






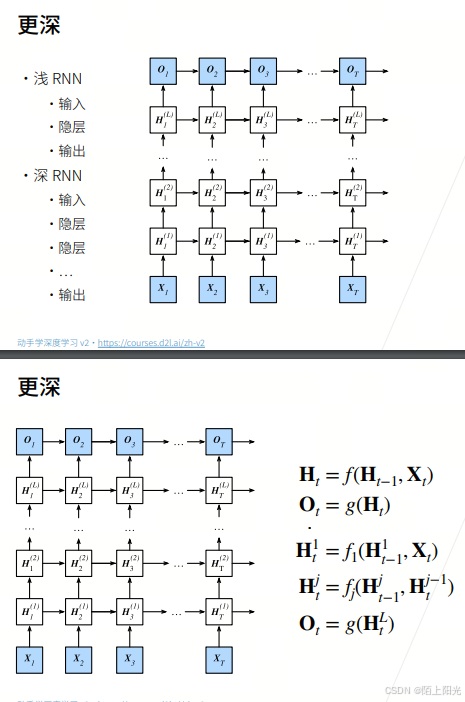
1. 深度循环神经网络
序列变长不是深度。 多加几个隐藏层。


多加隐藏层,和MLP没区别

右走:下一个时间步

代码
rnn不会用特别深的网络。深度网络在模型复杂度上更好,overfitting上更多。rnn一般用2层。
import torch
from torch import nn
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = load_data_time_machine(batch_size, num_steps)
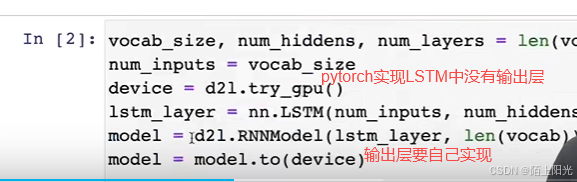
vocab_size, num_hiddens, num_layers = len(vocab), 256, 2
num_inputs = vocab_size
device = d2l.try_gpu()
lstm_layer = nn.LSTM(num_inputs, num_hiddens, num_layers)
model = RNNModel(lstm_layer, len(vocab))
model = model.to(device)
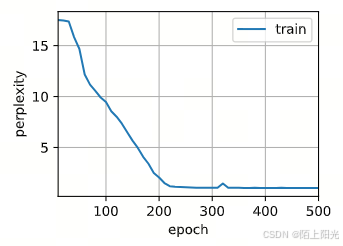
num_epochs, lr = 500, 2
train_ch8(model, train_iter, vocab, lr*1.0, num_epochs, device)
困惑度 1.0, 234109.9 词元/秒 cuda:0
time travelleryou can show black is white by argument said filby
travelleryou can show black is white by argument said filby
QA

14 一个个的隐藏层
15 文本翻译很成熟,不会再做很多工作。
16 书上有讲原理
17 是的。每一层都带了初始的weight
18 一般不会自己改hidden_size 不会用很深的网络,两层。

H:上一层的输出作为输出,又作为本层下一个时刻的输入和下一层的输入


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









