







 这篇博客介绍了迁移学习的概念,它涉及将已在一个领域学到的知识应用于另一个领域。以图像分类为例,通过预训练的神经网络提升模型的准确率。文章详细阐述了微调和特征提取两种迁移学习方法,并提供了代码示例。微调允许在源数据集上预训练的模型作为初始模型,针对目标数据进行进一步训练。特征提取则固定预训练模型的部分层,仅训练其余层。最终,通过调整全连接层的输出维度来适应不同的分类任务,并展示了如何在PyTorch中实现这一过程。
这篇博客介绍了迁移学习的概念,它涉及将已在一个领域学到的知识应用于另一个领域。以图像分类为例,通过预训练的神经网络提升模型的准确率。文章详细阐述了微调和特征提取两种迁移学习方法,并提供了代码示例。微调允许在源数据集上预训练的模型作为初始模型,针对目标数据进行进一步训练。特征提取则固定预训练模型的部分层,仅训练其余层。最终,通过调整全连接层的输出维度来适应不同的分类任务,并展示了如何在PyTorch中实现这一过程。
简单来说,迁移学习就是把一个领域学到的知识,应用到另一个领域。
举例来说,如果我们的任务是图片分类问题,假设分成10类。那么随机的正确率是10%,某个神经网咯经过一定的训练,正确率达到了20%(这比随机的效果好一些),我们就说该神经网络学到了知识!
事实上,我们在生活中也常常应用迁移学习的知识。比如还在上中学的时候,我们会根据当前的处境推断大学生的生活,中学生和大学生都会写作业,都会学习新知识……。也许会有推断错误的地方,但这总比一无所知好。
微调
初始化神经网络时,可以随机初始化,即从头开始训练,也可以用迁移学习的思想初始化,即先把神经网络在别的数据集(称为源数据)上训练出一个较好的结果,然后作为目标任务的初始化神经网络。
这里我们通常假设源数据较多而目标数据较少。因为如果目标数据也很多的话,迁移学习的用武之地就不大了。
目标数据较少会导致容易过拟合,因此可以加入正则项,使得在目标数据上训练的神经网络离源数据上训练的神经网络参数差的不太多。
特征提取
特征提取即固定预训练网络的一些层,不训练这些层的参数,仅仅训练别的层。在图像领域,常常固定前面的层而训练后面的层。在下面的例子中,我固定了除最后的全连接层之外的所有层。
from __future__ import print_function, division
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
import time
import os
import copy
from torch.utils.data import DataLoader
import warnings
warnings.filterwarnings("ignore")
plt.ion()
#加载数据
train, val = "train", "val"
#数据变换:训练集(数据扩充,归一化) 测试集(归一化)
data_transforms = {
train: transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
val: transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
data_dir = 'data/hymenoptera_data'
batch_size = 4
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in [train, val]}
dataloaders = {x: DataLoader(image_datasets[x], shuffle=True, batch_size=batch_size) for x in [train, val]}
dataset_size = {x:len(image_datasets[x]) for x in [train, val]}
class_name = image_datasets[train].classes
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# #可视化图像数据
# def imshow(inp:torch.Tensor, title = None):
# inp = inp.numpy().transpose((1, 2, 0))
# mean = np.array([0.485, 0.456, 0.406])
# std = np.array([0.229, 0.224, 0.225])
# inp = std * inp + mean
# inp = np.clip(inp, 0, 1)
# plt.imshow(inp)
# if title is not None:
# plt.title(title)
#
# plt.pause(0.1)
#
# #获取一批训练数据
# inputs, classes = next(iter(dataloaders['train']))
#
# #批量制作网格
# out = torchvision.utils.make_grid(inputs)
# print(out.size())
#
# imshow(out, title=[class_name[x] for x in classes])
def train_model(model, criterion, optimizer, scheduler, num_epochs=25):
since = time.time()
best_model = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print("Epoch {}/{}".format(epoch + 1, num_epochs))
print("-" * 10)
#每次都在最佳模型的基础上训练
model.load_state_dict(best_model)
# 每个epoch都有训练和验证阶段
for phase in [train, val]:
if phase == train:
scheduler.step()
model.train()
else:
model.eval()
running_loss = 0.0
running_corrects = 0
#迭代数据
for inputs, labels in dataloaders[phase]:
inputs, labels = inputs.to(device), labels.to(device)
#梯度清零
optimizer.zero_grad()
#训练和预测都需要前向传播
with torch.set_grad_enabled(phase == train):
# print(inputs.size())
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
#训练阶段需要反向传播,优化参数
if phase == train:
loss.backward()
optimizer.step()
#统计
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels)
epoch_loss = running_loss / dataset_size[phase]
epoch_acc = running_corrects.double() / dataset_size[phase]
print("{} Loss:{:.4f} Acc:{:.4f}".format(phase, epoch_loss, epoch_acc.item()))
#深复制
if phase == val and epoch_acc > best_acc:
best_acc = epoch_acc
best_model = copy.deepcopy(model.state_dict())
print()
time_elpased = time.time() - since
print('training complete in {:.0f}'.format(time_elpased))
print('Best acc:{:.4f}'.format(best_acc))
#加载最佳模型
model.load_state_dict(best_model)
return model
# #场景1
# #使用resnet18网络,并将最后一层的全连接层的输出维度改成2
# model_ft = models.resnet18(pretrained=True)
# num_ftrs = model_ft.fc.in_features
# model_ft.fc = nn.Linear(num_ftrs, 2)
# model_ft = model_ft.to(device)
#
# criterion = nn.CrossEntropyLoss()
#
# # 观察所有参数都正在优化
# optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9)
# # 每7个epochs衰减LR通过设置gamma=0.1
# exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
#
# model_ft = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler,num_epochs=25)
#场景2
model_conv = torchvision.models.resnet18(pretrained=True)
for param in model_conv.parameters():
param.requires_grad = False
# Parameters of newly constructed modules have requires_grad=True by default
#新增加的全连接层(权重和偏差)默认requires_grad是true
num_ftrs = model_conv.fc.in_features
model_conv.fc = nn.Linear(num_ftrs, 2)
model_conv = model_conv.to(device)
criterion = nn.CrossEntropyLoss()
# Observe that only parameters of final layer are being optimized as
# opposed to before.
optimizer_conv = optim.SGD(model_conv.fc.parameters(), lr=0.001, momentum=0.9)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_conv, step_size=7, gamma=0.1)
model_conv = train_model(model_conv, criterion, optimizer_conv,exp_lr_scheduler, num_epochs=25)
说明
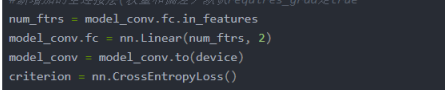
这里需要修改全连接层输出的维度,因为通常我们的分类数和原生Resnet的分类数不一样。
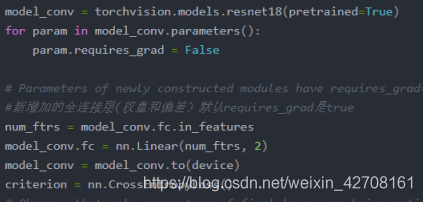
这里把前面层的requires_grad设置为False,即不训练他们。最后重新设置全连接层,其参数的requires_grad默认是True。

















 4420
4420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









