







Spark数据清洗优化方案
1、提前聚合
1.1、源数据聚合
实际场景:在Hive表跑批的时候,提前聚合部分数据,避免在Spark阶段的shuffle
1.2、聚合较粗的粒度,逐渐放细
实际场景:本来要统计city的人数,可以先统计<city,sex>粗粒度一点的数据
2、过滤某些Key(要考虑需求和业务场景)
实际场景:业务和需求允许的情况下,可以过滤部分倾斜的key
3、增加reduceTask的并行度(生产紧急使用,治标不治本)
使用方法
JavaPairRDD<Long, Long> clickCategoryId2CountRDD = clickCategoryIdRDD.reduceByKey(
new Function2<Long, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Long call(Long v1, Long v2) throws Exception {
return v1 + v2;
}
},1000);
4、针对reduceByKey/groupByKey的数据倾斜,在Key前面增加一个随机数,相当于把数量分布较多的Key打散,先局部聚合,再映射会本身的Key,最后再进行全局聚合的过程,图解如下
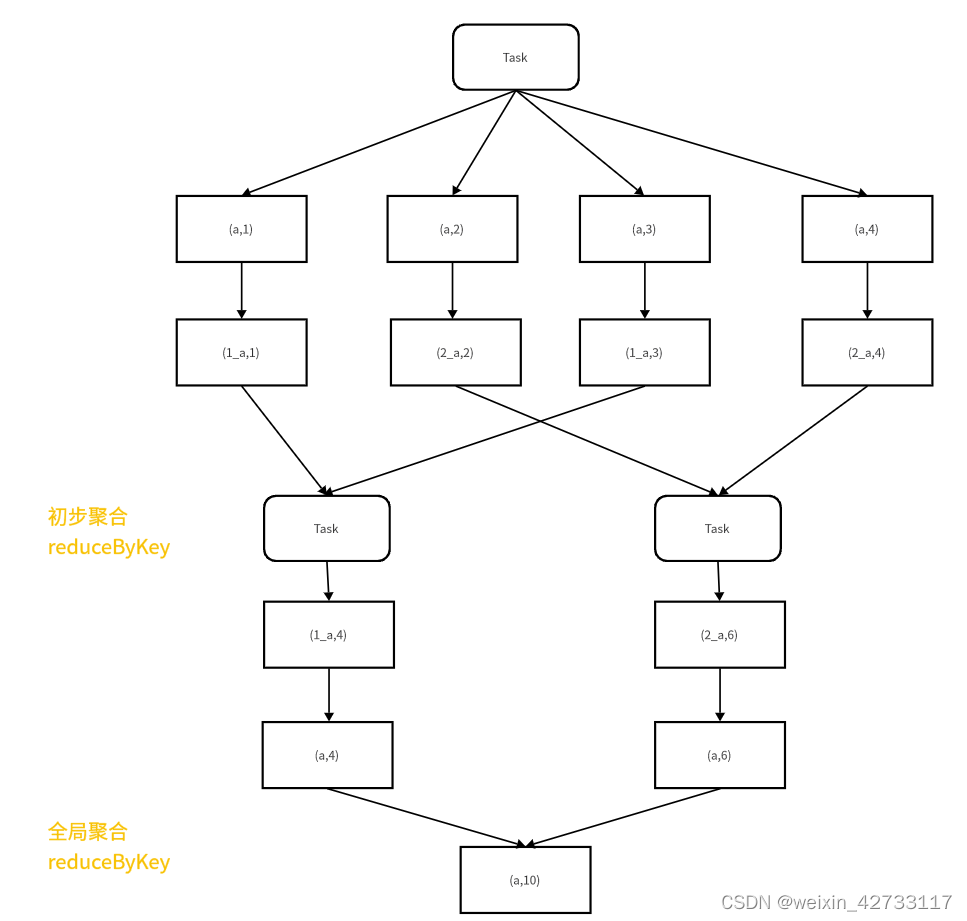
有点类似Hive数据倾斜的情况
适用:已经找出倾斜的Key,直接对倾斜Key进行打散操作,以及聚合的逻辑可以进行拆分局部和总体的,比如加减乘等
不适用:聚合逻辑复杂且不支持局部聚合,比如求平均值等
实际项目操作:
clickCategoryIdRDD.reduceByKey
1、在品类ID聚合之前,可以先映射随机数前缀,scala:map(),java:maptopair()
2、初步的reduceByKey
3、初步聚合后,再映射回本来的Key, scala:map(),java:maptopair()
4、全局的reduceByKey
5、针对(大表小表)join类型的数据倾斜,使用mapjoin优化
场景:适合大表和小表之间join,数据量差异比较大,且有Key分布不均的情况
原理:将小表做成广播变量broadcast,由collect分发到所有的Excetor_Block中,每部分数据进行map操作的时候,就可以直接获取对应Key在broadcast中的value,并进行mapToPair 实现 join,就不会有shuffle阶段,形成数据倾斜
注:被广播的表的大小不超过,spark.sql.autoBroadcastJoinThreshold 所配置的值,默认是10M
不适用:两个大表关联,且有数据倾斜的Key的情况
总结:就算没有数据倾斜,单单从优化的角度,也是可以考虑这种手段的
实际项目经验:
大表join小表,已经做了 broadcast,为什么走的还是shuffle,join
1,是不是直接用RDD来进行broadcast,会直接报错,以为RDD不存储数据,只能把RDD的结果broadcast
2,broadcast的数据是不是超过设定的参数值,导致广播失败,omm
3,用DataFrame广播的时候,广播的是dataFrame这个变量,而不是里面的素有数据
val smallTableBroadCastValue = sc.broadcast(smallTable).value
//转换成
val result = bigTable.join(org.apache.spark.sql.functions.broadcast(smallTable), "joinkey")
6、join类型两个大表之间的数据倾斜
场景:倾斜Key比较少,或仅有一个的情况下可以使用
原理:把原RDD拆分成两个部分,一个是倾斜Key的RDD,一个是非倾斜Key的RDD,分别与目标表join之后,再union再一起,达到最终的效果
实现原理:拆分前
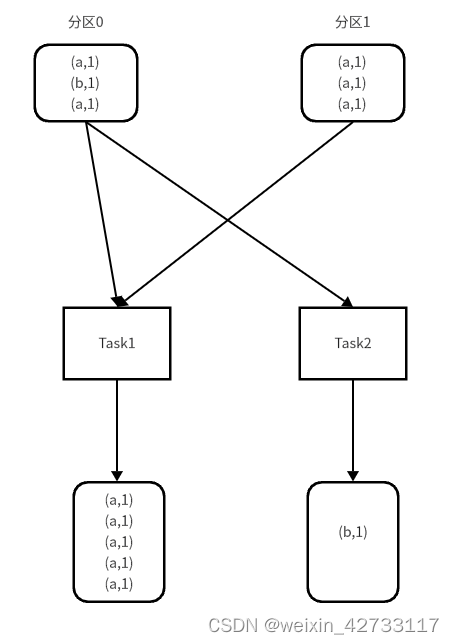
本来相同Key会分到同一个task中,导致数据倾斜
拆分后
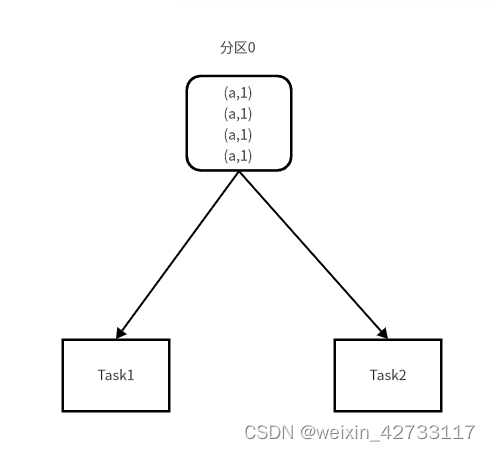
拆分后,只有一个key,就可以把一个key的数据分到多个task中,均衡处理
不适用:倾斜Key较多的情况下不适用
7、join类型倾斜,两个大表之间join,且倾斜Key较多的情况下
场景:两个大表之间join,且倾斜Key不是一个或者几个,很多个
原理:一般是将小表的数据进行扩容打散(flatMap),加上随机数prefix,一般是10,如果能找到倾斜Key,可以扩容更大的倍数,大表的key,添加一个同等倍数的随机数,0-10,然后再进行join,join再映射,再join,就不会有数据倾斜问题


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









