







一、基础依赖
软件版本
CentOS7 x64
Java 1.8
Hadoop 3.3.2
zookeeper 3.6.4
机器分布
说明:
NN: NameNode HDFS集群入口,复制维护和管理文件系统元文件,包括名称空间、文件和块位置信息、访问权限等
DN: DataNode,存储实际数据,执行客户请求,并通过定期发送心跳信息汇报自己负责的块列表。
ZKFC: ZKFailoverController 负责NN主备切换控制,定期检测NN状态
NM:Node Manager 资源监控代理就,监控节点的资源使用,向RM 上报节点状态
RM: Resource Manager 资源控制节点,负责全局统一的资源管理调度分配
JN: JournalNode 基于QJM共享存储系统的NN高可用方式,用于存储edit日志文件(后续详细介绍NN的高可用原理)
ZK: zookeeper 分布式协调器,用于后续NN选主使用。
主机名 | IP | 角色 | 服务 |
m01 | 192.168.3.203 | NN(Active) | NN、ZKFC |
m02 | 192.168.3.207 | NN(Standby) | NN、ZKFC、RM |
n01 | 192.168.3.204 | DN | DN、NM、JN、ZK |
n02 | 192.168.3.205 | DN | DN、NM、JN、ZK |
n03 | 192.168.3.206 | DN | DN、NM、JN、ZK |
用户、目录设置
创建hadoop账户,并配置该账户下无密码访问
创建工程、数据目录
mkdir /opt/module/ (自定义工程目录)
mkdir /home/hadoop/data/namenode (自定义数据目录)
mkdir /home/hadoop/data/tmp (自定义pid目录)
mkdir /home/hadoop/data/journalnode (自定义存放edit目录)
修改相应目录所属用户和组
chown -R hadoop.hadoop /opt/module
chown -R hadoop.hadoop /home/hadoop/data (使用hadoop账户创建该操作省略)
基础软件安装
安装java
#yum install java-1.8.0-openjdk.x86_64 -y
安装psmisc
#yum install psmisc -y
拷贝hadoop软件到服务器(略)
安装 zookeeper
#cp zoo_sample.cfg zoo.cfg
#vim zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/home/hadoop/zkdata
clientPort=2181
server.1=n01:2888:3888
server.2=n02:2888:3888
server.3=n03:2888:3888
#vim /home/hadoop/zkdata/myid
1
注意:这里的数字和配置文件中定义的server.x 要一致,即 n01 对应的ID 为1, n02对应的ID 为2...
分别启动服务
#./bin/zkServer.sh start
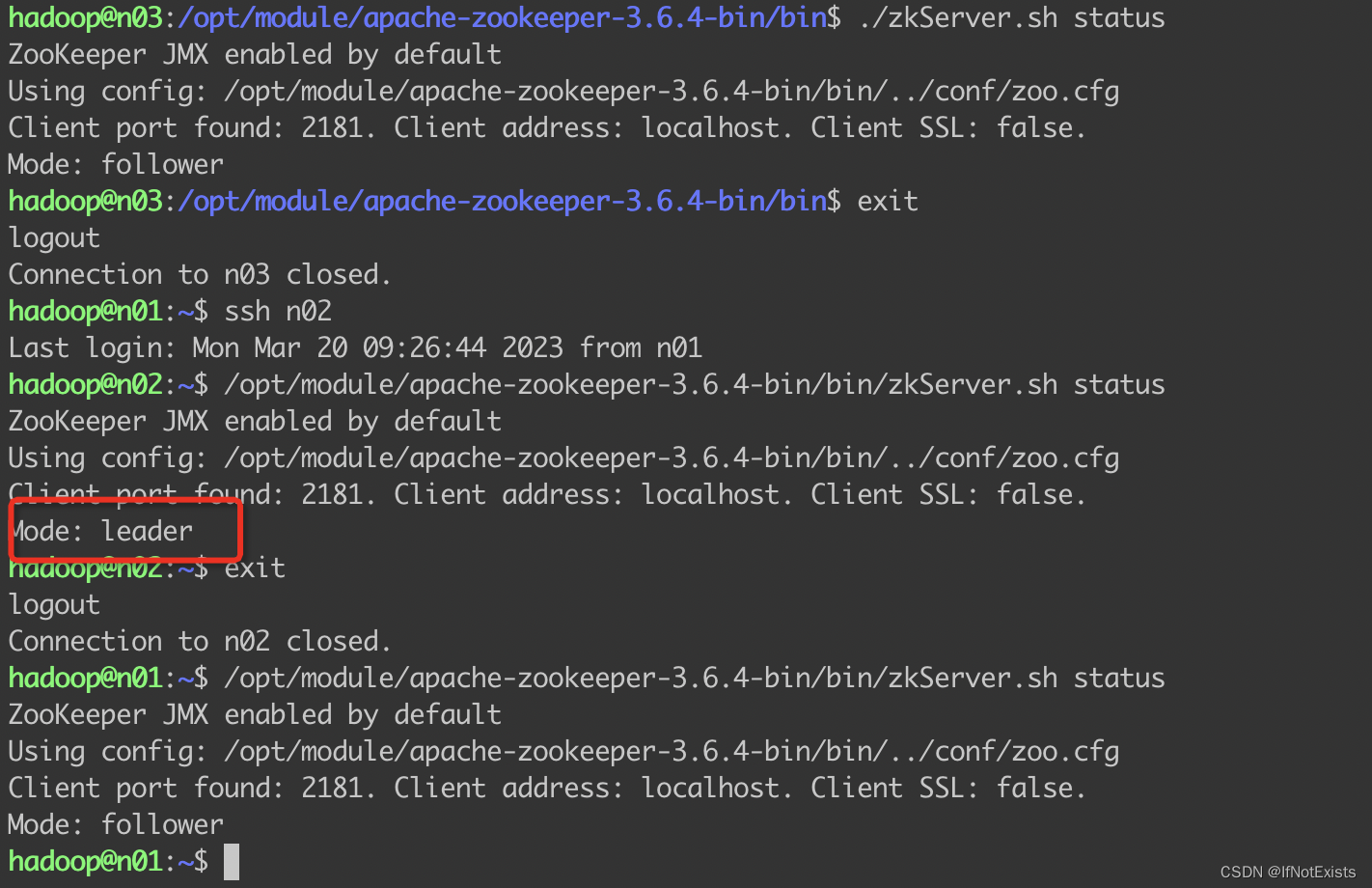
查看ZK集群状态
#./bin/zkServer.sh status
环境变量配置
#vim /etc/profile.d/hadoop.sh
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.362.b08-1.el7_9.x86_64/jre
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/opt/module/hadoop-3.3.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_CLASSPATH=/opt/module/hadoop-3.3.2/lib/*
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/opt/module/apache-hive-3.1.3-bin/lib/*
注:
获取YUM 安装java路径

二、安装部署
配置修改
配置文件存放目录 hadoop-3.3.2/etc/hadoop
1.1 core-site.xml
<!-- NameNode URL -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://myhdfs</value>
</property>
<!-- Data Dir-->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/data/namenode</value>
</property>
<!-- web brower user-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>n01:2181,n02:2181,n03:2181</value>
</property>
<!--系统垃圾桶保留时-->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<property>
<name>ipc.client.connect.retry.interval</name>
<value>10000</value>
</property>
1.2 hdfs-site.xml
<!-- 定义service 名字-->
<property>
<name>dfs.nameservices</name>
<value>myhdfs</value>
</property>
<!-- 定义service 包含的主机-->
<property>
<name>dfs.ha.namenodes.myhdfs</name>
<value>m01,m02</value>
</property>
<!-- 定义nn rpc地址和端口-->
<property>
<name>dfs.namenode.rpc-address.myhdfs.m01</name>
<value>m01:8082</value>
</property>
<property>
<name>dfs.namenode.rpc-address.myhdfs.m02</name>
<value>m02:8082</value>
</property>
<!-- 定义nn http地址和端口-->
<property>
<name>dfs.namenode.http-address.myhdfs.m01</name>
<value>m01:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.myhdfs.m02</name>
<value>m02:9870</value>
</property>
<!-- 定义nn间用于存放edits日志的journal节点列表-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://n01:8485;n02:8485;n03:8485/myhdfs</value>
</property>
<!-- 说明:客户端连接可用状态的NameNode所用的代理类,默认值:org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider -->
<property>
<name>dfs.client.failover.proxy.provider.myhdfs</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离方式,预防脑裂-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- ssh通讯使用的密钥文件在系统中的位置 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!-- 说明:失效转移时使用的秘钥文件。 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/data/journalnode</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.myhdfs</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 设置数据块应该被复制的份数,也就是副本数,默认:3 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 说明:是否开启权限检查 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
1.3 yarn-site.xml
<!-- MR use shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- ResourceManage -->
<!--
<property>
<name>yarn.resourcemanager.hostname</name>
<value>m02</value>
</property>
-->
<!--开启ResourceManager HA功能-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--标志ResourceManager-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>myyarn</value>
</property>
<!--集群中ResourceManager的ID列表,后面的配置将引用该ID-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>m01,m02</value>
</property>
<!-- 设置YARN集群主角色运行节点rm1-->
<property>
<name>yarn.resourcemanager.hostname.m01</name>
<value>m01</value>
</property>
<!-- 设置YARN集群主角色运行节点rm2-->
<property>
<name>yarn.resourcemanager.hostname.m02</name>
<value>m02</value>
</property>
<!--ResourceManager1的Web页面访问地址-->
<property>
<name>yarn.resourcemanager.webapp.address.m01</name>
<value>m01:8088</value>
</property>
<!--ResourceManager2的Web页面访问地址-->
<property>
<name>yarn.resourcemanager.webapp.address.m02</name>
<value>m02:8088</value>
</property>
<!--ZooKeeper集群列表-->
<property>
<name>hadoop.zk.address</name>
<value>n01:2181,n02:2181,n03:2181</value>
</property>
<!--启用ResouerceManager重启的功能,默认为false-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--用于ResouerceManager状态存储的类-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- 是否将对容器实施物理内存限制 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否将对容器实施虚拟内存限制 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CO NF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://m02:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为 7 天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
1.4 mapred-site.xml
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>m02:10020</value>
</property>
<!-- 历史服务器 web 端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>m02:19888</value>
</property>
<!-- yarn环境变量 -->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- map环境变量 -->
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- reduce环境变量 -->
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
1.5 hadoop-env.sh
服务启动后,默认hadoop相关的pid 会在/tmp目录下生成,该目录系统会定期清理,这里做了调整。
export HADOOP_PID_DIR=/home/hadoop/data/tmp
export HADOOP_HOME=/opt/module/hadoop-3.3.2
1.6 mapred-env.sh
export HADOOP_MAPRED_PID_DIR=/home/hadoop/data/tmp
1.7 workers
n01
n02
n03
三、服务启动
初始化
初始化集群在ZK的状态(创建zknode)
hdfs zkfc -formatZK
通过zkCli.sh 查看,发现多了一个目录


启动journalServer服务(n01, n02,n03)(第一次需手动启动,后续直接通过m01执行start-dfs.sh 启动)
hdfs --daemon start journalnode
初始化hadoop集群(m01)(注意:第一次搭建的空集群执行)
hdfs namenode -format

启动服务
第一次需手动启动,后续直接通过m01执行start-dfs.sh 启动所有hadoop相关服务
2.1 启动namenode 服务(m01)
hdfs --daemon start namenode
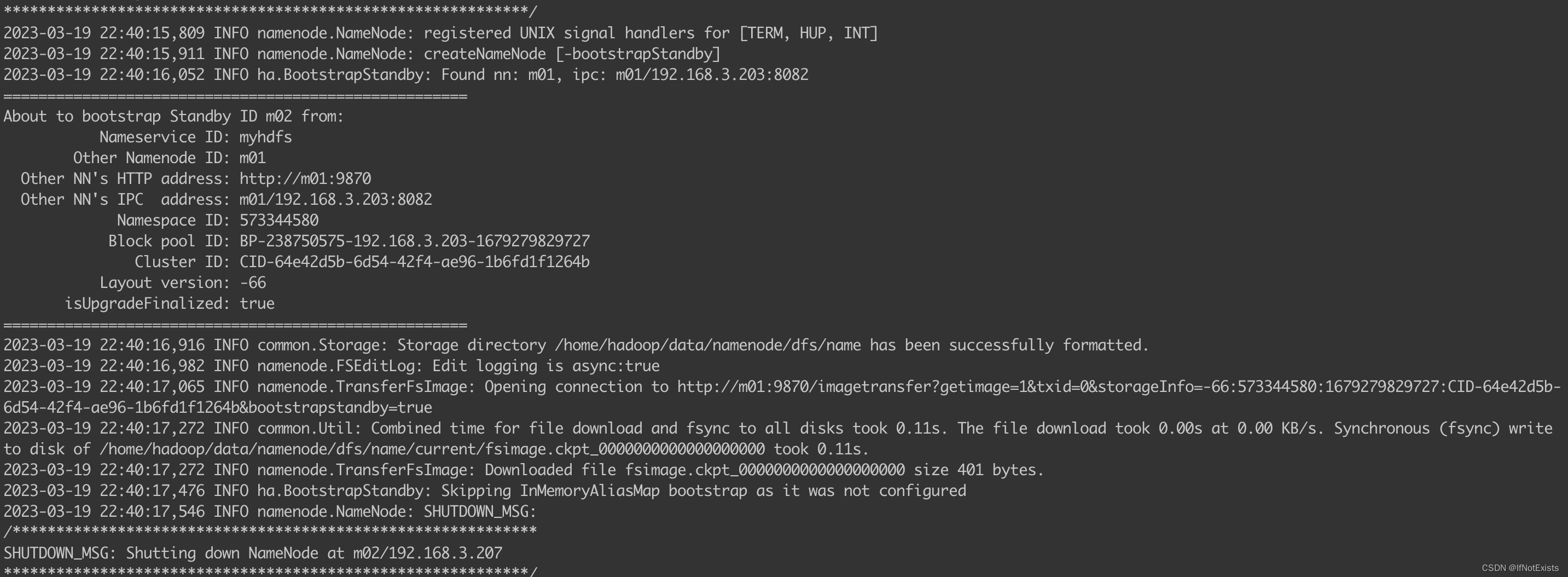
2.2 Standby namenode 同步镜像
hdfs namenode -bootstrapStandby
2.3 Standby namenode 启动
hdfs --daemon start namenode
2.4 查看集群主备状态
hdfs haadmin -getAllServiceState
发现2个节点均为standby 状态,同时通过jps 查看发现m01, m02 均没有ZKFC进程

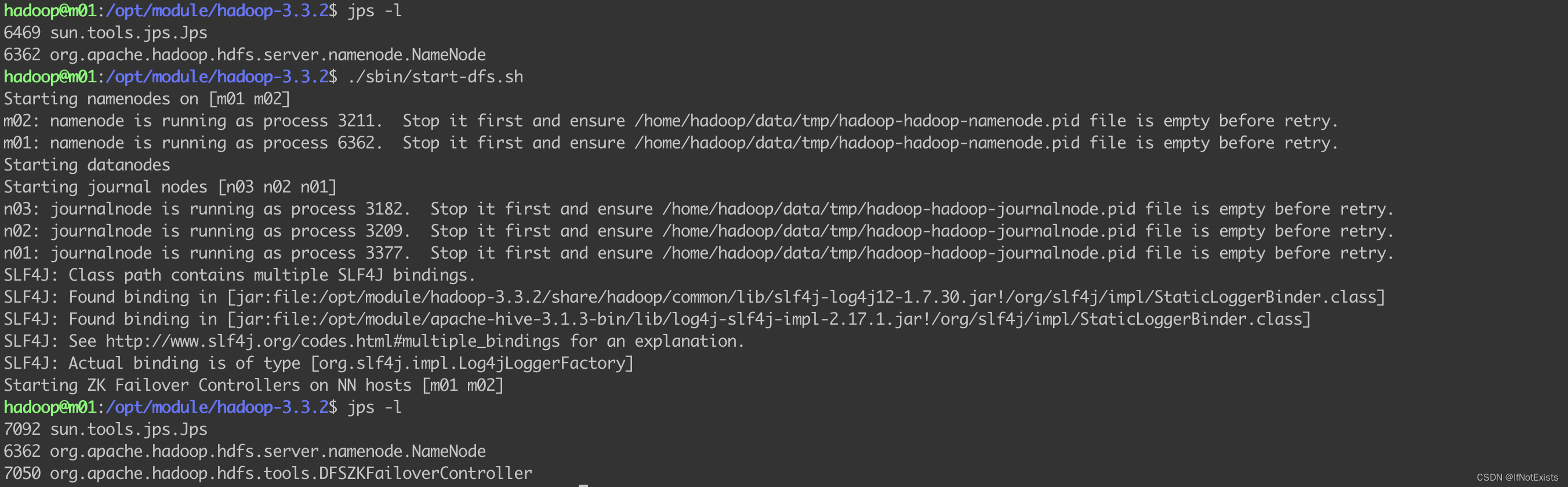
启动hdfs (m01)
./sbin/start-dfs.sh
获取NameNode节点

主备节点状态
hdfs haadmin -getAllServiceState

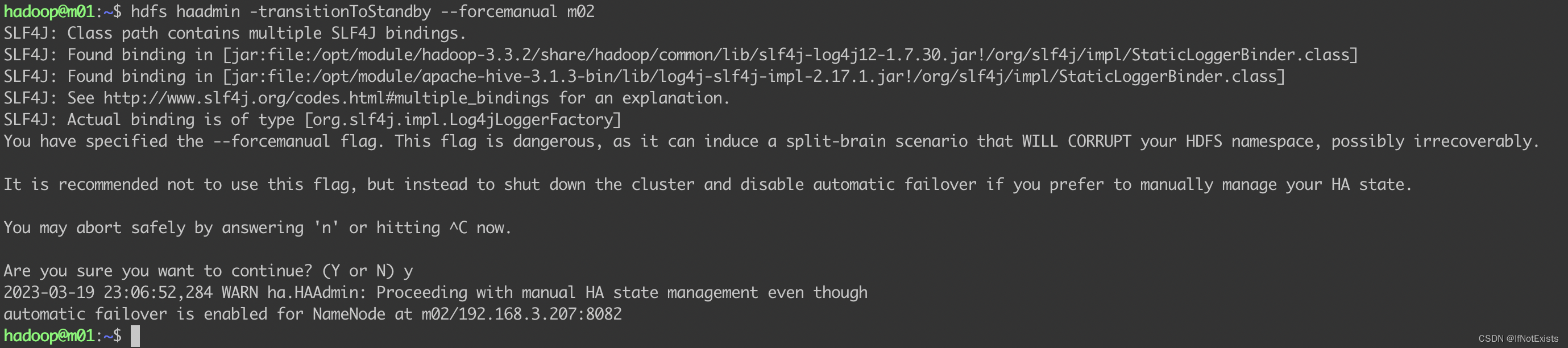
切换主备节点状态
hdfs haadmin -transitionToStandby --forcemanual m02

获取JN节点

2.5 启动yarn (m01)
./sbin/start-yarn.sh

四、Web访问
hdfs管理界面
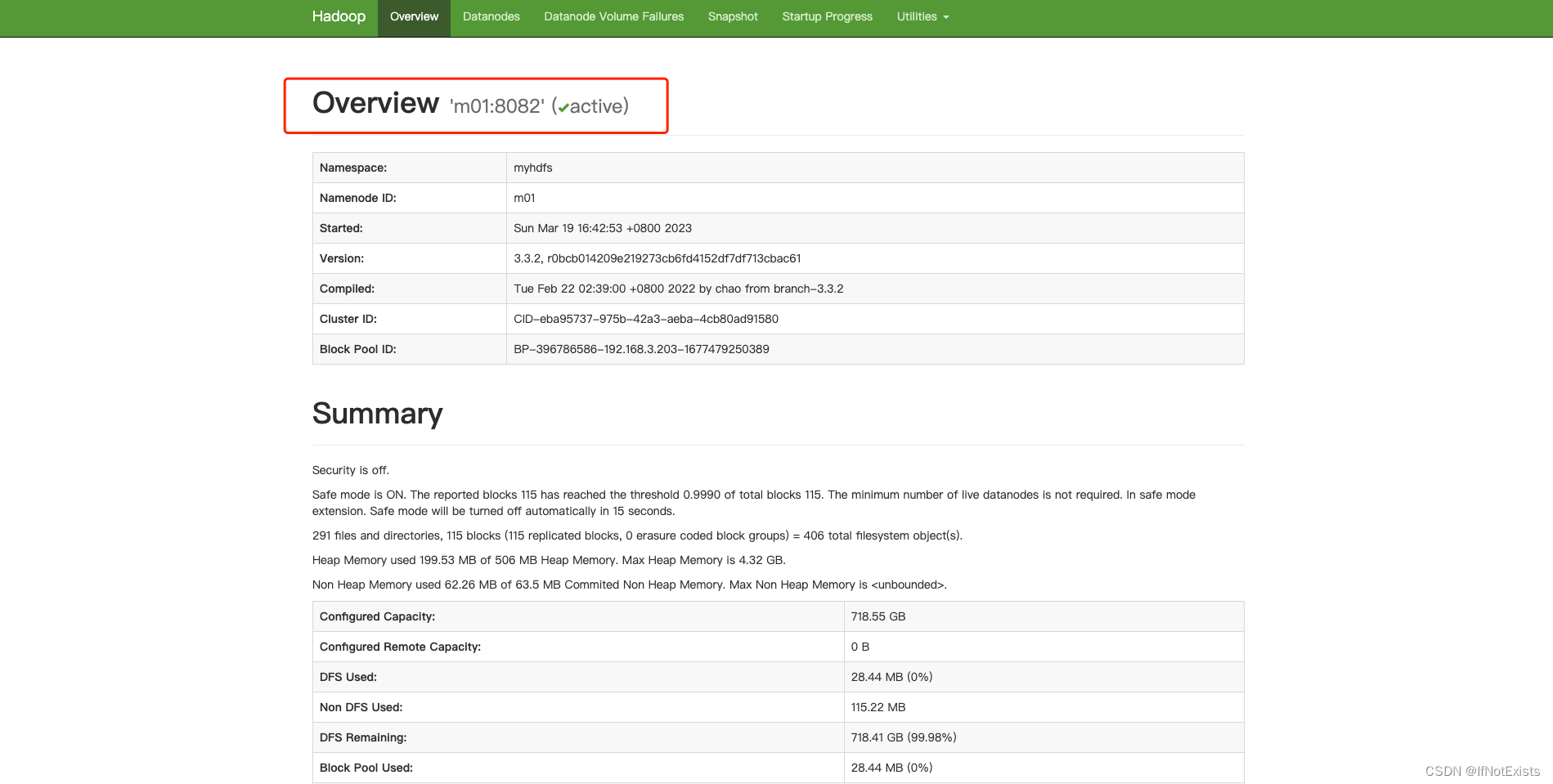
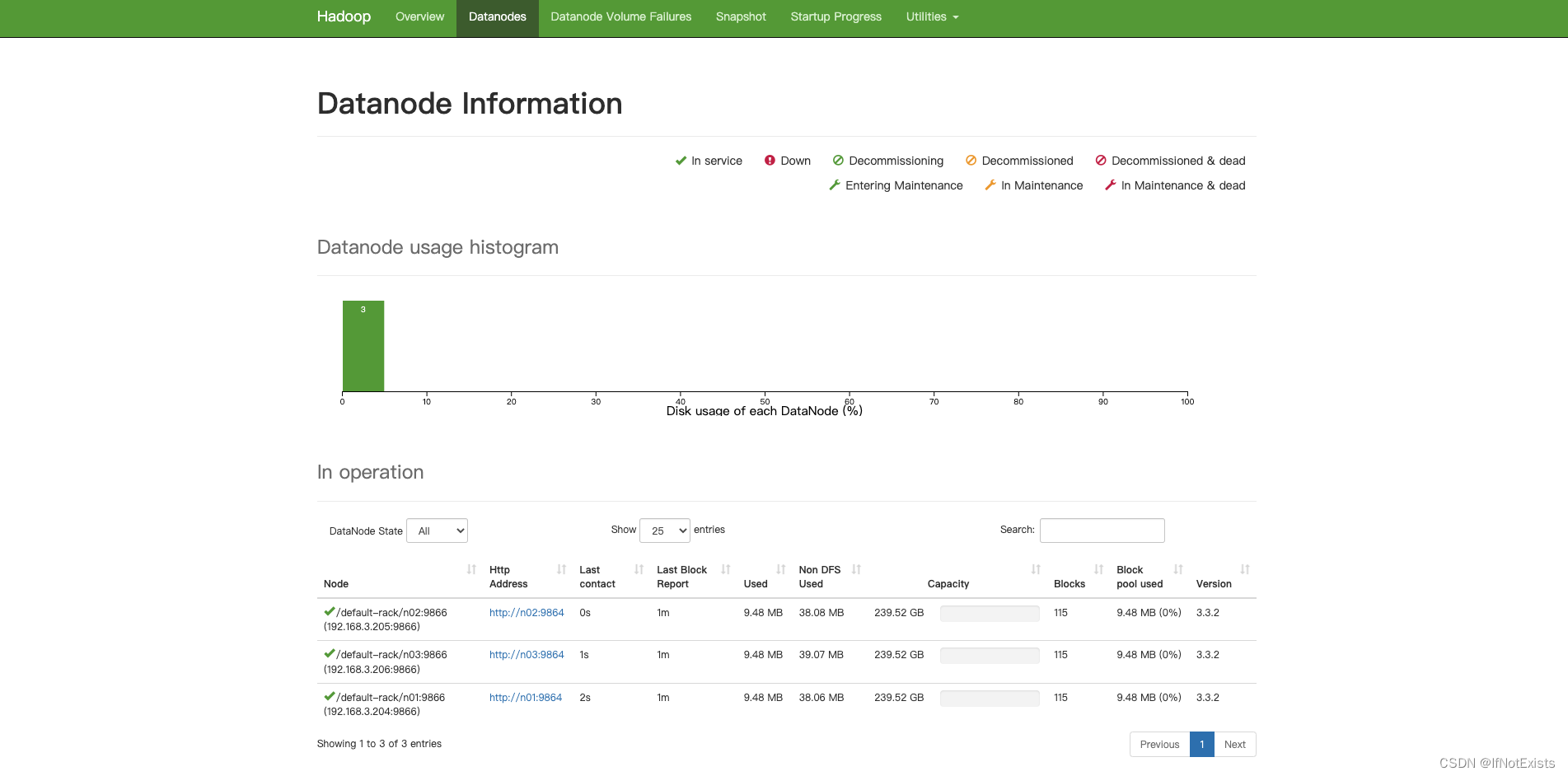
yarn 管理界面
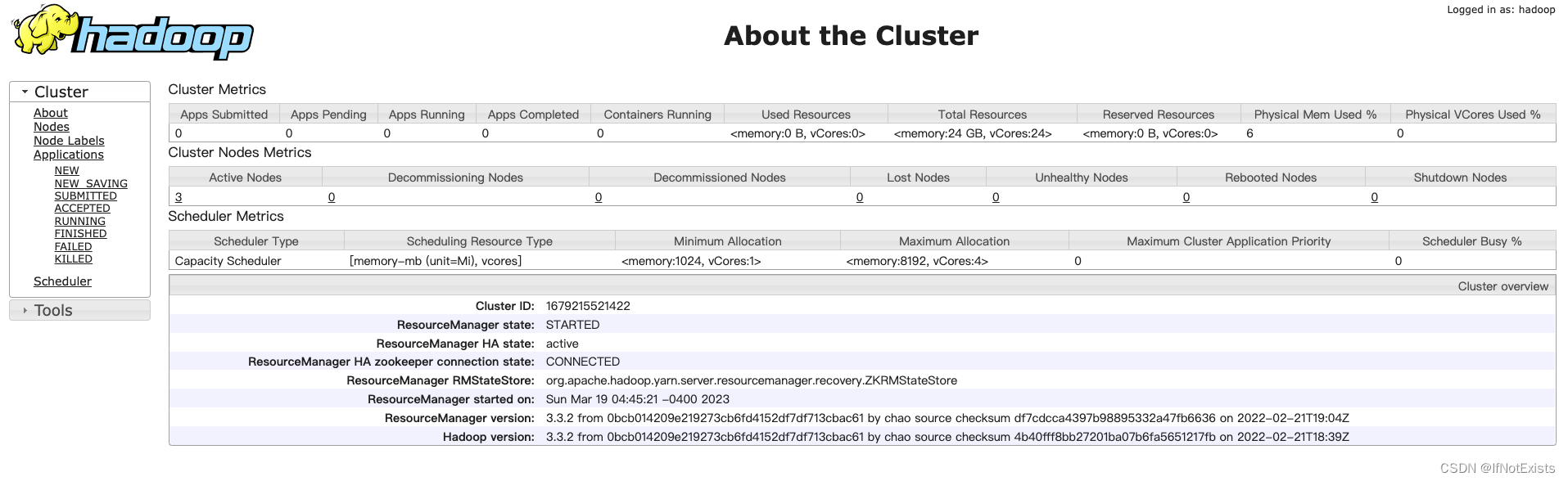
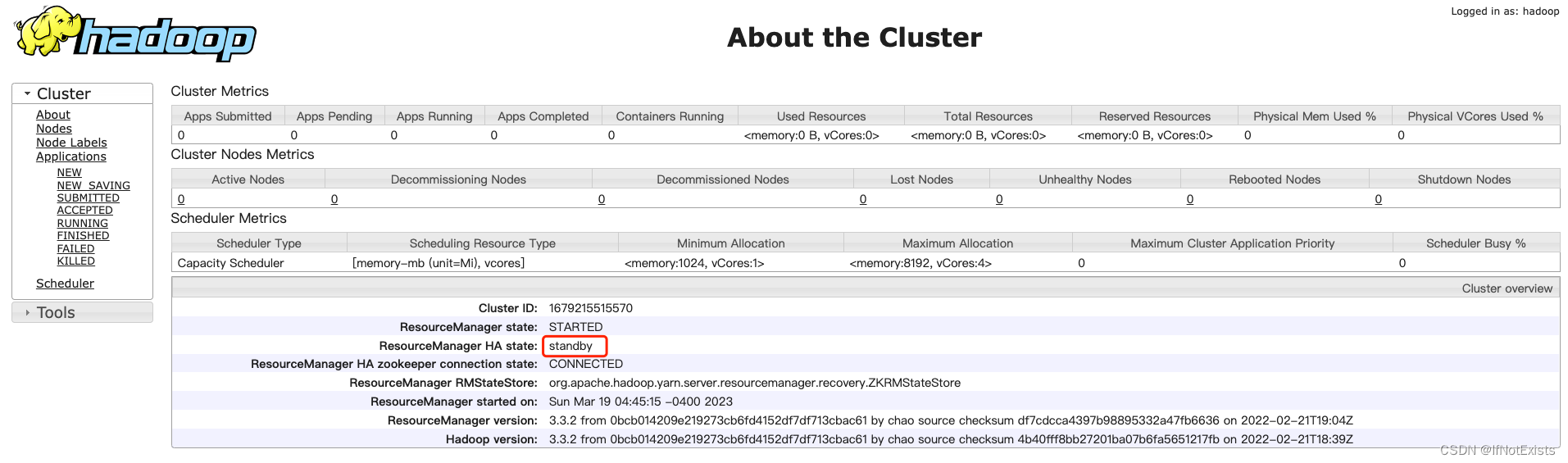
五、测试
文件加载、查看
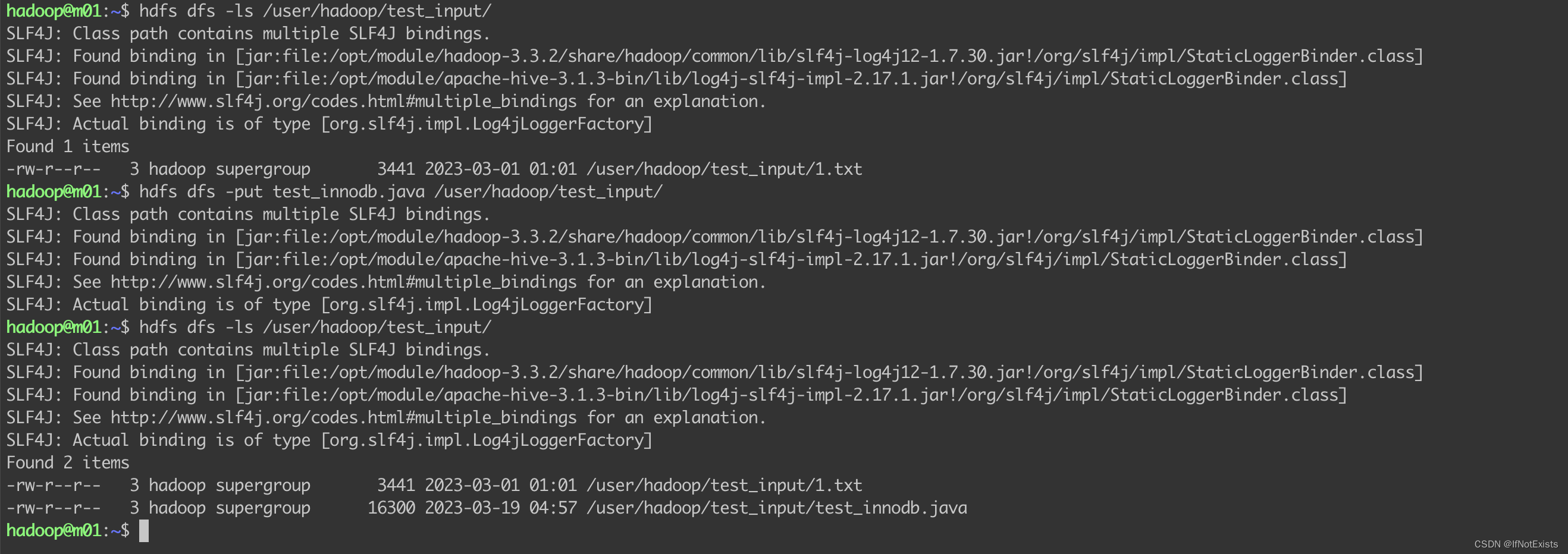
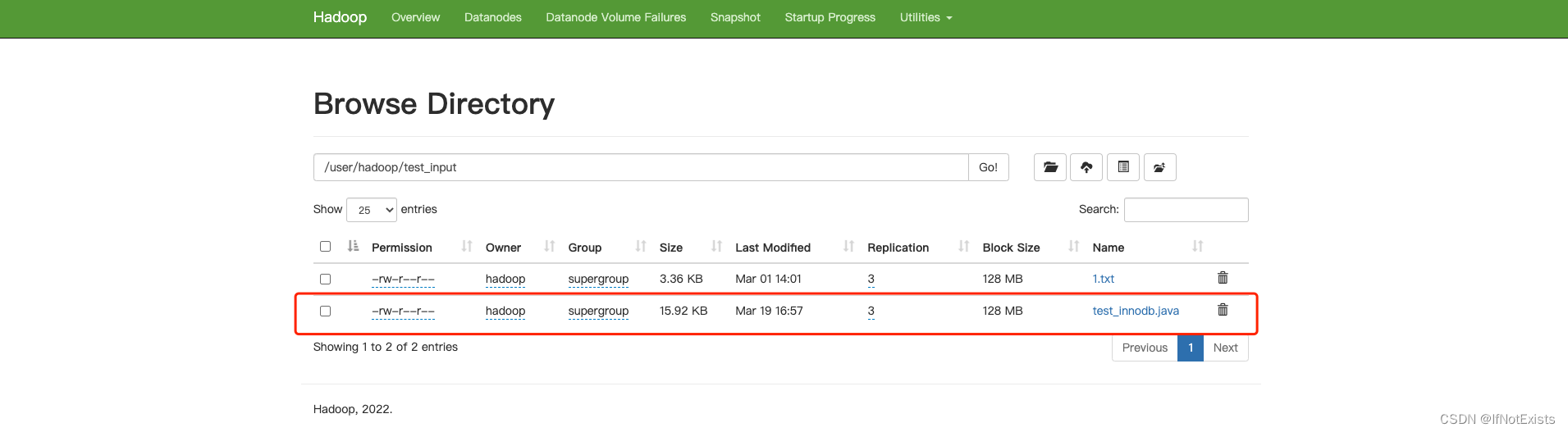
任务管理
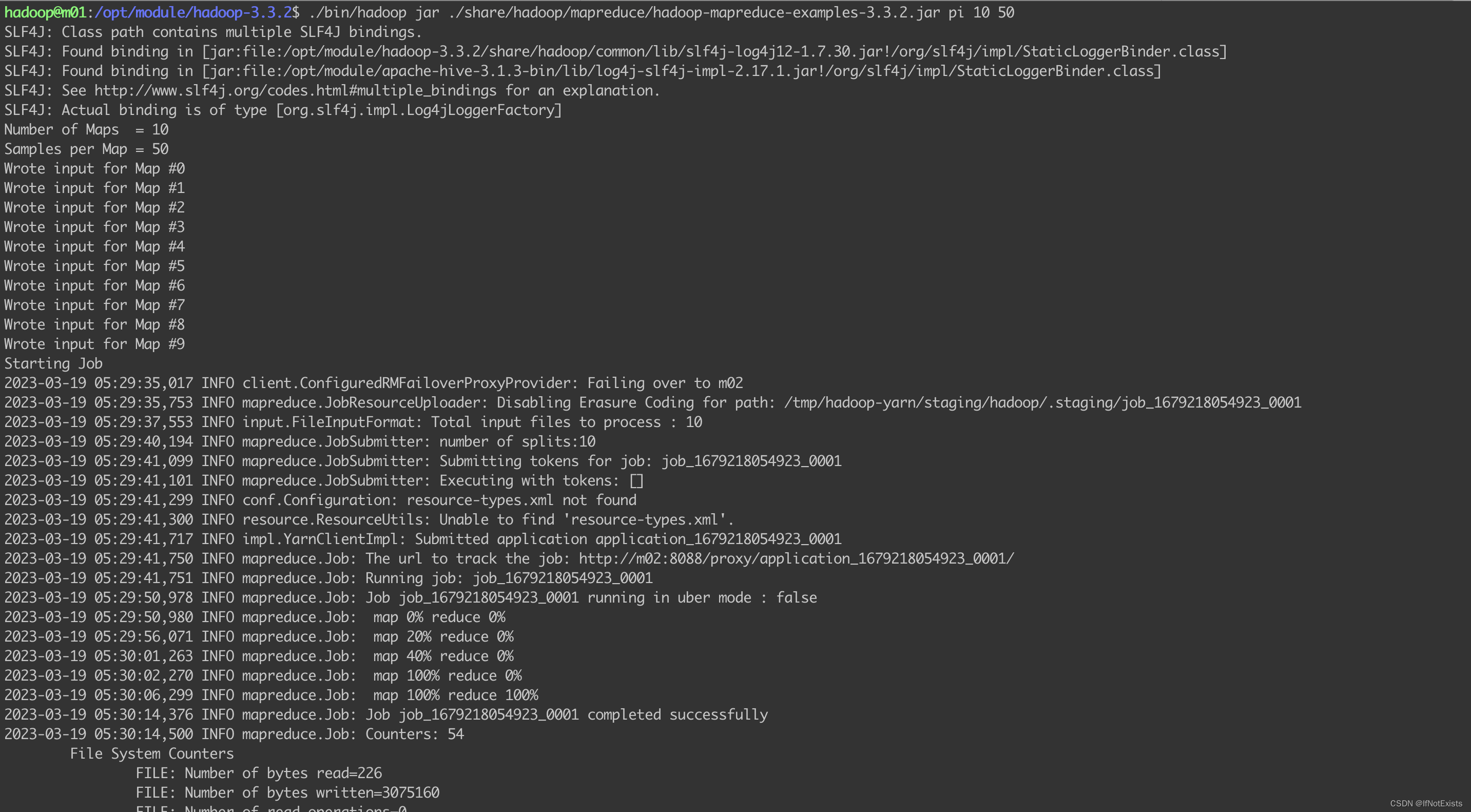
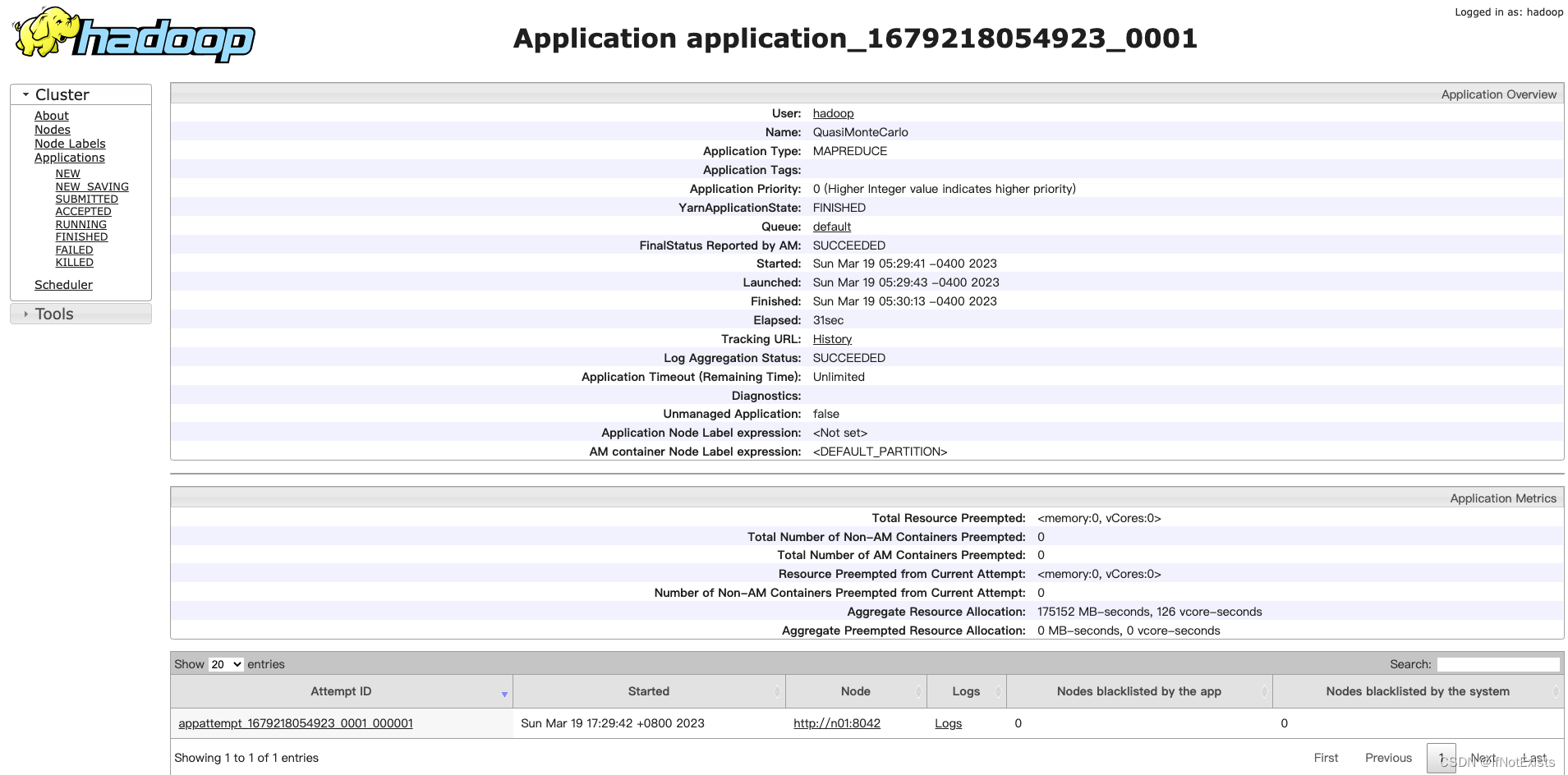
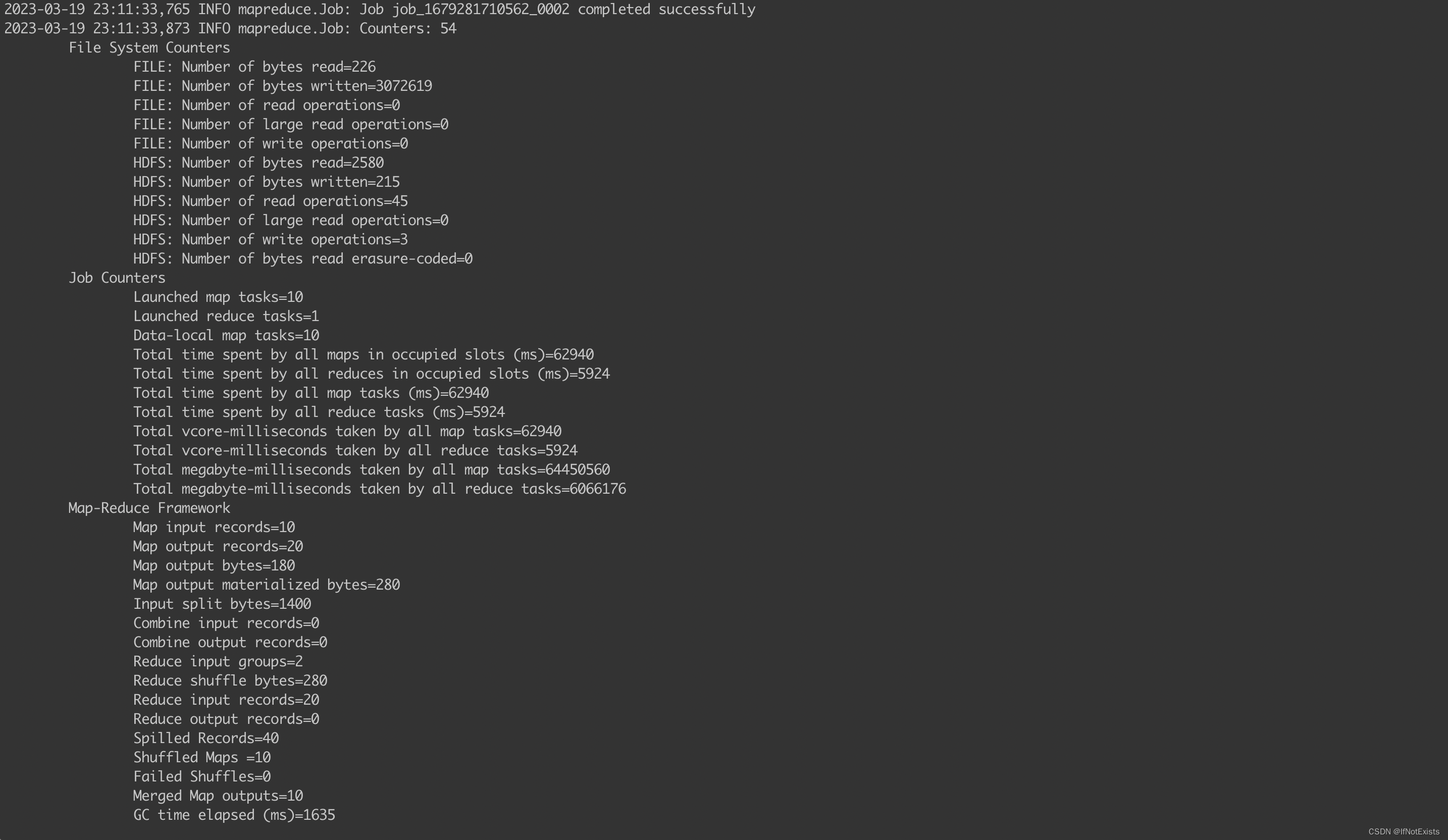
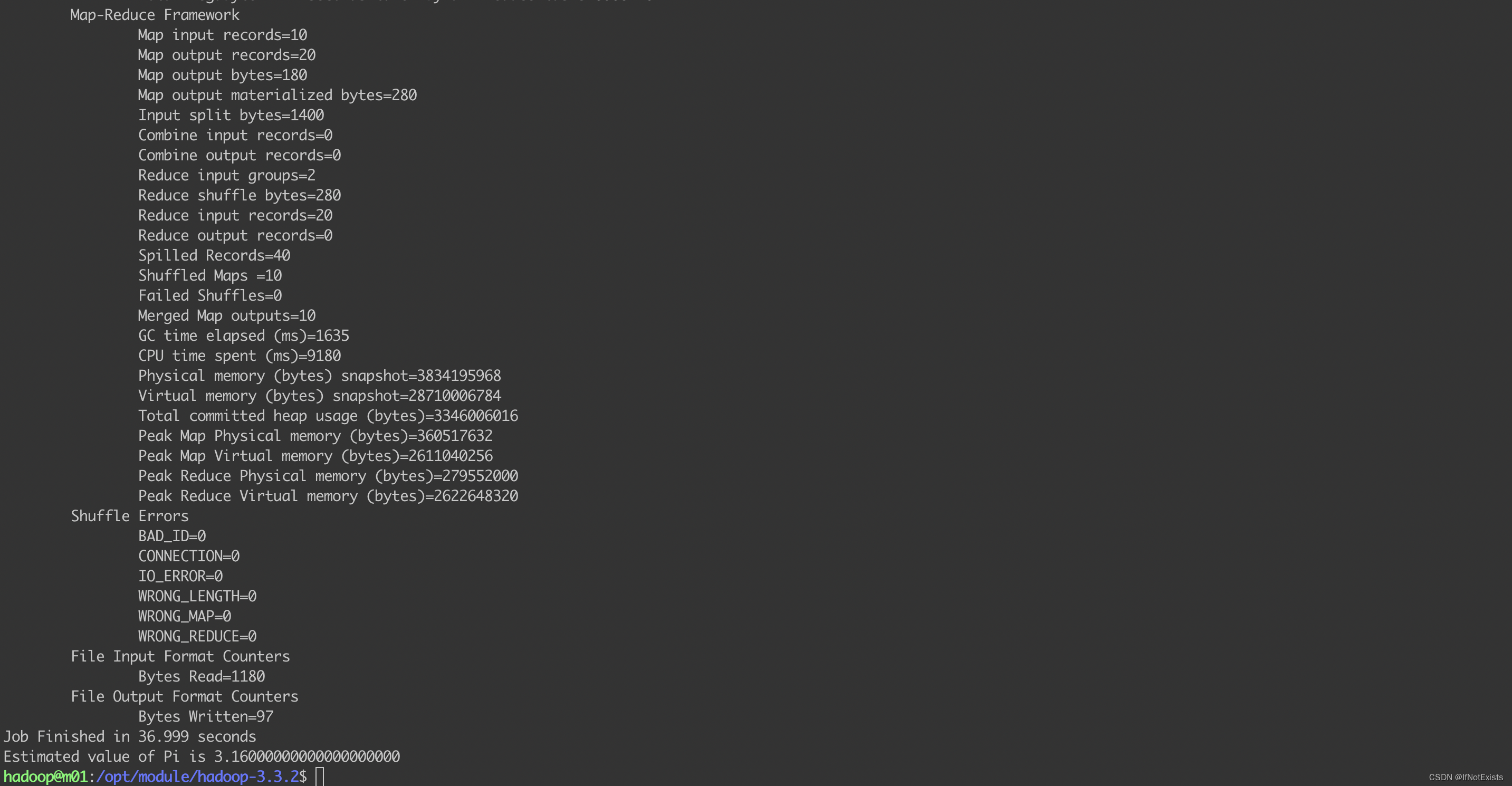
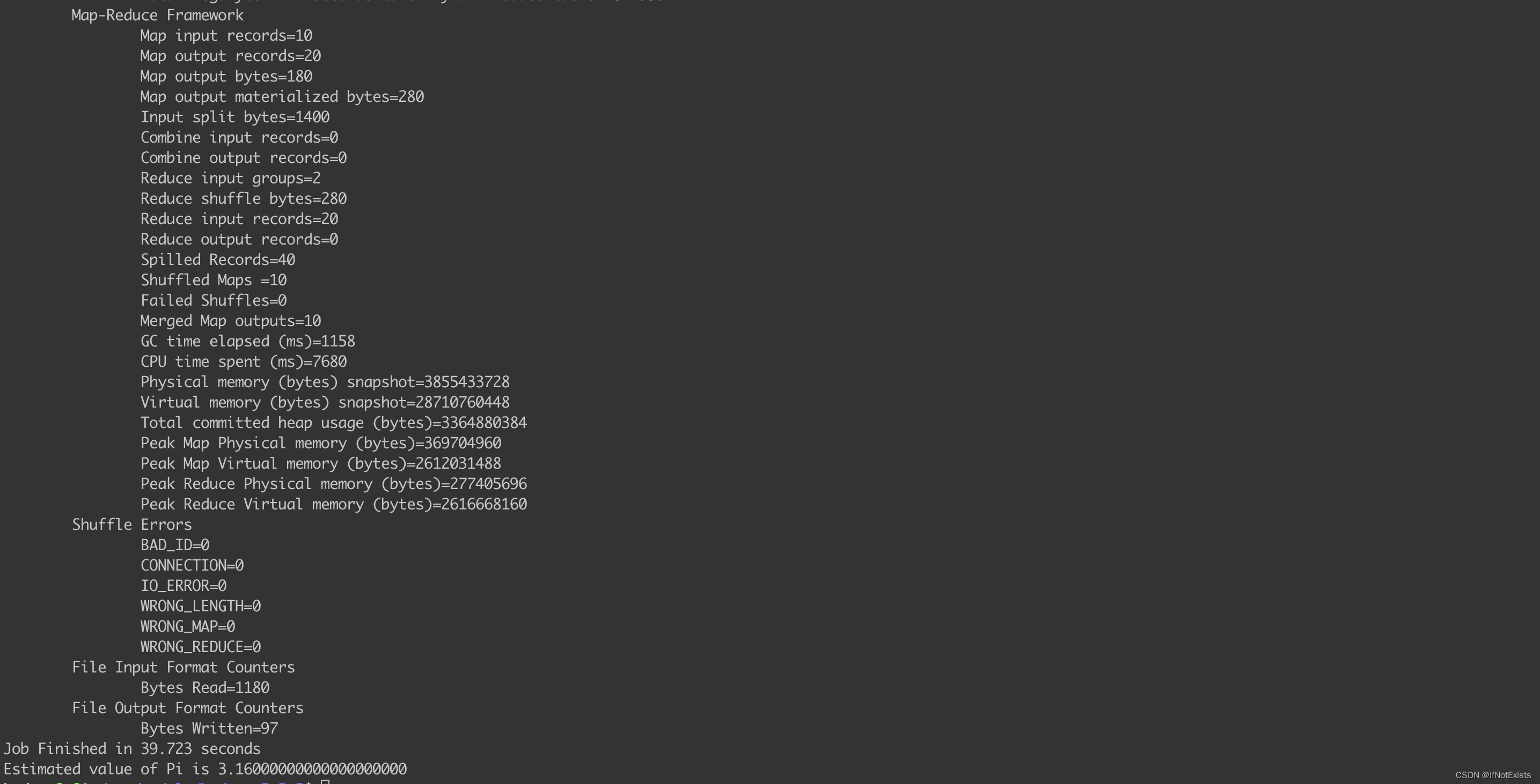
使用官方提供的测试用例,计算圆周率
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.2.jar pi 10 50

主备切换
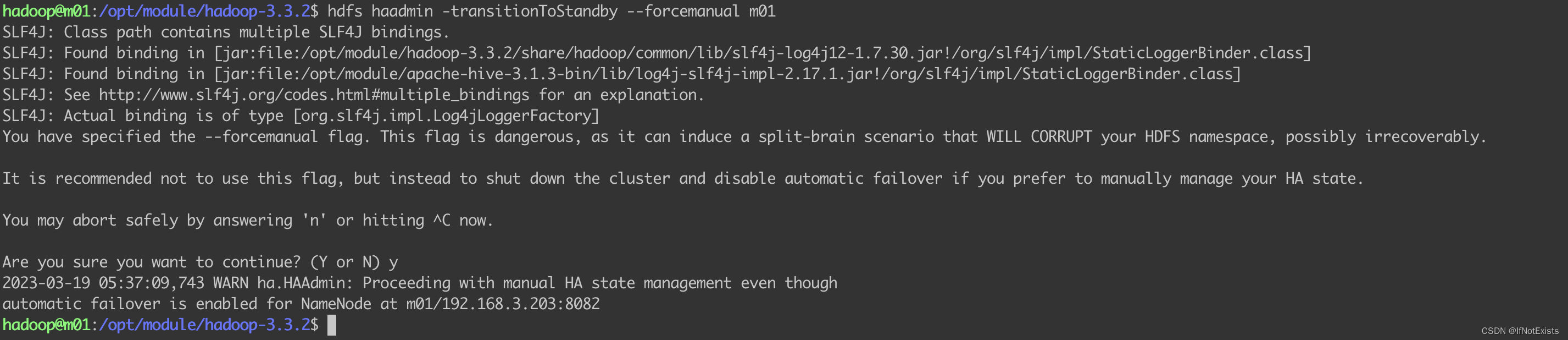
3.1 手动切换NameNode
#hdfs haadmin -getServiceState m01
此时m01处于active 状态

将m01 置为 standby 状态
hdfs haadmin -transitionToStandby --forcemanual m01
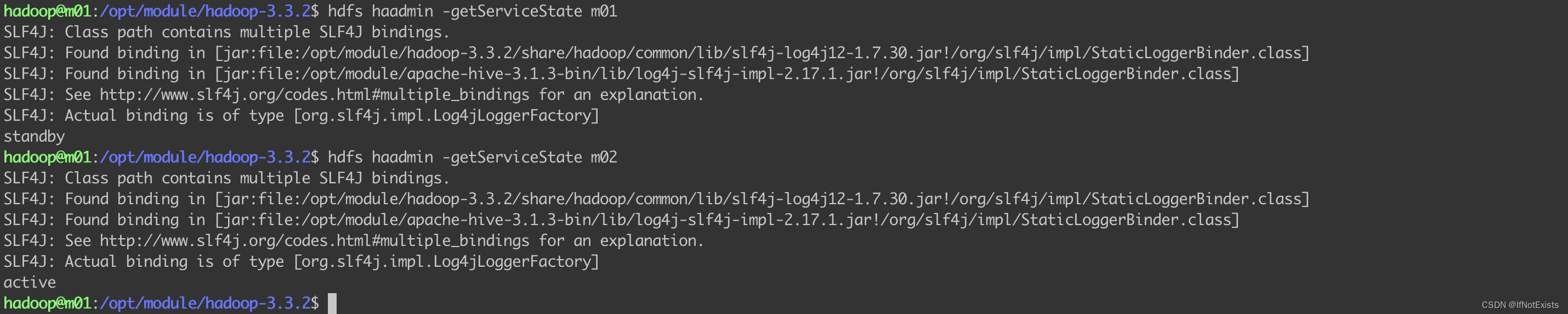
查看当前集群m01 m02 状态
注:
没有执行 hdfs haadmin -transitionToActive --forcemanual m02 将m02置为active状态,但 此时m02状态自动变更为active, 原因:hdfs-site 配置了失败自动切换。
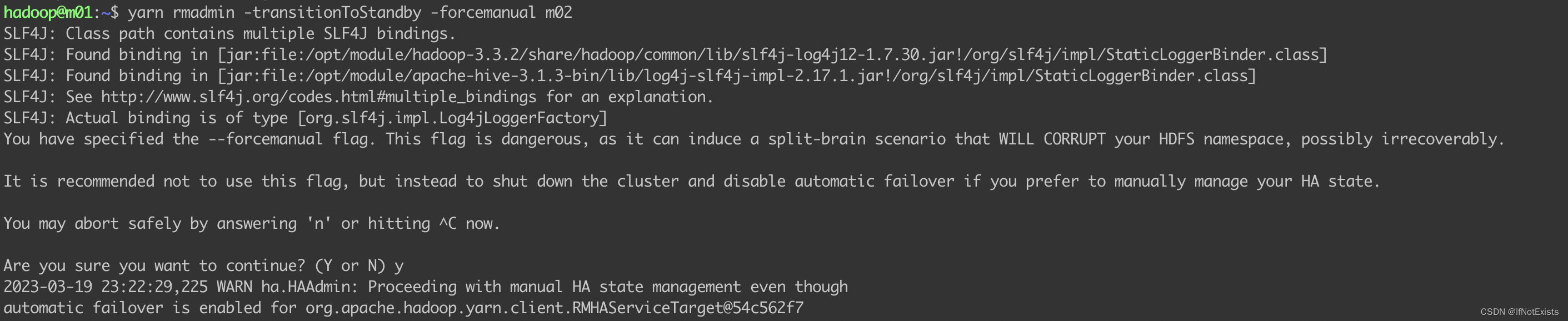
3.2 手动切换YARN
查看当前状态
yarn rmadmin -getAllServiceState

切换状态
yarn rmadmin -transitionToStandby -forcemanual m02
yarn rmadmin -transitionToActive -forcemanual m01
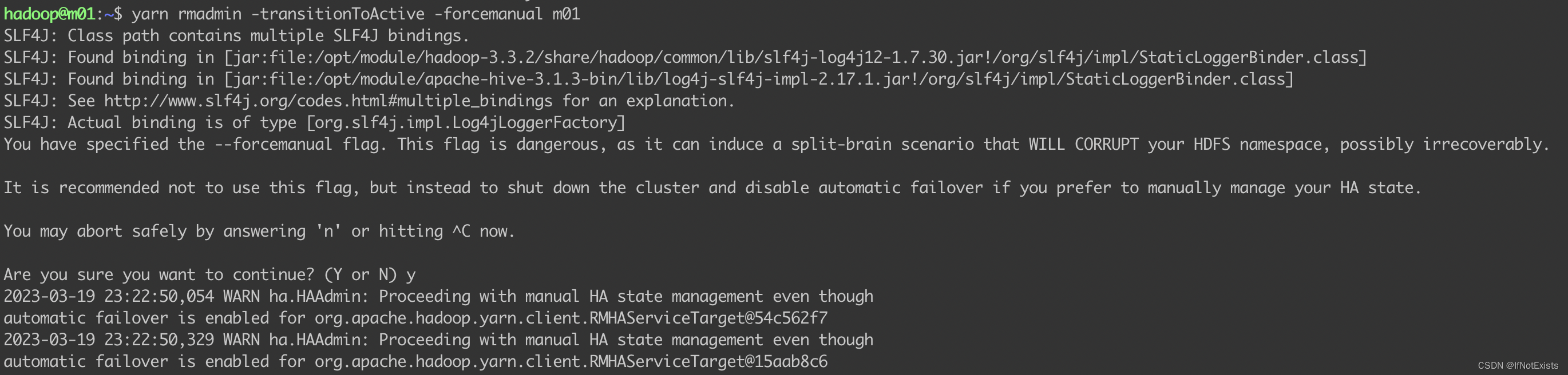
查看当前状态
yarn rmadmin -getAllServiceState

故障自动切换
4.1 NameNode 故障切换
查看当前状态
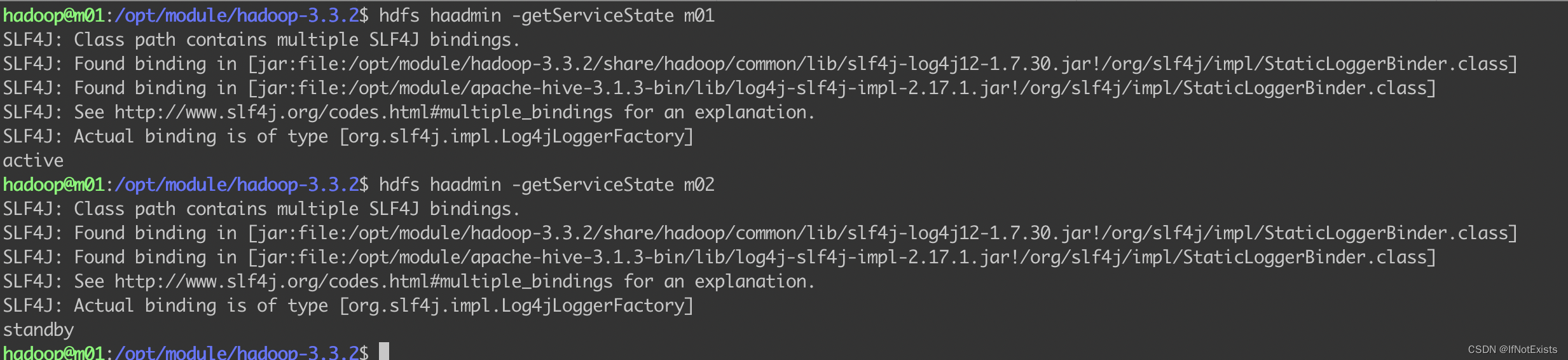
关停m01 上的namenode
hdfs --daemon stop namenode
查看状态

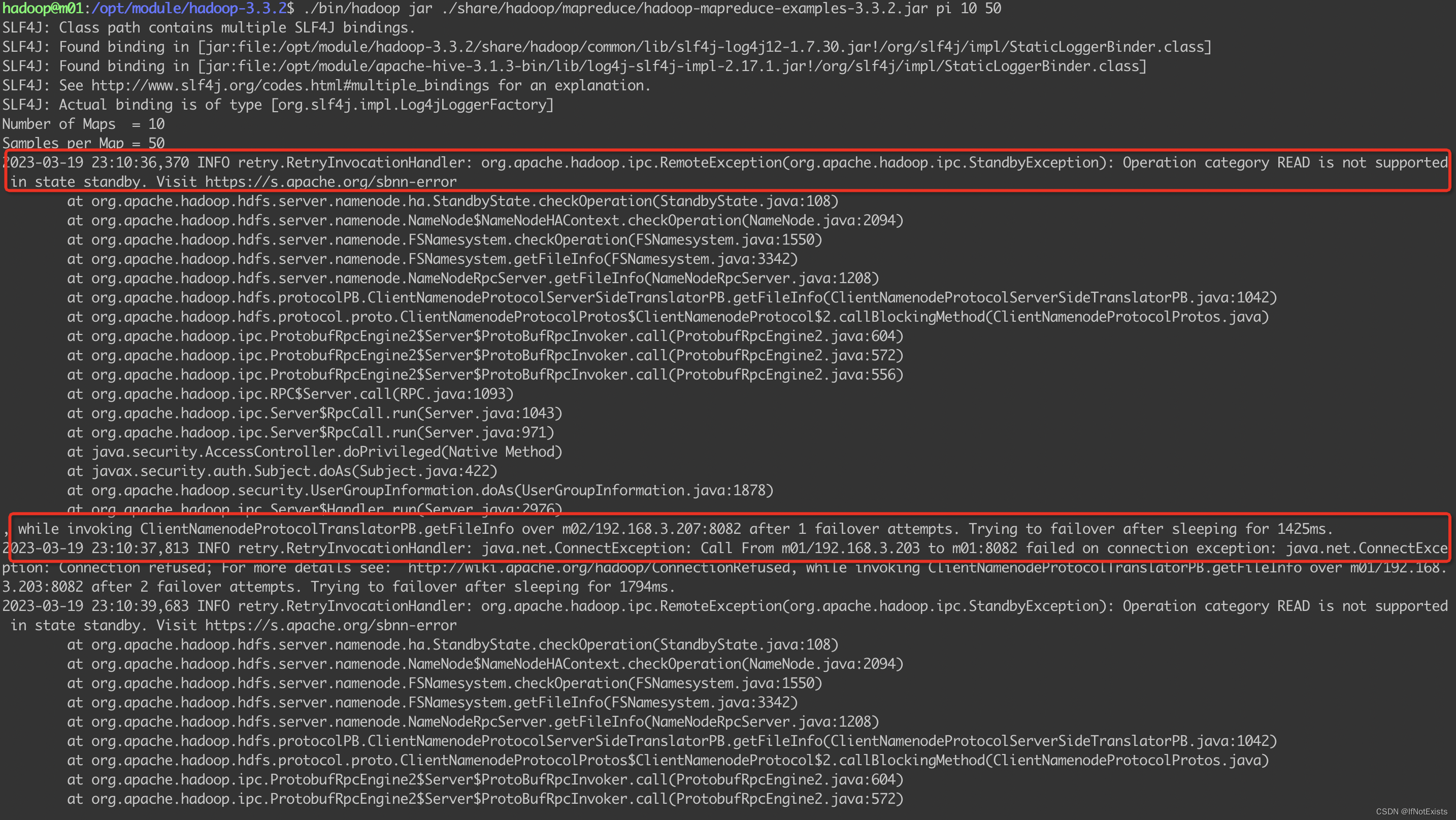
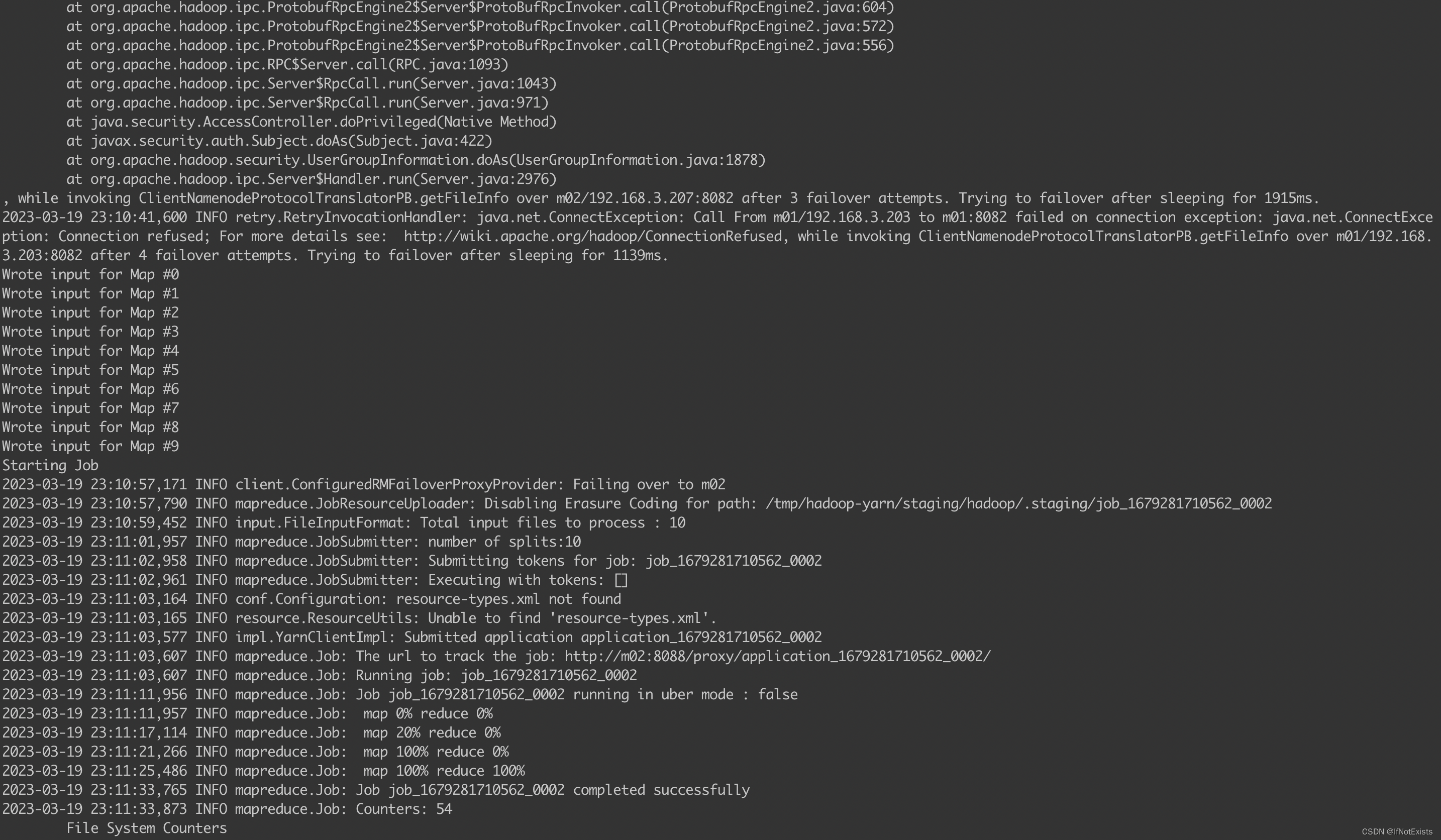
执行任务
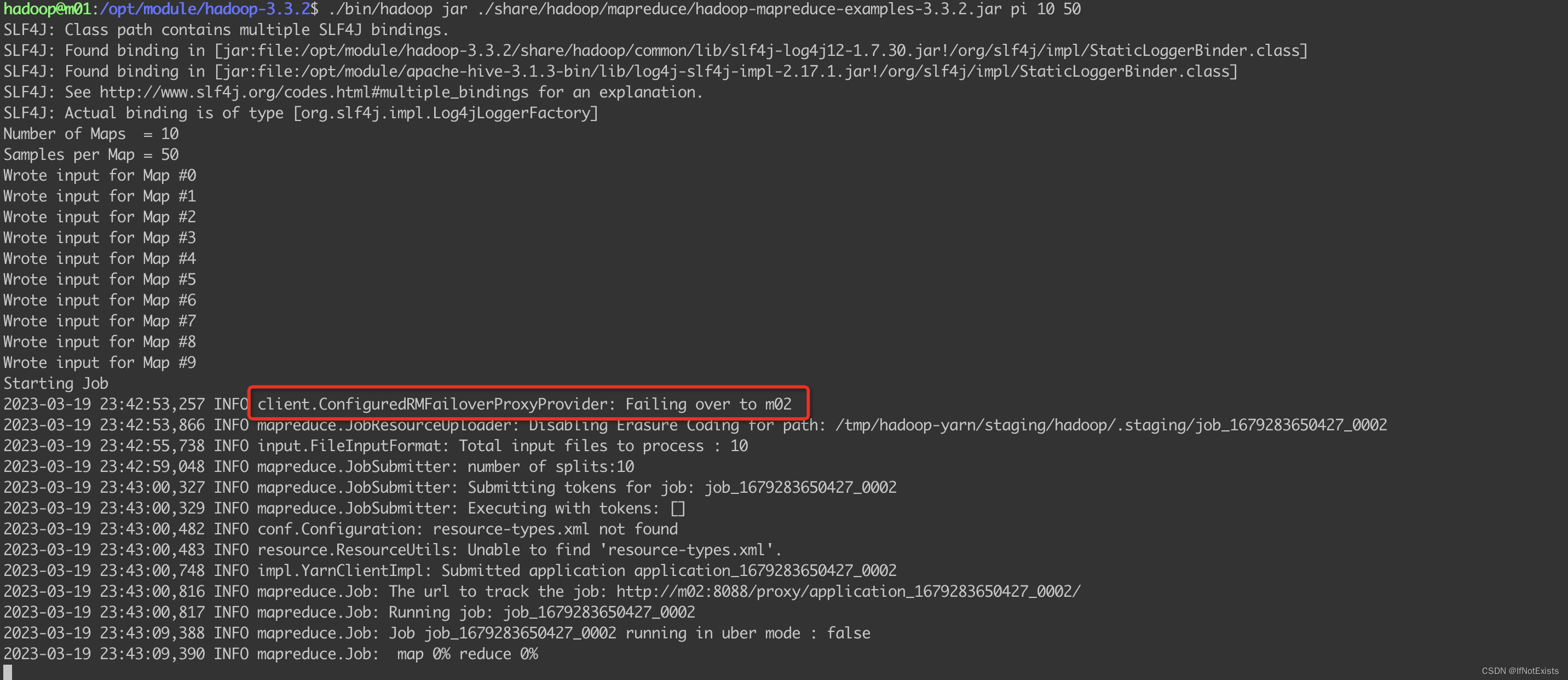
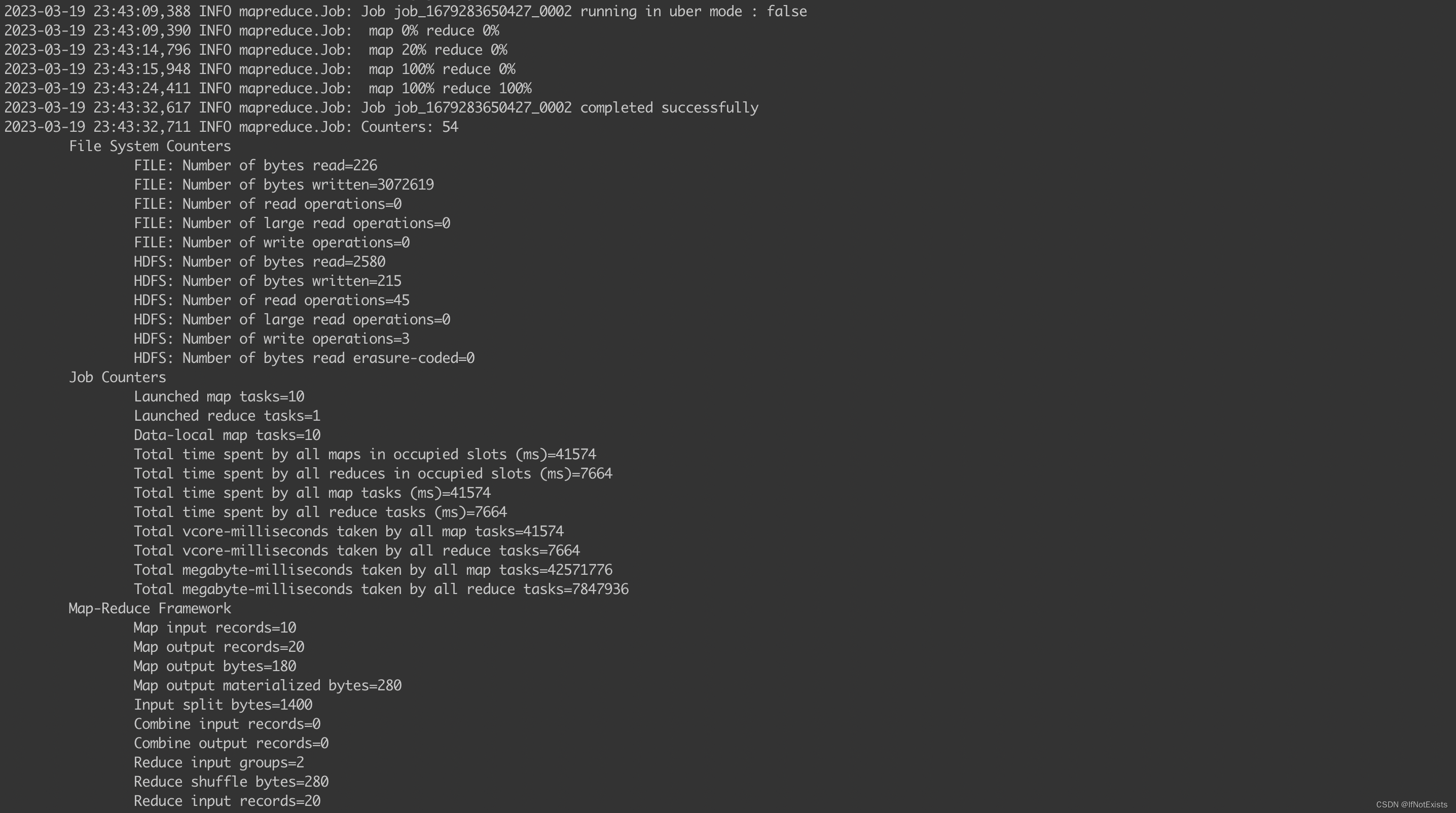
会发现过程中完成了一次主备节点切换
4.2 Yarn 故障切换
查看当前集群状态
yarn rmadmin -getAllServiceState

模拟m01故障
yarn --daemon stop resourcemanager

执行任务
5. 遗留问题
该测试集群2个namenode 节点,每次启动时m02都是active状态,原因待分析。

















 1188
1188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









