————————
例子:
public class Test{
public static void main(String args[]){
Integer x = 5;
System.out.println(x.compareTo(3));
System.out.println(x.compareTo(5));
System.out.println(x.compareTo(8));
}
}
返回:
1
0
-1
——————————————————————————————————
Arrays.sort()
对Java的八个【基本数据类型】的【数组】进行排序(当然,除了boolean )
实际上对七个基本数据类型的数组有效;
提问:对char[] ch = {'7','9','0'}进行正序排序?
(注意!char[]的格式很容易写错!!!!!!!!)
char[] ch = {'7','9','0'};
Arrays.sort(ch);
System.out.println(ch);
输出:
079
提问:对int[] a = {9,0,4}进行正序排序?
int[] a = {9,0,4};
Arrays.sort(a);
for(int val:a){
System.out.println(val);
}
输出:
049
提问:请将String s="7904652"排序后输出
public class Test2 {
public static void main(String[] args) {
String s = "7904652";
char[] ch = s.toCharArray();
Arrays.sort(ch);
System.out.println(ch);
}
}
输出:
0245679
页面搜索:toCharArray
——————————————————————————————————
Collections
Collections.sort() (只对List类型进行排序!!)
重点:Collections.sort()方法只对List类型进行排序!!
重点:Collections.sort()方法只对List类型进行排序!!
重点:Collections.sort()方法只对List类型进行排序!!
重点:Collections.sort()方法只对List类型进行排序!!
重点:Collections.sort()方法只对List类型进行排序!!
重点:Collections.sort()方法只对List类型进行排序!!
重点:Collections.sort()方法只对List类型进行排序!!
重点:Collections.sort()方法只对List类型进行排序!!
重点:Collections.sort()方法只对List类型进行排序!!
重点:Collections.sort()方法只对List类型进行排序!!
正序例子:
public class Oh{
public static void main(String[] args) {
List<Integer> list = Arrays.asList(2,3,1); //定义一个数组,直接转换成List
System.out.println("Before:");
System.out.println(list);
Collections.sort(list); //对List进行.sort(正排序)
System.out.println("After:");
System.out.println(list);
}
}
输出:
Before:
[2, 3, 1]
After:
[1, 2, 3]
倒序例子:
在原有.sort()中:
除了保留list实例,还加一个new Comparator<>(IDE会自行填充余下覆盖方法)
public class Oh{
public static void main(String[] args) {
List<Integer> list = Arrays.asList(2,3,1);
System.out.println("Before:");
System.out.println(list);
Collections.sort(list, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2 - o1;
}
});
System.out.println("After:");
System.out.println(list);
}
}
@Override public int compare(){} 方法
(在.sort()中写了new Comparator<>()后,IDE会自行填充此覆盖方法)
例子:
@Override
public int compare(Student o) {
//return o.age - this.age; //降序
return this.age - o.age; //升序
}
或
@Override
public int compare(Integer o1, Integer o2) {
return o2-o1; // 负数:表示倒序
}
此方法返回三种int类型的值: 负整数,零 ,正整数。
返回值 含义
———————————————————————————————————————————
负 当前对象的值 < 比较对象的值 , 位置排在前(表示倒序)
零 当前对象的值 = 比较对象的值 , 位置不变(表示相等)
正 当前对象的值 > 比较对象的值 , 位置排在后(表示正序)
提问:集合框架中,要实现对集合里的元素进行排序,要实现哪个接口?
答:
Comparator
Collections.singletonList()
singleton(T o)
返回一个只包含指定对象的不可变 set。此对象可以是任意对象
singletonList(T o)
返回一个只包含指定对象的不可变列表。
singletonMap(K key, V value)
返回一个不可变的映射,它只将指定键映射到指定值。
.indexOf() 查找数字或文字出现的fromIndex
.LastIndexOf()
心得:表示数字存在或不存在都不能包括=0,只能写<0或>0;
模版:
- public int
indexOf(int ch): 返回指定字符在字符串中第一次出现处的索引;
如果此字符串中没有这样的字符,返-1。 - public int
indexOf(int ch, int fromIndex): 返回从 fromIndex 位置开始查找指定字符在字符串中第一次出现处的索引;
如果此字符串中没有这样的字符,返-1。 - int
indexOf(String str): 返回指定字符在字符串中第一次出现处的索引;
如果此字符串中没有这样的字符,返-1。 - int
indexOf(String str, int fromIndex): 返回从 fromIndex 位置开始查找指定字符在字符串中第一次出现处的索引;
如果此字符串中没有这样的字符,返-1。 - 记得字符串要用单引号
''!!! - 当然,如果表示有这样的字符,返回
>0;
(不能写=0;=0虽然有防止空字符串的情况,但也有表示第一位数字的情况,如下)
——————————
注意!!!
.LastIndexOf()指从右到左,计字符第一次出现的位置,但是位置仍是从左边开始计!!!
心得:所以str.indexOf(cha) == str.lastIndexOf(cha))可以选出字符中唯一出现的字符!!!
—————————— .indexOf()输出为0的情况:
System.out.println(“1234”.indexOf("123"));
输出 0;
System.out.println(“I am ok:1234”.indexOf(""));
输出 0;
第一种:字符串的起始位置第0位开始;
第二种:如果使用空字符串和空字符串做比较,返回的还是0;
———————————————
ch:字符,Unicode 编码;(要查询的数字参数)
fromIndex:开始搜索的索引位置;(即一个数字:第一个字符是0,第二个是1,以此类推)
str:要搜索的子字符串。
———————————————
注意:如
String Str = new String("hello,this is a test");
System.out.print("从第10个位置开始查找字符 s 第一次出现的位置 :" );
System.out.println(Str.indexOf( 's', 10 ));
——————————————————————————————————————————
从第10个位置开始查找字符 s 第一次出现的位置 :12
特别注意!!个人易错点!!
indexOf查找数字第一次出现的位置,无论有没有规定fromIndex,通通都要从第0位开始计数:
第?个位置:
位置始终从开头的0开始计数,不是从?开始计!!
比如:处理对象string为"aaa456ac" ;
查找string.indexOf("a",3):这里匹配到的a实际为6(倒数第2位);
查找string.indexOf("a"):这里匹配到的a实际为0(正数第1位);
例子:
public class Main {
public static void main(String args[]) {
String string = "aaa456ac";
//对应fromIndex:01234567 //查找指定字符是在字符串中的下标。在则返回所在字符串下标;不在则返回-1.
System.out.println(string.indexOf("b")); //返:-1;indexOf(String str); 返回结果:-1:"b"不存在
// 从第四个字符位置开始往后继续查找,包含当前位置
System.out.println(string.indexOf("a",3)); //返:6;indexOf(String str, int fromIndex); 返回结果:6
//(与之前的差别:上面的参数是 String 类型,下面的参数是 int 类型)参考数据:a-97,b-98,c-99
// 从头开始查找是否存在指定的字符
System.out.println(string.indexOf(99)); //返:7
System.out.println(string.indexOf('c')); //返:7
//从fromIndex查找ch,这个是字符型变量,不是字符串。字符a对应的数字就是97。
System.out.println(string.indexOf(97,3)); //返:6
System.out.println(string.indexOf('a',3)); //返:6
}
}
返回:
-1
6
7
7
6
6
————————————————
例子:
public class Test {
public static void main(String[] args) {
String Str = new String("hello,this is a test");
String SubStr1 = new String("is");
String SubStr2 = new String("test");
System.out.print("查找字符i 第一次出现的位置 :" );
System.out.println(Str.indexOf( 'i' ));
System.out.print("从第10个位置查找字符 s 第一次出现的位置 :" );
System.out.println(Str.indexOf( 's', 10 ));
System.out.print("子字符串 SubStr1 第一次出现的位置:" );
System.out.println( Str.indexOf( SubStr1 ));
System.out.print("从第十五个位置开始搜索子字符串 SubStr1 第一次出现的位置 :" );
System.out.println( Str.indexOf( SubStr1, 11 ));
System.out.print("子字符串 SubStr2 第一次出现的位置 :" );
System.out.println(Str.indexOf( SubStr2 ));
}
}
返回:
查找字符i 第一次出现的位置 :8
从第10个位置查找字符 s 第一次出现的位置 :12
子字符串 SubStr1 第一次出现的位置:8
从第十五个位置开始搜索子字符串 SubStr1 第一次出现的位置 :11
子字符串 SubStr2 第一次出现的位置 :16
valueOf() 类型转换
该方法是静态方法。
模版:
static:
.valueOf(int i)
.Integer valueOf(String s)
.Integer valueOf(String s, int radix) //把10进制转换成radis进制
详解:
radix:指定使用的进制数;如写16指16进制;(/redɪks/)
———————————————
例子:
public class Test{
public static void main(String args[]){
Integer x =Integer.valueOf(9);
Double c = Double.valueOf(5);
Float a = Float.valueOf("80");
Integer b = Integer.valueOf("444",16); // 使用16进制:把10进制的444转换成16进制
System.out.println(x);
System.out.println(c);
System.out.println(a);
System.out.println(b);
}
}
返回:
9
5.0
80.0
1092
.trim()
把字符串两端所有的空格都去掉,但保留字符串内部的空格;
String s = " as f g ";
String s1 = s.trim();
那么s1就是"as f g"
.equalsIgnoreCase()
忽略大小写;
如:name.trim().equalsIgnoreCase("done"))
意思为(输入)“done”,去掉前后的空格,大小写都通过;
.getBytes()
两种形式:
getBytes(String charsetName):
使用指定的字符集将字符串编码为 byte 序列,并将结果存储到一个新的 byte 数组中。
getBytes():
使用平台的默认字符集将字符串编码为 byte 序列,并将结果存储到一个新的 byte 数组中。
byte[] 实例 = "字符".getByte("编码名");
————————————
将分别返回“中”这个汉字在GBK、UTF-8和ISO8859-1编码下的byte数组表示,
byte[] b_gbk = "中".getBytes("GBK");
byte[] b_utf8 = "中".getBytes("UTF-8");
byte[] b_iso88591 = "中".getBytes("ISO8859-1");
此时b_gbk的长度为2,b_utf8的长度为3,b_iso88591的长度为1。
————————————
而与getBytes相对的,可以通过new String(byte[], decode)的方式来还原这个“中”字时,这个new String(byte[], decode)实际是使用decode指定的编码来将byte[]解析成字符串。
String s_gbk = new String(b_gbk,"GBK");
String s_utf8 = new String(b_utf8,"UTF-8");
String s_iso88591 = new String(b_iso88591,"ISO8859-1");
————————————
class Main {
public static void main(String[] args) {
String str = "make a fortune";
byte[] byt = str.getBytes();
for (byte b : byt) {
System.out.println(b);
}
}
}
以上程序运行结果为:
109
97
107
101
32
97
32
102
111
114
116
117
110
101
可见 byte[]数组中存放的是字符串响应位置对应的字母的哈希值,如字符串中的字母 a 对应 byte[] 数组中的 97 。
另外:返回的 byte[] 数组的长度,与原字符串的长度相等。
public class Test {
public static void main(String args[]) {
String Str1 = new String("runoob");
try{
byte[] Str2 = Str1.getBytes();
System.out.println("返回值:" + Str2 );
Str2 = Str1.getBytes( "UTF-8" );
System.out.println("返回值:" + Str2 );
Str2 = Str1.getBytes( "ISO-8859-1" );
System.out.println("返回值:" + Str2 );
} catch ( UnsupportedEncodingException e){
System.out.println("不支持的字符集");
}
}
}
返回值:[B@7852e922
返回值:[B@4e25154f
返回值:[B@70dea4e
————————————
有时候,为了让中文字符适应某些特殊要求(如http header头要求其内容必须为iso8859-1编码),可能会通过将中文字符按照字节方式来编码的情况,如:
String s_iso88591 = new String("中".getBytes("UTF-8"),"ISO8859-1");
这样得到的s_iso8859-1字符串实际是三个在 ISO8859-1中的字符,在将这些字符传递到目的地后,
目的地程序再通过相反的方式:
String s_utf8 = new String(s_iso88591.getBytes("ISO8859-1"),"UTF-8")
来得到正确的中文汉字“中”。这样就既保证了遵守协议规定、也支持中文。
递归函数 Recursion
在计算机编程实现中有常常两种方法:一曰迭代(iterate);二曰递归(recursion)。
从“编程之美”的角度看,可以借用一句非常经典的话:“迭代是人,递归是神!”来从宏观上对二者进行把握。
从概念上讲,递归就是指程序调用自身的编程思想,即一个函数调用本身;迭代是利用已知的变量值,根据递推公式不断演进得到变量新值得编程思想。
编程语言中,函数Func(Type a,……)直接或间接调用函数本身,则该函数称为递归函数。
对于递归的概念,其实你可以简单的理解为自己定义自己。
记得小时候看过一部电视剧,里面主角叫做“常发”,但是个文盲,老师问他叫什么,他说“常发”。“哪个常?”“常发的常啊!”“哪个发?”“常发的发啊!”结果第二节课老师就让一群小朋友一起喊“常发的常,常发的发,傻瓜的傻,傻瓜的瓜”。
言归正传,显然在多数情况下递归是解释一个想法或者定义的一种合理方法。在思想上递归类似于数学中曾经学过的数学归纳法。
比方如下:
public class Test {
// 使用递归计算阶乘
// 定义一个方法
public static int recursion(int n){
//如果n==1那么直接返回1,,否则就再次调用自己
if(n==1){
return 1;
}else{
return n*recursion(n-1);// 每调用一次n就减1
}
}
public static void main(String[] args) {
int a=recursion(5);//把返回结果赋值给a
System.out.println(a);// 打印结果
}
}
n=5
结果 = 5*re(4)
re(4)=4*re(3)
re(3)=3*re(2)
re(2)=2*re(1)
re(1)=1
异常处理 Exception
异常指:程序运行时(非编译时)发生的非正常情况或错误;
补充:当程序违反了语义规则时,JVM会将出现的错误表示为一个异常并抛出,这个异常可在catch块中被捕获,然后进行处理;
目的:提高程序的安全性和健壮性;
————————
- 提问:画出Java异常类的继承体系结构,以及Java异常的分类,且为每种异常各举几个例子;

- 提问:写出五个你常见的RuntimeException
NullPointerException 空指针异常
ArithmeticException 零为除数等
ClassCastException 类型转换
ArrayIndexOutOfBoundsException 数组越界
StringIndexOutOfBoundsException 字符串越界
ClassNotFoundException 类型转换
IllegalArgumentException 不合法参数
————————
java.lang.Exception 全称 public class Exception extends Throwable
是所有异常直接/间接的父类;
java.lang.Throwable 全称 public class Throwable extends Object implements Serializable
Exception 是程序正常运行中,可以预料的意外情况,可能并且应该被捕获,进行相应处理。
Error 是指在正常情况下,不大可能出现的情况,绝大部分的 Error 都会导致程序(比如 JVM 自身)处于非正常的、不可恢复状态。既然是非正常情况,所以不便于也不需要捕获,常见的比 如 OutOfMemoryError 之类,都是 Error 的子类。
Exception 又分为可检查(checked)异常和不检查(unchecked)异常:
Checked Exception 在源代码里必须显式地进行捕获处理,这是编译期检查的一部分。
Unchecked Exception 就是所谓的运行时异常,通常是可以编码避免的逻辑错误,具体根据需要来判断是否需要捕获,并不会在编译期强制要求。
讲白话:
Checked Exception 这种异常在现实中难以避免,必须主动添加处理(try...catch),同时IDE也一定会给你检查,如果检查到没有处理(try...catch),IDE会生气,并报错;
例如:一个读取文件的方法代码逻辑没有错误,但程序运行时可能因为文件找不到而抛出FileNotFoundException,如果不处理这些异常,程序将来肯定会出错;不处理的话IDE就不能通过编译。
Unchecked Exception 这种异常一般是可以避免的,由于问题很明显,很简单,IDE不会帮你检查;如果因为你太笨没有自己抛出错误,IDE就袖手旁观等着你出错;
例如:你的程序逻辑本身有问题,比如数组越界、访问null对象,这种错误你自己是可以避免的;编译器不会强制你检查这种异常。
易错点:
他们都是public类;
Exception是Throwable的子类,Throwable不是接口;
因为Throwable实现了Serializable接口,所以可被序列化,既然父类可被序列化,子类亦可被序列化;
提问:哪个既是检查型异常,又需要在编写程序时声明?
A. NullPointException
B. ClassCastException
C. IOException
D. IndexOutOfBoundsException
____
答案C
————————
NoClassDefFoundError 和 ClassNotFoundException 有什么区别
ClassNotFoundException
从java.lang.Exception继承,是一个Exception类型;
当动态加载Class的时候找不到类会抛出该异常;
一般在执行Class.forName()、ClassLoader.loadClass()或ClassLoader.findSystemClass()的时候抛出;
NoClassDefFoundError
从java.lang.Error继承,是一个Error类型;
当编译成功以后执行过程中Class找不到导致抛出该错误;
由JVM的运行时系统抛出;
————————
- 提问:throw与throws的区别?
throw出现在函数体,由方法体内的语句处理;抛出了异常,执行throw则一定抛出了某种异常对象;【真实】
throws出现在方法函数头,由该方法的调用者来处理;throws表示出现异常的一种可能性,并不一定会发生这些异常。【可能,倾向】
两者都是消极处理异常的方式(这里的消极并不是说这种方式不好),只是抛出或者可能抛出异常,但是不会由函数去处理异常,真正的处理异常由函数的上层调用处理。
————————
Java编译器只允许try/catch/finally的三种组合方式:
try catchtry finallytry catch finally
即,try块只能有一个,catch块可以有多个,finally块如果有的话只能有1个;
当try块程序发生异常,才会执行catch块的程序;若无异常发生,catch块不会被执行;若有多个catch块,异常会按照catch块顺序执行;若执行了一个catch块,其余catch块都会被忽略;
无论程序是否发生错误以及捕捉到异常情况,finally块都会执行;
提问:方法如下,若方法运行时产生了一个IOException,此时输出的结果是?
public void f(){
try{
//may cause an Exception
}
catch(java.io.FileNotFoundException ex){
system.out.println("FileNotFoundException");
}
catch(java.io.IOException ex){
system.out.println("IOException");
}
catch(java.lang.Exception ex){
system.out.println("Exception");
}
}
__________________
答案是:IOException
————————
如果执行finally代码块之前方法返回了结果,或者JVM退出了,finally块中的代码还会执行吗?
不会,只有在try里面是有System.exit(0)来退出JVM的情况下finally块中的代码才不会执行。否则finally块中的代码都会执行。
思路:了解try.cath.finally的执行顺序就会迎刃而解,首先会执行try里面的代码,执行完了会查找有没有finally,如果没有,直接执行return或者是throw,
如果有finally,先执行finally里面的代码,再执行try里面的 return或者是throw;
一般来讲finally里面不会写return或者是throw,如果写了,会覆盖掉try里面的return和throw。
————————
给出3种打印异常信息的方式
try{
...
}catch(Exception e){
System.out.println(e);
System.out.println(e.getMessage());
e.printStackTrace();
}
————————
- 提问:你平时在项目中是怎样对异常进行处理的?
(1)尽量避免出现runtimeException 。例如对于可能出现空指针的代码,带使用对象之前一定要判断一下该对象是否为空,必要的时候对runtimeException也进行try catch处理。
(2)进行try catch处理的时候要在catch代码块中对异常信息进行记录,通过调用异常类的相关方法获取到异常的相关信息,返回到web端,不仅要给用户良好的用户体验,也要能帮助程序员良好的定位异常出现的位置及原因。
————————
try-with-resource
我们知道,Java中,如果打开了外部资源(文件、数据库连接、网络连接等),我们必须在这些外部资源使用完毕后,手动关闭它们。因为外部资源不由JVM管理,无法享用JVM的垃圾回收机制,如果我们不在编程时确保在正确的时机关闭外部资源,就会导致外部资源泄露,紧接着就会出现文件被异常占用,数据库连接过多导致连接池溢出等诸多很严重的问题。
为了确保外部资源一定要被关闭,通常关闭代码被写入finally代码块中;
传统的资源关闭方式:
public static void main(String[] args) {
FileInputStream inputStream = null;
try {
inputStream = new FileInputStream(new File("test"));
System.out.println(inputStream.read());
} catch (IOException e) {
throw new RuntimeException(e.getMessage(), e);
} finally {
if (inputStream != null) {
try {
inputStream.close();
} catch (IOException e) {
throw new RuntimeException(e.getMessage(), e);
}
}
}
}
很麻烦;
JDK7中新增了自动关闭外部资源的语法特性:try-with-resource语法
上述代码可以简化为:
public static void main(String[] args) {
try (FileInputStream inputStream = new FileInputStream(new File("test"))) { //有多个就用";"号分割
System.out.println(inputStream.read());
} catch (IOException e) {
throw new RuntimeException(e.getMessage(), e);
}
}
将外部资源的句柄对象的创建放在try关键字后面的括号中,当这个try-catch代码块执行完毕后,Java会确保外部资源的close方法被调用,代码瞬间简洁许多;
try-with-resource并不是JVM虚拟机的新增功能,只是JDK实现了一个语法糖,当你将上面代码反编译后会发现,其实对JVM虚拟机而言,它看到的依然是之前的写法。
————————
提问:下面的代码反映了异常处理中哪些不当之处?
try {
// 业务代码
// ... Thread.sleep(1000L);
} catch (Exception e) {
// Ignore it
}
虽然代码很短,但存在两个致命缺陷:
1.尽量不要捕获Exception这样的通用异常,而是应该捕获特定异常,在这里是 Thread.sleep() 抛出的InterruptedException;
日常的开发和合作中,我们读代码的机会往往超过写代码,软件工程是门协作艺术,所以我们有义务让自己的代码能够直观地体现出尽量多的信息,而泛泛的Exception之类,恰恰隐藏了我们的目的。另外,我们也要保证程序不会捕获到我们不希望捕获的异常;比如,你可能更希望 RuntimeException 被扩散出来,而不是被捕获;
2.未输出报错语句,这属于生吞(swallow)异常。这是异常处理中要特别注意的事情,因为生吞异常很可能会导致非常难以诊断的诡异情况。
生吞异常,往往是基于假设这段代码可能不会发生,或者感觉忽略异常是无所谓的,但是千万不要在产品代码做这种假设!
如果我们不把异常抛出来,或者也没有输出到日志(Logger)之类,程序可能在后续代码以不 可控的方式结束。没人能够轻易判断究竟是哪里抛出了异常,以及是什么原因产生了异常。
try…catch…finally
重要原则:
finally一定在return前执行!!!
(return在finally之后执行!!!)

输出:2

输出:1
public static void main(String args[]){ // 输出2
Test t = new Test();
int b = t.get();
System.out.println(b);
}
public int get(){
try{
return 1 ;
}
finally{
return 2 ;
}
}
I/O 流
https://blog.youkuaiyun.com/weixin_42915286/article/details/89764423
Java平台和垃圾回收 之平台
Java是面向对象的解释型高级编程语言
提问:JDK和JRE的区别?

JVM Java Virtual Machine Java虚拟机:是实现Java跨平台的核心,负责解释执行Class文件;
JRE Java Runtime Environment Java运行环境:是运行Java程序所必须的环境的集合,包括: (1).JVM标准实现 (2).Java核心类库 ;
编写Java程序时,常用到系统的类库;JVM在解释执行class文件时也会用到这些类库;
Java安装目录下,通常会有bin目录和lib目录(环境配置时,把bin目录配置到path中,把lib目录配置到classpath中),lib目录下就是写代码和运行代码时需要用到的类库。
可认为bin目录就是JVM,而 JVM+lib=JRE
(注:Java类库就是由一堆Java类打包在一起组成的库,封装一些类方便你使用,比如Map,List这种。)
(注:API(Application Programming Interface,应用程序编程接口)是一些预先定义的函数,目的是提供应用程序与开发人员基于某软件或硬件的以访问一组例程的能力,而又无需访问源码;通俗地讲,就是Java里面的所有方法,它的格式、具体方法,怎么用,都在API里)
JDK Java Development Kit Java开发工具包:是整个Java的核心,主要用于移动设备、嵌入式设备上的Java应用程序;包括JRE和Java开发工具(包括诸开发调试工具和JavaAPI),JRE+Java开发工具=JDK
下载了JDK就不用下载JRE了;
提问:下列说明正确的是?
A. 由于Java程序时解释执行的,所以执行前不用进行编译
B. 一个.java源程序编译后会产生一个 .class字节码文件
C. 安装了JDK后,安装程序会自动配置系统的环境变量path和classpath
D. Java是面向对象的解释型高级编程语言
答案D
A.Java是解释型语言,但…查看第一张图即懂
B.一个类对应一个字节码文件;所以若一个.java中有多个类,则对应多个字节码文件
C.要手动配置
D.正确
————————
Java程序运行从上到下的环境次序是:
(上)
Java程序
JRE / JVM
操作系统
硬件
(下)
计算机高级语言最底层都是硬件执行;
往上是操作系统将汇编语言解析成机器语言;
再就是高级语言环境编译成汇编语言。
————————
平台独立性?
平台独立性指:可以在一个平台上编写和编译程序,而在其他平台上运行;
保证Java具有平台独立性的机制为 中间码(字节码文件)和JVM ;
Java被编译后不是生成能在硬件平台上可执行的代码,而是生成了一个中间代码:字节码文件;
不同硬件平台上会安装不同的JVM,由JVM负责把中间代码翻译成硬件平台能执行的代码;
由此可见,JVM不具有平台独立性,与硬件平台是相关的,他保证了Java可以跨平台。
————————
提问:描述Java类加载器的原理及其组织结构
————————
JVM
提问:JVM的工作原理是什么?
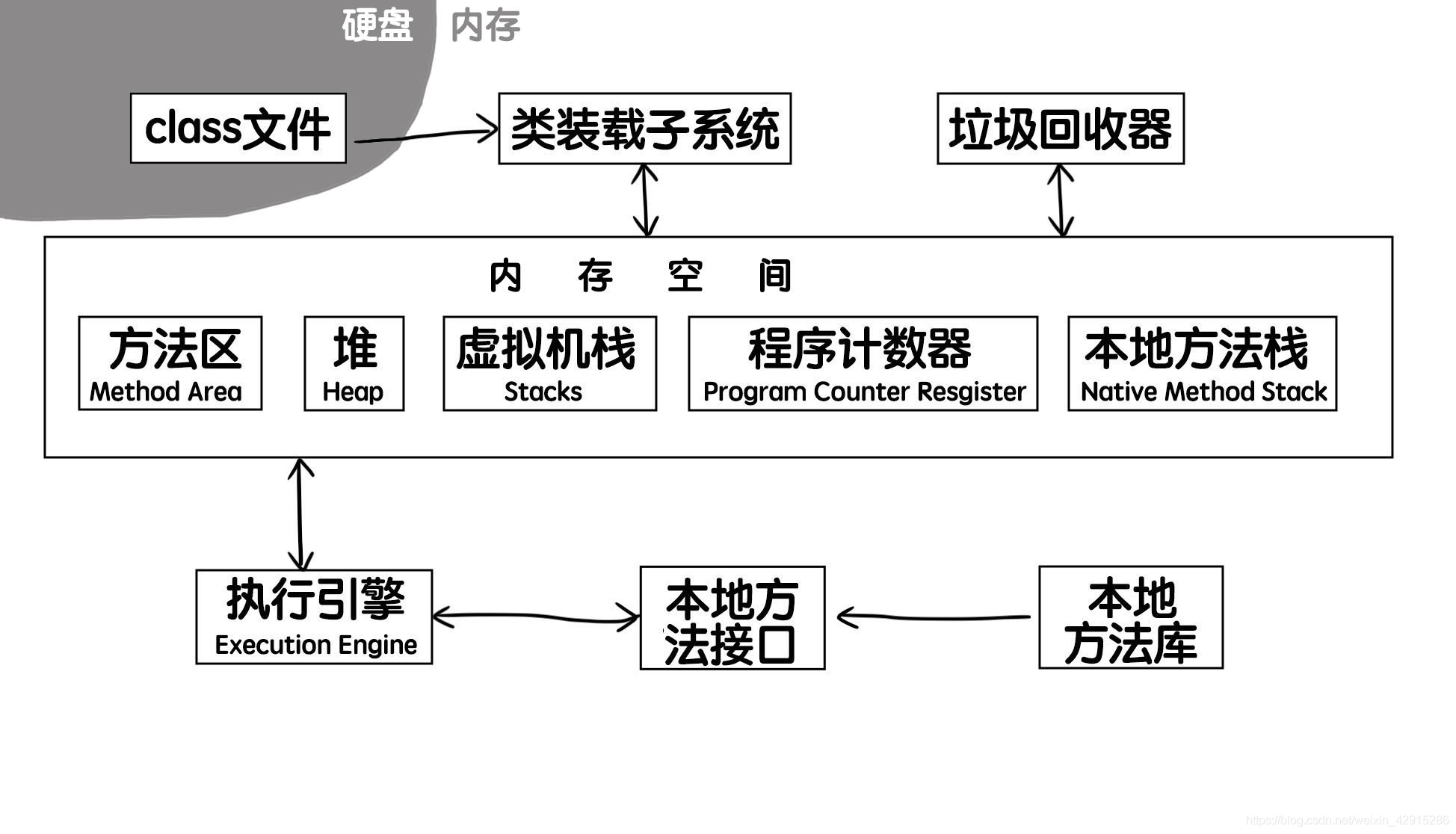
- class文件
是Java程序编译后生成的中间代码(字节码文件),稍后会被JVM解释执行; - 类装载子系统
负责把class文件装载到内存中,供虚拟机执行;
分两种:(1). 启动类装载器(JVM的一部分) (2).用户自定义装载器(Java程序的一部分,必须是ClassLoader类的子类) - 方法区
用来存储被虚拟机加载的类信息、常量、静态变量和编译后的代码等数据;
在类加载器加载class文件时,这些信息会被提取出来,存储到方法区中;
这个区域存放了运行时的常量池,经典应用如:字符串常量;所以他也是线程安全的,他被所有线程共享; - 堆
虚拟机启动时创建的被所有线程共享的区域;
主要存放对象的实例,通过new()操作创建出来的对象实例都存放在堆空间中;
因此,堆成为了垃圾回收器管理的重点区域; - 虚拟机栈
栈是线程私有的区域,每当有新的线程创建,就会分配给他一个栈空间,线程结束后,栈空间会被收回;
因此,栈与线程拥有相同的生命周期; - 程序计数器
也是线程私有的资源,JVM会给每个线程创建单独的程序计数器;
它可以被看作是当前线程执行的字节码的型号指示器;解释器的工作原理就是通过改变这个计数器的值来确定下一条需要被执行的字节码指令,程序控制的流程(循环、分支、异常处理、线程恢复)都通过它来完成。 - 本地方法栈
与虚拟机栈的作用类似,唯一不同的是:虚拟机栈为虚拟机执行Java方法(字节码)服务,本地方法栈则为虚拟机使用到的Native方法服务; - 执行引擎
主要负责执行字节码;
方法的字节码是由Java虚拟机的指令序列构成的,每一条指令包括一个单字节的操作码,执行完成后继续去的下一条操作码执行。 - 垃圾回收器
回收程序中不再使用的内存。
————————
提问:Java类加载器的原理及其组织结构?
类加载器就是上图中的类装载子系统
Java是一种具有动态性的解释型语言,类只有被加载到JVM中后才能运行;
运行程序时,JVM会把编译成功的.class文件按照需求和一定的规则加载到内存中,并组织称一个完整的Java应用程序。这个加载过程是由加载器来完成的,具体来说是由ClassLoader和他的子类来完成的。
加载器本身就是一个类,其本质是把类文件从硬盘读取到内存中。
类的加载方法分为:隐式装载和显示装载两种
隐式装载:程序在使用new等方式创建对象时,隐式地调用类的加载器把对应的类加载到JVM上;
显示装载:直接通过调用class.forName()方法把所需的类加载到JVM上;
任何一个项目都由多个类组成,当程序启动时,只把需要的类加载到JVM上,其他的类只有使用到时才会被加载,采用这种办法,一方面可以加快加载速度,另一方面可以节约诚寻运行过程中堆内存的开销。
此外,Java中每个类和接口都对应一个.class文件,这些文件可以看作是一个个可以被动态加载的单元,因此,当只有部分类被修改时,只需要重新编译变化的类即可,不需要重新编译所有的文件,因此加快了编译速度。
Java中,类的加载是动态的,他不会一次性把所有类全部加载后再运行,而是保证程序运行的基础类(如基类)完全加载到JVM中,至于其他类,需要的时候才加载。
Java把类分成三部分:系统类、扩展类、自定义类,Java针对这三种类也提供了三种加载器,关系如下:
Bootstrap Loader 负责加载系统类(jre/lib/rt.jar的类)
-- ExtClassLoader 负责加载扩展类(jar/lib/ext/*.jar的类)
--AppClassLoader 负责加载应用类(classpath指定的目录或jar中的类)
他们通过委托的方式协调工作,来完成类的加载;
有类需要被加载时,类装载器会请求父类完成这个载入工作,父类搜索自己的路径,若搜索不到,才会让子类按照其搜索路径搜索带加载的类。
类加载的主要步骤:3步
- 装载:根据路径找到对应的
class文件,然后导入; - 链接:分三小部分
(1).检查:检查待加载class文件的正确性
(2).准备:给类中的静态变量分配存储空间
(3).解析:将符号引用转换为直接引用(可选) - 初始化:对静态变量和静态代码块执行初始化工作;
Java平台和垃圾回收 之垃圾回收
一个对象成为垃圾是因为没有引用再指向他,该对象将不可能被程序访问;因此可以认定他是垃圾信息;
————————
提问:垃圾回收器的原理?垃圾回收器是否可以马上回收内存?
Java中,GC (Garbage Collection) 垃圾回收是一个很重要的概念,它的主要作用是回收程序中不再使用的内存;
C/C++中,开发人员必须非常仔细的管理好内存的分配和释放,若忘记或错误地释放内存,往往会导致程序运行不正确甚至是程序的崩溃;
为减轻开发人员的工作,同时增强程序的安全性和稳定性,Java提供了垃圾回收器自动检测对象的作用域,自动把不再使用的内存空间释放掉。
Java中,释放掉占据的内存空间是由GC完成的,程序员无法直接强制释放内存空间,当一个对象不被使用的时候,GC会将该对象标志为垃圾,在后面一个不确定的时间内回收垃圾(程序员无法控制这个时间)。
垃圾回收器的存在,一方面把开放人员从释放内存的复杂工作中解脱出来,提高了开发人员的生产效率;另外一方面,对开发人员屏蔽了释放内存的方法,可以避免因为开发人员错误的操作内存从而导致应用程序的崩溃,保证了程序的稳定性;
但是,垃圾回收器也带来了问题,为了实现垃圾回收,垃圾回收器必须跟踪内存的使用情况,释放没用的内存,在完成内存释放后还需要处理堆中的碎片,这些操作必定会增加JVM的负担,从而降低程序的执行效率;
对于一个对象而言,如果没有任何变量去引用他,那么该对象将不可能被程序访问,因此可以认定他是垃圾信息,可以被回收;只有一个或以上的变量引用他,该对象就不会被垃圾回收;
————————
提问:释放掉一个指定占据的内存空间的方法是?
A. 调用sys.gc()方法
B. 调用free()方法
C. 赋值给该项对象的引用为null
D. 程序员无法明确强调垃圾回收器运行
_____
答案D
————————
垃圾回收易错点!!!
一个对象成为垃圾后,不会立刻被回收;他要等下次垃圾回收器运行的时候才会被回收!!
Java的finalize是在垃圾回收器启动前调用的,且调用了finalize后,不一定会销毁垃圾;而C++中的析构函数调用后,一定会销毁垃圾,说明这两个方法是不同的;
一个对象成为垃圾是因为不再有引用指向他,但是线程并非如此!!!因为垃圾可以被回收,线程没有被引用也可以独立运行;线程和对象因此而不同;
————————
垃圾回收器负责3项任务:
- 分配 内存;
- 确保被引用对象的 内存 不被错误的回收;
- 回收不再被引用的对象的内存空间;
提问:代码如下
interface Animal{
public void test();
}
public class Hourse implements Animal{
public void test(){
}
public static void main(String[] args){
Animal a1 = new Hourse(); //a1为对象1
Animal a2 = new Hourse(); //a2为对象2
Animal a3 = new Hourse(); //a3为对象3
a1 = a2;
a2 = null;
a3 = a1;
}
}
问题:当程序执行完这三句 a1 = a2; a2 = null; a3 = a1;
被垃圾回收器回收的对象个数为?
当执行到a1 = a2,a1和a2都指向对象2,此时对象1不再被使用;对象1被垃圾回收;
执行a2 = null时,由于a1仍然执行对象2,所以对象2不能被垃圾回收;
执行a3 = a1时, a3也执行对象2,此时对象3不再被使用,对象3被垃圾回收;
画张图更好理解:
a1 a3
↘ ↙
a2
↓
null
提问:如何查看Java程序使用内存的情况?
Java中,每个应用程序中都有一个Runtime类实例,Runtime提供了多个查看内存使用情况的方法:
Runtime.getRuntime().freeMemory() 查看JVM中空闲内存量(单位:字节)
Runtime.getRuntime().totalMemory() 查看JVM中内存总量(单位:字节)
Runtime.getRuntime().maxMemory() 查看JVM中最大内存量(单位:字节)
Runtime.getRuntime().availableProcessors() 查看可用处理器数目
例子:
class Test{
public static void main(String[] args){
System.out.println(Runtime.getRuntime().freeMemory());
System.out.println(Runtime.getRuntime().totalMemory());
System.out.println(Runtime.getRuntime().maxMemory());
System.out.println(Runtime.getRuntime().availableProcessors());
}
}
————————
提问:下面代码是否可以进行优化?
for(int i = 0;i<1000,i++){
Object object = new Object();
Shystem.out.println("object name is" + object);
}
答案:可以优化,优化后为:
Object object;
for(int i = 0;i<1000,i++){
object = new Object();
Shystem.out.println("object name is" + object);
}
题目中的代码:每执行一次for循环,就要在栈中分配一个内存空间给object使用,每次巡回结束后,object作用域就结束了,就要收回object占用的栈空间。代码中规定循环1000次,于是需要分配1000次内存空间,同时收回1000次存储空间,开销非常大;
优化后的代码:object在for循环中的执行过程可见,因此不需要不断地在栈中给object申请与释放空间,此种方法具有更高效率;
————————
提问:如何让JVM的堆、栈发生内存溢出?
Java中,通过new实例化的对象都存储在堆空间中,因此只要做到两点 1.不断用new实例化对象 2. 一直保持对这些对象的引用(垃圾回收器无法回收),实例化够多就会导致栈溢出,如下:
List<Object> l = new ArrayList<Object>();
while(true)
l.add(new Object());
方法调用时,栈用来保存上下文的一些内容,由于站的大小是有上限的,当出现非常深层次的方法调用时,就会霸占的空间用完。
java.util.Collection 容器(集合类)
简单概念:Map是接口,不能直接实例化Map的对象,但是可以实例化实现Map接口的类的对象:HashMap;
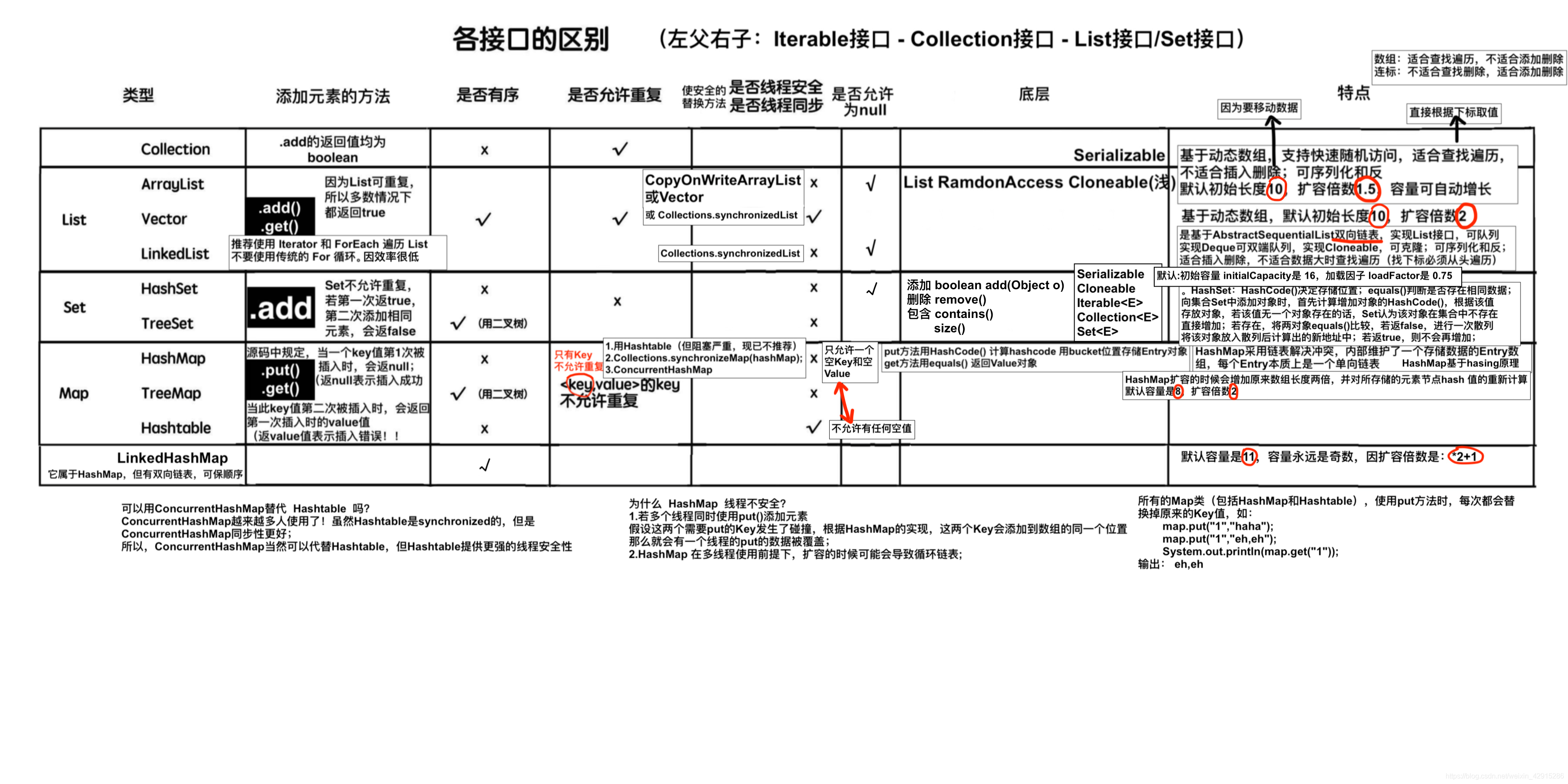
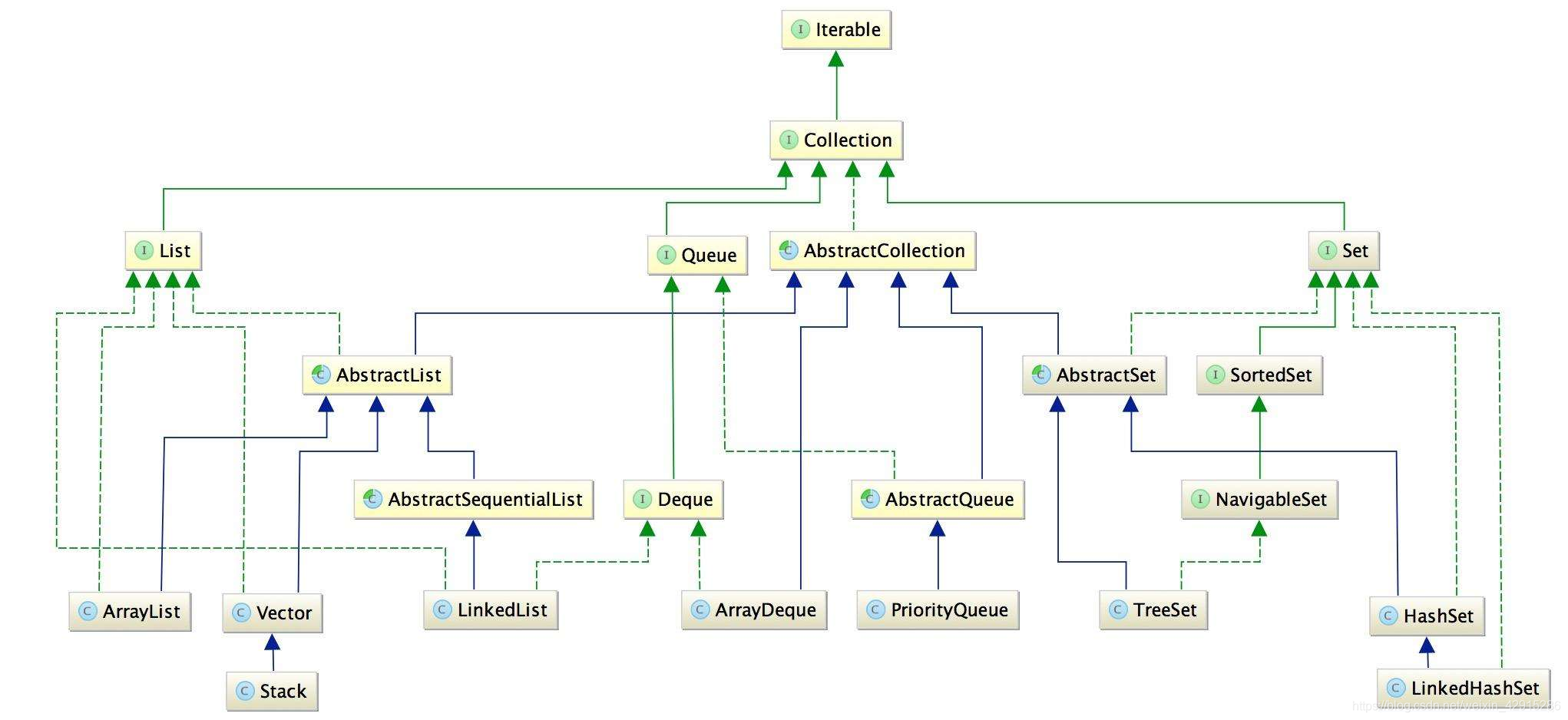
Collection:
ArrayList Vector LinkedList .add()
HashSet TreeSet .add()
HashMap TreeMap HashTable .put()
java.util.Collection 是一个集合接口,它提供了集合对象进行基本操作的接口方法,下面是他具体的接口;
java.util.List 可保存相同的多个元素,按照存入顺序保存,可重复;
java.util.Set 只保存唯一元素,不可重复;
java.util.Map 以键-值 对(key - value)存储对象,键不允许重复 ;
————————
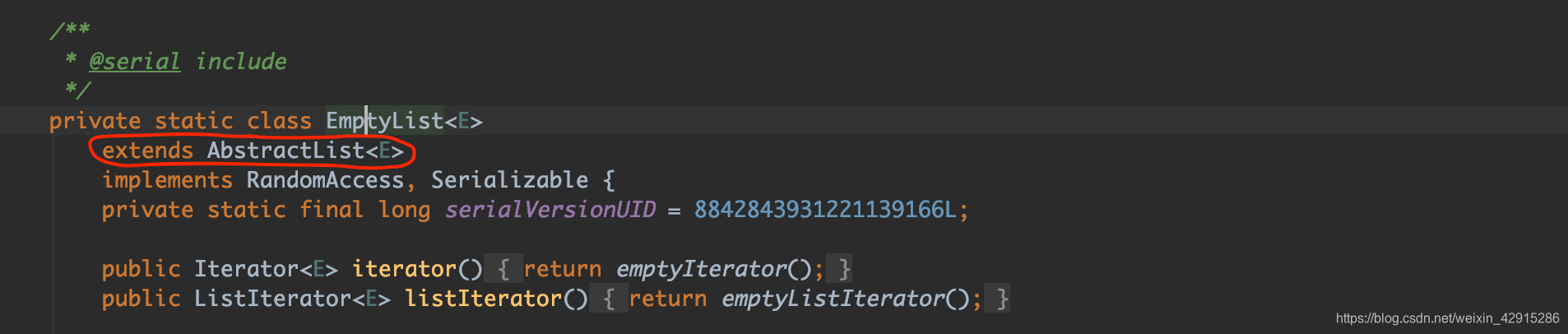
Collections.emptyList() / emptySet() / emptyMap() 有坑
Collections.emptyList() / Collections.emptySet() / Collections.emptyMap()坑的地方是相似的;
拿Collections.emptyList()打比方:
特点:可以new一个NULL的List,且此List之后也不能再添加元素;
这么做的好处:
(1).每一次new ArrayList() / new LinkedList()时,都会赋予初始大小,占用一定内存空间;
而Collections.emptyList()就没有这方面的困扰,节省了内存;
(2).new Collections.emptyList()后不用再判空,因为他本来就是空的;
这么做的隐患:
Collections.emptyList()不能进行add/remove方法,否则报错:throw new UnsupportedOperationException()
所以,若用到了Collections.emptyList()?
编码添加操作时会看上去一切正常,结果运行时则会报错,让人一头雾水!!!
此方法也容易让团队其他成员误操作,所以不建议使用;
——————————————————
List
- 提问:Map怎么转成List?
Map<Integer,实体类>初始化。。。
Collection<实体类> collection = map.values();
List<实体类> list = new ArrayList<>(collection);
————————
ArrayList
ArrayList扩充/扩容的问题:
提问:ArrayList list = new ArrayList(20);中的list扩容了几次?
这道题有点迷惑性;
ArrayList默认长度为10,ArrayList扩容一次为扩充到原来的1.5倍(10个,扩充一次 = 变成1.5倍,10个变成15个)
如果要在后期往ArrayList中添加到20个元素,需要扩充2次;
但是!!!这句式子在初始化时就已经制定了需要20个空间,初始化时已经一次性分配了这么多空间,不需要扩充了;
答案是:0
ArrayList的特点:
- 1. ArrayList底层是动态数组,实现了
List<E>,RandomAccess,Cloneable,java.io.Serializable,并允许包括null在内的所有元素。
1.1,实现了RandomAccess接口标识着其支持随机快速访问,实际上,我们查看RandomAccess源码可以看到,其实里面什么都没有定义.因为ArrayList底层是数组,那么随机快速访问是理所当然的,访问速度O(1).
RandomAccess是一个空的接口, 空接口一般只是作为一个标识, 如Serializable接口. JDK文档说明RandomAccess是一个标记接口(Marker interface), 被用于List接口的实现类, 表明这个实现类支持 快速随机访问功能 (如ArrayList). 当程序在遍历这中List的实现类时, 可以根据这个标识来选择更高效的遍历方式。
1.2,现了Cloneable接口,标识着可以它可以被复制.注意,ArrayList里面的clone()复制其实是浅复制;
-
2. 底层使用数组实现,默认初始容量为10.当超出后,会自动扩容为原来的1.5倍,即自动扩容机制。
数组的扩容是新建一个大容量(原始数组大小+扩充容量)的数组,然后将原始数组数据拷贝到新数组,然后将新数组作为扩容之后的数组。数组扩容的操作代价很高,我们应该尽量减少这种操作。 -
3. 该集合是可变长度数组,数组扩容时,会将老数组中的元素重新拷贝一份到新的数组中,每次数组容量增长大约是其容量的1.5倍,如果扩容一半不够,就将目标size作为扩容后的容量.这种操作的代价很高。采用的是 Arrays.copyOf浅复制;
3.1这里简单说一下什么是浅复制
浅复制:只复制一个对象,但新对象和老对象同是一个地址值,
深复制:复制一个对象,新老对象的地址值也变了.
详情请看(要了解什么是浅复制):点击打开链接https://blog.youkuaiyun.com/qq_38859786/article/details/80318977 -
4. 采用了Fail-Fast机制,面对并发的修改时,迭代器很快就会完全失败,报异常
concurrentModificationException(并发修改一次),而不是冒着在将来某个不确定时间发生任意不确定行为的风险; -
5. remove方法会让下标到数组末尾的元素向前移动一个单位,并把最后一位的值置空,方便GC;
-
6. 数组扩容代价是很高的,因此在实际使用时,我们应该尽量避免数组容量的扩张。当我们可预知要保存的元素的多少时,要在构造ArrayList实例时,就指定其容量,以避免数组扩容的发生。或者根据实际需求,通过调用ensureCapacity方法来手动增加ArrayList实例的容量。
-
7. ArrayList不是线程安全的,只能用在单线程环境下,多线程环境下可以考虑用Collections.synchronizedList(List l)函数返回一个线程安全的ArrayList类,也可以使用concurrent并发包下的
CopyOnWriteArrayList类。
eventbus的订阅方法subscribe()里面,就采用了线程较为安全的CopyOnWriteArrayList集合。
————————
Vector
————————
LinkedList
LinkedList 是一个继承于AbstractSequentialList的双向链表。它也可以被当作堆栈、队列或双端队列进行操作。
LinkedList 实现 List 接口,能对它进行队列操作。
LinkedList 实现 Deque 接口,即能将LinkedList当作双端队列使用。
LinkedList 实现了Cloneable接口,即覆盖了函数clone(),能克隆。
LinkedList 实现 java .io.Serializable接口,这意味着LinkedList支持序列化,能通过序列化去传输。
LinkedList 是非同步的。
——————————————————
Set
————————
HashSet
【构造方法摘要】
构造一个新的空set,其底层HashMap 实例的默认初始容量是 16,加载因子是 0.75。
HashSet(Collection<? extends E> c)
构造一个包含指定 collection 中的元素的新 set。
HashSet(int initialCapacity)
构造一个新的空 set,其底层 HashMap 实例具有指定的初始容量和默认的加载因子(0.75)。
HashSet(int initialCapacity, float loadFactor)
构造一个新的空 set,其底层 HashMap 实例具有指定的初始容量和指定的加载因子。
Set类是一个不包含重复元素的 collection。
更正式地说,set 不包含满足 e1.equals(e2) 的元素对 e1 和 e2,并且最多包含一个 null 元素。在所有构造方法以及 add、equals 和 hashCode 方法的协定上,Set 接口还加入了其他规定,这些规定超出了从 Collection 接口所继承的内容。
出于方便考虑,它还包括了其他继承方法的声明(这些声明的规范已经专门针对 Set 接口进行了修改,但是没有包含任何其他的规定)。对这些构造方法的其他规定是(不要奇怪),所有构造方法必须创建一个不包含重复元素的 set;
HashSet类实现 Set 接口,由哈希表(实际上是一个 HashMap 实例)支持。它不保证集合的迭代顺序;特别是它不保证该顺序恒久不变。此类允许使用 null 元素。 此类为基本操作提供了稳定性能,这些基本操作包括 add、remove、contains 和 size,假定哈希函数将这些元素正确地分布在桶中。对此集合进行迭代所需的时间与 HashSet 实例的大小(元素的数量)和底层 HashMap 实例(桶的数量)的“容量”的和成比例。因此,如果迭代性能很重要,则不要将初始容量设置得太高(或将加载因子设置得太低)。注意,此实现不是同步的。
什么是HashSet?
HashSet实现了Set接口,它不允许集合中有重复的值,当我们提到HashSet时,第一件事情就是在将对象存储在HashSet之前,要先确保对象重写equals()和hashCode()方法,这样才能比较对象的值是否相等,以确保set中没有储存相等的对象。如果我们没有重写这两个方法,将会使用这个方法的默认实现。
public boolean add(Object o)方法用来在Set中添加元素,当元素值重复时则会立即返回false,如果成功添加的话会返回true。
————————
TreeSet
TreeSet类实现 Set 接口,该接口由 TreeMap 实例支持。此类保证排序后的 set 按照升序排列元素,根据使用的构造方法不同,可能会按照元素的自然顺序进行排序(参见 Comparable),或按照在创建 set 时所提供的比较器进行排序。此实现为基本操作(add、remove 和 contains)提供了可保证的 log(n) 时间开销。注意,如果要正确实现 Set 接口,则 set 所维护的顺序(是否提供了显式比较器)必须为与等号一致(请参阅与等号一致 精确定义的 Comparable 或 Comparator)。这是因为 Set 接口根据 equals 操作进行定义,但 TreeSet 实例将使用其 compareTo(或 compare)方法执行所有的键比较,因此,从 set 的角度出发,该方法认为相等的两个键就是相等的。即使 set 的顺序与等号不一致,其行为也是 定义良好的;它只是违背了 Set 接口的常规协定。 注意,此实现不是同步的。 备注:要想使用TreeSet必须实现Comparable 接口或 Comparator接口,通过重写接口中的方法实现自然排序。
——————————————————
Map
Map常用方法介绍:
Map<String,String> map = new HashMap<>();
map.put("1","value1");
map.put("2","value2");
map.put("3","value3");
map.keySet() = [1, 2, 3] 是所有Key的集合;
map.values() = [value1, value2, value3] 是所有Value的集合;
map.entrySet = [1=value1, 2=value2, 3=value3] 是所有Entry的集合;
遍历Map的几种方法:
直接输出map
System.out.println(map)
返回:{1=value1, 2=value2, 3=value3}
// (1).用 Map.keySet 遍历
System.out.println("(1).用 Map.keySet 遍历");
for (String key:map.keySet()){
System.out.println("key = "+key+" value = "+map.get(key));
}
// (2).用 Map.entrySet iterator 遍历(个人感觉多此一举,不如方法3)
System.out.println("(2).用 Map.entrySet iterator 遍历");
Iterator<Map.Entry<String,String>> it = map.entrySet().iterator();
while(it.hasNext()){
Map.Entry<String,String> entry = it.next();
System.out.println("key = " + entry.getKey() + " value = " + entry.getValue());
}
// (3).用 Map.entry 遍历 【推荐,特别容量大时】
System.out.println("(3).用 Map.entry 遍历");
for (Map.Entry<String,String> entry:map.entrySet()){
System.out.println("key = "+entry.getKey()+" value = "+entry.getValue());
}
以上方法的输出都是一样:
key = 1 value = value1
key = 2 value = value2
key = 3 value = value3
(特别).用 Map.values 遍历所有Value,但不能遍历Key;
Map中只能靠Key找到Value,因为Key不可重复,Value可重复;
System.out.println("(特别).用 Map.values 遍历所有Value,但不能遍历Key");
for (String v:map.values()){
System.out.println("value = "+v);
}
————————
HashMap
- “你知道HashMap的工作原理吗?” “你知道HashMap的get()方法的工作原理吗?”
HashMap基于hashing原理,我们通过put()和get()方法储存和获取对象。
当我们将Key-Value(一个键值对就是一个Entry)传递给put()方法时,它调用Key对象的hashCode()方法来计算hashcode,然后找到bucket位置来储存Entry对象。
当用get()获取Value对象时,通过Key对象的equals()方法找到正确的Key-Value,然后返回Value对象。
HashMap使用 链表 来解决碰撞问题,当发生碰撞了,对象将会储存在链表的下一个节点中。 HashMap在每个链表节点中储存键值对对象。
这里关键点在于指出,HashMap是在bucket中储存键对象和值对象,作为Map.Entry。这一点有助于理解获取对象的逻辑。
- 我们能否让HashMap同步?
HashMap可以通过下面的语句进行同步:
Map m = Collections.synchronizeMap(hashMap);
-
能否让HashMap实现线程安全,如何做?
1、直接使用Hashtable,但是当一个线程访问HashTable的同步方法时,其他线程如果也要访问同步方法,会被阻塞住。举个例子,当一个线程使用put方法时,另一个线程不但不可以使用put方法,连get方法都不可以,效率很低, 【现在基本不会选择它了】!!!
2、HashMap可以通过下面的语句进行同步:
Collections.synchronizeMap(hashMap);
3、直接使用JDK 5 之后的ConcurrentHashMap。 -
“你用过HashMap吗?” “什么是HashMap?你为什么用到它?”
HashMap实现了Map接口,Map接口对键值对进行映射。Map中不允许重复的键。Map接口有两个基本的实现,HashMap和TreeMap。TreeMap保存了对象的排列次序,而HashMap则不能。HashMap存储的是键值对,允许键和值为null。
HashMap是非synchronized的,但collection框架提供方法能保证HashMap synchronized,这样多个线程同时访问HashMap时,能保证只有一个线程更改Map。
public Object put(Object Key,Object value)方法用来将元素添加到map中。 -
HashSet与HashMap的区别?

-
如果两个键的hashcode相同,你如何获取值对象?
当我们调用get()方法,HashMap会使用Key对象的hashcode找到bucket位置,找到bucket位置之后,会调用keys.equals()方法去找到链表中正确的节点,最终找到要找的值对象。
注意:面试官会问因为你并没有值对象去比较,你是如何确定确定找到值对象的?除非面试者直到HashMap在链表中存储的是键值对,否则他们不可能回答出这一题。
一些优秀的开发者会指出使用不可变的、声明作final的对象,并且采用合适的equals()和hashCode()方法的话,将会减少碰撞的发生,提高效率。不可变性使得能够缓存不同键的hashcode,这将提高整个获取对象的速度,使用String,Interger这样的wrapper类作为键是非常好的选择。 -
hashmap的存储过程?
HashMap内部维护了一个存储数据的Entry数组,HashMap采用链表解决冲突,每一个Entry本质上是一个单向链表。当准备添加一个key-value对时,首先通过hash(key)方法计算hash值,然后通过indexFor(hash,length)求该key-value对的存储位置,计算方法是先用hash&0x7FFFFFFF后,再对length取模,这就保证每一个key-value对都能存入HashMap中,当计算出的位置相同时,由于存入位置是一个链表,则把这个key-value对插入链表头。
HashMap中key和value都允许为null。key为null的键值对永远都放在以table[0]为头结点的链表中。 -
hashMap扩容问题?
扩容是是新建了一个HashMap的底层数组,而后调用transfer方法,将就HashMap的全部元素添加到新的HashMap中(要重新计算元素在新的数组中的索引位置)。 很明显,扩容是一个相当耗时的操作,因为它需要重新计算这些元素在新的数组中的位置并进行复制处理。因此,我们在用HashMap时,最好能提前预估下HashMap中元素的个数,这样有助于提高HashMap的性能。
HashMap共有四个构造方法。构造方法中提到了两个很重要的参数:初始容量和加载因子。这两个参数是影响HashMap性能的重要参数,其中容量表示哈希表中槽的数量(即哈希数组的长度),初始容量是创建哈希表时的容量(从构造函数中可以看出,如果不指明,则默认为16),加载因子是哈希表在其容量自动增加之前可以达到多满的一种尺度,当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 resize 操作(即扩容)。
默认加载因子为0.75,如果加载因子越大,对空间的利用更充分,但是查找效率会降低(链表长度会越来越长);如果加载因子太小,那么表中的数据将过于稀疏(很多空间还没用,就开始扩容了),对空间造成严重浪费。如果我们在构造方法中不指定,则系统默认加载因子为0.75,这是一个比较理想的值,一般情况下我们是无需修改的。 -
为什么HashMap是线程不安全的,实际会如何体现?
第一,如果多个线程同时使用put方法添加元素;
假设正好存在两个put的key发生了碰撞(hash值一样),那么根据HashMap的实现,这两个key会添加到数组的同一个位置,这样最终就会发生其中一个线程的put的数据被覆盖。
第二,如果多个线程同时检测到元素个数超过数组大小*loadFactor;
这样会发生多个线程同时对hash数组进行扩容,都在重新计算元素位置以及复制数据,但是最终只有一个线程扩容后的数组会赋给table,也就是说其他线程的都会丢失,并且各自线程put的数据也丢失。且会引起死循环的错误。
————————
TreeMap
————————
HashTable
-
我们可以使用CocurrentHashMap来代替Hashtable吗?
这是另外一个很热门的面试题,因为ConcurrentHashMap越来越多人用了。我们知道Hashtable是synchronized的,但是ConcurrentHashMap同步性能更好,因为它仅仅根据同步级别对map的一部分进行上锁。ConcurrentHashMap当然可以代替HashTable,但是HashTable提供更强的线程安全性。 -
为什么HashTable的默认大小和HashMap不一样?
前面分析了,Hashtable 的扩容方法是乘2再+1,不是简单的乘2,故hashtable保证了容量永远是奇数,合之前分析hashmap的重算hash值的逻辑,就明白了,因为在数据分布在等差数据集合(如偶数)上时,如果公差与桶容量有公约数 n,则至少有(n-1)/n 数量的桶是利用不到的,故之前的hashmap 会在取模(使用位与运算代替)哈希前先做一次哈希运算,调整hash值。这里hashtable比较古老,直接使用了除留余数法,那么就需要设置容量起码不是偶数(除(近似)质数求余的分散效果好)。
HashMap和LinkedHashMap的代码区别:
public static void main(String[] args) {
Map<String,String> map = new HashMap();
map.put("a3","aa");
map.put("a2","bb");
map.put("b1","cc");
for(Iterator iterator = map.values().iterator(); iterator.hasNext();){
String name = (String) iterator.next();
System.out.println(name);
}
}
输出:
bb
aa
cc
public static void main(String[] args) {
Map<String,String> map = new LinkedHashMap();
map.put("a3","aa");
map.put("a2","bb");
map.put("b1","cc");
for(Iterator i = map.values().iterator();i.hasNext();){
String name = (String)i.next();
System.out.println(name);
}
}
输出:
aa
bb
cc
————————
SortedMap / TreeMap
SortedMap<XX,XX> map = new TreeMap<>(); 可以实现对Map的排序;
SortedMap<Integer,String> map = new TreeMap<>();
map.put(10,"a");
map.put(1,"x");
map.put(5,"e");
for (Map.Entry<Integer,String> temp : map.entrySet()){
System.out.println("key = "+temp.getKey()+" value = "+temp.getValue());
}
返回:
key = 1 value = x
key = 5 value = e
key = 10 value = a
对Value也可以排序:
https://www.cnblogs.com/jpfss/p/9772818.html
————————
其他
格式举例:
List a = new ArrayList();
加范型,三种都可:
List<String> a = new ArrayList<String>();
List<String> a = new ArrayList<>();
List<String> a = new ArrayList();
(JDK7开始允许此种写法)
————————
三个接口的 添加方法 返回值例子:
List<String> list = new ArrayList<>();
System.out.println(list.add("a")); //true
System.out.println(list.add("a")); //true
System.out.println(list.add("a")); //true
System.out.println(list.add("b")); //true
Set<String> set = new TreeSet<>();
System.out.println(set.add("a")); //true
System.out.println(set.add("a")); //false
System.out.println(set.add("a")); //false
Map<String, String> map = new TreeMap<>();
System.out.println(map.put("k1", "v1")); //首次插入key值:k1,插入成功,返:null
System.out.println(map.put("k1", "v1")); //重复插入key值:k1,此时返回k1第一次插入时的value值:v1
System.out.println(map.put("k2", "v2")); //返:null
System.out.println(map.put("k2", "v2")); //返:v2
System.out.println(map.put("k3", "v3")); //返:null
System.out.println(map.put("k3", "v3")); //返:v3
————————
提问:List<String> list = new ArrayList<>()和List<String> list = new ArrayList<String>()有什么区别?
就是说,在前面括号内容已经写了的前提下,后面那个括号内容写不写有什么区别?
答:
没区别;这是JDK新版本越来越简化语法的行为,前面制定了范型,后面就可以忽略;
————————
提问:对比Vector、ArrayList、LinkedList有何区别?
这三者都是实现集合框架中的 List,也就是所谓的有序集合,因此具体功能也比较近似,比如都提供按照位置进行定位、添加或者删除的操作,都提供迭代器以遍历其内容等。
但因为具体的设计区别,在行为、性能、线程安全等方面,表现又有很大不同。
Vector 是 Java 早期提供的线程安全的动态数组,如果不需要线程安全不建议选择,毕竟同步是有额外开销的。Vector 内部有初始化容量大小,若存储元素超过了这个大小就要动态的扩充存储单元,可以根据需要自动的增加容 量,当数组已满时,会创建新的数组,并拷贝原有数组数据。
ArrayList 是应用更加广泛的动态数组实现,它本身不是线程安全的,所以性能要好很多。与 Vector 近似,ArrayList 也是可以根据需要调整容量,不过两者的调整逻辑有所区别,Vector 在扩容时会提高 1 倍,而 ArrayList 则是增加 50%。
LinkedList 顾名思义是 Java 提供的双向链表,所以它不需要像上面两种那样调整容量,插入元素时也不用对数据进行移动,所以插入效率高,它也不是线程安全的。
实际使用怎么选择?
当对数据的主要操作时作为索引或只在集合的末端增加、删除元素时,使用Vector、ArrayList效率更高;
当对数据的操作主要为指定位置的插入或删除。使用LinkedList效率更高;
当再多线程中使用容器时,Vector效率更高。
可补充:
Vector 和 ArrayList 作为动态数组,其内部元素以数组形式顺序存储的,所以非常适合随机访问的场合。除了尾部插入和删除元素,往往性能会相对较差,比如我们在中间位置插入一 个元素,需要移动后续所有元素。
而 LinkedList 进行节点插入、删除却要高效得多,但是随机访问性能则要比动态数组慢。
提问:对于java.util包,以下说法错误的是?
A. Vector属于java.util包
B. Vector类放在.../java/util目录下
C. Vector在java.util文件中
D. Vector类时Sun公司的产品
答案C这是包名,是一个目录结构而非一个文件
————————
提问:对比Hashtable、HashMap、TreeMap有什么不同?
Hashtable、HashMap、TreeMap 都是最常见的一些 Map 实现,是以键值对的形式存储和操
作数据的容器类型。
Hashtable 是早期 Java 类库提供的一个哈希表实现,本身是同步的,不支持 null 键和值,由 于同步导致的性能开销,所以已经很少被推荐使用。
HashMap 是应用更加广泛的哈希表实现,根据Key的HashCode存储数据,行为上大致上与 HashTable 一致(他是Hashtable的轻量级实现),主要区别在于 HashMap 不是同步的, 支持 null 键和值 (但仅仅允许一条这种情况的键值对存在)等。通常情况下,HashMap 进行 put 或者 get 操作,可以达到常数时间的性能,所以它是绝大部分利用键值对存取场景的首选,比如,实现一个 用户 ID 和用户信息对应的运行时存储结构。
TreeMap 则是基于红黑树的一种提供顺序访问的 Map,和 HashMap 不同,它的 get、put、 remove 之类操作都是 O(log(n))的时间复杂度,具体顺序可以由指定的 Comparator 来决定,或者根据键的自然顺序来判断。
提问:如何实现HashMap的同步?
Map m = Collections.synchronizedMap(new HashMap());
具体而言,该方法返回一个同步的Map,该Map封装了底层的HashMap所有方法,使得底层的HashMap即使在多线程环境中也是安全的。
提问:Hashtable上下文中,同步指什么?
同步意味着一个时间点上只有一个线程可以修改hash表,任何线程在执行Hashtable的更新操作前都需要获取对象锁,其他线程则等待锁的释放。
————————
提问:哪种创建Map集合的方式是对的?
A. Map m = new Map()
B. Map是接口,所以不能实例化;
答案B
Map是接口,所以不能直接实例化Map的对象,但是可以实例化实现Map接口的类的对象
如Map m = new HashMap();
迭代器 Iterator (是一个对象)
迭代器是一个对象;
工作是:遍历并选择序列中的对象;
提供了一种方法:无需暴露该对象中内部细节,又能访问一个容器对象中的各个元素;
迭代器格式:
Iterator<范型> 迭代器实例 = 集合实例.iterator() ;
while ( 迭代器实例.hasNext() ) {
....
}
或:
for( Iterator<范型> 迭代器实例 = 集合实例.iterator() ; 迭代器实例.hasNext() ;) {
....
}
即:
List<String> II = new LinkedList<String>();
....
Iterator<String> i = II.iterator();
while(i.hasNext()){
//
}
或者:
for(Iterator<String>i = II.iterator();i.hasNext();){ //注意有两个引号!!
//
}
——————————————
提问:迭代器与for循环的区别?
for循环 便于访问 顺序储存 的记录,而 迭代器 便于访问 链式储存 的记录。
foreach:for(int i:list)
迭代器:for(Iterator<Integer> i=list.iterator();i.hasNext();)
这两者的效果是一样的;
记录的存取方式有两种:一种是顺序存储,另一种是链接存储
对于顺序存储的记录可以根据其下标找到对应的记录;
而链接存储(拿单链表为例)则必须找到其前一个记录的位置才能够找到本记录。
所以for循环便于访问顺序存储的记录,比如数组等;
而迭代则更适用于链接存储的记录,虽然Java中有些底层通过链接存储原理实现的集合
也可以通过下标获取指定的记录,但是其每次都必须从链表头开始查找记录,这样会影响查找的效率;
——————————————
提问:for和foreach的区别?
foreach循环是利用迭代器的使用循环。
——————————————
迭代器例子:
public class IteratorTest{
public static void main(String[] args){
List<String> II = new LinkedList<String>();
II.add("first");
II.add("second");
II.add("third");
II.add("forth");
for(Iterator<String> iter = II.iterator();iter.hasNext();){
String str = iter.next();
System.out.println(str);
}
}
}
_______
结果:
first
second
third
forth
注意!当使用iterator()时常遇到ConcurrentModifiedException异常,这是因为使用此方法遍历容器的同时又对容器做增加或删除操作所导致的,比如:
public class IteratorTest{
public static void main(String[] args){
List<String> II = new LinkedList<String>();
II.add("first");
II.add("second");
II.add("third");
II.add("forth");
for(Iterator<String> iter = II.iterator();iter.hasNext();){
String str = <String>iter.next();
System.out.println(str);
if(str.equals("second"));
II.add("five");
}
}
}
_______
结果:
first
second
Exception in thread "main" Java.util.ConcurrentModificationException
ConcurrentModificationException:当方法检测到对象的并发修改,但不允许这种修改时,抛出此异常;
异常原因:
迭代器是依赖于集合而存在的,在判断成功后,集合的中新添加了元素,而迭代器却不知道,所以就报错了,这个错叫并发修改异常;其实这个问题描述的是:普通迭代器遍历元素的时候,通过集合是不能修改元素的;
细节:调用iterator(),返回Iterator对象时,会把容器中包含对象的个数赋值给exceptedModCount,在调用next()时,会比较exceptedModCount和modCount(容器中实际对象个数)值是否相等,若不想等,则会抛出ConcurrentModificationException;
解决办法:在遍历过程中把需要删除的对象保存到一个集合中,等遍历结束后调用removeAll()来删除,或者使用iter.remove();或:
A:迭代器迭代元素,迭代器修改元素
元素是跟在刚才迭代的元素后面的。
B:集合遍历元素,集合修改元素(普通for循环进行遍历)
元素是在最后添加的。
————————
为什么要重写equals()和hashCode()?
判断两个对象在逻辑上是否相等,可根据类的成员变量来判断两个类的实例,但继承了Object中的equals方法只能判断两个引用变量是否为同一对象,所以我们需要重写equals方法。
比如定义private Set<Category>时,(Category是一个实体类),需要判断Category中的变量id时,就需要重写equals和hashCode方法;
但如果定义private Set<String>时,就无须手动重写了,因为String本身就重写过,查看源码可知;
(递归算法中要重写equals和hashCode;因为使用Set对象时,要重写equals和hashCode方法;因为equals和hashCode方法间有个关系:
hashCode只会比较ID;equals除了ID还可以比较更多元素;
因此,若两个对象equals相同,hashCode一定相同;hashCode相同,equals不一定相同;
所以,遇到Set对象时,要重写equals和hashCode,【且保证里面判断因素是一样的】)
提问:两个对象值相同 x.equals(y) == true ,但却可有不同的 hash code ,这句话对不对?
答:不对,equals相同,则有相同的 hash code
这是java语言的定义:
- 对象相等则hashCode一定相等;
- hashCode相等对象未必相等
在Category的实体类中,重写即可;
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Category category = (Category) o;
return !(id != null ? !id.equals(category.id) : category.id != null);
}
@Override
public int hashCode() {
return id != null ? id.hashCode() : 0;
}
高质量实现equals方法的诀窍:
@Override
public boolean equals(Object o) {
if (this == o) return true;
//1.使用 == 操作符检查:参数是否为这个对象的引用;如果是,返回true;这是一种性能优化;
//2.使用instanceOf检查“参数是否为正确的类型”(这里没写)
if (o == null || getClass() != o.getClass()) return false;
Category category = (Category) o;
//3.把参数转换为正确的类型(因转换前进行过instanceOf测试,所以确保会成功)
return !(id != null ? !id.equals(category.id) : category.id != null);
}
@Override
public int hashCode() {
return id != null ? id.hashCode() : 0;
}
举个例子:多个参数时(id+name)
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Category category = (Category) o;
return Objects.equals(id, category.id) &&
Objects.equals(name, category.name);
}
@Override
public int hashCode() {
return Objects.hash(id, name);
}
提问:下列程序中构造了一个SET并且调用了他的add()方法,输出结果是什么?
public class A{
public int hashCode(){
return 1;
}
public Boolean equals(Object b){
return true;
}
public static void main(String args[]){
Set set=new HashSet();
set.add(new A());
set.add(new A());
set.add(new A());
System.out.println(set.size());
}
}
答:1
class A{
class Dog{
private String name;
private int age;
public int step;
Dog(String s,int a){
name=s;
age=a;
step=0;
}
public void run(Dog fast){
fast.step++;
}
}
public static void main (String args[]){
A a=new A();
Dog d=a.new Dog("Tom",3);
d.step=25;
d.run(d);
System.out.println(d.step);
}
}
答:
26
——————————
为什么要重写toString()?
所有类都继承自Object,而他有一个toString方法,所有类都会继承他:他返回对象的一个String标示,且对调试很有帮助;
但默认的toString()往往不能满足要求,所以需要重写。
比如一个实体类中:Product
写完了属性和setter getter后,还要重写一个toString():
因为如果不写toString(),打印日志时,就不能直观看到其中的内部结构;
比如没写toString()时,在Product中写一个main方法,System.out.println(new Order());
打印出来为:com.xxxx.entity.Product@60e53b93
看不出任何信息;
我们想看到其中的属性内有没有null值,于是可以重写toString():
@Override
public String toString() {
return "Product{" +
"id='" + id + '\'' +
", name='" + name + '\'' +
", threshouldAmount=" + threshouldAmount +
", stepAmount=" + stepAmount +
", lockTerm=" + lockTerm +
", rewardRate=" + rewardRate +
", status='" + status + '\'' +
", memo='" + memo + '\'' +
", createAt=" + createAt +
", createUser='" + createUser + '\'' +
", updateAt=" + updateAt +
'}';
}
打印出来为Product{id='null', name='null', threshould_amount=null, step_amount=null, lock_term=null, reward_rate=null, status='null', memo='null', create_at=null, create_user='null', update_at=null, update_user='null'}
容器 之 Map
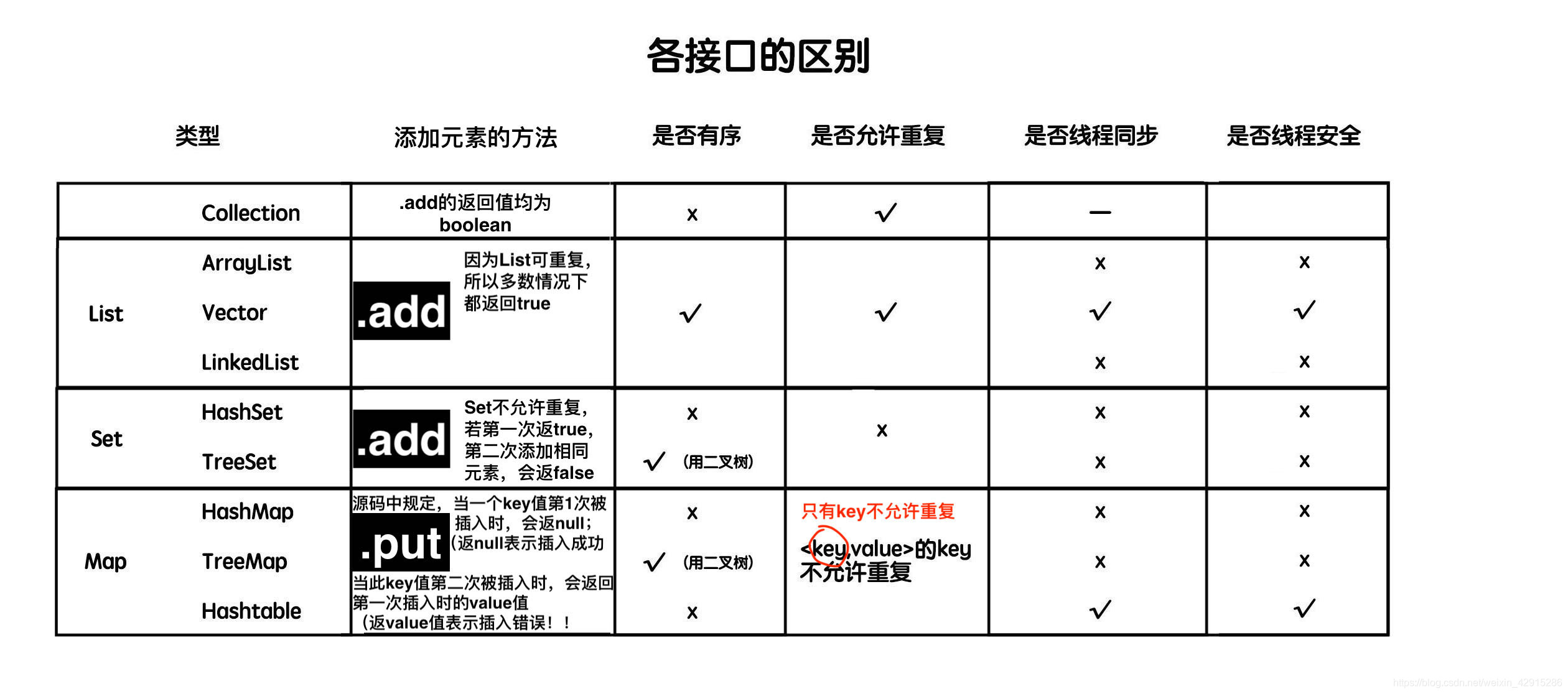
———————————————
注意:
因为ArrayList底层是数组,所以查询快,增删慢;而LinkedList底层是链表,所以反过来;
Map中只有Hashtable允许key和value为null,其他都不允许;
提问:Java中的集合类包括ArrayList、LinkedList、HashMap等类,下列关于集合类描述错误的是?
A.ArrayList和LinkedList均实现了List接口
B.ArrayList的访问速度比LinkedList快
C.添加和删除元素时,ArrayList的表现更佳
D.HashMap实现Map接口,它允许任何类型的键和值对象,并允许将null用作键或值
答:
C
———————————————
Map是Java中的接口,而Map.Entry是Map的一个内部接口(内部类);
Entry:是Map实现类的内部类 / 接口;
此接口为泛型,定义为Entry;它表示Map中的一个实体(表示一个key-value对);
(而Map实际上就是多个Entry的集合)
由于Map中存放的元素均为键值对,故每一个键值对必然存在一个映射关系;
Map中采用Entry内部类来表示一个映射项,映射项包含Key和Value
接口中有
getKey():
getValue:
Map提供了一些常用方法,如keySet()、entrySet()等方法。
keySet():返回Map中key值的集合;
entrySet():返回一个Set集合,此集合的类型为Map.Entry。
————————————
map.get()
在get中写key值,可以返回对应的value值;
例子:
Map map = new HashMap();
map.put("k","v");
String value = map.get("k");
System.out.println(value);
输出:
v
————————————
提问:keySet()和entrySet()有什么区别?
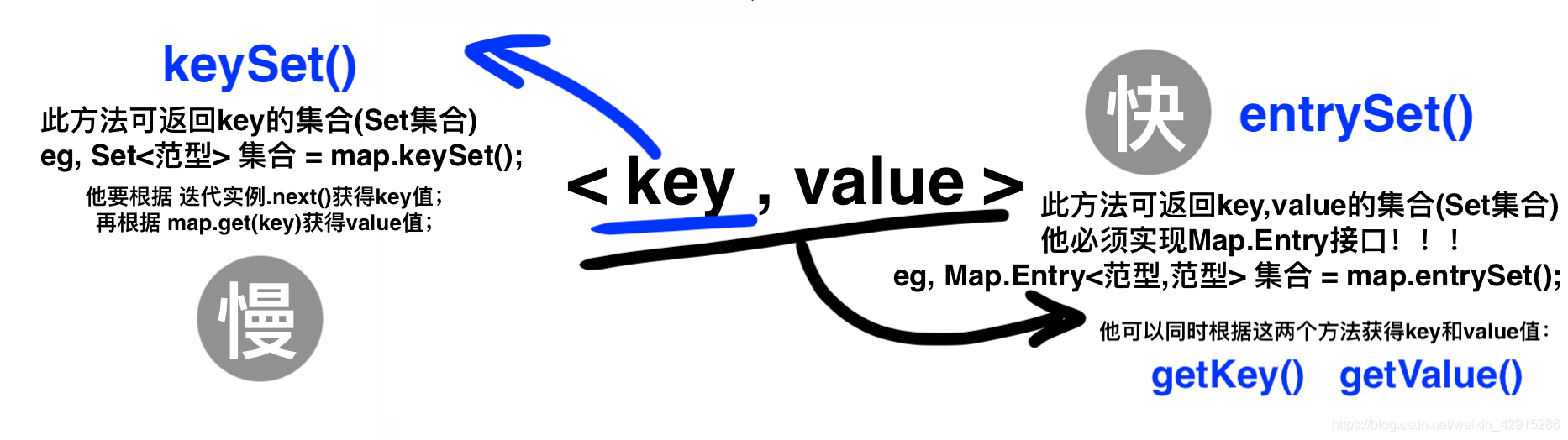
使用他们进行遍历能取得相同的结果;
但两者的遍历速度有差,entrySet()更快,性能更好。
keySet():通过他得到key的Set集合,迭代Set集合后,只能通过.next() 取key;再根据get(key)取value。
entrySet():通过他得到映射关系(key-value对)的Set集合,迭代Set集合后,可通过.next() 取key,value;再根据他直接取.getKey(),.getValue()。
keySet()是key的集合;
entrySet()是 键-值 对的集合,接口类型为Map.Entry(意思是:每一次写范型时都要在前面加上Map.Entry!!!);
Map的entrySet()方法返回一个实现Map.Entry接口的对象集合;
使用entrySet()则必须将map对象转换为Map.Entry;
keySet()则不需要;
map.keySet()
返回HashMap中<key>的集合(Set集合)
例子:通过keySet()返回的key值,输出HashMap中的key和value值;
public class Oh{
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("01", "zhangsan");
map.put("02", "lisi");
map.put("03", "wangwu");
Set<String> keySet = map.keySet(); // 获得key的Set集合
Iterator<String> it = keySet.iterator(); // 迭代key的集合
while (it.hasNext()) { // while it.hasNext()
String key = it.next(); // 定义key
String value = map.get(key); // 定义value // 本人曾经发生过错误:括号里写"key"(加了引号),导致输出的value值为null
System.out.println("key: " + key + "-->value: " + value);
}
}
}
输出:(1s 409ms)
key: 01-->value: zhangsan
key: 02-->value: lisi
key: 03-->value: wangwu
———————————————
map.entrySet()
返回HashMap中Map.Entry类型的<key,value>集合(Set集合)
例子:通过entrySet()返回的键值对,输出HashMap中的key和value值;
(跟上面的例子一个意思)
注意:从用到entrySet()的每一行开始,写范型时都要在前面加上Map.Entry!!!
(注意观察:第3行的范型还没用到entrySet(),不用加上Map.Entry)
public class Oh{
public static void main(String[] args) {
Map<String, String> map = new HashMap<String, String>();
map.put("01", "zhangsan");
map.put("02", "lisi");
map.put("03", "wangwu");
Set<Map.Entry<String, String>> entrySet = map.entrySet();
Iterator<Map.Entry<String, String>> it = entrySet.iterator();
while (it.hasNext()) {
Map.Entry<String, String> a = it.next();
String key = a.getKey();
String value = a.getValue();
System.out.println("key: " + key + "-->value: " + value);
}
}
}
输出:(1s 258ms)
key: 01-->value: zhangsan
key: 02-->value: lisi
key: 03-->value: wangwu
———————————————
范型 Generic(参数化类型)
(原生态类型 对应 参数化类型)
问:写一个排序方法,能够对整型数组、字符串数组甚至其他任何类型的数组进行排序,该如何实现?
答:使用 Java 泛型。
泛型:提供了编译时 类型安全检测机制,该机制允许程序员在编译时检测到非法的类型。
泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。
原生态类型:raw type
即不带任何实际类形参数的范型名称;
如:List<E>的原生态类型是List;
范型出现前,若不小心将一个错误类型插入集合,依然得以编译和运行,无任何错误提示;
然而直到从集合中取出这个错误类型时才会收到错误提示;
ClassCastException只会写:Contains only Stamp instance;
这违背了“出错后应该尽快在编译期就发现的原则”;
范型出现后,编译器通过声明可明确告知哪里出错了;
请不要在新代码中使用原生态类型;
(原生态类型 对应 参数化类型)
若使用原生态类型,就失去了范型在安全性和表述性方面的所有优势;
但由于移植兼容性(过去十年有大量代码使用原生态类型,Java仍需要对他们加以支持),促成了原生态类型的合法性;
——————
那么,List和List<Object>有区别吗?
虽然不应该在新代码中使用List这样的原生态类型,但List<Object>还是可以的;
前者逃避了范型检查,后者就明确告知了编译器他能持有任意类型的对象;
因为有范型有子类型化 subtyping 的规则:
比如:List<String>是原生态类型List的一个子类型,而不是List<Object>的子类型;
因此,List<String>可以传给List,但不能把他传给类型List<Object>的参数;
所以,用List这样的原生态类型会丧失类型安全性,但List<Object>这样的参数化类型则不会;
——————
多线程 Multithreading
通俗地说:
进程:比如IDEA或者QQ的运行,是程序(任务)的执行过程,持有资源(共享内存、共享文件)和线程;
(说明是动态性的,单个文件并不是进程,只有点击文件使程序运行后才发生进程)
(进程是资源、线程的载体,脱离了线程谈进程无意义)
线程:比如QQ中的“文字聊天”“收发文件”,所有这些人物都可以理解为线程;
线程的交互:互斥与同步;比方说进程是班级,线程是学生,学生沟通就是线程,学生之间有时需要合作(同步)才能达到目的,有时需要竞争(互斥)才能达到目的;
————————
面试提问:线程的五个状态?
新建、就绪、运行、阻塞、死亡
————————
Java对线程的支持体现在:
Thread类 和 Runnable接口 之上,他们都继承于java.lang包;
他们之间共通的方法是run(),此方法为我们提供了线程执行的代码;
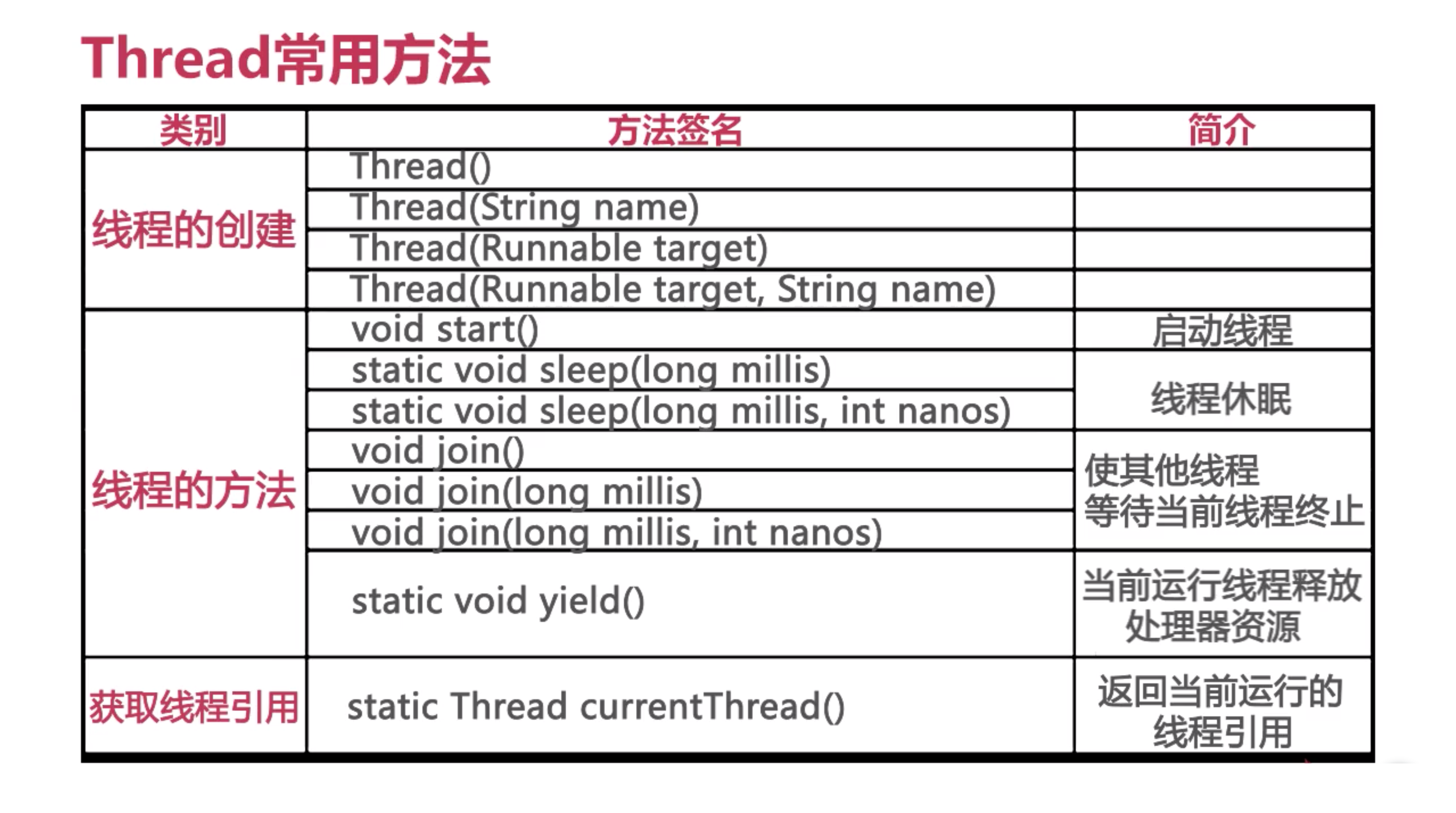
————————
————————
————————
并行 Parallel:一边吃饭一边接电话;强调 “同时” 处理多任务;
并发 Concurrent:饭吃一半,先接电话,接完电话接着吃饭;强调可处理 “多任务” ,而不强调一定要同时。
并行 Parallel:多个CPU实例或者多台机器同时执行一段处理逻辑,是真正的同时。
并发 Concurrent:通过CPU调度算法,让用户看上去同时执行,实际上从CPU操作层面不是真正的同时。并发往往在场景中有公用的资源,那么针对这个公用的资源往往产生瓶颈,我们会用TPS或者QPS来反应这个系统的处理能力。
多线程:指的是这个程序(一个进程)运行时产生了不止一个线程;
线程安全:经常用来描绘一段代码。指在并发的情况之下,该代码经过多线程使用,线程的调度顺序不影响任何结果。这个时候使用多线程,我们只需要关注系统的内存,CPU是不是够用即可。反过来,线程不安全就意味着线程的调度顺序会影响最终结果。
阻塞与非阻塞
同步异步是数据通信的方式,阻塞和非阻塞是一种状态。
比如同步这种数据通讯方式里面可以有阻塞状态也可以有非阻塞状态。从另外一个角度理解同步和异步,就是如果一个线程干完的事情都是同步,有线程切换才能干完的事情就是异步。
————————
————————————————
面试提问:run() 和 start() 有什么区别?
只有调用线程类的start()才能异步调用run(),真正达到多线程的目的;
直接调用run()是同步的,无法达到多线程的目的;
系统调用start()来启动一个线程,此线程现在处于就绪状态,而非运行状态,意味着这个线程可以被JVM调度执行;调度过程中,JVM通过调用run()方法来完成实际的操作,当run()结束后,改哦线程就会终止;
当直接调用线程类的run(),这会被当作一个普通函数调用,程序中只有一个线程;
————————————————
面试提问:sleep() 和 wait() 有什么区别?
- 1.原理不同:
sleep是Thread的静态类方法,线程控制自身,可以设定时间,时间一到自动苏醒;
wait来自Object,也可设置苏醒时间,用于通信; - 2.使用区域不同:
sleep随便;
wait由于本身特殊性,只能在同步语句块/同步方法内使用; - 3.锁的处理机制不同:
sleep不涉及通信,所以不会释放锁;
wait涉及通信,启用后,锁会释放,线程所在对象的其他synchronized数据会被其他线程使用;
提问:关于线程的说法,正确的是?
A. sleep执行时会释放对象锁;
B. wait执行时会释放对象锁;
C. sleep必须写在同步方法或同步块中;
D. wait必须写在同步方法或同步块中;
答:
BD
————————————————
提问:什么叫线程安全?
线程安全就是限制(通常是让请求排队)多个线程同时修改共享数据,从而保证数据的一致性或数据的正确性。
————————————————
面试提问:synchronized关键字的用法?
synchronized可以修饰普通方法、静态方法、代码块;
锁定的对象分别是:当前实例,当前Class实例,synchronized括号里包起来的实例。
当一个线程试图访问同步代码块时,它首先必须得到锁,如果锁被别的线程占用,则该线程会被阻塞直到别的线程释放锁。
synchronized可重入锁,假设synchronized方法1与synchronized方法2锁定的是同一个实例,则同一线程在synchronized方法1中调用synchronized方法2是可以拿到锁的。
但是为什么我们在日常使用中很少用来直接修饰静态方法、或者类呢?
当synchronized用来修饰静态方法或者类时,将会使得这个类的所有对象都是共享一把类锁,导致线程阻塞,所以这种写法一定要规避;
无论synchronized关键字加在方法上还是对象上,如果它作用的对象是非静态的,则它取得的锁是对象;
如果synchronized作用的对象是一个静态方法或一个类,则它取得的锁是对类,该类所有的对象同一把锁。
每个对象只有一个锁(lock)与之相关联,谁拿到这个锁谁就可以运行它所控制的那段代码。
实现同步是要很大的系统开销作为代价的,甚至可能造成死锁,所以尽量避免无谓的同步控制。
————————————————
提问:下列哪个方法可以创建一个可运行的类?
A.public class X implements Runnable {public void run(){......}}
B.public class X implements Thread {public void run(){......}}
C.public class X implements Runnable {public int run(){......}}
D.public class X implements Runnable {protected void run(){......}}
————————————————
答:
AD
- 使用
ExecutorService、Callable、Future实现有返回结果的多线程;(有返回值)
注意!当需要实现多线程时,一般推荐使用Runnable接口的方式,原因:
Thread类定义了很多种方法可以被派生类使用或重写,但只有run()方法必须被重写,在run()方法中实现这个现成的主要功能;
很多Java开发者认为,一个类仅在他们需要被加强或修改时才会被继承;
因此,若没有必要重写Thread类中其他方法,那么通过继承Thread的实现方式和实现Runnable接口的效果相同,在这种情况下最好通过实现Runnable接口的方式来创建线程。
————————
提问:start()和run()有什么区别?
start()是异步,run()是同步;
用start()启动线程代表线程处于就绪状态,不是运行状态;调度过程中用run()来完成实际的操作,他结束后,该线程就会终止;
若直接用run(),就会被当作一个普通函数调用,无法到达多线程的目的;
例子:
class ThreadDemo extends Thread{
@Override
public void run(){
System.out.println("ThreadDemo:begin");
try{
Thread.sleep(1000);
}catch(InterruptedException e){
e.printStackTrace();
}
System.out.println("ThreadDemo:end");
}
}
public class Test{
public static void test1(){
System.out.println("test1:begin");
Thread t1 = new ThreadDemo();
t1.start();
System.out.println("test1:end");
}
public static void test2(){
System.out.println("test2:begin");
Thread t1 = new ThreadDemo();
t1.run();
System.out.println("test2:end");
}
public static void main(String[] args){
test1();
System.out.println();
test2();
}
}
结果:
test1:begin
test1:end
ThreadDemo:begin
ThreadDemo:end
test2:begin
ThreadDemo:begin
ThreadDemo:end
test2:end
说明test1:end不需要等到t1.start();运行就能执行;因此,在test1 中调用start()方法,是异步的;
相反,run()是同步的。
————————
提问:sleep()和wait()有什么区别?
都是指让线程暂停执行一段时间;
区别:
1.原理不同
sleep() 是Thread类的静态方法,线程用来控制自身,他让当前线程暂停,把执行机会让给别人,等到计数时间一到,此线程会自动苏醒;
例如sleep(1000)让自己每隔1s执行一次,该过程如同闹钟一样;
wait()是Object类的方法,用于线程中的通信,此方法会让当前拥有该对象锁的进程等待,直到其他线程调用notify()或notifyAll()时才醒来(开发人也可以给他指定一个时间自动苏醒:wait(long));
2.对锁的处理机制不同
sleep() 由于他的方式是让线程暂停执行一段时间,时间一到自动回复,不涉及到下线程间的通讯,所以它不会释放锁;
wait()不同,调用他后,会释放他所占用的锁,从而使线程所在对象中其他synchronized数据可以被其他线程使用。
比方:sleep让人每隔10s用遥控器换一次台,期间遥控器一直在他手上;
3.使用区域不同
sleep()随便哪里都能用;
wait()他有特殊意义,只能在同步控制方法或同步语句块中使用;
sleep() 必须捕获异常;
wait() 和notify()不需要捕获异常;
————————
提问:join()的作用是什么?
让调用该方法的线程在执行完run()后,再执行join()后的代码;
就是将两个线程合并,用于实现同步功能;
具体而言:比如可以通过线程A的join()方法来等待线程A的结束,或者使用线程A的join(2000)方法来等待线程A的结束,但最多只等待2秒:
class ThreadImp implements Runnable{
public void run(){
try{
System.out.println("Begin ThreadImp");
Thread.sleep(5000);
System.out.println("End ThreadImp");
}catch(InterruptedException e){
e.printStackTrace();
}
}
}
public class JoinTest{
public static void main(String[] args){
Thread t = new Thread(new ThreadImp());
t.start();
try{
t.join(1000);
if(t.isAlive()){
System.out.println("t has not finished");
}else{
System.out.println("t has finished");
}
System.out.println("JoinFinished");
}catch(IntteruptedException e){
e.printStackTrace();
}
}
}
————————
什么情况下 Java 程序会产生死锁?如何定位、修复?
死锁是一种特定的程序状态;
在实体之间,由于循环依赖导致彼此一直处于等待之中,没有任何个体可以继续前进。死锁不仅仅是在线程之间会发生,存在资源独占的进程之间同样也可能出现死锁。
通常来说,我们大多是聚焦在多线程场景中的死锁,指两个或多个线程之间,由于互相持有对方需要的锁,而永久处于阻塞的状态。
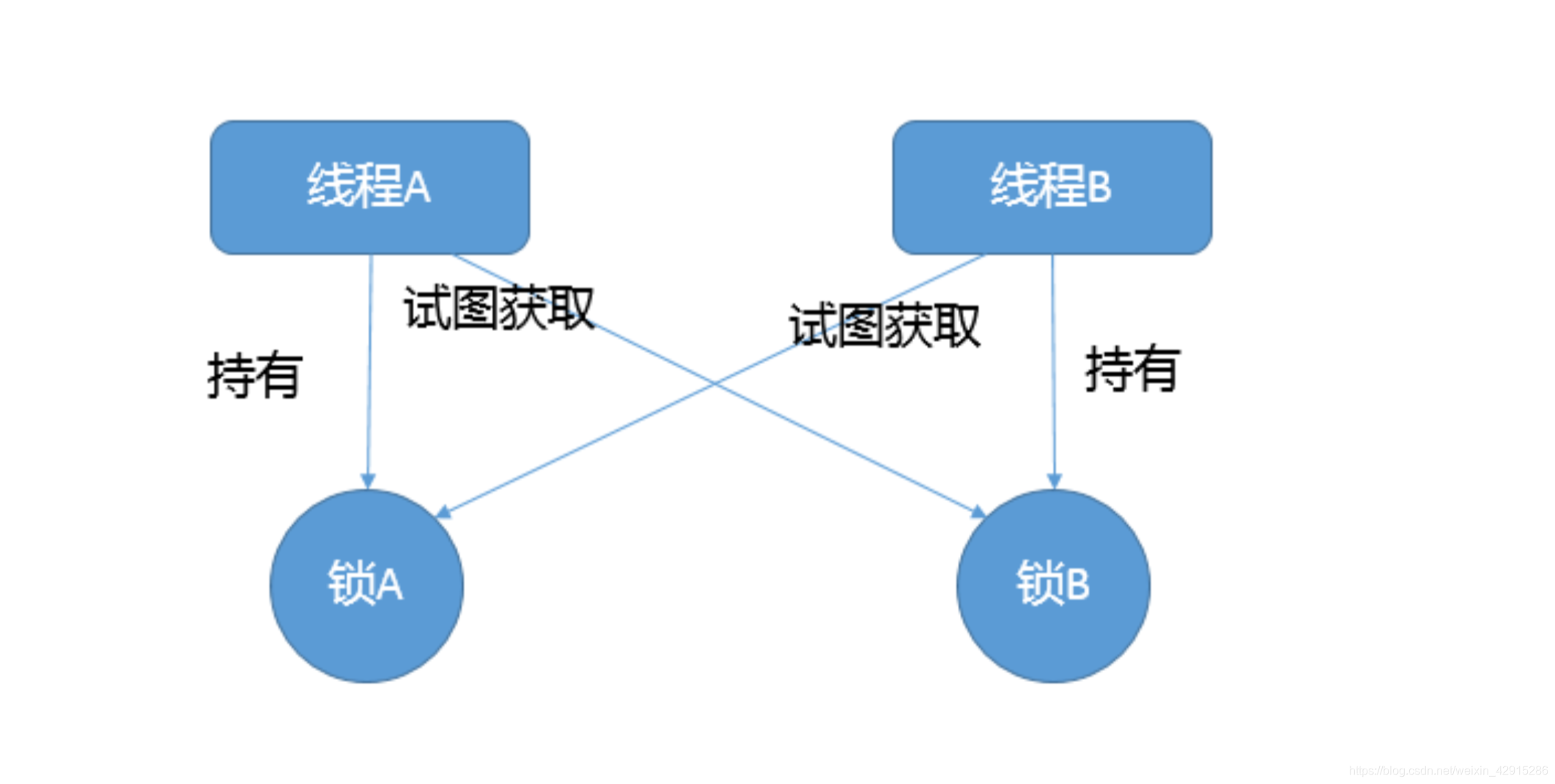
定位死锁最常见的方式就是利用jstack等工具获取线程栈,然后定位互相之间的依赖关系,进而找到死锁。
https://www.jianshu.com/p/025cb069cb69
如果是比较明显的死锁,往往 jstack 等就能直接定位,类似JConsole甚至可以在图形界面进行有限的死锁检测。
如果程序运行时发生了死锁,绝大多数情况下都是无法在线解决的,只能重启、修正程序本身问题。
所以,代码开发阶段互相审查,或者利用工具进行预防性排查,往往也是很重要的。
————————
提问:一个线程两次调用start()方法会出现什么情况?谈谈线程的生命周期 和状态转移。
Java 的线程是不允许启动两次的,第二次调用必然会抛出IllegalThreadStateException,这是 一种运行时异常,多次调用 start 被认为是编程错误。
关于线程生命周期的不同状态,在 Java 5 以后,线程状态被明确定义在其公共内部枚举类型 java.lang.Thread.State中,分别是:
- 新建(NEW),表示线程被创建出来还没真正启动的状态,可以认为它是个 Java 内部状 态。
- 就绪(RUNNABLE),表示该线程已经在 JVM 中执行,当然由于执行需要计算资源,它可 能是正在运行,也可能还在等待系统分配给它 CPU 片段,在就绪队列里面排队。
在其他一些分析中,会额外区分一种状态 RUNNING,但是从 Java API 的角度,并不能表示 出来。 - 阻塞(BLOCKED),这个状态和我们前面两讲介绍的同步非常相关,阻塞表示线程在等待 Monitor lock。比如,线程试图通过 synchronized 去获取某个锁,但是其他线程已经独占了,那么当前线程就会处于阻塞状态。
- 等待(WAITING),表示正在等待其他线程采取某些操作。一个常见的场景是类似生产者消 费者模式,发现任务条件尚未满足,就让当前消费者线程等待(wait),另外的生产者线程 去准备任务数据,然后通过类似
notify等动作,通知消费线程可以继续工作了。Thread.join()也会令线程进入等待状态。 - 计时等待(TIMED_WAIT),其进入条件和等待状态类似,但是调用的是存在超时条件的方 法,比如 wait 或 join 等方法的指定超时版本,如下面示例:
public final native void wait(long timeout) throws InterruptedException; - 终止(TERMINATED),不管是意外退出还是正常执行结束,线程已经完成使命,终止运 行,也有人把这个状态叫作死亡。
在第二次调用 start() 方法的时候,线程可能处于终止或者其他(非 NEW)状态,但是不论如 何,都是不可以再次启动的。
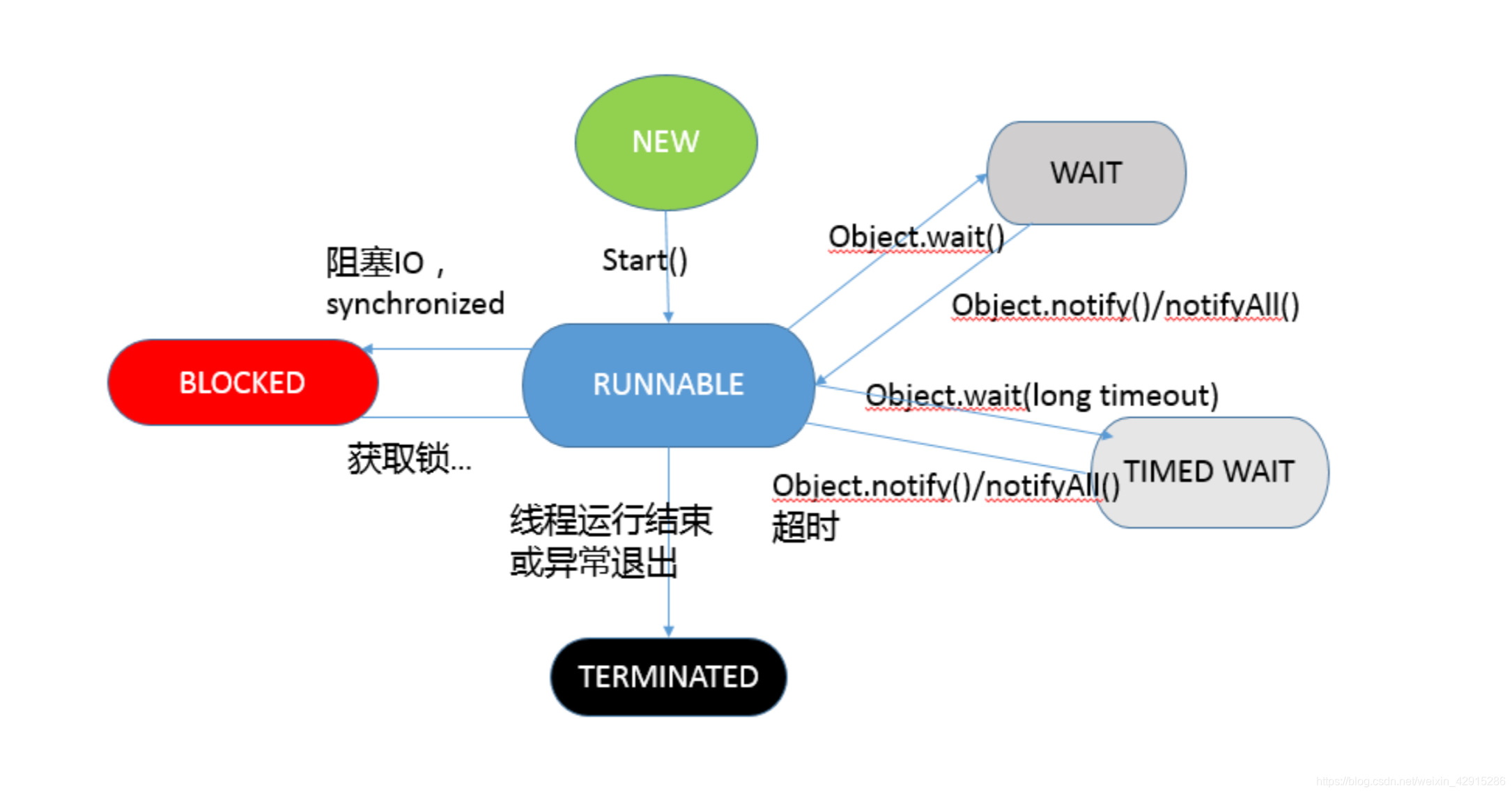
————————
Java的2种锁用法:同步锁 synchronized和异步锁 Lock
1.同步锁:synchronized
用法:可以在代码中使用,也可以用来修饰函数;
特性是:同一时间内,只有一个拥有锁的线程才能运行。
synchronized (obj) {
while (<condition does not hold>)
obj.wait();
... // Perform action appropriate to condition
}
常用方法:
obj:锁对象;
obj.wait() :暂停、等待;调用后,该线程会释放同步锁obj对象,并使进程处于等待状态;
obj.notify():唤醒;调用后将唤醒等待obj锁对象的线程队列中的第一个线程。唤醒等待该锁的线程队列中的第一个线程,并且当前进程释未释放锁,得在当前线程中需调用wait释放锁,使当前进程等待,唤醒的线程才可以执行,否则就等待线程释放它等待的锁;
obj.notifyAll():唤醒全部;调用后唤醒等待obj对象的线程队列中的所有线程,谁得到了线程释放的锁谁就运行;
sleep():是当前线程休眠指定的时间;
stop():终止线程;
suspend():将一个线程挂起(暂停),且不会自动恢复;必须通过resume()方法,才能让线程重新进入可执行状态;
():;
2.异步锁 Lock
————————
提问:多线程同步有几种实现方法?
使用多线程访问同一个资源时,非常容易出现线程安全的问题(例如,当多个线程同时对一个数据进行修改时,会导致某些线程对数据的修改丢失)。因此,需要采取同步机制来解决这种问题,Java提供了3种实现同步机制的方法:
synchronized关键字
在Java语言中,每个对象都有一个对象锁与之相关联,该锁表明对象在任何时候只允许被一个线程所拥有,当一个线程调用对象的一段synchronized代码时,首先需要获取这个锁,然后去执行相应的代码,执行结束后,释放锁;
synchronized关键字主要有两种方法(synchronized方法和synchronized块),此外该关键字还可以作用于静态方法、类或某个实例,但这都对程序的效率有很大的影响。
(1).synchronized方法:在方法声明前加入synchronized关键字,如:
public synchronized void multiThreadAccess();
只要把多个线程访问的资源的操作放到multiThreadAccess()方法中,就能保证这个方法这个方法在同一时刻只能被一个线程访问,从而保证了多个线程访问的安全性。 然而,当一个方法的方法体规模非常大时,把该方法声明为synchronized会大大影响程序的执行效率。 为了提高程序的执行效率,Java提供了synchronized块;
(2).synchronized块:可以把任意代码段声明为synchronized,也可以指定上锁的对象,有非常高的灵活性:
synchronized(syncObject){ ...wait和notify
当使用synchronized来修饰某个共享资源时,如果线程A1在执行synchronized代码,另外一个线程A2也要同时执行同一对象的同一synchronized代码时,线程A2将要等到线程A1执行完后,才能继续执行。在这种情况下,可以使用wait方法和notify方法;
在synchronized代码被执行期间,线程可以调用对象的wait方法,释放对象锁,进入等待状态,并且可以调用notify方法或notifyAll方法通知正在等待的其他线程,notify方法仅唤醒一个线程(等待排列中的第一个线程),并允许他去获得锁,而notifyAll方法唤醒所有等待这个对象的线程,并允许他们去竞争锁(不是让所有唤醒线程都获得锁,而是让他们去竞争)- .
Lock
Java中有Lock接口和他的一个实现类ReentrantLock(重入锁:是一种递归无阻塞的同步机制);Lock也可用来实现多线程的同步,具体而言,它提供了如下方法来实现多线程的同步:
(1).lock()以阻塞的方式来获得锁,也就是说如果获得了锁则立即返回,若有其他线程持有锁,当前线程等待,直到获取锁后返回;
(2).tryLock()以非阻塞的方式获得锁,只是尝试性地去获取一下锁,如果获取到锁,则立即返回true,否则立即返回false;
(3).tryLock(long timeout,TimeUnit unit)如果获取了锁,立即返回true,否则会等待参数给定的时间单元,在等待的过程中,如果获取了锁,就返回true,如果等待超时,则返回false;
(4).lockInterruptibly如果获取了锁,则立即返回,如果没有获取锁,则当前线程处于休眠状态,直至获得锁,或者当前线程被其他线程中断(会收到InterreptedException异常)。他与lock()方法最大的区别在于:如果lock()方法获取不到锁,则会一直处于阻塞状态,且会忽略interrupt()方法。
————————
提问:多线程编程时,有哪些注意事项?
多线程编程非常重要,操作时需要注意 1.避免死锁 2.如何提高多线程并发情况下的性能
- 若能用
volatile代替synchronized,尽可能用volatile。因为被synchronized修饰的方法或代码在同一时间内只允许一个线程访问,而volatile却没有这个限制,因此使用synchronized会降低并发亮。由于synchronized无法保证源自操作,因此在多线程的情况下,只有对变量的操作为源自操作的情况下才可以使用volatile; - 尽可能减少
synchronized块内的代码,只把临界区的代码放到synchronized块中,尽量避免用synchronized来修饰整个方法; - 尽可能给每一个线程都定义一个线程的名字,不要使用匿名线程,这样有利于调试;
- 尽可能用concurrent容器(
ConcurrentHashMap)来替代synchronized容器(Hashtable)。因为synchronized容器使用synchronized关键字通过对整个容器加锁来实现多线程安全,性能比较低。而ConcurrentHashMap采用了更加细粒度的锁,因此可以支持更高的并发量; - 使用线程池来控制多线程的执行。
提问:volatile能否保护线程安全?
不能
它保护的是变量安全。主要的功能是保护变量不被主函数和中断函数反复修改造成读写错误。
————————
提问:Java中有几种方法终止线程运行?
为什么不推荐使用stop()和suspend()?
错误的方法:stop(),他是Java1.0中出现的方法,但是随着时间的推进,人们发现他越来越不适合来停止线程;因为它会让线程戛然而止,程序员会不知道线程完成了什么,那些工作还没有做,也无法进行清理工作。
什么叫戛然而止?代码运行后,输出中没有明确的结束代码,让程序员不好找到合适的位置进行判断;或者程序进行中单被强行关闭。
Java中可以使用stop()和suspend()来终止线程的执行;
当使用Thread.stop()时,他会释放已经锁定的所有监视资源;如果当前任何一个受这些监视资源保护的对象处于一个不一致的状态,其他线程将会看到这个不一致的状态,这可能导致程序执行的不确定性,并且这种问题很难被定位;
当使用suspend()时,容易引起死锁;由于调用suspend()不会释放锁,这就会导致一个问题:如果使用一个suspend()挂起一个有锁的线程,那么在锁恢复之前将不会被释放;如果使用suspend()方法的线程试图取得相同的锁,程序就会发生死锁。
那么如何终止线程?一般建议让线程自行结束,进入Dead(死亡)状态。
网上还有一种广为流传的说法:用thread的interrupt()方法,是错误的;
原因是interrupt()方法初衷不是用于停止线程;查阅JavaAPI得知,interrupt()是中断,会让interrupt状态被清除,无法用于后面的isInterrupt()方法和让当前线程收到一个InterruptedException
正确退出方法:使用退出标志;
可以写线程名.keepRunning = false;
————————
————————
————————
————————
————————
强引用、软引用、弱引用、虚引用
在Java语言中,除了基本数据类型外,其他的都是指向各类对象的对象引用;Java中根据其生命周期的长短,将引用分为4类。
强引用 Strong Reference:项目中到处都是;通过关键字new创建的对象所关联的引用就是强引用,如我们平常典型编码Object obj = new Object()中的obj就是强引用;当JVM内存空间不足,JVM宁愿抛出OutOfMemory Error运行时错误(OOM),使程序异常终止,也不会靠随意回收具有强引用的“存活”对象来解决内存不足的问题。对于一个普通的对象,如果没有其他的引用关系,只要超过了引用的作用域或者显式地将相应(强)引用赋值为null,就是可以被垃圾收集的了,具体回收时机还是要看垃圾收集策略。软引用 Soft Reference:图片缓存框架中,“内存缓存”中的图片是以这种引用来保存,使得JVM在发生OOM之前,可以回收这部分缓存;软引用通过Soft Reference类实现。 软引用的生命周期比强引用短一些。只有当 JVM 认为内存不足时,才会去试图回收软引用指向的对象:即JVM 会确保在抛出OutOfMemory Error之前,清理软引用指向的对象。软引用可以和一个引用队列(ReferenceQueue)联合使用,如果软引用所引用的对象被垃圾回收器回收,Java虚拟机就会把这个软引用加入到与之关联的引用队列中。后续,我们可以调用ReferenceQueue的poll()方法来检查是否有它所 关心的对象被回收。如果队列为空,将返回一个null,否则该方法返回队列中前面的一个Reference对象;
应用场景:软引用通常用来实现内存敏感的缓存。如果还有空闲内存,就可以暂时保留缓存,当内存不足时清理掉,这样就保证了使用缓存的同时,不会耗尽内存;弱引用 Weak Reference:
弱引用通过WeakReference类实现。 弱引用的生命周期比软引用短。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。由于垃圾回收器是一个优先级很低的线程,因此不一定会很快回收弱引用的对象。弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果弱引用所引用的对象被垃圾回收,Java虚拟机就会把这个弱引用加入到与之关联的引用队列中。
应用场景:弱引用同样可用于内存敏感的缓存。幻象引用(幽灵引用/虚引用):
虚引用通过PhantomReference类来实现。无法通过虚引用访问对象的任何属性或函数。幻象引用仅仅是提供了一种确保对象被finalize以后,做某些事情的机制。如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收器回收。虚引用必须和引用队列 (ReferenceQueue)联合使用。当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之关联的引用队列中。
ReferenceQueue queue = new ReferenceQueue ();
PhantomReference pr = new PhantomReference (object, queue);程序可以通过判断引用队列中是否已经加入了虚引用,来了解被引用的对象是否将要被垃圾回收。如果程序发现某个虚引用已经被加入到引用队列,那么就可以在所引用的对象的内存被回收之前采取一些程序行动。
应用场景:可用来跟踪对象被垃圾回收器回收的活动,当一个虚引用关联的对象被垃圾收集 器回收之前会收到一条系统通知。
白话:
强引用就像大老婆,关系很稳固;
软引用就像二老婆,随时有失宠的可能,但也有扶正的可能;
弱引用就像情人,关系不稳定,可能跟别人跑了。;
幻像引用就是梦中情人,只在梦里出现过。
在 Java 语言中,除了原始数据类型的变量,其他所有都是所谓的引用类型,指向各种不同的对象,理解引用对于掌握 Java 对象生命周期和 JVM 内部相关机制非常有帮助。
提问:强引用、软引用、弱引用、幻象引用有什么区别?具体使用场景是什
么?
不同的引用类型,主要体现的是对象不同的可达性(reachable)状态和对垃圾收集的影响。
所谓 强引用 Strong Reference ,就是我们最常见的普通对象引用,只要还有强引用指向 一个对象,就能表明对象还“活着”,垃圾收集器不会碰这种对象。对于一个普通的对象,如果没有其他的引用关系,只要超过了引用的作用域或者显式地将相应(强)引用赋值为 null,就是可以被垃圾收集的了,当然具体回收时机还是要看垃圾收集策略。
软引用 Soft Reference,是一种相对强引用弱化一些的引用,可以让对象豁免一些垃圾收 集,只有当 JVM 认为内存不足时,才会去试图回收软引用指向的对象。JVM 会确保在抛出 OutOfMemoryError之前,清理软引用指向的对象。软引用通常用来实现内存敏感的缓存,如果还有空闲内存,就可以暂时保留缓存,当内存不足时清理掉,这样就保证了使用缓存的同时, 不会耗尽内存。
弱引用 Weak Reference 并不能使对象豁免垃圾收集,仅仅是提供一种访问在弱引用状态下对象的途径。这就可以用来构建一种没有特定约束的关系,比如,维护一种非强制性的映射关系,如果试图获取时对象还在,就使用它,否则重现实例化。它同样是很多缓存实现的选择。
对于 幻象引用 ,有时候也翻译成虚引用,你不能通过它访问对象。幻象引用仅仅是提供了一种确保对象被finalize以后,做某些事情的机制,比如,通常用来做所谓的Post-Mortem清理机制,Java 平台自身Cleaner机制等,也有人利用幻象引用监控对象的创建和销毁。
注: 这道面试题,属于既偏门又非常高频的一道题目。
Android开发面试中这道题大家基本都会,Java后端面试中遇到好些人说没听过的,说到底
有部分人还是Java基础不过关,只会用框架。
说它偏门,是因为在大多数应用开发中,很少直接操作各种不同引用,虽然我们使用的类库、框架可能利用了其机制。它被频繁问到,是因为这是一个综合性的题目,既考察了我们对基础概念的理解,也考察了对底层对象生命周期、垃圾收集机制等的掌握。
充分理解这些引用,对于我们设计可靠的缓存等框架,或者诊断应用 OOM 等问题,会很有帮助。比如,诊断MySQL connector-j 驱动在特定模式下(useCompression=true)的内存泄漏问题,就需要我们理解怎么排查幻象引用的堆积问题。
Switch()
易错点!!!
switch()有个重点是,一定要有break用来跳出语句!!
面试提问:结果是?
public class TestCode {
public static int getValue(int i){
int result =0;
i = 2;
switch(i){
case 1:
result = result +1;
case 2:
result = result + i*2;
break;
case 3:
result = result + i*3;
}
return result;
}
public static void main(String[] args) {
TestCode testCode = new TestCode();
System.out.println(testCode.getValue(2));
}
}
答:
10
因为没有break,所以进入case2后还会继续到case3,结果为10;
若想只执行case 2的话,需要在case 2下面添加一句:break;
————————————————
提问:switch能否作用在byte、long、String上?
答:
switch可作用于char byte short int以及对应的包装类上;
switch不可作用于long double float boolean,包括他们的包装类
switch可以作用于String(JDK1.7之后)
switch可以作用于枚举类型(JDK1.5之后)
(switch不可作用于 L D B F (沓来BF))
(switch不可作用于 L D B F (沓来BF))
(switch不可作用于 L D B F (沓来BF))
————————————————
提问:break和continue的区别?
1.break
用break语句可以使流程跳出switch语句体,也可以用break语句在循环结构 终止本层循环 ,从而提前结束本层循环。
2.continue
作用是跳过本次循环体中余下尚未执行的语句,进行下一次的循环条件判定 ,可以理解为仅结束本次循环。
注意: continue语句并没有使整个循环终止。
枚举 enum
可用静态常量替代枚举类
比如:
public static final int SEASON_SPRING = 1;
public static final int SEASON_SUMMER = 2;
public static final int SEASON_FALL = 3;
public static final int SEASON_WINTER = 4;
使用常量会有以下几个缺陷:
-
1.类型不安全;
若一个方法中要求传入季节这个参数?
用常量的话,形参配置int类型,开发者传入任意类型的int类型值就行;
但是如果是枚举类型的话,就只能传入枚举类中包含的对象; -
2.没有命名空间;
开发者要在命名的时候以SEASON_开头,这样另外一个开发者再看这段代码的时候,才知道这四个常量分别代表季节;
枚举类
先看一个简单的枚举类。
package enumcase;
public enum SeasonEnum {
SPRING,SUMMER,FALL,WINTER;
}
- 1.enum和class、interface的地位一样;
- 2.使用enum定义的枚举类默认extnds java.lang.Enum,而不是extends Object;枚举类可以实现一个或多个接口;
- 3.枚举类的所有实例都必须放在第一行展示,不需使用new关键字,不需显式调用构造器。自动添加public static final修饰;
- 4.使用enum定义、非抽象的枚举类默认使用final修饰,不可以被继承;
- 5.枚举类的构造器只能是私有的;
枚举类内也可以定义属性和方法,可是是静态的和非静态的;
package enumcase;
public enum SeasonEnum {
SPRING("春天"),SUMMER("夏天"),FALL("秋天"),WINTER("冬天");
private final String name;
private SeasonEnum(String name)
{
this.name = name;
}
public String getName() {
return name;
}
}
实际上在第一行写枚举类实例的时候,默认是调用了构造器的,所以此处需要传入参数,因为没有显式申明无参构造器,只能调用有参数的构造器;
构造器需定义成私有的,这样就不能在别处申明此类的对象了。枚举类通常应该设计成不可变类,它的Field不应该被改变,这样会更安全,而且代码更加简洁。所以我们将Field用private final修饰;
https://blog.youkuaiyun.com/hellojoy/article/details/79883671

















 1879
1879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









