







 本文探讨了Python和Scala在大数据处理中的竞争。尽管Python因其易用性而广泛使用,但Scala在Spark的支持下展现出强大的功能。文章介绍了Scala的基本特性和安装配置,并通过示例展示了其语法,包括数据类型、类和对象、控制结构等内容,强调了Scala在并发和分布式计算上的优势。
本文探讨了Python和Scala在大数据处理中的竞争。尽管Python因其易用性而广泛使用,但Scala在Spark的支持下展现出强大的功能。文章介绍了Scala的基本特性和安装配置,并通过示例展示了其语法,包括数据类型、类和对象、控制结构等内容,强调了Scala在并发和分布式计算上的优势。
在浏览spark的官网时,机缘巧合的我看到这这样一张图

这其中出现了三个熟悉的身影,Java、Scala、python,作为最近热门讨论的语言,那python和scala在大数据的竞争中到底谁更胜一筹呢?虽然python因为其“胶水”特性,被更多的使用和讨论,但是scala也真的不要小瞧他,他在spark的支撑下,真的也是一门强大的语言,来看一下scala的神秘色彩吧
Scala介绍
1.Spark中使用的是Sacla2.10。
2.Scala官网6个特征。
1).Java和scala可以混编
2).类型推测(自动推测类型)
3).并发和分布式(Actor)
4).特质,特征(类似java中interfaces 和 abstract结合)
5).模式匹配(类似java switch)
6).高阶函数
Scala安装使用
1. windows安装,配置环境变量
Ø 官网下载scala2.10:http://www.scala-lang.org/download/2.10.4.html
Ø 下载好后安装。双击msi包安装,记住安装的路径。
Ø 配置环境变量(和配置jdk一样)
l 新建SCALA_HOME
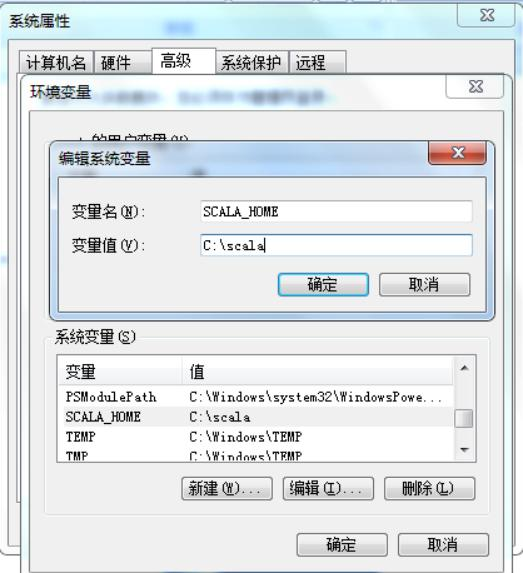
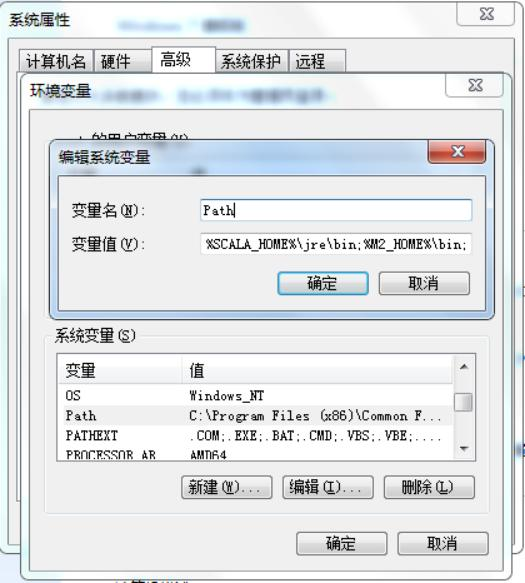
l 上个步骤完成后,编辑Path变量,在后面追加如下:
;%SCALA_HOME%\bin;%SCALA_HOME%\jre\bin
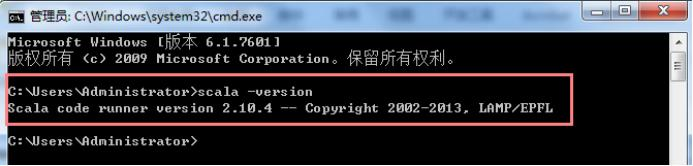
Ø 打开cmd,输入:scala - version 看是否显示版本号,确定是否安装成功
2. eclipse 配置scala插件
Ø 下载插件(一定要对应eclipse版本下载)
http://scala-ide.org/download/prev-stable.html
Ø 下载好zip包后,解压如下:

Ø 将features和plugins两个文件夹拷贝到eclipse安装目录中的” dropins/scala”目录下。进入dropins,新建scala文件夹,将两个文件夹拷贝到“dropins/scala”下
3. scala ide
下载网址:http://scala-ide.org/download/sdk.html
4. idea 中配置scala插件
Ø 打开idea,close项目后,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 783
783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









