









 本文介绍如何使用Apache Spark读取HBase数据,通过配置Spark应用程序、设置HBase连接参数及扫描过滤器,演示了从HBase表中读取特定行键范围的数据,并使用Spark进行数据处理的过程。
本文介绍如何使用Apache Spark读取HBase数据,通过配置Spark应用程序、设置HBase连接参数及扫描过滤器,演示了从HBase表中读取特定行键范围的数据,并使用Spark进行数据处理的过程。
依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>sparkTest</groupId>
<artifactId>sparkTest</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.4.6</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.4.6</version>
</dependency>
</dependencies>
</project>
代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.filter.BinaryPrefixComparator;
import org.apache.hadoop.hbase.filter.CompareFilter;
import org.apache.hadoop.hbase.filter.RowFilter;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.protobuf.ProtobufUtil;
import org.apache.hadoop.hbase.protobuf.generated.ClientProtos;
import org.apache.hadoop.hbase.util.Base64;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.hadoop.hbase.mapreduce.TableInputFormat;
import org.apache.hadoop.hbase.client.Result;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.io.IOException;
import java.util.List;
public class SparkTest {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf().setAppName("myTest").setMaster("local[2]");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "mini1:2181,mini2:2181,mini3:2181");
conf.set(TableInputFormat.INPUT_TABLE, "one");//查询的表
conf.set(TableInputFormat.SCAN_ROW_START, "001");//起始行键
conf.set(TableInputFormat.SCAN_ROW_STOP, "103");//结束行键
Scan scan = new Scan();
RowFilter rowFilter = new RowFilter(CompareFilter.CompareOp.EQUAL, new BinaryPrefixComparator("".getBytes()));//过滤器
scan.setFilter(rowFilter);
conf.set(TableInputFormat.SCAN, convertScanToString(scan));
JavaPairRDD<ImmutableBytesWritable, Result> rdd = sc.newAPIHadoopRDD(conf, TableInputFormat.class, ImmutableBytesWritable.class, Result.class);//获取rdd数据
//处理数据
JavaPairRDD<String, Integer> tuple2JavaRDD = rdd.mapToPair(new PairFunction<Tuple2<ImmutableBytesWritable, Result>, String, Integer>() {
@Override
public Tuple2<String, Integer> call(Tuple2<ImmutableBytesWritable, Result> immutableBytesWritableResultTuple2) throws Exception {
Result result = immutableBytesWritableResultTuple2._2;
Cell[] cells = result.rawCells();
for (Cell cell : cells) {//获取行键,列簇,列,时间戳与值
String row = Bytes.toString(CellUtil.cloneRow(cell));//行键
String value = "value=" + Bytes.toString(CellUtil.cloneValue(cell));//值
String family = Bytes.toString(CellUtil.cloneFamily(cell));//列簇
String col = Bytes.toString(CellUtil.cloneQualifier(cell));//列名
String column = "column=" + family + ":" + col;//列簇与列
String timestamp = "timestamp=" + cell.getTimestamp();//时间戳
System.out.println(String.format("%s %s %s %s", row, column, timestamp, value));//格式化输出
}
return new Tuple2<String, Integer>(new String("test"), 1);//返回数据
}
});
List<Tuple2<String, Integer>> collect = tuple2JavaRDD.collect();//算子计算
sc.close();
}
/**
* 字符串 过滤器
*
* @param scan
* @return
*/
public static String convertScanToString(Scan scan) {
ClientProtos.Scan proto = null;
try {
proto = ProtobufUtil.toScan(scan);
} catch (IOException e) {
e.printStackTrace();
}
return Base64.encodeBytes(proto.toByteArray());
}
}
运行结果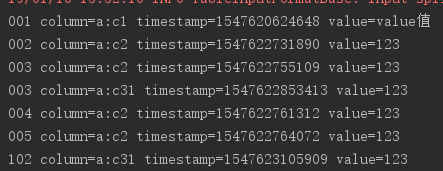


















 756
756

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











