






 本文详细介绍了如何在Intel架构服务器环境下部署TiDB分布式数据库集群,包括RedHat Enterprise Linux 7.3及以上的操作系统配置,以及在Zabbix监控系统中集成TiDB的过程。从服务器环境准备、软件安装到服务启动,再到Zabbix配置修改与重启,确保了TiDB与Zabbix的无缝对接。
本文详细介绍了如何在Intel架构服务器环境下部署TiDB分布式数据库集群,包括RedHat Enterprise Linux 7.3及以上的操作系统配置,以及在Zabbix监控系统中集成TiDB的过程。从服务器环境准备、软件安装到服务启动,再到Zabbix配置修改与重启,确保了TiDB与Zabbix的无缝对接。
TIDB简介:
介绍:TiDB作为一款开元分布式NewSQL数据库,可以很和好的部署和运行在Intel架构服务器环境及主流虚拟计划环境,并支持绝大多数的主流硬件网络。作为一款高性能数据库系统,TiDB支持主流的Linux操作环境。
对操作版本的要求: Red Hat Enterprise Linnx 7.3及以上,CentOS 7.3及以上, Oracle Enterprise Linux 7.3及以上,Ubuntu LTS 16.04及以上
实验环境:
rhel7.3 iptables和selinux均为disabled状态
server6: 172.25.254.6 PD1 tidb zabbix-server
server7: 172.25.254.7 tikv
server8: 172.25.254.8 tikv
server9: 172.25.254.9 tikv
操作步骤:
此处server6已经配置过了zabbix-server 并且也已经安装过mariadb服务
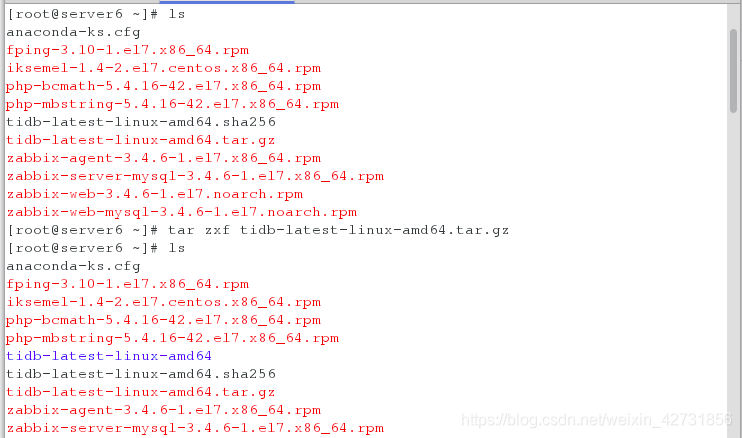
在四个主机上都安装binary,安装完成之后会显示ok,则为安装完成,并解压安装包(本实验在真机中下载包,拷到四个虚拟机)
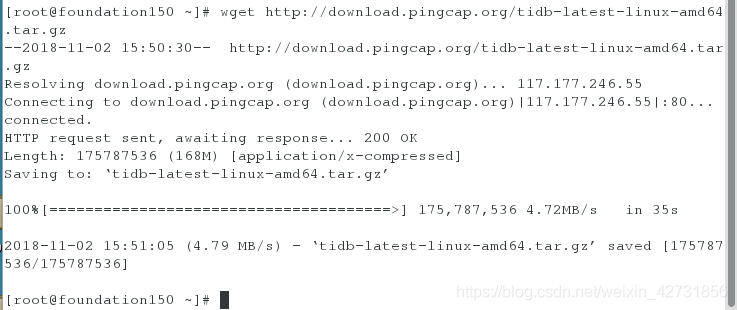
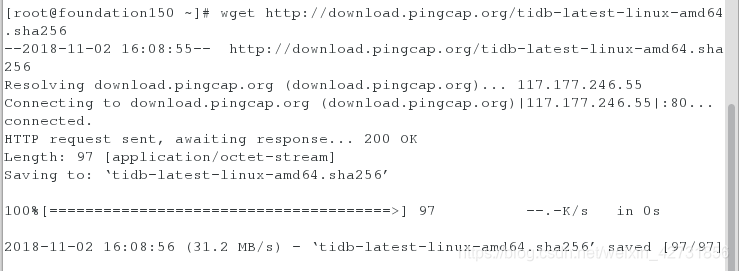
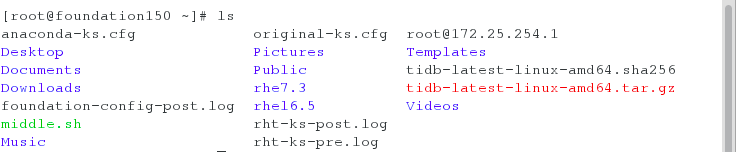
在server6上解压包,开启PD,并查看端口

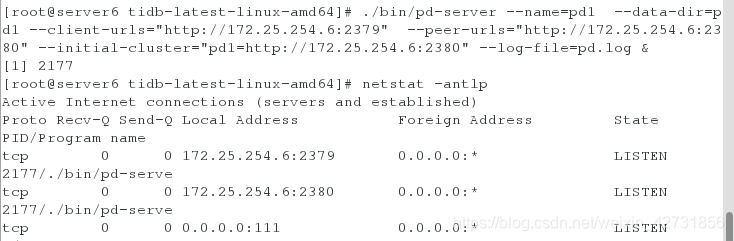
ps ax ##查看服务是否开启
在主机server7 server8 server9 上开启tikv,并查看端口,通过ps ax查看端口
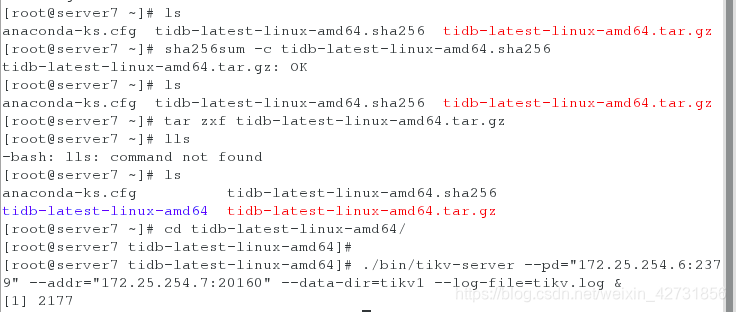
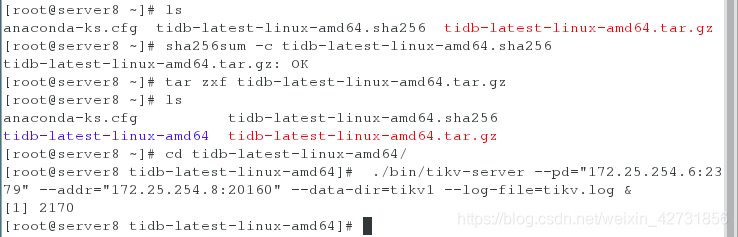
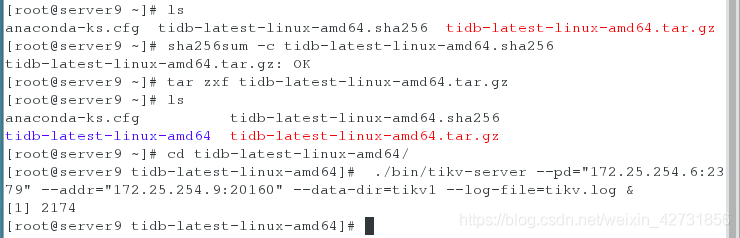
三台主机启动完kitv之后,再在server6上开启tidb
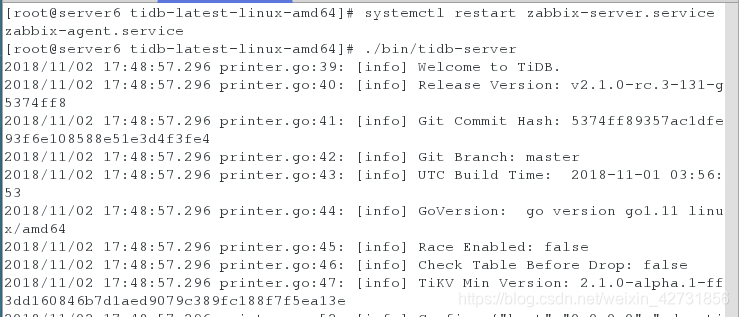
端口查是否开启4000

启动顺序为PD-tikv-tidb(顺序很重要)启动时选择后台启动,避免前台失效后程序自动退出
全部启动之后,在server6上做授权(若没有zabbix库,则要建立zabbix)
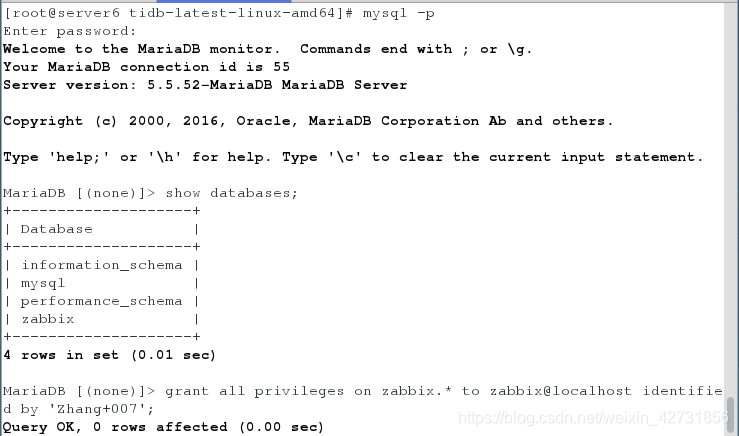
用mysql客户端连接tidb
若能连接上,那么说明数据库的基本配置就已经成功了
现在需要往zabbix应用中集成:
修改端口(改为4000)
vim /etc/zabbix/zabbix_server.conf
修改zabbix配置文件
vim /etc/zabbix/web/zabbix.conf.php
重启服务
systemctl restart zabbix-server
systemctl restart zabbix-agent
systemctl restart httpd
启动之后重新访问IP/zabbix,可以访问到zabbix的操作界面,才能证明配置成功

















 732
732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









