




题外话:类中的field和properties 的区别
后者有get方法,而且可以是内部类的field,前者无get方法。
线程
ThreadLocal
http://con.zhangjikai.com/ThreadLocal.html#%E7%BA%BF%E7%A8%8B%E5%B1%80%E9%83%A8%E5%8F%98%E9%87%8F
应用及原理
https://blog.youkuaiyun.com/weixin_45333509/article/details/115756410
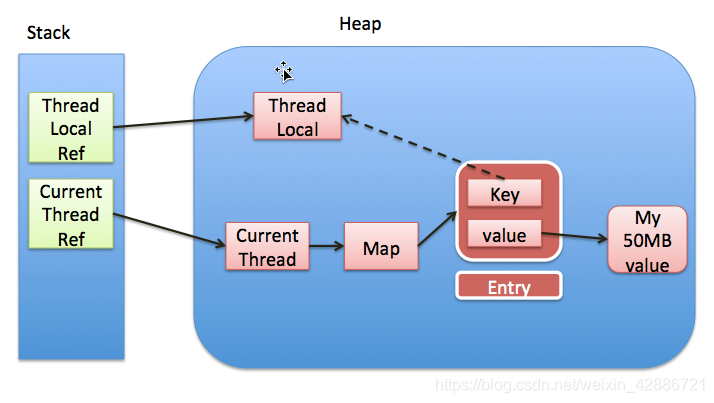
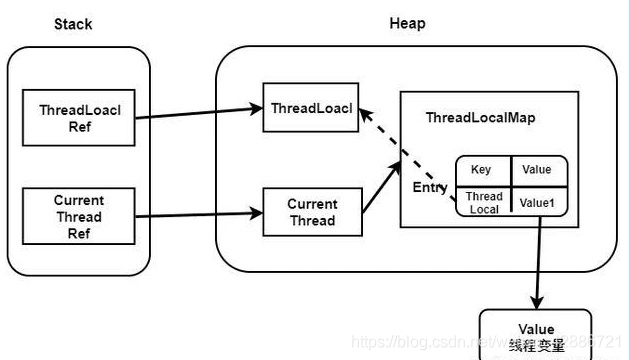
关键点 :
- 弱引用
- 用完要释放
- 哈希表防止哈希碰撞的方法
在每个线程中,都有一个
set方法
首先获取当前线程
利用当前线程作为句柄获取一个ThreadLocalMap的对象
如果上述ThreadLocalMap对象不为空,则设置值,否则创建这个ThreadLocalMap对象并设置值
ThreadLocalMap与内存泄漏
存储数值的Map由 ThreadLocal 类的静态内部类 ThreadLocalMap 提供。该类的实例维护某个 ThreadLocal 与具体实例的映射。与 HashMap 不同的是,ThreadLocalMap 的每个 Entry 都是一个对 键 的弱引用,这一点从super(k)可看出。另外,每个 Entry 都包含了一个对 值 的强引用。
散列冲突
ThreadLocalMap 中使用开放地址法来处理散列冲突,而 HashMap 中使用的分离链表法。之所以采用不同的方式主要是因为:在 ThreadLocalMap 中的散列值分散的十分均匀,很少会出现冲突。并且 ThreadLocalMap 经常需要清除无用的对象,使用纯数组更加方便。
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
内存泄漏及解决
使用弱引用的原因在于,当没有强引用指向 ThreadLocal 变量时,它可被回收,从而避免上文所述 ThreadLocal 不能被回收而造成的内存泄漏的问题。
但是,这里又可能出现另外一种内存泄漏的问题。ThreadLocalMap 维护 ThreadLocal 变量与具体实例的映射,当 ThreadLocal 变量被回收后,该映射的键变为 null,该 Entry 无法被移除。从而使得实例被该 Entry 引用而无法被回收造成内存泄漏。
注:Entry虽然是弱引用,但它是 ThreadLocal 类型的弱引用(也即上文所述它是对 键 的弱引用),而非具体实例的的弱引用,所以无法避免具体实例相关的内存泄漏。
内存泄漏的根本原因
所有Entry对象都被ThreadLocalMap类的实例化对象threadLocals持有,当ThreadLocal对象不再使用时,ThreadLocal对象在栈中的引用就会被回收,一旦没有任何引用指向ThreadLocal对象,Entry只持有弱引用的key就会自动在下一次YGC时被回收,而此时持有强引用的Entry对象并不会被回收。
简而言之: threadLocals对象中的entry对象不在使用后,没有及时remove该entry对象 ,然而程序自身也无法通过垃圾回收机制自动清除,从而导致内存泄漏。
解决方案:只要在使用完ThreadLocal对象后,调用其remove方法删除对应的Entry,即可从根本解决问题。
怎样停止一个正在运行的线程
https://www.jianshu.com/p/87f7b0147cba
中断线程的最佳实践是: 中断 + volatile 条件变量。
/**
* @author bruce_sha (bruce-sha.github.io)
* @version 2013-12-23
*/
public class BestPractice extends Thread {
private volatile boolean finished = false; // ① volatile条件变量
public void stopMe() {
finished = true; // ② 发出停止信号
interrupt();
}
@Override
public void run() {
while (!finished) { // ③ 检测条件变量
try {
// do dirty work // ④业务代码
} catch (InterruptedException e) {
if (finished) {
return;
}
continue;
}
}
}
}
也可以用thread.interrupt()
thread.interrupt()
public void Thread.interrupt() // 无返回值
public boolean Thread.isInterrupted() // 有返回值
public static boolean Thread.interrupted() // 静态,有返回值
- interrupt() :中断本线程。
- isInterrupted() :检测当前线程是否已经中断,是则返回true,否则false,并清除中断状态。
- interrupted()与isInterrupted()的唯一区别是,前者会读取并清除中断状态,后者仅读取状态。
锁的理论
多线程是为了效率,锁是为了安全。二者此消彼长。 ————高尔基没说过。
死锁
死锁的四个条件:
竞争统一资源,特定顺序,不释放,不剥夺。
一定可以死锁的代码
在这里插入代码片
JMM
https://blog.youkuaiyun.com/javazejian/article/details/72772461
Java内存模型(即Java Memory Model,简称JMM)本身是一种抽象的概念,并不真实存在,它描述的是一组规则或规范,通过这组规范定义了程序中各个变量(包括实例字段,静态字段和构成数组对象的元素)的访问方式。
由于JVM运行程序的实体是线程,而每个线程创建时JVM都会为其创建一个工作内存(有些地方称为栈空间),用于存储线程私有的数据,而Java内存模型中规定所有变量都存储在主内存,主内存是共享内存区域,所有线程都可以访问,但线程对变量的操作(读取赋值等)必须在工作内存中进行,首先要将变量从主内存拷贝的自己的工作内存空间,然后对变量进行操作,操作完成后再将变量写回主内存,不能直接操作主内存中的变量,工作内存中存储着主内存中的变量副本拷贝,前面说过,工作内存是每个线程的私有数据区域,因此不同的线程间无法访问对方的工作内存,线程间的通信(传值)必须通过主内存来完成,
volatile
禁止指令重排序以及缓存一致性
- volatile满足一致性,有序性,不满足原子性。
一致性:
为了提高处理速度,处理器不直接和内存进行通信,而是先将系统内存的数据读到内部缓存(L1,L2或其他)后再进行操作,但操作完全不知道何时会写到内存。如果对声明了volatile的变量进行写操作,JVM就会向处理器发送一条Lock前缀的指令,将这个变量所在缓存行的数据写回到系统内存。但是,就算写回到内存,如果其他处理器缓存的值还是旧的,再执行计算操作就会有问题。
Java内存模型告诉我们,各个线程会将共享变量从主内存中拷贝到工作内存,然后执行引擎会基于工作内存中的数据进行操作处理。线程在工作内存进行操作后何时会写到主内存中?这个时机对普通变量是没有规定的,而针对volatile修饰的变量给java虚拟机特殊的约定,线程对volatile变量的修改会立刻被其他线程所感知,即不会出现数据脏读的现象,从而保证数据的“可见性”。
一致性需要两个要素吧:可见和更新。
**可见性:**在多线程环境下,某个共享变量如果被其中一个线程给修改了,其他线程能够立即知道这个共享变量已经被修改了
当一个变量被声明为volatile时,在编译成会变指令的时候,会多出下面一行:
0x00bbacde: lock add1 $0x0,(%esp);
这句指令的意思就是在寄存器执行一个加0的空操作。不过这条指令的前面有一个lock(锁)前缀。当处理器在处理拥有lock前缀的指令时:
- lock会导致传输数据的总线被锁定,其他处理器都不能访问总线,保证当前处理器能够独享操作数据所在的内存区域。
- 由于总线被锁住,其他处理器都会被堵住,从而影响了多处理器的执行效率,所以都采用总线嗅探机制。
总线嗅探机制:
- 将当前处理器缓存行的数据写回系统内存;
- 这个写回内存的操作会使得其他CPU里缓存了该内存地址的数据无效
- 当处理器发现本地缓存失效后,就会从内存中重读该变量数据,即可以获取当前最新值。
https://www.jianshu.com/p/157279e6efdb
https://tech.meituan.com/2014/09/23/java-memory-reordering.html
https://blog.youkuaiyun.com/blueheart20/article/details/52117761
禁止指令重排序
采用读写屏障来禁止指令重排序。

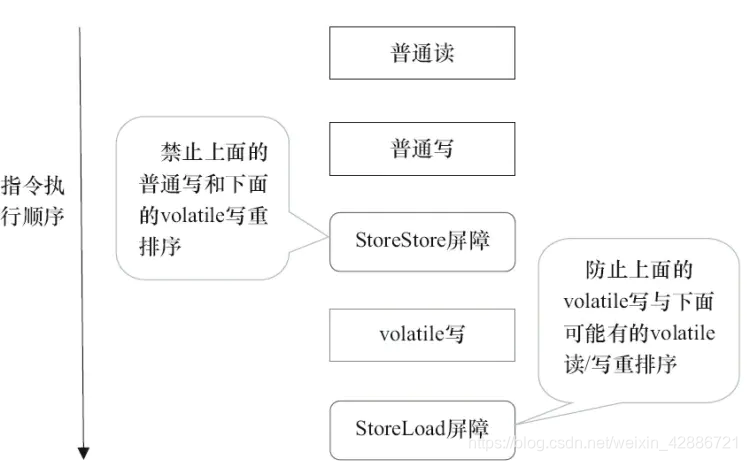
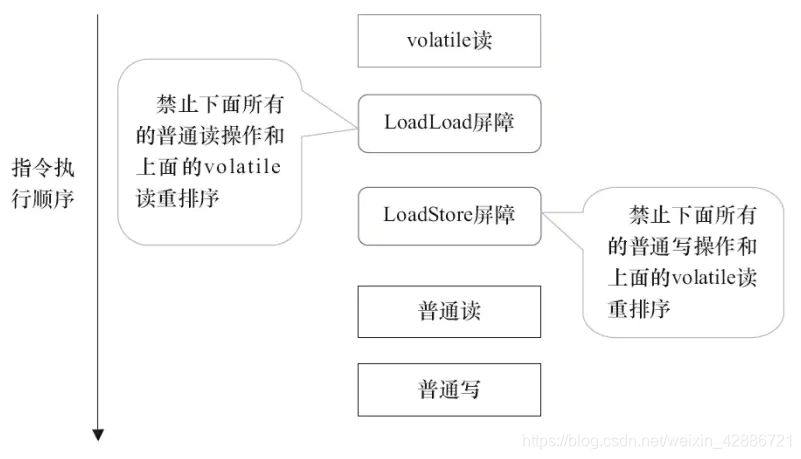
记忆:
- volatile写被两个屏障包着
- volatile读下面有两个屏障(防止读和写重排到刷新读前面,就读不到最新的了)
一定要熟记这个案例
- 应该给flag加volatile
class ReorderExample {
int a = 0;
boolean flag = false;
public void writer() {
a = 1; //1
flag = true; //2
}
Public void reader() {
if (flag) { //3
int i = a * a; //4
……
}
}
}
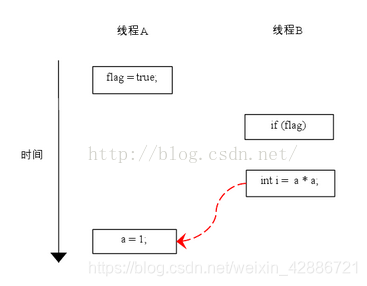
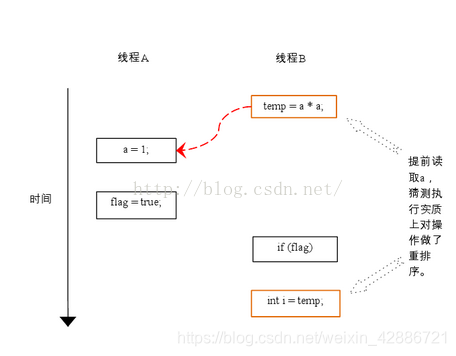
主要还是编译器以及CPU为了优化代码或者执行的效率而执行的优化操作;应用条件是单线程场景下,对于并发多线程场景下,指令重排会产生不确定的执行效果。
volatile有什么线程安全问题
https://juejin.im/post/6844903662108540935
volatile可以保证有序性和一致性,但不能保证原子性
读写屏障
八大原子操作
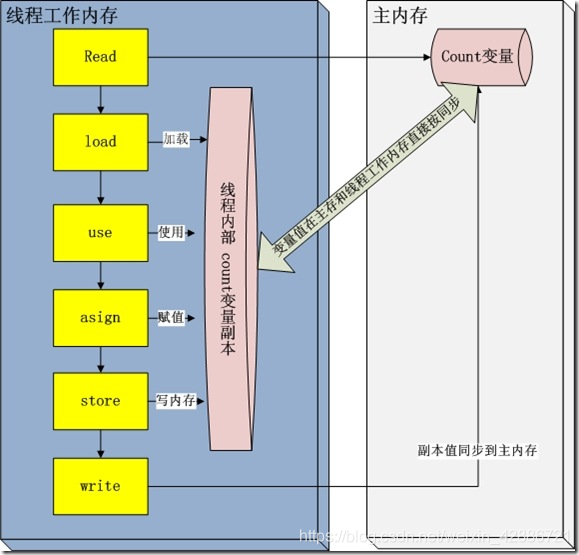
java内存模型定义了8种操作来完成。这8种操作每一种都是原子操作。8种操作如下:
lock(锁定):作用于主内存,它把一个变量标记为一条线程独占状态;
read(读取):作用于主内存,它把变量值从主内存传送到线程的工作内存中,以便随后的load动作使用;
load(载入):作用于工作内存,它把read操作的值放入工作内存中的变量副本中;
use(使用):作用于工作内存,它把工作内存中的值传递给执行引擎,每当虚拟机遇到一个需要使用这个变量的指令时候,将会执行这个动作;
assign(赋值):作用于工作内存,它把从执行引擎获取的值赋值给工作内存中的变量,每当虚拟机遇到一个给变量赋值的指令时候,执行该操作;
store(存储):作用于工作内存,它把工作内存中的一个变量传送给主内存中,以备随后的write操作使用;
write(写入):作用于主内存,它把store传送值放到主内存中的变量中。
unlock(解锁):作用于主内存,它将一个处于锁定状态的变量释放出来,释放后的变量才能够被其他线程锁定;
Java内存模型还规定了执行上述8种基本操作时必须满足如下规则:
1、不允许read和load、store和write操作之一单独出现(即不允许一个变量从主存读取了但是工作内存不接受,或者从工作内存发起会写了但是主存不接受的情况),以上两个操作必须按顺序执行,但没有保证必须连续执行,也就是说,read与load之间、store与write之间是可插入其他指令的。
2、不允许一个线程丢弃它的最近的assign操作,即变量在工作内存中改变了之后必须把该变化同步回主内存。
3、不允许一个线程无原因地(没有发生过任何assign操作)把数据从线程的工作内存同步回主内存中。
4、一个新的变量只能从主内存中“诞生”,不允许在工作内存中直接使用一个未被初始化(load或assign)的变量,换句话说就是对一个变量实施use和store操作之前,必须先执行过了assign和load操作。
5、一个变量在同一个时刻只允许一条线程对其执行lock操作,但lock操作可以被同一个条线程重复执行多次,多次执行lock后,只有执行相同次数的unlock操作,变量才会被解锁。
6、如果对一个变量执行lock操作,将会清空工作内存中此变量的值,在执行引擎使用这个变量前,需要重新执行load或assign操作初始化变量的值。
7、如果一个变量实现没有被lock操作锁定,则不允许对它执行unlock操作,也不允许去unlock一个被其他线程锁定的变量。
8、对一个变量执行unlock操作之前,必须先把此变量同步回主内存(执行store和write操作)。
synchronized关键字
三种应用方式:修饰实例方法,静态方法,代码块
synchronized底层原理
https://segmentfault.com/a/1190000016417017
简单版:
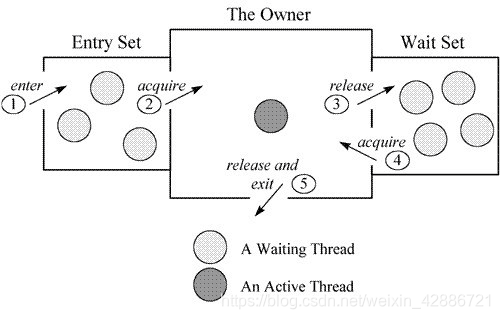
在 java 虚拟机中, 每个对象( Object 和 class )通过某种逻辑关联监视器,每个监视器和一个对象引用相关联, 为了实现监视器的互斥功能, 每个对象都关联着一把锁 . 一旦方法或者代码块被 synchronized 修饰, 那么这个部分就放入了监视器的监视区域(下图的Entry Set), 确保一次只能有一个线程执行该部分的代码 , 线程在获取锁之前不允许执行该部分的代码 另外 java 还提供了显式监视器( Lock )和隐式监视器( synchronized )两种锁方案
详细解释:
Java 虚拟机中的同步(Synchronization)基于进入和退出管程(Monitor)对象实现, 无论是显式同步(有明确的 monitorenter 和 monitorexit 指令,即同步代码块)还是隐式同步(方法中的ACC_SYNCHRONIZED )都是如此。

- 修饰
当一个进程试图获取一个锁对象时,锁对象受到监视器的管理,由此来控制线程。
在《操作系统同步原语》 这篇文章中,介绍了操作系统在面对 进程/线程 间同步的时候,所支持的一些同步原语,其中 semaphore 信号量 和 mutex 互斥量是最重要的同步原语。
在使用基本的 mutex 进行并发控制时,需要程序员非常小心地控制 mutex 的 down 和 up 操作,否则很容易引起死锁等问题。为了更容易地编写出正确的并发程序,所以在 mutex 和 semaphore 的基础上,提出了更高层次的同步原语 monitor,不过需要注意的是,操作系统本身并不支持 monitor 机制,实际上,monitor 是属于编程语言的范畴,当你想要使用 monitor 时,先了解一下语言本身是否支持 monitor 原语,例如 C 语言它就不支持 monitor,Java 语言支持 monitor。
一般的 monitor 实现模式是编程语言在语法上提供语法糖,而如何实现 monitor 机制,则属于编译器的工作,Java 就是这么干的。
monitor 机制需要几个元素来配合,分别是:
- 临界区
- monitor 对象及锁监视器
- 条件变量以及定义在 monitor 对象上的 wait,signal 操作。
使用 monitor 机制的目的主要是为了互斥进入临界区,为了做到能够阻塞无法进入临界区的 进程/线程,还需要一个 monitor object 来协助,这个 monitor object 内部会有相应的数据结构,例如列表,来保存被阻塞的线程;同时由于 monitor 机制本质上是基于 mutex 这种基本原语的,所以 monitor object 还必须维护一个基于 mutex 的锁。
此外,为了在适当的时候能够阻塞和唤醒 进程/线程,还需要引入一个条件变量,这个条件变量用来决定什么时候是“适当的时候”,这个条件可以来自程序代码的逻辑,也可以是在 monitor object 的内部,总而言之,程序员对条件变量的定义有很大的自主性。不过,由于 monitor object 内部采用了数据结构来保存被阻塞的队列,因此它也必须对外提供两个 API 来让线程进入阻塞状态以及之后被唤醒,分别是 wait 和 notify。
monitor object(监视的对象)
被 synchronized 关键字修饰的方法、代码块,就是 monitor 机制的临界区。
monitor object 充当着维护 mutex以及定义 wait/signal API 来管理线程的阻塞和唤醒的角色。
Java 对象存储在内存中,分别分为三个部分,即对象头、实例数据和对齐填充,而在其对象头中,保存了锁标识;同时,java.lang.Object 类定义了 wait(),notify(),notifyAll() 方法,这些方法的具体实现,依赖于一个叫 ObjectMonitor 模式的实现(这是一个模式),这是 JVM 内部基于 C++ 实现的一套机制,基本原理如下所示:
当一个线程需要获取 Object 的锁时,会被放入 EntrySet 中进行等待,如果该线程获取到了锁,成为当前锁的 owner。如果根据程序逻辑,一个已经获得了锁的线程缺少某些外部条件,而无法继续进行下去(例如生产者发现队列已满或者消费者发现队列为空),那么该线程可以通过调用 wait 方法将锁释放,进入 wait set 中阻塞进行等待,其它线程在这个时候有机会获得锁,去干其它的事情,从而使得之前不成立的外部条件成立,这样先前被阻塞的线程就可以重新进入 EntrySet 去竞争锁。这个外部条件在 monitor 机制中称为条件变量。
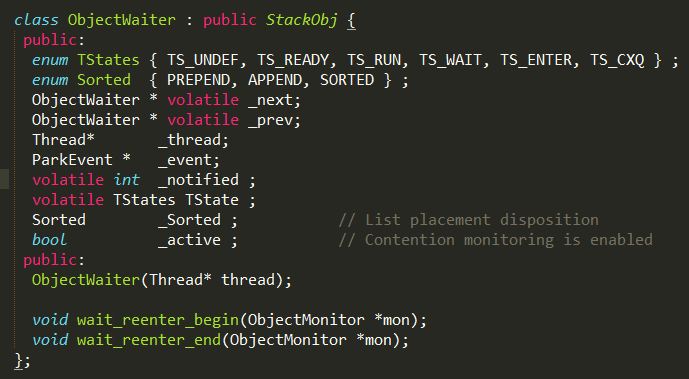
ObjectMonitor
在HotSpot虚拟机中,monitor采用ObjectMonitor实现。
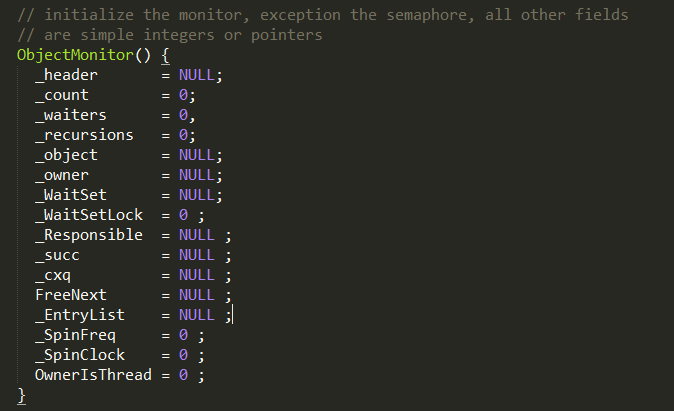
ObjectMonitor中有两个队列,_WaitSet 和 _EntryList,用来保存ObjectWaiter对象列表( 每个等待锁的线程都会被封装成ObjectWaiter对象),_owner指向持有ObjectMonitor对象的线程,当多个线程同时访问一段同步代码时,首先会进入 _EntryList 集合,当线程获取到对象的monitor 后进入 _Owner 区域并把monitor中的owner变量设置为当前线程同时monitor中的计数器count加1,若线程调用 wait() 方法,将释放当前持有的monitor,owner变量恢复为null,count自减1,同时该线程进入 WaitSe t集合中等待被唤醒。若当前线程执行完毕也将释放monitor(锁)并复位变量的值,以便其他线程进入获取monitor(锁)。如下图所示
ObjectWaiter
wait/notify 为什么一定要在sync里
- 防止出现notify 在wait前面执行,这样的话wait就不会被唤醒一直阻塞了,所以需要sync进行同步控制。
- 即使在sync里,如果编写不当还是会造成因执行顺序颠倒造成的“唤醒丢失”问题的。
本质上,wait和notify 是一种通知机制,即线程A判断某种状态不符合,于是执行wait。线程B改变状态,并执行notify将A唤醒,从而完成了“A必须在相应状态下执行”的功能。
但是判断状态和wait是非原子的,有可能A判断完状态,没执行wait呢,紧接着B改变状态然后执行了notify,此时A再执行wait,就会一直阻塞下去。
// 线程 A 的代码
while(!condition){ // 不能使用 if , 因为存在一些特殊情况, 使得线程没有收到 notify 时也能退出等待状态
wait();
}
// do something
// 线程 B 的代码
if(!condition){
// do something ...
condition = true;
notify();
}
加上同步块后自然不会有这种问题。
// 线程A 的代码
synchronized(obj_A)
{
while(!condition){
wait();
}
// do something
}
// 线程 B 的代码
synchronized(obj_A)
{
if(!condition){
// do something ...
condition = true;
notify();
}
}
题外话:一个非常有意思的写法。
public class ThreadA {
public static void main(String[] args) {
ThreadB b = new ThreadB();
b.start();// 主线程中启动另外一个线程
System.out.println("b is start....");
// 括号里的b是什么意思,应该很好理解吧
synchronized (b) {
try {
System.out.println("Waiting for b to complete...");
b.wait();// 这一句是什么意思,究竟谁等待?
System.out.println("ThreadB is Completed. Now back to main thread");
} catch (InterruptedException e) {
}
}
System.out.println("Total is :" + b.total);
}
}
class ThreadB extends Thread {
int total;
public void run() {
synchronized (this) {
System.out.println("ThreadB is running..");
for (int i = 0; i <= 100; i++) {
total += i;
}
System.out.println("total is" + total);
notify();
}
}
}
// 以下是结果
b is start....
ThreadB is running..
total is5050
Waiting for b to complete...
ThreadB is Completed. Now back to main thread
Total is :5050
wait和notify的实现
https://www.jianshu.com/p/f4454164c017
执行monitorenter指令可以获取对象的monitor,而lock.wait()方法通过调用native方法wait(0)实现,步骤如下
-
在多核环境下,线程A和B有可能同时执行monitorenter指令,并获取lock对象关联的monitor,只有一个线程可以和monitor建立关联,假设线程A执行加锁成功;
-
线程B竞争加锁失败,进入等待队列进行等待;
-
线程A继续执行,当执行到wait方法时
-
通过
ObjectMonitor::AddWaiter方法将线程封装成objectWaiter添加到_WaitSet列表中;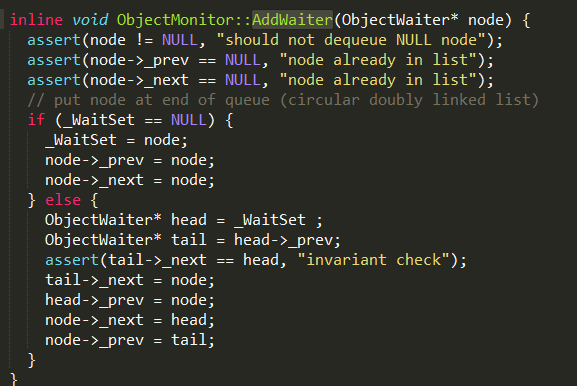
-
通过
ObjectMonitor::exit方法释放当前的ObjectMonitor对象,这样其它竞争线程就可以获取该ObjectMonitor对象。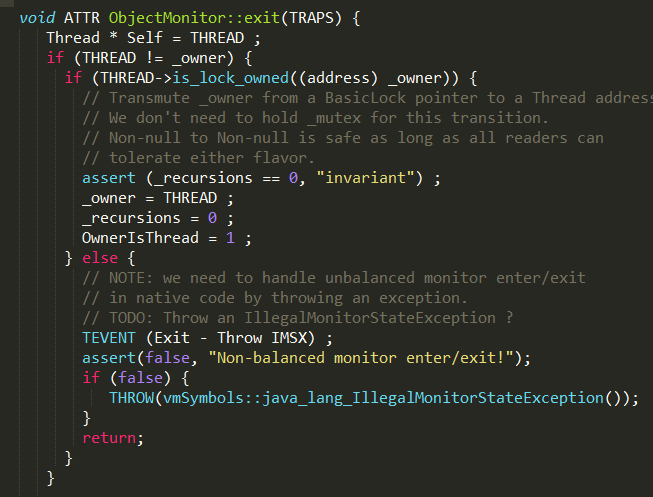
-
底层的park方法会挂起线程;
-
notify方法实现
lock.notify()方法最终通过ObjectMonitor的void notify(TRAPS)实现:
- 如果当前_WaitSet为空,即没有正在等待的线程,则直接返回;_
- 通过
ObjectMonitor::DequeueWaiter方法,获取_WaitSet列表中的第一个ObjectWaiter节点,实现也很简单。
这里需要注意的是,在jdk的notify方法注释是随机唤醒一个线程,其实是第一个ObjectWaiter节点_ - 根据不同的策略,将取出来的ObjectWaiter节点,加入到_EntryList或则通过
Atomic::cmpxchg_ptr指令进行自旋操作cxq
notifyAll方法实现
lock.notifyAll()方法最终通过ObjectMonitor的void notifyAll(TRAPS)实现:
通过for循环取出_WaitSet的ObjectWaiter节点,并根据不同策略,加入到_EntryList或则进行自旋操作。
从JVM的方法实现中,可以发现:notify和notifyAll并不会释放所占有的ObjectMonitor对象,其实真正释放ObjectMonitor对象的时间点是在执行monitorexit指令,一旦释放ObjectMonitor对象了,entry set中ObjectWaiter节点所保存的线程就可以开始竞争ObjectMonitor对象进行加锁操作了。
Thread.suspend, Thread.resume为什么会死锁?
使用suspend时,并不会释放锁;而如果我想先获取该锁,再进行resume,就会造成死锁。
可以使用object的wait和notify方法代替。wait方法会释放持有的锁。
为什么LockSupport不会遇到?答案在下面章节。
锁的升级过程
https://blog.youkuaiyun.com/javazejian/article/details/72828483
先了解结构
以下是markword
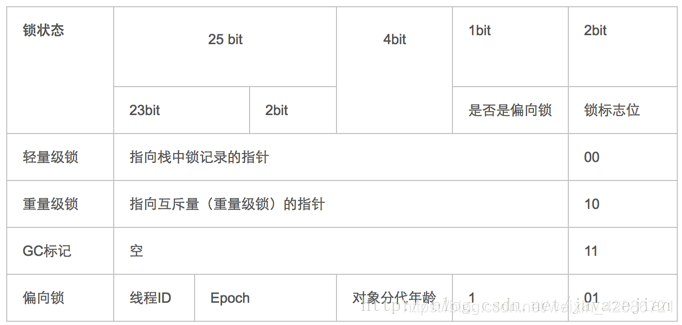
只有重量级锁涉及到了moniter
另一种记忆法:
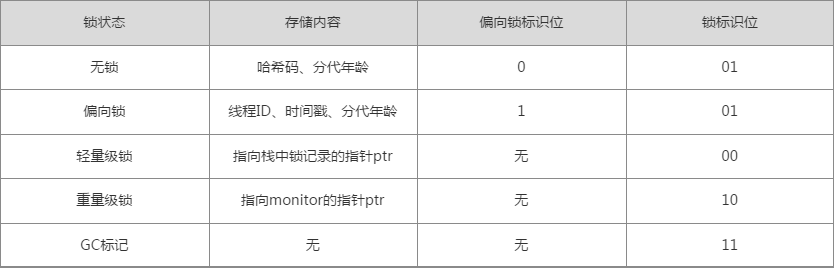
(1)偏向锁:
为什么要引入偏向锁?
因为经过HotSpot的作者大量的研究发现,大多数时候是不存在锁竞争的,常常是一个线程多次获得同一个锁,因此如果每次都要竞争锁会增大很多没有必要付出的代价,为了降低获取锁的代价,才引入的偏向锁。
偏向锁的升级
当线程1访问代码块并获取锁对象时,会在java对象头和栈帧中记录偏向的锁的threadID,因为偏向锁不会主动释放锁,因此以后线程1再次获取锁的时候,需要比较当前线程的threadID和Java对象头中的threadID是否一致,如果一致(还是线程1获取锁对象),则无需使用CAS来加锁、解锁;如果不一致(其他线程,如线程2要竞争锁对象,而偏向锁不会主动释放因此还是存储的线程1的threadID),那么需要查看Java对象头中记录的线程1是否存活,如果没有存活,那么锁对象被重置为无锁状态,其它线程(线程2)可以竞争将其设置为偏向锁;如果存活,那么立刻查找该线程(线程1)的栈帧信息,如果还是需要继续持有这个锁对象,那么暂停当前线程1,撤销偏向锁,升级为轻量级锁,如果线程1 不再使用该锁对象,那么将锁对象状态设为无锁状态,重新偏向新的线程。
偏向锁的取消:
偏向锁是默认开启的,而且开始时间一般是比应用程序启动慢几秒,如果不想有这个延迟,那么可以使用-XX:BiasedLockingStartUpDelay=0;
如果不想要偏向锁,那么可以通过-XX:-UseBiasedLocking = false来设置;
轻量级锁
https://blog.youkuaiyun.com/z69183787/article/details/104502540
- 关键词: Displaced Mark Word
为什么要引入轻量级锁?
轻量级锁考虑的是竞争锁对象的线程不多,而且线程持有锁的时间也不长的情景。因为阻塞线程需要CPU从用户态转到内核态,代价较大,如果刚刚阻塞不久这个锁就被释放了,那这个代价就有点得不偿失了,因此这个时候就干脆不阻塞这个线程,让它自旋这等待锁释放。
线程在执行同步块之前,JVM 会先在当前线程的栈桢中创建用于存储锁记录的空间,并将对象头中的 Mark Word 复制到锁记录中,官方称为 Displaced Mark Word。然后线程尝试使用 CAS 将对象头中的 Mark Word 替换为指向锁记录的指针。如果成功,当前线程获得锁,如果失败,表示其他线程竞争锁,当前线程便尝试使用自旋来获取锁
当
CASE(_monitorenter): {
oop lockee = STACK_OBJECT(-1);
...
if (entry != NULL) {
...
// 上面省略的代码中如果CAS操作失败也会调用到InterpreterRuntime::monitorenter
// traditional lightweight locking
if (!success) {
// 构建一个无锁状态的Displaced Mark Word
markOop displaced = lockee->mark()->set_unlocked();
// 设置到Lock Record中去
entry->lock()->set_displaced_header(displaced);
bool call_vm = UseHeavyMonitors;
if (call_vm || Atomic::cmpxchg_ptr(entry, lockee->mark_addr(), displaced) != displaced) {
// 如果CAS替换不成功,代表锁对象不是无锁状态,这时候判断下是不是锁重入
// Is it simple recursive case?
if (!call_vm && THREAD->is_lock_owned((address) displaced->clear_lock_bits())) {
entry->lock()->set_displaced_header(NULL);
} else {
// CAS操作失败则调用monitorenter
CALL_VM(InterpreterRuntime::monitorenter(THREAD, entry), handle_exception);
}
}
}
UPDATE_PC_AND_TOS_AND_CONTINUE(1, -1);
} else {
istate->set_msg(more_monitors);
UPDATE_PC_AND_RETURN(0); // Re-execute
}
}
轻量级锁什么时候升级为重量级锁?
- 自旋有一定次数,如果超过设置自旋的次数则升级到重量级锁。
- 或者一个线程在持有锁,一个在自旋,又有第三个来访时,轻量级锁升级为重量级锁,重量级锁使除了拥有锁的线程以外的线程都阻塞,防止CPU空转。
但是如果自旋的时间太长也不行,因为自旋是要消耗CPU的,因此自旋的次数是有限制的,比如10次或者100次,如果自旋次数到了线程1还没有释放锁,或者线程1还在执行,线程2还在自旋等待,这时又有一个线程3过来竞争这个锁对象,那么这个时候轻量级锁就会膨胀为重量级锁。重量级锁把除了拥有锁的线程都阻塞,防止CPU空转。
重量级锁图示
https://www.processon.com/diagraming/5f31182de401fd13e726f3fb
JUC
什么是AQS(设计模式:模板方法)
http://baijiahao.baidu.com/s?id=1661915411417744043
https://tech.meituan.com/2019/12/05/aqs-theory-and-apply.html
(没有什么问题是美团技术团队写不清楚的,respect)
什么是AQS?
- AQS,队列同步器AbstractQueuedSynchronizer的简写,JDK1.5引入的,是用来构建锁或者其他同步组件的基础框架,它使用了一个int成员变量表示同步状态,通过内置的FIFO队列来完成资源获取线程的排队工作。
- AQS中里有一个volatile修饰int型的state来代表同步状态,使用(不需要重写)同步器提供的3个方法(getState()、setState(int newState)和compareAndSetState(int expect,int update))来改变状态,因为它们能够保证状态的改变是安全的。(需要重写的方法见下表)
- AQS使用的是模板方法模式,主要使用方式是继承,且通常将子类推荐定义为静态内部类,子类通过继承AQS并实现它的抽象方法来管理同步状态。
- 同步器既可以支持独占式地获取同步状态,也可以支持共享式地获取同步状态,这样就可以方便实现不同类型的同步组件(ReentrantLock、ReentrantReadWriteLock和CountDownLatch等)。
AQS原理
AQS提供的模板方法基本上分为3类:独占式获取与释放同步状态、共享式获取与释放同步状态和查询同步队列中的等待线程情况。AQS中可重写的方法如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rcgEkLVz-1598931201761)(http://pics5.baidu.com/feed/3ac79f3df8dcd100d76f019356ae2116b8122fb8.jpeg?token=7b52aa3e1460a2e8eae2ae853d2152c7)]
子类直接使用下面的模板方法(都是public的,调用上面的那些需要重写的方法,体现了模板方法模式)

AQS分层结构

- 上图中有颜色的为Method,无颜色的为Attribution。
- 总的来说,AQS框架共分为五层,自上而下由浅入深,从AQS对外暴露的API到底层基础数据。
- 当有自定义同步器接入时,只需重写第一层所需要的部分方法即可,不需要关注底层具体的实现流程。当自定义同步器进行加锁或者解锁操作时,先经过第一层的API进入AQS内部方法,然后经过第二层进行锁的获取,接着对于获取锁失败的流程,进入第三层和第四层的等待队列处理,而这些处理方式均依赖于第五层的基础数据提供层。
同步器是如何完成线程同步的
-
同步队列
-
独占式同步状态获取与释放
-
共享式同步状态获取与释放
-
独占式超时获取同步状态
Lock与syncronized锁相比的优势
- 教你高情商七个字:非阻中断可超时。直男:学到了
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-drdCWzBs-1598931201763)(http://pics3.baidu.com/feed/b58f8c5494eef01f1025cc6fc4dbff23bc317d16.jpeg?token=9746126134e39424f0f64e7ae7ddd7f6)]
与关键字synchronized相比,Lock有以下几个优势:
(1)可以尝试非阻塞地获取锁,如果这一时刻锁没有被其他线程获取到,则成功获取并持有锁。(tryLock)
(2)获取锁过程中可以被中断。
(3)超时获取锁,可以指定一个时间,在指定的时间范围内获取锁,如果截止时间到了仍然无法获取锁,则返回,可以避免线程长时间阻塞。
(4)ReentrantLock可以定义为公平锁或非公平锁,synchronized内部实现使用的是非公平锁机制。
Lock也有缺点,必须手动的释放锁
(5)在一个ReentrantLock中可以生成不同的condition状态变量,即可以实现点对点通知
(6)在读多写少的场景可以使用ReentrantReadWriteLock
使用synchronized+wait()/notifyAll()的时候,不能指定唤醒某类线程,只能唤醒等待在对象上的所有线程,故尽量使用notifyAll()而不是notify(),在使用Lock+Condition的时候,由于可以指定唤醒某类线程,所以尽量使用signal()而不是signalAll()。
AQS怎样实现公平与非公平?
- 公平性与否是针对获取锁而言的
公平锁和非公平锁加锁的源码,区别其实非常小,先看非公平锁:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RnSD13h4-1598931201764)(http://pics2.baidu.com/feed/bba1cd11728b471047148890e0eba5fbfc03235a.jpeg?token=0640258a72fe2ead66ff106b65603e86)]
再看公平锁:
- 该方法与nonfairTryAcquire(int acquires)比较,唯一不同的位置为判断条件多了hasQueuedPredecessors()方法,即加入了同步队列中当前节点是否有前驱节点的判断,如果该方法返回false,则表示有线程比当前线程更早地请求获取锁,因此需要等待前驱线程获取并释放锁之后才能继续获取锁。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cGX3AIXN-1598931201765)(http://pics6.baidu.com/feed/d8f9d72a6059252d2576ff6c17be653d5bb5b925.jpeg?token=c11873386eb0ea174cc7272e6c43205f)]
在《并发编程的艺术》中作者做了测试:
在测试中公平性锁与非公平性锁相比,总耗时是其94.3倍,总切换次数是其133倍。可以看出,公平性锁保证了锁的获取按照FIFO原则,而代价是进行大量的线程切换。非公平性锁虽然可能造成线程“饥饿”,但极少的线程切换,保证了其更大的吞吐量。
读写锁
ReentrantReadWriteLock会使用两把锁来解决问题,一个读锁,一个写锁
ReentrantReadWriteLock和ReentrantLock的一个相同点和不同点,相同的是使用了同一个关键实现AbstractQueuedSynchronizer,不同的是ReentrantReadWriteLock使用了两个锁分别实现了AQS,而且WriteLock和ReentrantLock一样,使用了独占锁。而ReadLock和Semaphore一样,使用了共享锁。再往下的内容估计看过前面几篇文章的都很熟悉了,独占锁通过state变量的0和1两个状态来控制是否有线程占有锁,共享锁通过state变量0或者非0来控制多个线程访问。
-
线程进入读锁的前提条件:
- 没有其他线程的写锁
- 没有写请求或者,有写请求但调用线程和持有锁的线程是同一个
-
线程进入写锁的前提条件:
没有其他线程的读锁
没有其他线程的写锁
原理
- 读写锁的内部维护了一个ReadLock和一个WriteLock,它们依赖Sync实现具体功能。而Sync继承自AQS,并且也提供了公平和非公平的实现。
- ReentrantReadWriteLock巧妙地使用state的高16位表示读状态,也就是获取到读锁的次数;使用低16位表示获取到写锁的线程的可重入次数。
可以看到用到了WriteLock和ReadLock两个静态内部类,他们对锁的实现如下:
public static class ReadLock implements Lock, java.io.Serializable {
public void lock() {
sync.acquireShared(1); //共享
}
public void unlock() {
sync.releaseShared(1); //共享
}
}
public static class WriteLock implements Lock, java.io.Serializable {
public void lock() {
sync.acquire(1); //独占
}
public void unlock() {
sync.release(1); //独占
}
}
加锁
- 其他对象获得写锁,加锁失败
- 自己获得写锁或没有写锁被获得,加锁成功。
(具体步骤)读锁是一个支持重进入的共享锁,它能够被多个线程同时获取:
- 在没有其他写线程访问(写状态为0)时,读锁总会被成功地获取,
- (线程安全的)增加读状态。如果当前线程已经获取了读锁,则增加读状态。
- 如果当前线程在获取读锁时,写锁已被其他线程获取,则进入等待状态。
protected final int tryAcquireShared(int unused) {
/*
* Walkthrough:
* 1. If write lock held by another thread, fail.
* 2. Otherwise, this thread is eligible for
* lock wrt state, so ask if it should block
* because of queue policy. If not, try
* to grant by CASing state and updating count.
* Note that step does not check for reentrant
* acquires, which is postponed to full version
* to avoid having to check hold count in
* the more typical non-reentrant case.
* 3. If step 2 fails either because thread
* apparently not eligible or CAS fails or count
* saturated, chain to version with full retry loop.
*/
Thread current = Thread.currentThread();
int c = getState();
if (exclusiveCount(c) != 0 &&
getExclusiveOwnerThread() != current)
return -1;
int r = sharedCount(c);
if (!readerShouldBlock() &&
r < MAX_COUNT &&
compareAndSetState(c, c + SHARED_UNIT)) {
if (r == 0) {
firstReader = current;
firstReaderHoldCount = 1;
} else if (firstReader == current) {
firstReaderHoldCount++;
} else {
HoldCounter rh = cachedHoldCounter;
if (rh == null || rh.tid != getThreadId(current))
cachedHoldCounter = rh = readHolds.get();
else if (rh.count == 0)
readHolds.set(rh);
rh.count++;
}
return 1;
}
return fullTryAcquireShared(current);
}
释放
- 读锁的每次释放(线程安全的,可能有多个读线程同时释放读锁)均减少读状态,减少的值是(1<<16)。
锁降级
锁降级是指把持住(当前拥有的)写锁,再获取到读锁,随后释放(先前拥有的)写锁的过程。
使用读写锁实现一个缓存
https://blog.youkuaiyun.com/qq_14855971/article/details/106721687
实现了按需加载
public class Cache<String, V> {
private final Map<String, V> DATA_MAP = new HashMap<>();
private final ReentrantReadWriteLock readWriteLock = new ReentrantReadWriteLock();
/**
* 读锁
*/
private final Lock readLock = readWriteLock.readLock();
/**
* 写锁
*/
private final Lock writeLock = readWriteLock.writeLock();
/**
* 读取缓存,若缓存不存在则查找数据库并放到缓存
* @param key
* @return
*/
public V get(String key) {
V value = null;
//读取缓存
readLock.lock(); // 1
try {
value = DATA_MAP.get(key); //2
} finally {
readLock.unlock(); // 3
}
// 缓存中存在,直接返回
if (Objects.nonNull(value)) { // 4
return value;
}
writeLock.lock(); //5
try {
// 再次验证是否为空,可能其他写线程已经查询过数据库写到缓存中了,后续再次获取到写锁的线程就不用再次查数据库
value = DATA_MAP.get(key); // 6
if (Objects.isNull(value)) { // 7
//模拟查询数据库
value = (V) "queryFromDB";
DATA_MAP.put(key, value);
}
} finally {
writeLock.unlock();
}
return value;
}
}
还可以使用锁降级的方法,更高效,详见https://blog.youkuaiyun.com/weixin_42886721/article/details/107225309
特性
(a).重入方面其内部的WriteLock可以获取ReadLock,但是反过来ReadLock想要获得WriteLock则永远都不要想。
(b).WriteLock可以降级为ReadLock,顺序是:先获得WriteLock再获得ReadLock,然后释放WriteLock,这时候线程将保持Readlock的持有。反过来ReadLock想要升级为WriteLock则不可能,为什么?参看(a)。
©.ReadLock可以被多个线程持有并且在作用时排斥任何的WriteLock,而WriteLock则是完全的互斥。这一特性最为重要,因为对于高读取频率而相对较低写入的数据结构,使用此类锁同步机制则可以提高并发量。
(d).不管是ReadLock还是WriteLock都支持Interrupt,语义与ReentrantLock一致。
(e).WriteLock支持Condition并且与ReentrantLock语义一致,而ReadLock则不能使用Condition,否则抛出UnsupportedOperationException异常。
package com.thread;
import java.util.Random;
import java.util.concurrent.locks.ReentrantReadWriteLock;
public class ReadWriteLockTest {
public static void main(String[] args) {
final Queue3 q3 = new Queue3();
for(int i=0;i<3;i++)
{
new Thread(){
public void run(){
while(true){
q3.get();
}
}
}.start();
}
for(int i=0;i<3;i++)
{
new Thread(){
public void run(){
while(true){
q3.put(new Random().nextInt(10000));
}
}
}.start();
}
}
}
class Queue3{
private Object data = null;//共享数据,只能有一个线程能写该数据,但可以有多个线程同时读该数据。
private ReentrantReadWriteLock rwl = new ReentrantReadWriteLock();
public void get(){
rwl.readLock().lock();//上读锁,其他线程只能读不能写
System.out.println(Thread.currentThread().getName() + " be ready to read data!");
try {
Thread.sleep((long)(Math.random()*1000));
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "have read data :" + data);
rwl.readLock().unlock(); //释放读锁,最好放在finnaly里面
}
public void put(Object data){
rwl.writeLock().lock();//上写锁,不允许其他线程读也不允许写
System.out.println(Thread.currentThread().getName() + " be ready to write data!");
try {
Thread.sleep((long)(Math.random()*1000));
} catch (InterruptedException e) {
e.printStackTrace();
}
this.data = data;
System.out.println(Thread.currentThread().getName() + " have write data: " + data);
rwl.writeLock().unlock();//释放写锁
}
}
ReentrantLock怎样实现的可重入?
获取
- 通过判断当前线程是否为获取锁的线程来决定获取操作是否成功,如果是获取锁的线程再次请求,则将同步状态值进行增加并返回true,表示获取同步状态成功。
abstract static class Sync extends AbstractQueuedSynchronizer {
// ...省略一段
final boolean nonfairTryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
}
释放
- 如果该锁被获取了n次,那么前(n-1)次tryRelease(int releases)方法必须返回false,而只有同步状态完全释放了,才能返回true。可以看到,该方法将同步状态是否为0作为最终释放的条件,当同步状态为0时,将占有线程设置为null,并返回true,表示释放成功。
protected final boolean tryRelease(int releases) {
int c = getState() - releases;
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
if (c == 0) {
free = true;
setExclusiveOwnerThread(null);
}
setState(c);
return free;
}
LockSupport的原理
LockSupport是基本线程阻塞原语
- LockSupport.park()不会释放锁资源
- 如果在park()之前执行了unpark()会怎样?线程不会被阻塞,直接跳过park(),继续执行后续内容;
第二条特性使得park()可以处理下面的bug
public class TestObjWait {
public static void main(String[] args)throws Exception {
final Object obj = new Object();
Thread A = new Thread(new Runnable() {
@Override
public void run() {
int sum = 0;
for(int i=0;i<10;i++){
sum+=i;
}
try {
synchronized (obj){
obj.wait();
}
}catch (Exception e){
e.printStackTrace();
}
System.out.println(sum);
}
});
A.start();
//睡眠一秒钟,保证线程A已经计算完成,阻塞在wait方法
//Thread.sleep(1000);
synchronized (obj){
obj.notify();
}
}
}
如果先执行了 obj.notify();是不可以的。
下面的可以。
public class TestObjWait {
public static void main(String[] args)throws Exception {
final Object obj = new Object();
Thread A = new Thread(new Runnable() {
@Override
public void run() {
int sum = 0;
for(int i=0;i<10;i++){
sum+=i;
}
LockSupport.park();
System.out.println(sum);
}
});
A.start();
//睡眠一秒钟,保证线程A已经计算完成,阻塞在wait方法
//Thread.sleep(1000);
LockSupport.unpark(A);
}
}
https://www.jianshu.com/p/4d19684917d2
LockSupport类可以阻塞当前线程以及唤醒指定被阻塞的线程。主要是通过park()和unpark(thread)方法来实现阻塞和唤醒线程的操作的。
每个线程都有一个许可(permit),permit只有两个值1和0,默认是0。所以先unpark再park不会阻塞。
- 当调用unpark(thread)方法,就会将thread线程的许可permit设置成1(注意多次调用unpark方法,不会累加,permit值还是1)。
- 当调用park()方法,如果当前线程的permit是1,那么将permit设置为0,并立即返回。如果当前线程的permit是0,那么当前线程就会阻塞,直到别的线程将当前线程的permit设置为1.park方法会将permit再次设置为0,并返回。
HotSpot里park/unpark的实现
https://blog.youkuaiyun.com/hengyunabc/article/details/28126139
每个java线程都有一个Parker实例
class Parker : public os::PlatformParker {
private:
volatile int _counter ;
...
public:
void park(bool isAbsolute, jlong time);
void unpark();
...
}
class PlatformParker : public CHeapObj<mtInternal> {
protected:
pthread_mutex_t _mutex [1] ;
pthread_cond_t _cond [1] ;
...
}
Parker类实际上用Posix的mutex,condition来实现的。
-
当调用park时,先尝试直接能否直接拿到“许可”,即_counter>0时,如果成功,则把_counter设置为0,并返回:
-
当unpark时,则简单多了,直接设置_counter为1,再unlock mutext返回。如果_counter之前的值是0,则还要调用pthread_cond_signal唤醒在park中等待的线程:
简而言之,是用mutex和condition保护了一个_counter的变量,当park时,这个变量置为了0,当unpark时,这个变量置为1。
LockSupport的应用
- Future的get()
- condition的awite()
LockSupport为什么不会死锁?
因为park() 和 unpark()有许可的存在;调用 park() 的线程和另一个试图将其 unpark() 的线程之间的竞争将保持活性。
如果满足死锁的四个条件,当然也会发生死锁。这就是lock锁的问题了,有没有park()都会锁。
condition的原理
(https://zhuanlan.zhihu.com/p/97292945)
aqs内部有一个state和队列,线程获取锁基本就是两步:
- CAS尝试更改state,如果成功修改了state就是抢占成功
- 修改state失败后就进入等待队列,等待队首获取锁的线程执行完后唤起后面的线程
Condition则是在aqs的基础上又维护了一个队列,
public class ConditionObject implements Condition, java.io.Serializable {
/** First node of condition queue. */
private transient Node firstWaiter;
/** Last node of condition queue. */
private transient Node lastWaiter;
}
firstWaiter和lastWaiter就是Condition的队列,标识队列头和队列尾。调用addConditionWaiter();就是入队操作
await的方法主要逻辑:
1、首先调用addConditionWaiter();创建一个节点,把当前节点加入到Condition的队列(此队列为单向链表)
2、然后调用fullyRelease(node);释放AQS锁,并唤醒AQS同步队列等待节点中的一个线程。
3、最后LockSupport.park(this);挂起当前线程。
那么此时会产生两个队列,一个是AQS队列,一个是Condition队列,最后信息如下图:
public final void await() throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
//创建一个节点,添加到Condition队列(单向链表)
Node node = addConditionWaiter();
//释放锁,并唤醒AQS同步等待队列((双向链表))中的一个节点线程
int savedState = fullyRelease(node);
int interruptMode = 0;
//判断当前节点是否存在于AQS队列
while (!isOnSyncQueue(node)) {
//如果不存在于AQS阻塞队列,则说明在Condition队列里,则将该线程挂起阻塞
LockSupport.park(this);
//当前节点线程被唤醒后继续从这里执行
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)
break;
}
//竞争锁
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
//清除Condition队列无效节点
if (node.nextWaiter != null)
unlinkCancelledWaiters();
if (interruptMode != 0)
reportInterruptAfterWait(interruptMode);
}
signal方法主要逻辑:
1、首先验证当前线程是否获取了锁,没有获取锁直接抛异常,没有获得锁的线程是不允许调用condition.signal()方法的;
2、获得condition队列的firstWaiter首部节点,把此节点从condition队列移出,添加到AQS队列中。
3、唤醒AQS中一个等待节点的线程。
public final void signal() {
//验证当前线程是否获得了锁
if (!isHeldExclusively())
throw new IllegalMonitorStateException();
//获取第一个Condition等待节点
Node first = firstWaiter;
if (first != null)
doSignal(first);
}
private void doSignal(Node first) {
do {
//如果链表只有一个节点
if ( (firstWaiter = first.nextWaiter) == null)
lastWaiter = null;
first.nextWaiter = null;
} while (!transferForSignal(first) &&
(first = firstWaiter) != null);
}
final boolean transferForSignal(Node node) {
//把当前节点状态waitStatus从等待condition.变更为新建状态
if (!compareAndSetWaitStatus(node, Node.CONDITION, 0))
return false;
//上一步成功则把当前节点添加到AQS同步队列尾部,返回链表中的原尾部节点
Node p = enq(node);
int ws = p.waitStatus;
//唤醒原尾部节点的等待线程
if (ws > 0 || !compareAndSetWaitStatus(p, ws, Node.SIGNAL))
LockSupport.unpark(node.thread);
return true;
}
详细流程见图
https://www.processon.com/diagraming/5f321a6c0791297d38e26ecc
(参考自:https://zhuanlan.zhihu.com/p/97292945)
JUC包工具的使用
在 Java 中 CycliBarriar 和 CountdownLatch 有什么区别?
CountDownLatch一般用于某个线程A等待若干个其他线程执行完任务之后,它才执行;而CyclicBarrier一般用于一组线程互相等待至某个状态,然后这一组线程再同时执行;CountDownLatch强调一个线程等多个线程完成某件事情。CyclicBarrier是多个线程互等,等大家都完成,再携手共进。
线程池
- worker就是包装后并持有线程的任务,是ThreadPoolExecutor的私有类。(继承了AQS,持有thread,实现runnable)
- 任务是task是runnable的对象
- 一开始提交后线程池中没有worker,提交后调用addworker方法。
- 线程池是基于
生产者-消费者模式来实现的,任务的提交方是生产者,线程池是消费者。
ctl关键字:线程数量和线程池状态
workerCountOf和runStateOf两种方法可读取
一开始学的时候容易将workQueue里的任务也算作线程,其实不是,线程数指活着的worker数。(起名字不太好)
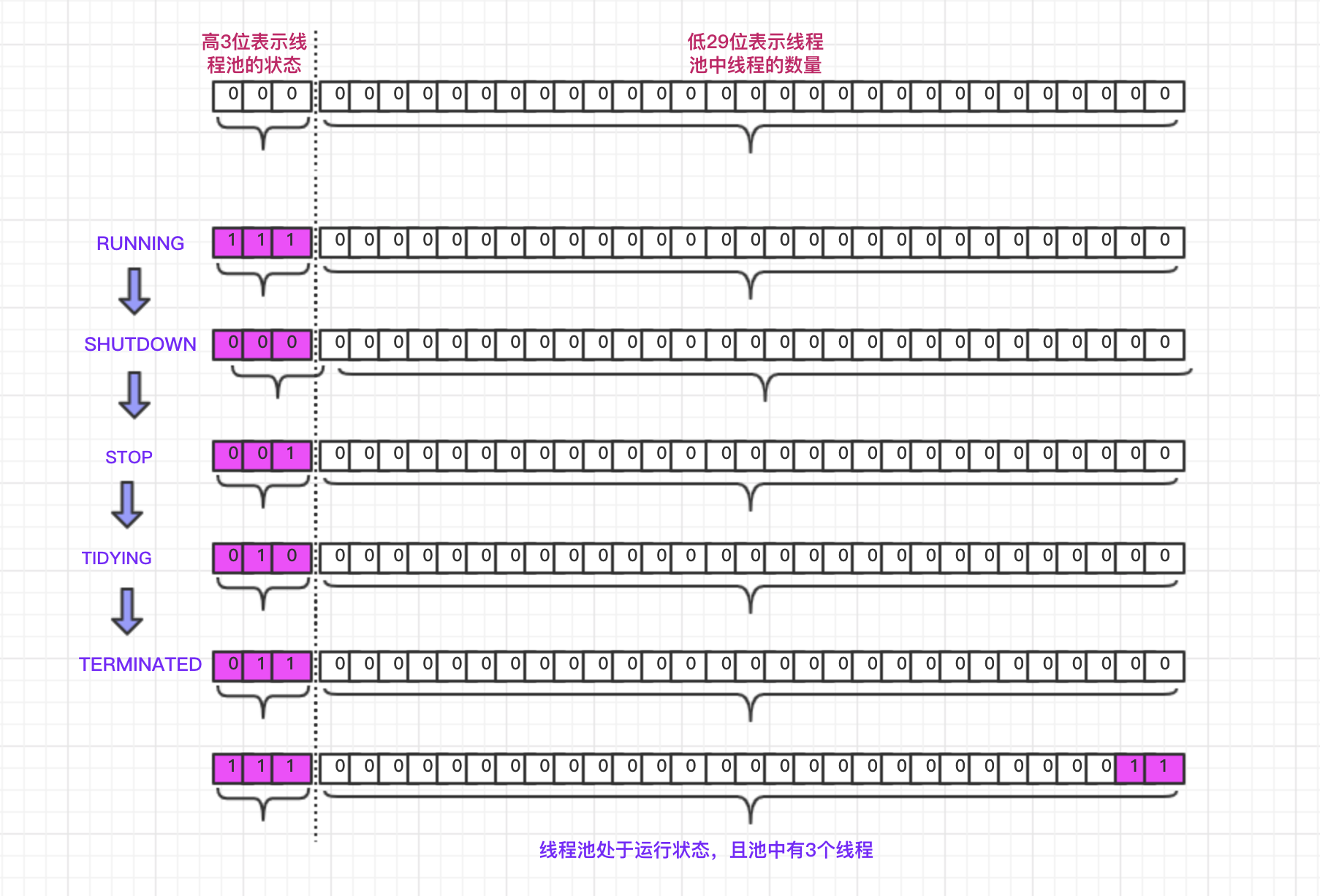
线程池的使用
实验代码
public class FutureTest {
public static class Task implements Callable<String> {
@Override
public String call() throws Exception {
System.out.println("execute!!!");
Thread.sleep(10000);
return "complete";
}
}
public static void main(String[] args) throws InterruptedException,
ExecutionException {
List<Future<String>> results = new ArrayList<Future<String>>();
// 测试拒绝策略
final RejectedExecutionHandler handler =
new ThreadPoolExecutor.CallerRunsPolicy();
ExecutorService executorService = new ThreadPoolExecutor(0, 5,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(),handler);
for (int i = 0; i < 10; i++) {
results.add(executorService.submit(new Task()));
}
for (Future<String> future : results) {
System.out.println(future.get());
}
System.out.println("Main complete");
if (!executorService.isShutdown()) {
executorService.shutdown();
}
}
}
- 创建 :
一般是用Executors进行创建,这个体现了工厂方法。
Executors.newCachedThreadPool():无限线程池。
Executors.newFixedThreadPool(nThreads):创建固定大小的线程池。
Executors.newSingleThreadExecutor():创建单个线程的线程池。
看源码发现还是ThreadPoolExecutor中实现的
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
2,参数
corePoolSize 为线程池的基本大小。
maximumPoolSize 为线程池最大线程大小。
keepAliveTime 和 unit 则是线程空闲后的存活时间。
workQueue 用于存放任务的阻塞队列。
handler 当队列和最大线程池都满了之后的饱和策略。
拒绝策略
拒绝策略在线程池执行任务的execute()方法中用到,有两处地方:
- 线程池此时不处于running状态,调用拒绝策略拒绝任务
- 线程池创建新的Worker失败,调用拒绝策略拒绝任务
几种策略以及源码
- AbortPolicy:
抛出一个异常
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
- DiscardPolicy:
什么都不做
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
- DiscardOldestPolicy
也很简单,如果线程池没有shutdown,那么就讲队列中的任务poll出来一个(对于这个任务什么也不做,就是丢弃掉了最早的任务);然后在调用execute()方法执行刚提交的任务(扔到队列里面)。
把最早入队的抛弃掉,哥们说这个行为叫杀熟,那么我们就把他定名为"xx策略"(xx是一家电商平台名字).
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
e.getQueue().poll();
e.execute(r);
}
}
- CallerRunsPolicy
最流弊的是这个…让提交任务的线程自己来执行(前提是线程池没有shutdown)。哈哈,看到这个策略,发现自己好像又学到了一点。
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();//让提交任务的线程自己run,hhh
}
}
任务调度机制
就看workerCount 与corePoolSize和maximumPoolSize的比较以及阻塞队列满不满。
- 首先检测线程池运行状态,如果不是RUNNING,则直接拒绝,线程池要保证在RUNNING的状态下执行任务。
- 如果workerCount < corePoolSize,则创建并启动一个线程来执行新提交的任务。
- 如果workerCount >= corePoolSize,且线程池内的阻塞队列未满,则将任务添加到该阻塞队列中。
- 如果workerCount >= corePoolSize && workerCount < maximumPoolSize,且线程池内的阻塞队列已满,则创建并启动一个线程来执行新提交的任务。
- 如果workerCount >= maximumPoolSize,并且线程池内的阻塞队列已满, 则根据拒绝策略来处理该任务, 默认的处理方式是直接抛异常。
核心线程池如何扩容
关闭
-
shutdown()
停止接收新任务,原来的任务继续执行;
停止接收新的submit的任务;
已经提交的任务(包括正在跑的和队列中等待的),会继续执行完成;
等到第2步完成后,才真正停止; -
shutdownNow()
停止接收新任务,原来的任务停止执行;
跟 shutdown() 一样,先停止接收新submit的任务;
忽略队列里等待的任务;
尝试将正在执行的任务interrupt中断;
返回未执行的任务列表;
说明:它试图终止线程的方法是通过调用 Thread.interrupt() 方法来实现的,这种方法的作用有限,如果线程中没有sleep、wait、Condition、定时锁等应用, interrupt() 方法是无法中断当前的线程的。所以,shutdownNow() 并不代表线程池就一定立即就能退出,它也可能必须要等待所有正在执行的任务都执行完成了才能退出。但是大多数时候是能立即退出的。
worker原理(aqs)
https://juejin.im/post/6844904000056197127
addwork的源码
- 第一个参数就是我们传入的Runnable任务,第二参数是一个boolean值,传入true表示的是当前线程池中的线程数还没有达到核心线程数,传false表示当前线程数已经大于等于核心线程数了。
- 使用了两个无限for和一个CAS操作来设置线程池的线程数量。如果线程池的线程数修改成功,就中断循环,进入后半部分代码的逻辑,如果修改失败,就利用for循环再一次进行修改,这样的好处是,既实现了线程安全,也避免使用锁,提高了效率。
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
// 1. 当线程池的状态大于SHUTDOWN时,返回false。因为线程池处于关闭状态了,就不能再接受任务了
// 2. 当线程池的状态等于SHUTDOWN时,firstTask不为空或者任务队列为空,返回false
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
int wc = workerCountOf(c);
// 1. 线程数大于等于理论上的最大数(2^29-1),则直接返回false。(因为线程数不能再增加了)
// 2. 根据core来决定线程数应该和谁比较。当线程数大于核心线程数或者最大线程数时,直接返回false。
// (因为当大于核心线程数时,表示此时任务应该直接添加到队列中(如果队列满了,可能入队失败);当大于最大线程数时,肯定不能再新创建线程了,不然设置最大线程数有毛用)
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
// 线程数+1,如果设置成功,就跳出外层循环
if (compareAndIncrementWorkerCount(c))
break retry;
// 再次获取线程池的状态,并将其与前面获取到的值比较,
// 如果相同,说明线程池的状态没有发生变化,继续在内循环中进行循环
// 如果不相同,说明在这期间,线程池的状态发生了变化,需要跳到外层循环,然后再重新进行循环
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
// 省略后半部分代码
// ......
}
addwork的源码2
- 在这一部分代码中,通过
new Worker(firstTask)创建了一个Worker对象,Worker对象继承了AQS,同时实现了Runnable接口,它是线程池中真正干活的人。我们提交到线程的任务,最终都是封装成Worker对象,然后由Worker对象来完成任务。
private boolean addWorker(Runnable firstTask, boolean core) {
// 省略前半部分代码
// ......
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
// 创建一个新的worker线程
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
// 再次获取线程池的状态,因为在获取锁期间,线程池的状态可能改变了
int rs = runStateOf(ctl.get());
// 如果线程池状态时运行状态或者是关闭状态但是firstTask是空,就将worker线程添加到线程池
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
// 判断worker线程是否已经启动了,如果已经启动,就抛出异常
// 个人觉得这一步没有任何意义,因为worker线程是刚new出来的,没有在任何地方启动
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
// 启动线程
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
// 如果启动失败,就将worker线程从线程池移除,并将线程数减1
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
- 先简单看下Woker的构造方法,其源码如下。在构造方法中,首先设置了同步变量state为-1,然后通过ThreadFactory创建了一个线程,
注意在通过ThreadFactory创建线程时,将Worker自身也就是this,传入了进去,也就是说最后创建出来的线程对象,它里面的target属性就是指向这个Worker对象。
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
newThread底层就是创建我们熟悉的Thread,并传入Runnable(下面是Exectors的静态内部类DefaultThreadFactory的方法)
public Thread newThread(Runnable r) {
Thread t = new Thread(group, r,
namePrefix + threadNumber.getAndIncrement(),
0);
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
线程池的状态都是啥?
running
shutdown : 不接受任务,继续执行阻塞队列里的
stop :不接受任务,中断阻塞队列里的任务
tiding :所有任务终止,workcount为0
terminated 调用terminated ()方法后进入该状态。
Callable、Future和FutureTask
Callable与Runnable
都是接口
public interface Callable<V> {
/**
* Computes a result, or throws an exception if unable to do so.
*
* @return computed result
* @throws Exception if unable to compute a result
*/
V call() throws Exception;
}
public interface Callable<V> {
/**
* Computes a result, or throws an exception if unable to do so.
*
* @return computed result
* @throws Exception if unable to compute a result
*/
V call() throws Exception;
}
区别就是使用ExecutorService的不同提交方法(13常用):
<T> Future<T> submit(Callable<T> task);
<T> Future<T> submit(Runnable task, T result);
Future<?> submit(Runnable task);
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null); //转成 RunnableFuture,传的result是null
execute(ftask);
return ftask;
}
public <T> Future<T> submit(Runnable task, T result) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task, result);
execute(ftask);
return ftask;
}
public <T> Future<T> submit(Callable<T> task) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task);
execute(ftask);
return ftask;
}
newTaskFor方法是new了一个FutureTask返回。 所以三个方法其实都是把task转成FutureTask,如果task是Callable,就直接赋值。如果是Runnable 就转为Callable再赋值。
在newTaskFor中,会区分task是Runnable和task是Callable的情况。内部task必须是Callable,如果task是Runnable ,就在Runnable 外面包个Callable马甲
Future
- 是返回结果的操作对象。
Future就是对于具体的Runnable或者Callable任务的执行结果进行取消、查询是否完成、获取结果。必要时可以通过get方法获取执行结果,该方法会阻塞直到任务返回结果。
public interface Future<V> {
boolean cancel(boolean mayInterruptIfRunning);
boolean isCancelled();
boolean isDone();
V get() throws InterruptedException, ExecutionException;
V get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
}
-
cancel方法用来取消任务,如果取消任务成功则返回true,如果取消任务失败则返回false。
-
isCancelled方法表示任务是否被取消成功,如果在任务正常完成前被取消成功,则返回 true。
-
isDone方法表示任务是否已经完成,若任务完成,则返回true;
-
get()方法用来获取执行结果,这个方法会产生阻塞,会一直等到任务执行完毕才返回;
-
get(long timeout, TimeUnit unit)用来获取执行结果,如果在指定时间内,还没获取到结果,就直接返回null。
也就是说Future提供了三种功能:
1)判断任务是否完成;
2)能够中断任务;
3)能够获取任务执行结果。
因为Future只是一个接口,所以是无法直接用来创建对象使用的,因此就有了下面的FutureTask。
FutureTask

事实上,FutureTask是Future接口的一个唯一实现类。
- FutureTask是一个可取消的异步计算,FutureTask 实现了Future的基本方法,提供start cancel 操作
- 当FutureTask处于未启动或已启动状态时,如果此时我们执行FutureTask.get()方法将导致调用线程阻塞;当FutureTask处于已完成状态时,执行FutureTask.get()方法将导致调用线程立即返回结果或者抛出异常。
- 当FutureTask处于未启动状态时,执行FutureTask.cancel()方法将导致此任务永远不会执行。
- 当FutureTask处于已启动状态时,执行cancel(true)方法将以中断执行此任务线程的方式来试图停止任务,如果任务取消成功,cancel(…)返回true;但如果执行cancel(false)方法将不会对正在执行的任务线程产生影响(让线程正常执行到完成),此时cancel(…)返回false。
下面两种使用都可以获取执行结果
-
使用Callable+Future获取执行结果
-
使用Callable+FutureTask获取执行结果
下面是两种的伪码。
ExecutorService es = Executors.newSingleThreadExecutor();
//创建Callable对象任务
CallableDemo calTask=new CallableDemo();
//提交任务并获取执行结果
Future<Integer> future =es.submit(calTask);
...
System.out.println("future.get()-->"+future.get());
...
//创建线程池
ExecutorService es = Executors.newSingleThreadExecutor();
//创建Callable对象任务
CallableDemo calTask=new CallableDemo();
//创建FutureTask
FutureTask<Integer> futureTask=new FutureTask<>(calTask);
//执行任务
es.submit(futureTask);
...
System.out.println("futureTask.get()-->"+futureTask.get());
...
其中
public class CallableDemo implements Callable<Integer> {
...
}
FutureTask和Future的区别
看上面两个例子貌似两者差别不大,实际上有区别:
- FutureTask实现了Runnable,因此它既可以通过Thread包装来直接执行,也可以提交给ExecuteService来执行。因此FutureTask既是Future、Runnable,又包装了Callable( 如果是Runnable最终也会被转换为Callable ,在newTaskFor()方法中包装的), 它是这两者的合体。
- 甚至futureTask.run()也是可以的,因为它是实现类。
下面是通过Thread包装来直接执行:
FutureTask<Integer> futureTask = new FutureTask<Integer>(task);
Thread thread = new Thread(futureTask);
thread.start();
线程池调优
《java性能权威指南》

















 409
409

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









