







combineByKey 算子是一个稍微复杂的算子,所以在这里记录一下 combineByKey 的操作方式。
combineByKey 的参数
combineByKey 总共有三个参数
- 第一个参数是对相同分区,相同 key 的第一个 value 进行初始化。
- 第二个参数是对相同分区,相同 key 的 values 进行的操作。
- 第三个参数是对不同分区,相同 key 的 values 进行的操作。
举个栗子🌰
val conf = new SparkConf().setMaster("local").setAppName("test")
val sc = new SparkContext(conf)
val groupByte = Array(
("Gerald", 99.0), ("Gerald", 98.0), ("Gerald", 99.5),
("Seligman", 95.0), ("Seligman", 96.0), ("Seligman", 97.0)
)
val value: RDD[(String, Double)] = sc.parallelize(groupByte)
val rdd = value
rdd.combineByKey(
x => {
println(s"第一个 key 的初始化 $x");
x
},
(score: Double, otherScore: Double) => {
println(s"2 ---> $score + $otherScore")
score + otherScore
},
(partition: Double, otherPartition: Double) => {
println(s"3 ---> $partition + $otherPartition")
partition + otherPartition
}
).collect.foreach(println)
sc.stop()
运行结果:
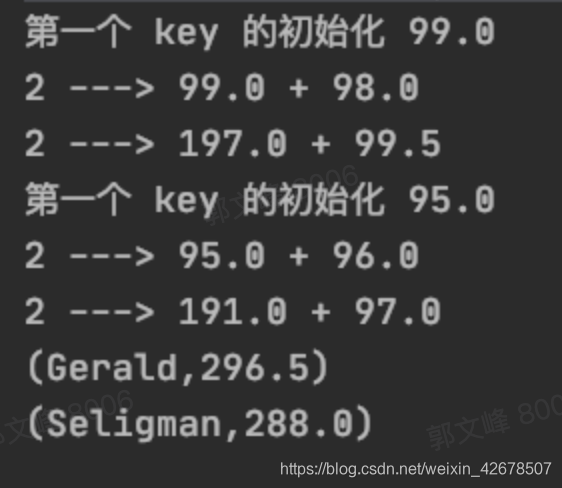
解释:
- 从结果可以看出,第一个参数只会发生在每一组 key 的第一个 key 的 value 上。
- 第二个参数就是对相同分区,相同 key 的 values 进行作用。
- 因为没有对数据进行分区,所以第三个参数没有用到。
对数据分区来看看
val conf = new SparkConf().setMaster("local").setAppName("test")
val sc = new SparkContext(conf)
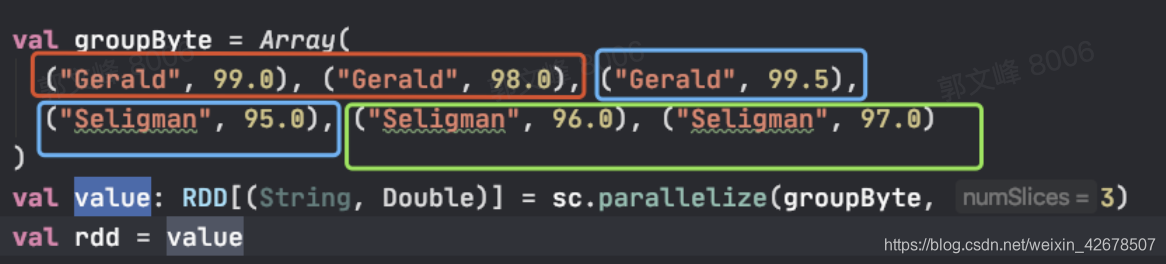
val groupByte = Array(
("Gerald", 99.0), ("Gerald", 98.0), ("Gerald", 99.5),
("Seligman", 95.0), ("Seligman", 96.0), ("Seligman", 97.0)
)
val value: RDD[(String, Double)] = sc.parallelize(groupByte, 3)
val rdd = value
rdd.combineByKey(
x => {
println(s"第一个 key 的初始化 $x");
x
},
(score: Double, otherScore: Double) => {
println(s"2 ---> $score + $otherScore")
score + otherScore
},
(partition: Double, otherPartition: Double) => {
println(s"3 ---> $partition + $otherPartition")
partition + otherPartition
}
).collect.foreach(println)
sc.stop()
运行结果:
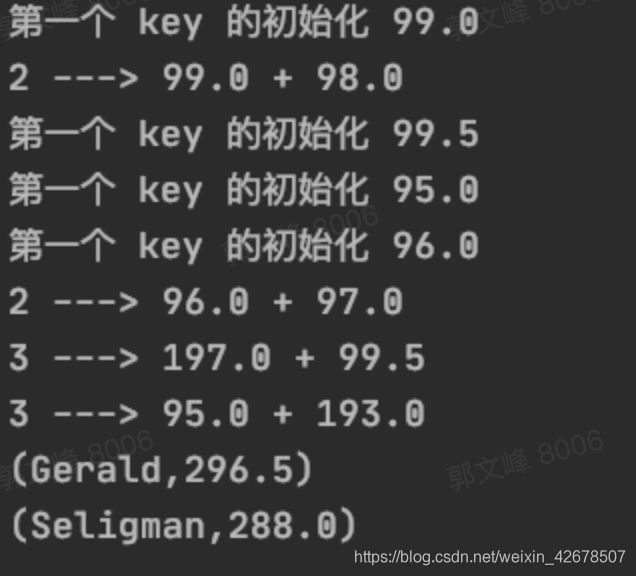
解释:
- 首先这次把数据划分成了三个分区,就是这样:
- 第一个参数发生了四次,分别是:
- 第一个分区发生了一次。
- 第二个分区发生了两次:因为第二个分区中有两个不同的 keys
- 第三个分区发生了一次。
- 第二个参数发生了两次,分别是:
- 第一个分区发生了一次。
- 第二个分区没有发生,因为第二个分区两个数据都是只有一组,没办法加。
- 第三个分区发生了一次
- 第三个参数发生了两次,分别是:
- 第一个分区的 Gerald 和第二个分区的 Gerald 之间的相加。
- 第二个分区的 Seligman 和第三个分区的 Seligman 之间的相加。
叮~🔔

















 542
542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









