




 本文对比了Python中列表推导式与生成器的优缺点,列表推导式执行速度快,适合小数据量;生成器节省内存,适用于大数据处理。通过字节码分析,揭示了列表推导式为何更快,同时指出生成器遍历数据的特性。
本文对比了Python中列表推导式与生成器的优缺点,列表推导式执行速度快,适合小数据量;生成器节省内存,适用于大数据处理。通过字节码分析,揭示了列表推导式为何更快,同时指出生成器遍历数据的特性。
列表推导式
优点:如果生成列表的方式不太复杂,这是建议使用列表推导式,其内部是通过cpython来实现的比较用for循环要快;列表推导式可以遍历任意次。
缺点:一次性加载所有的数据到内存,不适合大量数据。
生成器
生成器可以使用yield关键字编写也可以使用生成器表达式即把[]改成(),不会将所有的值一次性加载到内存中,延迟计算,一次返回一个结果,它不会一次生成所有的结果,这对大数据量处理,非常有用。
生成器遍历数据只能遍历一次。
下面举列子说明。
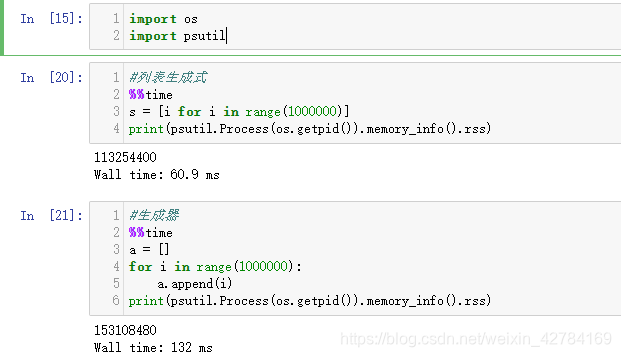
从上面可以看出,生成相同数据量的列表,列表生成式所用的时间不到生成器的一半。这也是列表生成式的优点。
下面再看一下内存的占用情况。
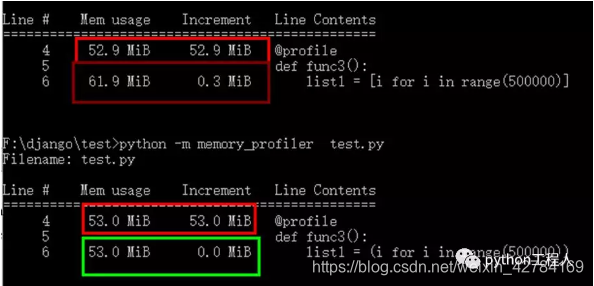
可以看到,生成器生成数据,但是increment都为0,生成器的优点是省内存(生成器不会一次将所用的值返回,可以在需要的时候再取,因此不会有大量数据一直占用内存。)
遍历数据次数
生成器只能遍历一次。
generator = (i for i in range(1,5))
print(next(generator))
print(next(generator))
for i in generator:
print(i)
for i in generator:
print(i)
1
2
3
4
列表可以无限遍历
list1 = [i for i in range(1,5)]
print(list1[0])
print(list1[1])
print(list1[2])
for i in list1:
print(i)
for i in list1:
print(i)
1
2
3
1
2
3
4
1
2
3
4
为什么列表生成式会更快?
这是因为,列表推导式被编译后的字节码执行速度更快。python当然不是一门编译型语言,但是它还是要被解析成二进制的字节码才能被执行,执行它的正是python解释器。
通过dis模块对原生的代码分析,通过它,我们可以查看python代码被编译后的字节码。
查看dis中的api的解释,地址:https://docs.python.org/2/library/dis.html
- dis.dis([bytesource])
btesource对象可以表示一个模块、一个类、一个方法、一个函数或一个代码对象。对于模块,它分解了所有的函数。对于一个类,它分解所有的方法。对于单个代码序列,它在每个字节码指令中打印一行。如果没有提供对象,它将分解最后一个回溯对象。
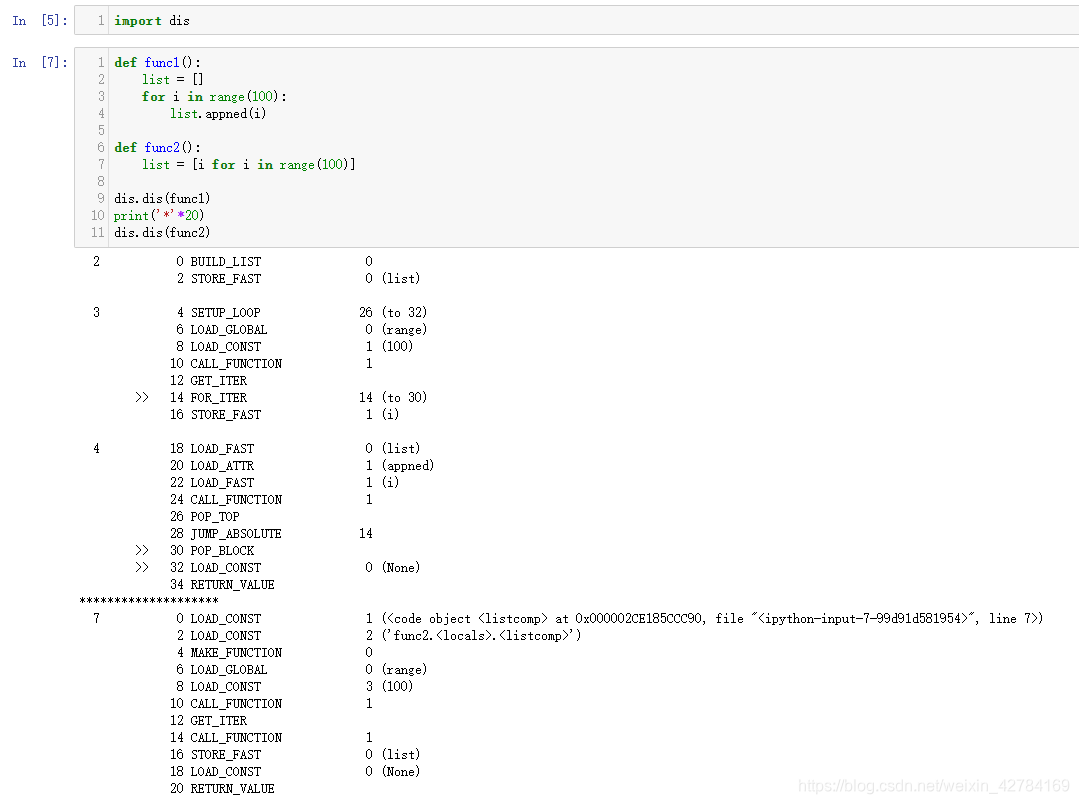
对比一下,不难发现,两个段字节码最大的区别在于添加元素的部分
func1 中,先要LOAD_ATTR,将append方法加载进来,然后CALL_FUNCTION,也就是执行
而在func2中,则直接调用了LIST_APPEND命令来添加元素,就是这一个小小的区别,使得列表推导式的速度会更快,因为func1相比于func2多了一个LOAD_ATTR的过程,要明白,这条命令在每次循环中都会被执行,一旦循环的次数多起来,就必然拖慢速度。
参考:
https://www.jianshu.com/p/2244651d22a3
https://blog.youkuaiyun.com/jimmy_gyn/article/details/79142101
https://mp.weixin.qq.com/s/jiBmEb0DmMxPm5q2182rlw

















 1646
1646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









