







java面试笔记自己用
- 高阶-2020
- 基础
- 第一阶段
- 1、面向对象
- 2、JDK、JRE、JVM
- 3、equals和==
- 4、final和finalize
- 5、String、StringBuffer、StringBuilder
- 6、重载和重写
- 7、接口和抽象类
- 8、List和Set
- 9、HashCode和equals
- 10、ArrayList和LinkedList
- 11、HashMap和HashTable和ConcurrentHashMap
- 12、如何实现IOC容器
- 13、java的类加载器有哪些
- 14、java中的异常体系
- 15、GC垃圾回收
- 16、线程的生命周期、状态
- 17、sleep()、wait()、join()、yield()
- 18、ThreadLocal
- 19、接口幂等性
- 20、Filter和Interceptor的区别
- 高阶-2024
- 高阶-2025
高阶-2020
一、第一阶段
尚硅谷Java大厂面试题第二季(java面试必学,周阳主讲)
1、 volatile关键字的理解
前提:了解JMM(java内存模型:缓存一致性协议,用于定义数据读写的规则,也就是线程的工作内存和主内存之间的读写规则,线程的工作内存是从主内存复制拷贝的)、原子性的概念(不可分割)、了解并发三大特性: 可见性、原子性、有序性
定义:轻量级的同步机制(低配版的synchronize)
三大特性:可见性、不保证原子性、禁止指令重排
总结(volatile和synchronized的区别):
1.volatile本质是在告诉jvm当前变量在寄存器(工作内存)中的值是不确定的,需要从主存中读取;synchronized则是锁定当前变量,只有当前线程可以访问该变量,其他线程被阻塞住。
2.volatile仅能使用在变量级别;synchronized则可以使用在变量、方法、和类级别的
3.volatile仅能实现变量的修改可见性,不能保证原子性;而synchronized则可以保证变量的修改可见性和原子性
4.volatile不会造成线程的阻塞;synchronized可能会造成线程的阻塞。
5.volatile标记的变量不会被编译器优化;synchronized标记的变量可以被编译器优化
个人总结:
1、volatile,只是作用于变量的,而且比synchronized同步性要弱很多。
2、volatile只保证可见性,不保证原子性,因为当对非原子性的操作i++,某个线程s1在寄存器操作中断的时候,s2已经将主存的i改了,s1的工作内存也会跟着改,但是此时s1完成寄存器的加法,然后写入到工作内存,再写入到主存,这样只增加了1次。
3、volatile使用范围:某个变量只进行原子操作的时候,可以使用volatile修饰例如volatile boolean flag = false;
4、volatile会立即将线程的工作内存写入到主存中。
具体分析:1、可见性,图解:
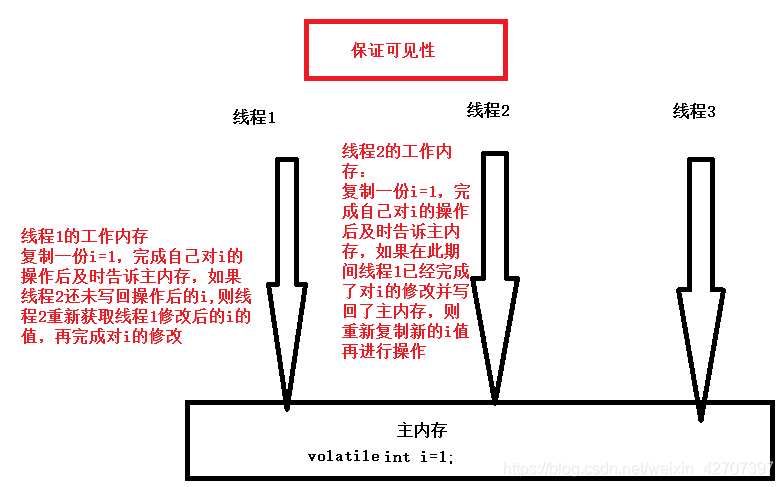
2、不保证原子性,比如i++;看java代码就一个操作,实际上编译成java字节码后,有三步代码:(1)执行getfield拿到i(2)执行i的add操作 (3)执行putfield从自己的工作内存把加一后的i写到共享的主内存
volatile int a = 0;
@Test
public void testAdd() throws InterruptedException {
for (int i = 0; i < 100; i++) {
new Thread(() -> {
for (int j = 0; j < 1000; j++) {
a++;
}
}).start();
}
TimeUnit.SECONDS.sleep(1);
System.out.println("最后结果: " + a);
}
图解:
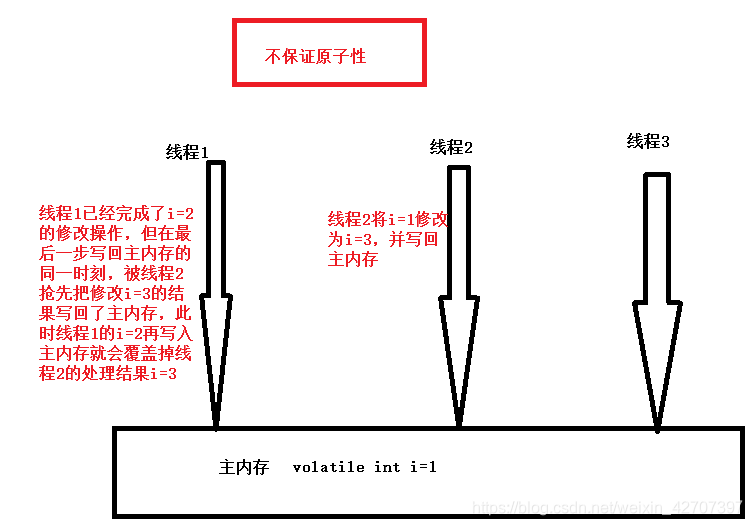
3、禁止指令重排:(指令重排是指:比如你代码的顺序是int a=1;int b=2;b=b+10; a=a+1;实际上在保证没有数据依赖的前提下,会自动完成优化代码执行效率的排序,可能重排后成为了int a=1;a=a+1;int b=2;b=b+10;)。
特别注意: 使用volatile来达到禁止指令重排序时,有一个内存屏障的概念,对于赋值写操作,不允许volatile上面的跑到下面,对于用其他变量来读取的操作,不允许volatile下面的跑到上面,总之就是写操作,volatile尽量放在最后面,对于读操作,尽量放在最上面。比如下面的例子,先赋值x,再赋值带volatile的y,先读带volatile的y,再读x
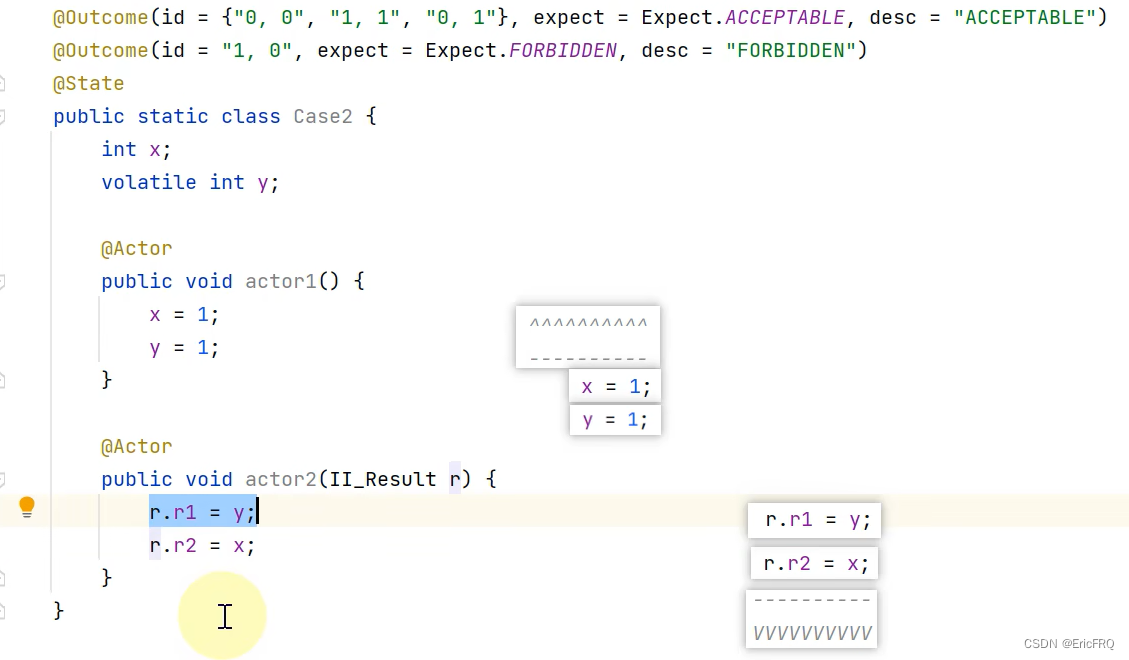
不保证原子性的解决方式:(cas:比较并交换)具体方法如:使用atomic包下的原子类。
比如i++可以使用AtomicInteger,自定义类可用java.util.concurrent.atomic.AtomicReference。
案例:
public class AtomicDemo {
private static AtomicReference<User> reference = new AtomicReference<>();
public static void main(String[] args) {
User user1 = new User("a", 1);
User user2 = new User("b",2);
reference.set(user1);
boolean result=reference.compareAndSet(user2);//如果当前状态值等
//于预期值,即比较reference里的user是否等于user1,是返回true,
//并把reference里的user改为user2
System.out.println(result);
System.out.println(reference.get());
}
static class User {
private String userName;
private int age;
public User(String userName, int age) {
this.userName = userName;
this.age = age;
}
@Override
public String toString() {
return "User{" +
"userName='" + userName + '\'' +
", age=" + age +
'}';
}
}
}
输出结果:
true
User{userName='b', age=2}
问题:
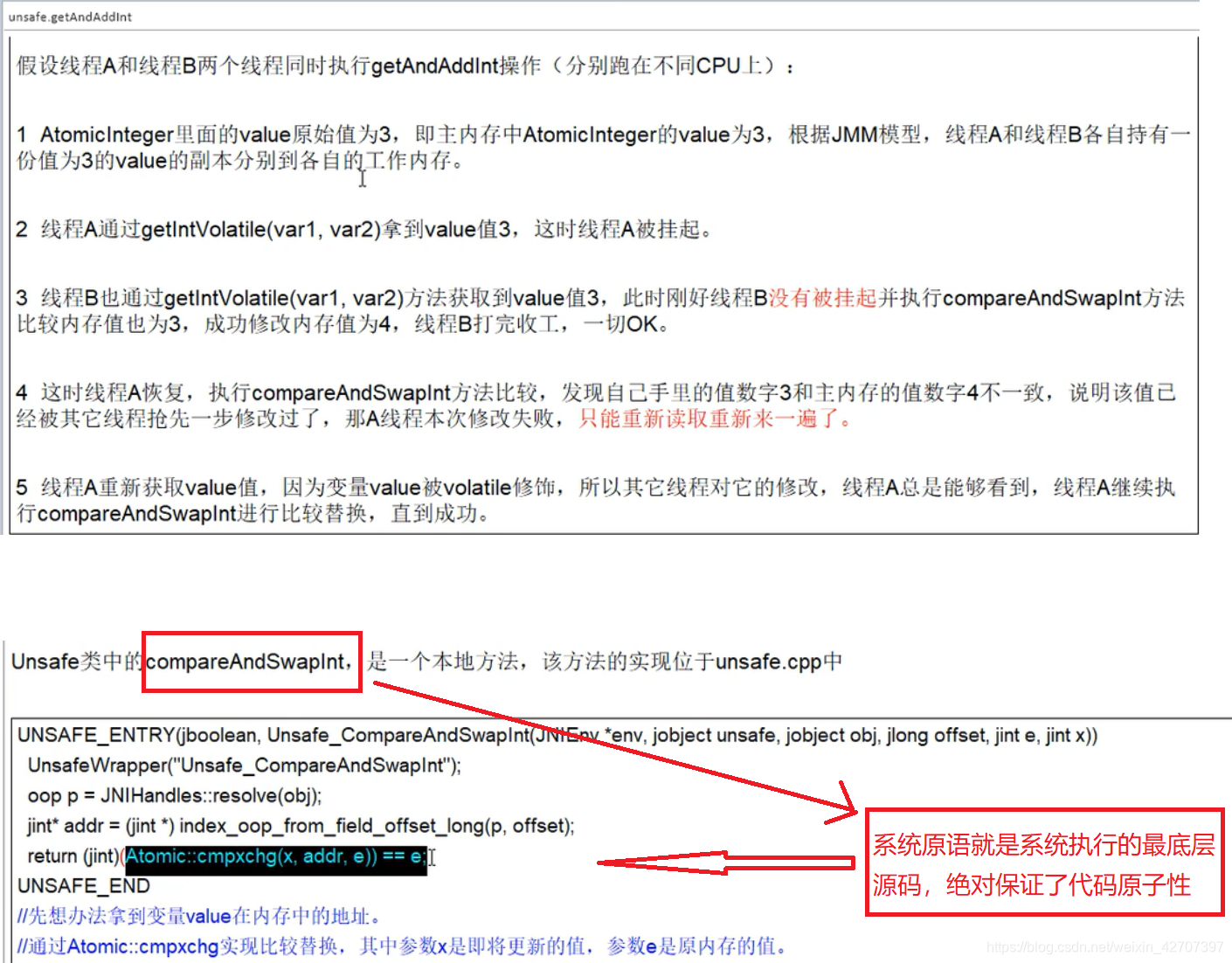
1、atomic原子类cas实现的过程?
答:比如使用atomicInteger原子类的getAndIncrement()方法时,在getAndIncrement()里调用了UnSafe的“自旋方法”getAndAddInt(),在getAndAddInt()里,调用了最底层native修饰的系统原语方法compareAndSwapInt具体代码如下:
public final int getAndIncrement() {
return unsafe.getAndAddInt(this, valueOffset, 1);
}
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
2、为什么用CAS可以解决volatile的不保证原子性?
详细解释:
3、CAS的缺点?

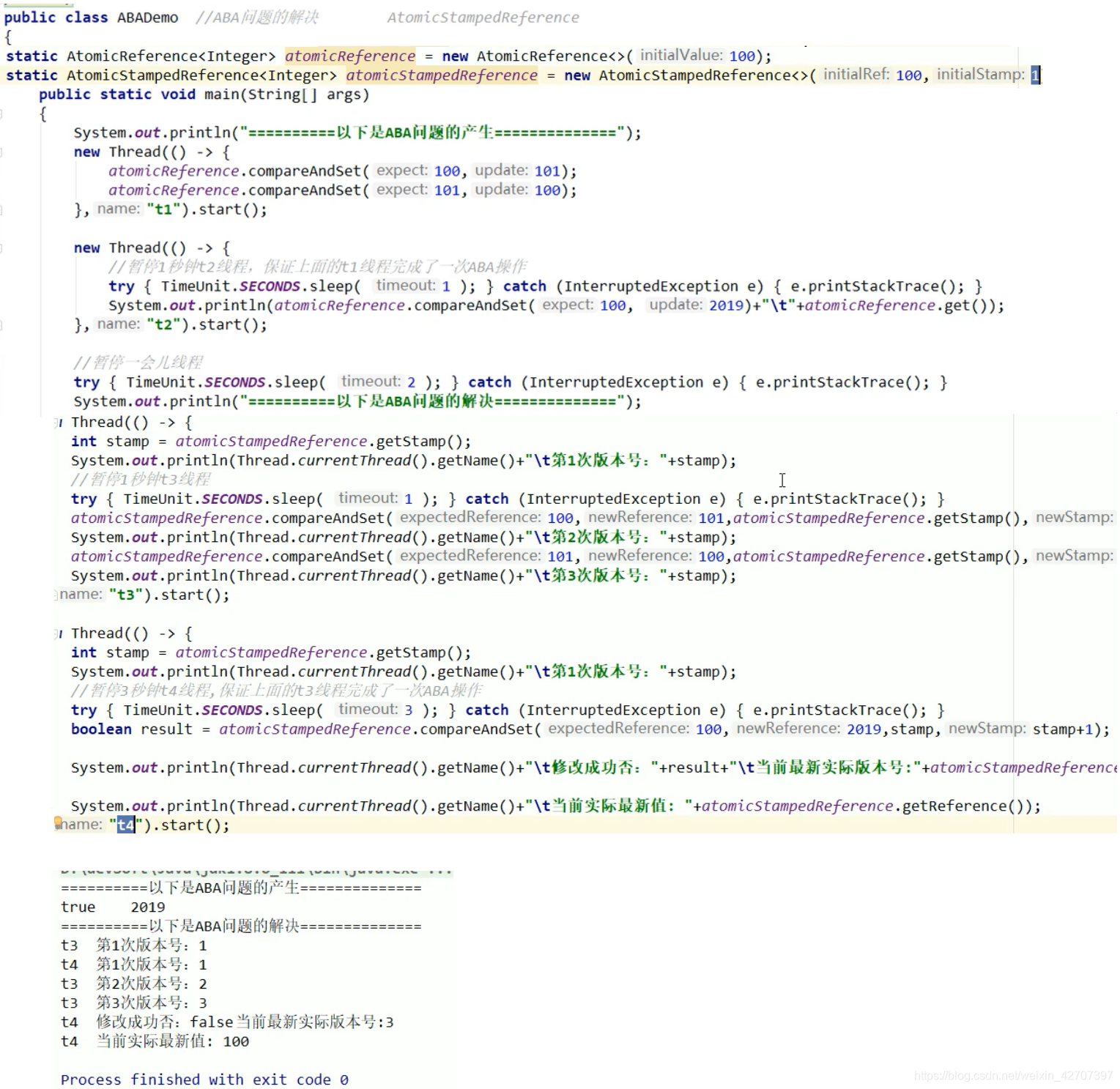
4、何为ABA(狸猫换太子)?
ABA:假设线程1把a=1改成a=2,又把a=2一顿操作后改成了a=1,线程2分配到线程资源后发现a的值还是初始化时的a=1,再进行CAS比较并交换时,就以为自己工作内存的a=1就是共享主内存的a=1,在此期间没其他线程动过
5、ABA问题的解决
使用atomic原子类带有版本戳的类AtomicStampedReference
2、集合类线程不安全问题
1、ArrayList
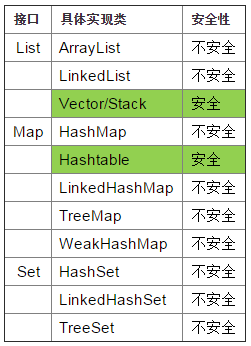
原因:ArrayList 底层是以数组方式实现的,实现了可变大小的数组,它允许所有元素,包括null。当开启多个线程操作List集合,比如向ArrayList中增加元素,就会出现线程不安全问题
解决方法:(1) List< Object> arrayList = new ArrayList();替换为List arrayList = new Vector<>();
(2) List< Object> arrayList = Collections.synchronizedList(new ArrayList< Object>());
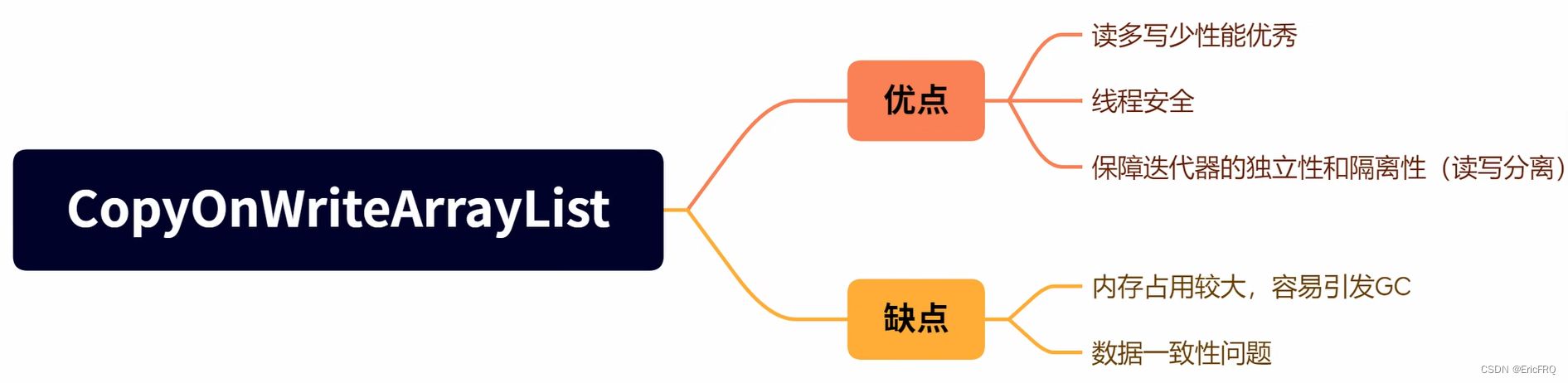
(3)使用JUC中的CopyOnWriteArrayList类进行替换,其中CopyOnWriteArrayList是写操作线程安全,读操作不安全就会出现数据不能一致性(比如写一半的时候去读),它的优缺点如下:
2、HashSet
原因:HashSet底层是由HashMap实现的,因为hashMap不安全,所以HashSet也是线程不安全的。HashSet单个的值,对应的HashMap中Key-value的key
解决方法:(1)Set< Object> set = Collections.synchronizedSet(new HashSet<>());
(2)Set< Object> set = new CopyOnWriteArraySet<>();
3、HashMap
解决方法:(1)使用Hashtable来代替HashMap
(2)Collections.synchronizedMap
(3)ConcurrentHashMap<k,v> 是JUC包中的一个类,方法内部使用了synchronized保证线程安全。在JDK1.7之前,使用分段数组(Segment 数组结构和 HashEntry 数组)+链表实现,JDK1.8使用Node数组+链表/红黑树(当链表长度大于8时转为红黑树存储)实现,通过cas+synchronized保证线程安全。
经测试,ConcurrentHashMap生成的Map性能是明显优于Hashtable和Collections 的synchronizedMap()方法。
面试题:1、Hashtable和ConcurrentHashMap的区别是什么?

2、有序的map有哪些,有什么区别?
- 跟据key值排序:TreeMap
- 跟据存放顺序:
LinkedHashMap是有序的,但是线程不安全,TreeMap与LinkedHashMap的区别(1)TreeMap是根据元素的内部比较器进行排序的,它可以根据key值的大小排序;(2)LinkedHashMap是保持存放顺序的。(3)TreeMap采用红黑树算法,遍历效率高;(4)LinkedHashMap采用链表实现,添加删除时效率高,遍历时效率低。 Map<String, Integer> linkedHashMap = Collections.synchronizedMap(new LinkedHashMap<String, Integer>());是跟据存放顺序有序且线程安全的ConcurrentSkipListMap也是跟据key有序且线程安全的,它和无序的ConcurrentHashMap的区别如下
【1】ConcurrentHashMap 与 ConcurrentSkipListMap都是线程安全的,适用于高并发的场景。
【2】ConcurrentHashMap是无序的,ConcurrentSkipListMap是有序的。
【3】ConcurrentSkipListMap 和 TreeMap,它们虽然都是有序的哈希表,但是有如下区别:它们的线程安全机制不同,TreeMap是非线程安全的,而ConcurrentSkipListMap是线程安全的。
ConcurrentSkipListMap是通过跳表实现的,而TreeMap是通过红黑树实现的。
【4】ConcurrentHashMap
和 HashMap,它们虽然都是有序的哈希表,但是有如下区别:
它们的线程安全机制不同,HashMap是非线程安全的,而ConcurrentHashMap 是线程安全的。
ConcurrentHashMap 底层采用分段的数组+链表实现。
【5】在4线程1.6万数据的条件下,ConcurrentHashMap 存取速度是ConcurrentSkipListMap 的4倍左右。
但ConcurrentSkipListMap有几个ConcurrentHashMap 不能比拟的优点:
1、ConcurrentSkipListMap 的key是有序的。
2、ConcurrentSkipListMap
支持更高的并发。ConcurrentSkipListMap
的存取时间是log(N),和线程数几乎无关。也就是说在数据量一定的情况下,并发的线程越多,ConcurrentSkipListMap越能体现出他的优势。
【6】何时使用
在非多线程的情况下,应当尽量使用TreeMap。
对于并发性相对较低的并行程序可以使用Collections.synchronizedSortedMap将TreeMap进行包装,也可以提供较好的效率。
对于高并发程序,应当使用ConcurrentSkipListMap,能够提供更高的并发度。
在多线程程序中,如果需要对Map的键值进行排序时,尽量使用ConcurrentSkipListMap,能得到更好的并发度。
注意,调用ConcurrentSkipListMap的size时,由于多个线程可以同时对映射表进行操作,所以映射表需要遍历整个链表才能返回元素个数,这个操作是个O(log(n))的操作。
3、线程锁
1、公平锁和非公平锁
(1)公平锁是有序的,依次排队获取锁,先到先得,但由于每个线程都要排队,所以效率低
(2)非公平锁是可以插队的,比如synchronized修饰的方法和ReentrantLock lock = new ReentrantLock(false);都是非公平锁,非公平锁在尝试插队失败后会排序,在插队成功后会马上进入方法执行,效率高,但是如果某一线程无限被其他线程插队,就会出现线程饥饿
2、非公平锁代码演示
public class MyNonfairLock {
/**
* false 表示 ReentrantLock 的非公平锁
*/
private ReentrantLock lock = new ReentrantLock(false);
public void testFail(){
try {
lock.lock();//**注意,一个锁lock 对应一个unlock**
System.out.println(Thread.currentThread().getName() +"获得了锁");//在lock和unlock之间的代码是加锁的代码
}finally {
lock.unlock();
}
}
public static void main(String[] args) {
MyNonfairLock nonfairLock = new MyNonfairLock();
Runnable runnable = () -> {
System.out.println(Thread.currentThread().getName()+"启动");
nonfairLock.testFail();
};
Thread[] threadArray = new Thread[10];
for (int i=0; i<10; i++) {
threadArray[i] = new Thread(runnable);
}
for (int i=0; i<10; i++) {
threadArray[i].start();
}
}
}
3、可重入锁(也叫递归锁):指同一线程在外层方法获取锁的时候,在内层方法会自动获取锁。ReentrantLock和Synchronized是典型的可重入锁。可重入锁最大的作用是避免死锁。
4、自旋锁(类似unsafe类里的getAndAddInt方法Unsafe.getUnsafe().getAndAddInt())
(1)理解:自旋锁不会做内核态和用户态之间的切换进入阻塞状态,而是不停地自旋判断有没有锁,等到持有锁的线程释放锁之后即可获取,这样就避免了用户进程和内核切换的消耗
(2)优缺点:自旋锁尽可能的减少线程的阻塞,但占用消耗cpu
(3)案例:
package com.myspringboot.test;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicReference;
/*
* @Description:自旋锁
**/
public class SpinLockDemo {
AtomicReference<Thread> atomicReference = new AtomicReference<>();
public void myLock(){
Thread thread = Thread.currentThread();
System.out.println(Thread.currentThread().getName()+"\t come in");
while(! atomicReference.compareAndSet(null,thread)){
}
}
public void myUnLock(){
Thread thread = Thread.currentThread();
atomicReference.compareAndSet(thread,null);
System.out.println(Thread.currentThread().getName() + "\t MyUnLock!!");
}
public static void main(String[] args) {
SpinLockDemo spinLockDemo = new SpinLockDemo();
new Thread(()->{
spinLockDemo.myLock();
try {TimeUnit.SECONDS.sleep(4);} catch (InterruptedException e) { e.printStackTrace(); }
spinLockDemo.myUnLock();
},"AA").start();
// try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) { e.printStackTrace(); }
new Thread(()->{
spinLockDemo.myLock();
try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) { e.printStackTrace(); }
spinLockDemo.myUnLock();
},"BB").start();
}
}
5、读写锁(ReentrantReadWriteLock)
理解:

图解:
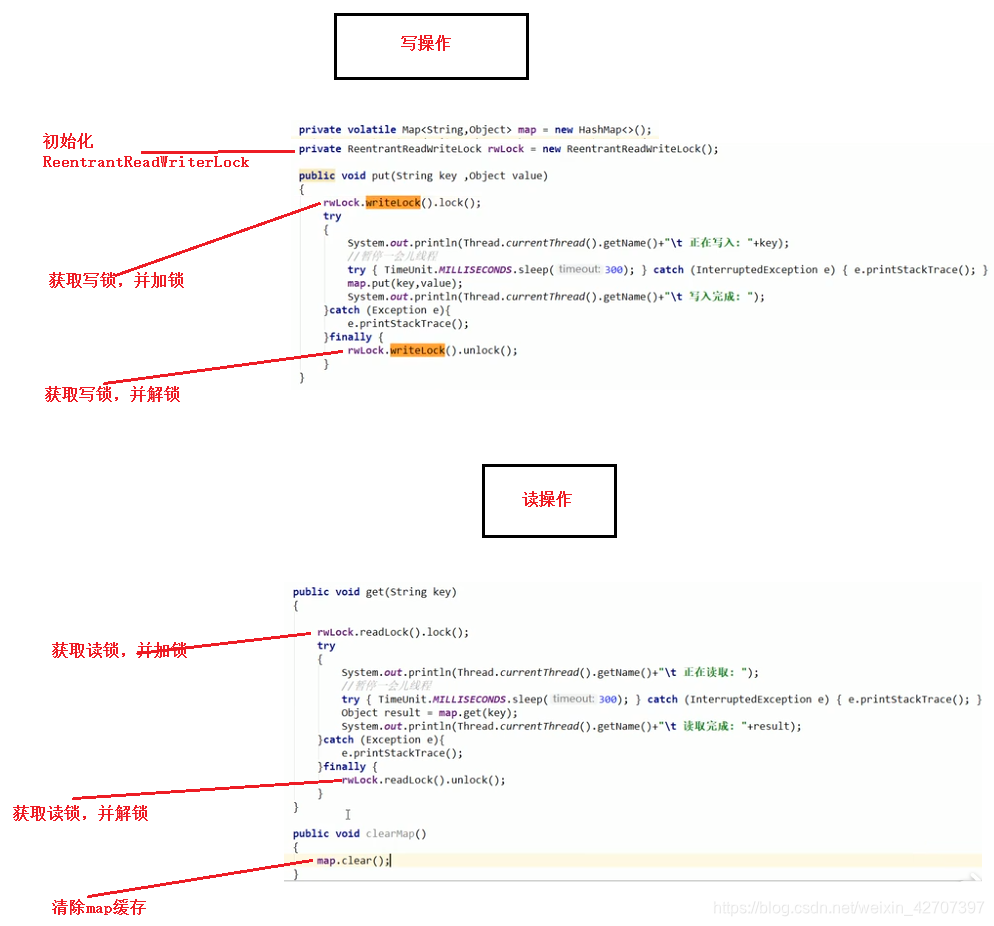
代码执行结果:(写只允许一个线程操作,读可以多线程共同操作)
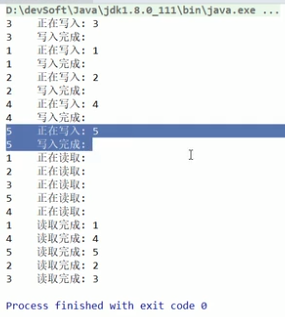
6、闭锁(CountDownLatch:倒计时,为0放行)
图解:
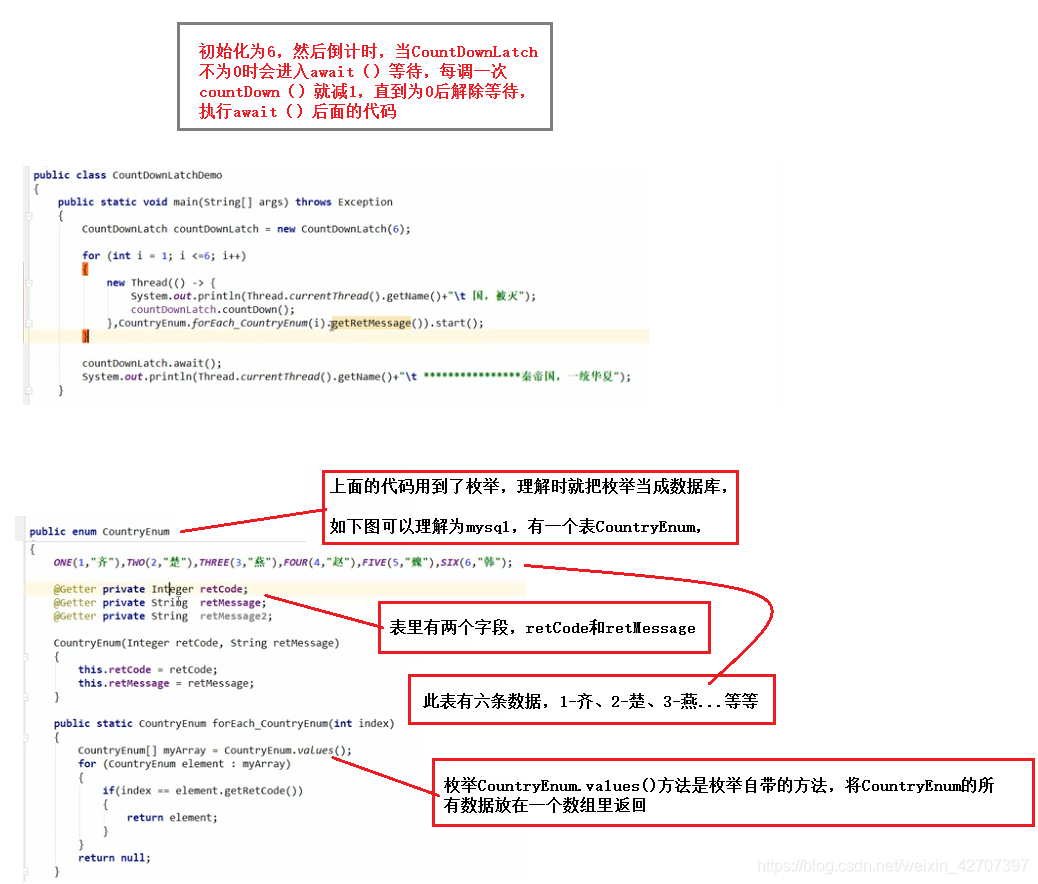
7、CyclicBarrier(循环屏障锁:累加,到某个值放行)

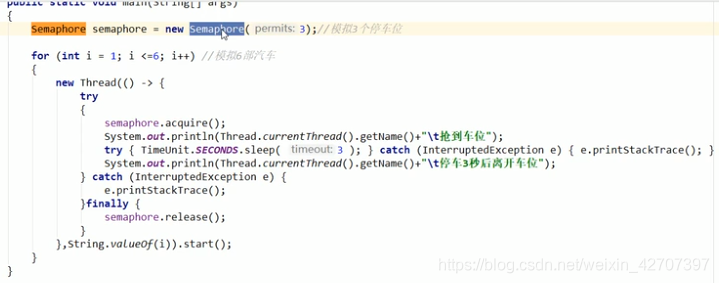
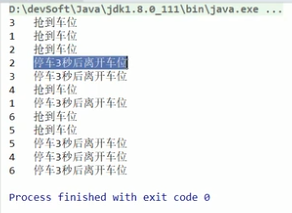
8、Semaphore(红绿灯锁:出一个就能进一个,不必等到所有都出)
运行结果:
9、悲观锁和乐观锁
比如:synchronized和lock就是悲观锁,上面的4、自旋锁(类似unsafe类里的getAndAddInt方法)自旋锁等使用cas解决并发问题的都是乐观锁

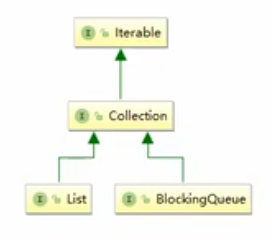
4、阻塞队列(BlockingQueue,先进先出)
1、所属Collection接口
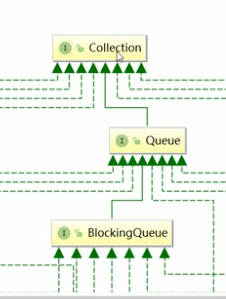
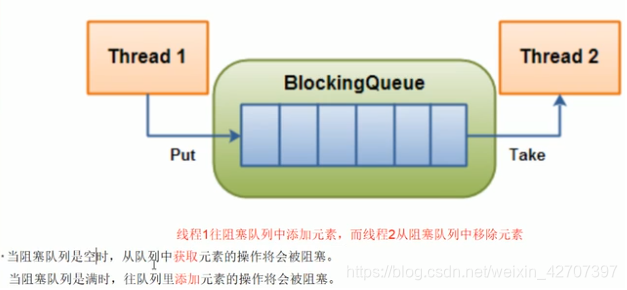
2、阻塞队列的原理?(什么情况下会阻塞?)
3、实现接口BlockingQueue的几个阻塞队列类(常用的是红色三个)


4、常用阻塞队列的用法之ArrayBlockingQueue 和 LinkedBlockQueue。
(案例)
ArrayBlockingQueue 和 LinkedBlockQueue使用是一样的,就像ArrayList和LinkedList一样,都有一样的例如add()、remove()等等这种方法,如下:
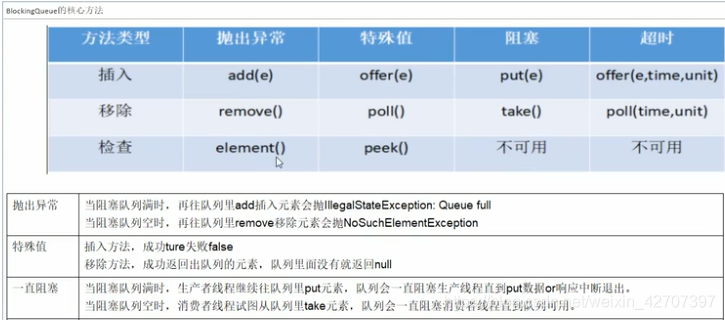

演示:以ArrayBlockingQueue为例,
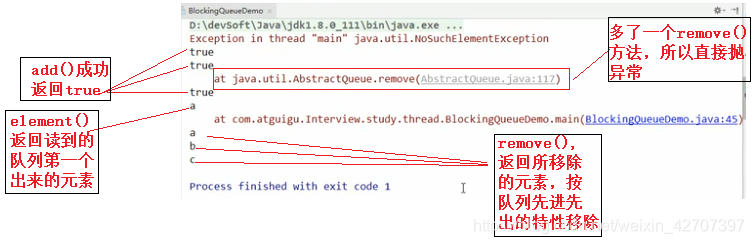
(1)使用add()方法时,add了几个元素,就remove()几个,对应不上的一律抛异常:
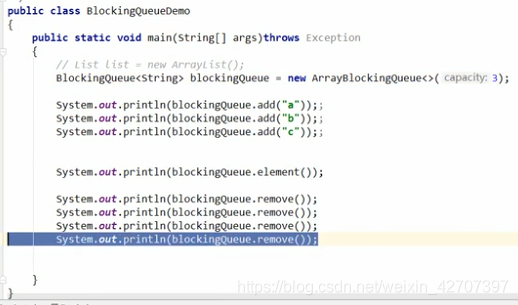
运行结果:
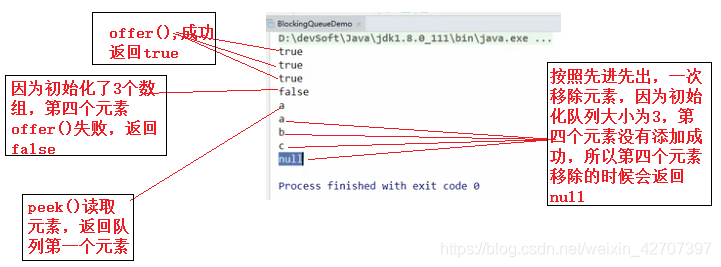
(2)offer()和poll()
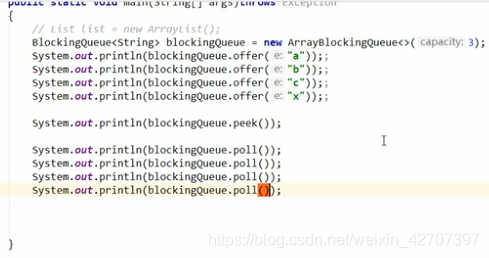
运行结果:
(3)一直阻塞:put()和take()
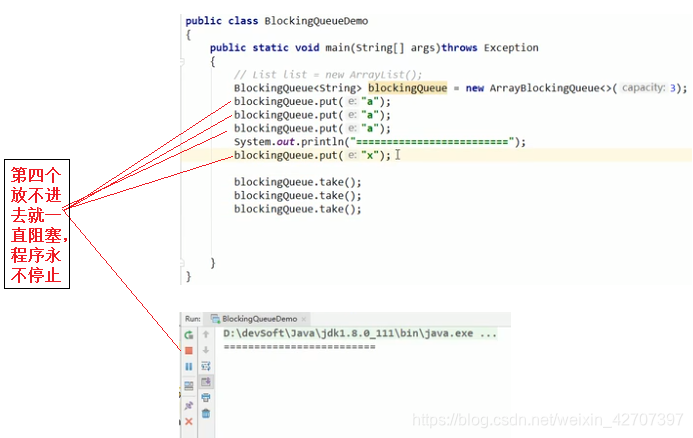
(4)超时结束阻塞:offer(e,time,unit)和poll(time,unit)
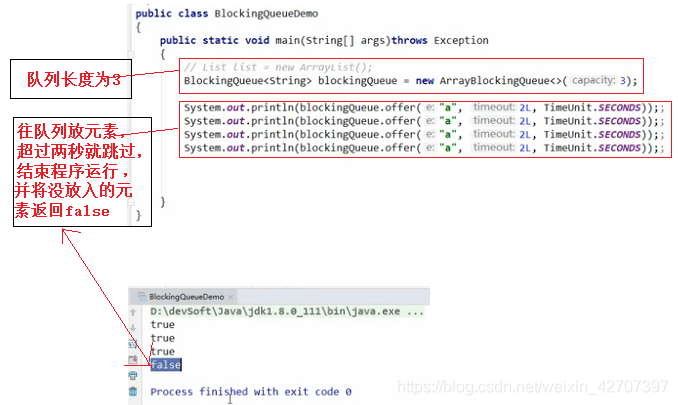
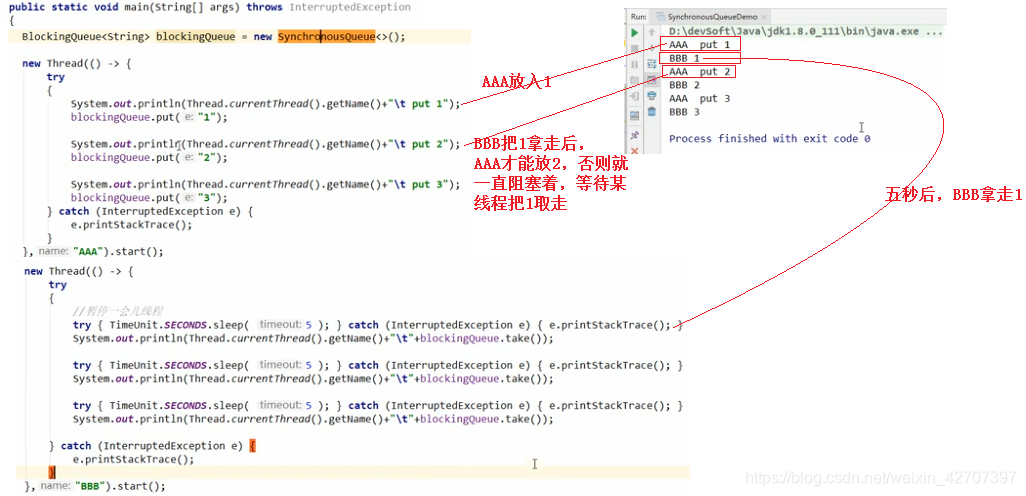
5、常用阻塞队列用法之synchronousQueue(拿走一个才能写入一个,有点类似于红绿灯锁—Semaphore的意思)
5、synchronized和Lock的区别
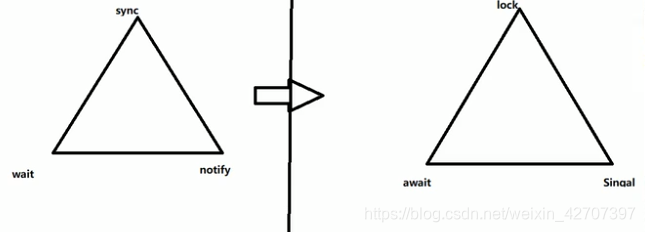
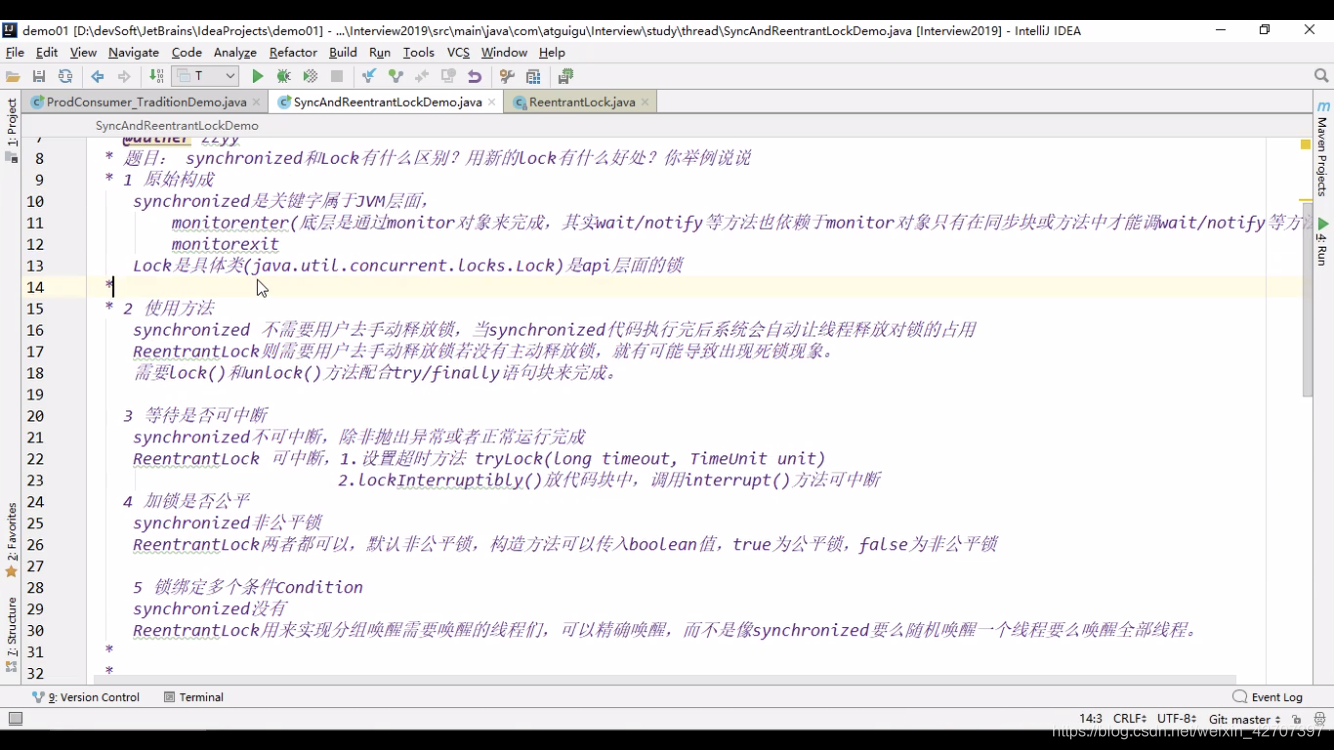
关于上述第五点,精确唤醒的用法如下:
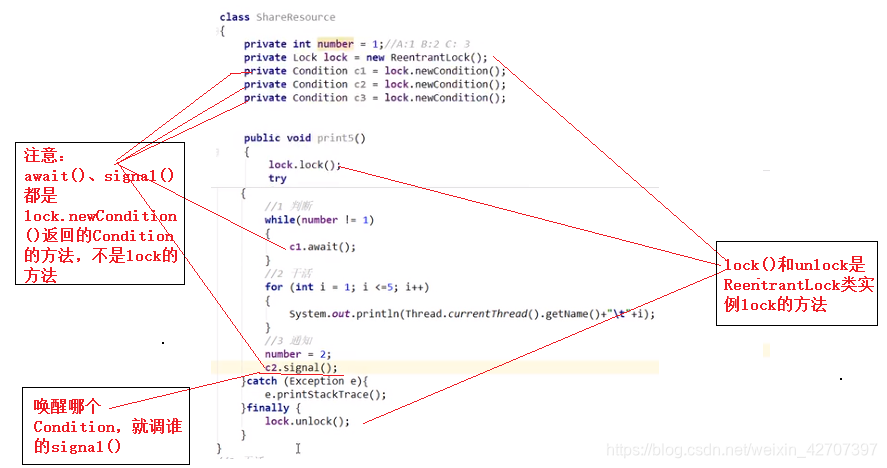


6、阻塞队列实现多线程等待唤醒(不用synchronized和lock来实现生产消费交替进行)
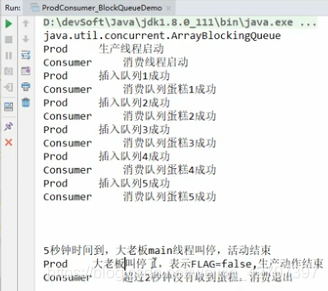
案例:两个线程,一个生产一份蛋糕,一个消费一份蛋糕,交替进行,直到五秒后全部停止
代码:

运行结果:
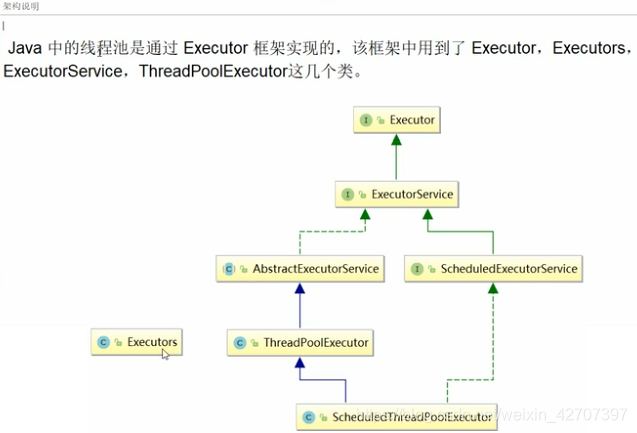
7、线程池
了解普通线程,参考博客:JUC和JAVA8新特性学习笔记的0、普通线程知识回顾和1、基础知识
作用:

线程复用原理:将任务和线程进行解耦,不再调用thread的start方法,而是runI()
架构说明:
常见的三种线程池:

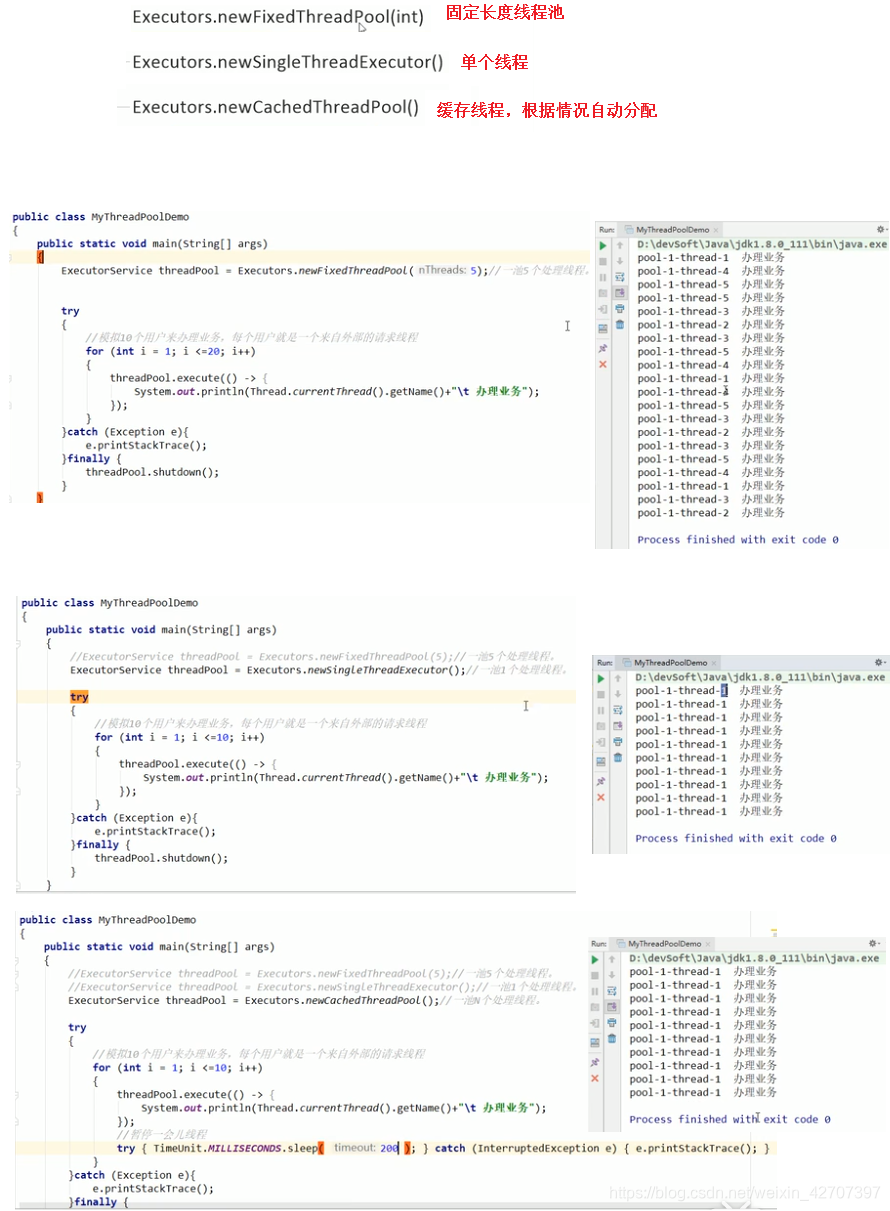
线程池的底层原理:
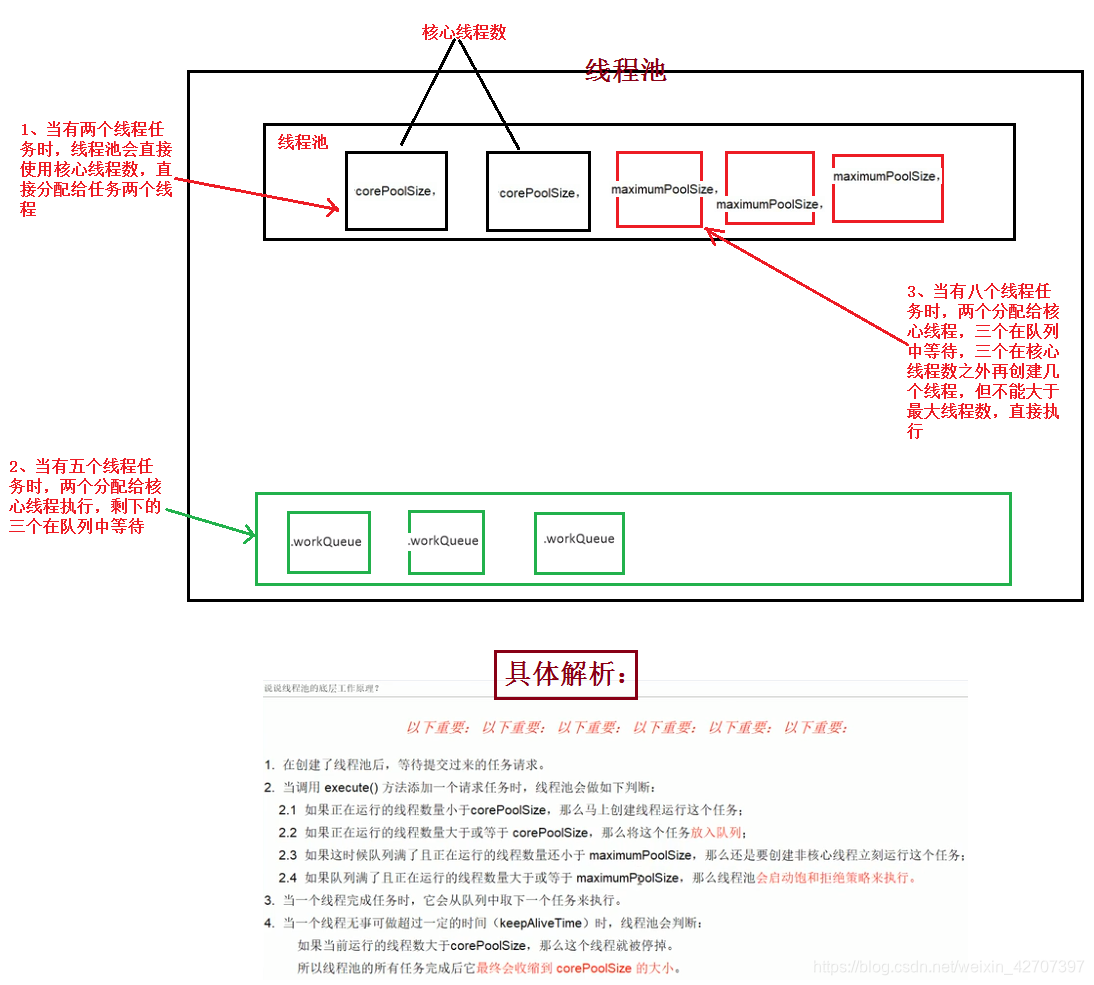

****注意两点:一就是救急线程执行完救急任务后,会从等待的队列中取排队的任务来执行,而不是不管队列中排队的任务,二就是上面的(3)描述,等待时间是指救急线程执行完自己任务和队列中任务后的存活时间,到keepAliveTime后会销毁
线程池的五大参数(实际有七大参数):

线程池七大参数中的第七个参数------拒绝策略:
(1)什么时候拒绝策略起作用?

(2)JDK内置的拒绝策略都有哪些?(4个)

(3)平时你用哪个线程池?为什么?
上面三个都不用,自己写。因为

自写线程池:
package com.wssp.business;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.TimeUnit;
import org.apache.tomcat.util.threads.ThreadPoolExecutor;
public class MyThread {
public static void main(String[] args) {
ExecutorService threadPool = new ThreadPoolExecutor(1, 3, 1L, TimeUnit.SECONDS,
new LinkedBlockingQueue<Runnable>(4), Executors.defaultThreadFactory(),
new java.util.concurrent.ThreadPoolExecutor.AbortPolicy());
try {
for (int i = 1; i < 10; i++) {
threadPool.execute(() -> {//这里调用的是execute方法,还可以使用submit,区别在下面写着
System.out.println(Thread.currentThread().getName() + "正在执行。。。");
});
}
} catch (Exception e) {
System.out.println(Thread.currentThread().getName() + "有异常");
} finally {
threadPool.shutdown();
}
}
}
//1. execute只能提交Runnable类型的任务,没有返回值,
//而submit既能提交Runnable类型任务也能提交Callable类型任务,返回Future类型。
//2. execute方法提交的任务异常是直接抛出的,而submit方法是是捕获了异常的,
//当调用FutureTask的get方法时,才会抛出异常。
(4)自写线程池时,最大线程数怎么配合理?
大量的计算,需要依靠cpu时,先查看本机的内核数:
System.out.println(Runtime.getRuntime().availableProcessors());

大量的数据读取存储时

补充:springboot项目中使用线程池
(1)新建配置类ThreadPoolConfig,代码如下:
/**
* @author: EricFRQ
* @date: 2021年12月21日
*/
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.annotation.EnableAsync;
import java.util.concurrent.*;
@Configuration(proxyBeanMethods = true)//这里设置成true,下面的getThreadPoolExecute注入后
//使用时都是同一个对象,是单例的,这里设置成false,后面使用的时候是不同的对象
public class ThreadPoolConfig {
@Bean(value ="getThreadPoolExecute" )
public ExecutorService getThreadPoolExecute() {
ExecutorService threadPool = new ThreadPoolExecutor(5, 10, 15L, TimeUnit.SECONDS, new LinkedBlockingDeque<Runnable>(10),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.CallerRunsPolicy());
return threadPool;
}
}
(2)使用自定义线程池
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ExecutorService;
@RestController
@RequestMapping(value = "/geoCode/crawler")
public class GeoPoiController {
@Resource(name = "getThreadPoolExecute")
ExecutorService execute;
@GetMapping("/crawlersGeoPoiByUrl")
public void crawlersGeoPoiByUrl() {
//两种使用自定义线程池方式
//线程池直接执行run()
execute.execute(() -> {
//...业务代码
});
//异步编排提交给自定义线程池
CompletableFuture.runAsync(() -> {
//...业务代码
}, execute);
}
}
8、GC垃圾回收相关
(1)常见的垃圾回收算法?
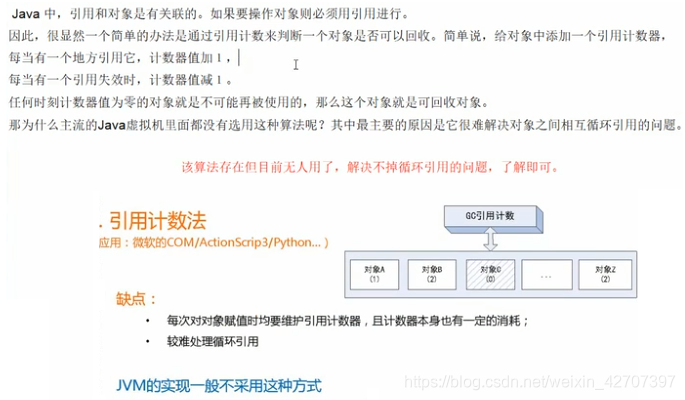
1、引用计数法,每次引用加一,取消引用减一,为0当垃圾回收(解决不了循环引用问题,已淘汰,了解即可)
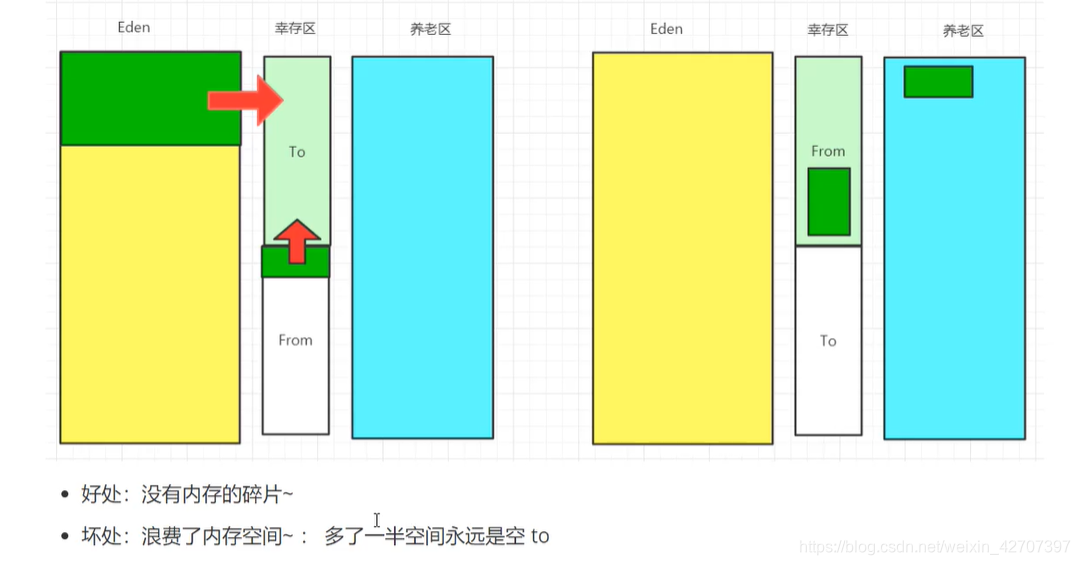
2、复制

3、标记清除法
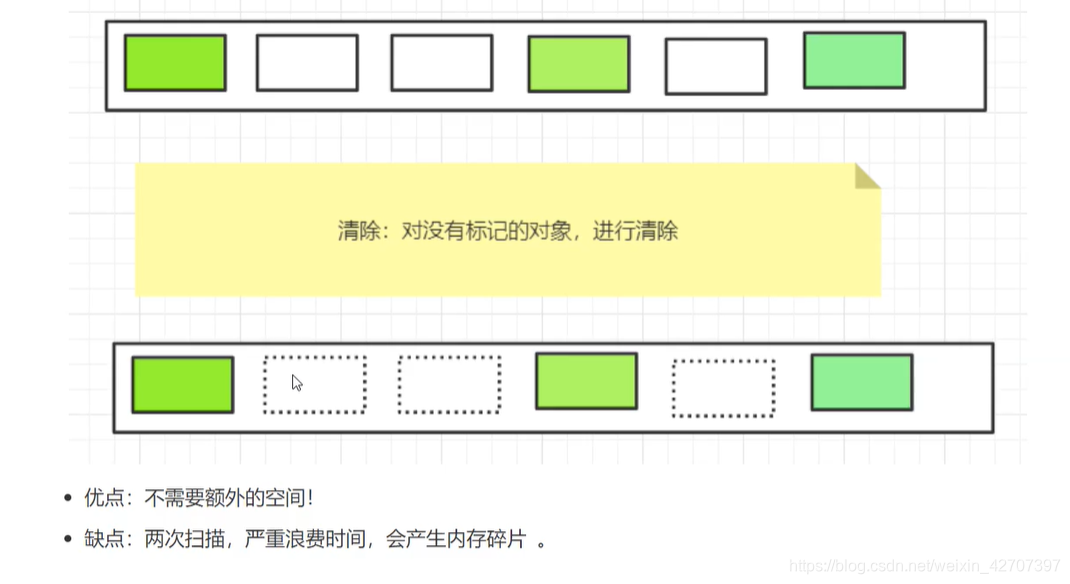

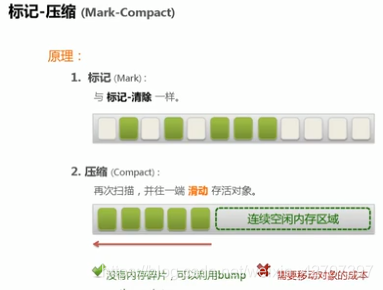
4、标记整理(也叫标记清除压缩)
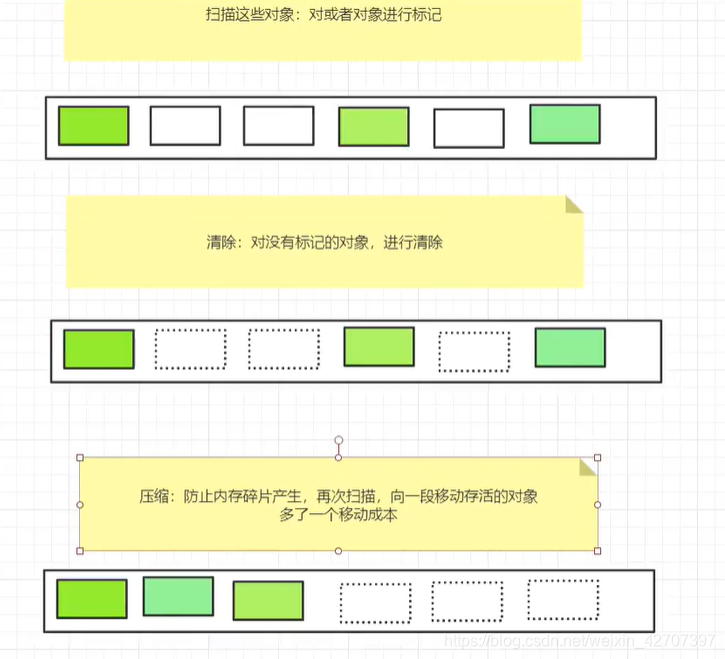

(2)什么是垃圾?
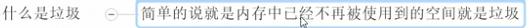
(3)回收的时候如何确定垃圾?

其中可达性分析使用到了GC roots算法(没有gc roots或者gc roots不可达的对象就是垃圾,需要回收)
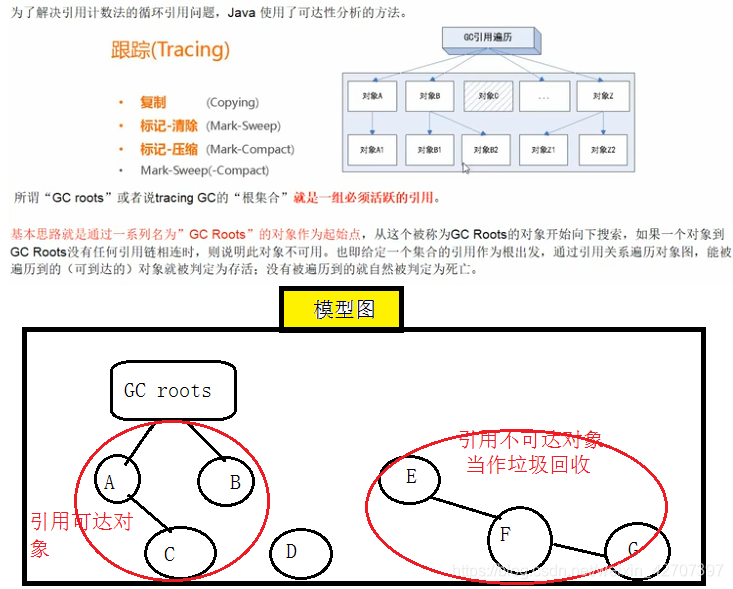
(4)GC roots是什么?什么对象适合作为gc roots?

(5)垃圾收集器有哪些?
首先明确什么是垃圾收集器:就是上面GC算法的实现

收集器种类:
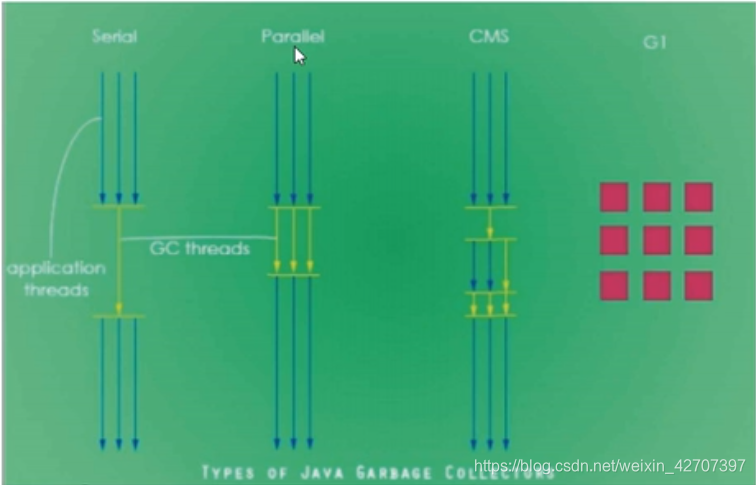
java8:
- serial:串行
- parallel:并行
- CMS(Concurrent Mark Sweep):并发标记清除
- G1:将堆内存分割成不同的区域然后并发的对其进行垃圾回收
java12: - 新增了一个ZGC
(6)GC回收的类型主要有哪几种?

(7)垃圾收集器怎么使用?(young和old区都用哪些垃圾收集器)
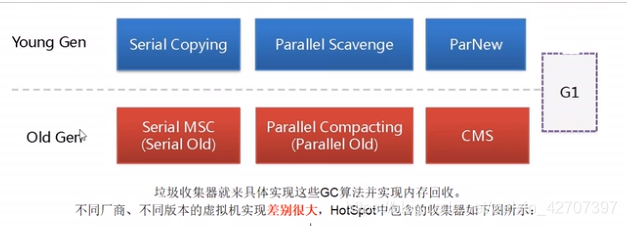
下面是七大垃圾收集器,连上线的是指当配置其中一个,另外一个默认配置
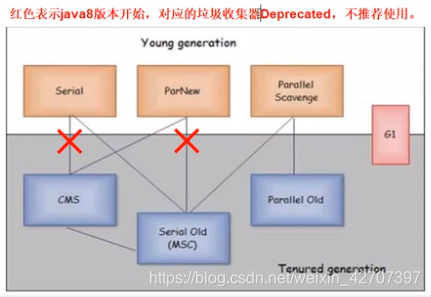
-
GC之Serial

-
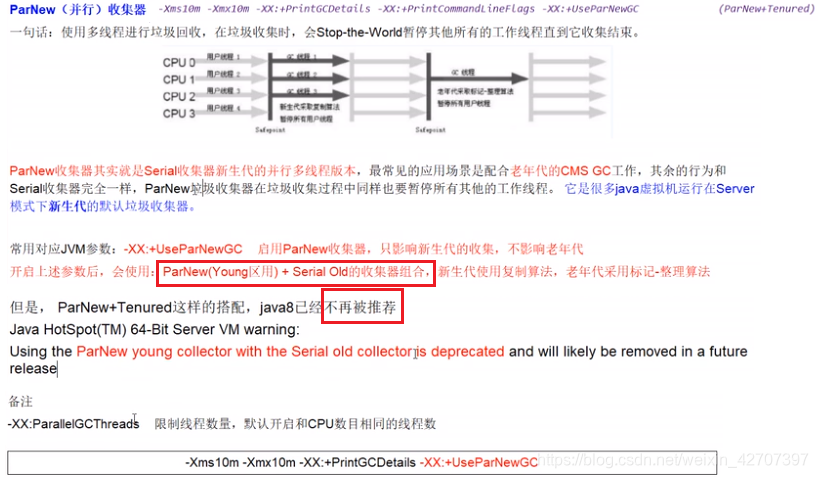
GC之ParNew
-
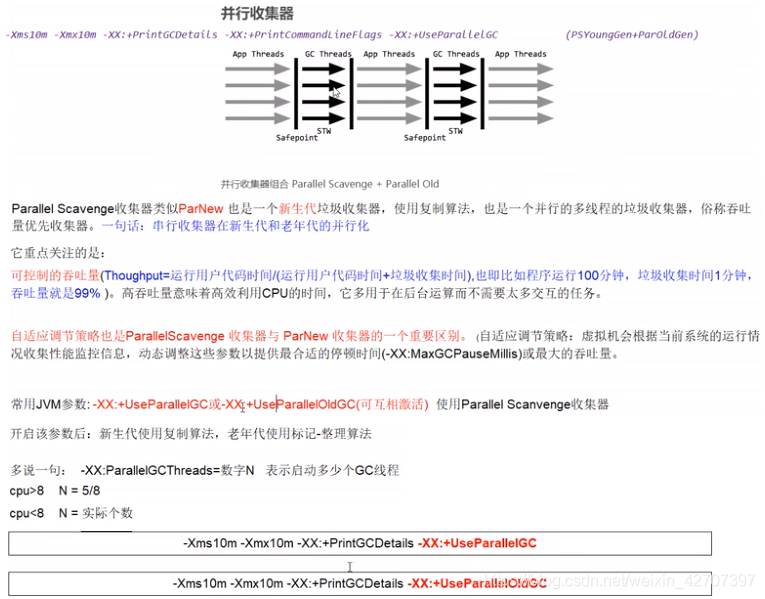
GC之Parallel
-
GC之Parallel Old

-
GC之CMS:并发收集低停顿但并发执行对cpu执行压力大,采用的标记清除发会导致大量碎片

注意上述圈红圈的

-
GC之G1

(8)如何根据实际业务选择垃圾收集器组合?
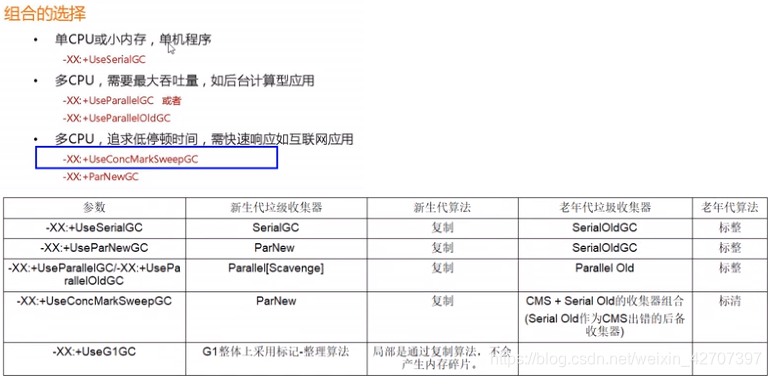
组合的选择是根据每个垃圾回收器的特性来选择的,垃圾回收器的几种总结对比:
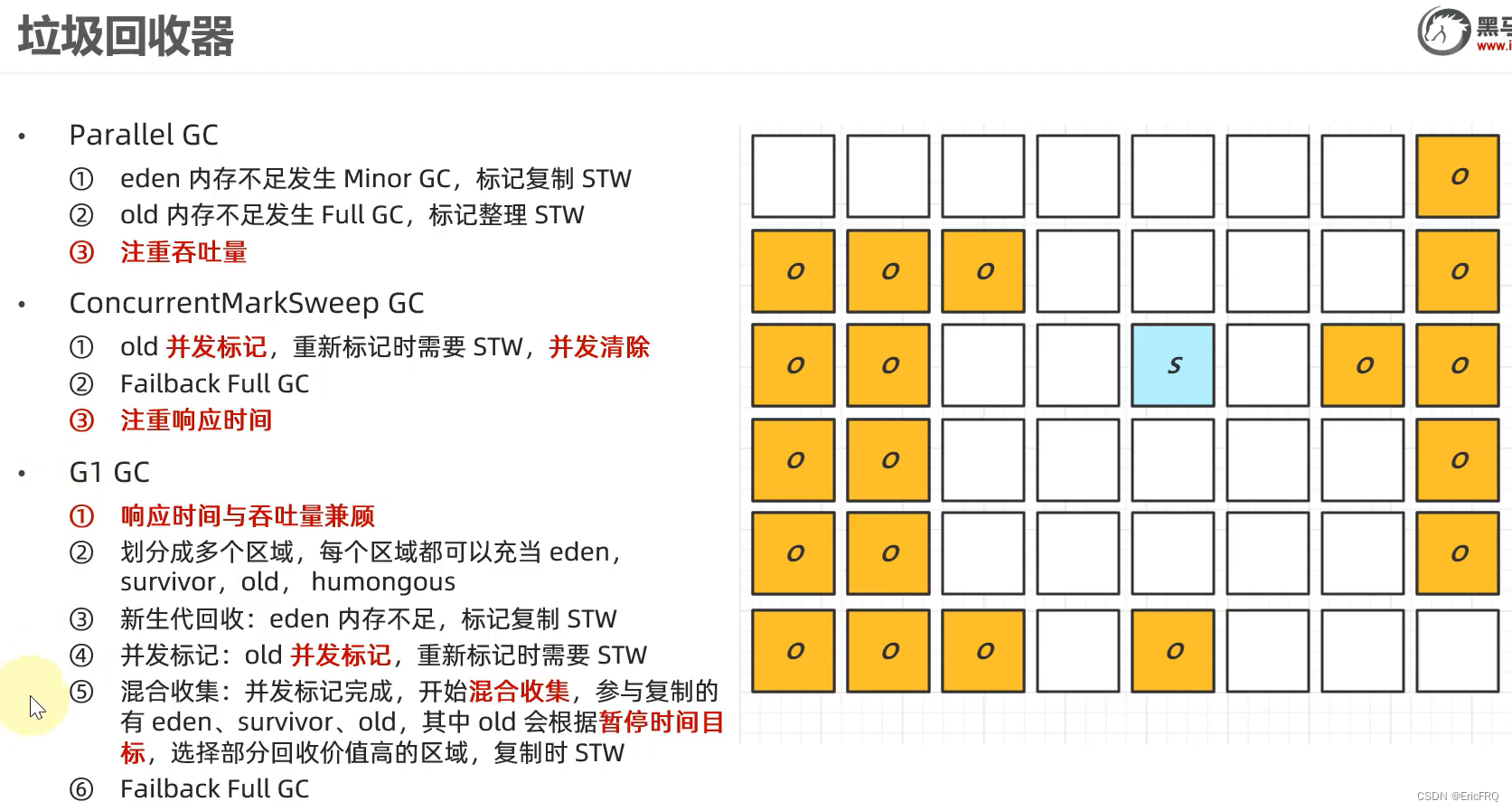
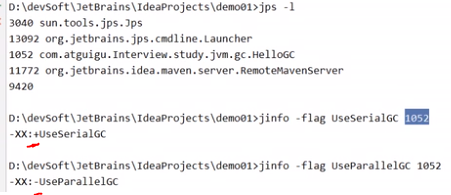
(9)怎样查看程序使用的垃圾收集器是什么?
- -XX:+PrintCommandLineFlags -version

- 或者使用jps和jinfo命令,结果中+是开启状态,-是关闭状态
9、JVM调优相关
附上大佬总结:JVM常见面试题解析
另一篇博客:JVM学习笔记
jvm实战案例:阿里终面:每天100w次登陆请求, 8G 内存该如何设置JVM参数?
JVM中的堆,一般分为三大部分:新生代、老年代、永久代(在JVM中的一个非堆内存在java8之前叫做永久代,在java8后,就更名为元空间):
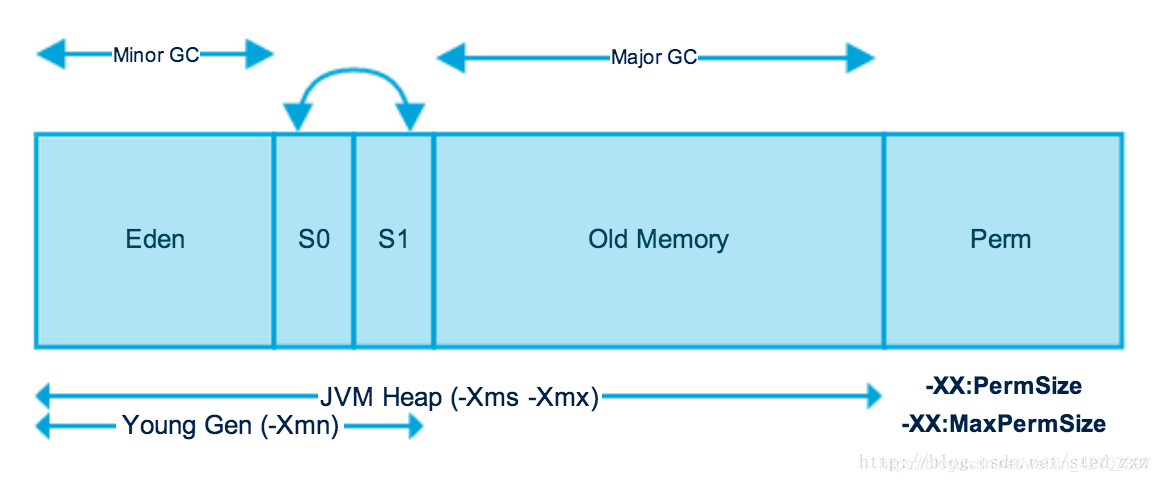
新生代和老年代又分为以下四个区:
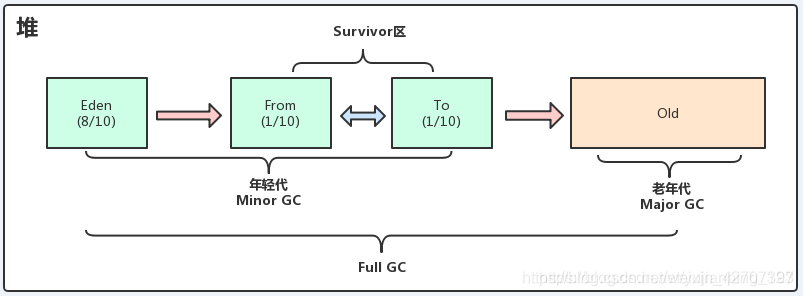
新生代老年代工作过程:

(1)说说你做过的jvm调优和参数配置
-xms 、 -xmx 等配置、jps 、 jinfo、jstack、jmap等命令

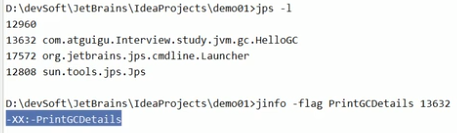
排查内存使用情况:
- 将某个java程序的栈信息导出到文件

打开下面的工具
将导出的文件导入进去进行分析
java自带的监控工具有两个,一个是jconsole、一个是jvisualvm
打开方式:在安装了java环境的前提下,cmd命令直接输入jconsole即可弹出版面,如下图:
参数类型:
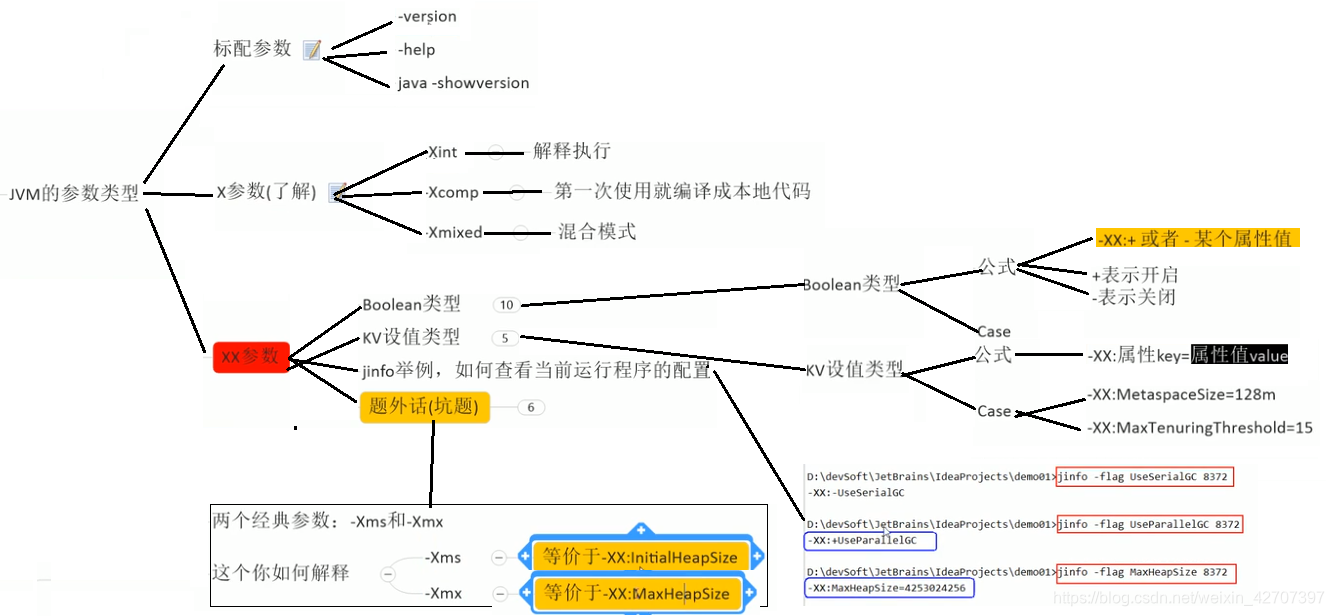
修改后查看jvm参数

(2)JVM基本配置参数有哪些?
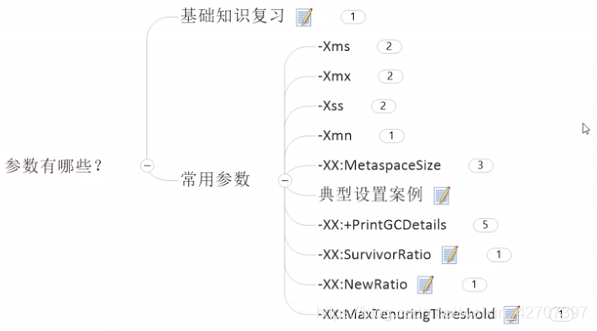
每个参数的位置图示如下:
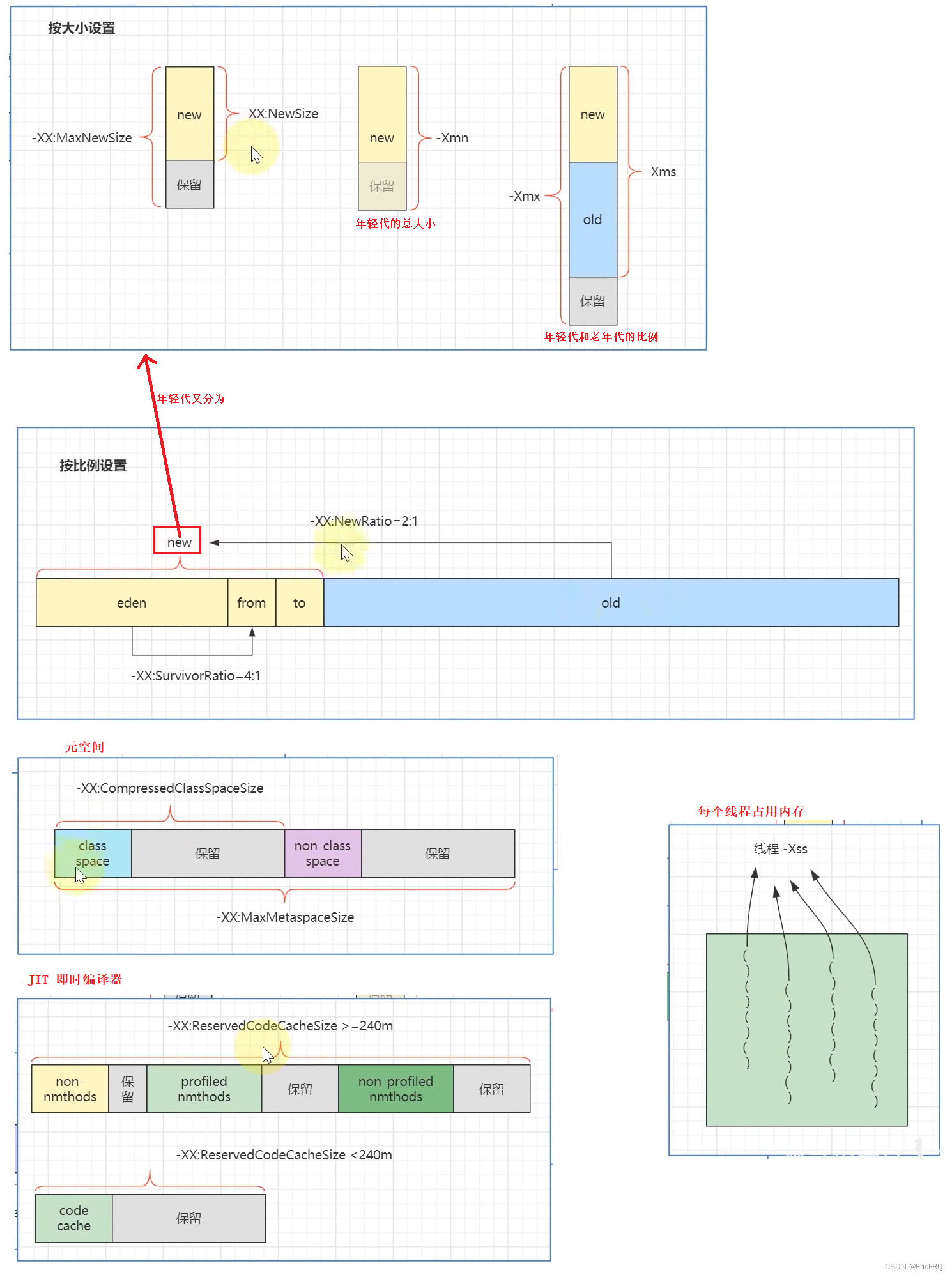
每个参数的文字描述如下:
-
-Xms:初始大小内存,默认为物理内存的1/64。等价于-XX:InitialHeapSize
-
-Xmx:最大分配内存,默认为物理内存的1/4。等价于-XX:MaxHeapSize
-
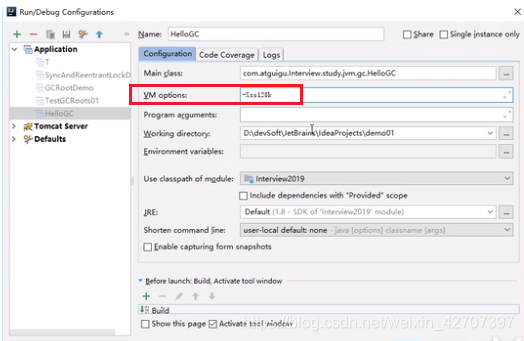
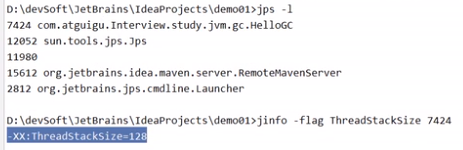
-Xss:设置单个线程栈的大小,一般默认为512k–1024k。等价于-XX:ThreadStackSize。例如:
-Xss256k设置栈大小为256k
例如:查看某个java程序的线程栈大小?-
jps查看此程序JVM的参数号
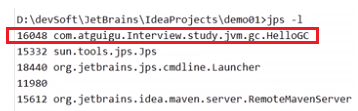
-
jinfo 查看具体某参数号的某参数

-
当手动设置-Xss=128k后,再次执行上面两个命令查看,就成了设置的128k
-
-
-Xmn:设置年轻代大小
-
-XX:MetaspaceSize:设置元空间大小

-
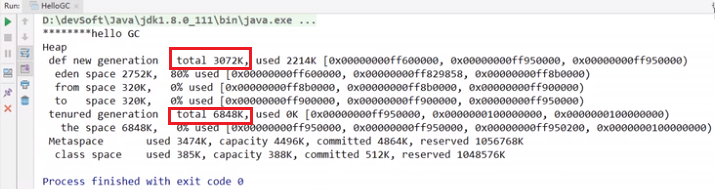
-XX:PrintGCDetails:运行时打印GC工作细节
- 没有OOM(内存溢出)时
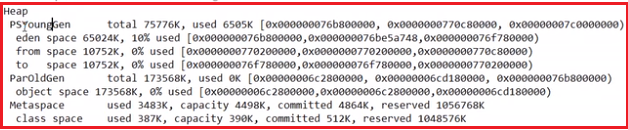
- OOM时

- 没有OOM(内存溢出)时
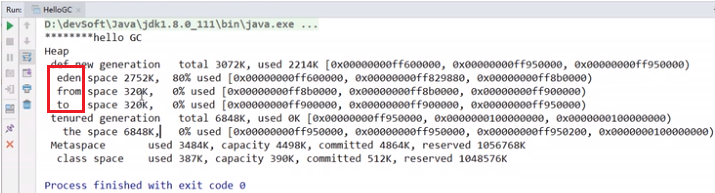
-
-XX:SurvivorRatio=8:设置新生代中eden和s0/s1(s0=s1)空间的比例为eden:s0:s1=8:1:1(8:1:1也是默认值),设置完后可使用-XX:PrintGCDetails查看设置后的具体比例
-
-XX:NewRatio=2:配置年轻代和老年代在堆结构的占比(默认为2,新生代占1,老年代占2,年轻代占整个堆的1/3),NewRatio的值就是设置老年代的占比,剩下的1给新生代。设置完后可使用-XX:PrintGCDetails查看设置后的具体比例

-
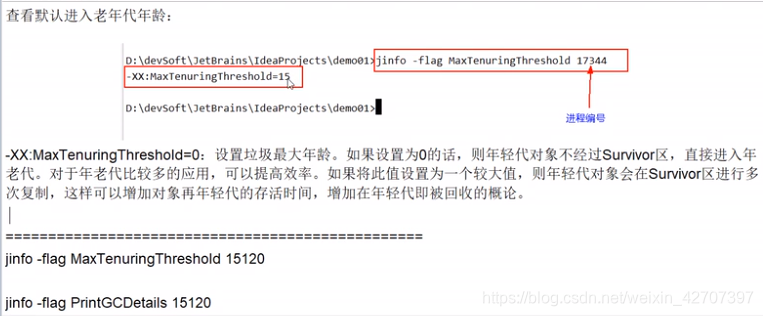
-XX:MaxTenuringThreshold=15:设置垃圾最大年龄(默认值为15)
-
JVMGC结合springboot调优
- 启动jar(war)包的普通方式:
java -jar xxx.jar

- 使用maven打包成jar包,然后
java -server jvm的各种参数命令 -jar xxx.jar

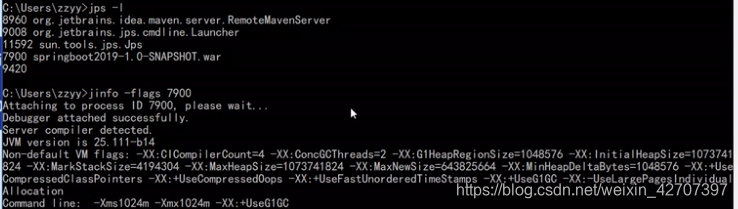
运行上诉命令后 , 可使用jps -l查看此程序的进程号,再根据进程号jinfo -flags 进程号查看具体jvm参数
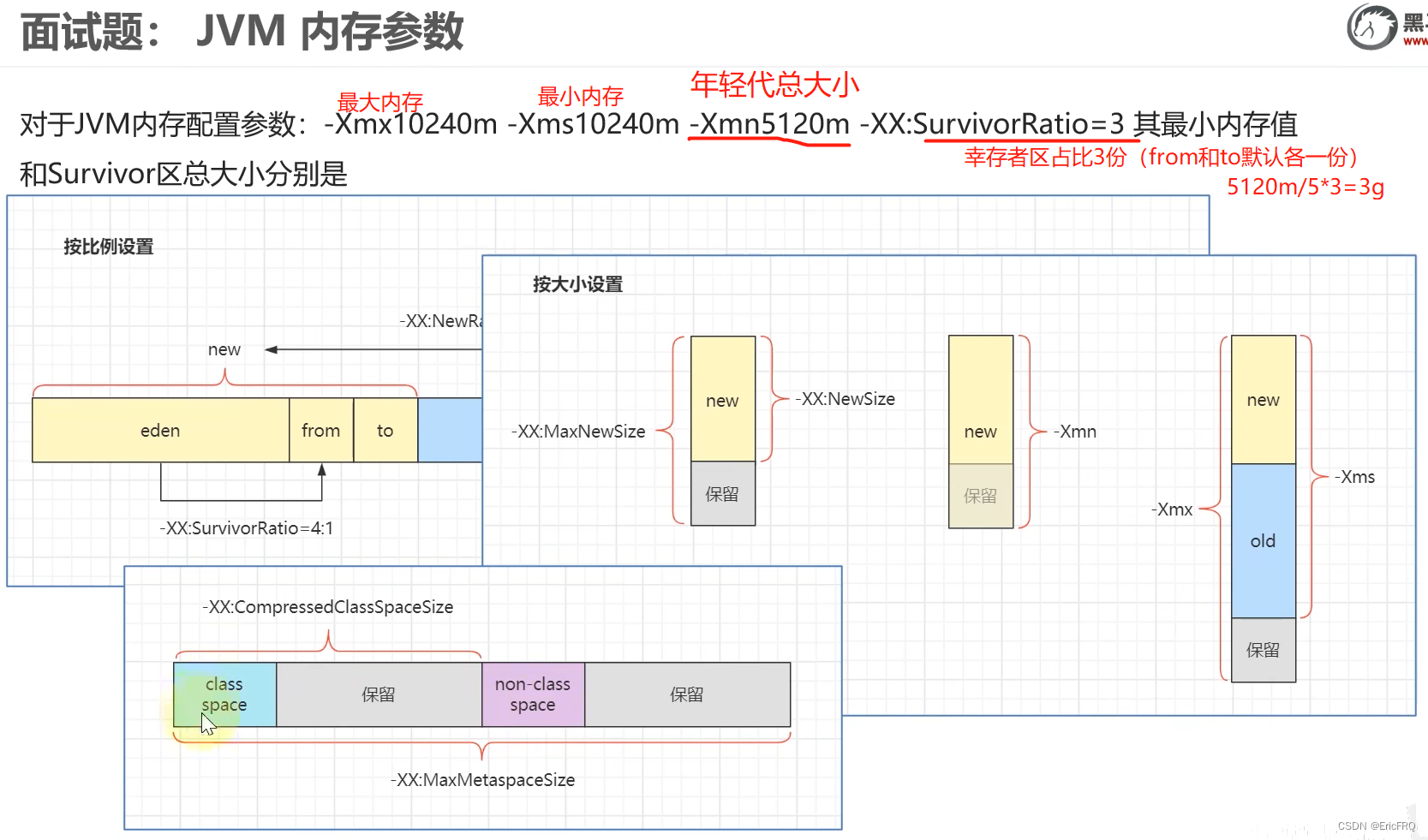
(3)跟据上面的介绍,看一个案例题:
10、java对象的引用类型
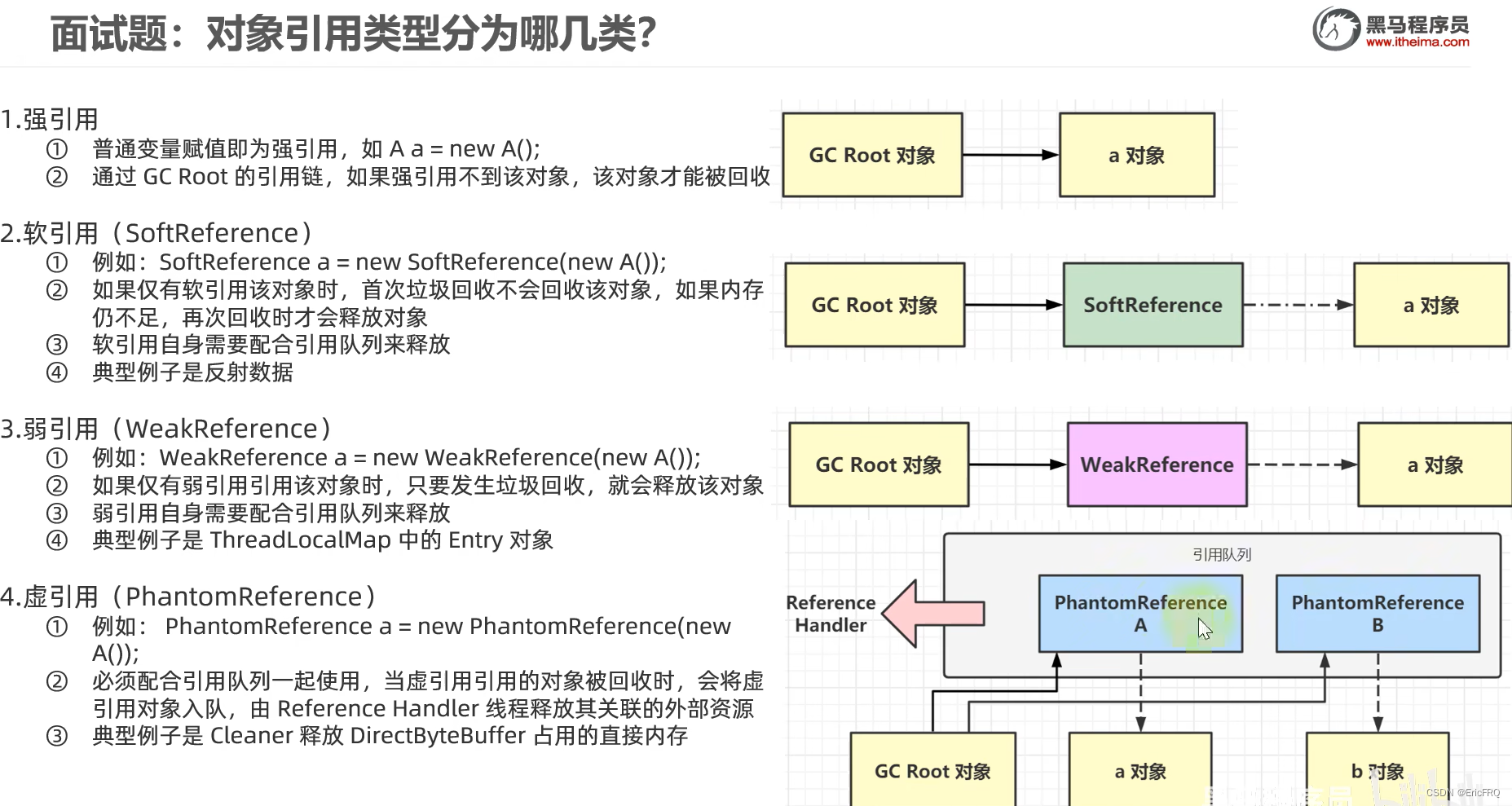
1、 强引用:GC永远不回收此引用对象
Object object1=new Object(); //这样定义的默认为强引用
Object object2=object1; //2引用赋值
object1=null;
System.gc();//此时object1被回收,object2不能被GC回收
2、软引用:内存够的时候不回收,不够的时候回收

Object o1=new Object();
SoftReference<Object> sr1=new SoftReference<>(o1);
System.out.println(o1);//未被回收
System.out.println(sr1.get());//未被回收
o1=null;
System.gc();
System.out.println(o1);//null
System.out.println(sr1.get());//若内存够用就保留,内存不够用回收,sr1=null
3、弱引用:只要调用了GC,一定被回收(主要解决OOM问题)
Object o1 = new Object();
WeakReference<Object> sr1 = new WeakReference<>(o1);
System.out.println(o1);
System.out.println(sr1.get());
o1 = null;
System.gc();
System.out.println(o1);//null
System.out.println(sr1.get());//null
拓展:WeakHashMap。普通map在把key置为null时,调用gc()后map仍存在,而WeakHashMap把key置空,map也被清空了
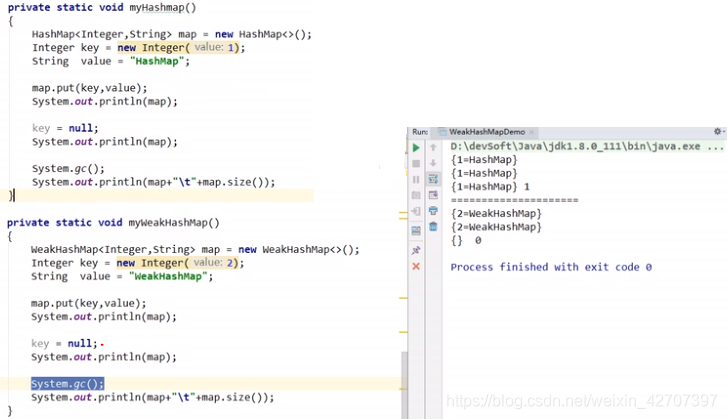
4、虚引用(幽灵引用):无论有没有调用gc,此引用总为空(get()方法总返回null),当回收后放入引用队列(ReferenceQueue)中 。一般用来处理监控到垃圾回收时收到一个系统通知或下一步处理。
- ReferenceQueue
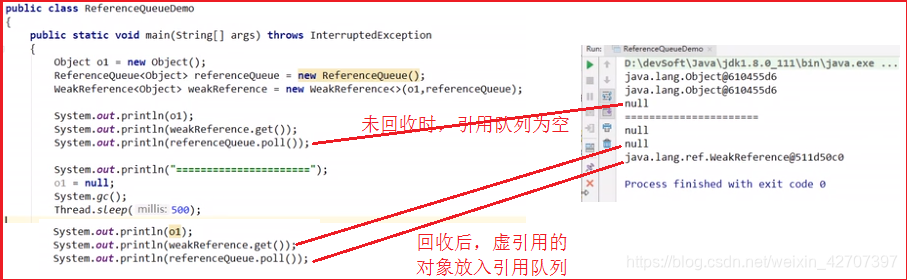
- PhantomReference
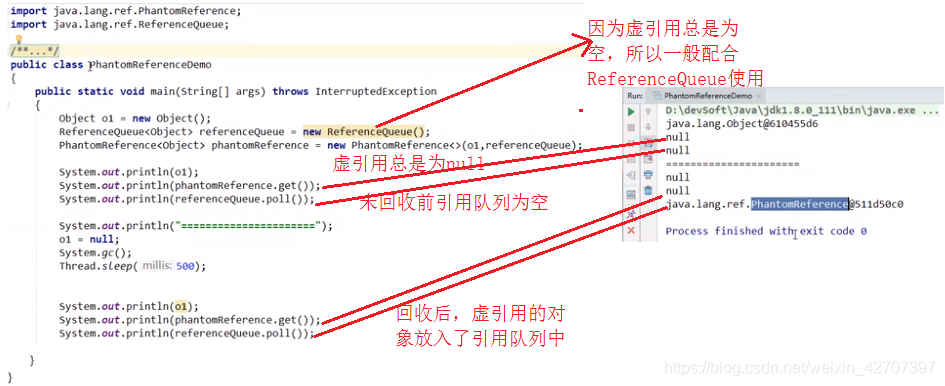
5、总结:几种引用的总结
11、OOM(OutOfMemory内存溢出错误)
- 首先要明确一点,在jvm中,内存溢出可能发生的地方:栈(jvm栈和本地方法栈)、堆、方法区,不会内存溢出的地方只有程序计数器

- 其次我们要考虑下在什么情况下会出现OOM?
常见的有以下几种情况:
(1)错误使用线程池
(1-1)误用固定大小线程池,等待的队列个数为Integer的max值,要用自定义线程池
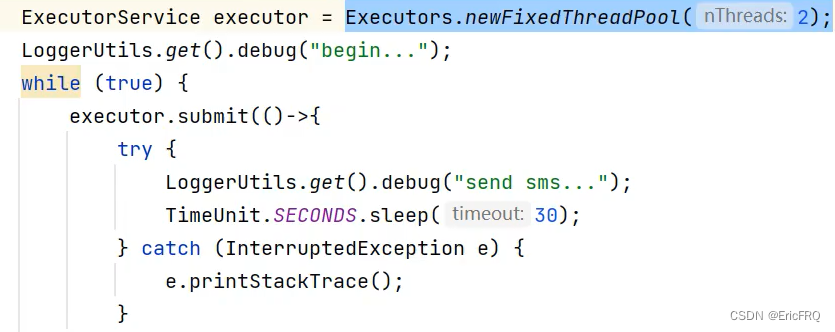
(1-2)误用缓存线程池,允许创建的最大线程数量为Integer的max值,解决方法也是要用自定义线程池

(2)一次查询的数据量过大
(3)动态创建类时导致类过多 - OOM的继承关系
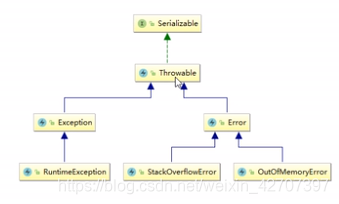

- StackOverflowError(栈溢出错误)
public class OOMDemo {
public static void main(String[] args) {
System.out.print("***********");
stackOverflowDemo();
}
private static void stackOverflowDemo() {
stackOverflowDemo();
}
}
/**执行结果:
************Exception in thread "main" java.lang.StackOverflowError
at com.ws.wssp.elec.business.OOMDemo.stackOverflowDemo(OOMDemo.java:12)
at com.ws.wssp.elec.business.OOMDemo.stackOverflowDemo(OOMDemo.java:12)
at com.ws.wssp.elec.business.OOMDemo.stackOverflowDemo(OOMDemo.java:12)
at com.ws.wssp.elec.business.OOMDemo.stackOverflowDemo(OOMDemo.java:12)
at com.ws.wssp.elec.business.OOMDemo.stackOverflowDemo(OOMDemo.java:12)
at com.ws.wssp.elec.business.OOMDemo.stackOverflowDemo(OOMDemo.java:12)
at com.ws.wssp.elec.business.OOMDemo.stackOverflowDemo(OOMDemo.java:12)
at com.ws.wssp.elec.business.OOMDemo.stackOverflowDemo(OOMDemo.java:12)
at com.ws.wssp.elec.business.OOMDemo.stackOverflowDemo(OOMDemo.java:12)
at com.ws.wssp.elec.business.OOMDemo.stackOverflowDemo(OOMDemo.java:12)
at com.ws.wssp.elec.business.OOMDemo.stackOverflowDemo(OOMDemo.java:12)
at com.ws.wssp.elec.business.OOMDemo.stackOverflowDemo(OOMDemo.java:12)
at com.ws.wssp.elec.business.OOMDemo.stackOverflowDemo(OOMDemo.java:12)
at com.ws.wssp.elec.business.OOMDemo.stackOverflowDemo(OOMDemo.java:12)
at com.ws.wssp.elec.business.OOMDemo.stackOverflowDemo(OOMDemo.java:12)
at com.ws.wssp.elec.business.OOMDemo.stackOverflowDemo(OOMDemo.java:12)
at com.ws.wssp.elec.business.OOMDemo.stackOverflowDemo(OOMDemo.java:12)
at com.ws.wssp.elec.business.OOMDemo.stackOverflowDemo(OOMDemo.java:12)
at com.ws.wssp.elec.business.OOMDemo.stackOverflowDemo(OOMDemo.java:12)
at com.ws.wssp.elec.business.OOMDemo.stackOverflowDemo(OOMDemo.java:12)
*/
- OutOfMemoryError:java heap space(java堆空间错误)
String str = "Eric";
while (true) {
str += str + new Random().nextInt(111111) + new Random().nextInt(222222);
str.intern();//intern():查看常量池中是否存在和调用方法的字符
//串内容一样的字符串,如果有的话,就返回该常量池中的字符串,若没有
//的话,就在常量池中写入一个堆中该字符串对象的一个引用,指向堆中的
//该对象,并返回该引用。
}
/*运行结果:
* ***********Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at java.util.Arrays.copyOf(Arrays.java:3332)
at java.lang.AbstractStringBuilder.expandCapacity(AbstractStringBuilder.java:137)
at java.lang.AbstractStringBuilder.ensureCapacityInternal(AbstractStringBuilder.java:121)
at java.lang.AbstractStringBuilder.append(AbstractStringBuilder.java:421)
at java.lang.StringBuilder.append(StringBuilder.java:136)
at com.ws.wssp.elec.business.OOMDemo.heapSpaceDemo(OOMDemo.java:15)
at com.ws.wssp.elec.business.OOMDemo.main(OOMDemo.java:9)
* */
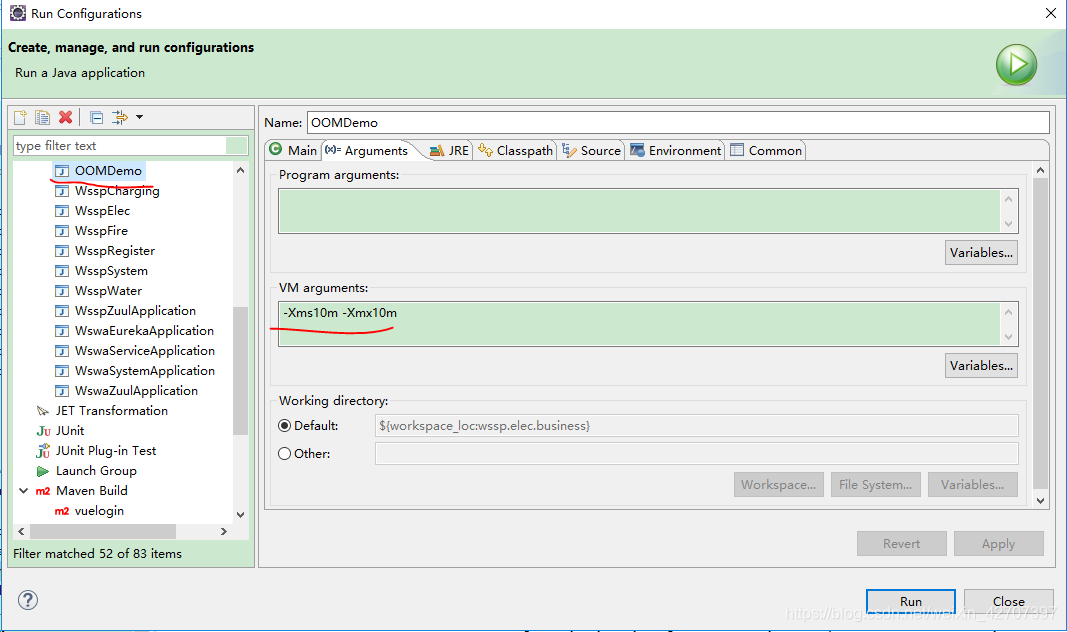
注意:运行时把jvm内存调小会更快看到效果
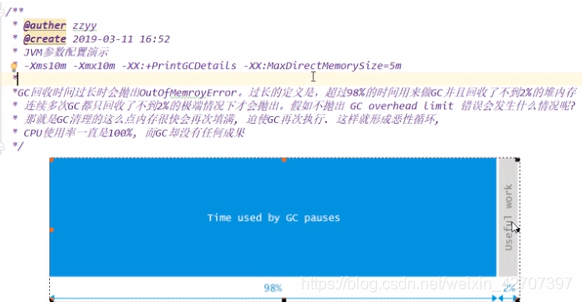
- OutOfMemoryError:GC overhead limit exceeded(超过GC开销限制)
private static void gcOverheadLimitDemo() {
ArrayList<Object> arrayList = new ArrayList<>();
int i = 0;
try {
while (true) {
arrayList.add(String.valueOf(i++));
}
} catch (Error e) {
System.err.println("xxxxxxxxxxxx");
e.printStackTrace();
}
}
/*
***********[GC (Allocation Failure) [PSYoungGen: 2004K->480K(2560K)] 2004K->1376K(9728K), 0.0011721 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 2528K->505K(2560K)] 3424K->3141K(9728K), 0.0021825 secs] [Times: user=0.00 sys=0.03, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 2553K->485K(2560K)] 5189K->5006K(9728K), 0.0021801 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 2533K->496K(2560K)] 7054K->6801K(9728K), 0.0023501 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[Full GC (Ergonomics) [PSYoungGen: 496K->0K(2560K)] [ParOldGen: 6305K->6686K(7168K)] 6801K->6686K(9728K), [Metaspace: 2693K->2693K(1056768K)], 0.0467610 secs] [Times: user=0.13 sys=0.00, real=0.05 secs]
[Full GC (Ergonomics) [PSYoungGen: 2048K->2046K(2560K)] [ParOldGen: 6686K->6269K(7168K)] 8734K->8315K(9728K), [Metaspace: 2693K->2693K(1056768K)], 0.0290151 secs] [Times: user=0.06 sys=0.00, real=0.03 secs]
[Full GC (Ergonomics) [PSYoungGen: 2048K->2047K(2560K)] [ParOldGen: 6269K->6269K(7168K)] 8317K->8317K(9728K), [Metaspace: 2693K->2693K(1056768K)], 0.0211767 secs] [Times: user=0.05 sys=0.00, real=0.02 secs]
[Full GC (Ergonomics) [PSYoungGen: 2047K->2047K(2560K)] [ParOldGen: 6271K->6271K(7168K)] 8318K->8318K(9728K), [Metaspace: 2693K->2693K(1056768K)], 0.0206695 secs] [Times: user=0.06 sys=0.00, real=0.02 secs]
[Full GC (Ergonomics) [PSYoungGen: 2047K->2047K(2560K)] [ParOldGen: 6272K->6272K(7168K)] 8320K->8320K(9728K), [Metaspace: 2693K->2693K(1056768K)], 0.0193628 secs] [Times: user=0.03 sys=0.00, real=0.02 secs]
[Full GC (Ergonomics) [PSYoungGen: 2047K->2047K(2560K)] [ParOldGen: 7044K->7044K(7168K)] 9092K->9092K(9728K), [Metaspace: 2693K->2693K(1056768K)], 0.0219041 secs] [Times: user=0.08 sys=0.00, real=0.02 secs]
[Full GC (Ergonomics) [PSYoungGen: 2047K->2047K(2560K)] [ParOldGen: 7046K->7046K(7168K)] 9094K->9094K(9728K), [Metaspace: 2693K->2693K(1056768K)], 0.0233974 secs] [Times: user=0.05 sys=0.00, real=0.02 secs]
[Full GC (Ergonomics) [PSYoungGen: 2047K->2047K(2560K)] [ParOldGen: 7048K->7048K(7168K)] 9096K->9096K(9728K), [Metaspace: 2693K->2693K(1056768K)], 0.0236220 secs] [Times: user=0.06 sys=0.01, real=0.02 secs]
xxxxxxxxxxxx
java.lang.OutOfMemoryError: GC overhead limit exceeded
[Full GC (Ergonomics) [PSYoungGen: 2048K->2047K(2560K)] [ParOldGen: 7051K->7050K(7168K)] 9099K->9098K(9728K), [Metaspace: 2717K->2717K(1056768K)], 0.0259748 secs] [Times: user=0.06 sys=0.00, real=0.03 secs]
at java.lang.Integer.toString(Integer.java:401)
at java.lang.String.valueOf(String.java:3099)
at com.ws.wssp.elec.business.OOMDemo.gcOverheadLimitDemo(OOMDemo.java:19)
at com.ws.wssp.elec.business.OOMDemo.main(OOMDemo.java:11)
[Full GC (Ergonomics) [PSYoungGen: 2047K->0K(2560K)] [ParOldGen: 7055K->838K(7168K)] 9103K->838K(9728K), [Metaspace: 2717K->2717K(1056768K)], 0.0041612 secs] [Times: user=0.05 sys=0.00, real=0.00 secs]
Heap
PSYoungGen total 2560K, used 41K [0x00000000ffd00000, 0x0000000100000000, 0x0000000100000000)
eden space 2048K, 2% used [0x00000000ffd00000,0x00000000ffd0a418,0x00000000fff00000)
from space 512K, 0% used [0x00000000fff80000,0x00000000fff80000,0x0000000100000000)
to space 512K, 0% used [0x00000000fff00000,0x00000000fff00000,0x00000000fff80000)
ParOldGen total 7168K, used 838K [0x00000000ff600000, 0x00000000ffd00000, 0x00000000ffd00000)
object space 7168K, 11% used [0x00000000ff600000,0x00000000ff6d1a38,0x00000000ffd00000)
Metaspace used 2723K, capacity 4486K, committed 4864K, reserved 1056768K
class space used 293K, capacity 386K, committed 512K, reserved 1048576K
*/
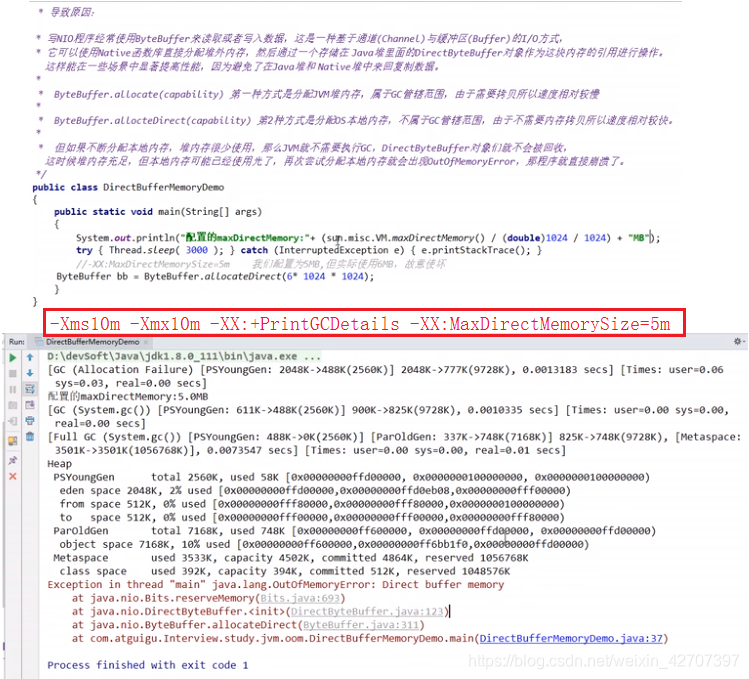
注意:运行时设置jvm参数(-Xms10m -Xmx10m -XX:+PrintGCDetails -XX:MaxDirectMemorySize=5m)可更快看到效果。
-XX:MaxDirectMemorySize可以设置java堆外内存的峰值,此参数的含义是当Direct ByteBuffer分配的堆外内存到达指定大小后,即触发Full GC。注意该值是有上限的,默认是64M,最大为sun.misc.VM.maxDirectMemory(),在程序中中可以获得-XX:MaxDirectMemorySize的设置的值。
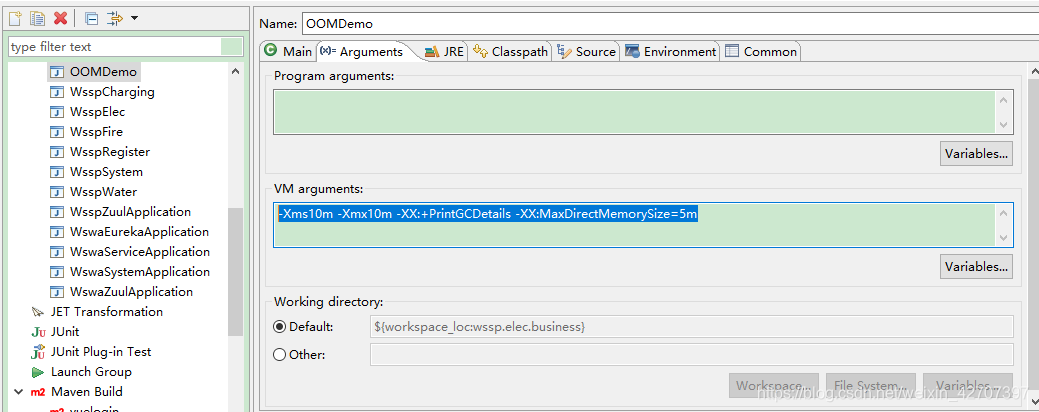
- OutOfMemoryError:Direct buffer memory
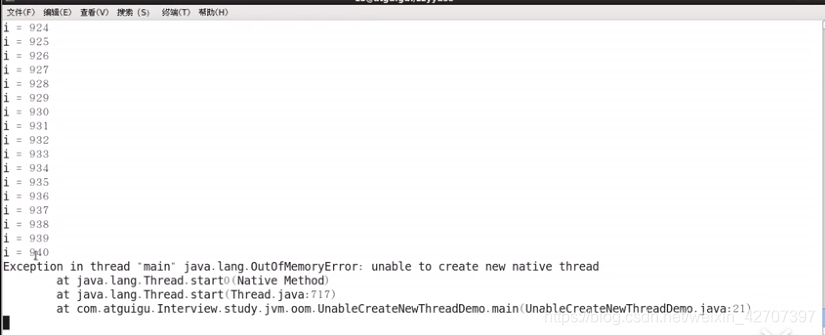
- OutOfMemoryError:Unable create new native thread(linux非root用户最大创建的理论线程数为1024,但真实结果小于1024。root用户可创建的线程数不受限制。无论是root或者是普通用户都可调整线程数上限)。
在linux环境下测试此OOM:- 在linux下切换到非root用户,新建java文件,粘贴上图代码
- 编译java程序:javac -d . xxx.java。执行成功后此java的.class文件就在同级目录下的包名文件夹里
- 执行java程序:java 包名.xxx
- OutOfMemoryError:Metaspace
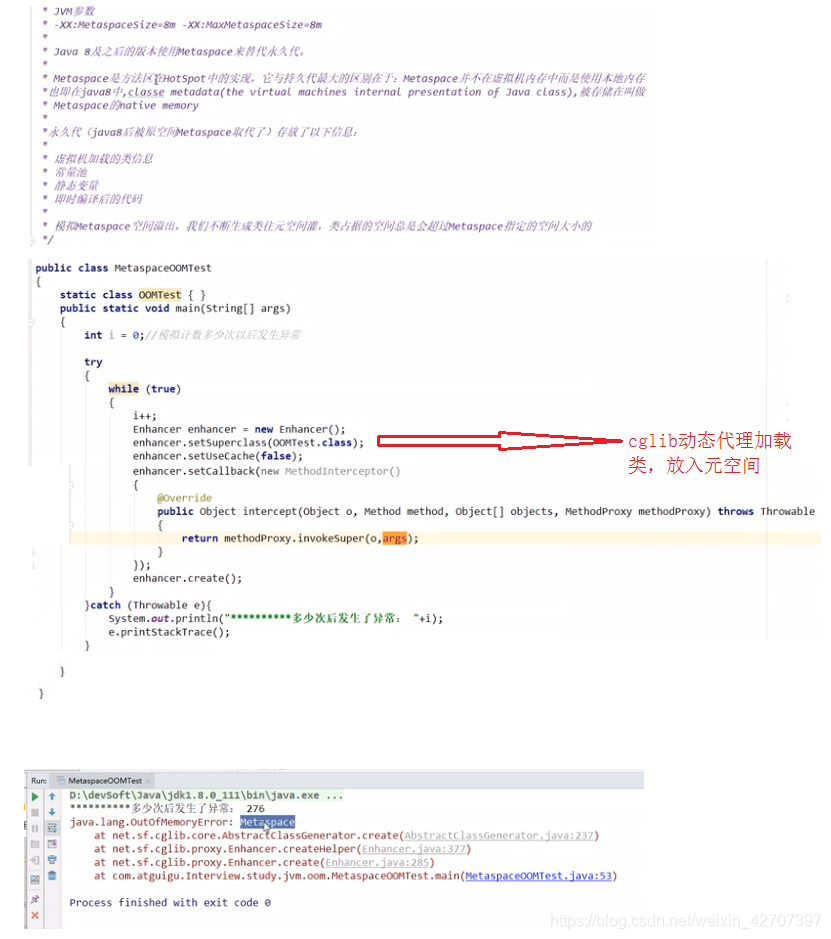
12、生产环境服务器问题排查相关
- 生产环境的服务器变慢,诊断思路和性能评估谈谈?
答:linux常用命令总结的第三条linux调优相关命令 - 服务器cpu使用率过高,怎样定位排查?
-
使用top 查看使用cpu最高的进程是不是java程序
-
使用命令
jps -l或者ps -ef|grep java|grep -v grep查看java进程号,并记录
-
定位到具体线程或代码,使用命令
ps -mp 进程号 -o THREAD,tid,time找到最耗cpu的线程号,其中-m指显示所有的线程、-p pid进程使用cpu的时间、-o 该参数后是用户自定义格式
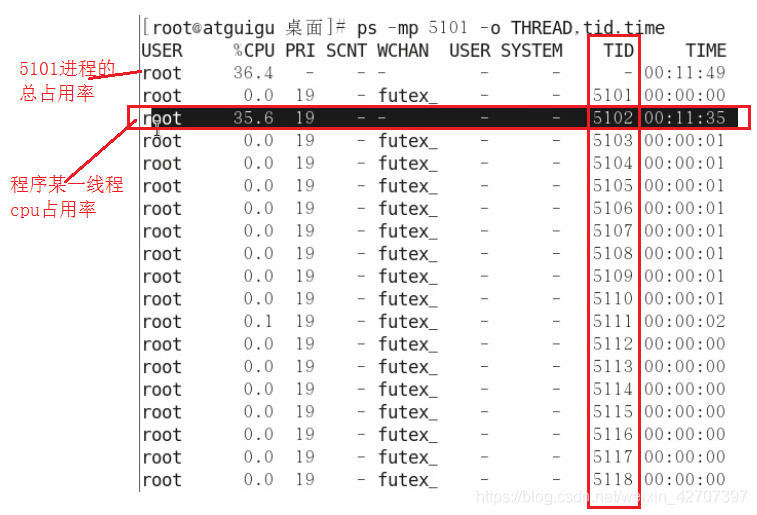
-
将第三步高占用的线程号转为十六进制(英文字母小写)比如线程号5102转为十六进制为13ee,再使用命令(打印出进程号为5101,线程号为13ee的前六十行运行轨迹):
jstack 5101(进程号) | grep 13ee(十六进制线程号) -A60,可以看出是第javaDemo02的十行占用最高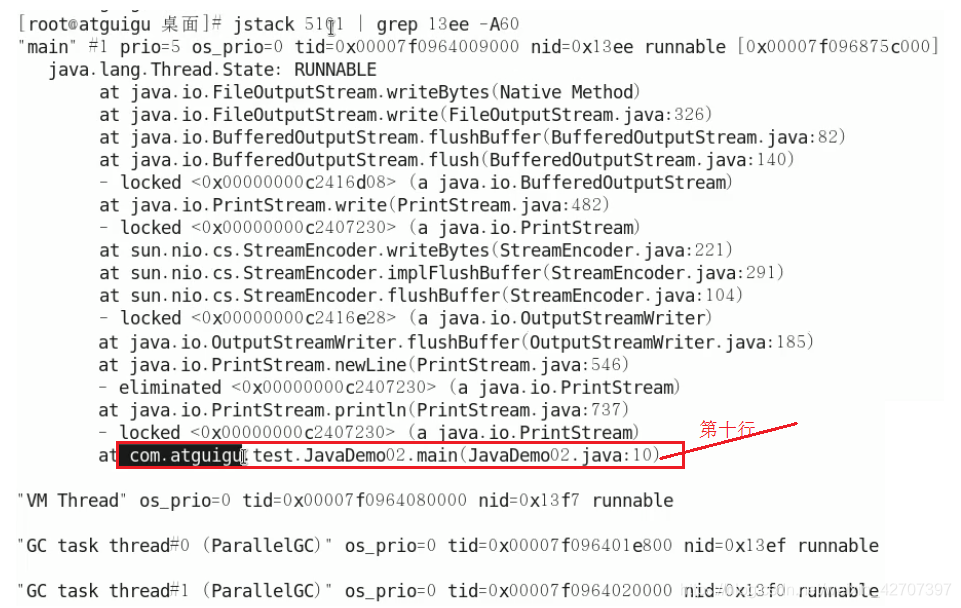
-
二、第二阶段
2019-Java-阳哥面试指导-java面试-周阳-尚硅谷-基础
1、方法的参数传递机制
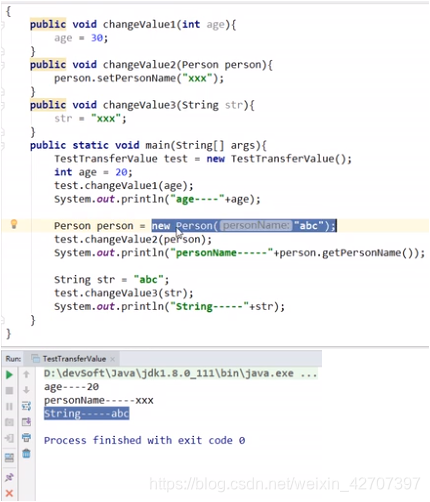
总结:
- 基本类型传的是复制,无论其他方法如何改变其值,都不影响本方法的值
- 引用类型会被其他方法改变
- 字符串String类型虽然也是引用类型,但其他方法不会改变其值,因为它比较特殊,有个字符串常量池,当修改一个字符串值的时候并不会直接改变其值,而是在字符串常量池新建此字符串
2、equals和==
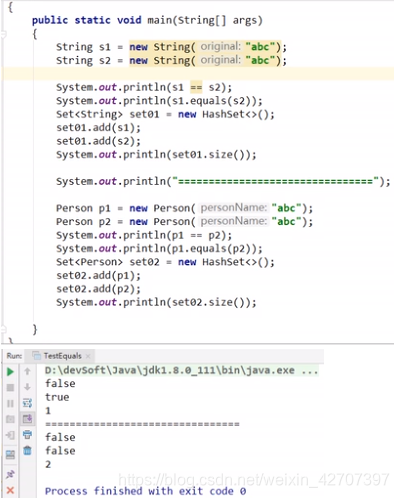
总结:
-
==比较的是栈中的引用地址,都是唯一的,所以一般引用类型的
==判断都为false,基本类型如int等可使用== -
引用类型String的equals()被重写过,是根据字符串中的每个字符(char)来判断,所以为true
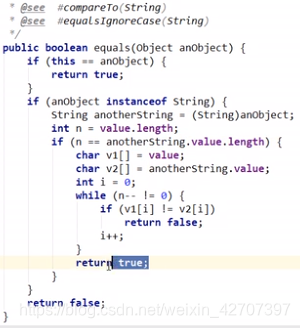
-
其他引用类型没有重写equals()时使用的是Object的equals(),Object的equals()是为了判断调用它的对象和传入的对象的引用是否相等。也就是说,默认的equals()进行的是引用比较。如果两个引用是相同的,equals()函数返回true;否则,返回false

-
hashcode和equals():重写equals时一般都会重写hashcode()方法。

-
HashSet<k>底层使用了HashMap<k,v>,

其中Set的add(k)调用了Map的put(k,v),只占用了key,所以HashSet不能为空且不能重复
调用HashSet的add(k)时会根据hashCode(k)来判断是否重复,上题中,String类型的hashCode是重写过的,s1、s2的hashcode值相同,所以s2覆盖了s1,set01.size()为1;
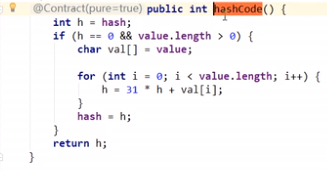
自己创建的类Person没有重写hashCode,add(k)时是两个不同的值,所以set02.size()为2
3、类方法、属性的加载顺序
类加载的三个阶段

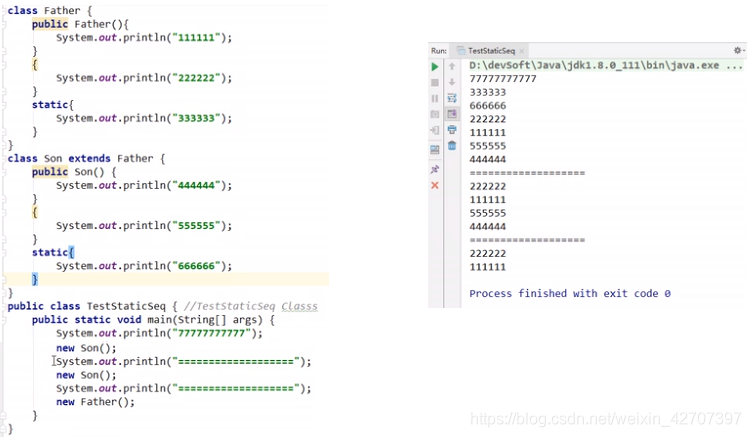
总结: 就上题而言,
- 加载入口类(含main()的类)中的静态属性(注意:静态属性只加载一次,下同)
- 加载入口类的普通属性
- 进入入口类的入口方法(main()方法),第一行打印
7 - 当
new Son();的时候加载其父类Father的静态属性,打印3 - 加载Son的静态属性,打印
6 - 加载父类Father的普通属性,打印
2 - 加载父类Father的构造方法,打印
1 - 加载Son的普通属性,打印
5 - 加载Son的构造方法,打印
4 - 分隔符========
- 再次
new Son();不再加载已经加载过的静态属性,所以直接加载父类Father的普通属性,打印2;加载父类Father的构造方法,打印1; 加载Son的普通属性,打印5; 加载Son的构造方法,打印4; - 分隔符========
- 当
new Father();加载父类Father的普通属性,打印2;加载父类Father的构造方法,打印1;
4、数据库相关
- 存储引擎。如何查看某库的某表使用的是什么存储引擎?
show table status from 'your_db_name' where name='your_table_name';

- 上面的InnoDB底层使用什么实现的?


-
索引。数据库索引现在使用的是B+树,其中B是指balance(平衡)而不是binary(二叉)

-
索引演变史
(1)全部遍历:不管查找几个,时间复杂度都很高O(n)
(2)hash:时间复杂度O(1),但只适合查找单个,不能查找范围
(3)二叉树:比根节点小的放左边,比根节点大的放右边,时间复杂度为O(log n),其中log n相当于数学中的log 2n。但是一旦出现极端情况,比如每插入的新节点都比上一个节点大,就会出现节点都在右方的单链表,这是时间复杂度为O(n)

(4)平衡二叉树:大于节点放左边,小于节点放右边,如果某个节点连续大或连续小,就会把中间节点提为根节点,就不会出现单链表的情况,时间复杂度稳定为O(log n),如下图

- 但是,当数据量很大很大的时候,树的高度依旧很高,查找依旧很费时,这时,我们就引入了B树,B树比平衡二叉树减少了一次IO操作
(5)B树(balance tree 多路平衡查找树):一个节点位置可有多个数据节点,转“高瘦”为“矮胖”,如下图

- 注意:此时数据和键值都在节点上存储着

(6)B+树(加强版B树)。与B树相比,数据和键值分开存储,节点上只存键值,好处是查询范围时只用查找头和尾,中间的数据直接在叶子链表上取即可,而且数据库索引一般在磁盘上,数据量过大无法一次装入内存,B+树允许每次加载一个节点,再一步一步往下找,分批读取数据



- 上面的动图演示链接:树的动态在线演示
- 其他:coder sheep羊哥的关于mysql总结
- mysql面试题:mysql面试题
- MySQL中有四种索引类型,可以简单说说吗?
FULLTEXT :即为全文索引,目前只有MyISAM引擎支持。其可以在CREATE TABLE ,ALTER TABLE ,CREATE INDEX 使用,不过目前只有 CHAR、VARCHAR ,TEXT 列上可以创建全文索引。
HASH :由于HASH的唯一(几乎100%的唯一)及类似键值对的形式,很适合作为索引。HASH索引可以一次定位,不需要像树形索引那样逐层查找,因此具有极高的效率。但是,这种高效是有条件的,即只在“=”和“in”条件下高效,对于范围查询、排序及组合索引仍然效率不高。
BTREE :BTREE索引就是一种将索引值按一定的算法,存入一个树形的数据结构中(二叉树),每次查询都是从树的入口root开始,依次遍历node,获取leaf。这是MySQL里默认和最常用的索引类型。
RTREE :RTREE在MySQL很少使用,仅支持geometry数据类型,支持该类型的存储引擎只有MyISAM、BDb、InnoDb、NDb、Archive几种。相对于BTREE,RTREE的优势在于范围查找。
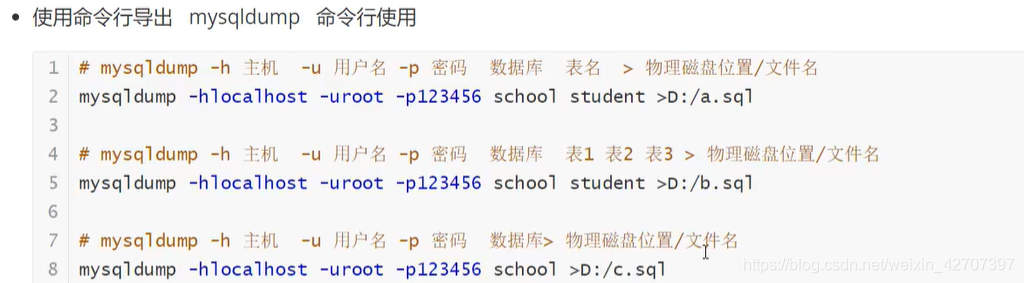
- 数据库备份的方法
1、直接拷贝 data 文件夹 E:\ProgramData\MySQL\MySQL Server 5.7\Data
2、在可视化工具中手动导出(navicat等)
3、使用命令行 mysqldump 导出
三、第三阶段
1.下列代码输出什么?
public class TestDemo implements GrandParents, Parent {
public static void main(String[] args) {
String java = new StringBuffer("ja").append("va").toString();
System.out.println(java.intern() == java);
String redis = new StringBuffer("re").append("dis").toString();
System.out.println(redis.intern() == redis);
}
结果:false
true
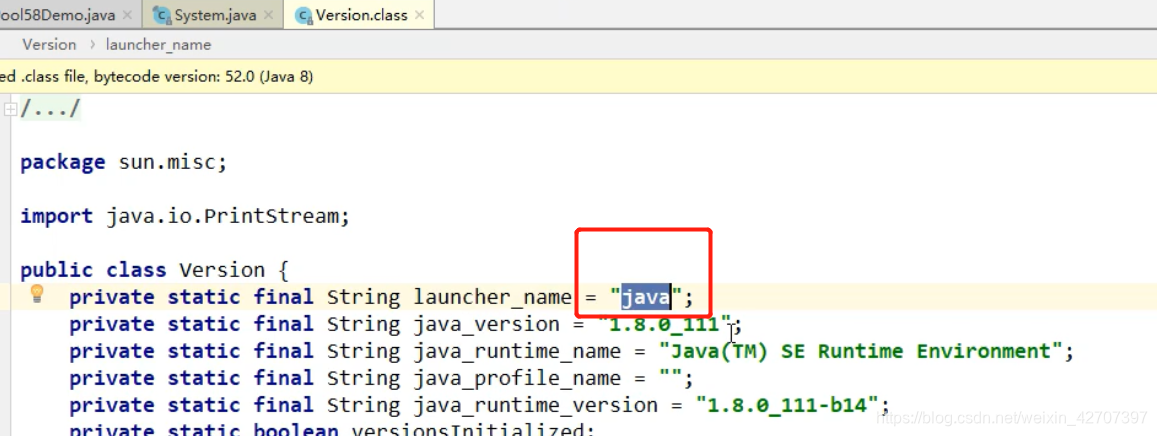
分析:

当调用System这个类的时候,会初始化一个静态方法sun.misc.Version.init(),它包含了一个“java”
2、算法题,返回数组两数和下标
比如:nums=[1,2,5,7], targer=9, num[1]+num[3]=2+7=9,所以返回1,3
解法1(暴力解法):
package javaDemo;
public class TwoNumSum {
public static void main(String[] args) {
int[] nums = new int[] { 1, 2, 5, 7 };
String numSum = numSum(nums, 9);
System.out.println(numSum);
}
private static String numSum(int[] nums, int targer) {
for (int i = 0; i < nums.length; i++) {
for (int j = 0; j < nums.length; j++) {
if (targer - nums[i] == nums[j] && i != j) {
System.out.println(nums[i] + "," + nums[j]);
return i + "," + j;
}
}
}
return null;
}
}
解法二(优化解法,巧用HashMap):
private static String numSumBetter(int[] nums, int targer) {
Map<Integer, Integer> map = new HashMap<Integer, Integer>();
for (int i = 0; i < nums.length; i++) {
if (map.containsKey(targer - nums[i])) {
return map.get(targer - nums[i]).toString() + "," + String.valueOf(i);
} else {
// System.out.println(nums[i]);
map.put(nums[i], i);
}
}
return null;
}
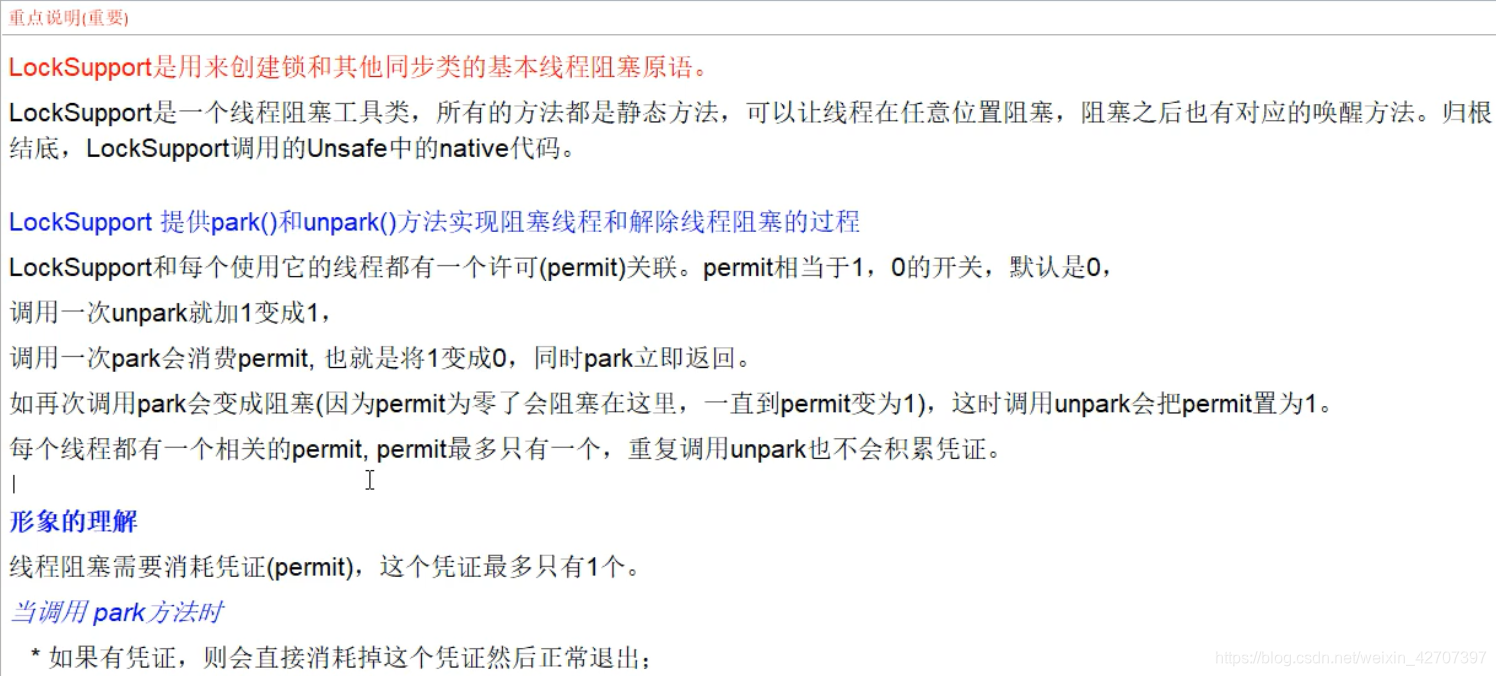
3、LockSupport
是什么?
通过park()和unpark(thread)方法来实现阻塞和唤醒线程的操作。在之前的synchronized的wait,notify,Lock的await,signal中,先notify、signal后再遇到wait,
是进不去方法里的,只能等待,而在LockSupport中,先unpark只是把许可证(默认为0)设置为1(最多也是1),park时只要判断许可为1时就能进入


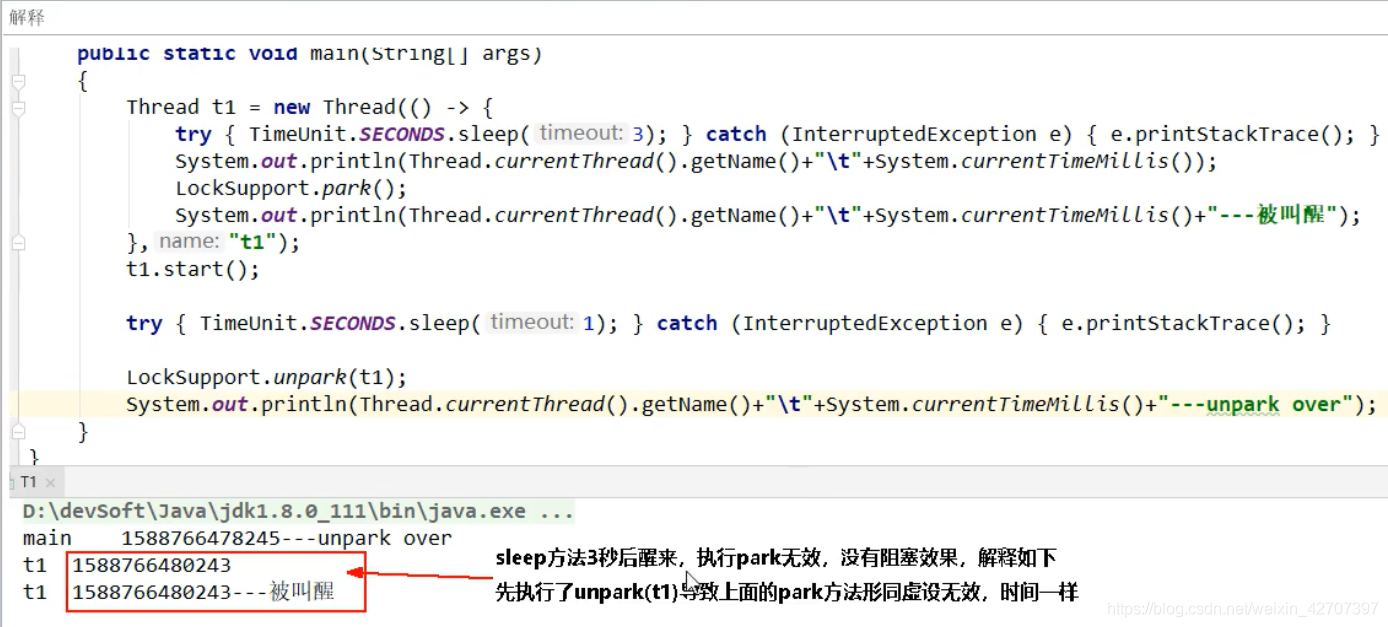
使用案例
案例一,在park之后使用unpark

案例二,在park之前就unpark
4、AQS(AbstractQueuedSynchronizer:抽象的队列同步器)
-
和AQS相关的锁:ReentrantLock、CountDownLatch、ReentrantReadWriteLock、Semaphore
-
为什么相关?拿ReentrantLock举例,ReentrantLock的lock()方法其实是调用了ReentrantLock的内部类Sync的sync.lock(),而Sync实现了接口AQS。
ReentrantLock的unlock()调用了Sync的sync.release(1);
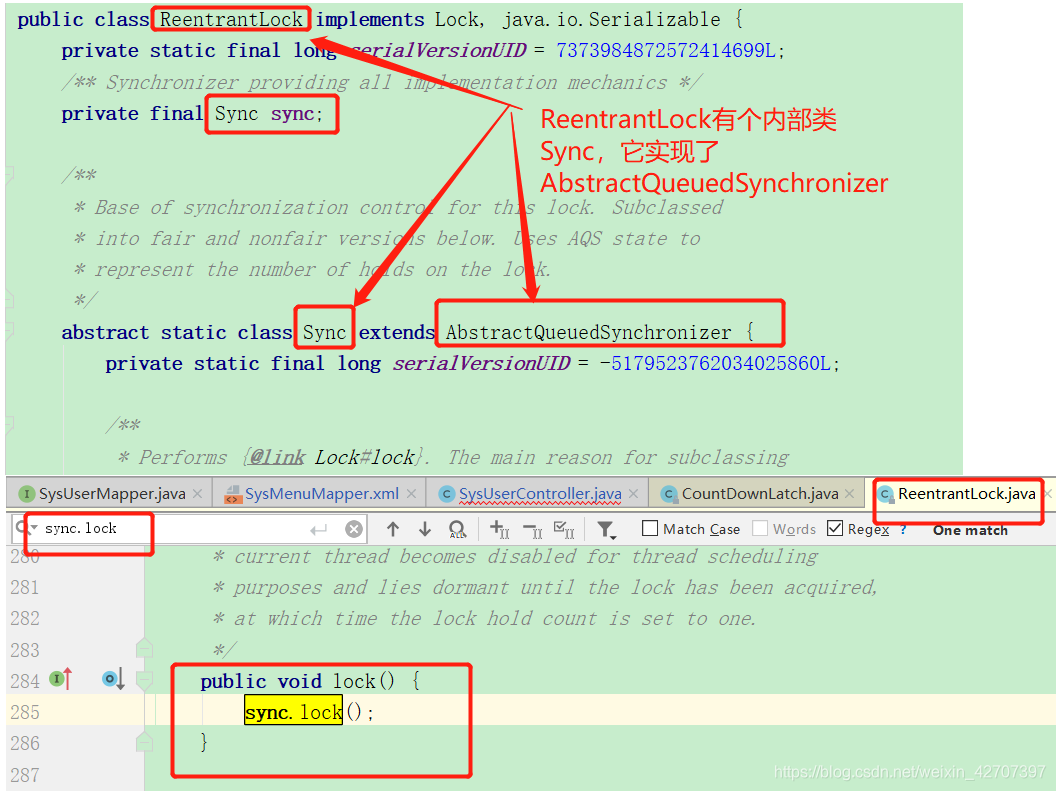
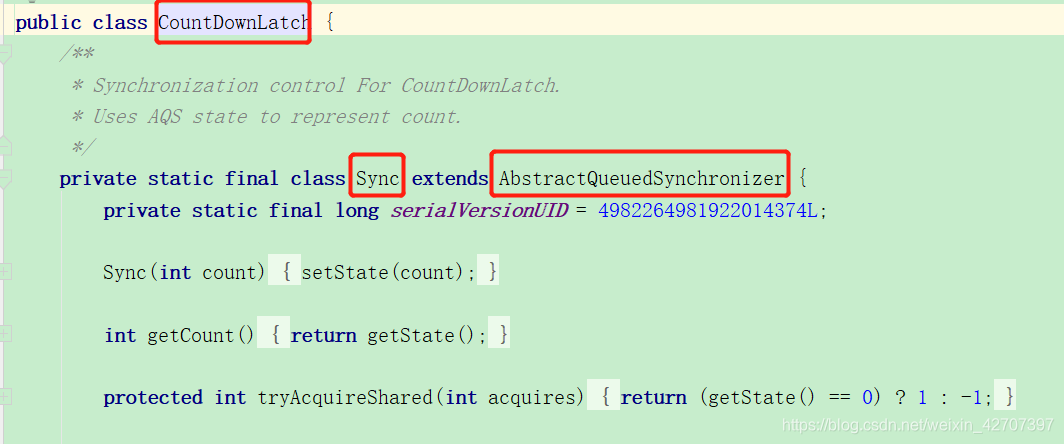
其他锁亦是如此:
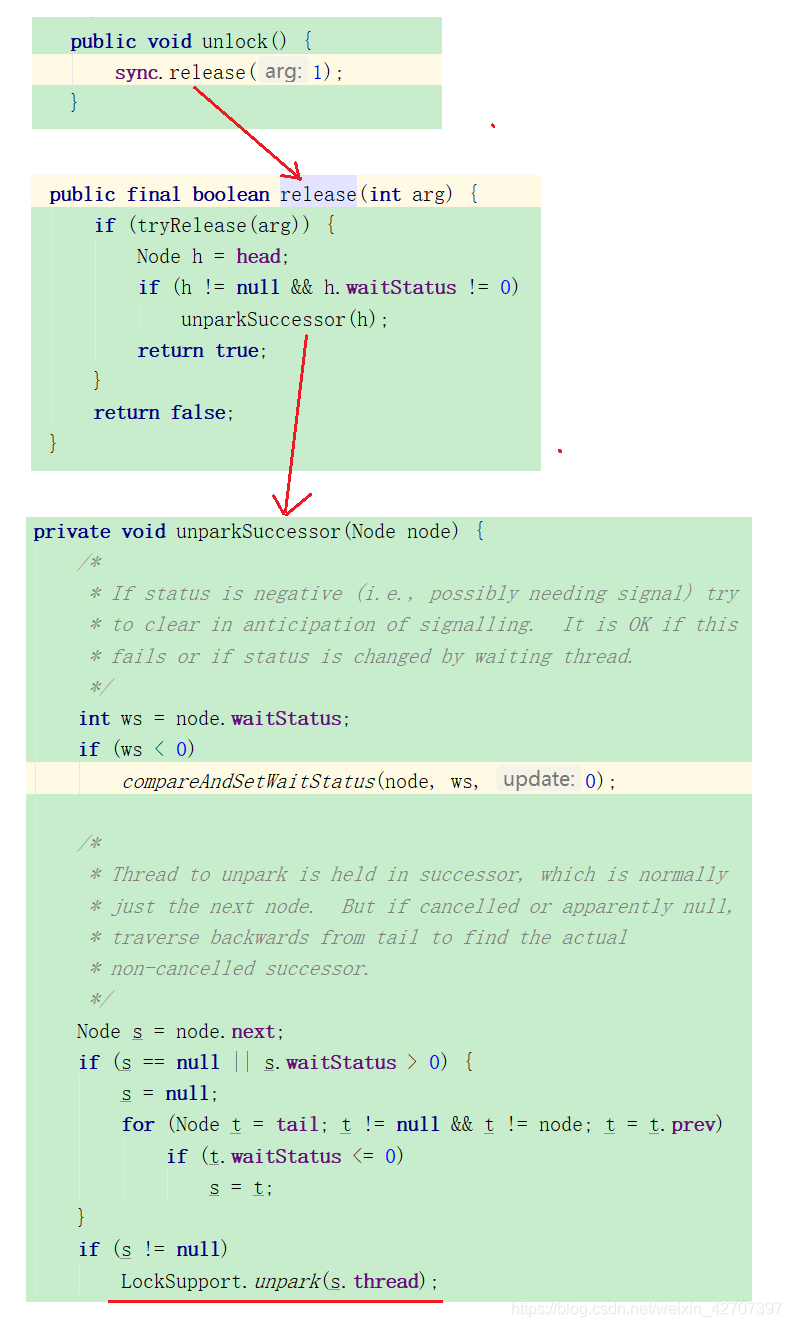
而unlock()调用的也是Sync的release()
-
了解AQS底层几个重要属性
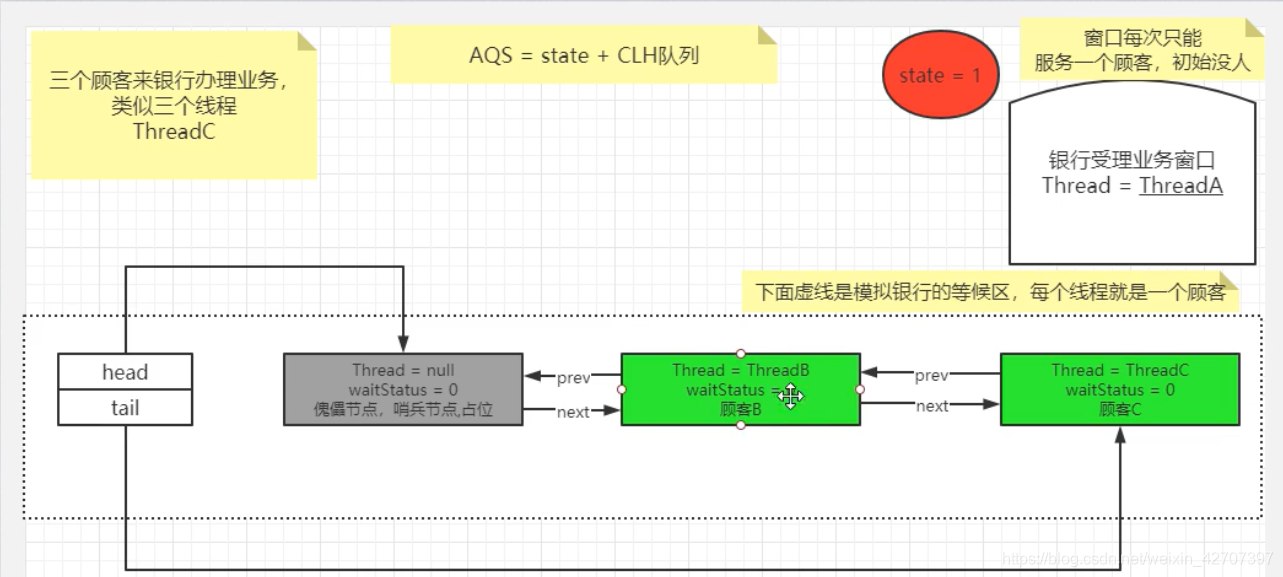
AQS底层有几个重要的属性volatile Node prev;前指针节点volatile Node next;下一个指针节点volatile Thread thread;线程其中Node这个内部类也包含了几个重要属性private transient volatile Node head;头节点private transient volatile Node tail;尾节点private volatile int state;状态值 -
sync的lock()深度解析
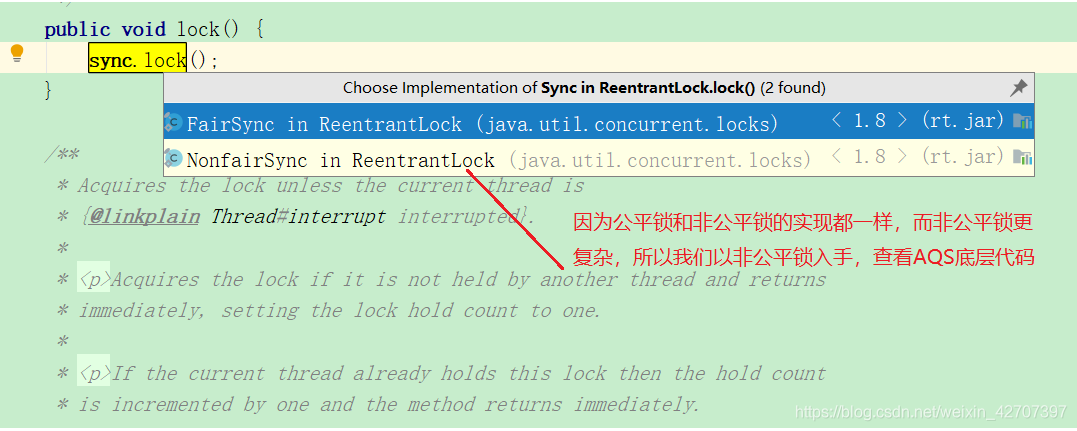
占到锁的线程就执行,没占到的线程进入CLH队列等待
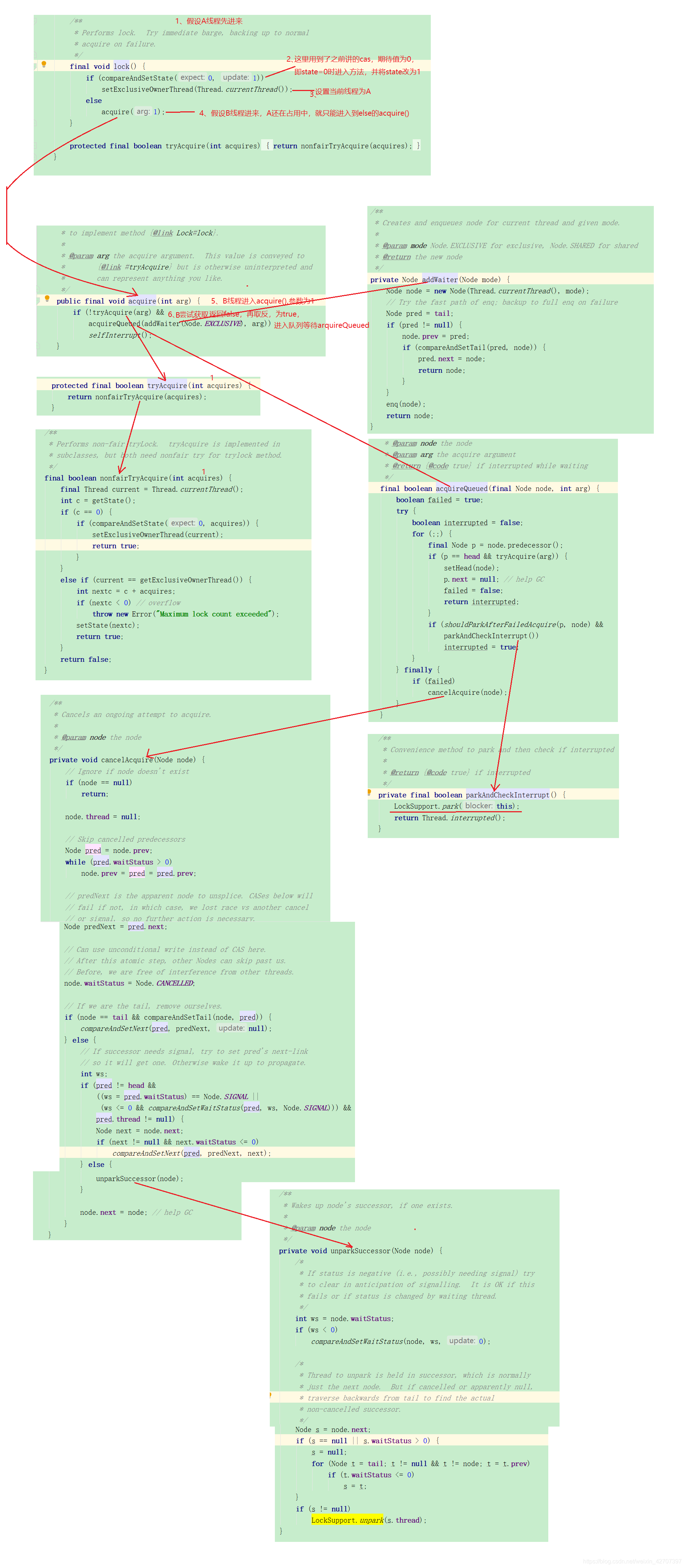
最后一步的unpark()是指正在执行的A线程执行到一半时突然取消或明显为null,不想执行了,就会解锁
而进入队列等待的时候就用到了上面AQS的几个重要属性,模型如下:
-
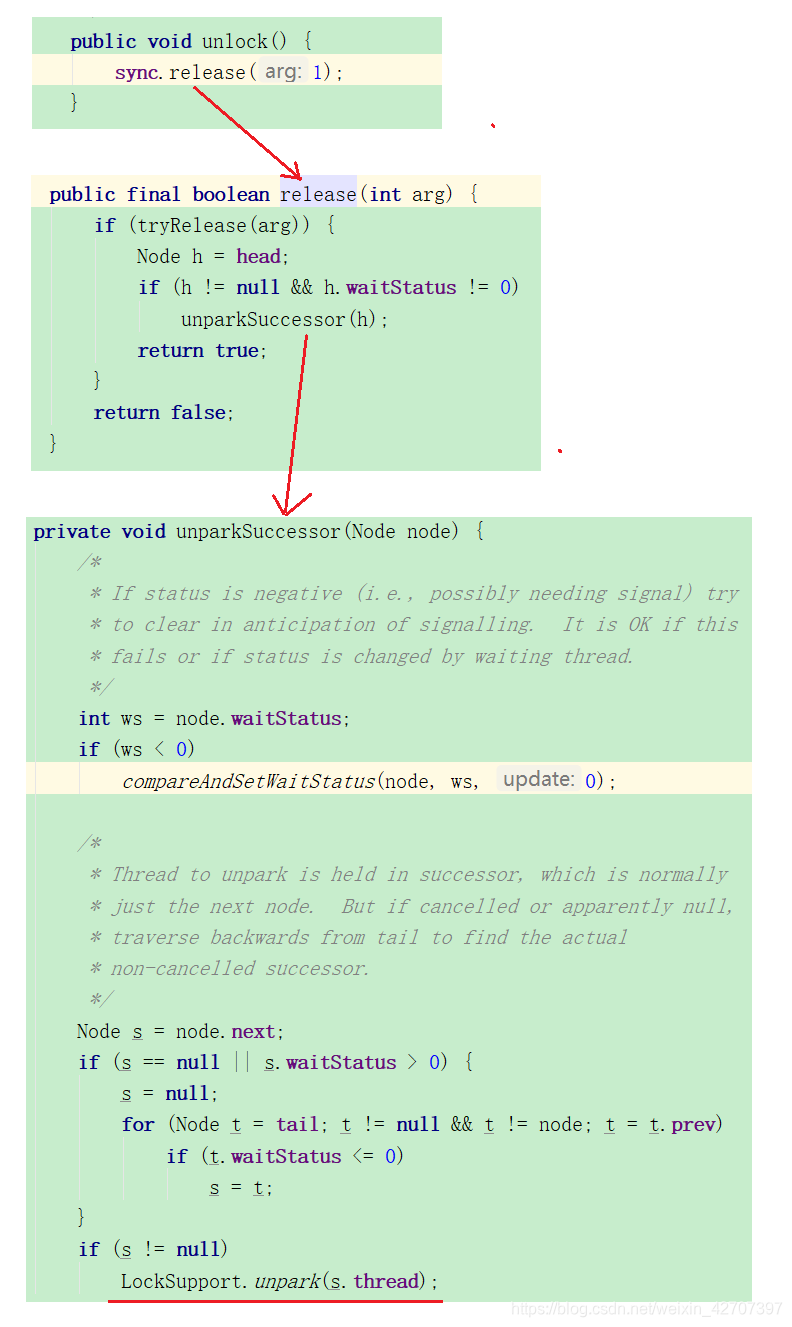
当调用unlock()时候,底层实际是调用的Sync的release(),而底层还是LockSupport的unpark()
-
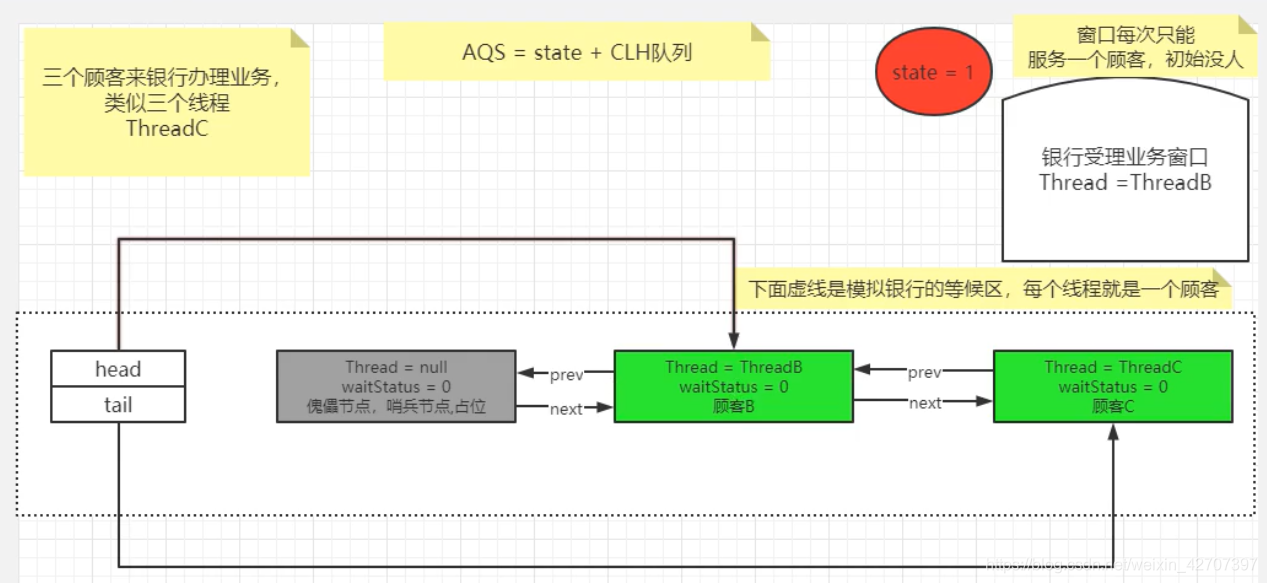
A线程执行完毕调用unlock()解锁,B线程开始去执行,B在等待队列里的占位成为新的哨兵节点,原哨兵节点制空null被GC回收,C线程成为队列第一等待者,继续等待,演变图如下
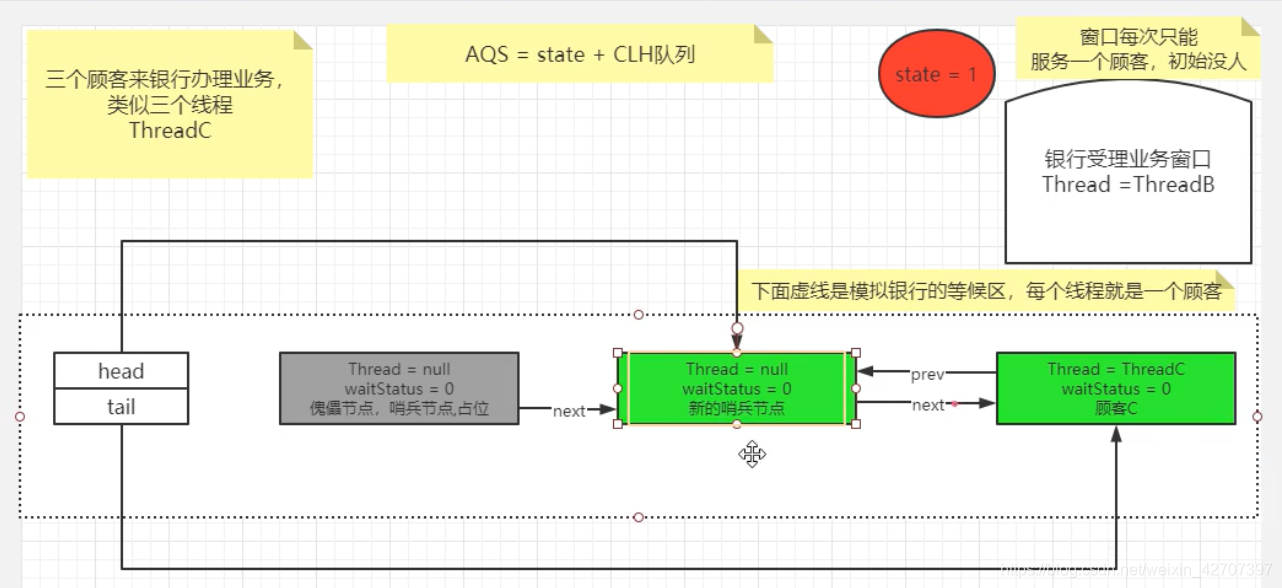
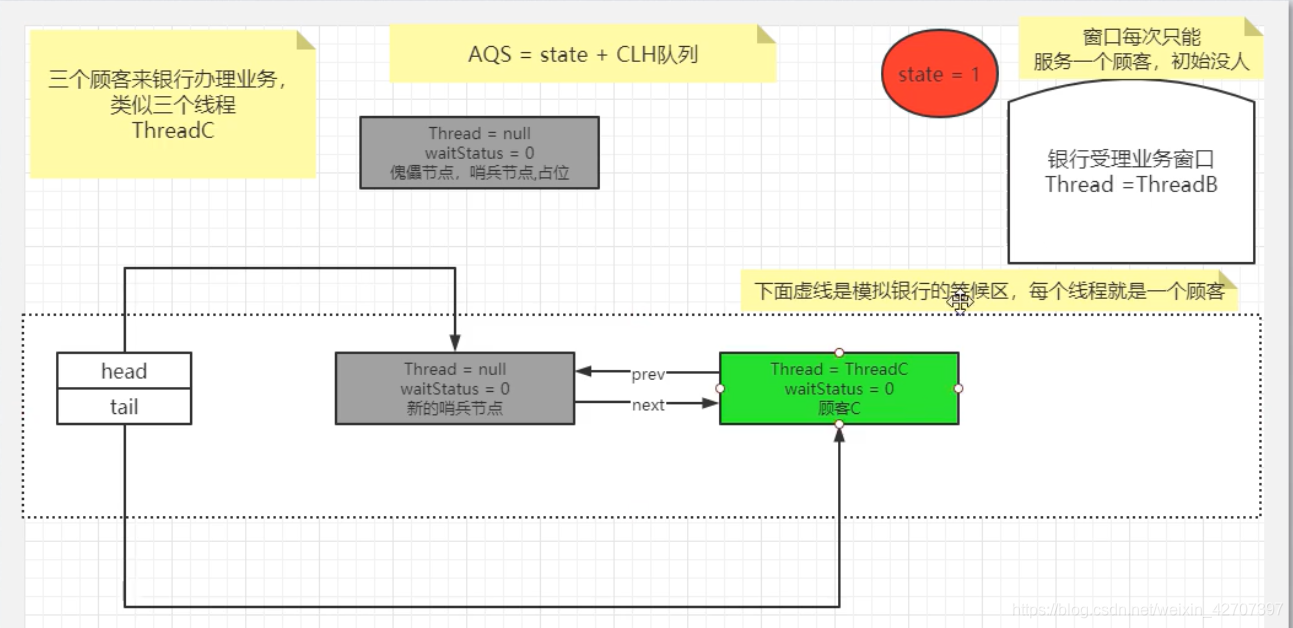
5、Spring之AOP
- aop常用注解

- aop调用顺序
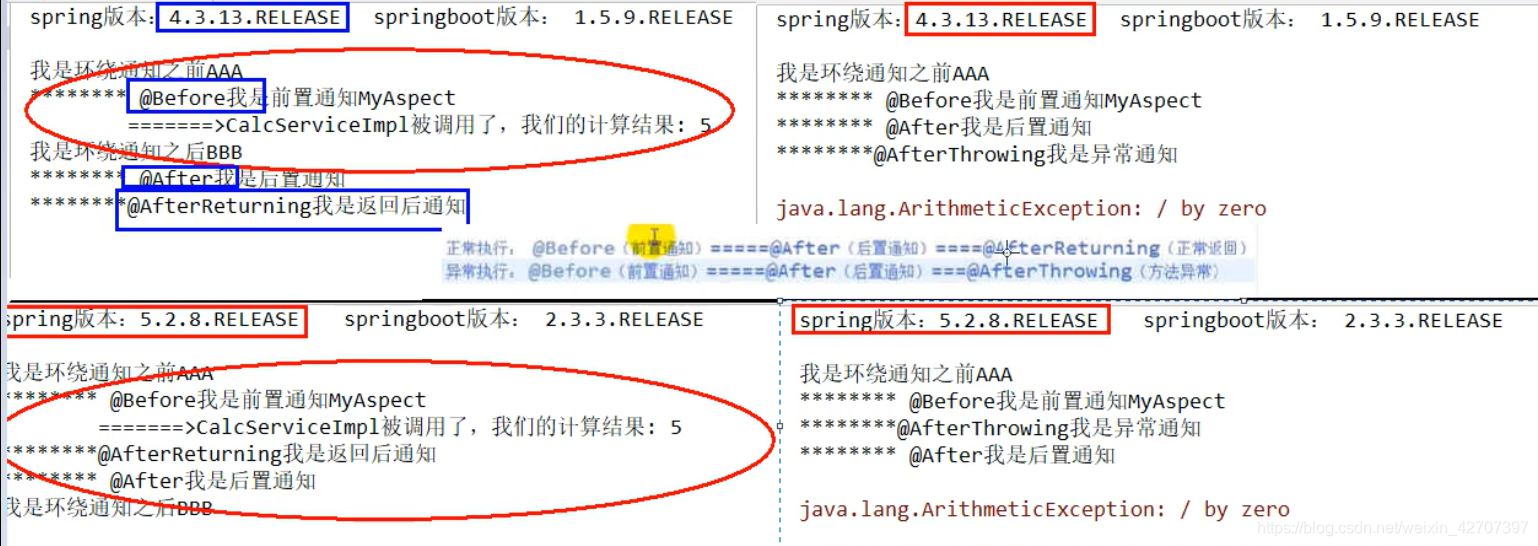
首先了解下springboot各版本底层使用的是spring的哪个版本:
springboot1对应spring4
springboot2对应spring5
所以,aop上面的五个注解执行顺序是不同的
测试代码如下:(execution():这里是切入点表达式,对哪个类里面的哪个方法增强)
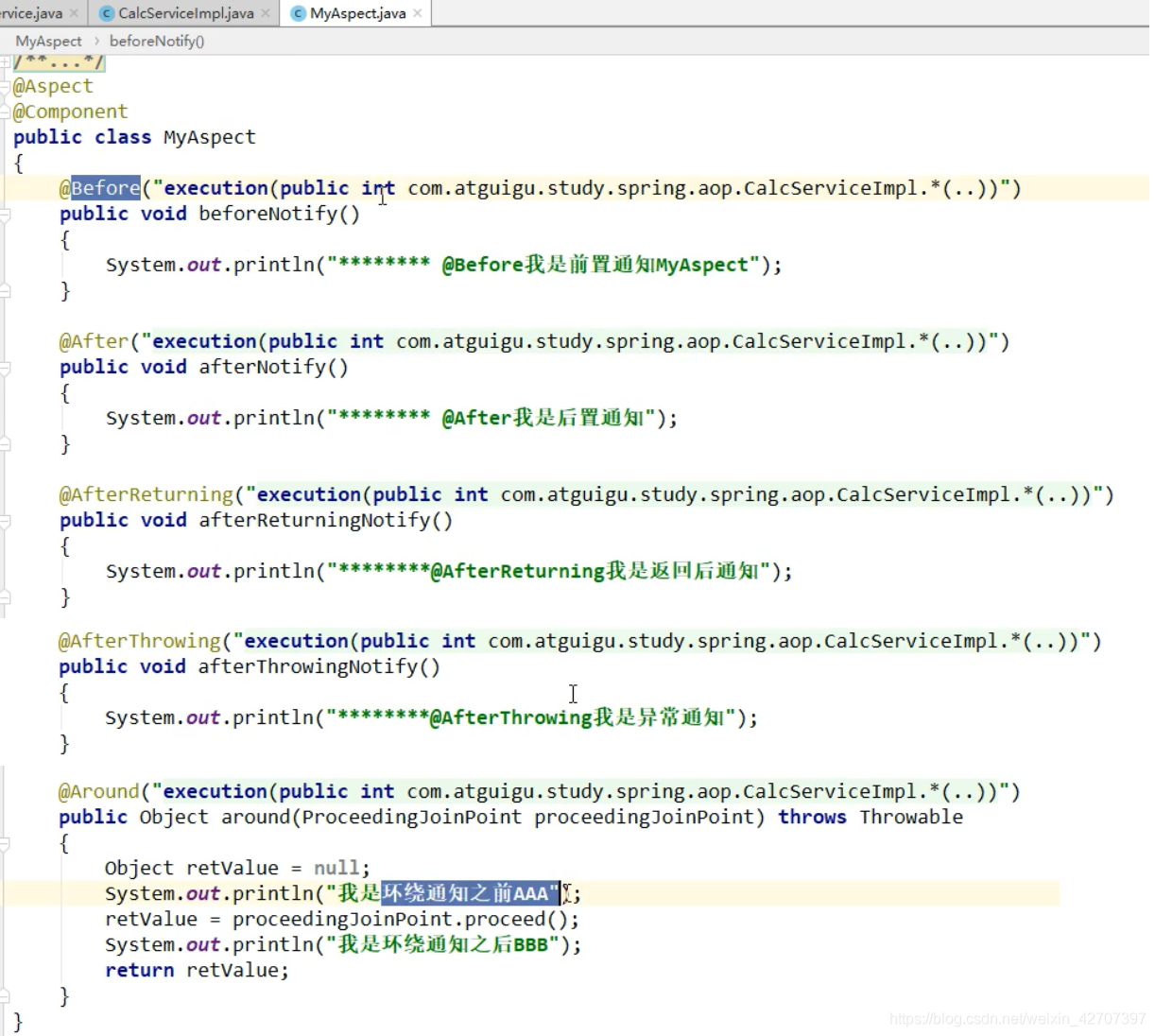
springboot1无异常结果

springboot1有异常情况下
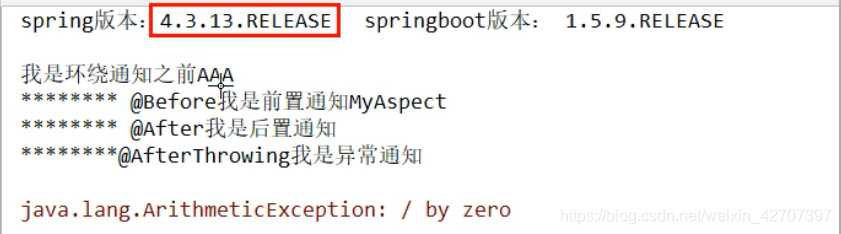
springboot2无异常结果
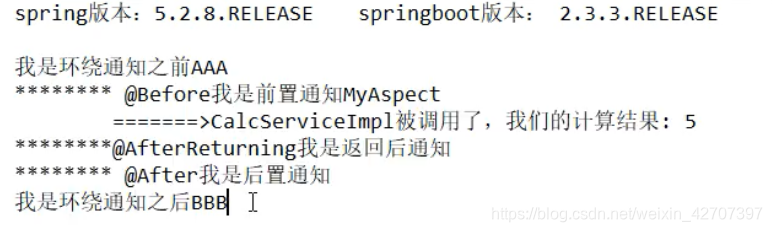
springboot2有异常情况下
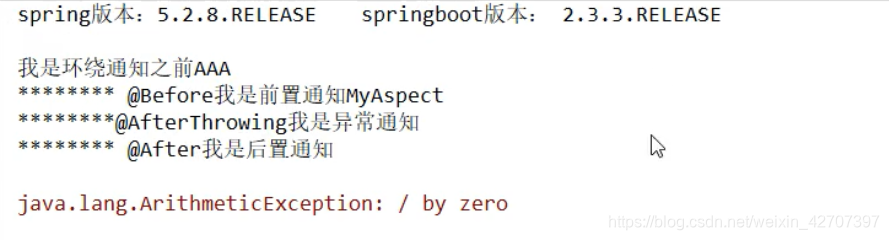
顺序总结
5、Redis相关
- Redis之分布式锁
补充几个相关知识的博客:
- 我的另一篇reids使用博客也有几道面试题,可以参考:redis学习笔记
- zookeeper实现分布式锁:zookeeper实现分布式锁
- 关于redis在springboot项目的使用说明Redis的三个客户端框架比较:Jedis,Redisson,Lettuce 、 Redission使用方式总结 、 springboot 集成redission 以及分布式锁的使用
Jedis:是Redis的Java实现客户端,提供了比较全面的Redis命令的支持,
Redisson:实现了分布式和可扩展的Java数据结构。公司大佬一般自己写,不用这个,中小企业这个够用了
Lettuce:高级Redis客户端,用于线程安全同步,异步和响应使用,支持集群,Sentinel,管道和编码器。
为什么会出现分布式锁:
- JVM层面的锁,也就是单机版的锁,单服务保证线程安全;
- 分布式微服务架构,不同的JVM,单机版的锁已经没用了,服务拆分之后为了避免冲突和数据故障而加入的一种锁------分布式锁;
分布式锁实现的方式:
- mysql
- zookeeper:zookeeper实现分布式锁
- redis:①redisson的lock、unlock方法实现 ②自己手写
- Redis缓存过期淘汰策略
- redis设置内存
如果在redis.conf里这一行

被注释,则说明没有设置最大内存

在生产中,一般设置为最大物理内存的3/4
设置方式有两种,一种是上面的配置文件第二种是直接用命令

- 超过内存最大值时即内存满了,触发Redis缓存过期淘汰策略,过期淘汰策略一共有八种

如果不配置,默认使用的是

写操作会返回error
- redis过期键的删除策略

三种:

第三种:定期删除

- lru算法(least recently used)
控制时间复杂度为O(1)
算法核心:hash+链表
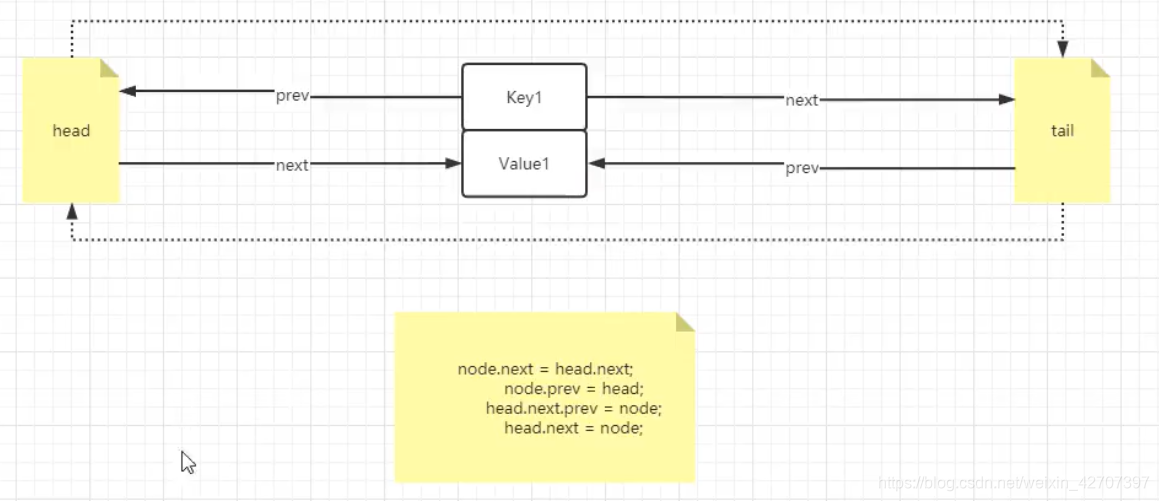
手写LRU:
package javaDemo;
import java.util.HashMap;
import java.util.Map;
public class LcuDemo {
// map负责查找,构建一个虚拟的双向列表,它里面安装的就是一个Node节点,作为数据载体
// 1、构造一个Node节点,作为数据载体
class Node<K, V> {
K key;
V vaule;
Node<K, V> prev;
Node<K, V> next;
public Node() {
this.prev = this.next = null;
}
public Node(K key, V vaule) {
this.key = key;
this.vaule = vaule;
this.prev = this.next = null;
}
}
// 构造一个虚拟双向链表,里面安装的就是一个一个Node节点
class DoubleLinkedList<K, V> {
Node<K, V> head;
Node<K, V> tail;
public DoubleLinkedList() {
head = new Node<K, V>();
tail = new Node<K, V>();
head.next = tail;
tail.prev = head;
}
public void addHead(Node<K, V> node) {
node.next = head.next;
node.prev = head;
head.next.prev = node;
head.next = node;
}
public void removeNode(Node<K, V> node) {
node.next.prev = node.prev;
node.prev.next = node.next;
node.prev = null;
node.next = null;
}
public Node getLast() {
return tail.prev;
}
}
private int cacheSize;
Map<Integer, Node<Integer, Integer>> map;
DoubleLinkedList<Integer, Integer> doubleLinkedList;
public LcuDemo(int cacheSize) {
this.cacheSize = cacheSize;
map = new HashMap<>();
doubleLinkedList = new DoubleLinkedList<>();
}
public int get(int key) {
if (!map.containsKey(key)) {
return -1;
}
Node<Integer, Integer> node = map.get(key);
doubleLinkedList.removeNode(node);
doubleLinkedList.addHead(node);
return node.vaule;
}
public void put(int key, int value) {
if (map.containsKey(key)) {
Node<Integer, Integer> node = map.get(key);
node.vaule = value;
map.put(key, node);
doubleLinkedList.removeNode(node);
doubleLinkedList.addHead(node);
} else {
if (map.size() == cacheSize) {
Node<Integer, Integer> lastNode = doubleLinkedList.getLast();
map.remove(lastNode.key);
doubleLinkedList.removeNode(lastNode);
}
Node<Integer, Integer> newNode = new Node<>(key, value);
map.put(key, newNode);
doubleLinkedList.addHead(newNode);
}
}
public static void main(String[] args) {
LcuDemo l = new LcuDemo(2);
l.put(1, 1);
l.put(2, 2);
l.put(3, 3);
System.out.println(l.get(1));
System.out.println(l.get(2));
System.out.println(l.get(3));
}
}
四、第四阶段
1、美团面试八连问
解释下对象的创建过程
答:分为创建普通对象和数组两种,比如
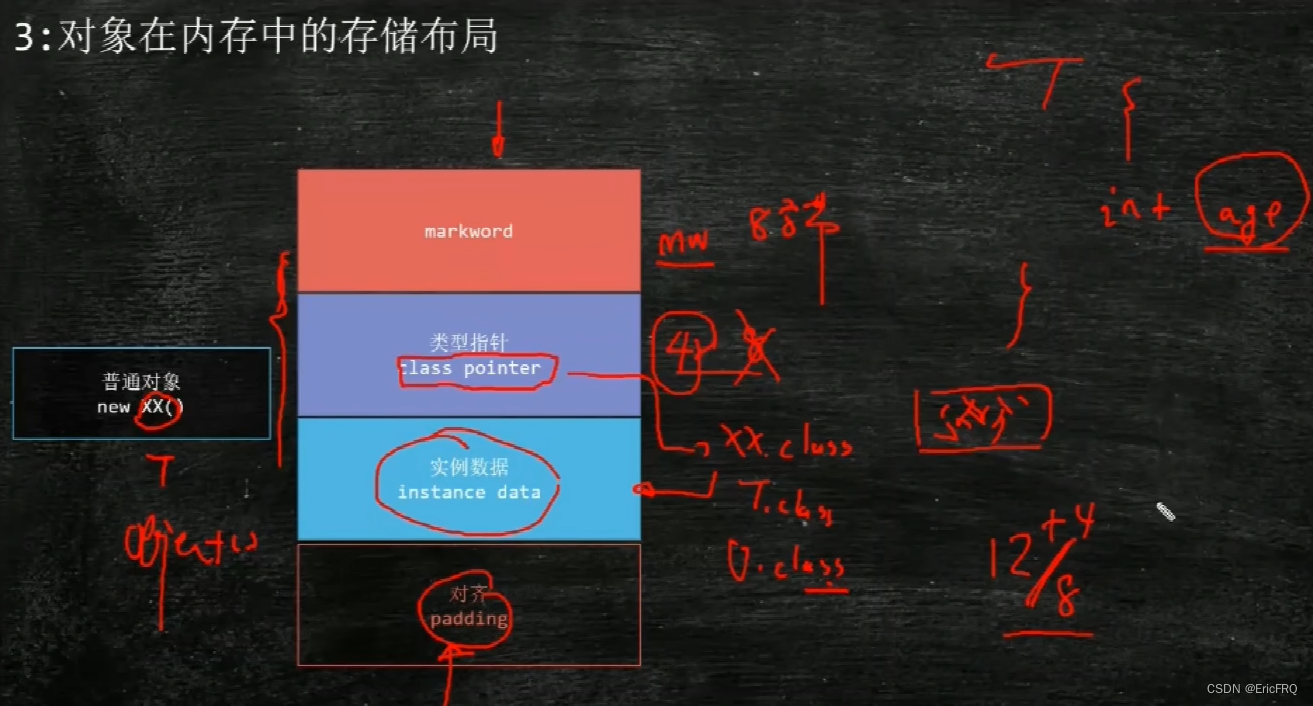
Object o= new Object();此行代码,新建的普通对象o在内存中的存储布局如下图:
markword占八个字节、类型指针(比如上面就是指向Objcet.class,new的是什么对象,就指向什么.class),一般压缩后占四个字节、
实例数据,存储普通对象里面的实例属性,比如里面有integer、boolean类型的数据、对齐(padding)比如上面所占字节有8+4=12个字节,不够整除8,就会在后面加上4,能被8整除
同样的,这也解释了上面第七个问题Object o= new Object();在内存中占多少(16)个字节
同样的,这也解释了上面第四个问题,对象头具体包括什么,对象头部有markword,它包括了锁信息、hashcode、gc,对象头部还有类型指针class pointer
总结下具体的包含图

下面回答第一个问题,首先new一个对象,赋予对象默认值(比如int 就是0),第二步执行构造方法赋初始值,第三步,建立关联
下面回答第二个问题,dcl(双重检查锁),
第二种数组对象的布局如下图:

2、排序与查找
1、二分查找
相关面试题

总结公式:2n =total
文字描述:将数据从小到大按序排列,取中间下标与查找值比较,查找值大,就在右边找,查找值小,就在左边找
代码实现:
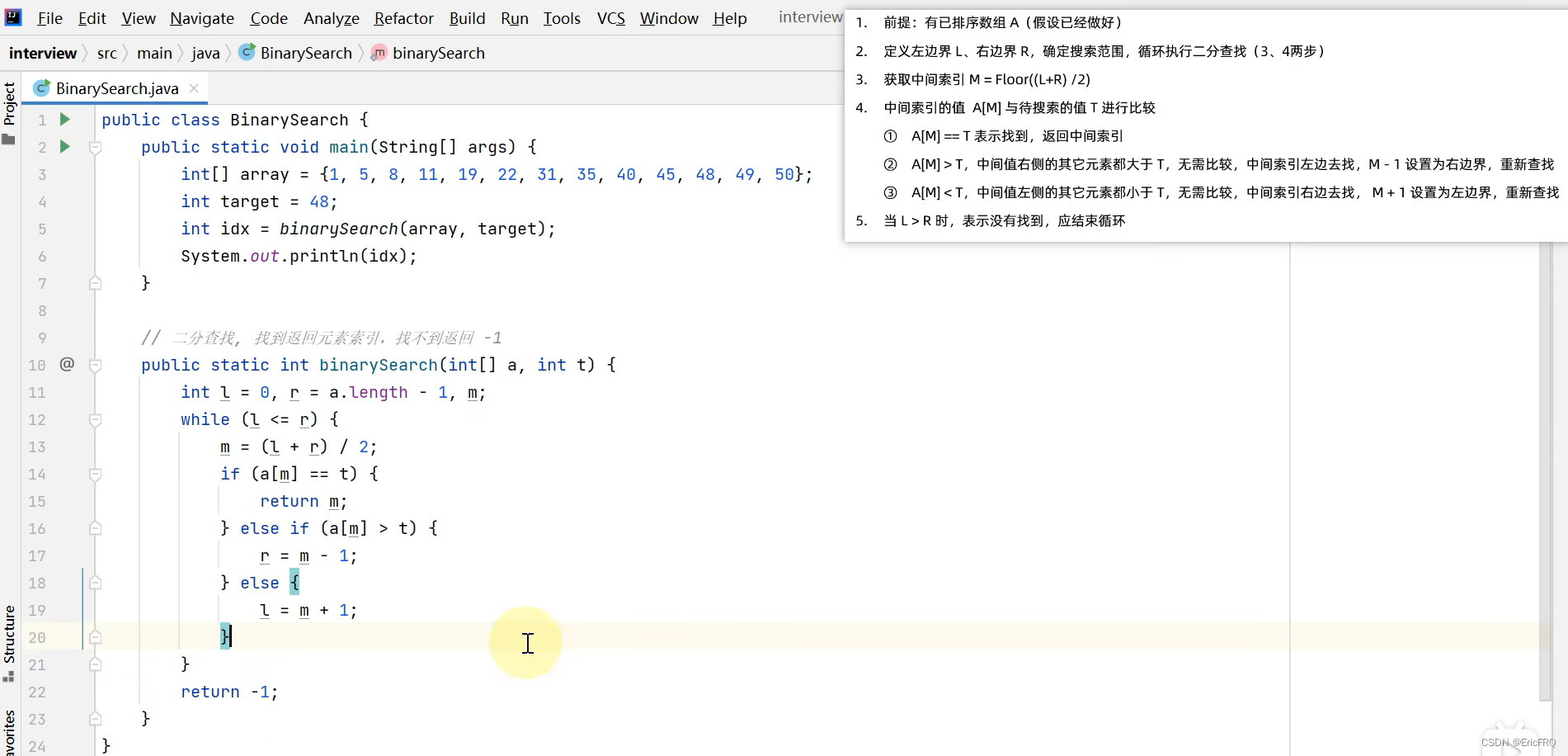
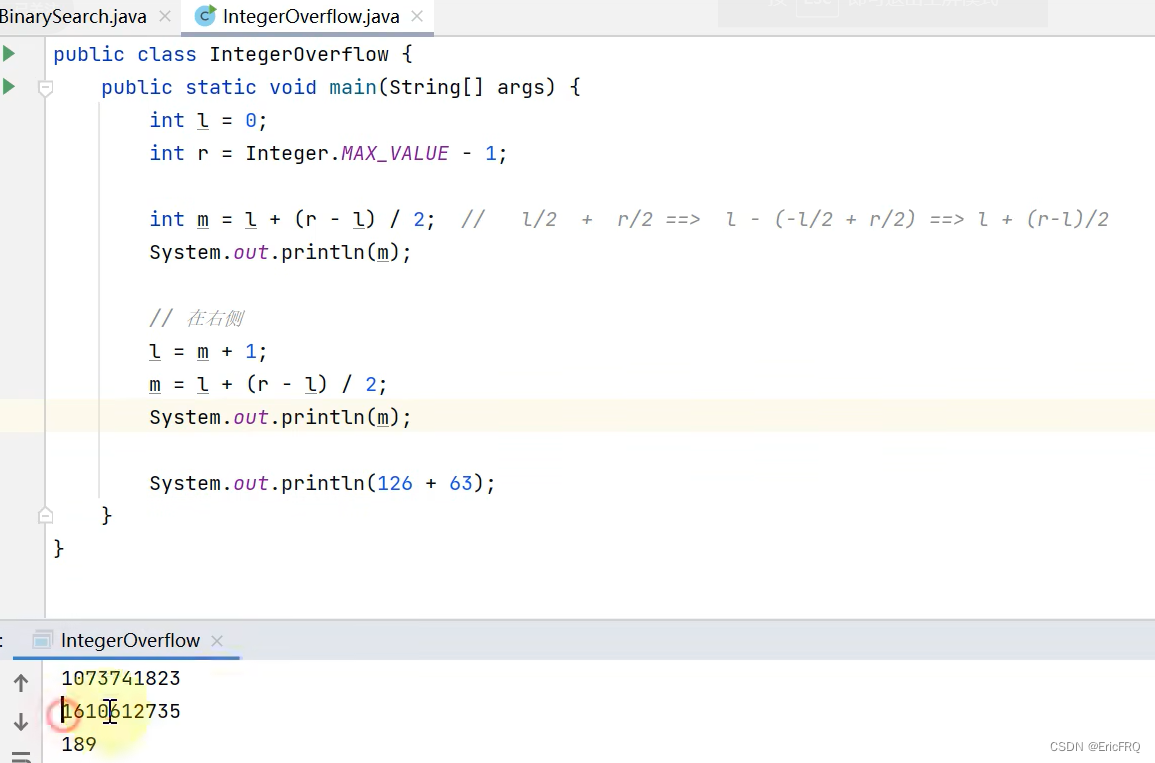
上面的代码有一个小问题,问题如下图
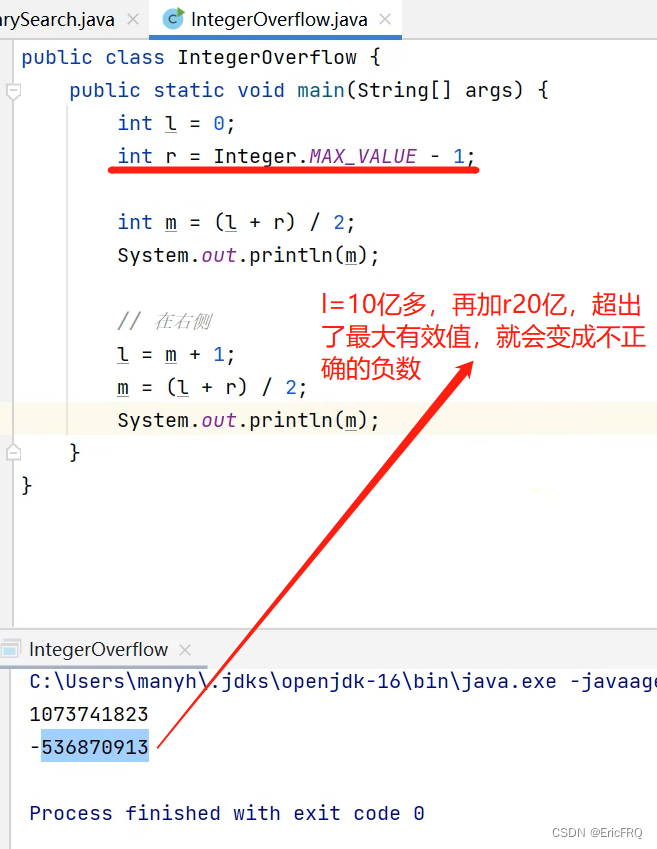
解决方式1:根据数学公式,由(l+r)/2推导出l/2+r/2==>l-l/2+r/2==>l+r/2-l/2==>l+(r-l)/2,由l+(r-l)/2代替(l+r)/2
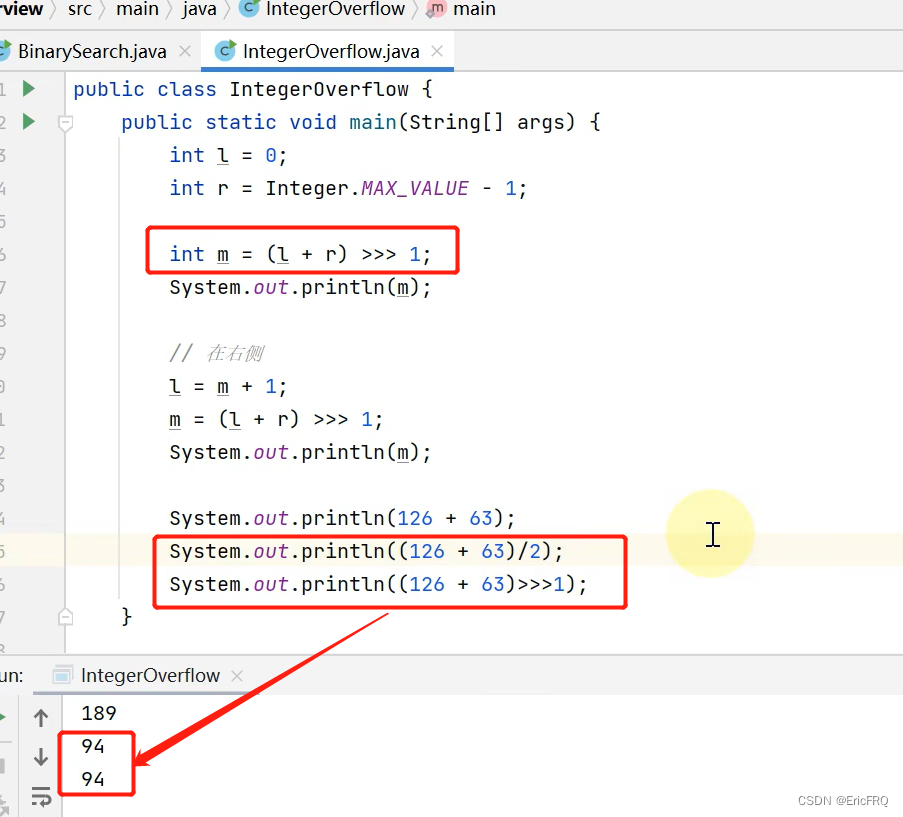
解决方式2:无符号右移>>>
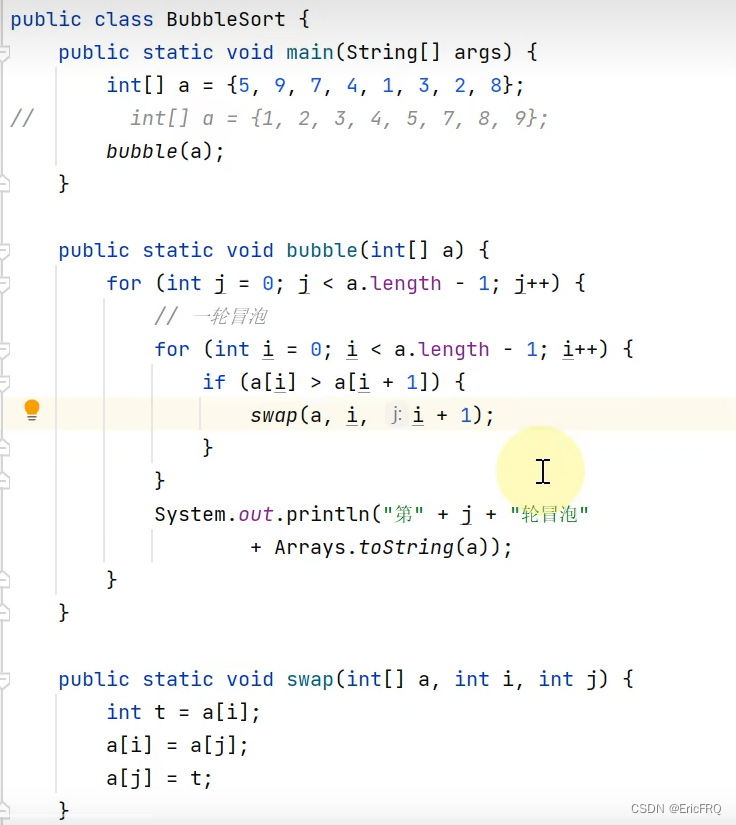
2、冒泡排序

(1)最基础的写法
(2)优思路基础版
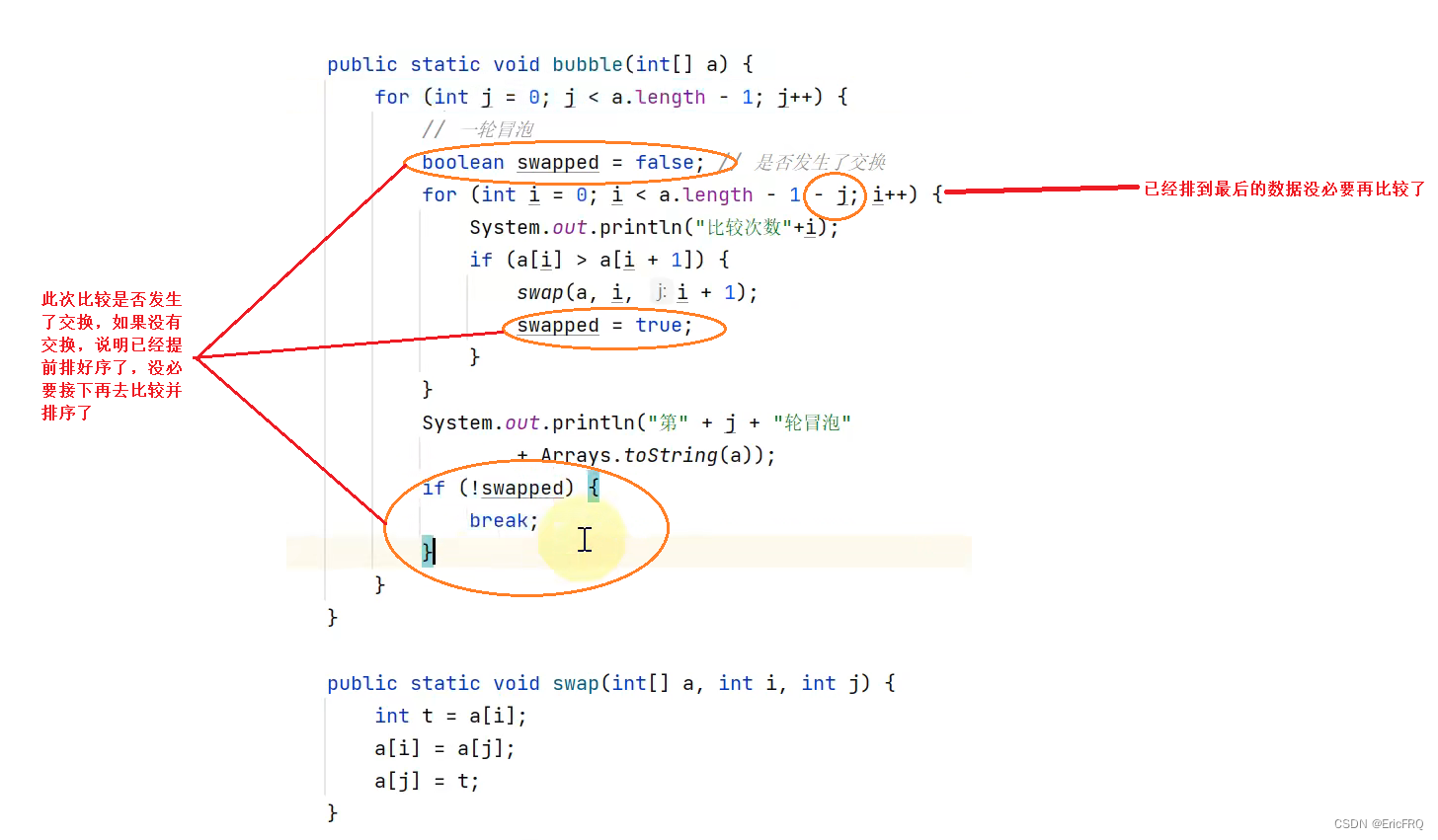
(3)优化思路进阶版

3、选择排序
从下标0开始,从所有数据中选出最小的与当前的(第一次是下标为0)数据交换位置
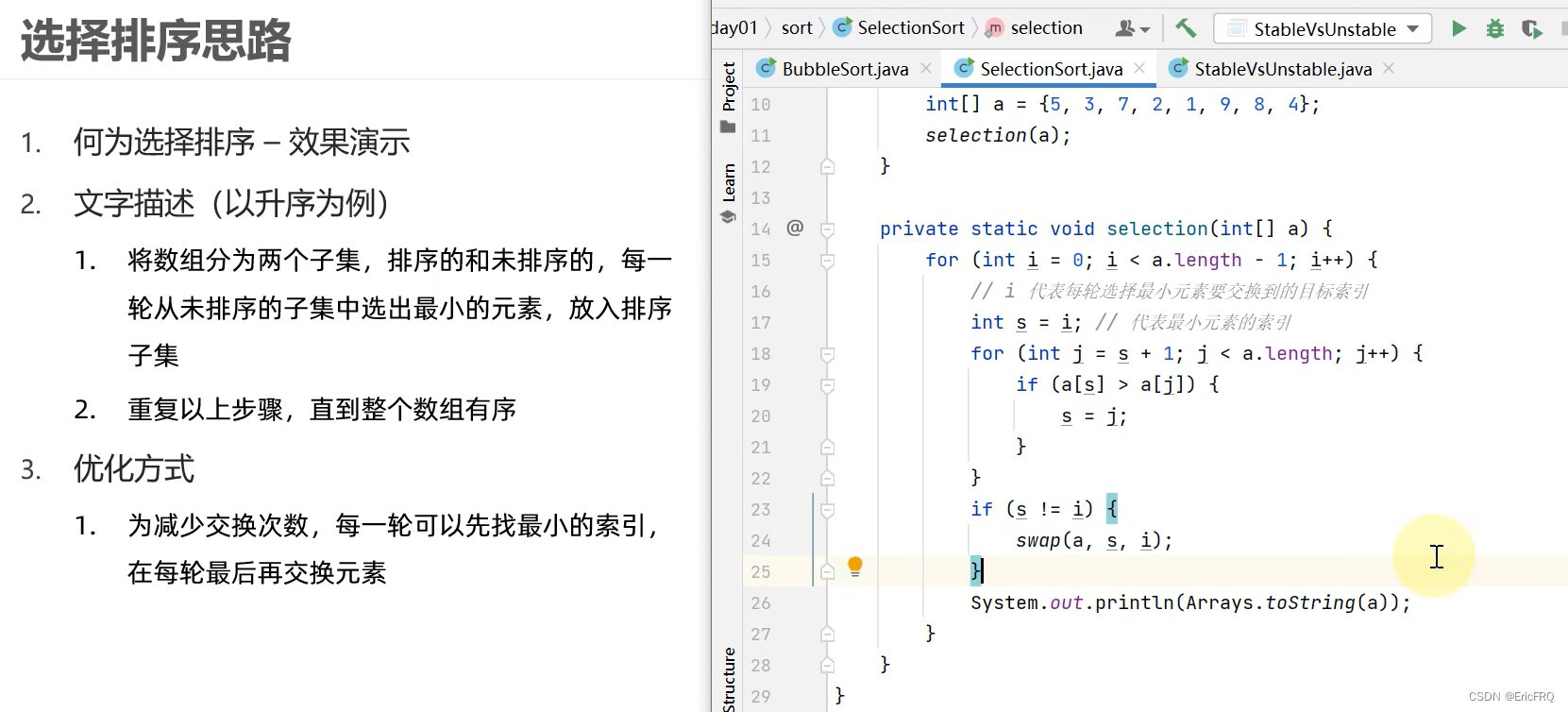
相比于冒泡排序,区别如下:

4、插入排序
从下标为1开始,比上一个小就插入到前面,把上一个后移到后面
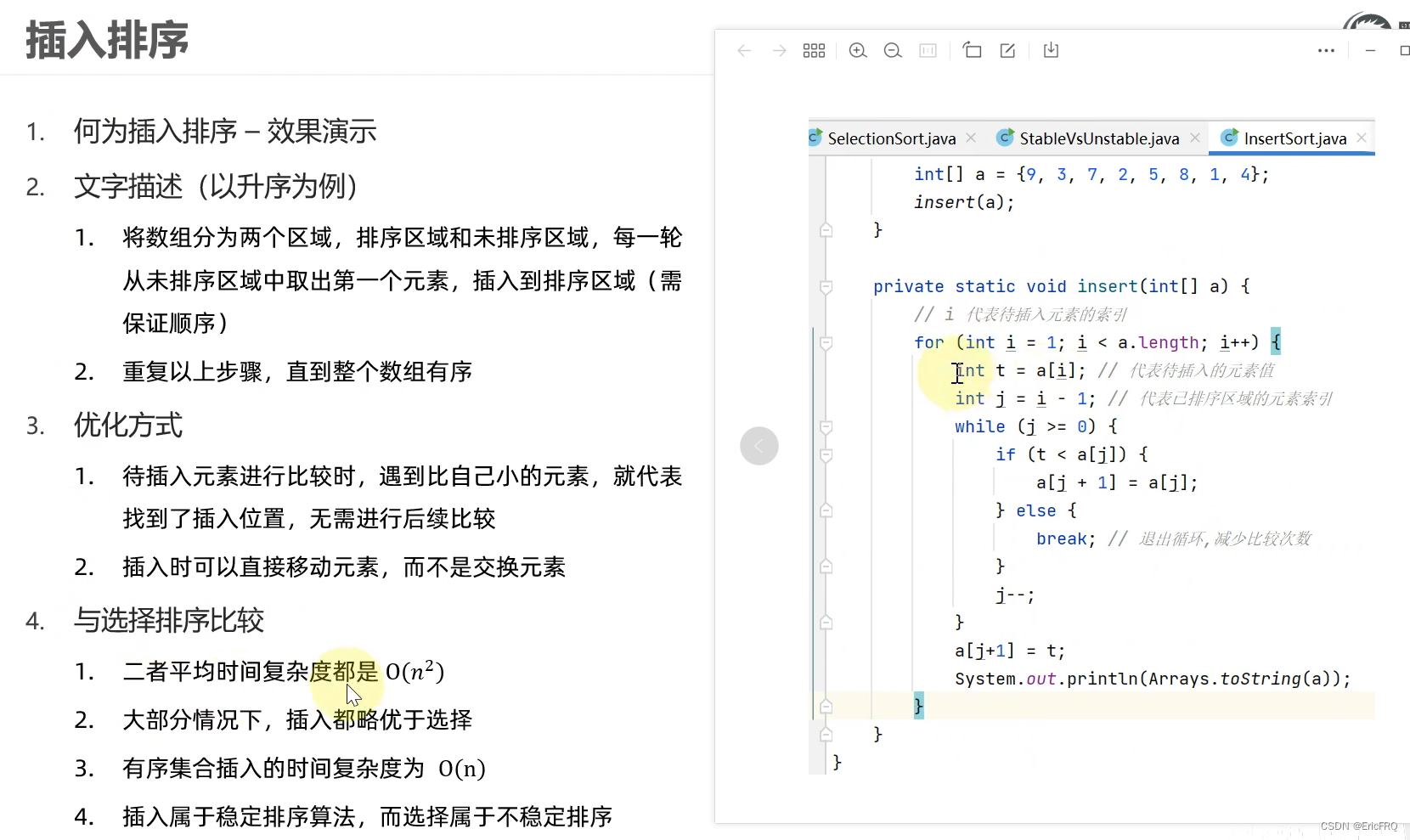
5、希尔排序
是插入排序的改进算法
6、快速排序
先介绍两种常见的快排方式:

单边循环代码实现:
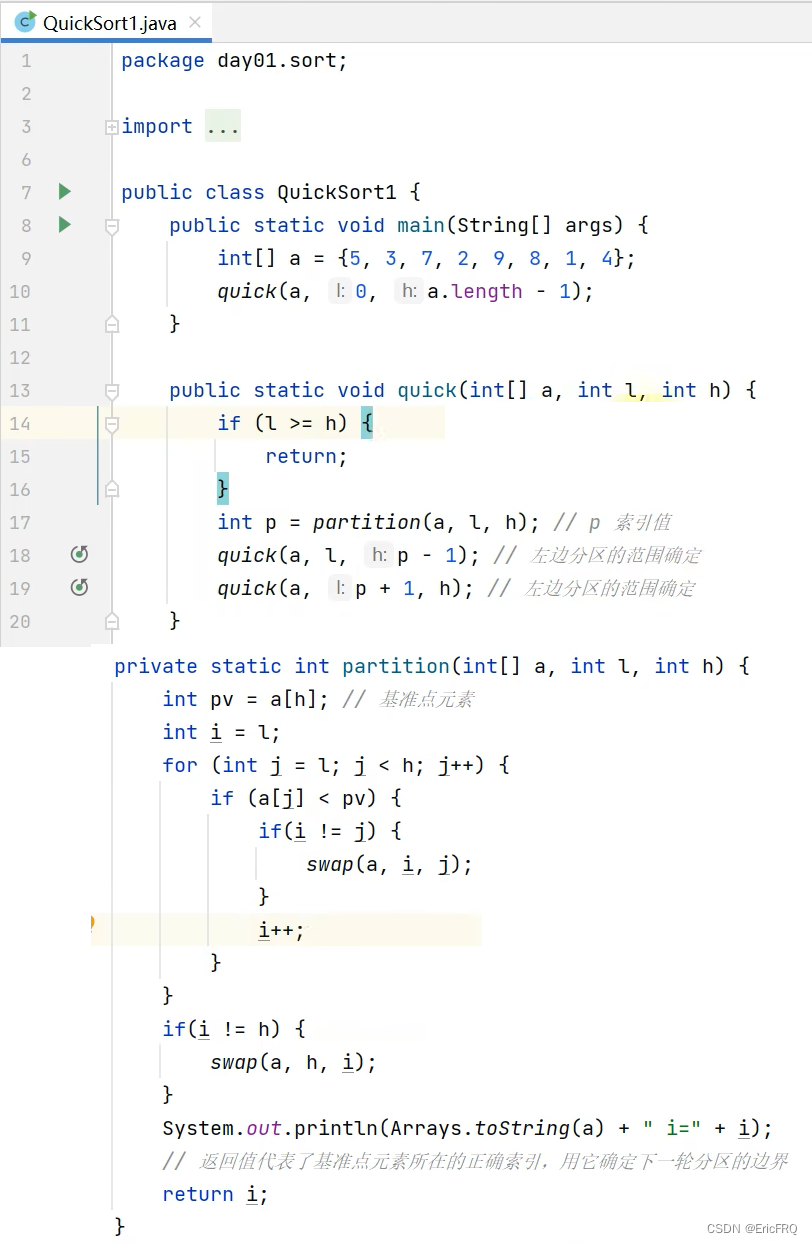
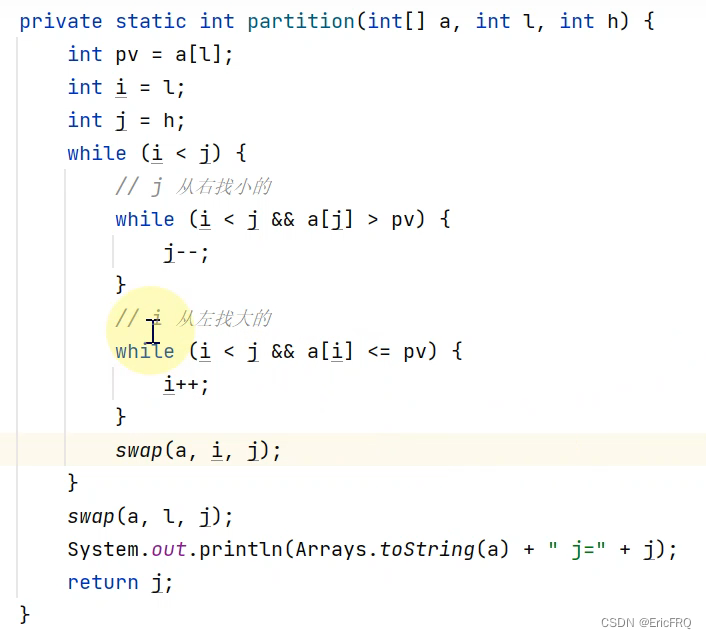
双边循环代码:其他部分代码与单边循环一样,只有partition方法有改动
快速排序特点

7、例题
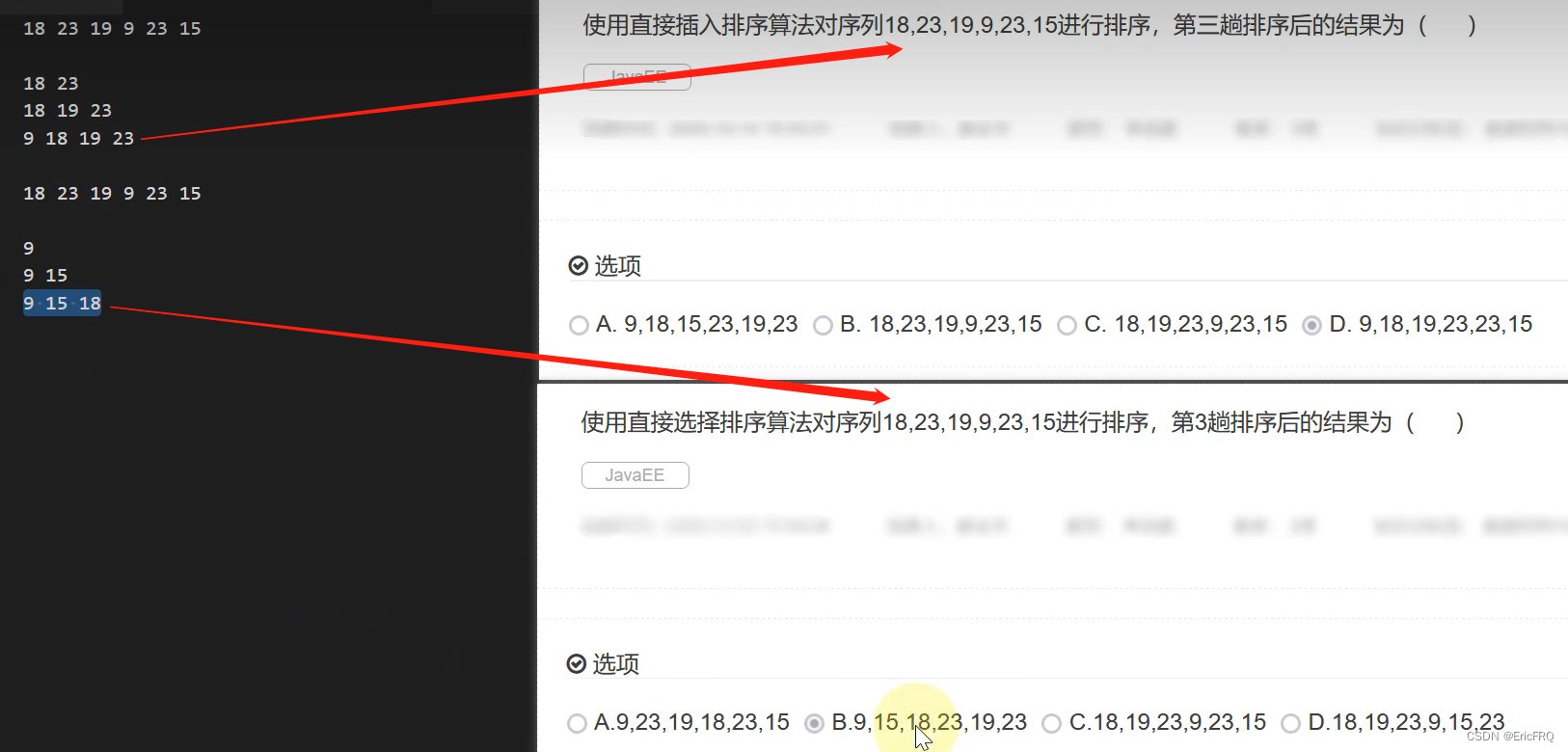
3、设计模式
参考另一篇:23种设计模式
1、单例模式
(1)饿汉式
public class Singleton {
// 直接创建对象
public static Singleton instance = new Singleton();//因为是静态对象,所以线程安全
// 私有化构造函数
private Singleton(){}
// 返回对象实例
public static Singleton getInstance() {
return instance;
}
}
(2)懒汉式(优化后线程安全)
public class Singleton {
// 声明变量
private static volatile Singleton singleton = null;// volatile修饰的对象
// 私有构造函数
private Singleton(){}
// 提供对外方法
public static Singleton getInstance() {
if (singleton == null) {
synchronized (Singleton.class) {
if (singleton == null) {//DCL检测是否为null
singleton = new Singleton();
}
}
}
return singleton;
}
}
五 、第五阶段
1、springboot源码相关问题
SpringBoot框架在设计之初,为了有更好的兼容性,在不同的运行阶段,提供了非常多的扩展点, 可以让程序员根据自己的需求, 在整个Spring应用程序运行过程中执行程序员自定义的代码
1、ApplicationContextInitializer
(1)IOC容器对象创建完成后执行,可以对上下文环境做一些操作, 例如运行环境属性注册等。
使用:
- 自定义类,实现ApplicationContextInitializer接口
- 在META-INF/spring.factories配置文件中配置自定义的类
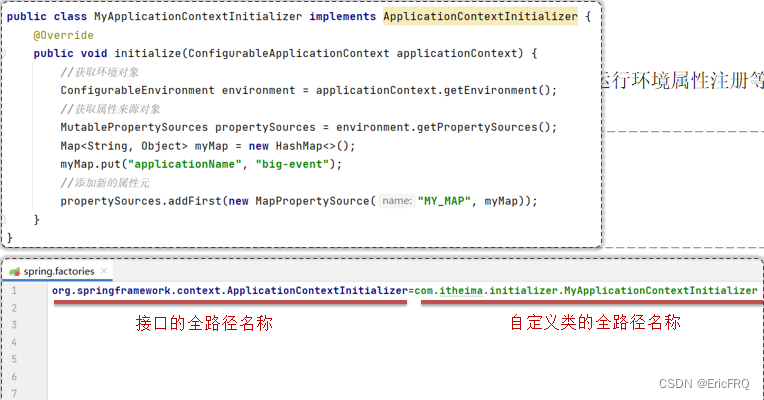
initialize方法什么时候执行?
IOC容器对象创建完成后执行, 常用于环境属性注册
2、ApplicationListener
使用:
- 自定义类,实现ApplicationListener接口
- 在META-INF/spring.factories配置文件中配置自定义的类
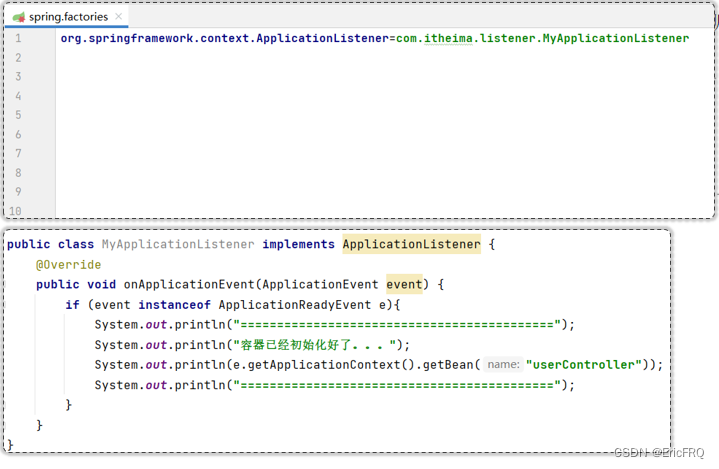
onApplicationEvent方法什么时候执行?
IOC容器发布事件之后执行, 通常用于资源加载, 定时任务发布等
3、BeanFactory
Bean容器的根接口, 提供Bean对象的创建、配置、依赖注入等功能
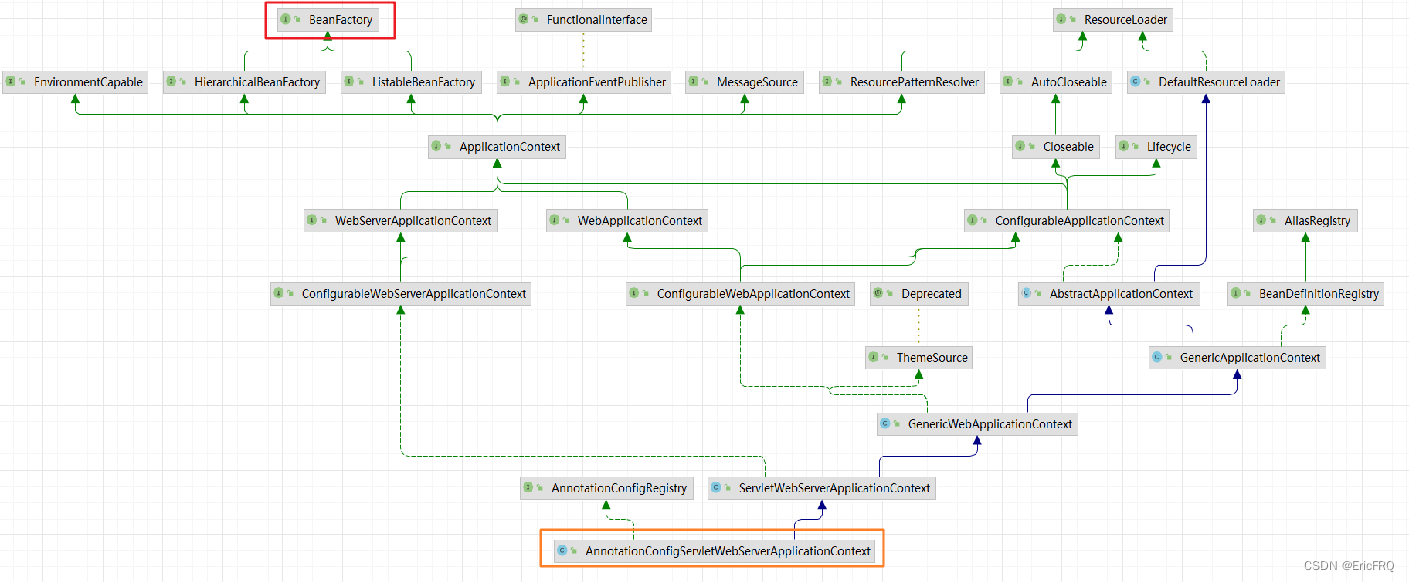
ApplicationConfigServletServerApplicationContext ->DefaultListableBeanFactory
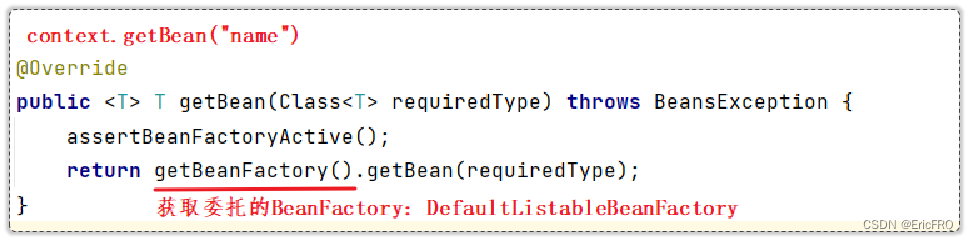
BeanFactory的作用?
Bean容器的根接口, 提供Bean对象的创建、配置、依赖注入等功能
BeanFactory常见的两个实现?
ApplicationConfigServletServerApplicationContext
DefaultListableBeanFactory
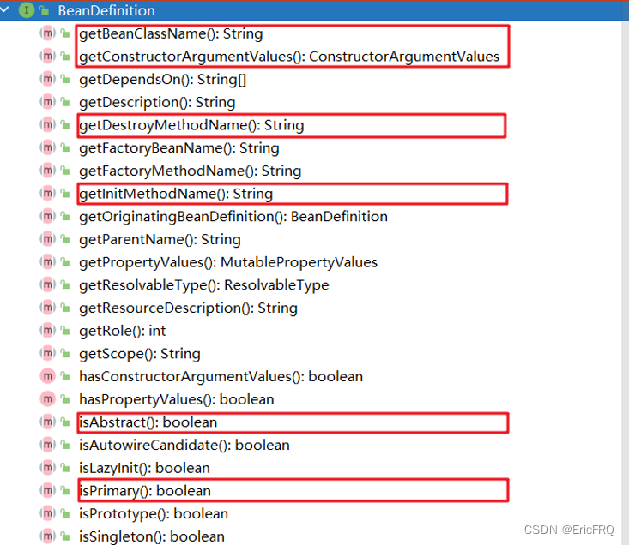
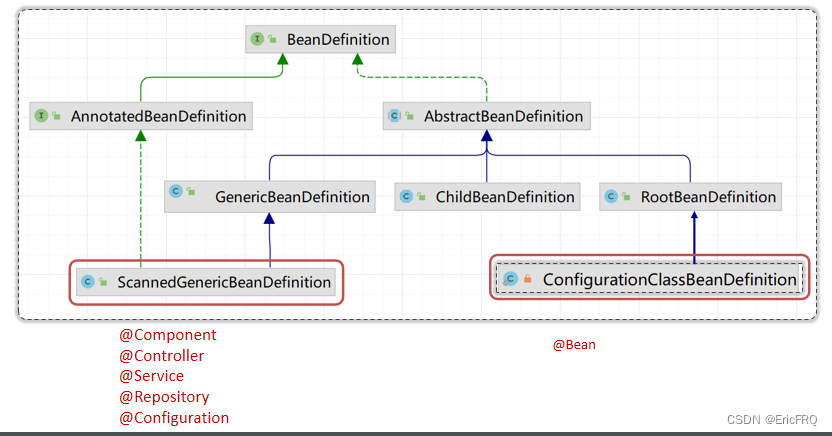
4、BeanDefinition
用于描述Bean,包括Bean的名称,Bean的属性,Bean的行为,实现的接口,添加的注解等等,Spring中,Bean在创建之前,都需要封装成对应的BeanDefinition,然后根据BeanDefinition进一步创建Bean对象
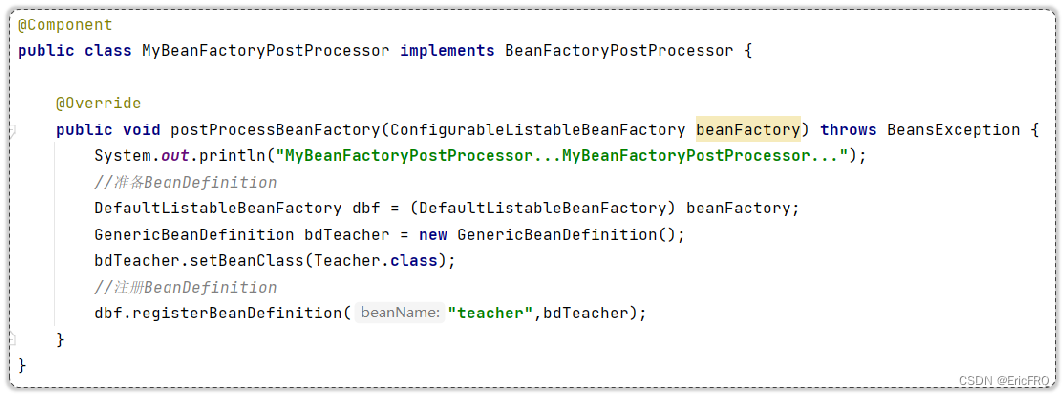
5、BeanFactoryPostProcessor
Bean工厂后置处理器,当BeanFactory准备好了后(Bean初始化之前),会调用该接口的postProcessBeanFactory方法,经常用于新增BeanDefinition
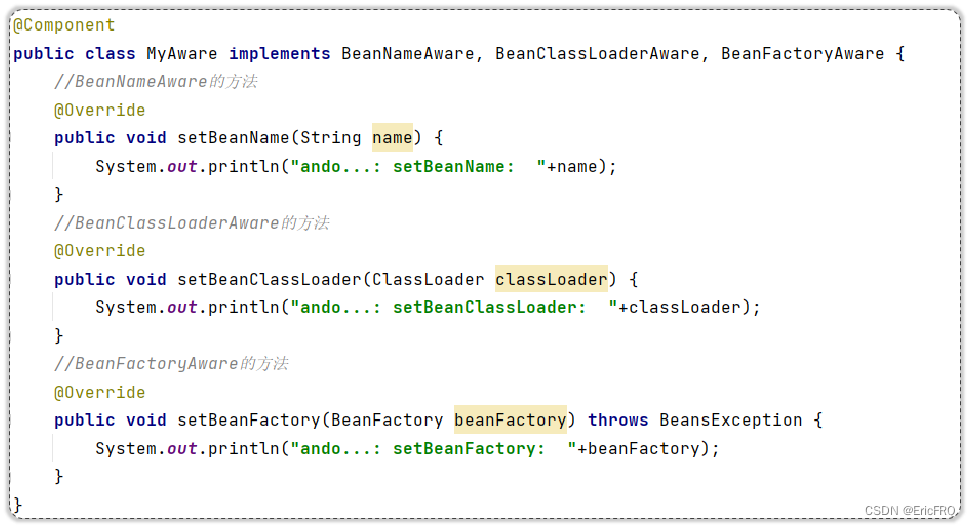
6、Aware
感知接口,Spring提供的一种机制,通过实现该接口,重写方法,可以感知Spring应用程序执行过程中的一些变化。Spring会判断当前的Bean有没有实现Aware接口,如果实现了,会在特定的时机回调接口对应的方法

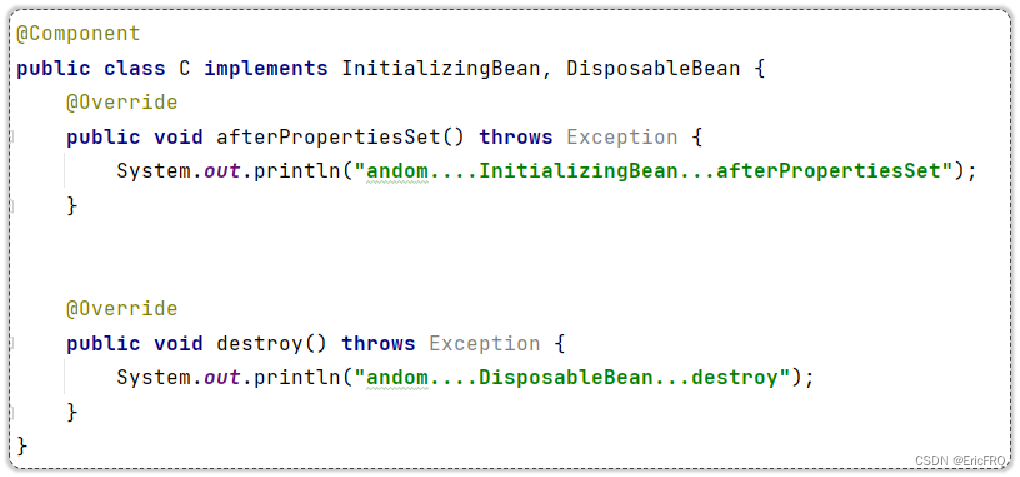
7、InitializingBean/DisposableBean
- 初始化接口,当Bean被实例化好后,会回调里面的函数,经常用于做一些加载资源的工作
- 销毁接口,当Bean被销毁之前,会回调里面的函数,经常用于做一些释放资源的工作
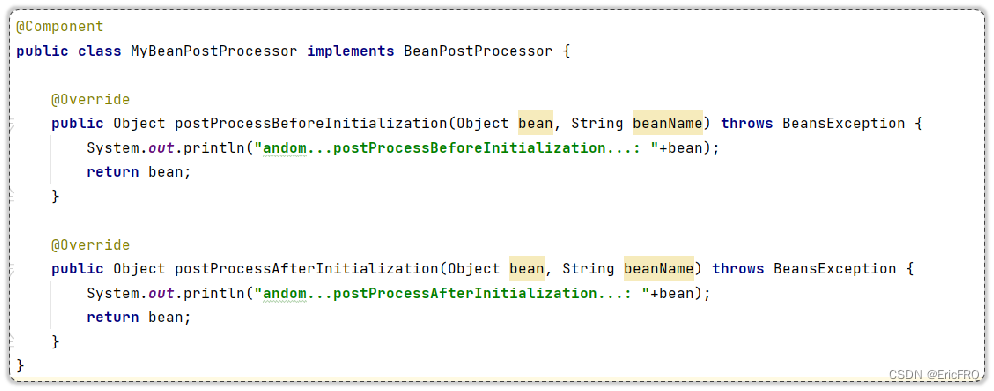
8、BeanPostProcessor
Bean的后置处理器,当Bean对象初始化之前以及初始化之后,会回调该接口对应的方法
- postProcessBeforeInitialization: Bean对象初始化之前调用
- postProcessAfterInitialization: Bean对象初始化之后

2、springboot启动流程
- new SpringApplication()
(1)、确认web应用的类型(是传统mvc还是响应式)
(2)、加载ApplicationContextInitializer
(3)、加载ApplicationListener
(4)、记录主启动类 - run()
(1)、准备环境对象Environment,用于加载系统属性等等
(2)、打印Banner
(3)、实例化容器Context
(4)、准备容器,为容器设置Environment、BeanFactoryPostProcessor,并加载主类对应的BeanDefinition
(5)、刷新容器(创建Bean实例)
(6)、返回容器
面试题:请聊一聊SpringBoot的启动流程?
总: SpringBoot启动,其本质就是加载各种配置信息,然后初始化IOC容器并返回
分:在其启动的过程中会做这么几个事情
首先,当我们在启动类执行SpringApplication.run这行代码的时候,在它的方法内部其实会做两个事情
1. 创建SpringApplication对象;
2. 执行run方法。
其次,在创建SpringApplication对象的时候,在它的构造方法内部主要做3个事情。
1. 确认web应用类型,一般情况下是Servlet类型,这种类型的应用,将来会自动启动一个tomcat
2. 从spring.factories配置文件中,加载默认的ApplicationContextInitializer和ApplicationListener
3. 记录当前应用的主启动类,将来做包扫描使用
最后,对象创建好了以后,再调用该对象的run方法,在run方法的内部主要做4个事情
1. 准备Environment对象,它里面会封装一些当前应用运行环境的参数,比如环境变量等等
2. 实例化容器,这里仅仅是创建ApplicationContext对象
3. 容器创建好了以后,会为容器做一些准备工作,比如为容器设置Environment、BeanFactoryPostProcessor后置处理器,并且加载主类对应的Definition
4. 刷新容器,就是我们常说的referesh,在这里会真正的创建Bean实例
总:总结一下我刚说的,其实SpringBoot启动的时候核心就两步,创建SpringApplication对象以及run方法的调用,在run方法中会真正的实例化容器,并创建容器中需要的Bean实例,最终返回

3、IOC容器的初始化流程
主要是执行了AbstractApplicationContext.refresh()方法
- 准备BeanFactory(DefaultListableBeanFactory)
- 设置ClassLoader
- 设置Environment
- 扫描要放入容器中的Bean,得到对应的BeaDefinition(只扫描,并不创建)
- 注册BeanPostProcessor
- 处理国际化
- 初始化事件多播器ApplicationEventMulticaster
- 启动tomcat(执行onRefresh()方法)
- 绑定事件监听器和事件多播器
- 实例化非懒加载的单例Bean
- 扫尾工作,比如清空实例化时占用的缓存等

面试题:请聊一聊IOC容器的初始化流程?
总: IOC容器的初始化,核心工作是在AbstractApplicationContext.refresh方法中完成的
分:在refresh方法中主要做了这么几件事
1. 准备BeanFactory,在这一块需要给BeanFacory设置很多属性,比如类加载器、Environment等
2. 执行BeanFactory后置处理器,这一阶段会扫描要放入到容器中的Bean信息,得到对应的BeanDefinition(注意,这里只扫描,不创建)
3. 是注册BeanPostProcesor,我们自定义的BeanPostProcessor就是在这一个阶段被加载的, 将来Bean对象实例化好后需要用到
4. 启动tomcat
5. 实例化容器中实例化非懒加载的单例Bean, 这里需要说的是,多例Bean和懒加载的Bean不会在这个阶段实例化,将来用到的时候再创建
6. 当容器初始化完毕后,再做一些扫尾工作,比如清除缓存等
总:简单总结一下,在IOC容器初始化的的过程中,首先得准备并执行BeanFactory后置处理器,其次得注册Bean后置处理器,
并启动tomcat,最后需要借助于BeanFactory完成Bean的实例化
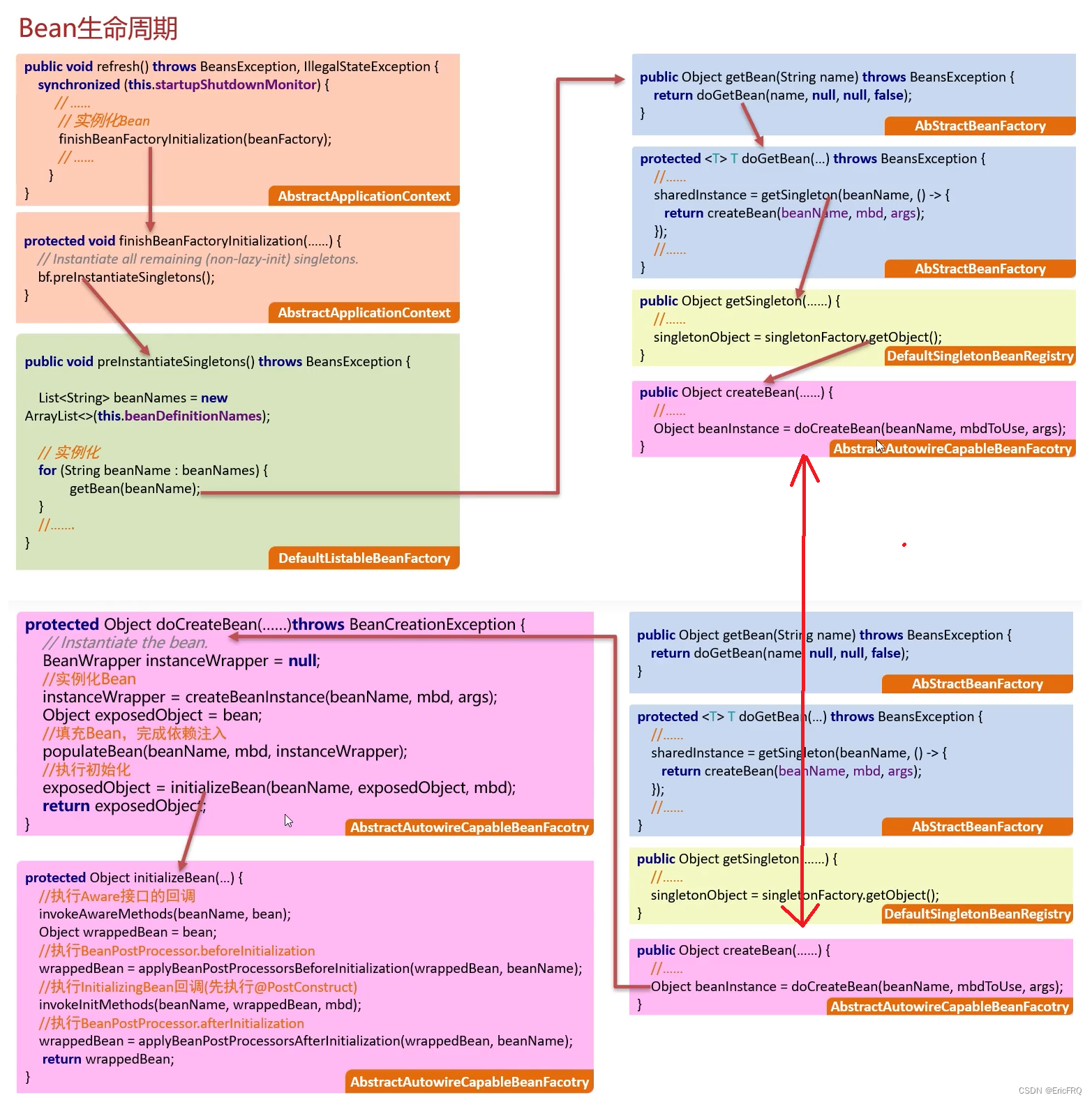
4、Bean的生命周期
创建对象和初始化对象都是执行了AbstractAutowireCapableBeanFactory.doCreateBean()
- 创建对象
(1)、实例化(构造方法)
(2)、依赖注入 - 初始化对象
(1)、执行Aware(感知)接口回调
(2)、执行BeanPostProcessor.postProcessBeforeInitialization
(3)、执行InitializingBean回调(先执行@PostConstruct标记的对象)
(4)、执行BeanPostProcessor.postProcessAfterInitialization - 使用对象
(1)、调用操作对象的各种方法,自己定义 - 销毁对象
(1)、执行disposableBean回调(先执行@PreDestory标记的对象)
对应上述描述的具体执行代码如下图:
面试题:请聊一聊Spring中Bean的生命周期?
总: Bean的生命周期总的来说有4个阶段,分别有创建对象,初始化对象,使用对象以及销毁对象,而且这些工作大部分是交给Bean工厂的doCreateBean方法完成的
分:
首先,在创建对象阶段,先调用构造方法实例化对象,对象有了后会填充该对象的内容,其实就是处理依赖注入
其次,对象创建完毕后,需要做一些初始化的操作,在这里涉及到几个扩展点。
1.执行Aware感知接口的回调方法
2.执行Bean后置处理器的postProcessBeforeInitialization方法
3.执行InitializingBean接口的回调,在这一步如果Bean中有标注了@PostConstruct注解的方法,会先执行它
4.执行Bean后置处理器的postProcessAfterInitialization
把这些扩展点都执行完,Bean的初始化就完成了
接下来,在使用阶段就是程序员从容器中获取该Bean使用即可
最后,在容器销毁之前,会先销毁对象,此时会执行DisposableBean接口的回调,这一步如果Bean中有标注了@PreDestroy接口的函数,会先执行它
总:简单总结一下,Bean的生命周期共包含四个阶段,其中初始化对象和销毁对象我们程序员可以通过一些扩展点执行自己的代码
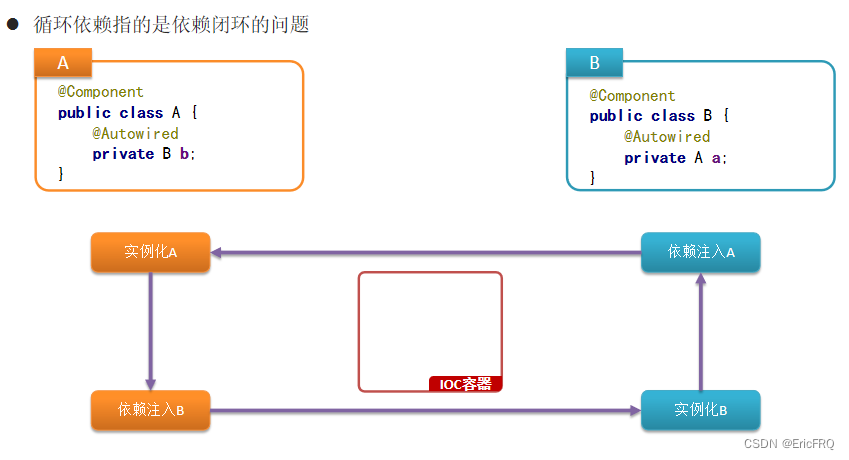
5、Bean的循环依赖
- 什么是循环依赖(依赖闭环)?

默认spring出现循环依赖会报错,但是可以在springboot的配置文件中设置属性,让spring支持循环依赖spring.main.allow-circular-references=true - spring解决循环依赖的具体实现?

面试题:请聊一聊Spring中Bean的循环依赖?
总: Bean的循环依赖指的是A依赖B,B又依赖A这样的依赖闭环问题,在Spring中,通过三个对象缓存区来解决循环依赖问题,这三个缓存区被定义到了DefaultSingletonBeanRegistry中,分别是singletonObjects用来存储创建完毕的Bean,earlySingletonObjecs用来存储未完成依赖注入的Bean,还有SingletonFactories用来存储创建Bean的ObjectFactory。假如说现在A依赖B,B依赖A,整个Bean的创建过程是这样的
分:
首先,调用A的构造方法实例化A,当前的A还没有处理依赖注入,暂且把它称为半成品,此时会把半成品A封装到一个ObjectFactory中,并存储到springFactories缓存区
接下来,要处理A的依赖注入了,由于此时还没有B,所以得先实例化一个B,同样的,半成品B也会被封装到ObjectFactory中,并存储到springFactory缓存区
紧接着,要处理B的依赖注入了,此时会找到springFactories中A对应的ObjecFactory, 调用它的getObject方法得到刚才实例化的半成品A(如果需要代理对象,则会自动创建代理对象,将来得到的就是代理对象),把得到的半成品A注入给B,并同时会把半成品A存入到earlySingletonObjects中,将来如果还有其他的类循环依赖了A,就可以直接从earlySingletonObjects中找到它了,那么此时springFactories中创建A的ObjectFactory也可以删除了
至此,B的依赖注入处理完了后,B就创建完毕了,就可以把B的对象存入到singletonObjects中了,并同时删除掉springFactories中创建B的ObjectFactory
B创建完毕后,就可以继续处理A的依赖注入了,把B注入给A,此时A也创建完毕了,就可以把A的对象存储到singletonObjects中,并同时删除掉earlySingletonObjects中的半成品A
截此为止,A和B对象全部创建完毕,并存储到了singletonObjects中,将来通过容器获取对象,都是从singletonObejcts中获取
总:总结起来还是一句话,借助于DefaultSingletonBeanRegistry的三个缓存区可以解决循环依赖问题
6、springmvc执行流程


面试题:请聊一聊SpringMvc执行流程?
总: 使用了SpringMvc后,所有的请求都需要经过DispatcherServlet前端控制器,该类中提供了一个doDispatch方法,有关请求处理和结果响应的所有流程都在该方法中完成
分:
首先,借助于HandlerMapping处理器映射器得到处理器执行链,里面封装了HandlerMethod代表目标Controller的方法,同时还通过一个集合记录了要执行的拦截器
接下来,会根据HandlerMethod获取对应的HandlerAdapter处理器适配器,里面封装了参数解析器以及结果处理器
然后,执行拦截器的preHandle方法
接下来是核心,通过HandlerAdapter处理器适配器执行目标Controller的方法,在这个过程中会通过参数解析器和结果处理器分别解析浏览器提交的数据以及处理Controller方法返回的结果
然后,执行拦截器的postHandle方法,
最后处理响应,在这个过程中如果有异常抛出,会执行异常的逻辑,这里还会执行全局异常处理器的逻辑,并通过视图解析器ViewResolver解析视图,再渲染视图,最后再执行拦截器的afterCompletion
7、spring、spring mvc、springboot区别

8、反射


基础
第一阶段
1、面向对象
封装、继承、多态
2、JDK、JRE、JVM
3、equals和==
参考上面高阶部分,第二阶段的2、equals和==
4、final和finalize
1、final:



2、finalize:java技术允许使用finalize()方法在垃圾收集器将对象从内存中清除出去之前做必要的清理工作。这个方法是由垃圾收集器在确定这个对象没有被引用时对这个对象调用的。它是在object类中定义的,因此所有的类都继承了它。子类覆盖finalize()方法以整理系统资源或者被执行其他清理工作。finalize()方法是在垃圾收集器删除对象之前对这个对象调用的。
但是!finalize非常不好,非常影响性能

5、String、StringBuffer、StringBuilder

6、重载和重写
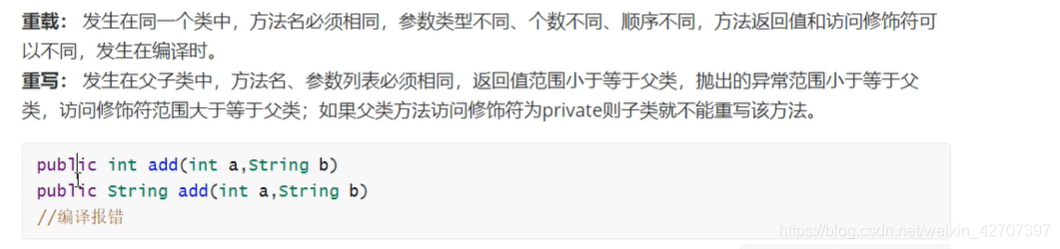
7、接口和抽象类

8、List和Set

9、HashCode和equals
10、ArrayList和LinkedList
-
ArrayList扩容的方式,1.5倍扩容。
(1)存储数据前大小为0
比如ArrayList调用add()时候,可传带下标参数add(1,“数据1”),若不传,则初始化为0,下标默认为0++,
(2)开始存储数据时的初始大小是10。
(3)int newCapacity = oldCapacity + (oldCapacity >> 1);
数组长度超过十之后扩容,扩容到原来的1.5倍,就是原长度右移一位(相当于10÷2),也就是5,再加上原来的10,也就是5+10=15。
(3-2)java17版本初始大小也是10,ArrayList()第二次扩容后容量是多少?
15的一半=7,15+7=22,所以第二次扩容大小是22。
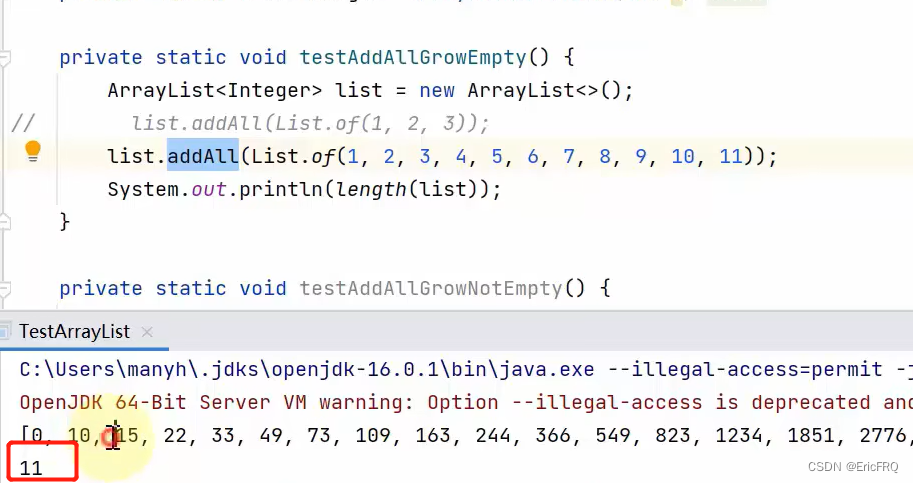
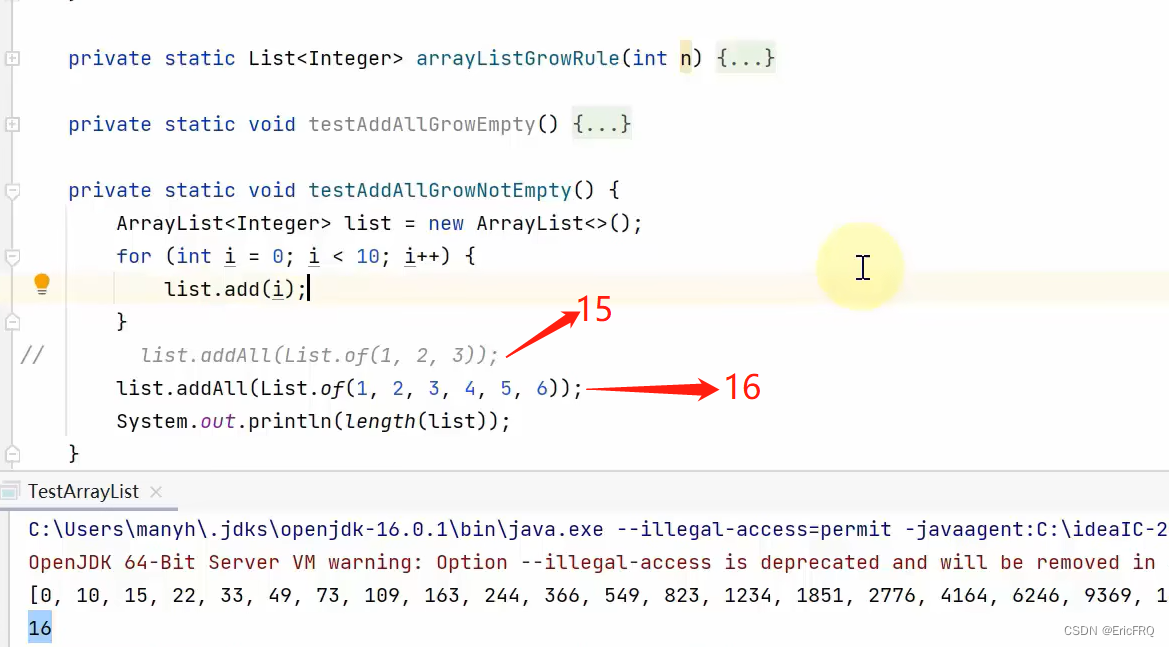
(4)ArrayList扩容机制:

如果初始化后添加元素时,从0往10扩容时,同时放入了11个元素,就会直接扩容至11,而不是先扩容至10再扩至15。
比如下面两个案例:
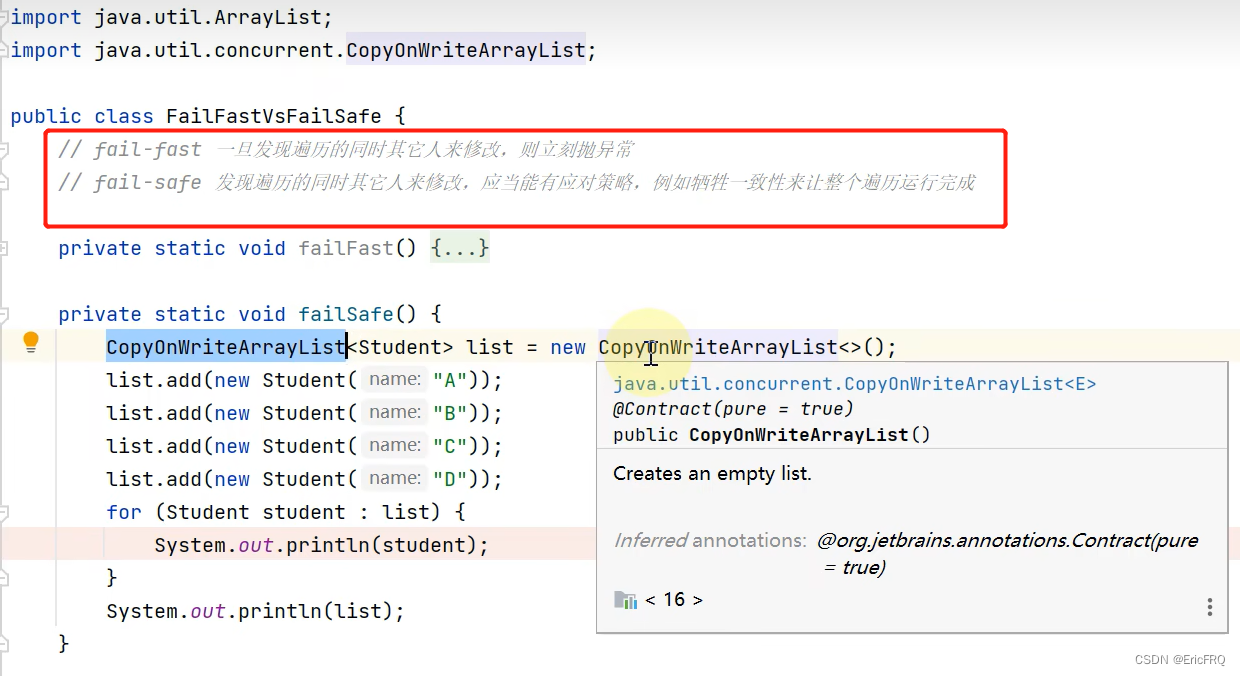
(5)ArrayList的failfast和failsafe
failfast:用ArrayList时,不允许遍历的同时被另外一个线程修改,否则会在遍历下一个元素过程中报异常
failsafe:用CopyOnWriteArrayList时,可以遍历的同时被另外一个线程修改,但是遍历的依旧是未修改前的队列,它会牺牲数据的一致性保证遍历完成

-
不指定下标,直接add()尾部插入,当输入的数据一直是小于千万级别的时候,大部分是Linked效率高,而当数据量大于千万级别的时候,就会出现ArrayList的效率比较高了。原因:数据量小时:当ArrayList扩容的时候,会效率降低,所以ArrayList的效益比较低。数据量大时:LinkedList每次增加的时候,会new 一个Node对象来存新增加的元素,所以当数据量小的时候,这个时间并不明显,其中如果ArrayList出现不需要扩容的时候,那么ArrayList的效率应该是比LinkedList高的,当数据量很大的时候,new对象的时间大于扩容的时间,那么就会出现ArrayList的效率比Linkedlist高了
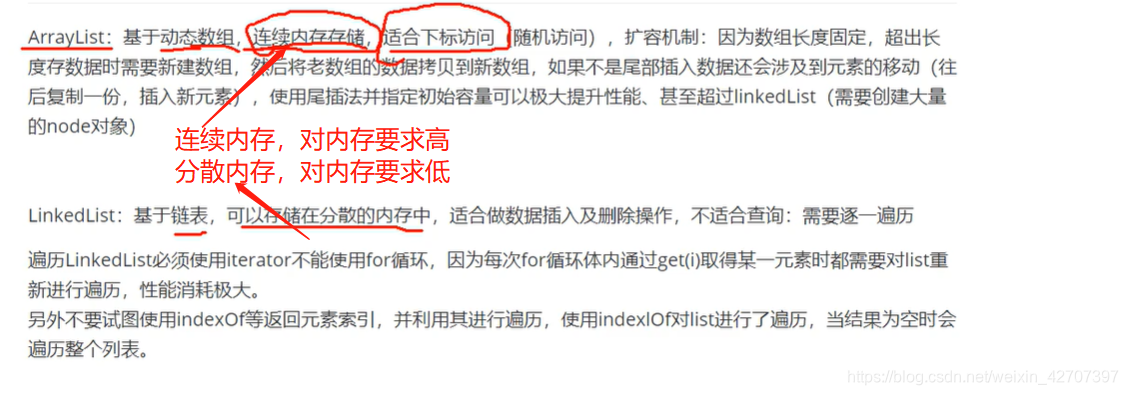

11、HashMap和HashTable和ConcurrentHashMap
参考上面高阶、第一阶段、2集合类线程不安全问题



12、如何实现IOC容器

13、java的类加载器有哪些
参考另一篇:3、类加载器之双亲委派机制

看一道错误的面试题:
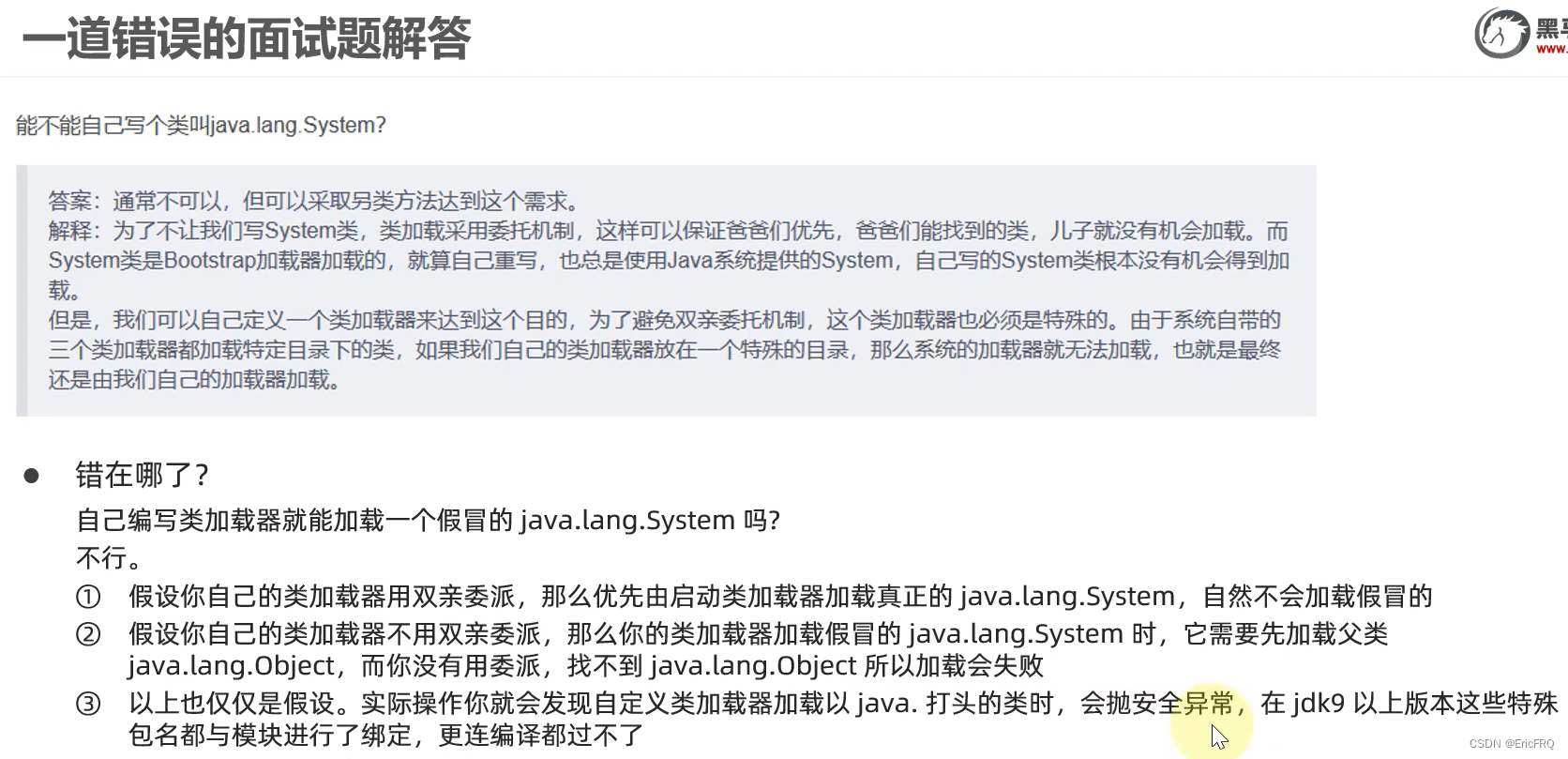
14、java中的异常体系
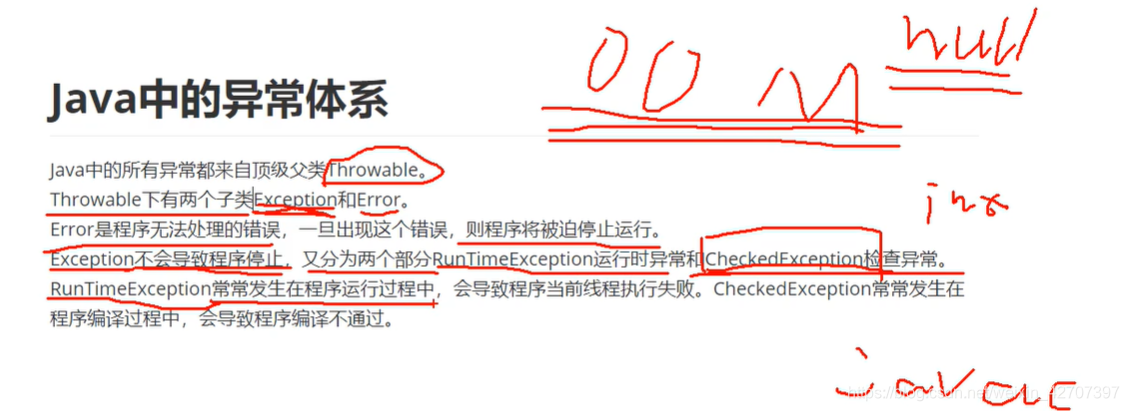
注意:OOM是Error不是Exception,一般我们的自定义异常都会继承RunTimeException
15、GC垃圾回收
参考上面高阶,第二阶段8、GC垃圾回收相关
16、线程的生命周期、状态

17、sleep()、wait()、join()、yield()

18、ThreadLocal
参考另外一篇博客:ThreadLocal原理及使用
原理:

使用场景:

ThreadLocal内存泄漏如何避免


调用remove方法的前提是知道是否使用完,即key值是否已经为空,那么就涉及到弱引用是否为空的判断,java9提供了方便的判断方式,如下图:

同样的类似方法还有jdk内部的一个类
19、接口幂等性
1、接口幂等性相关概念
一次或多次重复请求某接口,导致结果是一致的,不会因为多次点击请求就有多个一样数据到数据库




20、Filter和Interceptor的区别

高阶-2024
学习视频
一、java
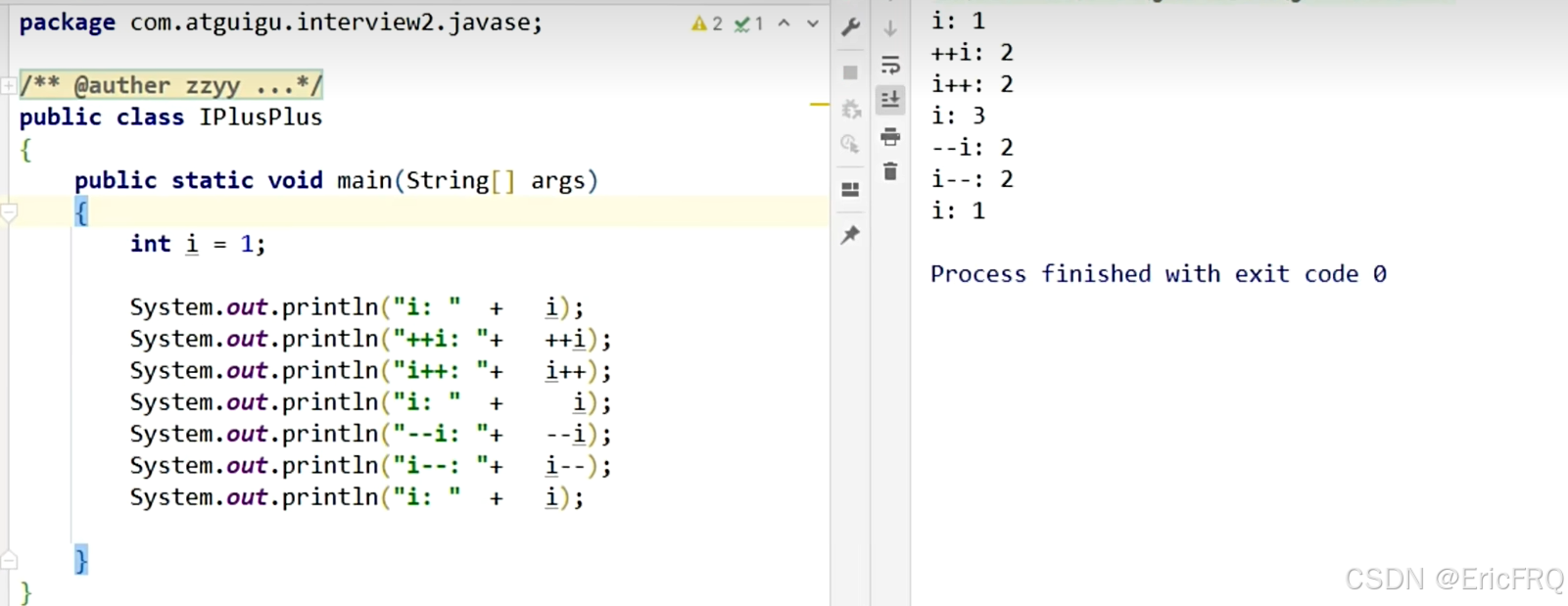
1、经典i++输出
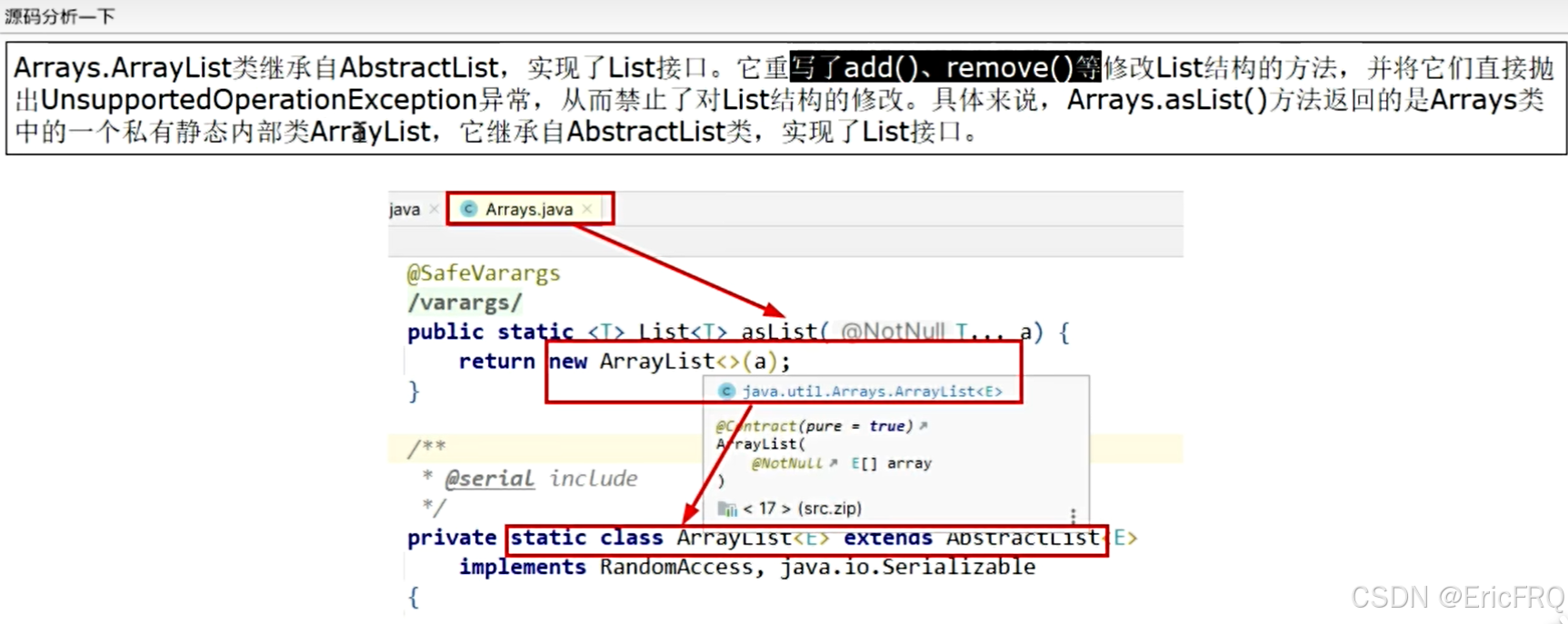
2、Arrays.asList()方法不可增删改

原因:返回的ArrayList是Arrays的一个静态内部类,而不是java.util的ArrayList
如果非要进行写操作,可以在外面包一层ArrayList

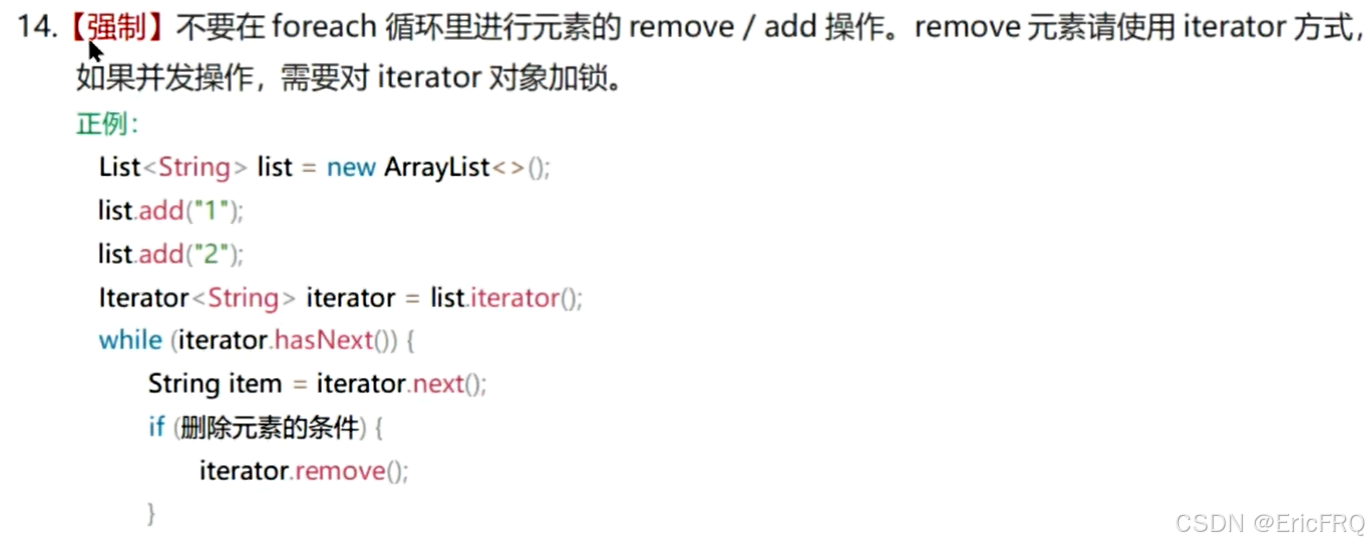
3、List集合删除问题
比如:

4、hashCode冲突案例
(1)、什么是hashcode,它属于哪个类的方法?
hashCode 是 Java 编程语言中的一个术语,它是一个整数,由 Object 类中的 hashCode() 方法返回。每个 Java 对象都有一个 hashCode 值,这个值在对象的生命周期中通常保持不变。hashCode 方法的主要用途是快速查找对象,特别是在哈希表(如 HashMap 和 HashSet)中。
hashCode 方法属于 Object 类,这意味着它是所有 Java 类的超类,因此每个 Java 类都继承了这个方法。开发者可以重写 hashCode 方法来提供自定义的哈希码计算逻辑,以确保对象在哈希表中的分布更加均匀,从而提高哈希表的性能。如果两个对象相等(即 equals() 方法返回 true),它们的 hashCode 值也必须相同。但是,如果两个对象的 hashCode 值相同,它们并不一定相等。
(2)、手写一个hashcode冲突案例
简单案例:字符串"Aa"和字符串"BB"的hashcode值相等
复杂案例:循环遍历大约十一万次的创建对象,其中创建的对象使用.hashCode()方法得到的hashcode值会出现碰撞。
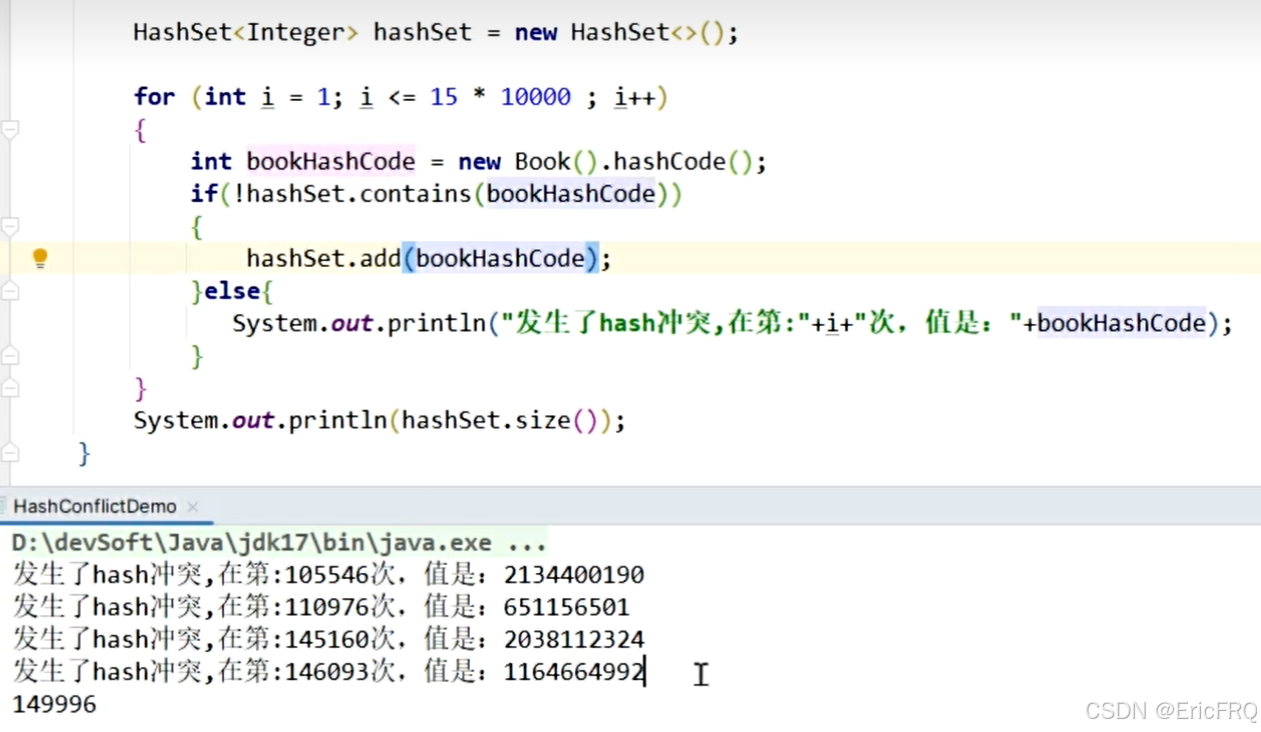
5、Integer相等问题
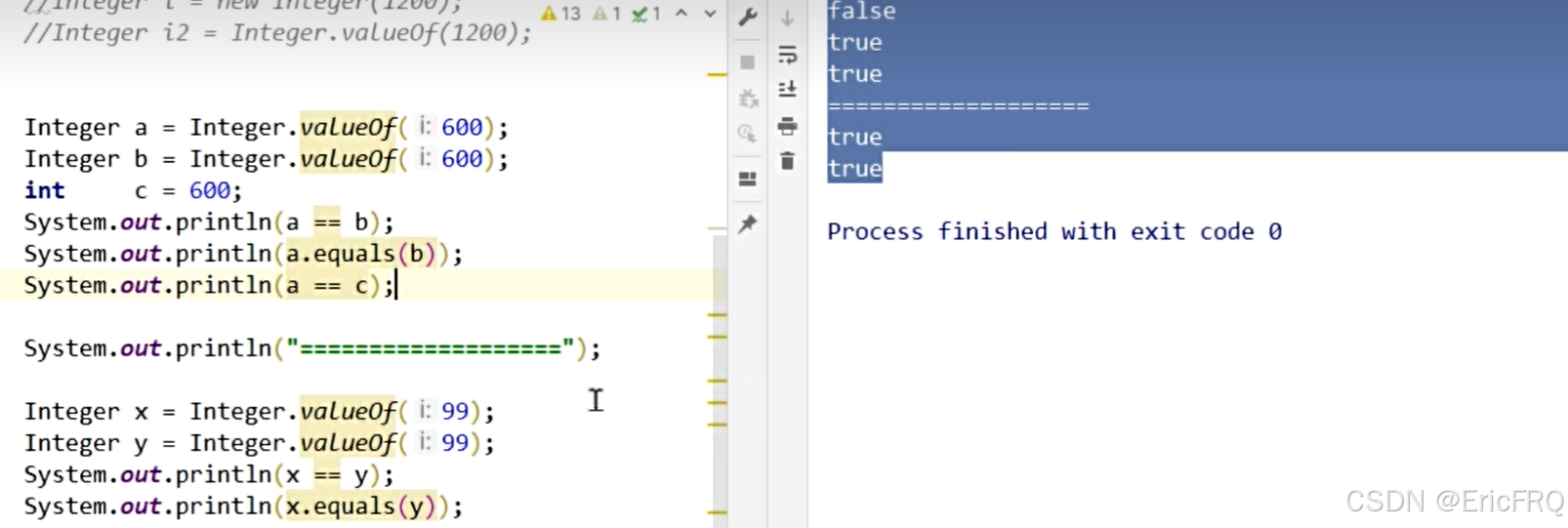
原因:-128-127之间会读缓存

6、BigDecimal的使用注意点
(1)、建议使用BigDecimal.valueOf()静态方法创建。
(2)、比较两个数大小建议使用.compareTo();

(3)、对于数字精度要求很高的情况下,在java实体类中建议使用BigDecimal,在sql设计表字段类型中建议使用Decimal类型。
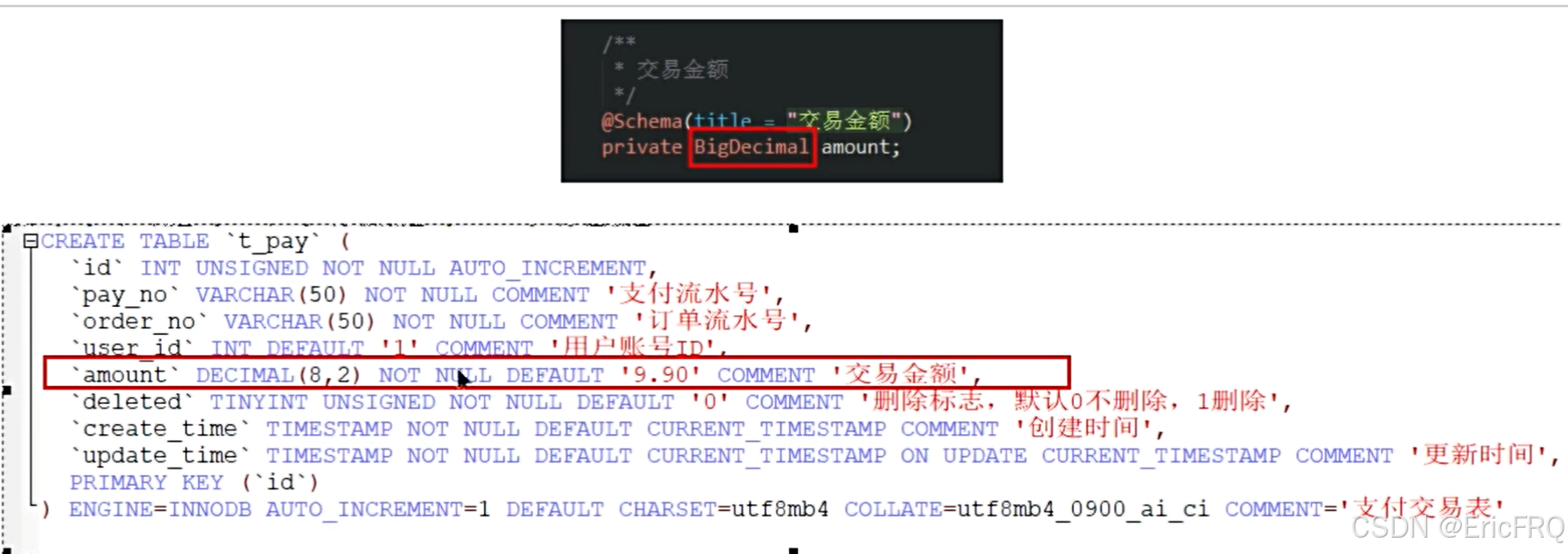
(4)、对于除法,要指定保留位数和类型。(比如四舍五入保留两位小数)。

7、List去重几种方式
(1)、for循环遍历,判断是否已存在,不存在加入新list集合。
(2)、使用HashSet(无序)或者LinkedHashSet(有序)去重。
(3)、使用stream流的distinct()方法。
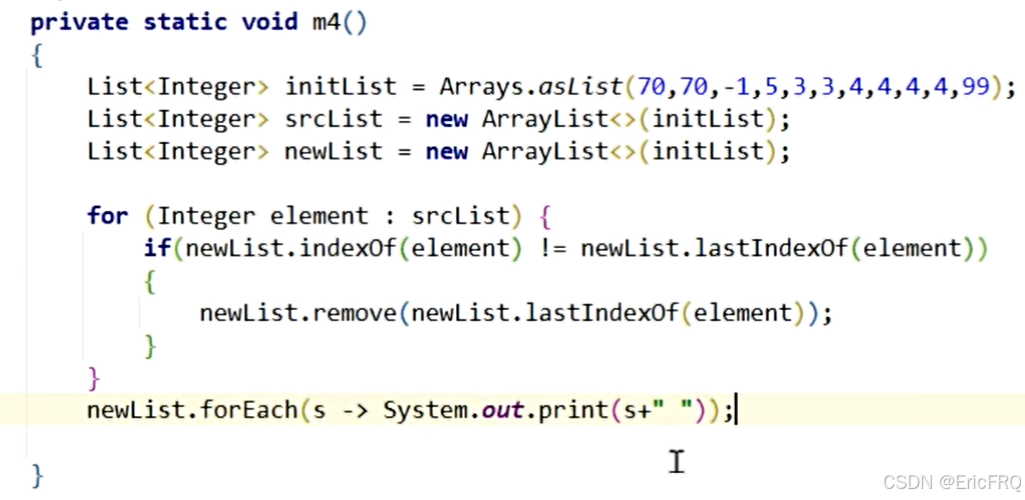
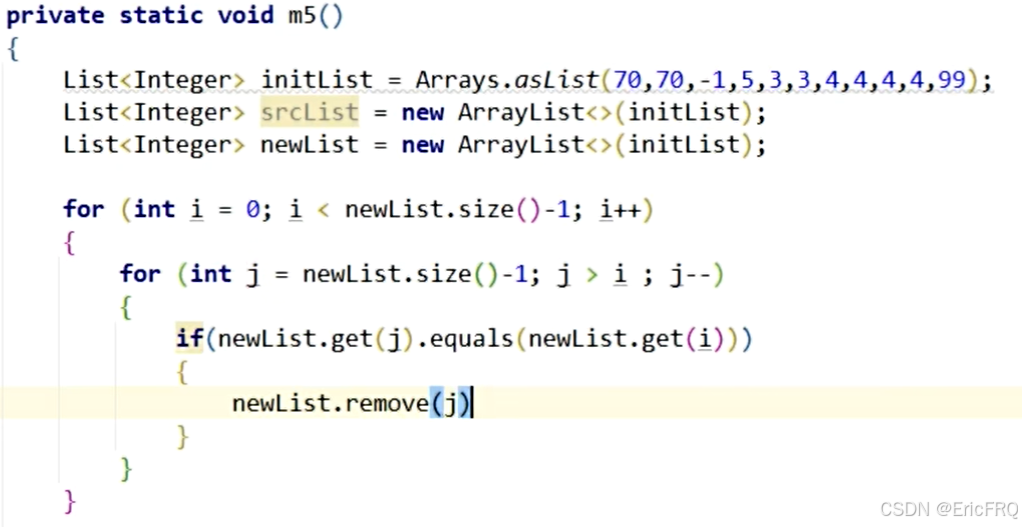
(4)、双指针判断元素下标是否相同,不相同为重复项。使用List的.indexOf()和.lastIndexOf()
两个一样的List遍历
同一个List遍历
8、深拷贝和浅拷贝
理论:
(1)、浅拷贝只复制某个对象的指针,不复制对象本身,新旧对象还是共享同一块内存。拷贝基本类型就是拷贝基本类型的值,拷贝引用类型,拷贝的就是内存地址,如果其中一个对象改变了这个地址,会影响到另外一个对象。
(2)、深拷贝会复制一个一模一样的对象,新对象和原对象不共享内存,修改新对象不影响原对象,原对象的值改变也不影响新对象。
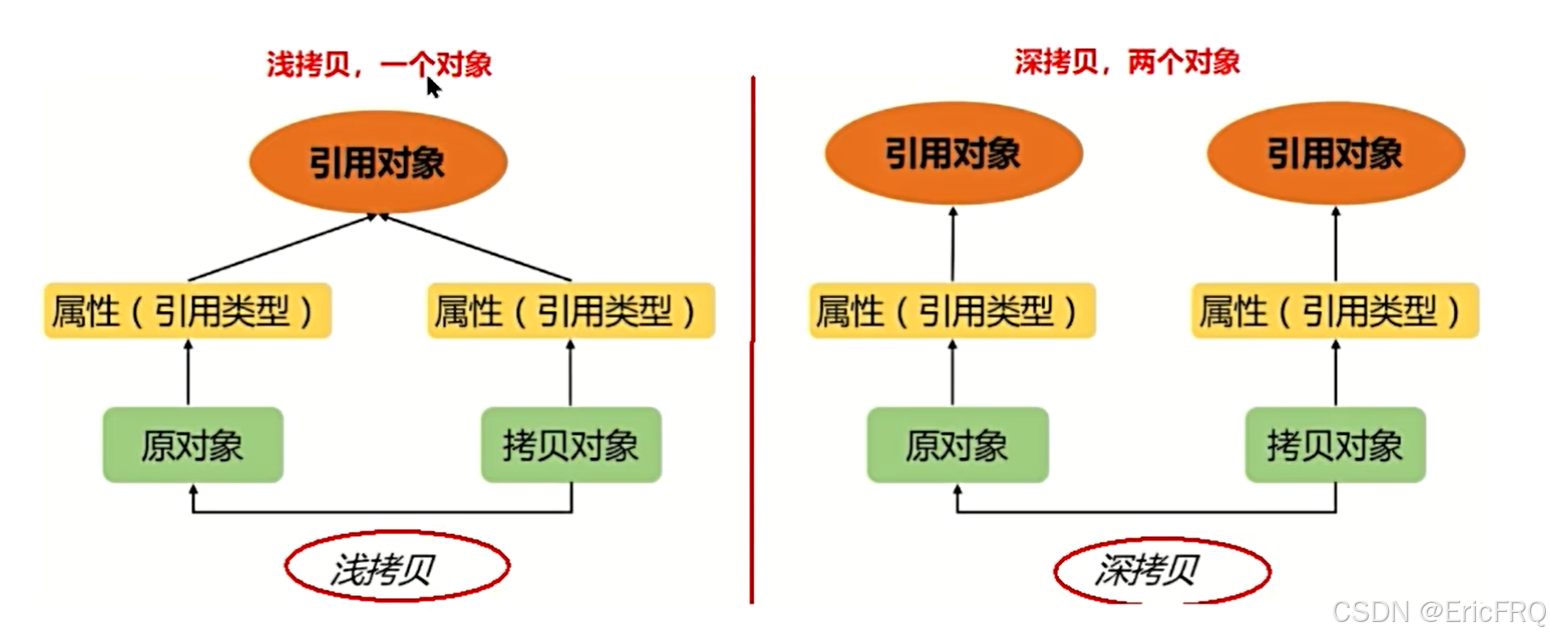
代码:
(1)、浅拷贝代码实现。实现java.lang.Cloneable接口,使用它默认的clone()方法即可
(2)、深拷贝代码实现。实现java.lang.Cloneable接口,重写clone()方法返回一个重新new的对象,方法内容如下:
@Override
protected ValidTest clone() throws CloneNotSupportedException {
return new ValidTest();
}
二、idea
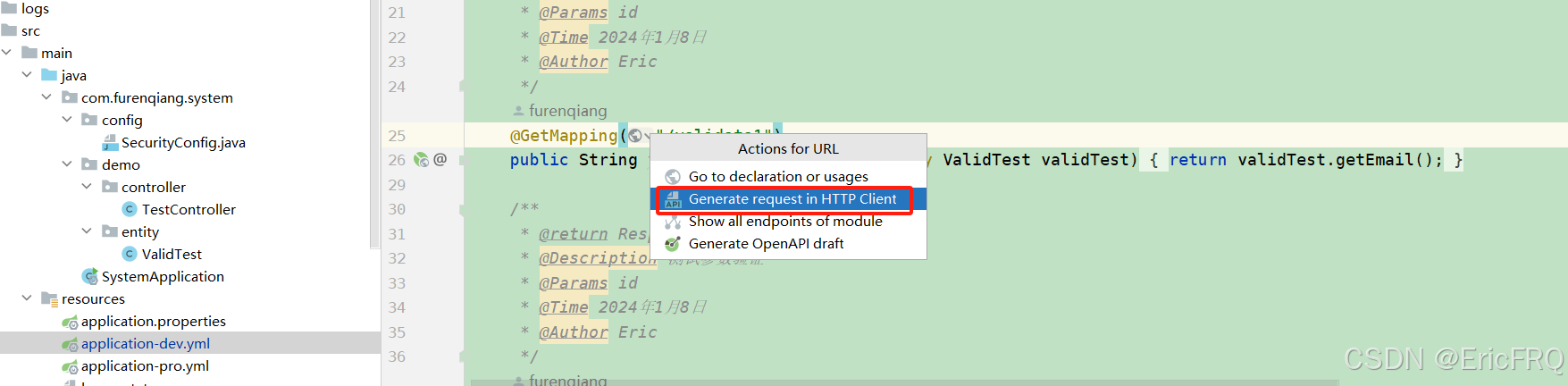
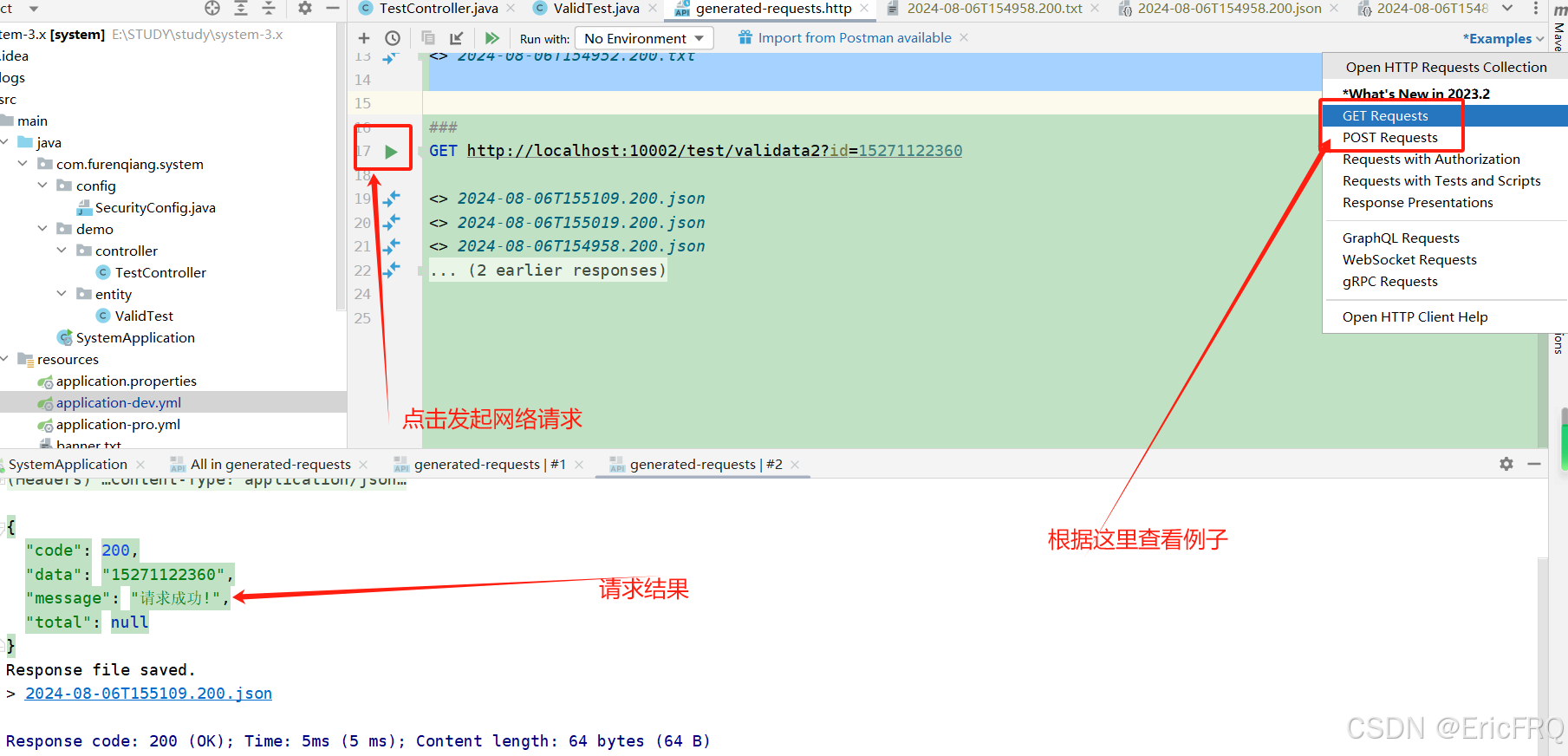
1、自带网络接口测试
2、debug高级用法
(1)、调试功能显示操作
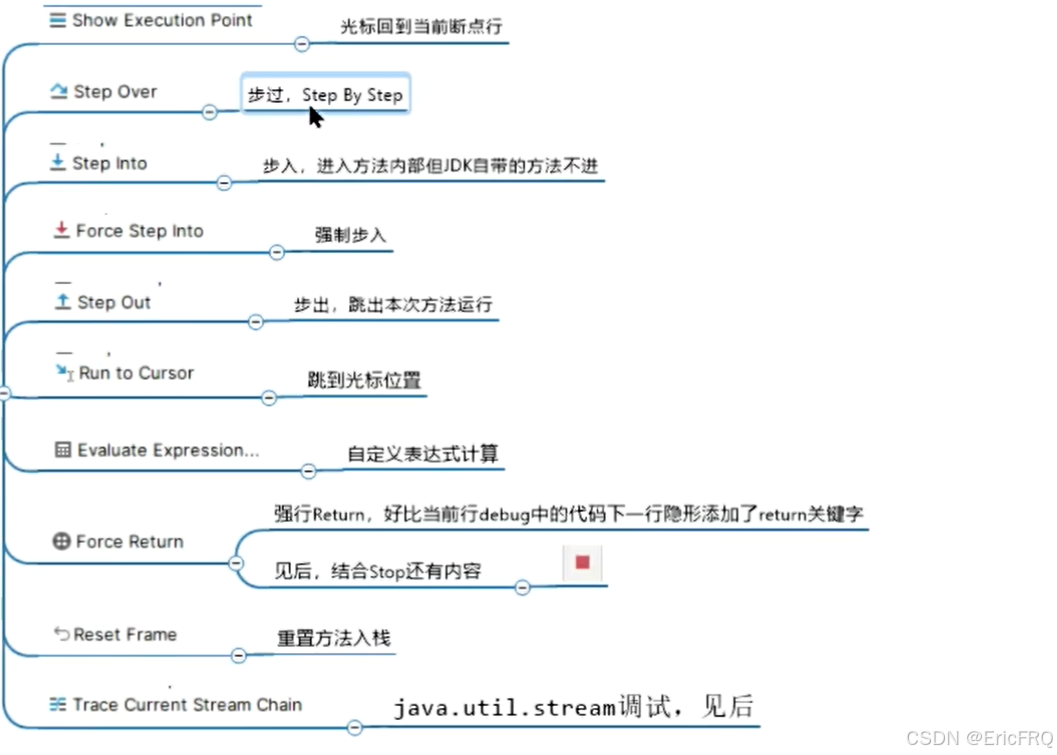
(2)、调试按钮功能介绍
(3)、流式代码debug
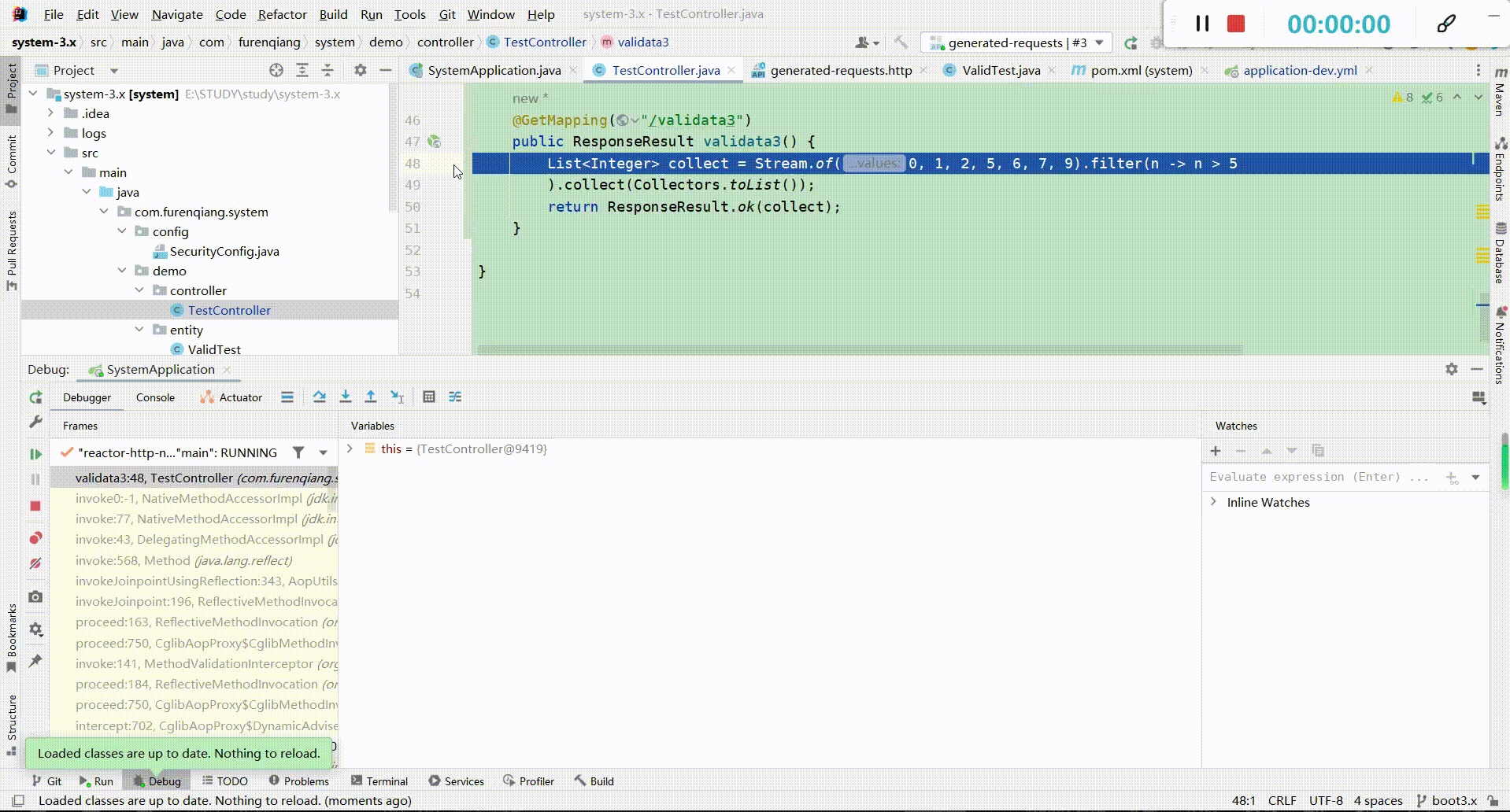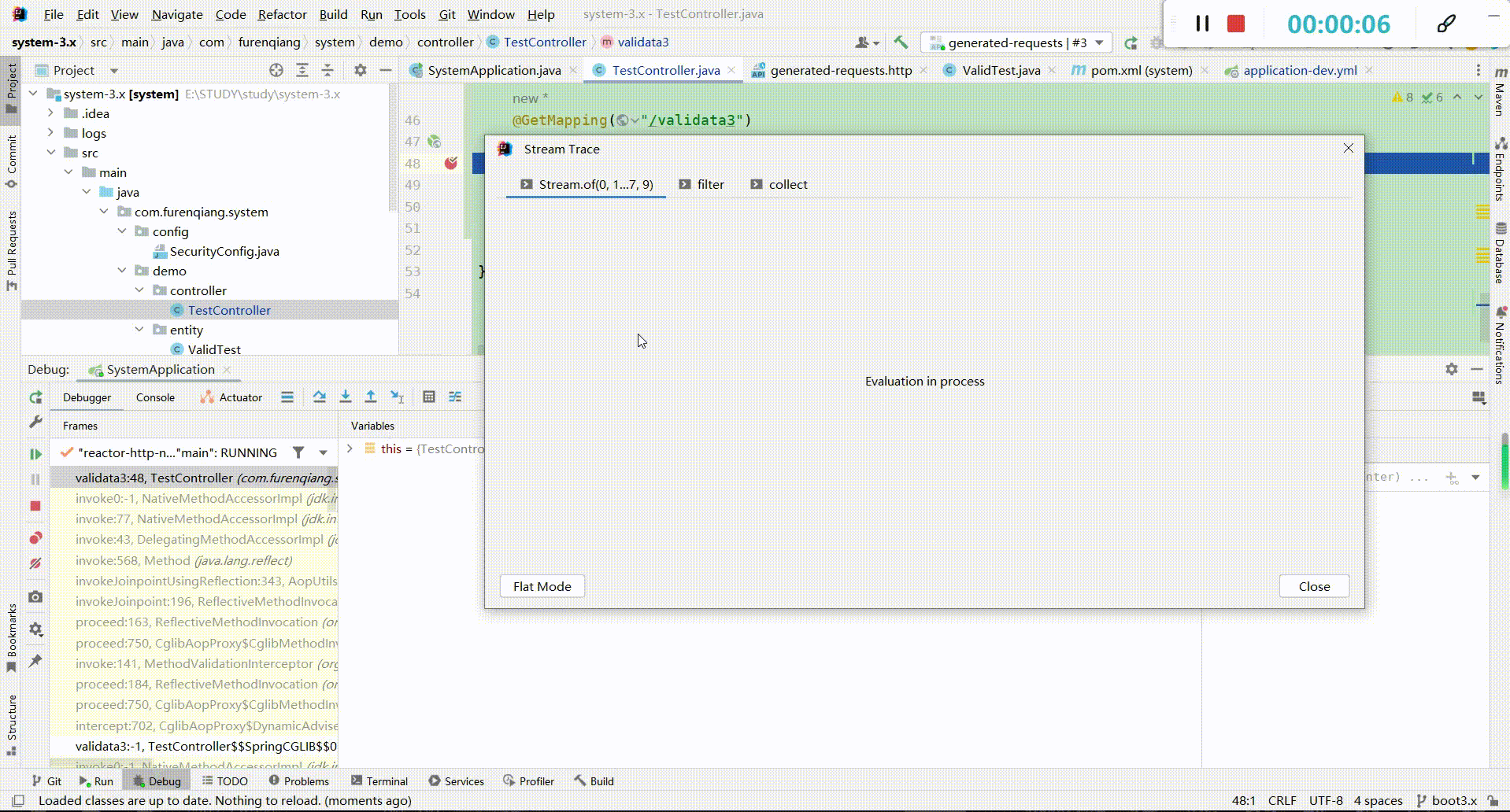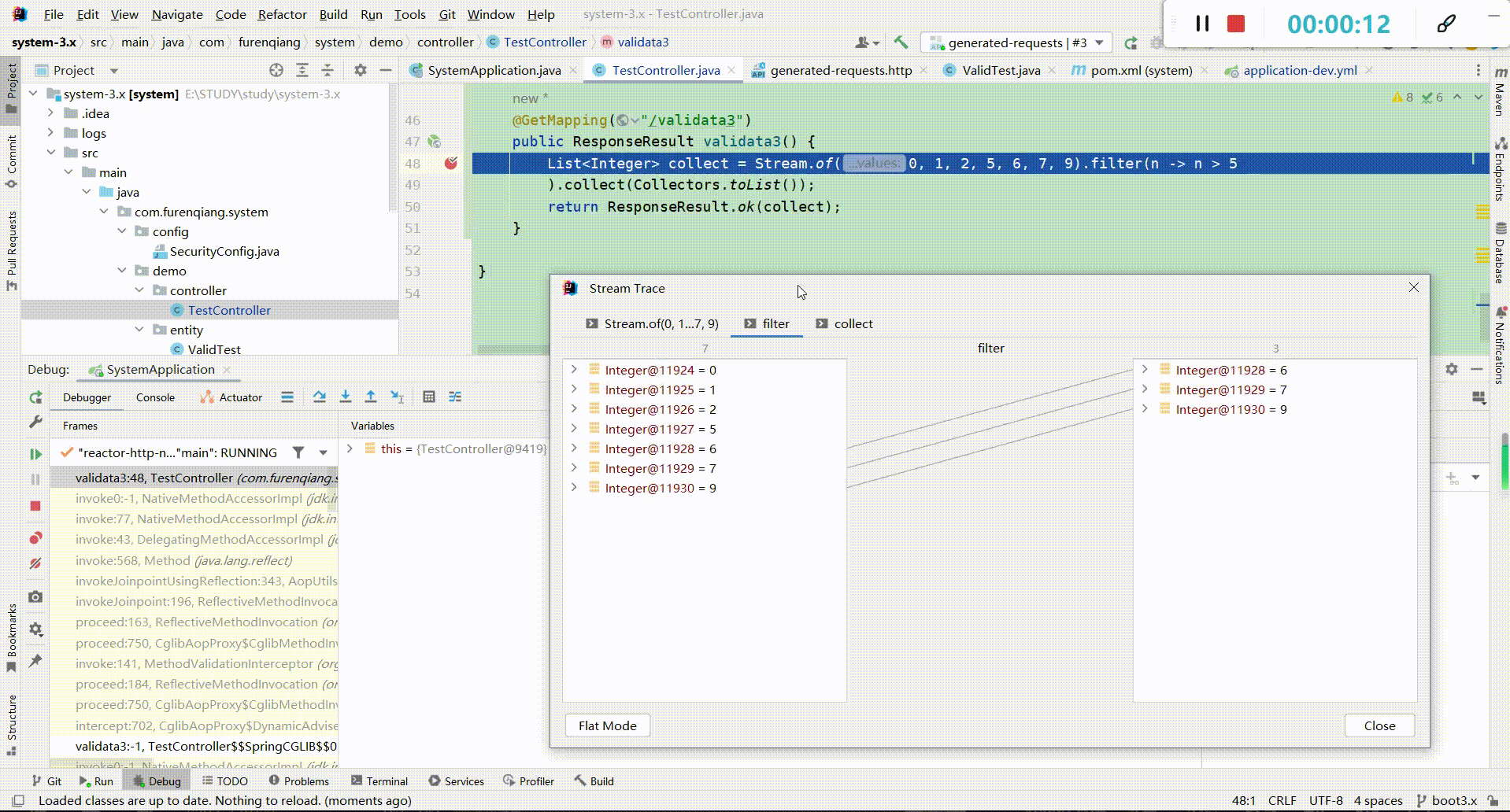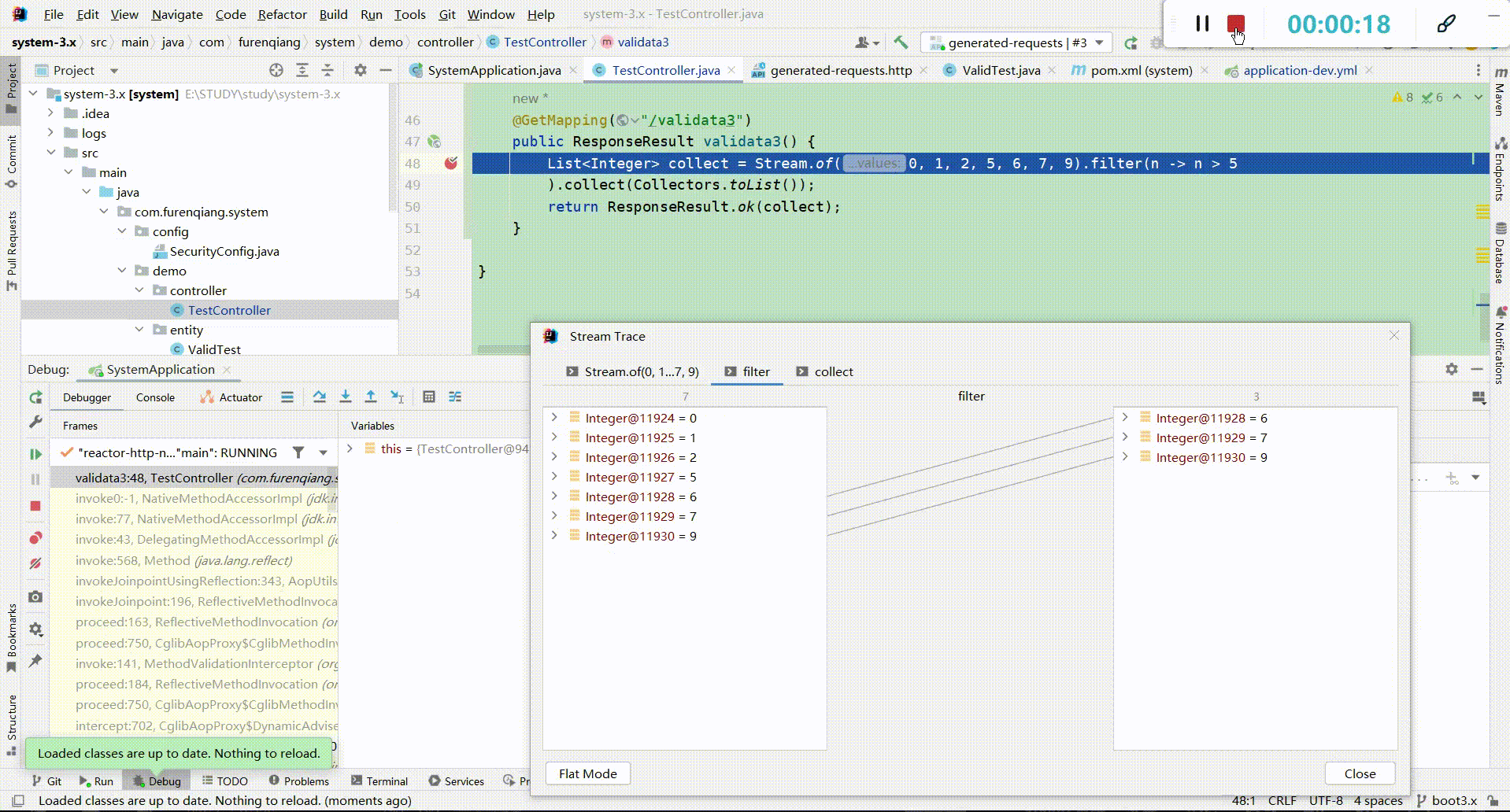
(4)、断点类型介绍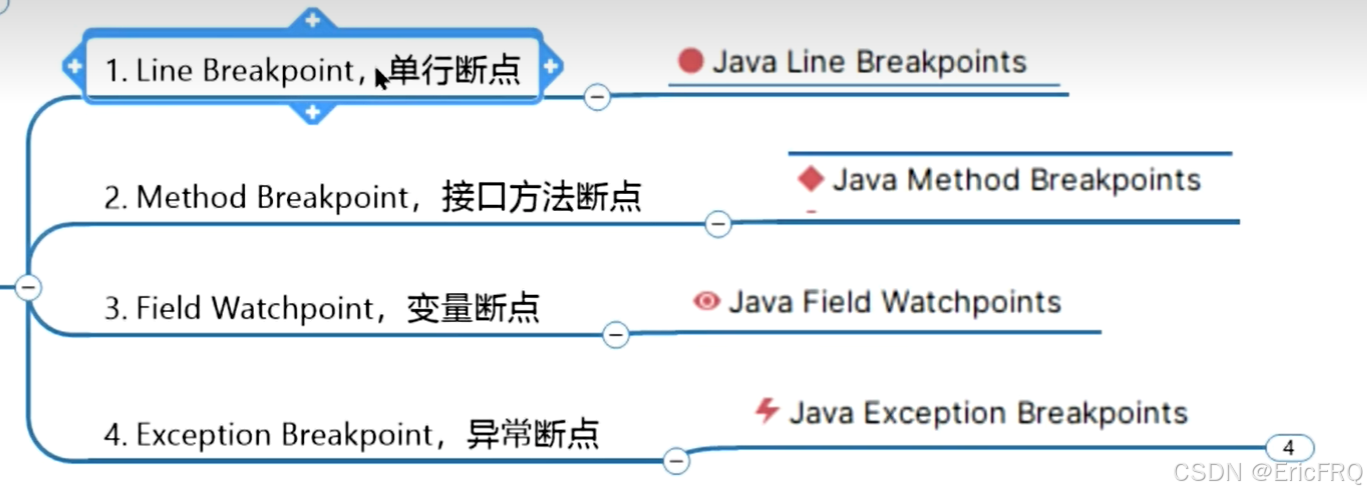
三、jUnit单元测试
1、
高阶-2025
一、数据库
1、数据库事务隔离级别
先了解下事务的特性ACID:原子性、隔离性、一致性、持久性

隔离性有四个隔离级别:mysql默认为重复读。Oracle、pgsql默认为读已提交read committed。
1、读未提交:会导致脏读,例如事务A修改未提交,B读。可设置事务隔离级别为读已提交解决,这时事务B只能查询已提交的事务。
2、不可重复读:A事务查询数据1,B事务修改数据1为2,A事务再查数据1发现值为2,前后不一致。可设置事务隔离级别为可重复读。A事务执行期间禁止其他事务操作数据1。
3、幻读。事务A争对整个表进行统计和汇总时,事务B插入了一条记录,A再次统计发现前后不一致。可设置事务隔离级别为串行化来解决。即事务A统计表的时候会给表加个表锁
2、数据库的MVCC
了解完事务隔离级别后再来看MVCC。
MVCC 是一种并发控制技术,用于在数据库中实现高效的事务处理,特别是在高并发环境下。MVCC 的核心思想是通过为数据创建多个版本,允许事务在不锁定数据的情况下读取数据的多个版本,从而提高并发性能。
(1)工作原理
数据版本:
每次数据被修改时,数据库会创建一个新的版本,保留旧版本。
每个版本都有一个唯一的版本号或时间戳。
(2)读操作:
事务读取数据时,会根据事务的隔离级别和开始时间选择合适的数据版本。
对于 Read Committed,事务只能读取已提交的数据版本。
对于 Repeatable Read,事务在整个事务期间读取相同的数据版本,确保数据一致性。
(3)写操作:
事务写入数据时,会创建一个新的数据版本,而不会直接覆盖旧版本。
旧版本保留,以便其他事务可以读取。
(4)垃圾回收:
旧版本的数据在不再需要时会被垃圾回收机制清理,以节省存储空间。
(5)优势
高并发:MVCC 允许多个事务同时读取数据,而不需要锁定数据,从而提高并发性能。
减少锁定:通过数据版本管理,MVCC 减少了传统锁定机制带来的性能开销。
数据一致性:在不使用锁定的情况下,MVCC 仍能保证事务的隔离性和数据一致性。
假设有一个简单的数据库表 accounts,包含以下数据:
| id | balance |
|---|---|
| 1 | 100 |
| 2 | 200 |
事务 A 开始读取 accounts 表。
事务 B 修改 accounts 表中的 balance 字段。
事务 A 再次读取 accounts 表时,仍能看到原始数据版本,而不会看到事务 B 的修改。
事务 B 提交后,新的数据版本成为可见版本。
通过 MVCC,事务 A 和事务 B 可以在不互相阻塞的情况下并发执行,从而提高系统的整体性能。
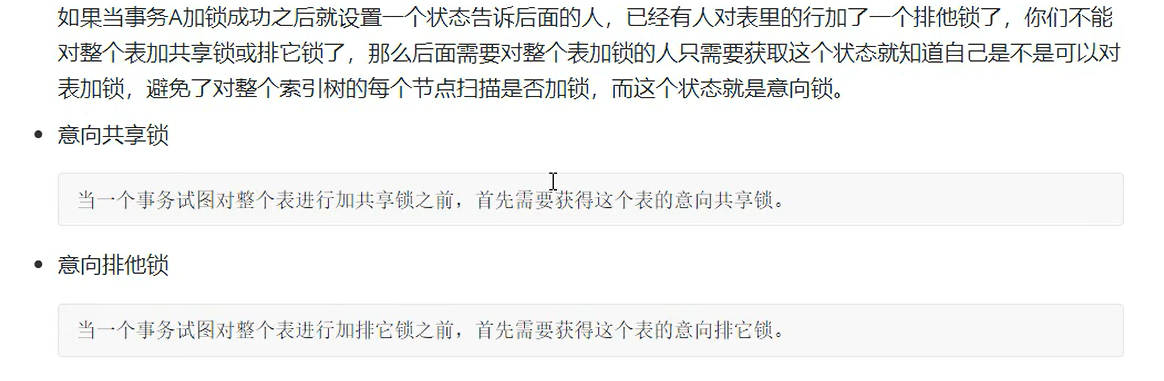
3、mysql的锁

4、mysql主从同步


5、mysql索引myisam和innodb的区别


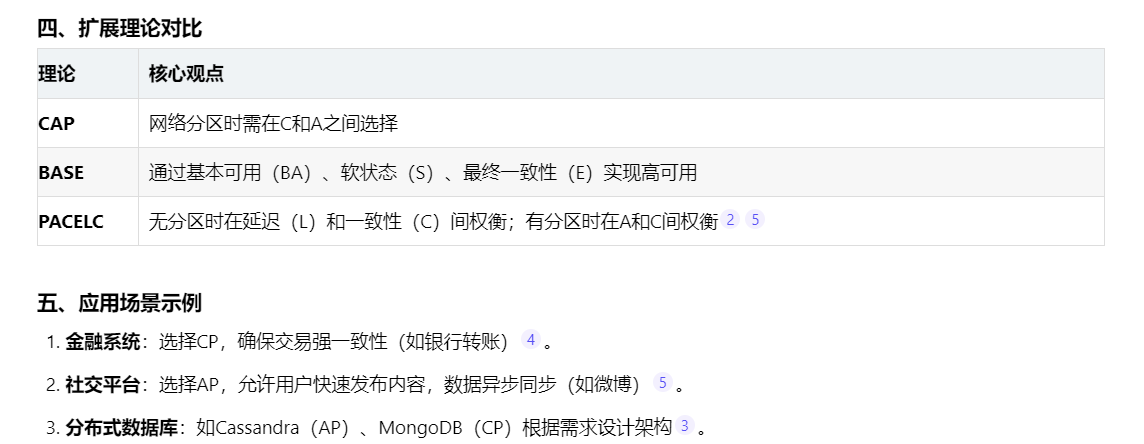
6、CAP
CAP理论是分布式系统设计的核心原则,指出在一致(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)三者中,系统最多只能同时满足两项,无法三者兼得。
- 一致性:所有节点在同一时间的数据完全一致,即每次读操作都能获取最新写入结果。
- 可用性:系统在有限时间内响应请求,且不会返回错误或超时。
- 分区容错性:系统在网络分区(节点间通信中断)时仍能继续运行。
假设网络分区(P)不可避免,系统必须在C和A之间权衡:
CP系统:优先保证一致性与分区容错性。例如,数据库在同步数据时加锁,导致暂时不可用。
AP系统:优先保证可用性与分区容错性。例如,Redis主从架构允许从节点在故障时接管服务,但可能短暂返回旧数据。
弱化一致性:采用最终一致性(如BASE理论),允许数据短暂不一致但最终同步。
降低可用性要求:在关键操作(如支付)中,通过加锁或事务保证强一致性。
动态调整:PACELC定理指出,即使无分区,系统仍需在延迟(Latency和一致性之间权衡。例如,高并发场景可能优先降低延迟,容忍短暂不一致。

















 2214
2214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









