









Mamba,一种具有强大信息整合能力的技术,加上多模态特征融合,不仅能提升模型在处理复杂任务时的准确性和鲁棒性,还拓宽了应用边界:从智能交互到复杂数据分析的多个领域...都涵盖了。创新空间和落地应用前景可见一斑。
去年至今,Mamba+多模态特征融合相关的论文呈爆发式增长,其中顶会顶刊成果占比可观,比如ICASSP 2025的DepMamba模型,计算效率、准确率等都优于SOTA。如果有同学也对此感兴趣,想出成果,推荐优先探索动态模态融合、轻量化混合架构、特定领域(如医疗或机器人)的多模态应用,结合真实场景需求设计创新点。
为方便大家找参考,我已经整理好了11篇Mamba+多模态特征融合前沿论文(基本都有代码),需要的可直接获取,帮各位节省时间加快论文进度。
全部论文+开源代码需要的同学看文末
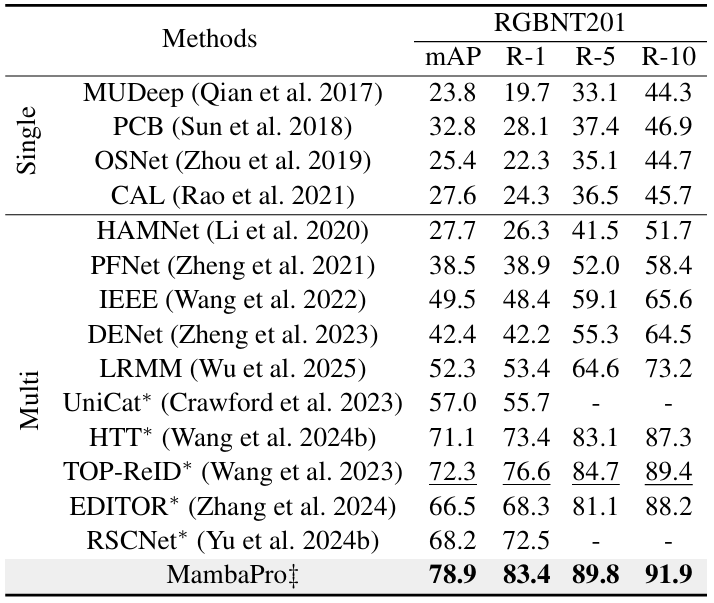
MambaPro: Multi-Modal Object Re-Identification with Mamba Aggregation and Synergistic Prompt
方法:论文提出了一种名为MambaPro的多模态目标重识别方法,通过Mamba的高效序列建模和协同提示机制,实现了多模态特征的深度融合与交互,有效提升了特征的判别力和模型性能。
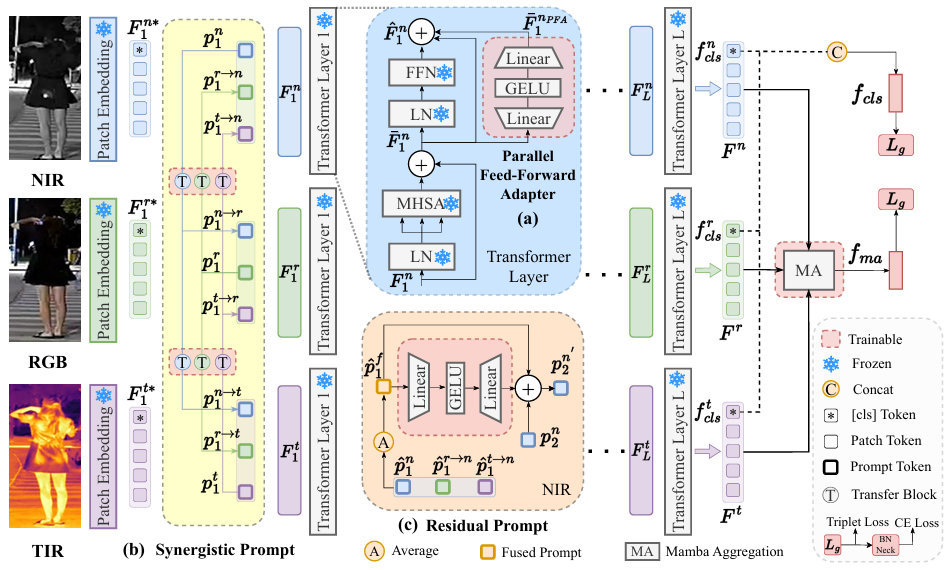
创新点:
-
PFA 被引入到冻结的 CLIP 图像编码器中,以促进预训练知识向多模态目标重识别任务的转移。
-
SRP 被提出用于指导多模态特征的联合学习,有效促进了判别性多模态信息的交换,并通过残差提示逐层聚合多模态信息,显著增强了信息的协同效应。
-
MA 高效地对来自不同模态的长序列进行建模交互,整合了模态内部和模态之间的互补特征。
MambaGesture: Enhancing Co-Speech Gesture Generation with Mamba and Disentangled Multi-Modality Fusion
方法:论文提出了一种名为MambaGesture的新框架,旨在通过结合Mamba模型的序列处理能力与多模态特征融合模块SEAD,解决现有协同语音手势生成方法中忽视多模态交互的问题,以提升手势生成的真实性和多样性。
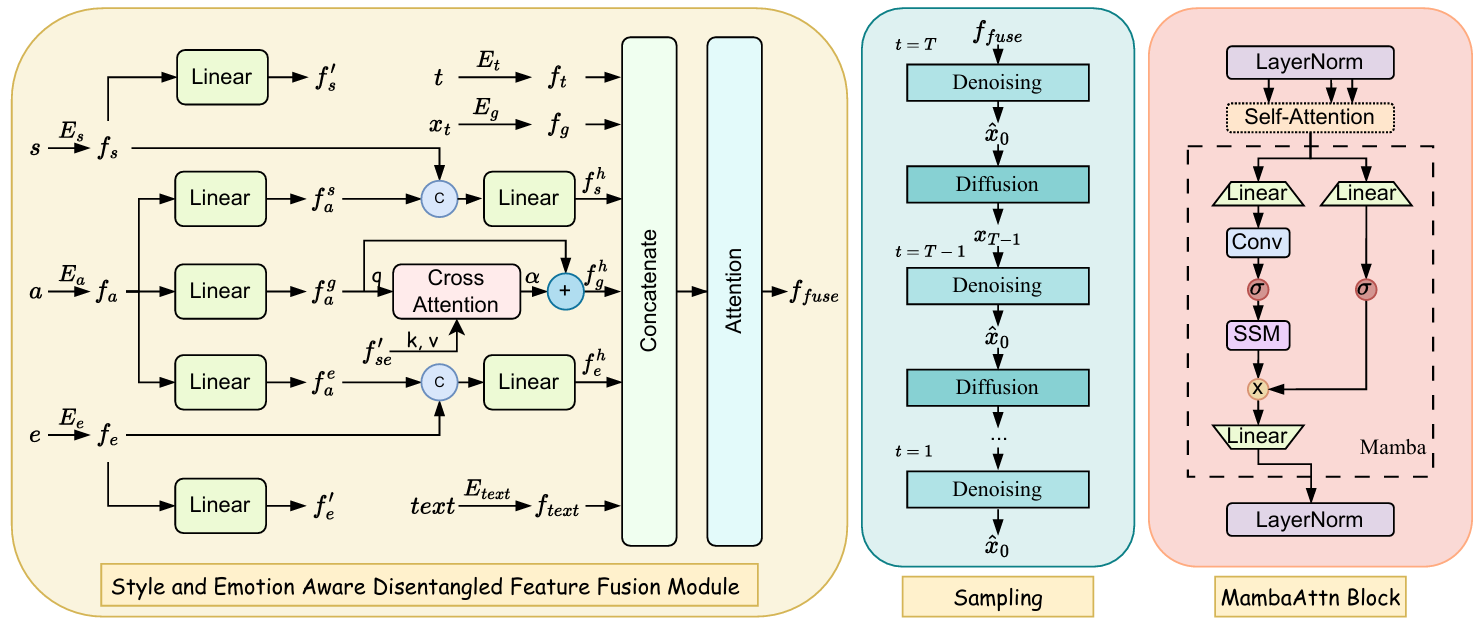
创新点:
-
引入Mamba模型用于扩散基础的共同语音手势生成,这是首次在该领域使用Mamba模型。
-
提出了MambaAttn模块,强化了序列建模能力,以及SEAD模块,一种新颖的音频解耦方法,能够融合多模态数据。
-
引入了多模态特征融合模块,通过音频、文本、风格和情感的解耦,深化了融合过程,从而生成具备更高逼真度和多样性的手势。
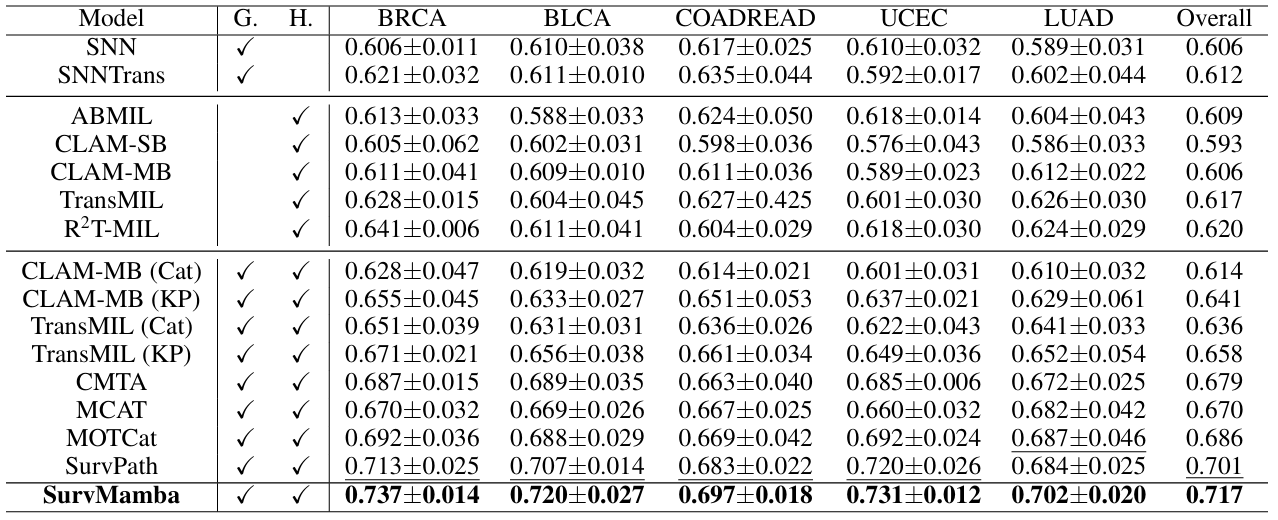
Survmamba: State space model with multi-grained multi-modal interaction for survival prediction
方法:论文介绍了一个名为 SurvMamba 的新框架,它结合了 Mamba 状态空间模型和多模态特征融合技术,通过多粒度的多模态交互在组织切片图像和转录组数据中高效提取和整合细粒度和粗粒度特征,实现了更全面的患者生存预测。
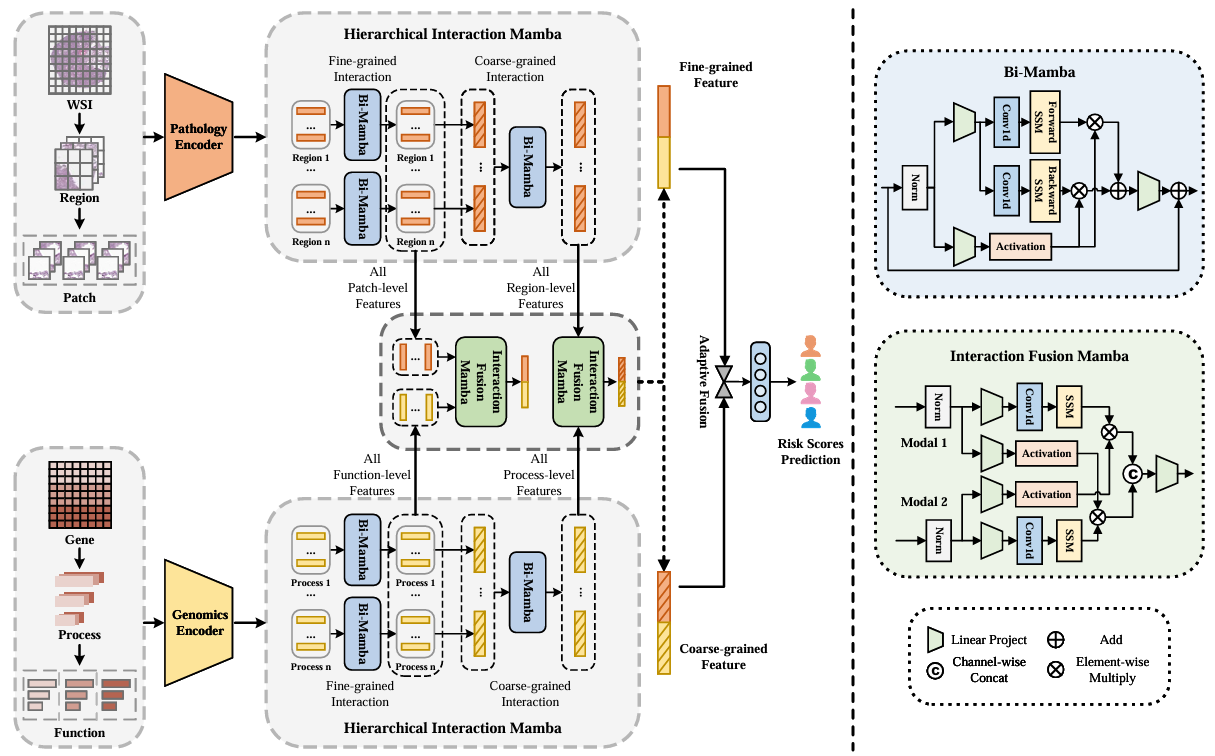
创新点:
-
利用Mamba高效处理高维病理图像和转录组数据,有效降低计算复杂度,提升模型性能。
-
引入了分层交互模块 (HIM),能够在不同粒度上进行高效的模态内交互。
-
使用交互融合模块 (IFM) 实现级联的模态间交互融合,产生更全面的特征用于生存预测。
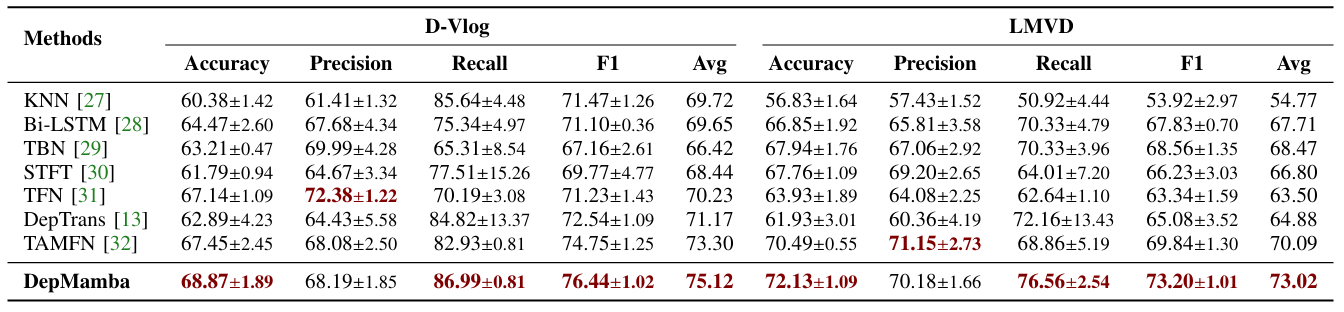
Depmamba: Progressive fusion mamba for multimodal depression detection
方法:本文提出DepMamba方法,通过Mamba模型结合音频和视频特征,实现高效的多模态融合。它利用层次化建模提取局部和全局特征,并通过逐步融合策略增强模态间协同性,从而提升抑郁检测的性能和效率。
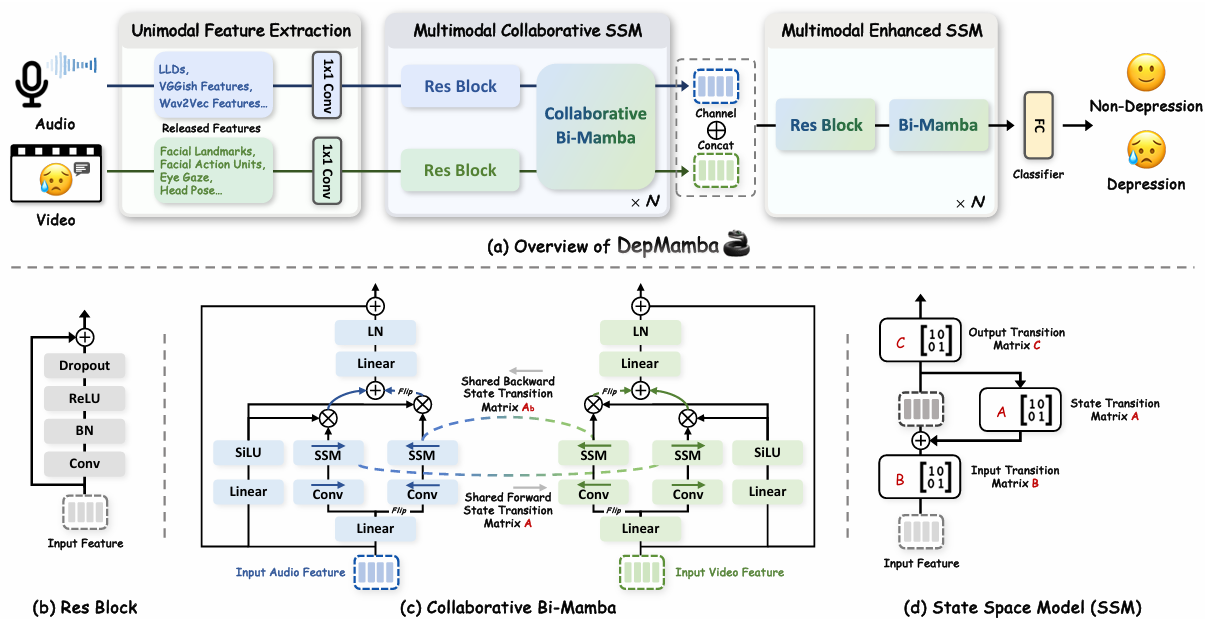
创新点:
-
引入CNN和双向Mamba(Bi-Mamba)进行分层上下文建模,从局部到全局尺度有效地捕捉长序列的视听内容。
-
采用协作和增强状态空间模型(CoSSM和EnSSM),分别提取模态间共享信息和增强模态协同性,提升检测性能。
-
首次将Mamba模型应用于抑郁检测,结合音频和视频模态,提升多模态特征融合效率。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“曼巴特征”获取全部方案+开源代码
码字不易,欢迎大家点赞评论收藏

















 1964
1964

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









