







 本文基于1986年Lalonde发布的基准数据集,探讨了就业培训对收入和就业状态的影响。通过Smith&Todd于2005年的研究,引入更大规模的数据集,分析了包括年龄、教育水平等在内的8个协变量。本文构建了一个二元分类任务,旨在预测未来失业的可能性。通过计算干预组的平均干预效应和策略风险,评估了不同模型在ITE估计上的性能。
本文基于1986年Lalonde发布的基准数据集,探讨了就业培训对收入和就业状态的影响。通过Smith&Todd于2005年的研究,引入更大规模的数据集,分析了包括年龄、教育水平等在内的8个协变量。本文构建了一个二元分类任务,旨在预测未来失业的可能性。通过计算干预组的平均干预效应和策略风险,评估了不同模型在ITE估计上的性能。
1986年,Lalonde公开的一个数据集,被因果推理社区作为了基准数据集。在该数据集中,干预(即Treatment)为是否接受就业培训,结果(Outcomes)是收入和就业状况。2005年,Smith & Todd结合了国家对工作工程统计的观测性数据,扩展成了一个更大的数据集——随机分组使得因果效应的ground truth可以被估计。这项数据集共包含8个协变量,比如说年龄、教育程度、先前收入…本文在此基础上,采用2002年Dehejia & Wahba提出的特征集,构建了一个二元分类任务,Jobs,其目标是去预测是否未来失业。基于2005年Smith & Todd的研究工作,本文用到的数据样本来自LaLonde数据集(干预组:297;控制组:425)和PSID对比组(控制组:2490)。截至研究结束,共有482名受试者(约15%)失业。我们按比例56/24/20随机划分train/validation/test数据集,并做了10次实验,然后将其结果平均。
因为所有干预组成员(297)都是原始随机样本E(LaLonde数据集)的一部分,因此我们可以估计干预组的平均干预效应:
A
T
T
=
∣
T
∣
−
1
∑
i
∈
T
y
i
−
∣
C
∩
E
∣
−
1
∑
i
∈
C
∩
E
y
i
\mathrm{ATT}=|T|^{-1} \sum_{i \in T} y_{i}-|C \cap E|^{-1} \sum_{i \in C \cap E} y_{i}
ATT=∣T∣−1∑i∈Tyi−∣C∩E∣−1∑i∈C∩Eyi,其中
C
C
C代表控制组。估计误差即为:
ϵ
A
T
T
=
∣
A
T
T
−
1
∣
T
∣
∑
i
∈
T
(
f
(
x
i
,
1
)
−
f
(
x
i
,
0
)
)
∣
\epsilon_{\mathrm{ATT}}=| \mathrm{ATT}-\frac{1}{|T|} \sum_{i \in T}\left(f\left(x_{i}, 1\right)-\right.\left.f\left(x_{i}, 0\right)\right)|
ϵATT=∣ATT−∣T∣1∑i∈T(f(xi,1)−f(xi,0))∣。在这个数据集上我们无法评估
ϵ
P
E
H
E
\epsilon_{\mathrm{PEHE}}
ϵPEHE,因为我们没有可用于
I
T
E
ITE
ITE评估的
g
r
o
u
n
d
ground
ground
t
r
u
t
h
truth
truth。因此,为了评估模型
I
T
E
ITE
ITE估计的性能,我们选取的指标为:策略风险。
I
T
E
ITE
ITE估计器采用策略在训练时的策略风险被视为平均损失(loss)。在本文设计中,对于模型函数
f
f
f,我们的干预策略为:
π
f
(
x
)
=
1
,
f
(
x
,
1
)
−
f
(
x
,
0
)
>
λ
\pi_{f}(x)=1,f(x, 1)-f(x, 0)>\lambda
πf(x)=1,f(x,1)−f(x,0)>λ;我们的控制策略为:
π
f
(
x
)
=
1
,
o
t
h
e
r
w
i
s
e
\pi_{f}(x)=1,otherwise
πf(x)=1,otherwise。该策略风险即为:
R
P
o
l
(
π
f
)
=
1
−
(
E
[
Y
1
∣
π
f
(
x
)
=
1
]
⋅
p
(
π
f
=
1
)
+
E
[
Y
0
∣
π
f
(
x
)
=
0
]
⋅
p
(
π
f
=
0
)
)
R_{\mathrm{Pol}}\left(\pi_{f}\right)=1-\left(\mathbb{E}\left[Y_{1} | \pi_{f}(x)=1\right] \cdot p\left(\pi_{f}=1\right) +\mathbb{E}\left[Y_{0} | \pi_{f}(x)=0\right] \cdot p\left(\pi_{f}=0\right)\right)
RPol(πf)=1−(E[Y1∣πf(x)=1]⋅p(πf=1)+E[Y0∣πf(x)=0]⋅p(πf=0))。我们可以采用下式估计随机试验子集的策略风险值
R
^
P
o
l
(
π
f
=
1
−
(
E
[
Y
1
∣
π
f
(
x
)
=
1
,
t
=
1
]
⋅
p
(
π
f
=
1
)
+
E
[
Y
0
∣
π
f
(
x
)
=
0
,
t
=
0
]
⋅
p
(
π
f
=
0
)
)
\hat{R}_{\mathrm{Pol}}\left(\pi_{f}=1-\left(\mathbb{E}\left[Y_{1} | \pi_{f}(x)=1, t=1\right] \cdot p\left(\pi_{f}=1\right)+\mathbb{E}\left[Y_{0} | \pi_{f}(x)=0, t=0\right] \cdot p\left(\pi_{f}=0\right)\right)\right.
R^Pol(πf=1−(E[Y1∣πf(x)=1,t=1]⋅p(πf=1)+E[Y0∣πf(x)=0,t=0]⋅p(πf=0)) 干预阈值
λ
λ
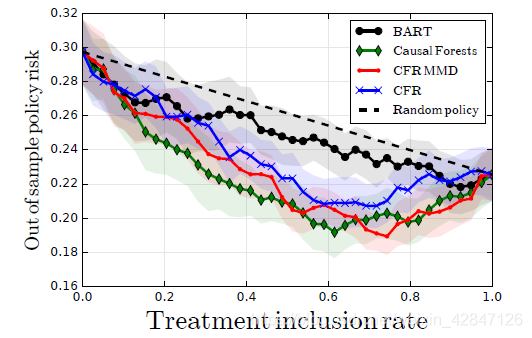
λ的函数风险如下图所示,按干预比例排列。

















 3466
3466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









