






 客户端提交MR作业到ResourceManager,资源调度器分配任务到NodeManager执行MapTask和ReduceTask。MRAppMaster协调任务执行,包括MapTask的数据分区和ReduceTask的数据拉取。
客户端提交MR作业到ResourceManager,资源调度器分配任务到NodeManager执行MapTask和ReduceTask。MRAppMaster协调任务执行,包括MapTask的数据分区和ReduceTask的数据拉取。
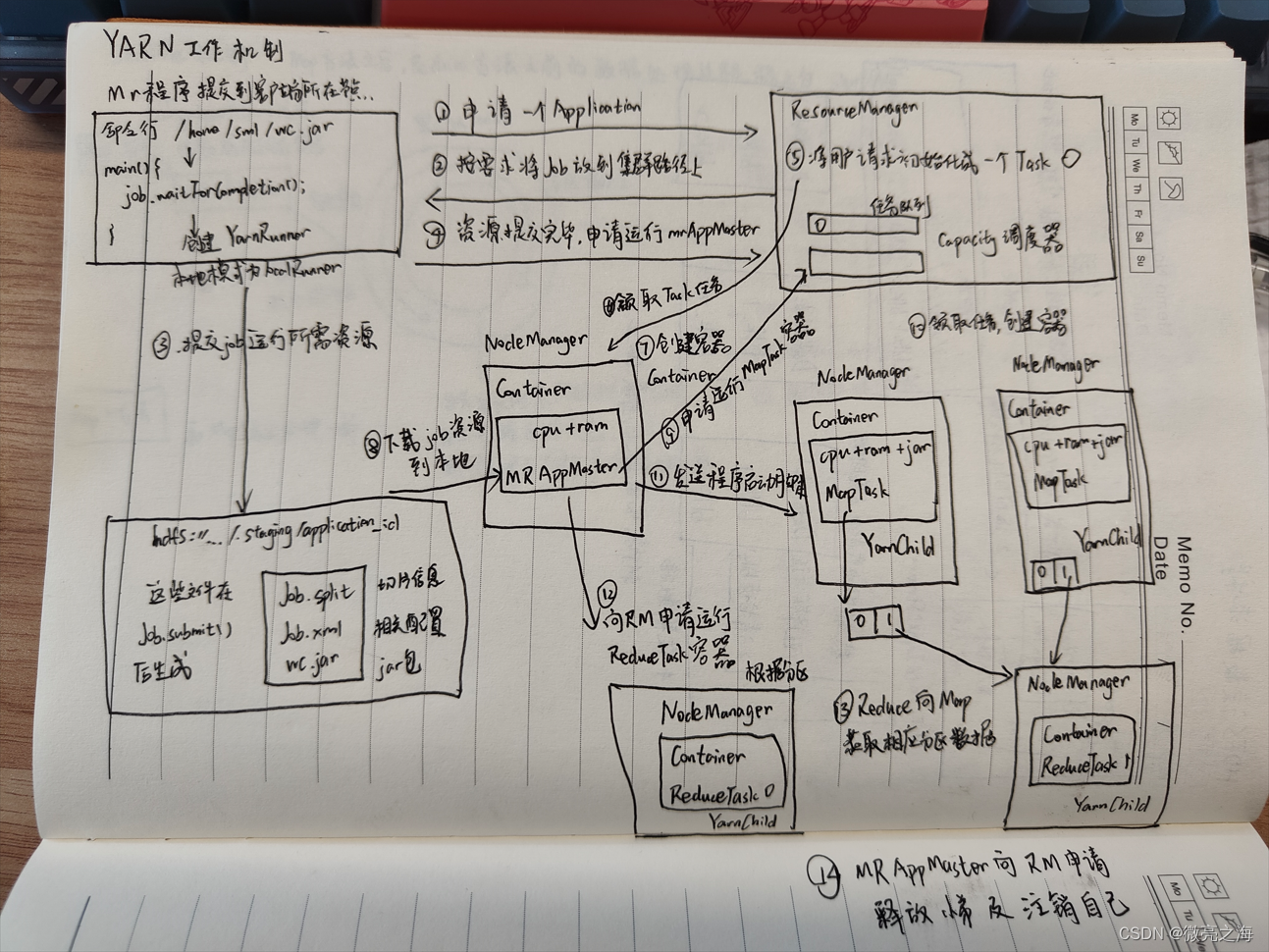
MR程序提交到客户端所在节点,客户端创建yarnRunner
1.客户端向ResourceManager申请一个Application
2.ResourceManager要求客户端将Job放到集群路径上
3.客户端提交job运行所需资源(切片信息Job.split、相关配置Job.xml、jar包wc.jar)
4.资源提交完毕,客户端向ResourceManager申请运行MRAppMaster
5.将用户的请求初始化成一个Task,放进capacity容量调度器(Hadoop3之后的默认资源调度器),容量调度器中有不同的队列,每个队列中采用FIFO先入先出调度器
6.NodeManager从队列中领取Task任务
7.NodeManager创建容器Container运行MRAppMaster
8.MRAppMaster下载客户端提交的job资源到本地
9.MRAppMaster向ResourceManager申请运行MapTask容器
10.其他NodeManager领取任务,创建容器运行MapTask
11.MRAppmaster发送程序运行脚本到运行MapTask容器的NodeManager
12.MRAppmaster向ResourceManager申请运行ReduceTask容器
13.Reduce向Map获取对应分区的数据
14.MRAppmaster向ResourceManager申请释放容器及注销自己
加强记忆,默写一遍
1.客户端向RM申请要在集群上运行一个Application
2.RM返回Application资源提交路径和application_id
3.客户端提交job运行所需资源(切片信息、配置信息、jar包)
4.资源提交完毕后,客户端向RM申请运行job的老大,mrAppMaster
5.然后在RM内部会产生一个任务Task,这些任务会放入队列中,默认的是capacity容量调度器,内部的队列是FIFO先入先出调度队列
6.空闲的NodeManager领取队列中的Task任务,创建容器Container,获取对应的cpu和内存资源,启动mrAppMaster进程
7.mrAppMaster去集群资源路径上下载job资源到本地,拿到切片信息后,向RM申请MapTask容器
8.空闲的NodeManager领取队列中对应的Task任务,创建容器
9.mrAppMaster发送程序启动脚本,启动对应的MapTask,结束后将数据按分区持久化到磁盘
10.mrAppMaster知道MapTask结束后,向RM申请ReduceTask容器
11.空闲的NodeManager领取队列中对应的Task任务,创建容器
12.mrAppMaster发送程序启动脚本,启动对应的ReduceTask,Reduce向Map拉取对应分区的数据
13.mrAppMaster向RM申请释放容器及注销自己

















 9383
9383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









