




 本文介绍使用PaddlePaddle框架训练5-gram模型的过程,通过N-gram预测下一个词,涉及词向量、embedding、神经网络等关键技术。
本文介绍使用PaddlePaddle框架训练5-gram模型的过程,通过N-gram预测下一个词,涉及词向量、embedding、神经网络等关键技术。
词向量
本文是学习博客,转载自百度paddle框架的学习文档,代码自己敲了一遍,会有一点改动。


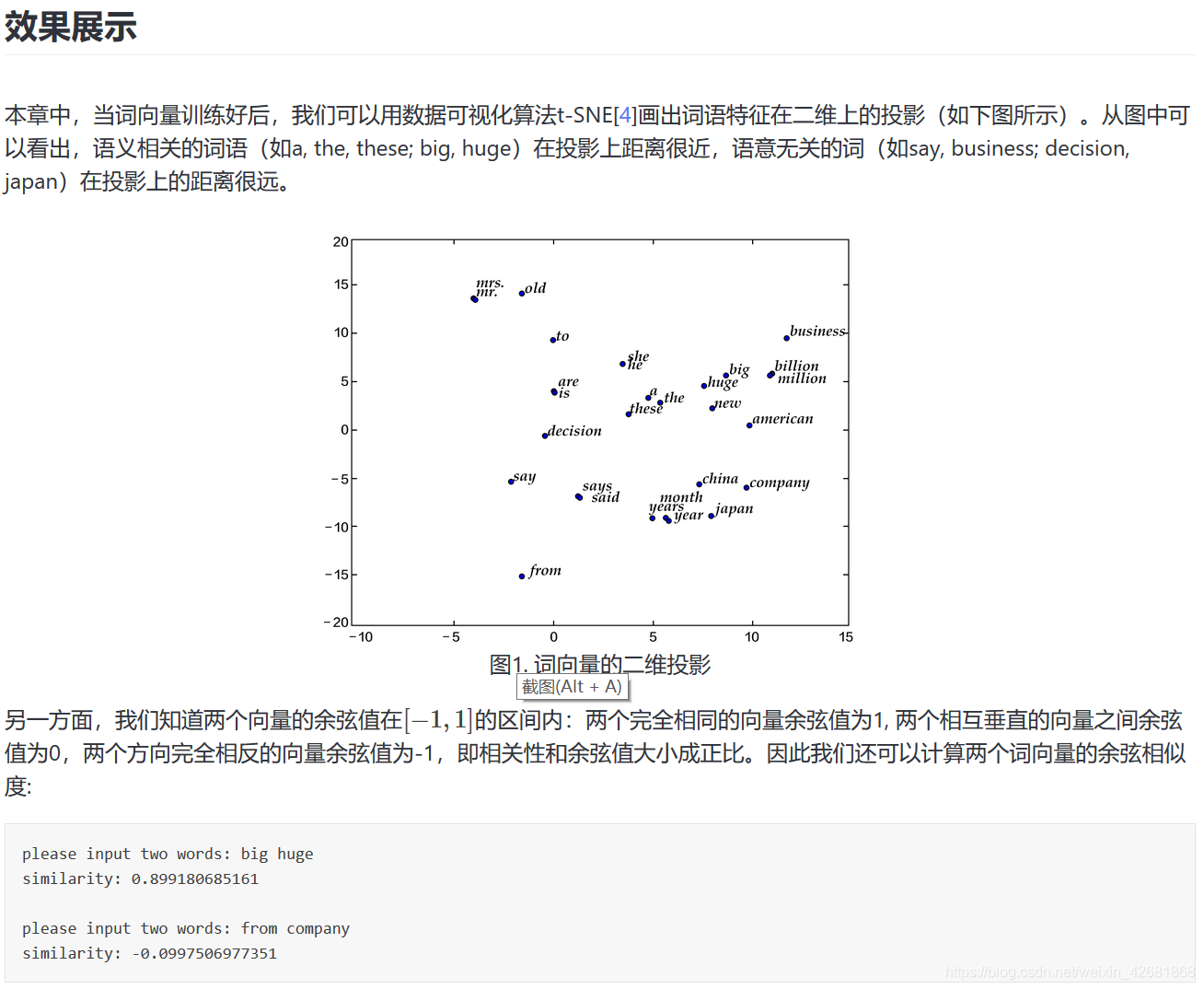



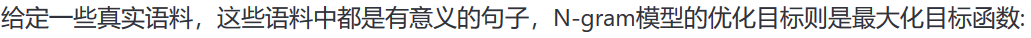
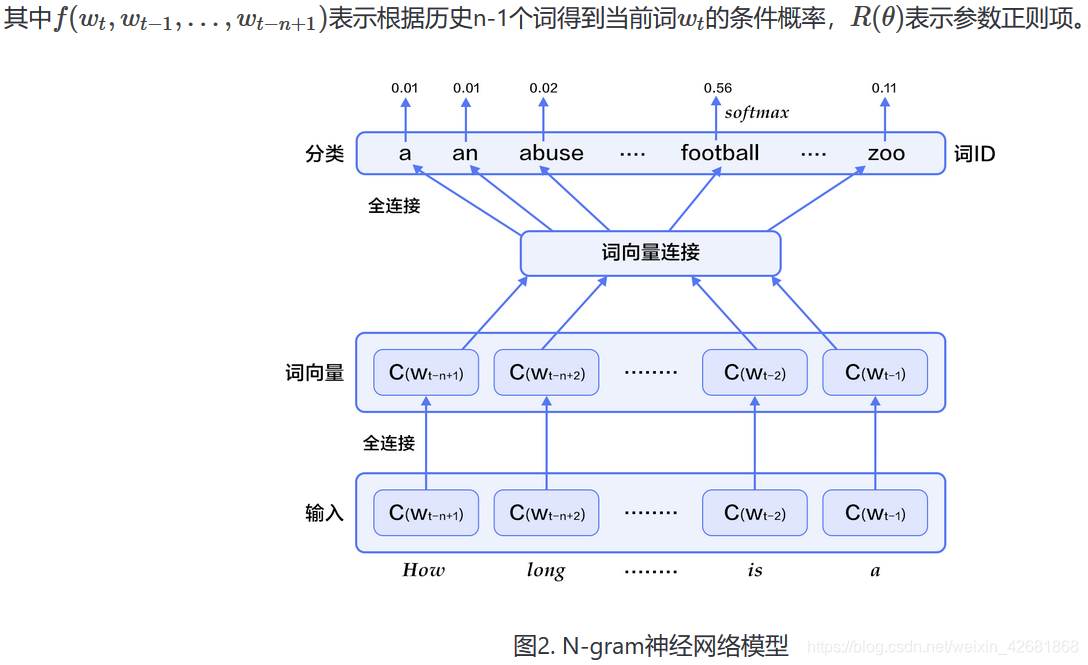


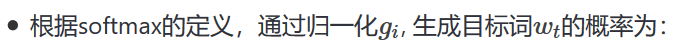

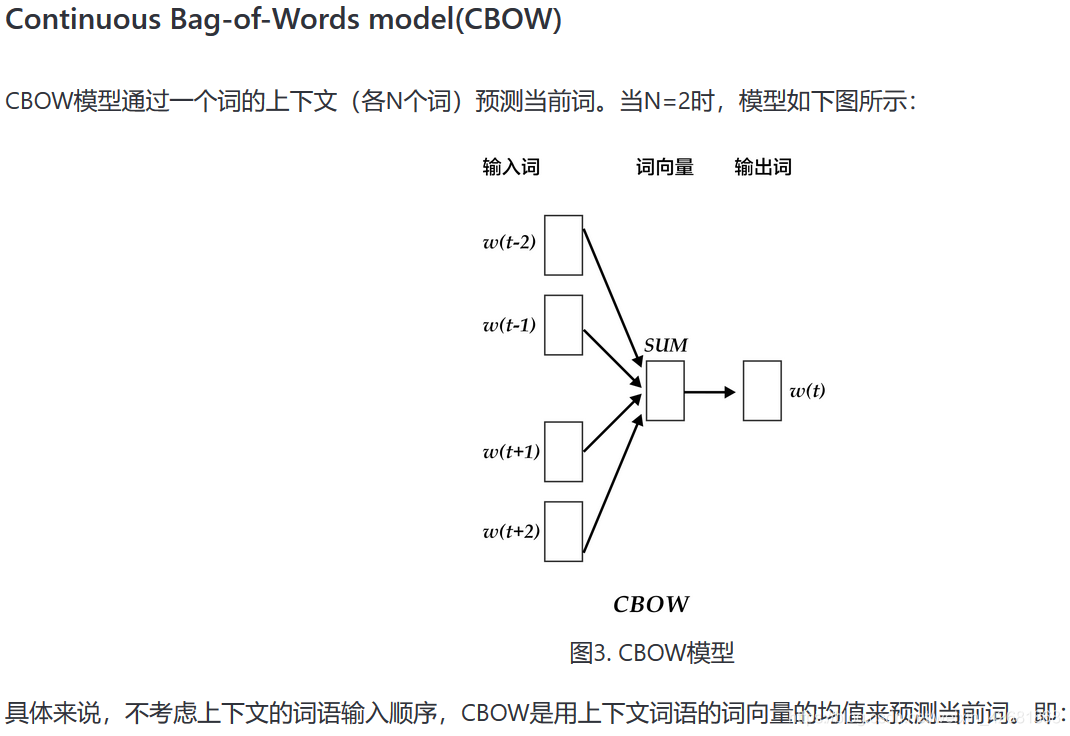
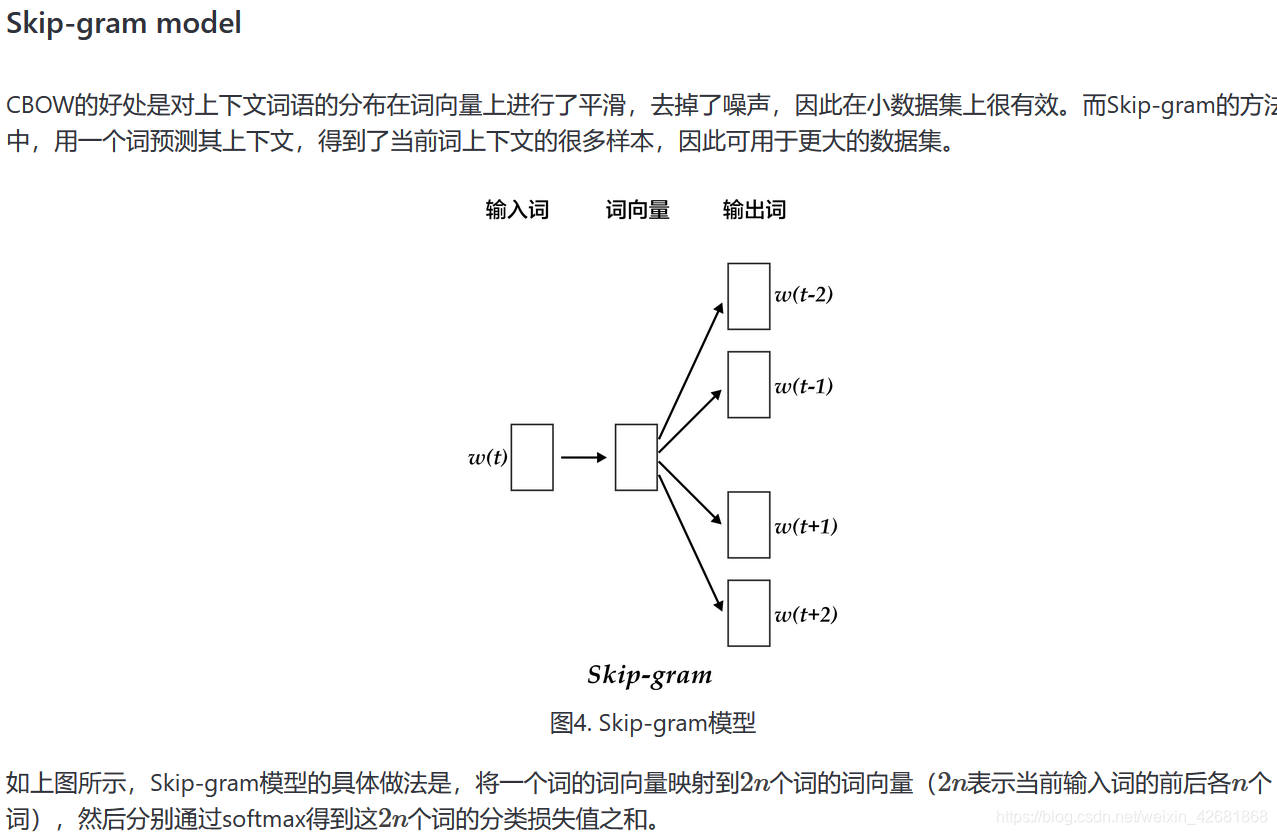
# 本次使用本章训练的是5-gram模型,表示在PaddlePaddle训练时,每条数据的前4个词用来预测第5个词。
import paddle as paddle
import paddle.fluid as fluid
import numpy as np
import math
EMBED_SIZE = 32 # embedding维度
HIDDEN_SIZE = 256 # 隐层大小
N = 5 # N-gram大小 ,这里固定取5
BATCH_SIZE = 100 # batch大小
PASS_NUM = 100 # 训练轮数
word_dict = paddle.dataset.imikolov.build_dict()
dict_size = len(word_dict)
def inference_program(words,is_sparse):
embed_first = fluid.layers.embedding(
input=words[0],
size=[dict_size, EMBED_SIZE],
dtype='float32',
is_sparse=is_sparse,
param_attr='shared_w')
embed_second = fluid.layers.embedding(
input=words[1],
size=[dict_size, EMBED_SIZE],
dtype='float32',
is_sparse=is_sparse,
param_attr='shared_w')
embed_third = fluid.layers.embedding(
input=words[2],
size=[dict_size, EMBED_SIZE],
dtype='float32',
is_sparse=is_sparse,
param_attr='shared_w')
embed_fourth = fluid.layers.embedding(
input=words[3],
size=[dict_size, EMBED_SIZE],
dtype='float32',
is_sparse=is_sparse,
param_attr='shared_w')
concat_embed = fluid.layers.concat(
input=[embed_first, embed_second, embed_third, embed_fourth], axis=1)
hidden1 = fluid.layers.fc(
input=concat_embed, size=HIDDEN_SIZE, act='sigmoid')
predict_word = fluid.layers.fc(input=hidden1, size=dict_size, act='softmax')
return predict_word
def train_program(predict_word):
# 'next_word'的定义必须要在inference_program的声明之后,
# 否则train program输入数据的顺序就变成了[next_word, firstw, secondw,
# thirdw, fourthw], 这是不正确的.
next_word = fluid.layers.data(name='nextw', shape=[1], dtype='int64')
cost = fluid.layers.cross_entropy(input=predict_word, label=next_word)
avg_cost = fluid.layers.mean(cost)
return avg_cost
def optimizer_func():
return fluid.optimizer.AdagradOptimizer(
learning_rate=3e-3,
regularization=fluid.regularizer.L2DecayRegularizer(8e-4))
def train(params_dirname,is_sparse):
#设置运行环境
place = fluid.CPUPlace()
#下载数据并建立批处理读取器
train_reader = paddle.batch(
reader = paddle.dataset.imikolov.train(word_dict, N),
batch_size = BATCH_SIZE
)
test_reader = paddle.batch(
reader=paddle.dataset.imikolov.test(word_dict, N),
batch_size=BATCH_SIZE
)
#建立词数据的张量层
first_word = fluid.layers.data(name='firstw', shape=[1], dtype='int64')
second_word = fluid.layers.data(name='secondw', shape=[1], dtype='int64')
third_word = fluid.layers.data(name='thirdw', shape=[1], dtype='int64')
forth_word = fluid.layers.data(name='fourthw', shape=[1], dtype='int64')
next_word = fluid.layers.data(name='nextw', shape=[1], dtype='int64')
word_list = [first_word, second_word, third_word, forth_word, next_word]
feed_order = ['firstw', 'secondw', 'thirdw', 'fourthw', 'nextw']
#设置运行过程(参数)
main_program = fluid.default_main_program()
start_program = fluid.default_startup_program()
#设置predict计算模型
predict_word = inference_program(word_list, is_sparse)
avg_cost = train_program(predict_word)
test_program = main_program.clone(for_test=True)
#设置优化函数
sgd_optimizer = optimizer_func()
sgd_optimizer.minimize(avg_cost)
exe = fluid.Executor(place)
def train_test(program,reader):
cont = 0
def train_loop():
step = 0
feed_var_list_loop = [
main_program.global_block().var(var_name) for var_name in feed_order
]
feeder = fluid.DataFeeder(feed_list=feed_var_list_loop, place=place)
exe.run(start_program)
for pass_id in range(PASS_NUM):
for data in train_reader():
avg_cost_np = exe.run(
main_program, feed=feeder.feed(data), fetch_list=[avg_cost])
if step % 10 == 0:
print(avg_cost_np)
train_loop()
def main():
is_sparse = True
params_dirname = r'D:\pro\paddlepaddle\result_train\word2vec.inference.model'
train(params_dirname,is_sparse)
if __name__ == '__main__':
main()

















 413
413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









