







 本文介绍了一种将PDF文件中的目录快速转换为书签的方法。通过解析目录中的文本信息,并利用Python及其相关库(如openpyxl)来操作Excel文件,从而实现自动化地创建PDF书签的功能。
本文介绍了一种将PDF文件中的目录快速转换为书签的方法。通过解析目录中的文本信息,并利用Python及其相关库(如openpyxl)来操作Excel文件,从而实现自动化地创建PDF书签的功能。
将PDF文件中的目录快速转换为书签
背景需求
许多PDF文件只有目录,但是没有生成书签。本文要解决的问题就是,如何从将PDF文件中的目录快速转换为书签。
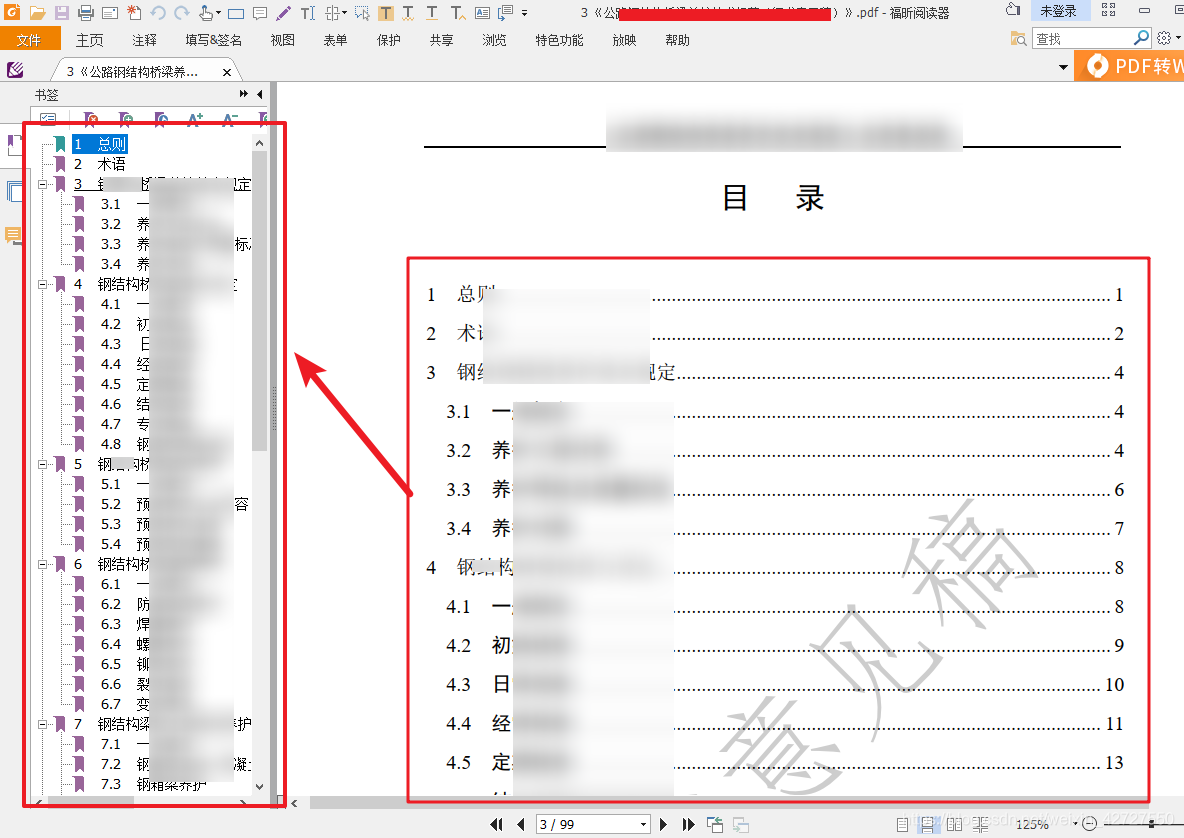
思路
- 将pdf文件的目录转换成可操作的内容。如将目录另存为txt,或者利用ocr工具识别出文字字符等。
本文是将获取的文本存放在excel中,再用python操作excel - 分析pdf的书签格式:利用PdgCntEditor编辑pdf书签,可知书签的分级是按列进行存储。如二级书签的题目和一级书签的标题是在同一列。
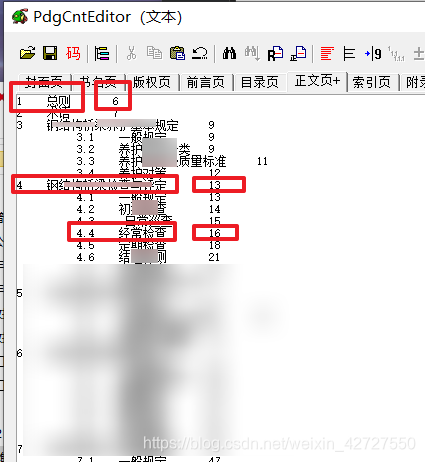
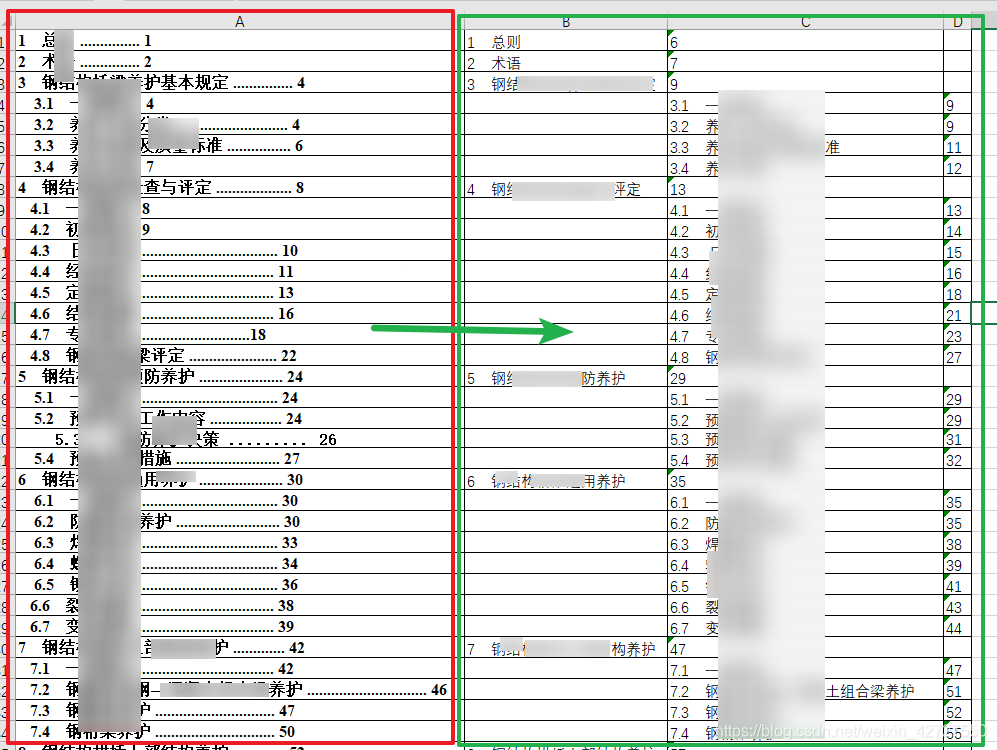
最终,问题转换为下图的excel操作
python代码实现
openpyxl 的使用教程可参考python中使用openpyxl操作Excel的常用方法及案例
import openpyxl #openpyxl只能操作xlsx文件而不能操作xls文件。
import re
from openpyxl import Workbook
# 从 "1第一章...432" 中 获取数字 432 作为页码
def getPageNum(text):
PageNumStr="";
n=-4; #目录的页码数最多是由4为数字组成
while n<0:
numbleStr=text[n]
n=n+1
intNum=0
try:
intNum=int(numbleStr)
except:
continue
else:
PageNumStr=PageNumStr+str(intNum)
return PageNumStr
#从 "1第一章...432" 中 抽取 “1第一章” 作为标题
def getTitle(text):
mo= r'[\u4e00-\u9fa5]'
resList=re.findall(mo,text) #获取所有汉字,组成有单个汉字构成的list
lastStr=str(resList[-1]) #最后的一个汉字
indexList = [i.start() for i in re.finditer(lastStr, text)]#最后一个汉字有可能在text重复,这里获取所有的最后一个汉字的索引
title=text[0:max(indexList)+1] #从text中获取最后一个汉字(含)之前的所有汉字作为标题
level=title.count('.') #章节标题等级,0表示第一级 1表示第二季 2表示第三级
return level,title # 0, 1第一章
def excel2pdfCnt(fileName,sheetName,correctPageNum=0):
'''
将excel的A列内容转换到其他列成为pdf书签
:param fileName:xlsx工作簿文件的完整地址
:param sheetName: 工作表名称
:param correctPageNum: 书签页码的修正值
:return:无
'''
# 打开文件
wb = openpyxl.load_workbook(fileName)
# 选择表单
sh = wb[sheetName]
# 按行读取数据转化为列表
rows_data = list(sh.rows)
num= len(rows_data)
titleData=[]
pageNumData=[]
#将A列的不规则目录分别存储到BCD……
rowLen=len(sh["A"])
i=1
while i<rowLen+1:
ob=sh["A%d"%i].value #A1 A2 A3……的值
ob=str(ob).strip();
print(ob)
try:
level,title =getTitle(ob)
PageNumStr=getPageNum(ob)
pagenum = str(int(PageNumStr) + correctPageNum)
sh.cell(i, level + 2).value = title # cell(行号,列号) 如果level=1则为二级标题,将二级标题填充在第三列C列
sh.cell(i, level + 3).value = pagenum # 将二级标题的页码填充在第四列D列
i = i + 1
except ValueError:
print("请检查该行文本是否缺少页码或标题或其他不符合格式的内容:"+ob)
i = i + 1
continue
wb.save(fileName)
if __name__ == '__main__':
excel2pdfCnt(r'D:\LIcong\pyExcel\pdfcontext.xlsx','s3',10)

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









