







机器学习应用分析–有监督算法-分类算法
目录
①监督学习
数据集中的每个样本有相应的“正确答案”, 根据这些样本做出预测, 分有两类: 回归问题和分类问题。
( 1) 回归问题举例
例如: 预测房价, 根据样本集拟合出一条连续曲线。
( 2) 分类问题举例
例如: 根据肿瘤特征判断良性还是恶性,得到的是结果是“良性”或者“恶性”, 是离散的。
监督学习:从给定的训练数据集中学习出一个函数(模型参数), 当新的数据到来时,可以根据这个函数预测结果。监督学习的训练集要求包括输入输出,也可以说是特征和目标。训练集中的目标是由人标注的。
监督学习包含 分类问题/回归问题/降维(LDA)https://blog.youkuaiyun.com/sinat_30353259/article/details/81569550/集成学习(Ensemble Learning)
②无监督学习
无监督学习:输入数据没有被标记,也没有确定的结果。样本数据类别未知, 需要根据样本间的相似性对样本集进行分类(聚类, clustering)试图使类内差距最小化,类间差距最大化。
实际应用中, 不少情况下无法预先知道样本的标签,也就是说没有训练样本对应的类别,因而只能从原先没有样本标签的样本集开始学习分器设计
常见应用场景:聚类和数据降维
PCA和很多deep learning算法都属于无监督学习
③半监督学习
半监督学习: 即训练集同时包含有标记样本数据和未标记样本数据。
④强化学习Qlearning
实质是: make decisions问题,即自动进行决策,并且可以做连续决策。
主要包含四个元素: agent, 环境状态, 行动, 奖励;
强化学习的目标就是获得最多的累计奖励。
应用场景:强化学习目前还不够成熟,应用场景也比较局限。最大的应用场景就是游戏了。
一个典型的强化学习场景:
· 机器有一个明确的小鸟角色——代理
· 需要控制小鸟飞的更远——目标
· 整个游戏过程中需要躲避各种水管——环境
· 躲避水管的方法是让小鸟用力飞一下——行动
· 飞的越远,就会获得越多的积分——奖励
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dfO3SVQ7-1644566845678)(C:\Users\10982\AppData\Roaming\Typora\typora-user-images\image-20210418200641691.png)]
一 有监督之分类问题
分类问题:
-
感知机(perceptron)
-
KNN算法
-
决策树
-
朴素贝叶斯
-
logistic回归
-
支持向量机SVM
1.1感知机(perceptron)
2.1.1应用场景:
2.1.2算法思想:
二类分类的线性分类模型,是神经网络和支持向量机的基础。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PDvLJYjT-1644566845679)(C:\Users\10982\AppData\Roaming\Typora\typora-user-images\image-20210730180715905.png)]
2.1.3 计算流程:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KekvZWxn-1644566845680)(C:\Users\10982\AppData\Roaming\Typora\typora-user-images\image-20210730181021983.png)]
1.1 k-近邻(KNN)算法
1.1.1 应用场景:
有字符识别、 文本分类、 图像识别等领域。
- 需要一个特别容易解释的模型的时候。比如需要向用户解释原因的推荐算法。
1.1.2算法思想:
一个样本与数据集中的k个样本最相似, 如果这k个样本中的大多数属于某一个类别, 则该样本也属于这个类别。
1.1.3计算流程:
1) 计算已知类别数据集中的点与当前点之间的距离
2) 按距离递增次序排序
3) 选取与当前点距离最小的k个点
4) 统计前k个点所在的类别出现的频率
5) 返回前k个点出现频率最高的类别作为当前点的预测分类
优点:
1、简单有效
2、重新训练代价低
3、算法复杂度低
4、适合类域交叉样本
5、适用大样本自动分类
缺点:
1、惰性学习
2、类别分类不标准化
3、输出可解释性不强
4、不均衡性
5、计算量较大
1.1.4 调包实战
例子1[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eHOHjT9T-1644566845680)(C:\Users\10982\AppData\Roaming\Typora\typora-user-images\image-20210417091937644.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Yvl2WN8h-1644566845680)(C:\Users\10982\AppData\Roaming\Typora\typora-user-images\image-20210417092035779.png)]
import math movie_data = { "宝贝当家": [45, 2, 9, "喜剧片"], "美人鱼": [21, 17, 5, "喜剧片"], "澳门风云3": [54, 9, 11, "喜剧片"], "功夫熊猫3": [39, 0, 31, "喜剧片"], "谍影重重": [5, 2, 57, "动作片"], "叶问3": [3, 2, 65, "动作片"], "伦敦陷落": [2, 3, 55, "动作片"], "我的特工爷爷": [6, 4, 21, "动作片"], "奔爱": [7, 46, 4, "爱情片"], "夜孔雀": [9, 39, 8, "爱情片"], "代理情人": [9, 38, 2, "爱情片"], "新步步惊心": [8, 34, 17, "爱情片"]} # 测试样本 唐人街探案": [23, 3, 17, "?片"] #下面为求与数据集中所有数据的距离代码: x = [23, 3, 17] KNN = [] for key, v in movie_data.items(): d = math.sqrt((x[0] - v[0]) ** 2 + (x[1] - v[1]) ** 2 + (x[2] - v[2]) ** 2) KNN.append([key, round(d, 2)]) # 输出所用电影到 唐人街探案的距离 print(KNN) #按照距离大小进行递增排序 KNN.sort(key=lambda dis: dis[1]) #选取距离最小的k个样本,这里取k=5; KNN=KNN[:5] print(KNN) #确定前k个样本所在类别出现的频率,并输出出现频率最高的类别 labels = { "喜剧片":0,"动作片":0,"爱情片":0} for s in KNN: label = movie_data[s[0]] labels[label[3]] += 1 labels =sorted(labels.items(),key=lambda l: l[1],reverse=True) print(labels,labels[0][0],sep='\n')
调包实战—例子2
糖尿病预测
(数据链接:https://pan.baidu.com/s/1gqaGuQ9kWZFfc-SXbYFDkA 密码:lxfx)
import numpy as np import pandas as pd #读入数据 data = pd.read_csv('data/pima-indians-diabetes/diabetes.csv') data.head()
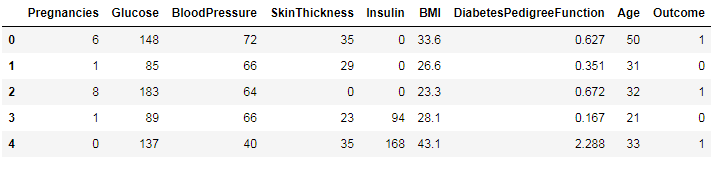
简单看下各字段的意思:
Pregnancies:怀孕的次数
Glucose:血浆葡萄糖浓度
BloodPressure:舒张压
SkinThickness:肱三头肌皮肤皱皱厚度
Insulin: 胰岛素
BMI:身体质量指数
Dia…:糖尿病血统指数
Age:年龄
Outcone:是否糖尿病,1为是
我们把数据划分为特征和label,前8列为特征,最后一列为label。
X = data.iloc[:, 0:8] Y = data.iloc[:, 8] #切分数据集在模型训练前,需要将数据集切分为训练集和测试集(73开或者其它),这里选择82开,使用sklearn中model_selection模块中的train_test_split方法。 from sklearn.model_selection import train_test_split X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=22)
这里的test_size为测试集的比例,random_state为随机种子,这里可设置任意数字,保证下次运行同样可以选择出对应的训练集和测试集
模型训练与评估
KNN算法使用sklearn.neighbors模块中的KNeighborsClassifier方法。常用的参数如下:
- n_neighbors,整数,也就是k值。
- weights,默认为‘uniform’;这个参数可以针对不同的邻居指定不同的权重,也就是说,越近可以权重越高,默认是一样的权重。‘distance’可以设置不同权重。
在sklearn.neighbors还有一个变种KNN算法,为RadiusNeighborsClassifier算法,可以使用一定半径的点来取代距离最近的k个点。
接下来,我们通过设置weight和RadiusNeighborsClassifier,对算法进行比较from sklearn.neighbors import KNeighborsClassifier,RadiusNeighborsClassifier model1 = KNeighborsClassifier(n_neighbors=2) model1.fit(X_train, Y_train) score1 = model1.score(X_test, Y_test) model2 = KNeighborsClassifier(n_neighbors=2, weights='distance') model2.fit(X_train, Y_train) score2 = model2.score(X_test, Y_test) model3 = RadiusNeighborsClassifier(n_neighbors=2, radius=500.0) model3.fit(X_train, Y_train) score3 = model3.score(X_test, Y_test) print(score1, score2, score3) #result #0.714285714286 0.701298701299 0.649350649351
可以看出,还是默认情况的KNN算法结果最好。
交叉验证
通过上述结果可以看出:默认情况的KNN算法结果最好。这个判断准确么?答案是不准确,因为我们只是随机分配了一次训练和测试样本,可能下次随机选择训练和测试样本,结果就不一样了。这里的方法为:交叉验证。我们把数据集划分为10折,每次用9折训练,1折测试,就会有10次结果,求十次的平均即可。当然,可以设置cv的值,选择不同的折数。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









