







 本文汇总了Hive和HBase在实际使用中的常见问题,包括Hive的sort by与order by区别、内部表与外部表、分区、存储格式等,并探讨了HBase的架构、行键设计、热点问题及应用场景。了解这些问题有助于深入理解大数据处理中的数据存储与查询策略。
本文汇总了Hive和HBase在实际使用中的常见问题,包括Hive的sort by与order by区别、内部表与外部表、分区、存储格式等,并探讨了HBase的架构、行键设计、热点问题及应用场景。了解这些问题有助于深入理解大数据处理中的数据存储与查询策略。
2018.12.4
1.hive中sort by与order by的区别
sort by是分组排序,order by是全局排序。
2.hive与mysql的区别
回答思路:hive背景(原理、本质)–>两者操作、本质的差别–>读写差别–>其它差别。
Hive的诞生背景:学mysql的也想入门大数据,但又不会java,于是hive就诞生了。Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张表。本质是将HQL语句转化为MR程序。
hive总体来说操作等方面和MySQL没有太大差别。但是本质却有差别,Hive注重联机分析的处理,mysql注重事务的处理。Hive注重的是分析,mysql注重的是处理。
MySQL在写的时候检查字段,hive在读的时候检查字段。所以在新增数据时,hive比较快,只需要直接load就行,而MySQL需要先检查字段。
hive与mysql的其它差别如下:
1)数据存储位置:Hive 的数据都是存储在 HDFS 中的。而数据库则可以将数据保存在块设备或者本地文件系统中。
2)执行:Hive 中大多数查询的执行是通过 Hadoop 提供的 MapReduce 来实现的。而数据库通常有自己的执行引擎。
3)执行延迟:hive高延迟,mysql低延迟。
4)可扩展性:hive的可扩展性高,而数据库由于ACID语义限制,扩展性有限。
5)数据规模:hive可以支持很大规模的数据,数据库可以支持的数据规模较小。
3.hive内部表和外部表的 区别
未被external修饰的是内部表(managed table),被external修饰的为外部表(external table)。
区别:
内部表数据由Hive自身管理,外部表数据由HDFS管理。
删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除。
对内部表的修改会将修改直接同步给元数据,而对外部表的表结构和分区进行修改,则需要修复(MSCK REPAIR TABLE table_name;)
4.hive中union和union all的区别
Union合并时去除重复行,union all合并时不去除重复行。
5.公司中使用内部表多还是外部表多
内部表。
2018.12.7
1.hive中创建库和创建表的本质是什么
本质是在HDFS上创建目录或命令空间。
2.说一下你所学过的窗口函数
FIRST_VALUE:取分组内排序后,截止到当前行,第一个值 。
LAST_VALUE: 取分组内排序后,截止到当前行,最后一个值 。
LEAD(col,n,DEFAULT) :用于统计窗口内往下第n行值。第一个参数为列名,第二个参数为往下第n行(可选,默认为1),第三个参数为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL) 。
LAG(col,n,DEFAULT) :与lead相反,用于统计窗口内往上第n行值。第一个参数为列名,第二个参数为往上第n行(可选,默认为1),第三个参数为默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL)。
2018.12.08
1.hive加载数据的方式
LOAD DATA [LOCAL] INPATH ‘/AA/BB/CC’ INTO TABLE TABLE_NAME;
加载数据的本质:
将数据文件copy(不完全是copy)或者移动数据到表对应的目录下。
加载数据:
insert into table t_5
select * from t_4
where uid <5
;
克隆表,不带数据:
create table if not exists t_6 like t_5;
克隆表带数据:
create table if not exists t_7 like t_4
location ‘/user/hive/warehouse/gp1808.db/t_4’
;
location:后面接的一定是hdfs上的目录,不是文件
克隆带数据:
##更灵活更常用的方式:
##跟创建表的方式一样,元数据和目录都会创建。
create table if not exists t_8
as
select * from t_4
where uid >1
;
2.hive内部表和外部表的转换
alter table t_newuser set TBLPROPERTIES(‘EXTERNAL’=‘TRUE’); ###true一定要大写
alter table t_newuser set TBLPROPERTIES(‘EXTERNAL’=‘false’); ###false大小写都没关系
3.hive分区的三种类型
静态分区:加载数据的时候指定分区的值。
动态分区:数据未知,根据分区的值确定创建分区。
混合分区:静态加动态。
4.hive的存储格式
Textfile 未经过压缩的。
Sequencefile:hive为用户提供的二进制存储,本身就压缩,不能使用load方式加载数据。
Rcfile:hive提供的行列混合存储,hive在该格式下,会尽量将附近的行和列的块存储到一起,仍然是压缩格式,查询效率比较高。
Orc是rcfile的升级版本。
Parquet列式存储。
2018.12.10
1.hive的建表语法
CREATE
[EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], …)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], …)]
[CLUSTERED BY (col_name, col_name, …)
[SORTED BY (col_name [ASC|DESC], …)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
create table if not exists stu(name string,age int)
partitioned by (year int,month int)
row format delimited fields terminated by ‘,’
LINES TERMINATED BY ‘\n’
stored as orc;
2.hive中怎么解决分组后的数据倾斜
设置hive.groupby.skewindata
hive.groupby.skewindata如果设置为true,生成的查询计划会有两个MR 的job
第一个MR job中map的输出结果集合会随机分配到reduce中,每个reduce做部分的聚合操作,然后输出结果.
也就是说原来分在一个组的数据打散后分散到多个reduce中,从而达到负载均衡的目的.
第二个MR job处理第一个MR job处理过的结果进行group by.
3.HDFS中的普通格式的数据如何导入到hive表中并且存储格式改为orc,说明实现的步骤。
创建一个临时表tab1(默认存储格式)---->将数据加载到该临时表tab1中---->创建存储格式为orc的hive表tab2---->将临时表tab1中数据插入到表tab2中,insert into tab2 select ……from tab1.
2018.12.15
1.hbase的架构
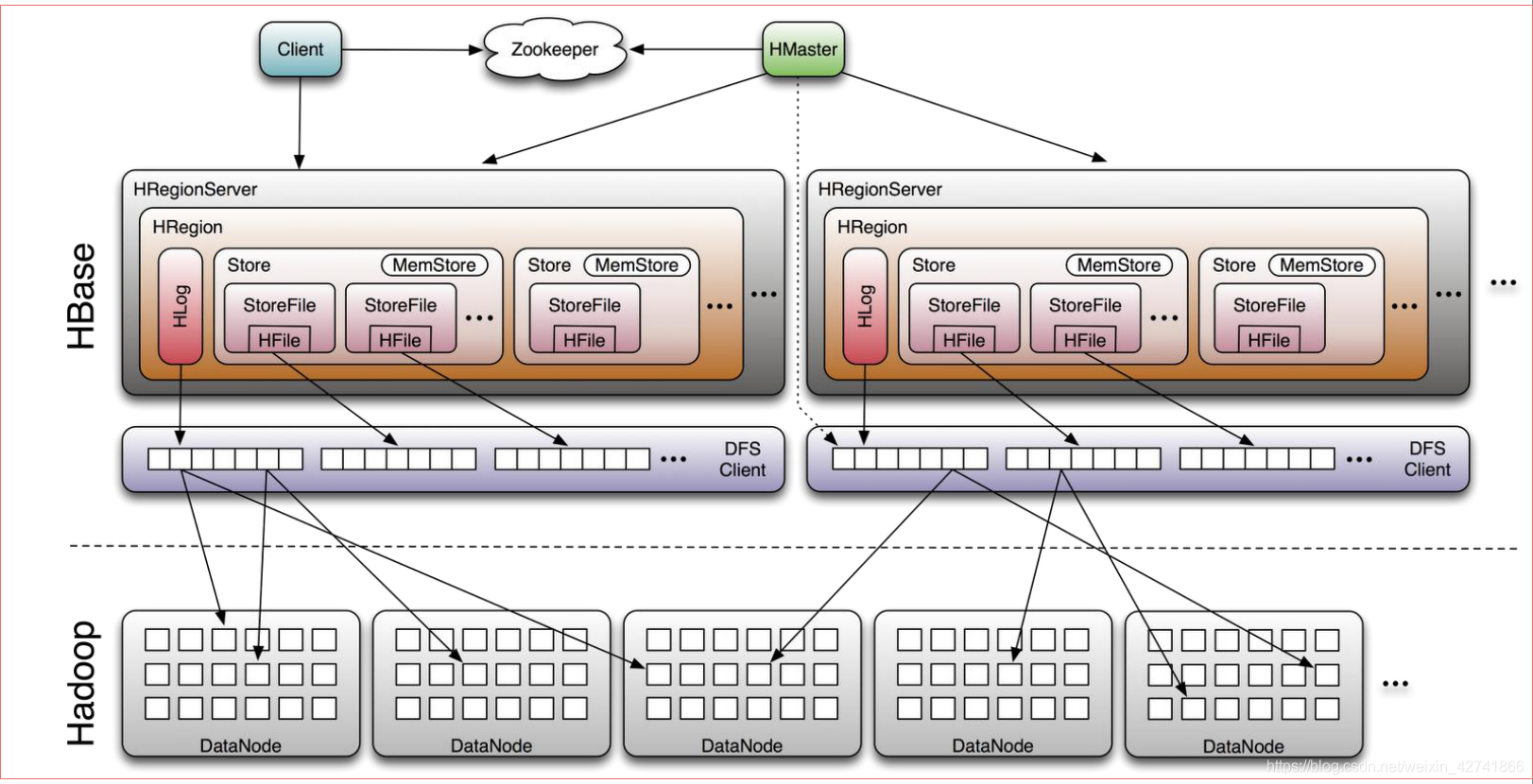
HMaster:
负责HBase中table和region的管理,regionserver的负载均衡,region分布调整,region分裂以及分裂后的region分配,regionserver失效后的region迁移等。
Zookeeper:
存储root表的地址和master地址,regionserver主动向zookeeper注册,使得master可随时感知各regionserver的健康状态。避免master单点故障。
RegionServer:
HRegion Server主要负责响应用户I/O请求,向HDFS文件系统中读写数据,是HBase中最核心的模块。
HRegion Server内部管理了一系列HRegion对象,每个HRegion对应了Table中的一个Region,Region中由多个Store组成。每个Store对应了Table中的一个Column Family的存储,即一个Store管理一个region上的一个列簇。每个Store包含一个MemStore和0到多个StoreFile。Store是HBase存储核心,由MemStore和StoreFiles组成。
MemStore:
MemStore是Sorted Memory Buffer,用户写入的数据首先会放入MemStore,当MemStore满了以后会Flush成一个StoreFile(底层实现是HFile), 当StoreFile文件数量增长到一定阈值,会触发Compact合并操作,将多个StoreFiles合并成一个StoreFile,合并过程中会进行版本合并和数据删除,因此可以看出HBase其实只有增加数据,所有的更新和删除操作都是在后续的compact过程中进行的,这使得用户的写操作只要进入内存中就可以立即返回,保证了HBase I/O的高性能。当StoreFiles Compact后,会逐步形成越来越大的StoreFile,当单个StoreFile大小超过一定阈值后,会触发Split操作,同时把当前Region Split成2个Region,父Region会下线,新Split出的2个孩子Region会被HMaster分配到相应的HRegionServer 上,使得原先1个Region的压力得以分流到2个Region上。
2.hbase的行键(rowkey)设计原则
参见此篇博文末尾
3.如何避免hbase行键的热点问题
参见此篇博文末尾
4.hbase的应用场景
1)需对数据进行随机读写操作;
2)大数据上高并发操作,比如每秒对PB级数据进行上千次操作;
3)读写访问均是非常简单的操作。
5.hbase的寻址过程(读写数据过程)
client–zookeeper–root–meta–region
客户端先通过zookeeper获取到root表的地址,通过root表获取.meta表的地址,.meta表上记录了具体的region的地址。

















 1178
1178

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









