






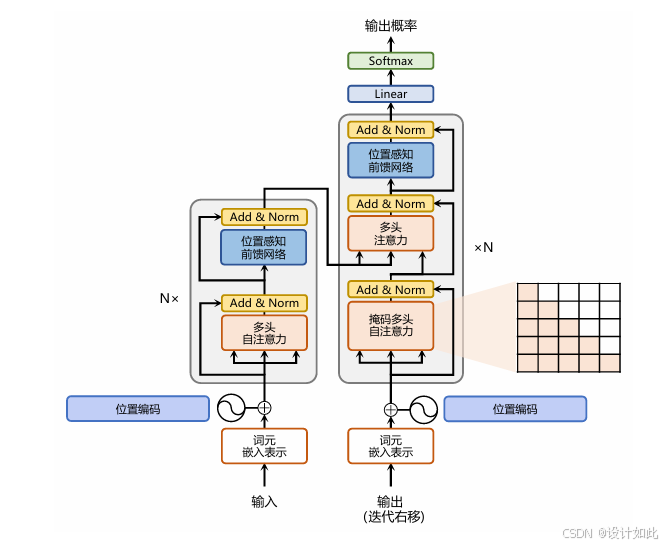
自注意力(Self-Attention)操作是基于Transformer的机器翻译模型的基本操作,在源语言的编
码和目标语言的生成中频繁地被使用以建模源语言、目标语言任意两个单词之间的依赖关系。
一句话**“我”“要”“吃”“饭”**是如何来计算每个词的关系的呢
1、首先通过对每个词进行embedding得到每个词的词向量
(word2vec),假如每个词是个4维向量:
我“0.2,0.5,0.7,0.5”,
要“0.2,0.3,0.8,0.5”,
吃“0.1,0.5,0.6,0.3”
饭“0.3,0.4,0.4,0.8”
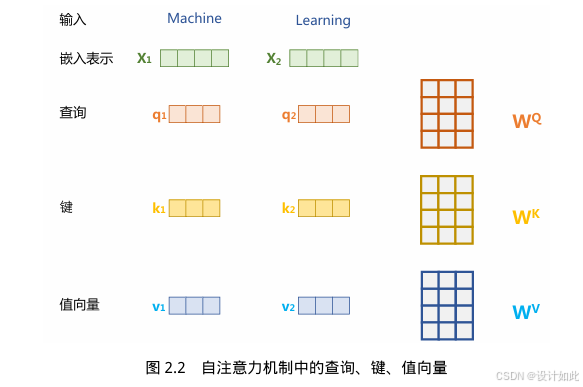
2、计算每个词的在这句话的每个词与其他词的上下文关系
query、keys、values(q、k、v都是矩阵用来辅助理解每个词与其他上下文的关系):
Q、K、V是怎么来的?
Q:要去查询的
K:等待被查询的
V:实际的特征值
一开始是给他们三个矩阵先初始化随机值,然后通过模型训练得到的参数也就是W,所以写成这样Wq、Wk、Wv
3、计算关系:
由谁来发起计算就用谁的q矩阵,比如“我”这个向量要算和其他几个词的上下文关系,q就用“我”这个词的矩阵
我:q1、k1、v1
要:q2、k2、v2
吃:q3、k3、v3
饭:q4、k4、v4
”我“这个词在这句话的中与其他词的关系:q1k1+q1k2+q1k3+q1k4
就是两个矩阵求内积然后相加,内积越大说明两个词的关系越近
其他的词算法一样
4、softmax归一化
4.1 什么是归一化?为什么要进行归一化?
归一化就是把一组数据进行计算这一个数据在这组数据中占比的概率分布?
比如经过第三个步骤的关系计算得出
【“我”】这句话的内积是【3.2,2.3,1.8,5.1】然后经过一个E的x幂的映射得到【140,40,30,180】然后经过归一化计算:
【0.358,0.102,0.077,0.461】(就是“我”这个词=140/(140+40+30+180),整个组的词概率相加等于1)
4.2 求内积之后为什么还要除以根号下√d?
q和k都代表是一个词的特征值,也就是维度越大,内积越大,这样是不准确的(就好比是刻画一个人的特征点越多,这个人就越好。这样算是不准确的)
所以要除以一个根号下√d来降维。根号下√d也就是两个内积的维度,也就是缩放因子
5、计算每个词在这句话中所占的比重
我:z=0.358*v1+0.102*v2+0.077*v3+0.461*v4
其他词的算法一样
6、最后附上公式算法
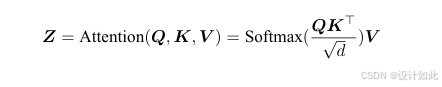


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









