







 本文介绍了Spark MLlib中向量和矩阵的基本概念及其应用场景,详细讲解了Spark中的本地向量、向量标签、本地矩阵和分布式矩阵,包括它们的创建和使用方法,特别强调了分布式矩阵的四种存储格式:行矩阵、带有索引的行矩阵、坐标矩阵和分块矩阵。
本文介绍了Spark MLlib中向量和矩阵的基本概念及其应用场景,详细讲解了Spark中的本地向量、向量标签、本地矩阵和分布式矩阵,包括它们的创建和使用方法,特别强调了分布式矩阵的四种存储格式:行矩阵、带有索引的行矩阵、坐标矩阵和分块矩阵。
1、概述
Spark早期版本时,MLlib是基于RDD来进行分析的,其使用的是 spark. mllib包。而言2.0版本后,由RDD这种抽象数据结构转换到了基于 dataframe上,其相关API也被封装到了 spark.ml包下。而在 spark MLlib/ML中为了方便数据的整理和分析,将存储数据的格式转化为向量和矩阵进行存储和计算,以便将数据定量化。
1.1 向量和矩阵的概念
向量:类比于数学中的概念,在spark中可以将其理解为由一维数组刻画的数据模型;
矩阵:是由行和列组成的数据类型,是由多组向量构成的,较向量而言计算效率更高。
1.2 向量和矩阵的应用场景
向量:标签向量因其带有标记,常被用在监督学习算法中,如回归( Regression)和分类( Classification)等。
矩阵:以向量为基础,可以用来处理更多的数据,可以应用于回归预测,协同过等算法中。
2、Spark中的使用说明
Spark MLlib使用的数据格式类型是矩阵和向量,而两者又可以分为本地向量,向量标签,本地矩阵,分布式矩阵,其中,分布式矩阵又可以细分为行矩阵,带有索引的行矩阵,坐标矩阵和分块矩阵。
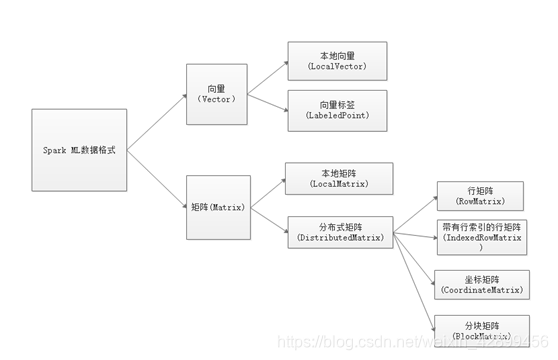
2.1 本地向量(LocalVector)
本地化向量集主要由稀疏型数据集(sparse)和密集型数据集(dense),而两者是基于数组(Array)的向量的顶级接囗是 Vector。两者主要区别如下:
密集型数据集的数值数组中的元素类型为 double类型;
稀疏性数据集的向量格式由索引(下标)数组和数值数组组成,其中,索引的类型为整型,数组元素的类型仍旧为double双精度类型, 密集型数据简而言之就是每个索引位置都有数值,而稀疏型矩阵则是可以只在特定位置有数值。
创建密集型数据集的方式:
//创建一个密集型向量,官方推荐使用Vectors工厂方式创建
Vector v = Vectors.dense(1.0,2.0,3.0);
//第二种创建方
Vector v2 = Vectors.dense(new double[] {1.0, 2.0 3.0});创建稀疏型索引的方式:
//创建一个稀疏型索引,参数一表示向量最多可以存9个数据,参数二表示给定的索引,
//该例中给定的索引是0和2,没有给定1,参数三便是给定的数据,这里的数据是1.0和2.0,
//索引个数和元素的个数要严格一致,且索引要呈现递增趋势
Vector v1 = Vectors.sparse(9,new int[]{0,2},new double[]{8.0,2.0});2.2 向量标签( LabeledPoint)
向量标签,是一种基于密集型向量和稀疏型向量而额外给定一个标签(Label)的类型,这些统称为一个标记点。这些标签点的设置是有用户自己给定的,标记常用double类型的数据予以给定,这些值的给定是对数据进行标记,目的是为了分类和回归算法中的应用。简单理解就是一个向量组会对应的一个特殊值,但是这些标记值是可以重复的。
创建密集型向量标签的方式:
//创建一个带有标记点的密集型数据
LabeledPoint pos = new LabeledPoint(1.0, Vectors.dense(1.0, 2.0,3.0));创建稀疏型向量标签的方式:
//创建一个带有标记点的稀疏型数据:
LabeledPoint neg = new LabeledPoint(0.0, Vectors.sparse(3, new int[]{0,2},new double[]{1.0,2.5}));另外,Spak还提供了一种读取特定文件格式的方式来获取标签向量:
//使用外来文件(格式需要符合LIBSVM)创建labeledPoint
//使用该API需要注意下面几点:
1)、文件格式必须符合LIBSVM要求:label index1: 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









