







Python网易云爬虫——实现网易云歌词的爬取(输入歌手的id,即可实现歌词的爬取)
开始动手
打开网易云音乐,找到任意一位歌手的歌曲界面(我们以邓紫棋的《来自天堂的魔鬼》为例)。
第一步:尝试常规思路,把网页的源码爬下来,直接对源码的分析,提取出来对应的歌词。上代码:
import requests #引入request库
url = 'http://music.163.com/#/song?id=36270426' #网页的url
r = requests.get(url) #用get的方法获取网页的源码
print(r.text) #打印出来
运行结果:
<!doctype html>
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=7" >
<title>网易云音乐</title>
<style type="text/css">
/* Reset */
body,html,h1,h2,h3,h4,h5,h6,ul,ol,li,dl,dt,dd,header,menu,section,p,input{padding:0;margin:0;}
body{font-family:Microsoft Yahei, Arial, Helvetica, sans-serif;
............中间太长省掉了......................
<div class="g-ft">
<div class="g-wrap">
<div class="m-copy">
<p>
<a href="//gb.corp.163.com/gb/about/overview.html" target="_blank">关于网易</a><span>|</span>
<a href="#" target="_blank">关于网易云音乐</a><span>|</span>
<a href="//help.mail.163.com/service.html" target="_blank">客户服务</a><span>|</span>
<a href="#" target="_blank">隐私策略</a><span>|</span>
<a href="#" target="_blank">常见问题</a> </p>
<p>网易公司版权所有©1997-2019 全国文化市场统一举报电话:12318 </p>
</div>
</div>
</div>
</body>
</html>
(鬼知道这是什么玩意,贼长)
发现这根本不是我们需要的源码,根本没有歌词。
第二步:在网页按F12查看元素,点击网络,找到post方法中的lyric?csrf_token=,发现真正的url被网易云隐藏掉了。
假的url:
 真的url:
真的url:
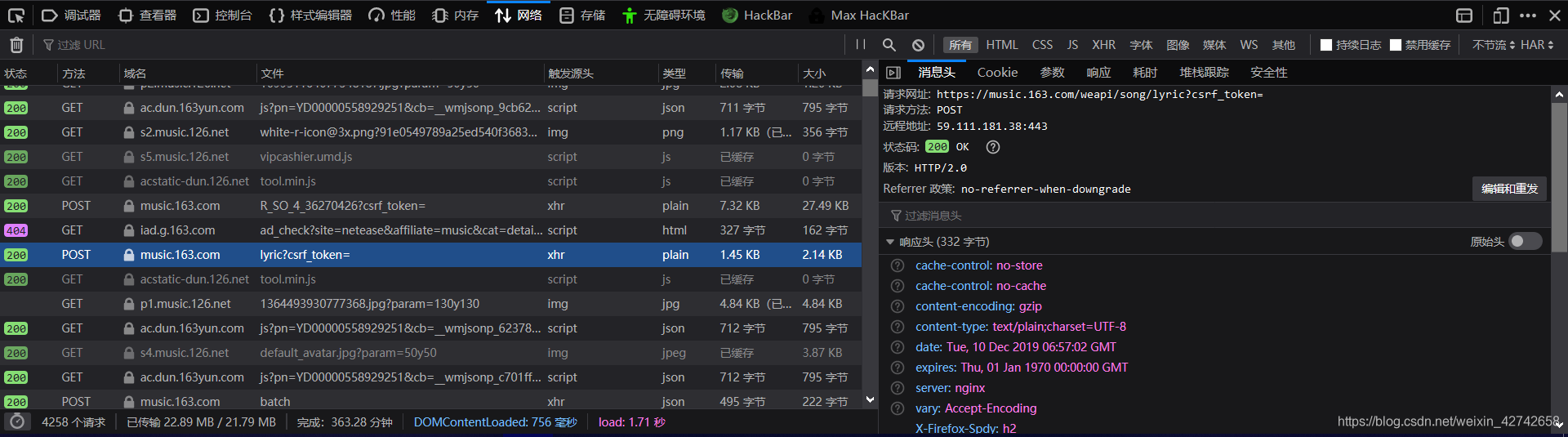 发现网易云偷偷的把‘api’换成了“#”,难怪读取的网页源码不对。其而还发现了存在歌词的url,但是这个url有token认证,可以看到这里需要两个参数:params和encSecKey,然后浏览各大博主的博客,发现一个比较好的绕过方式
发现网易云偷偷的把‘api’换成了“#”,难怪读取的网页源码不对。其而还发现了存在歌词的url,但是这个url有token认证,可以看到这里需要两个参数:params和encSecKey,然后浏览各大博主的博客,发现一个比较好的绕过方式
第三步:改写正确的url再试,代码和上面一样,就修改一句
url = 'http://music.163.com/api/song/lyric?'+ 'id=' + music_id+ '&lv=1&kv=1&tv=-1'
运行结果
{"code":-460,"msg":"Cheating"}
不信命的我尝试了N+1次,最终变成了这样。。。。
{"code":404,"msg":"该资源不存在。"}
这时候只能找百度了,然后就知道了网易云大名鼎鼎的反爬虫,好吧接着百度反反爬虫,你有反爬虫,我就试试能不能绕过。
果然经过一番尝试,我找到了这个:(点这里) 某位大佬的博客
一、 分析网页请求头
1、User-Agent:这个是保存用户访问该网站的浏览器的信息,我上面这个表示的是我通过window的浏览器来访问这个网站的,如果你是用python来直接请求这个网站的时候,这个的信息会带有python的字眼,所以网站管理员可以通过这个来进行反爬虫。
2、Referer:当浏览器发送请求时,一般都会带上这个,这个可以让网站管理者知道我是通过哪个链接访问到这个网站的,上面就说明我是从网易云音乐的主页来访问到这个页面的,若你是用python来直接请求是,就没有访问来源,那么管理者就轻而易举地判断你是机器在操作。
3、authorization:有的网站还会有这个请求头,这个是在用户在访问该网站的时候就会分配一个id给用户,然后在后台验证该id有没有访问权限从而来进行发爬虫
二、用户访问网站的ip
当你这个ip在不断地访问一个网站来获取数据时,网页后台也会判断你是一个机器。就比如我昨天爬的网易云音乐评论,我刚开始爬的一首《海阔天空》时,因为评论较少,所以我容易就得到所有数据,但是当我选择爬一首较多评论的《等你下课》时,在我爬到800多页的时候我就爬不了,这是因为你这个ip的用户在不断地访问这个网站,他已经把你视为机器,所以就爬不了,暂时把你的ip给封了
三、反反爬虫的方式:
1.添加请求头
2.使用代理ip
既然知道了,然后开始修改代码,这里我选用添加请求头的方式:
import requests
music_id=input("请输入歌手的id:")
headers={"User-Agent" : "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9.1.6) ",
"Accept" : "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language" : "en-us",
"Connection" : "keep-alive",
"Accept-Charset" : "GB2312,utf-8;q=0.7,*;q=0.7"
url = 'http://music.163.com/api/song/lyric?'+ 'id=' + music_id+ '&lv=1&kv=1&tv=-1'
r = requests.get(url,headers=headers,allow_redirects=False)
#allow_redirects设置为重定向
print(r.text)
运行结果:
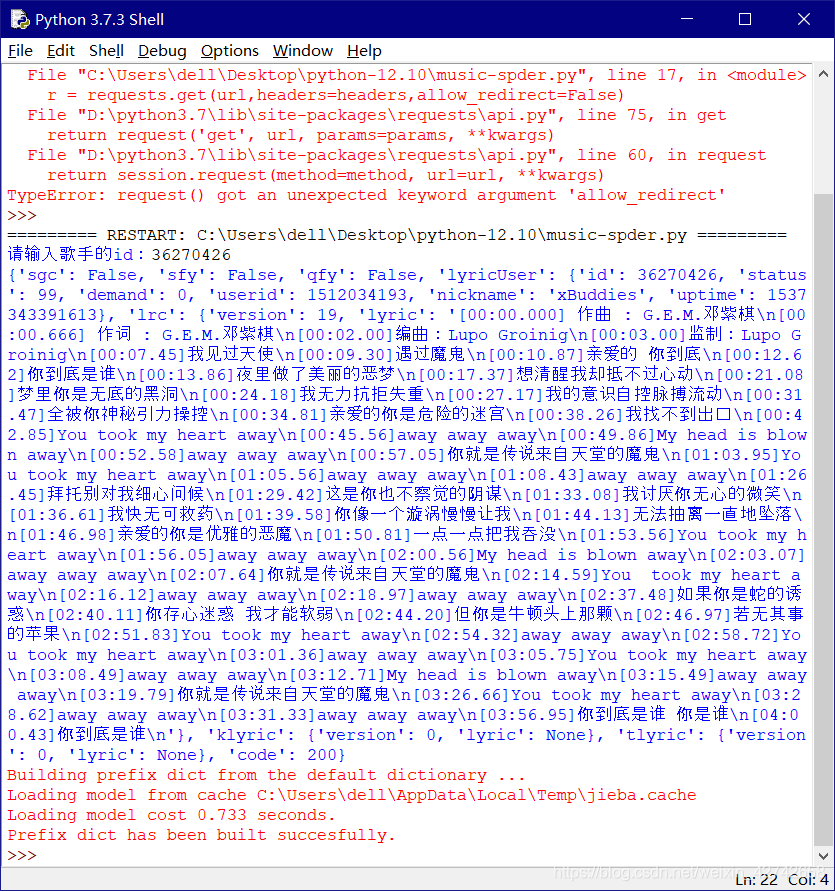 到这里已经算是成功了,歌词给我们爬下来了,但是还能进一步优化
到这里已经算是成功了,歌词给我们爬下来了,但是还能进一步优化
最终完整代码
import requests
import json
music_id=input("请输入歌手的id:")
headers={"User-Agent" : "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9.1.6) ",
"Accept" : "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language" : "en-us",
"Connection" : "keep-alive",
"Accept-Charset" : "GB2312,utf-8;q=0.7,*;q=0.7"}
url = 'http://music.163.com/api/song/lyric?'+ 'id=' + music_id+ '&lv=1&kv=1&tv=-1'
r = requests.get(url,headers=headers,allow_redirects=False)
#allow_redirects设置为重定向的参数
#headers=headers添加请求头的参数,冒充请求头
json_obj = r.text
j = json.loads(json_obj)#进行json解析
print(j['lrc']['lyric'])
by 久违 2019.12.10
运行结果:
 总结:思路过程,通用方法—网页分析—token绕过----冒充请求头—完成爬取
总结:思路过程,通用方法—网页分析—token绕过----冒充请求头—完成爬取
数据爬取之后后面就好办了,可以加几行代码把文件存放到txt文件中,excel表格中或者数据库中,因人而异。
by 久违 2919.12.10


















 839
839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











