







简介:本软件包旨在为企业简化大数据环境的部署与管理,提高数据质量、安全性和分析效率。它包含了关键组件如Hadoop、Spark、Hive等,以及实现自动化安装和数据治理的脚本和工具。课程设计将深入解析大数据概念、自动化安装、元数据管理、数据安全等核心知识,提供一套完整的解决方案以满足现代企业数据管理的需求。 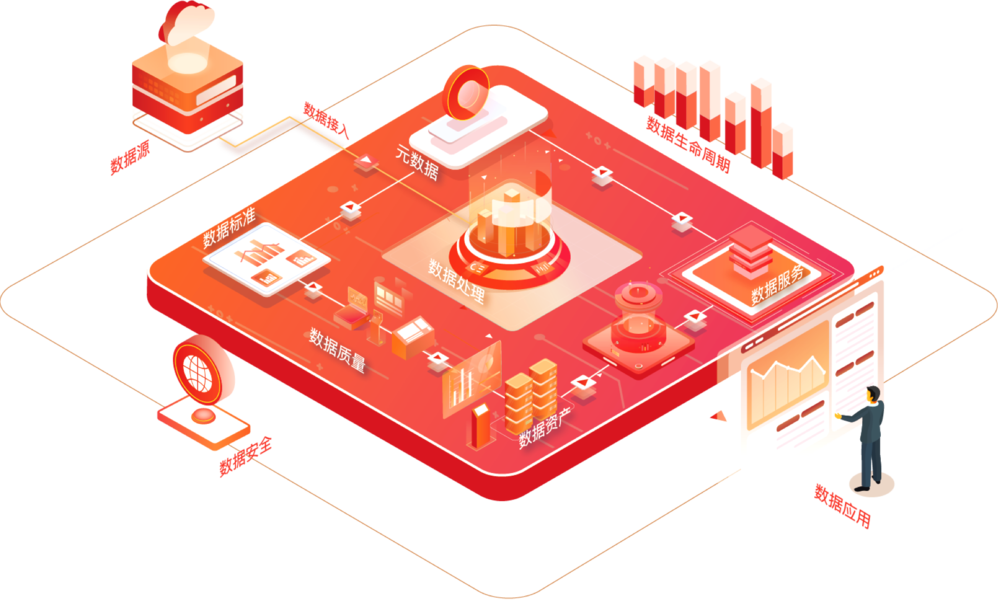
1. 大数据环境部署与管理优化
在当今信息爆炸的时代,大数据技术已成为企业获取竞争优势的关键。本章旨在为读者展示如何高效部署和管理大数据环境,使之能够支撑业务的快速发展并优化运维成本。
大数据技术栈的构成
大数据技术栈通常由多个组件构成,包括数据存储、数据处理、数据仓库以及数据可视化等。选择正确的技术对于确保系统的性能、可伸缩性和可靠性至关重要。
部署策略的选择
在部署大数据环境时,企业需要考虑以下策略: - 云服务 : 灵活、可扩展的云基础架构可减少前期投资,支持按需使用。 - 预配置解决方案 : 这种方案通常由硬件供应商提供,可以快速部署,但可能缺乏灵活性。 - 开源解决方案 : 虽然前期成本较低,但需要专业知识来集成和维护。
管理优化的关键点
管理优化主要围绕提高系统性能、降低运营成本以及增强数据安全三个核心目标展开。这要求运维团队能够有效监控系统状态,快速响应系统故障,并对系统进行定期的调优和升级。
实操示例
- 监控工具 : 使用开源工具如Prometheus和Grafana来实时监控系统资源使用情况和应用性能。
- 性能调优 : 根据监控数据调整集群配置,比如Hadoop的YARN资源管理器,以及Spark的内存和CPU分配。
- 成本控制 : 利用云服务的成本管理工具,比如AWS的Cost Explorer,来分析资源使用情况并优化云资源分配。
通过本章的探讨,读者应能掌握大数据环境部署的关键要素和管理优化的策略,为后续章节中关于数据质量和数据安全等更深入的讨论打下基础。
2. 数据质量与可用性提升
2.1 数据质量控制流程
2.1.1 数据清洗与预处理
数据清洗是数据预处理的一个重要环节,它主要涉及数据的检测和纠正工作,旨在提升数据的准确性和一致性。在大数据环境下,数据清洗通常包括去除重复数据、填补缺失值、纠正错误、处理异常值等。有效的数据清洗可确保数据质量,为后续的数据分析和挖掘提供可靠基础。
import pandas as pd
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OneHotEncoder, StandardScaler
# 示例数据集
data = pd.DataFrame({
'Age': [25, 33, 37, 39, 28, None, 27],
'Salary': [50000, 55000, None, 70000, 52000, 48000, 49000]
})
# 填补缺失值
age_imputer = SimpleImputer(strategy='mean')
age_imputed = age_imputer.fit_transform(data[['Age']])
salary_imputer = SimpleImputer(strategy='median')
salary_imputed = salary_imputer.fit_transform(data[['Salary']])
# 对分类数据进行独热编码
age_encoder = OneHotEncoder()
age_encoded = age_encoder.fit_transform(age_imputed.reshape(-1, 1)).toarray()
# 对数值数据进行标准化
salary_scaler = StandardScaler()
salary_scaled = salary_scaler.fit_transform(salary_imputed)
# 清洗后数据
cleaned_data = pd.DataFrame({
'Age': age_encoded,
'Salary': salary_scaled
})
以上代码展示了如何使用Python的pandas库和scikit-learn库对含有缺失值和需要进行分类编码的数据集进行清洗。其中, SimpleImputer 用于填补缺失值, OneHotEncoder 用于对分类变量进行编码处理, StandardScaler 用于数值特征的标准化。在清洗过程中,根据数据的类型和分布情况选择合适的策略是非常重要的。
2.1.2 数据质量评估方法
数据质量评估是指在数据清洗之后,对数据进行一系列的质量检查,确保数据达到了预设的质量标准。常用的评估方法包括数据分布分析、数据一致性和准确性检查、以及数据完整性的评估。
-- SQL示例:查询数据表中的重复记录数量
SELECT COUNT(*), column_names
FROM table_name
GROUP BY column_names
HAVING COUNT(*) > 1;
在SQL中,通过分组和计数的方式可以识别出表中的重复记录,有助于评估数据的一致性。而对于准确性评估,可以采用抽样检查的方式,或者实施逻辑一致性检查。完整性评估则涉及到检查数据记录的字段是否齐全,缺失值是否在可接受的范围内。
2.2 数据可用性保障技术
2.2.1 数据冗余与备份策略
数据冗余和备份是确保数据可用性的关键措施。数据冗余通过创建数据的副本,防止因系统故障而导致的数据丢失。而数据备份策略则需要制定详细的备份计划,包括选择合适的备份类型(全备份、增量备份、差异备份等)、备份频率、备份存储方式和备份数据的恢复流程。
graph LR
A[开始] --> B[确定备份范围]
B --> C[选择备份类型]
C --> D[设置备份时间点]
D --> E[执行备份操作]
E --> F[备份数据传输]
F --> G[备份数据存储]
G --> H[备份验证]
H --> I[备份记录]
I --> J[结束]
以上流程图展示了数据备份策略制定的基本步骤。每一步都至关重要,缺一不可。备份范围的确定需要考虑到业务需求和数据重要性。备份类型的选择依赖于数据恢复的需求和存储资源。备份时间点的设置需平衡备份窗口和数据保护的需要。数据传输和存储应保证数据的安全性和完整性。备份验证确保备份的有效性,而备份记录则为后期的恢复操作和审计提供依据。
2.2.2 数据恢复与灾难恢复机制
数据恢复是指在数据丢失或损坏后,将备份数据还原的过程。灾难恢复机制则是指一套系统的流程和策略,它保证在面临重大灾难(如地震、洪水、火灾等)导致的数据中心故障时,业务能迅速恢复。
### 数据恢复操作流程:
1. **评估损失**:首先需要评估数据丢失或损坏的程度。
2. **准备恢复**:准备好必要的备份数据和恢复工具。
3. **停止服务**:在确保数据安全的前提下,暂时停止相关服务。
4. **数据恢复**:使用备份数据和恢复工具进行数据恢复操作。
5. **验证数据**:验证恢复后的数据是否完整和一致。
6. **重启服务**:确保数据正确无误后,逐步重启相关服务。
7. **记录和分析**:记录整个恢复过程,分析原因并采取预防措施。
数据恢复操作的每个步骤都需要严格遵循,确保在面对数据丢失时,能以最小的损失和最快的速度恢复数据。灾难恢复机制则需要涉及灾难恢复计划制定、资源分配、演练培训和持续改进等多方面内容,以确保在真正灾难发生时,能够有效地执行。
数据质量和可用性是大数据环境下的核心问题,它们直接关系到数据资产的价值和数据驱动决策的有效性。通过上述措施和方法,可以大幅提升数据质量,并保障数据的高可用性。在下一章节中,我们将探讨如何通过有效的数据安全与合规性措施,确保数据安全和隐私保护。
3. 数据安全与合规性保障
随着大数据应用的飞速发展,数据安全与合规性成为企业关注的焦点。本章将深入探讨在大数据环境下,如何制定数据安全策略并确保隐私保护和法律法规的遵循。
3.1 数据安全策略与实践
3.1.1 数据加密与访问控制
为了确保数据在存储和传输过程中的安全性,数据加密是必不可少的措施。通过加密技术,即便数据被未经授权的个体截获,也无法被解读。加密技术的应用分为对称加密和非对称加密两种:
- 对称加密指的是使用相同的密钥进行数据的加密和解密。
- 非对称加密则涉及一对密钥,一个公钥用于加密数据,一个私钥用于解密。
而在实际应用中,应综合考虑加密算法的强度、系统性能开销以及密钥管理的复杂度。例如,AES(高级加密标准)因其高安全性和相对较好的性能,是广泛采用的对称加密算法。而RSA算法则是应用最广的非对称加密算法之一。
// 示例:AES加密解密代码块
import javax.crypto.Cipher;
import javax.crypto.KeyGenerator;
import javax.crypto.SecretKey;
import javax.crypto.spec.SecretKeySpec;
import java.security.SecureRandom;
// 密钥生成器
KeyGenerator keyGenerator = KeyGenerator.getInstance("AES");
keyGenerator.init(128, new SecureRandom());
SecretKey secretKey = keyGenerator.generateKey();
byte[] key = secretKey.getEncoded();
// AES加密
Cipher aesCipher = Cipher.getInstance("AES/ECB/PKCS5Padding");
SecretKeySpec secretKeySpec = new SecretKeySpec(key, "AES");
aesCipher.init(Cipher.ENCRYPT_MODE, secretKeySpec);
byte[] encryptedText = aesCipher.doFinal("This is the data to encrypt".getBytes());
// AES解密
// 注意:在实际中应确保IV的保密性
Cipher aesCipherDecrypt = Cipher.getInstance("AES/ECB/PKCS5Padding");
aesCipherDecrypt.init(Cipher.DECRYPT_MODE, secretKeySpec);
byte[] decryptedText = aesCipherDecrypt.doFinal(encryptedText);
在访问控制方面,实施基于角色的访问控制(RBAC)是常见的策略,能够限制用户根据其角色或职责范围访问数据。细致的权限管理有助于减少内部威胁和数据泄露的风险。
3.1.2 安全审计与合规性检查
安全审计是检查和评估系统、网络和应用的安全性并提供改进建议的过程。合规性检查则是确保企业遵循相关法律法规要求的过程。
审计可以通过日志审查、系统扫描、漏洞检测等多种方式执行。审计日志是追踪潜在入侵或内部滥用行为的关键证据。合规性检查一般包括:
- 对数据处理流程进行检查,确保其符合数据保护法规的要求,如欧盟的GDPR。
- 对数据存储和传输的安全措施进行评估,保证合规性。
-- 示例:审计日志查询
SELECT * FROM audit_logs WHERE event_time > '2023-01-01 00:00:00';
企业可以通过定期的合规性培训和更新安全策略来强化内部员工对数据保护法规的理解和遵守。
3.2 隐私保护与合规性要求
3.2.1 用户隐私保护政策
用户隐私保护政策是企业向用户明确其如何收集、使用和保护用户个人数据的声明。政策应涵盖以下要点:
- 数据收集的目的和范围
- 数据的使用方式和限制
- 数据共享和披露的条件
- 用户的权限和控制权
- 数据保护措施和安全流程
隐私政策应当透明、明确且易于用户理解,避免使用过于复杂或技术化的语言。
3.2.2 法律法规遵循与案例分析
企业应遵循所在国家或地区关于数据保护的法律法规,如美国加州的CCPA(加州消费者隐私法案),以及欧盟的GDPR。下面通过一个案例来分析合规性的重要性:
案例分析:合规性失误的后果
某在线零售商由于未遵守GDPR规定,导致大量个人数据泄露。在被监管机构发现后,该公司面临巨额罚款和声誉损失。此案例强调了企业必须对合规性给予足够的重视,不仅要从技术层面实现安全措施,还要从管理层面确保流程和策略的执行。
是大数据处理的基石之一。HDFS由NameNode和DataNode组成。NameNode负责管理文件系统的命名空间,维护文件系统树以及整个文件系统的元数据。DataNode则在集群中的各个节点上存储实际的数据。
在架构优化方面,HDFS的NameNode单点故障问题,可以通过启用High Availability(HA)模式解决。在HA模式下,有多个NameNode同时工作,其中一个处于活动状态,另一个处于热备份状态。当活动的NameNode发生故障时,热备份的NameNode会迅速接管,保证系统的高可用性。
为了提高数据的读写效率,数据本地化(Data locality)是一个重要的优化点。数据本地化是指尽量在数据存储的物理位置附近进行计算,减少数据在集群中的传输,以降低网络带宽的使用和提高处理速度。Hadoop社区通过引入YARN(Yet Another Resource Negotiator)进行资源管理和任务调度来优化资源利用率。
5.1.2 实际案例:HDFS在大数据环境中的应用
以一家大型电子商务公司为例,其利用HDFS存储海量商品数据和用户行为日志。通过合理配置HDFS块大小和副本策略,成功实现了快速读写大量数据和系统故障的快速恢复。具体操作如下:
- 修改HDFS配置文件
hdfs-site.xml中的dfs.replication参数设置为3,以保证数据的安全性和可靠性。 - 将HDFS块大小配置为128MB,以适应中等规模数据处理的需要,减少了NameNode内存的占用,同时也减少了NameNode和DataNode之间的通信次数。
5.2 Spark大数据处理框架
5.2.1 Spark核心组件介绍
Apache Spark是一个强大的集群计算系统,它提供了一个快速的分布式计算平台,支持多种数据处理模型,包括批处理、迭代算法、交互式查询和流处理。Spark的核心组件包括Spark Core、Spark SQL、Spark Streaming、MLlib和GraphX。
- Spark Core 提供了Spark的基本功能,包括任务调度、内存管理、错误恢复、与存储系统交互等。
- Spark SQL 用于处理结构化数据,支持SQL查询和Hive表。
- Spark Streaming 用于处理实时数据流。
- MLlib 是机器学习算法库。
- GraphX 用于图形处理和图并行计算。
5.2.2 Spark性能调优与故障排除
在使用Spark进行大数据处理时,性能调优和故障排除是两个关键的环节。性能调优通常包括资源分配、内存管理、网络调优等方面。例如:
- 在资源分配方面,需要合理配置集群的
spark.executor.memory和spark.executor.cores参数,以避免内存溢出或CPU资源浪费。 - 在内存管理方面,可以启用
spark.memory.fraction和spark.memory.useLegacyMode参数,进行精细控制。 - 对于网络问题,可以通过调节
spark.executor Shuffle Service参数来优化Shuffle过程中的网络IO。
故障排除时,监控日志文件是关键。Spark的日志信息能够反映作业的运行状况和故障原因。此外,使用Spark UI监控作业运行的实时性能指标也是一种常见的诊断手段。
通过这些优化和排错方法,可以大大提高Spark作业的执行效率,确保大数据处理任务的顺利完成。
简介:本软件包旨在为企业简化大数据环境的部署与管理,提高数据质量、安全性和分析效率。它包含了关键组件如Hadoop、Spark、Hive等,以及实现自动化安装和数据治理的脚本和工具。课程设计将深入解析大数据概念、自动化安装、元数据管理、数据安全等核心知识,提供一套完整的解决方案以满足现代企业数据管理的需求。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









