








 从加州大学伯克利分校教授的视角,回顾了并行编程的发展历程:从MPI框架到MapReduce模型,再到Hadoop的诞生及其十年辉煌,直至Apache Spark的兴起。Spark在保留MapReduce优点的基础上,引入更多编程模式如SQL、Streaming、ML和Graph,极大简化了大数据时代的并行编程。
从加州大学伯克利分校教授的视角,回顾了并行编程的发展历程:从MPI框架到MapReduce模型,再到Hadoop的诞生及其十年辉煌,直至Apache Spark的兴起。Spark在保留MapReduce优点的基础上,引入更多编程模式如SQL、Streaming、ML和Graph,极大简化了大数据时代的并行编程。
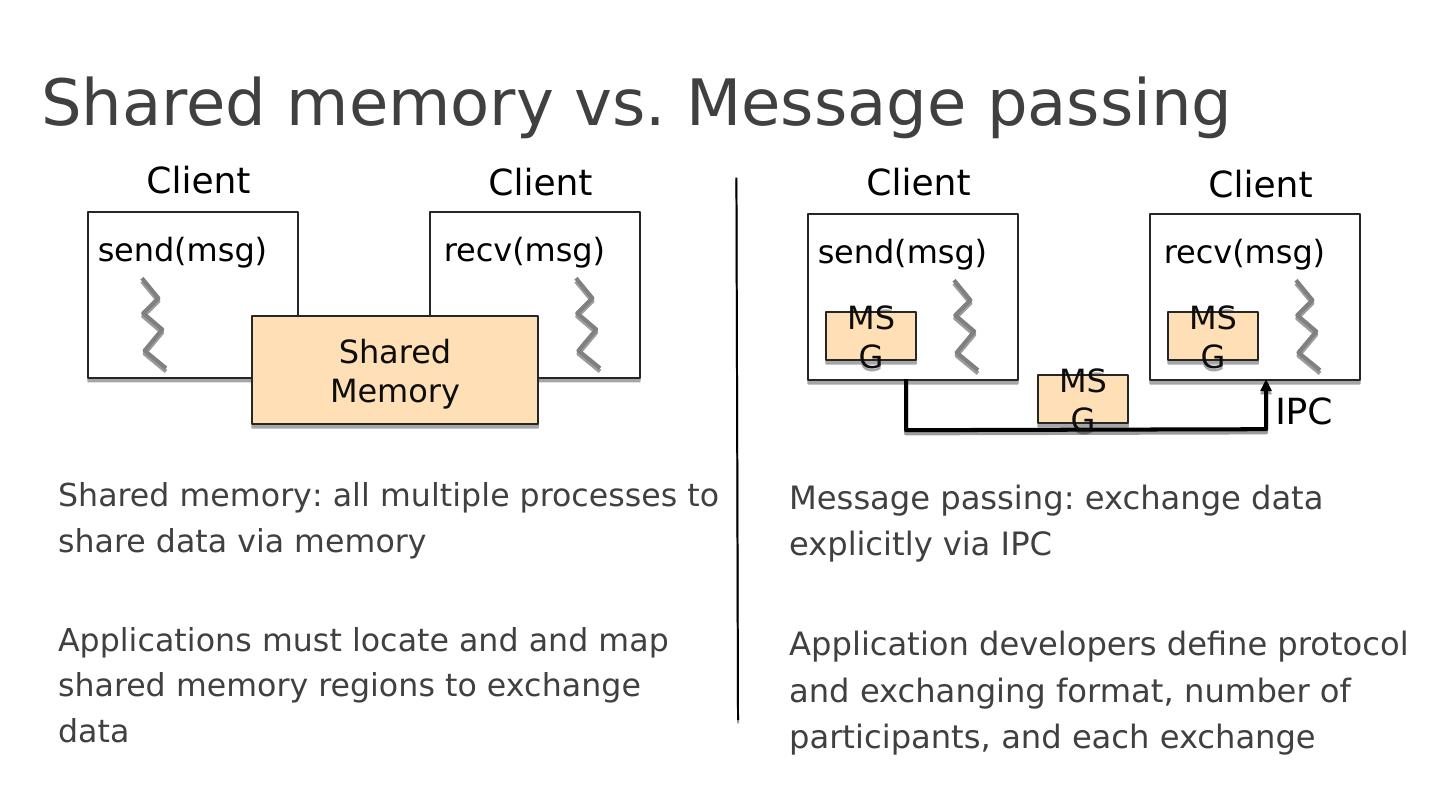
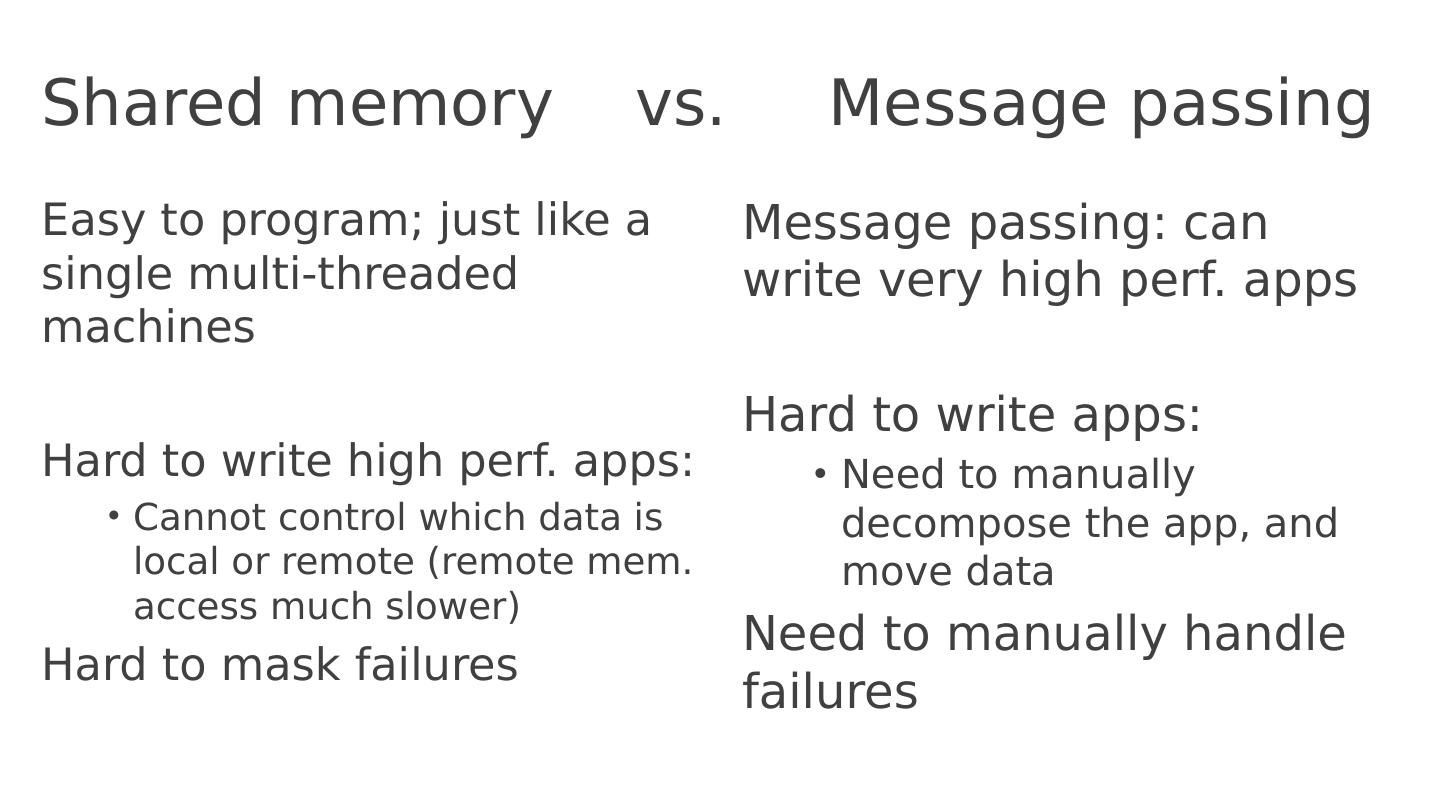
加州大学伯克利分校的教授,从历史发展的角度,讲述了在超级计算机中如何编程,从而引出风行几十年的MPI编程框架,然后这个框架编程过于复杂,进而演化出了MapReduce模型,这个模型的第一个开源实践版本是Hadoop,Hadoop风光了近10年以后,其中的计算引擎MapReduce被Apache Spark所取代,Spark在MapReduce(BSP)模型基础之上,有增加了很多其它编程模式,比如SQL/Streaming/ML/Graph等等,让当今大数据时代的并行编程变得如此简单。本文是整个历史的亲见者和推动者所写,让我们从源头和根本理解并行编程的发展史!





























03-16
 1277
1277
1277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









