






举例解释bitmap数据结构和算法
给定一块长度是10bit的内存空间,想要依次插入整型数据4,2,1,3.我们需要怎么做呢?
1. 给定长度是10的bitmap,每一个bit位分别对应着从0到9的10个整型数。此时bitmap的所有位都是0。

2. 把整型数4存入bitmap,对应存储的位置就是下标为4的位置,将此bit置为1。

3. 把整型数2存入bitmap,对应存储的位置就是下标为2的位置,将此bit置为1。

4. 把整型数1存入bitmap,对应存储的位置就是下标为1的位置,将此bit置为1。

5. 把整型数3存入bitmap,对应存储的位置就是下标为3的位置,将此bit置为1。

如果求此时bitmap里存储了哪些元素?显然是4,3,2,1,一目了然。
Bitmap不仅方便查询,还可以去除掉重复的整型数。做位运算的交并差运算效率高。
用项目指标来举例。
如下图,每一行是一条数据。
| 时间 | 广告位 | SDK版本 | cuid(设备id,bitmap存储) |
| 2024-01-01 11:11:11 | 1 | 2 | 1 |
| 2024-01-01 11:11:11 | 2 | 1 | 3 |
| 2024-01-02 11:11:11 | 1 | 1 | 2 |
| 2024-01-02 11:11:11 | 1 | 1 | 3 |
如筛选条件为时间=2024-01-01,DAU为2(1,3)
如筛选条件为时间=2024-01,广告位为1,DAU为3(1,2,3)
当然我们存储使用的是预聚合引擎,所以上面数据在数据表中会是下面的样子。除了bitmap类型和聚合类型(如SUM)的字段。其它字段均为主键。
当然,上面筛选的计算结果还是相同的。bitmap相当于存储了所以得明细数据。
| 日期 | 小时 | 广告位 | SDK版本 | cuid(设备id,bitmap存储) |
| 2024-01-01 | 11 | 1 | 2 | 1 |
| 2024-01-01 | 11 | 2 | 1 | 3 |
| 2024-01-02 | 11 | 1 | 1 | 2,3(示意,不可见) |
bitmap的优点
如果上表的cuid字段使用HashSet或者TreeSet也是可以保证计算结果是准确的。但是无论是内存还是计算速度角度,bitmap的好处都是遥遥领先。内存上考虑,如果使用HashSet每个用户按int型存,即32bit。而一个用户在Bitmap中只占一个bit,内存节省32倍!
不仅如此,在计算方面BItmap对比HashSet的提升更是巨大的。比如要统计2024-01-01的uv。只需要将选中行的bitmap做并集运算即可。Bitmap在做交集和并集运算的时候因为是位运算所以性能非常高。
如果使用HashSet,则需要每行取值遍历去重。当选中行数量增加时,需要的计算量将非常大。
bitmap的缺点
bitmap不擅长处理离散程度大的数据。会有很大的空间浪费。
比如第一个bitmap数是1,第二个bitmap数是1000000。那我要存这两个数就要准备一百万个bit。
当然,成熟的bitmap已经做了优化。在数据稀疏的情况下会自动使用Roaring Bitmap格式来存储数据。大大的降低了空间浪费的情况。但是这样就牺牲的计算高性能。因此在使用bitmap时。还是要尽量降低数据的离散程度。
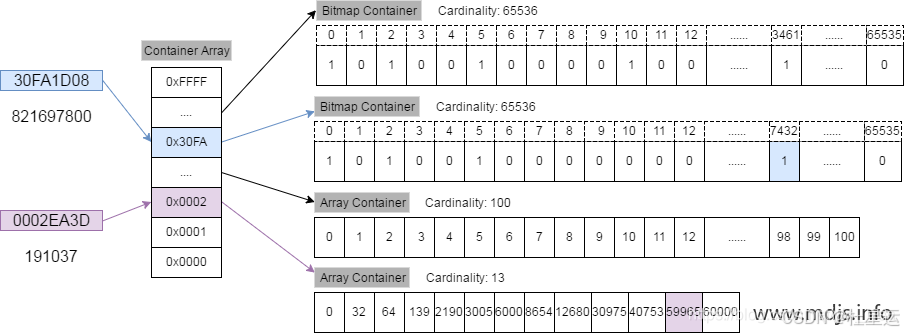
Roaring Bitmap简介
RoaringBitmap的原理并不复杂,但是实现还是挺复杂的。这里就简单介绍一下算法思想。其主要思想是在存储和查询数值的时候。将目标也就是32位整数划分为高16位和低16位,取高16位值进行计算,计算出的结果代表应该存储的桶(Container)的编号,然后再将这个数的低16位值存放在相应的Container中。
图示:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









