




 NFS是网络文件系统,允许客户端通过网络访问服务器端文件。NFS分为多个版本,从无状态的NFSv2到有状态的NFSv4。客户端通过RPC与服务端通讯,依赖于111端口获取服务端NFS功能端口。无状态协议意味着每次请求都包含完整信息,避免因服务端崩溃导致的依赖问题。文件句柄是关键,包含卷标识符、inode号和世代号以唯一标识文件。NFS缓存存在于客户端和服务端,可能导致一致性问题,通过关闭时刷新和读取文件属性来解决。
NFS是网络文件系统,允许客户端通过网络访问服务器端文件。NFS分为多个版本,从无状态的NFSv2到有状态的NFSv4。客户端通过RPC与服务端通讯,依赖于111端口获取服务端NFS功能端口。无状态协议意味着每次请求都包含完整信息,避免因服务端崩溃导致的依赖问题。文件句柄是关键,包含卷标识符、inode号和世代号以唯一标识文件。NFS缓存存在于客户端和服务端,可能导致一致性问题,通过关闭时刷新和读取文件属性来解决。
前文
linux-nfs文件系统全称是Network File System,即网络文件系统,是一种分布式系统。它的作用是允许客户端主机可以访问访问服务器端文件,并且其过程与访问本地存储时一样,它由Sun微系统(已被甲骨文公司收购)开发,于1984年发布。它的实现是基于RPC,依托UDP/TCP协议达成。
&esmp; nfs文件系统当前共4个大版本:
- NFSv1,在SUN公司内部用作实验目的
- NFSv2,1985年发布,它定义了NFS是无状态协议,定义了文件锁,缓存&缓存一致性
- NFSv3,1995年发布,它在NFSv2上进行了大量的功能和性能的优化,详见wiki
- NFSv4,2000年发布,最主要的特性是其将无状态协议变成有状态协议。接着是10年的v4.1,16年的v4.2
网络上的nfs文件系统相关博客都是千篇一律的教你如何搭建,实际上搭建永远是最简单的,了解并掌握它的由来,它的原理和实现,以及对应的应用才是最重要的。试着回答下面几个问题:
- NFS主要用于解决什么?什么场景下我们会用到NFS?
- 客户端是如何实现文件系统的访问的?是通过RPC实时访问,亦或是RPC实时同步数据到客户端?
- NFS里的无状态协议是什么?为什么要无状态?以及缓存是指客户端还是服务端?缓存一致性又是如何实现的?
- …
相关文献
NFS的相关文献这里推介三篇:
- NFS wiki:https://zh.wikipedia.org/wiki/%E7%BD%91%E7%BB%9C%E6%96%87%E4%BB%B6%E7%B3%BB%E7%BB%9F
- 鸟哥的私房菜-NFS的原理和搭建:http://cn.linux.vbird.org/linux_server/0330nfs.php#What_NFS_0
- 操作系统导论-NFS相关:https://hjk.life/assets/pdf/%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F%E5%AF%BC%E8%AE%BA/48%20Network%20File%20System%20(NFS).pdf
这三篇看完,掌握NFS即不再是问题。关于前文的问题,都能在其中找到对应的答案。
原理
NFS作为分布式文件系统,一般可用于解决分布式服务、数据共享等功能,比如Elasticsearch的快照备份&恢复,可以利用NFS挂载服务端的备份目录,客户端访问该备份目录进行实时的备份恢复;比如Gitlab的分布式搭建,在Gitlab 13.0版本之前,未引入Gitaly cluster时,用NFS做仓库数据的挂载目录,多个实例主机访问该仓库目录实现分布式服务搭建;再比如,web服务通过NFS系统存储上传文件,同步到服务器所在目录,就能做到直接访问自己服务器文件目录,降低了开发难度。
明白了NFS的应用场景,那客户端究竟是如何访问服务端的?这里引用鸟哥的私房菜里NFS一文来解释,因为NFS的实现是依赖于RPC,所以客户端和服务端的通讯也是基于RPC,但NFS的功能很多,不同的功能对应的服务端不同端口,而这些端口默认是小于1024的随机端口,那么在客户端初始访问时是未知服务端对应端口的,于是第一步是要请求到不同NFS功能对应的端口。此时就要用到约定俗成的111端口了(RPC的端口,NFS的服务端口是2049),作为服务端RPC的默认端口提供给客户端访问得到所有NFS功能的端口,接着再根据所需功能和服务端进行通讯。
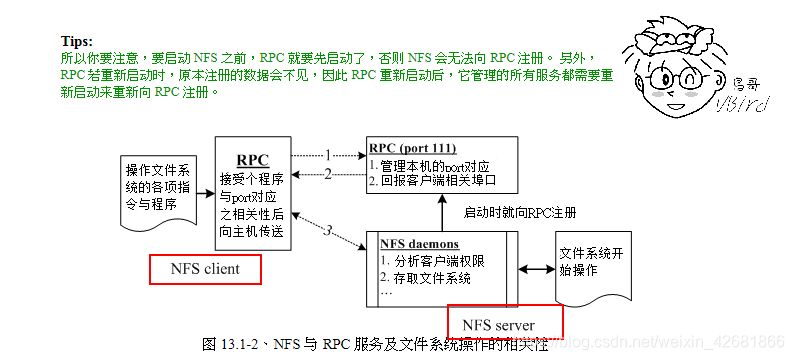
归纳为三步:
- 客户端向服务器端的 RPC (port 111) 发出 NFS 文件存取功能的询问要求;
- 服务器端找到对应的已注册的 NFS daemon 端口后,会回报给客户端;
- 客户端了解正确的端口后,就可以直接与 NFS daemon 来联机。
通过上面的描述,我们明白服务端的各类端口是不定的,那linux的防火墙规则该如何设置?我总不能将小于1024的端口全部开放吧,那就等着大量的病毒攻击吧!因为NFS多数对内网开放,所以遭受攻击的概率较低;另外像Centos提供了对应的专门服务于NFS的防火墙规则,实现上只要执行下面语句即可:firewall-cmd --permanent --add-service=nfs。
讲完防火墙规则,我们还需了解的是客户端不同权限的人是如何访问服务端文件的,抛开nfs单独轮操作系统的文件访问,是通过UID、GID以及读写权限(即rwx相关)控制的,那客户端访问服务端二者UID并不是相同的,rwx倒是可以以服务端的为准。简单来说,如果是客户端的root,那么在服务端后也能以root的身份访问吗?答案是:可以也不可以,因为NFS可以配置规则来定义是否可以。其余的几种情况比如客户端有该用户而服务端没有,客户端和服务端对应UID的用户不同等等,以及读写权限的配置参见鸟哥的私房菜即可。
缓存和无状态
nfs的无状态
这里主要参考操作系统导论。首先什么是无状态,很简单,http协议就是无状态的,所以我们在web上每次鼠标的点击请求都是会携带所有所需的参数,比如我们要查询用户信息,那在这次查询上肯定会带上userid,而服务端根据userid查询数据库得到该用户的信息。同理可得,在nfs这边也是如此,假如我用vim /home/foo.txt,然后写入aaaa,如果是有状态协议,则第一次会传输我要访问home目录下的foo.txt,第二次传输就是写入aaaa,如果这之间断开连接,则第二次传输服务端就无法识别是哪个文件;无状态协议,则每次都会传输完整的文件句柄和操作内容。
为什么要无状态?原因是因为如果服务端奔溃、客户端和服务端网络丢失等发生的话,有状态服务就会因为信息丢失而致使依赖的步骤失败,所以才要每个步骤都是独立的。
理解 NFS 协议设计的一个关键是理解文件句柄(file handle)。文件句柄用于唯一地描述文件或目录。因此,许多协议请求包括一个文件句柄。可以认为文件句柄有 3 个重要组件:卷标识符、inode 号和世代号。这 3 项一起构成客 户希望访问的文件或目录的唯一标识符。卷标识符通知服务器,请求指向哪个文件系统(NFS 服务器可以导出多个文件系统)。inode 号告诉服务器,请求访问该分区中的哪个文件。最后, 复用 inode 号时需要世代号。通过在复用 inode 号时递增它,服务器确保具有旧文件句柄的 客户端不会意外地访问新分配的文件。
每次客户端通过LooKup协议请求文件句柄时,服务端会将文件句柄+文件属性一起返回给客户端;属性就是文件系统追踪每个文件的元信息,包括文件创建时间、上次修改时间、大小、 所有权和权限信息等,即对文件调用 stat()会返回的信息。
客户端的操作在nfs这边大多数都是幂等性的,所以服务端崩溃重启后很多操作是无影响。除了像mkdir这类的,当文件已存在时,服务端崩溃重启时则会通过报错来体现。
nfs缓存一致性问题
根据前面所说nfs的缓存会同时存在客户端和服务端(这个缓存同时包含write缓存,这样当客户端修改的时候,可以很快返回响应,将write的内容缓存到内存中,随后再发给服务端),而服务端还好,因为写操作服务端感知到通过系统调用可以刷新缓存;但是客户端上修改,就会因为网络等原因出现和服务端不一致的情况,这会导致两个问题:
- A客户端修改了内容缓存了未发给服务端;但是B客户端此时读取服务端的则是旧内容
- A客户端修改的内容发给服务端并修改了服务端的内容;但是B客户端因为缓存在,仍旧读取到的是旧内容
解决方案:
- 针对上述1,通过关闭时刷新来解决,只要A客户端更新完后关闭文件,就立马发送给服务端
- 针对上述2,通过读取文件属性来确认文件是否被更新,比如B客户端每次使用缓存的前提是GETATTR确认文件属性是否一致。
总结
关于原理就介绍到这,搭建相对就简单多了,这个后续再单独开篇来说。


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









