



 本文介绍了如何使用Tess4j在Java中进行图片文字识别,包括下载Tess4j库和中文字体,配置项目,以及通过示例代码展示英文和中文的识别过程。此外,还提到了图像预处理对于提高识别效果的重要性,以及Tess4j在处理复杂图像和验证码时的局限性。文章最后提到,对于更高识别率的需求,可以考虑使用第三方API或训练字库。
本文介绍了如何使用Tess4j在Java中进行图片文字识别,包括下载Tess4j库和中文字体,配置项目,以及通过示例代码展示英文和中文的识别过程。此外,还提到了图像预处理对于提高识别效果的重要性,以及Tess4j在处理复杂图像和验证码时的局限性。文章最后提到,对于更高识别率的需求,可以考虑使用第三方API或训练字库。
想学习下识别图片中的文字,找到了Tess4j图文识别的方式,于是就初步探究下,玩下识别验证码。
第一步,下载
1、以3.4.2版本为例,下载Tess4j-3.4.2-src.zip。
2、下载中文字库,chi_sim.traineddata。
下载Tess4j参考:
http://sourceforge.net/projects/tess4j/
字库下载参考:
https://github.com/tesseract-ocr/tessdata/tree/3.04.00
api文档参考:
http://tess4j.sourceforge.net/docs/docs-3.4/
第二步,准备工作
1、解压Tess4J-3.4.2-src.zip。
2、把根目录的lib和dist相关jar拷贝到你的项目lib中。
3、再把tessdata目录拷贝到你的项目根目录中。
4、再把中文字库放入tessdata目录。
5、dll不用理,Tess4j.jar已经包含。
6、如果遇到异常,Error: Invalid memory access,Error opening data file ./tessdata/eng.traineddata说明tessdata路径不对。
压缩包目录:
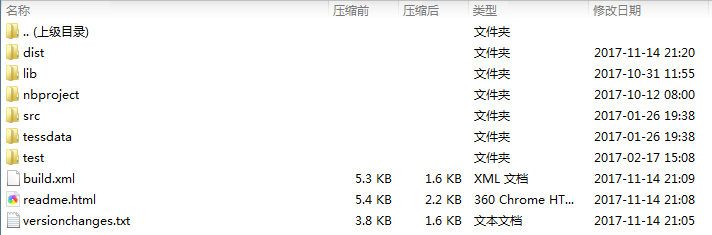
如果是使用maven:
就在pom.xml加入即可。
net.sourceforge.tess4j
tess4j
3.4.2
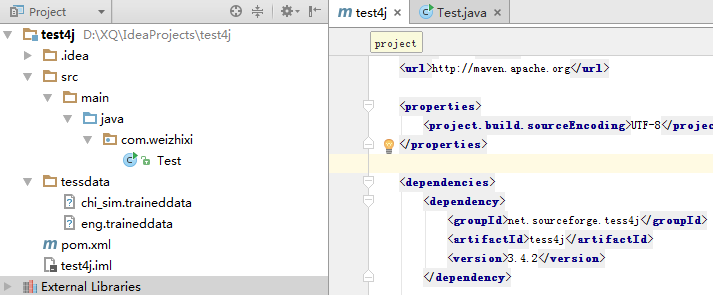
我的项目test for java结构:
Tess4j依赖jar参考:commons-beanutils-1.9.2.jar
commons-io-2.6.jar
commons-logging-1.2.jar
ghost4j-1.0.1.jar
hamcrest-core-1.3.jar
itext-2.1.7.jar
jai-imageio-core-1.3.1.jar
jboss-vfs-3.2.12.Final.jar
jcl-over-slf4j-1.7.25.jar
jna-4.1.0.jar
jul-to-slf4j-1.7.25.jar
junit-4.12.jar
lept4j-1.6.2.jar
log4j-1.2.17.jar
log4j-over-slf4j-1.7.25.jar
logback-classic-1.2.3.jar
logback-core-1.2.3.jar
slf4j-api-1.7.25.jar
xmlgraphics-commons-1.5.jar
第三步,开发测试
官方简单例子:package net.sourceforge.tess4j.example;
import java.io.File;
import net.sourceforge.tess4j.*;
public class TesseractExample {
public static void main(String[] args) {
File imageFile = new File("eurotext.tif");
ITesseract instance = new Tesseract(); // JNA Interface Mapping
// ITesseract instance = new Tesseract1(); // JNA Direct Mapping
try {
String result = instance.doOCR(imageFile);
System.out.println(result);
} catch (TesseractException e) {
System.err.println(e.getMessage());
}
}
}
我的初探例子:package com.weizhixi;
import net.sourceforge.tess4j.ITesseract;
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.util.ImageHelper;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
public class Test {
public static void main(String[] args) throws Exception{
testEn();
//testZh();
}
//使用英文字库 - 识别图片
public static void testEn() throws Exception {
File imageFile = new File("C:/Users/XQ/Desktop/en.png");
BufferedImage image = ImageIO.read(imageFile);
//对图片进行处理
image = convertImage(image);
ITesseract instance = new Tesseract();//JNA Interface Mapping
String result = instance.doOCR(image); //识别
System.out.println(result);
}
//使用中文字库 - 识别图片
public static void testZh() throws Exception {
File imageFile = new File("C:/Users/XQ/Desktop/zh.png");
BufferedImage image = ImageIO.read(imageFile);
//对图片进行处理
//image = convertImage(image);
ITesseract instance = new Tesseract();//JNA Interface Mapping
instance.setLanguage("chi_sim");//使用中文字库
String result = instance.doOCR(image); //识别
System.out.println(result);
}
//对图片进行处理 - 提高识别度
public static BufferedImage convertImage(BufferedImage image) throws Exception {
//按指定宽高创建一个图像副本
//image = ImageHelper.getSubImage(image, 0, 0, image.getWidth(), image.getHeight());
//图像转换成灰度的简单方法 - 黑白处理
image = ImageHelper.convertImageToGrayscale(image);
//图像缩放 - 放大n倍图像
image = ImageHelper.getScaledInstance(image, image.getWidth() * 3, image.getHeight() * 3);
return image;
}
}
处理倾斜图片:
如果图片字体倾斜的,可以用下面代码纠正BufferedImage bi = ImageIO.read(imageFile);
ImageDeskew id = new ImageDeskew(bi);
double imageSkewAngle = id.getSkewAngle(); //获取倾斜角度
if ((imageSkewAngle > 0.05d || imageSkewAngle
bi = ImageHelper.rotateImage(bi, -imageSkewAngle); //纠偏图像
}
测试1:
测试一张英文截图en.png。

未使用图像简单处理,运行读取图片文字:
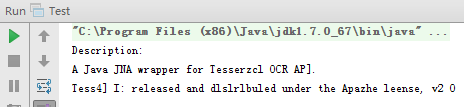
发现有几次无法准确识别。
使用convertImage方法对图像简单处理,运行读取图片文字:
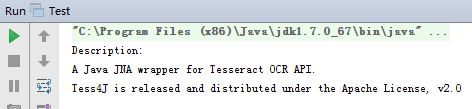
发现已经完全识别了。
测试2:
测试一张中文图片zh.png

用不用convertImage,测试结果都正常:
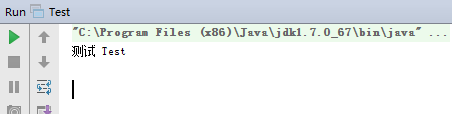
测试3:
来点复杂的图片:

来看看识别输出:
1、未使用图像处理
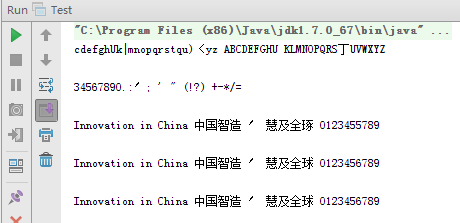
2、使用图像处理
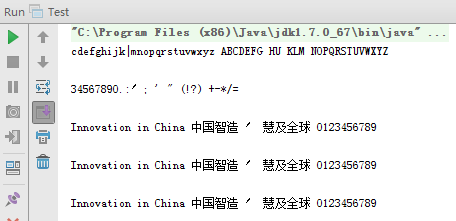
发现识别度提高了很多,但部分还是未能够识别。
测试4:
识别干扰度比较低的简单验证码

识别结果:已经正确识别了。

经测试多张各种验证码,干扰度比较大的,扭曲字体的验证码不能识别。
关于训字库
训字库能提高中文字库的识别度。
需要下载中文字库:chi_sim.traindata
需要下载tesseract-ocr安装:tesseract-ocr-setup.exe
需要下载jTessBoxEditor用于修改box文件
至于怎么训字库,这里不展开说了。
初探总结
初探了一天,发现初级简单应用Tess4j:
1、只能识别几乎没有干扰,比较清晰的图片。
2、对图片灰度处理和放大处理,能提高识别度,但不是一定能起作用。
3、如果不准确的识别,可能要去训字库了,如测试识别图中的逗号,已经变成偏上的点了。
4、识别度受字体颜色、大小、清晰度、干扰度、扭曲、倾斜等度影响。
5、官方还提供了一些test例子,还有很多操作和应用。
初级应用只是简单的识别,能识别复杂度很大的图片文字,那是要很多牛B技术和逻辑的大神级操作。
如果想识别度很高很高几乎所有都能识别,又要快速集成、建议还是调用第三方识别API了,有些要收费的有些不用收费但有调用频次限制。
Demo下载
由于资源太大,我就不上传到我网站了。
请到我的网盘下载:
链接:https://pan.baidu.com/s/1dHje9pR
密码:z0bi
内含:
1、项目:基于maven_test4j例子项目.zip
2、官方Tess4j:Tess4J-3.4.2-src.zip
3、中文训字库:chi_sim.traineddata
原创文章,转载请注明出处:https://www.weizhixi.com/article/59.html

















 346
346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









