







参考文章
LangChain之Memory
一文入门最热的LLM应用开发框架LangChain
搭建RAG
LLM 接入 LangChain
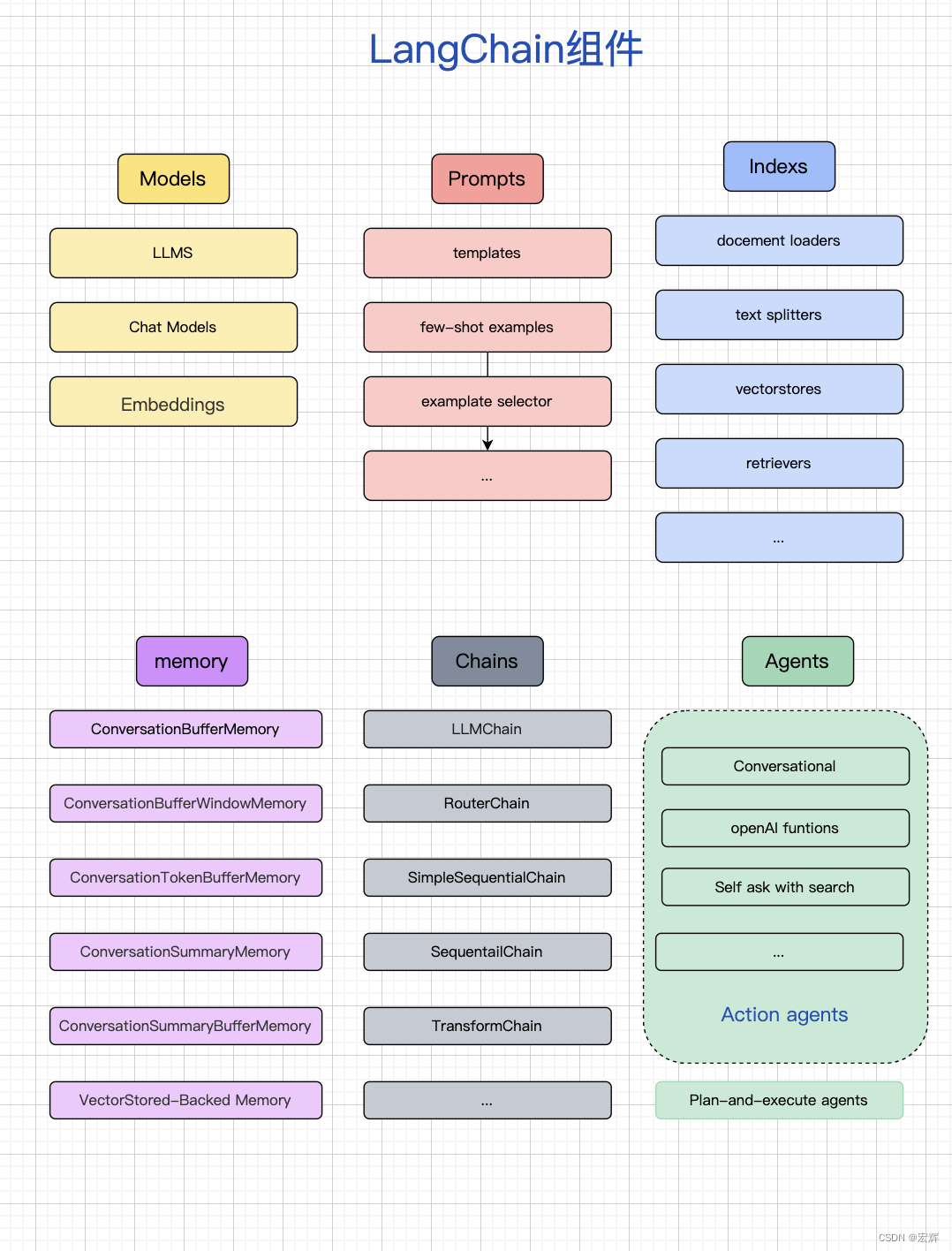
LanhChain的组成
LangChain 包含六部分组成,分别为:Models、Prompts、Indexes、Memory、Chains、Agents。
DataWhale 教程中描述了以下多种LLM的接入方式,LLM接入LangChain教程
-
基于 LangChain 调用 ChatGPT
-
使用 LangChain 调用百度文心一言
-
讯飞星火
-
使用 LangChain 调用智谱 GLM
-
构建检索问答链
本次使用第二节开通的千帆大模型进行调试。
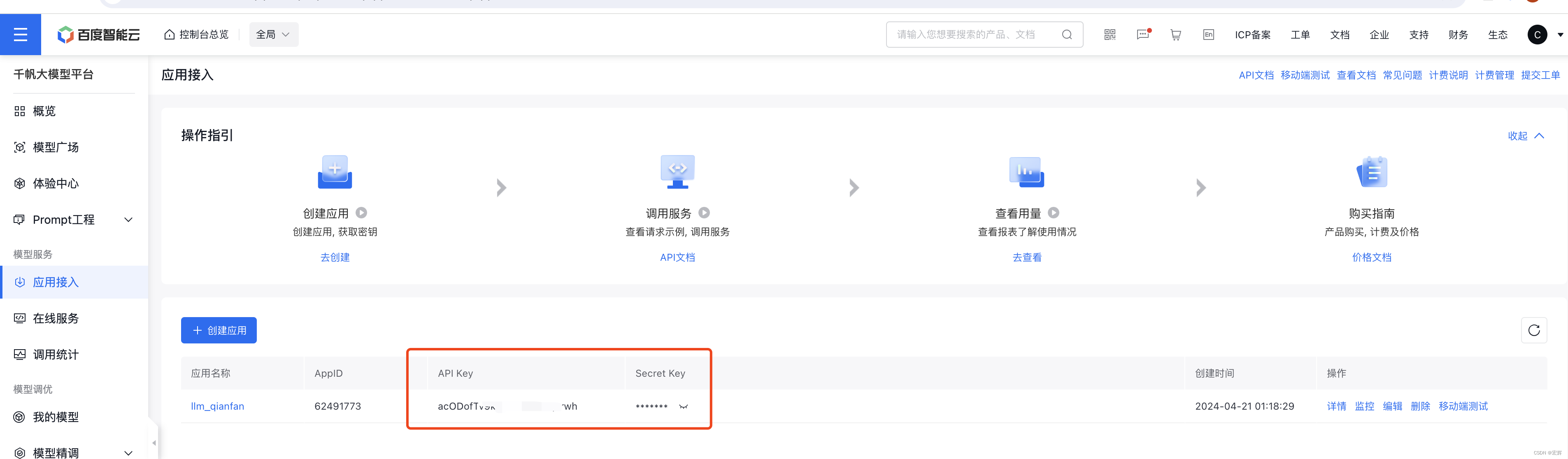
首先通过百度智能云控制台获取应用的API key 和 Secret key,将其填入本次学习工程的.env文件中。
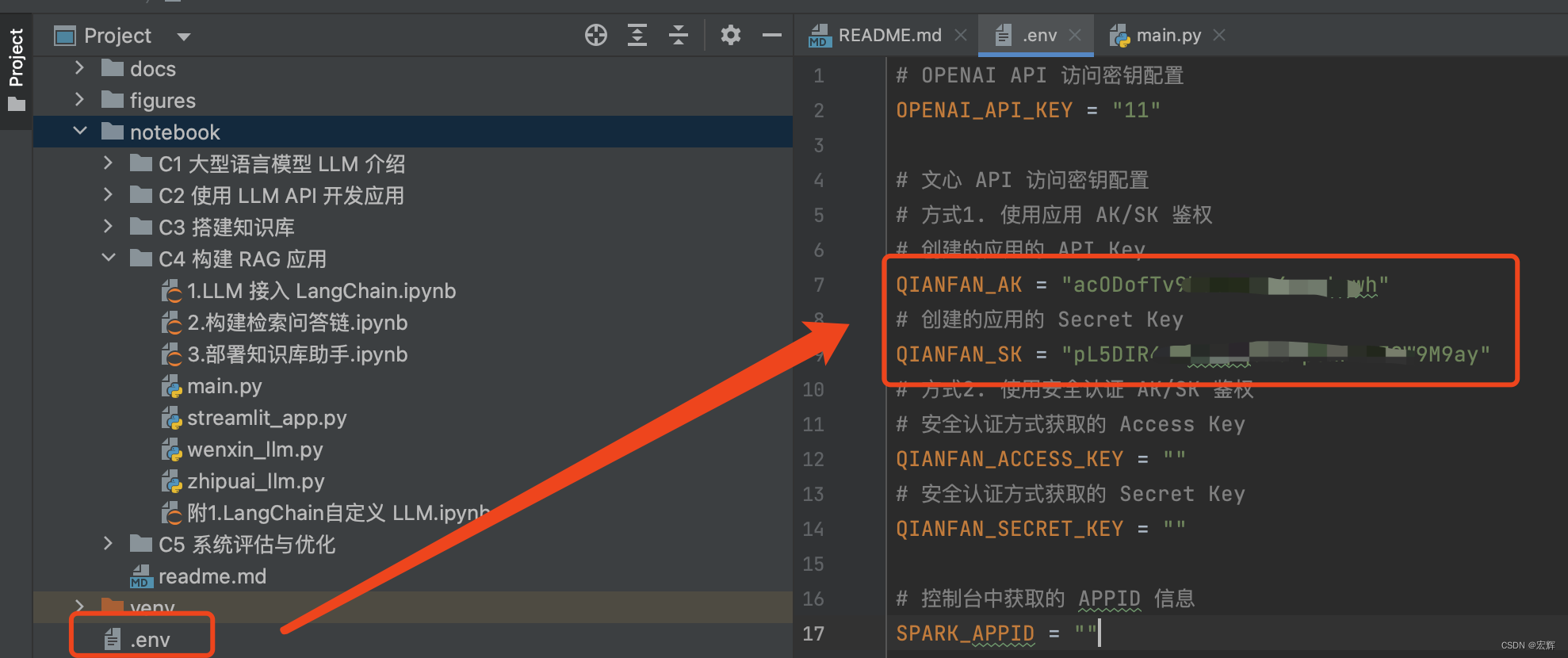
新建一个main.py 调用LLM
import os
from dotenv import load_dotenv, find_dotenv
from wenxin_llm import Wenxin_LLM
from langchain_community.llms import QianfanLLMEndpoint
def main():
print("Hello LLM")
# find_dotenv()寻找并定位.env文件的路径
# load_dotenv()读取该.env文件,并将其中的环境变量加载到当前的运行环境中
# 如果你设置的是全局的环境变量,这行代码则没有任何作用。
_ = load_dotenv(find_dotenv())
wenxin_api_key = os.environ["QIANFAN_AK"]
wenxin_secret_key = os.environ["QIANFAN_SK"]
# 使用个人封装的方法调用LLM
# llm = Wenxin_LLM(api_key=wenxin_api_key, secret_key=wenxin_secret_key, system="你是一个助手!")
# print(llm.invoke("你好,请你自我介绍一下!"))
# 使用langchain兼容的千帆方法进行调用
llm = QianfanLLMEndpoint(streaming=True)
res = llm("你好,请你自我介绍一下!")
print(res)
if __name__ == "__main__":
main()
部署知识库助手
思考
Langchain memory分类
在LangChain中,Memory指的是大语言模型(LLM)的短期记忆。为什么是短期记忆?那是因为LLM训练好之后(获得了一些长期记忆),它的参数便不会因为用户的输入而发生改变。当用户与训练好的LLM进行对话时,LLM会暂时记住用户的输入和它已经生成的输出,以便预测之后的输出,而模型输出完毕后,它便会“遗忘”之前用户的输入和它的输出。因此,之前的这些信息只能称作为LLM的短期记忆。
LangChain提供了如下几种短期记忆管理的方式:BufferMemory、BufferWindowMemory、ConversionMemory、VectorStore-backed Memory等
1.BufferMemory,它是直接将之前的对话,完全存储下来。这样在每一轮新的对话中,都会将原来的所有对话传递给LLM。
2.BufferWindowMemory,它是将最近的K组对话存储下来,这样在每一轮新的对话中将这K组对话传递给LLM。
3.VectorStore-backed Memory,它是将所有之前的对话通过向量的方式存储到VectorDB(向量数据库)中,在每一轮新的对话中,会根据用户的输入信息,匹配向量数据库中最相似的K组对话。
4.ConversionMemory,它是将对话进行时对对话信息进行摘要,并将当前摘要存储在内存中。然后在新一轮对话中,可以将此摘要作为短期记忆传递给LLM。这种方式对于较长的对话非常有用,因为它是相当于压缩了历史的对话信息,能够将做够多的短期记忆发送给LLM。
总结
本节主要是实操内容,将前面三节所学的知识库、model api、langchain组合成一个RAG系统。简单入门了Streamlit框架,尝试发布了自己的第一个RAG应用。
本次学习中发现Langchain居然有memory功能,上一节学习语义知识库时候想到了一个方案:将用户历史聊天记录处理成向量录入向量知识库中,在新的一轮对话中,用户输入新信息会先匹配向量数据库中最相似的K组对话。这个idea就是LangChain已经实现的VectorStore-backed Memory功能!!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









