




SkyWalking 是一个开源的 应用性能监控系统(APM),专为云原生、微服务架构设计。其核心原理基于 分布式追踪(Distributed Tracing)、指标收集(Metrics Collection) 和 日志关联(Log Correlation),通过无侵入或轻量级的方式实现全链路监控。
一、整体架构与组件原理
SkyWalking 采用 四层架构 设计,各组件分工明确:
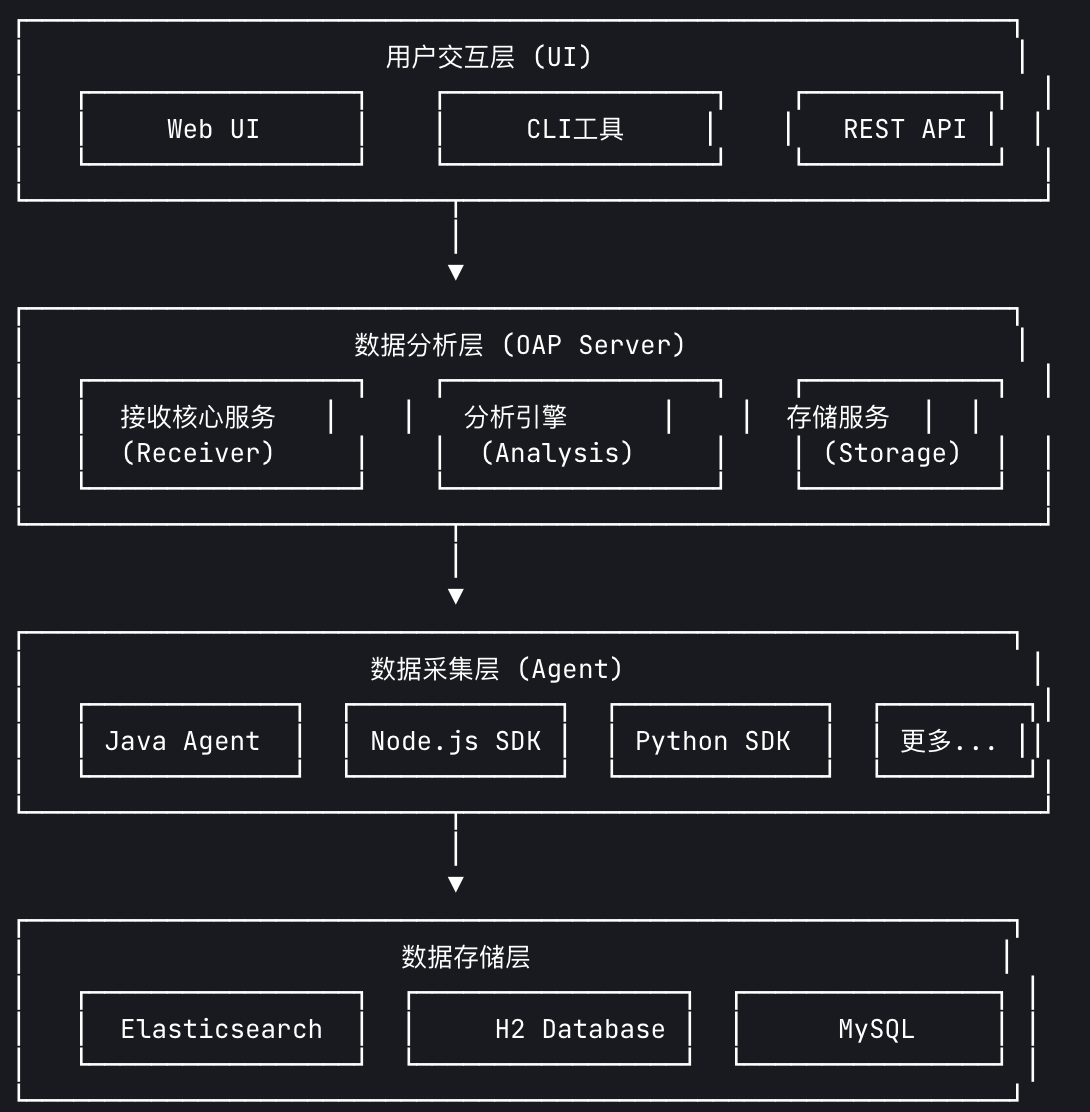
1. Agent(数据采集层)
- 功能:
- 无侵入式监控:通过字节码增强技术(如 Java Agent)自动收集应用性能数据。
- 轻量级 SDK:为非 Java 语言(如 Node.js、Python)提供手动埋点 SDK。
- 采集内容:
- 请求链路数据(Trace):记录请求在各服务间的调用路径和耗时。
- 指标数据(Metrics):如响应时间、吞吐量、错误率。
- 环境元数据:服务拓扑关系、实例信息。
2. OAP Server(数据分析层)
- 接收核心服务(Receiver):
- 支持多种协议接收数据:如 gRPC、HTTP、Kafka、Zipkin 等。
- 数据格式转换:将不同来源的数据统一为内部格式。
- 分析引擎(Analysis):
- 流处理:实时分析数据流,计算指标(如 P99 响应时间)。
- 关联分析:将 Trace、Metrics 和日志关联,构建服务拓扑图。
- 告警引擎:基于规则触发告警(如响应时间超过阈值)。
- 存储服务(Storage):
- 支持多种存储后端:Elasticsearch、H2、MySQL、TiDB 等。
3. UI(用户交互层)
- 提供可视化界面,展示:
- 服务拓扑图:直观呈现服务间依赖关系。
- 性能指标面板:如 QPS、响应时间趋势。
- 分布式追踪详情:查看完整调用链和瓶颈点。
- 告警历史:查看和管理触发的告警。
二、分布式追踪原理
1. 基本概念
- Span(跨度):
- 表示调用链中的一个操作单元(如一次方法调用、SQL 查询)。
- 包含元数据:操作名称、开始 / 结束时间、标签(如错误信息)。
- Trace(追踪):
- 由多个 Span 组成的有向无环图(DAG),表示一次完整请求的路径。
- 上下文传递:
- 通过 HTTP Header 或消息队列传递 TraceID 和 SpanID,跨服务追踪。
2. 追踪流程
plaintext
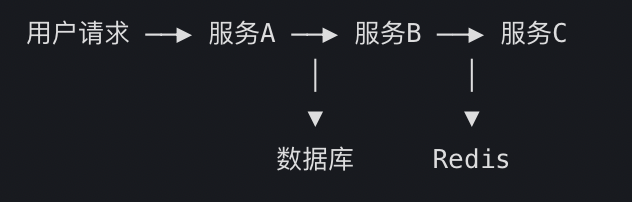
- 客户端发起请求:生成全局唯一的 TraceID 和根 SpanID。
- 服务 A 处理请求:
- 记录自身 Span 信息(如处理时间)。
- 将 TraceID 和 SpanID 通过 HTTP Header 传递给服务 B。
- 服务 B 接收请求:
- 提取 TraceID 和 SpanID,创建子 Span。
- 继续传递上下文到服务 C。
- 数据聚合:
- 各服务将 Span 数据发送给 OAP Server。
- OAP Serv
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









