




简介:本资源集合提供一本涵盖数据结构与算法应用书籍的所有C++源代码实例,帮助学习者通过实践理解并掌握这些重要概念。内容包含各类链表、栈与队列、数组与向量、排序与搜索算法、树结构、图算法、哈希表、递归与分治策略、动态规划和贪心算法的实现,旨在提升C++编程技巧,为实际问题解决提供坚实基础。 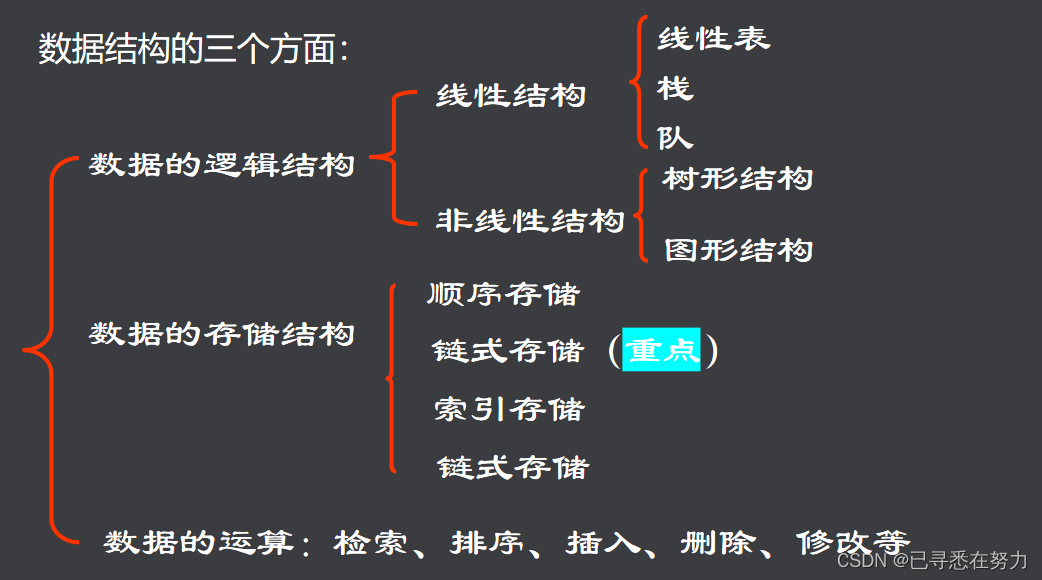
1. 数据结构与算法源代码概述
数据结构与算法的重要性
在编程领域,数据结构和算法是构建有效软件和解决复杂问题的基石。数据结构定义了信息如何存储和组织,而算法则指导如何操作这些信息。无论是初学者还是资深开发者,掌握它们都是提高开发效率和优化性能的关键。
源代码的作用
源代码是实现数据结构和算法思想的具体载体。通过阅读和分析源代码,我们可以深入理解其内在逻辑和运作机制。C++作为性能强劲的语言,在实现数据结构和算法方面尤为突出,其源代码能够提供出色的性能和灵活性。
学习目标
本系列文章旨在通过C++语言,详细探讨数据结构与算法的实现方式。从基础的线性结构到复杂的高级结构,以及排序、搜索算法,再到实际应用中的递归、动态规划与贪心算法,我们将逐步深入,为你展示如何编写高效、优雅的代码。让我们开始揭开数据结构与算法的神秘面纱,进入编程的深层次探索。
2. 线性数据结构的C++实现
2.1 链表的数据结构与C++实现
2.1.1 单向链表的定义和操作
单向链表是一种常见的线性数据结构,它的特点是节点之间通过指针连接,每个节点包含数据部分和指向下一个节点的指针。在C++中,单向链表可以通过结构体或类来实现。
struct Node {
int data; // 数据域
Node* next; // 指针域,指向下一个节点
};
class LinkedList {
private:
Node* head; // 链表头指针
public:
LinkedList() : head(nullptr) {} // 构造函数初始化头指针为null
// 向链表尾部添加元素
void append(int value) {
Node* newNode = new Node{value, nullptr};
if (head == nullptr) {
head = newNode;
return;
}
Node* current = head;
while (current->next != nullptr) {
current = current->next;
}
current->next = newNode;
}
// 其他链表操作函数...
};
单向链表的操作包括添加元素、删除元素、查找元素等。在添加元素时,新创建的节点始终被添加到链表的末尾。删除元素时,需要遍历链表来找到要删除节点的前一个节点,然后进行删除操作。查找元素则需要从头节点开始,逐个遍历直到找到目标节点或遍历完整个链表。
2.1.2 双向链表的定义和操作
双向链表是单向链表的扩展,它的每个节点除了有指向下一个节点的指针外,还有一个指向前一个节点的指针。双向链表可以更方便地进行向前和向后的遍历。
struct DoublyNode {
int data;
DoublyNode* prev; // 指向前一个节点
DoublyNode* next; // 指向下一个节点
};
class DoublyLinkedList {
private:
DoublyNode* head;
DoublyNode* tail;
public:
DoublyLinkedList() : head(nullptr), tail(nullptr) {}
// 在链表尾部添加元素
void append(int value) {
DoublyNode* newNode = new DoublyNode{value, tail, nullptr};
if (tail == nullptr) {
head = newNode;
} else {
tail->next = newNode;
}
tail = newNode;
if (head == nullptr) {
head = newNode;
}
}
// 双向链表的其他操作...
};
2.1.3 循环链表的定义和操作
循环链表是一种特殊类型的链表,其尾节点的指针不是指向null,而是指向链表的头节点,从而形成一个环。
struct CircularNode {
int data;
CircularNode* next;
};
class CircularLinkedList {
private:
CircularNode* head;
CircularNode* tail;
public:
CircularLinkedList() : head(nullptr), tail(nullptr) {}
// 向循环链表添加元素
void append(int value) {
CircularNode* newNode = new CircularNode{value, nullptr};
if (head == nullptr) {
head = newNode;
tail = newNode;
newNode->next = head;
} else {
tail->next = newNode;
newNode->next = head;
tail = newNode;
}
}
// 循环链表的其他操作...
};
以上代码展示了不同种类链表的基础实现。每一种链表都有其特定的应用场景。例如,单向链表适合快速插入和删除操作,特别是在链表尾部;而循环链表由于其结构特性,常用于设计如约瑟夫环问题等特殊算法。这些基础操作为链表的进一步应用打下了坚实的基础。
3. 集合数据结构的C++实现
集合数据结构是处理一组数据元素的组织方式,这些数据元素具有某些共同的特性。在C++中,集合数据结构通常用于存储和管理数据,以便快速检索和操作。本章将探讨数组与向量、哈希表等常用集合数据结构的现代C++实现方式,并分析它们的性能和实现细节。
3.1 数组与向量的现代C++实现
数组是C++中最基本的数据结构之一,而向量(vector)则是C++标准模板库(STL)中的一种动态数组实现,提供了更加灵活和强大的功能。在现代C++编程中,向量通常替代了传统的静态数组。
3.1.1 动态数组vector的使用
动态数组vector在C++中的使用极为广泛,它能够根据元素的插入和删除自动调整其大小。这种灵活性使得vector成为处理不确定数量元素的理想选择。vector支持随机访问,即可以通过索引直接访问任意位置的元素。
#include <vector>
int main() {
std::vector<int> vec; // 创建一个int类型的vector
// 插入元素
vec.push_back(10);
vec.push_back(20);
vec.push_back(30);
// 访问元素
std::cout << "The second element is: " << vec[1] << std::endl;
// 遍历vector
for (auto i : vec) {
std::cout << i << ' ';
}
// 清空vector中的元素
vec.clear();
return 0;
}
以上代码展示了如何创建一个vector对象、添加元素、访问元素、遍历元素以及清空vector。在实际应用中,vector的容量管理对于性能至关重要,特别是当vector中存储了大量数据时,频繁的内存分配和释放将影响程序的执行效率。
3.1.2 数组与向量性能比较
当决定使用数组还是向量时,需要考虑内存管理和性能方面的问题。静态数组在编译时大小就已确定,因此它不涉及动态内存分配,这意味着对于小规模数据集来说,使用静态数组可能会更加高效。而向量由于其动态特性,能够支持运行时大小的变化,因此更适合于数据规模不确定的情况。
3.1.3 vector的自定义迭代器实现
迭代器是C++ STL中的一个关键概念,它提供了一种访问容器(如vector)中元素的方式,而无需暴露容器的内部结构。自定义迭代器允许开发者根据特定需求定制容器的行为。
template <typename T>
class CustomIterator {
public:
using iterator_category = std::random_access_iterator_tag;
using value_type = T;
using difference_type = ptrdiff_t;
using pointer = T*;
using reference = T&;
CustomIterator(pointer ptr) : ptr_(ptr) {}
// 迭代器的运算符重载
reference operator*() const { return *ptr_; }
pointer operator->() const { return ptr_; }
reference operator[](difference_type n) const { return *(ptr_ + n); }
// 前缀和后缀运算符
CustomIterator& operator++() { ++ptr_; return *this; }
CustomIterator operator++(int) { CustomIterator tmp(*this); ++(*this); return tmp; }
CustomIterator& operator--() { --ptr_; return *this; }
CustomIterator operator--(int) { CustomIterator tmp(*this); --(*this); return tmp; }
bool operator==(const CustomIterator& other) const { return ptr_ == other.ptr_; }
bool operator!=(const CustomIterator& other) const { return ptr_ != other.ptr_; }
private:
pointer ptr_;
};
// 迭代器在vector的实现中非常关键
上面的代码展示了如何定义一个自定义迭代器,并在vector的实现中使用它。迭代器的定义需要遵循C++的迭代器模式,包括指针运算符重载和比较操作符等。
通过本章节的介绍,我们深入理解了数组与向量在现代C++中的使用和实现,以及它们在性能方面的考量。接下来,我们将探讨哈希表的C++实现,它在集合数据结构中扮演着重要的角色,尤其是在快速检索和插入场景中。
4. 高级数据结构的C++实现
4.1 树结构的实现
4.1.1 二叉树的定义和遍历
二叉树是每个节点最多有两个子树的树结构,通常子树被称作“左子树”和“右子树”。二叉树在计算机科学中有许多应用,如二叉搜索树、平衡树和堆等。
struct TreeNode {
int value;
TreeNode *left;
TreeNode *right;
TreeNode(int x) : value(x), left(nullptr), right(nullptr) {}
};
void preOrderTraversal(TreeNode* root) {
if (root == nullptr) return;
std::cout << root->value << " ";
preOrderTraversal(root->left);
preOrderTraversal(root->right);
}
void inOrderTraversal(TreeNode* root) {
if (root == nullptr) return;
inOrderTraversal(root->left);
std::cout << root->value << " ";
inOrderTraversal(root->right);
}
void postOrderTraversal(TreeNode* root) {
if (root == nullptr) return;
postOrderTraversal(root->left);
postOrderTraversal(root->right);
std::cout << root->value << " ";
}
- 在这段代码中,我们定义了一个简单的二叉树节点结构,并实现了三种遍历方式:前序遍历(
preOrderTraversal)、中序遍历(inOrderTraversal)和后序遍历(postOrderTraversal)。遍历过程中,每个节点都会被访问一次,并可以在此基础上进行进一步的操作,如打印节点值。 - 前序遍历首先访问根节点,然后递归地前序遍历左子树,接着递归地前序遍历右子树。
- 中序遍历先递归地中序遍历左子树,然后访问根节点,最后递归地中序遍历右子树。
- 后序遍历先递归地后序遍历左子树,然后递归地后序遍历右子树,最后访问根节点。
4.1.2 二叉搜索树的实现和平衡策略
二叉搜索树(BST)是一种特殊的二叉树,它满足:对于任何节点,其左子树中的所有元素的值都小于该节点的值,其右子树中的所有元素的值都大于该节点的值。这使得二叉搜索树在进行查找操作时效率较高。
class BinarySearchTree {
public:
BinarySearchTree() : root(nullptr) {}
void insert(int value) {
root = insertIntoBST(root, value);
}
TreeNode* search(int value) {
return searchBST(root, value);
}
private:
TreeNode* root;
TreeNode* insertIntoBST(TreeNode* node, int value) {
if (node == nullptr) return new TreeNode(value);
if (value < node->value) {
node->left = insertIntoBST(node->left, value);
} else {
node->right = insertIntoBST(node->right, value);
}
return node;
}
TreeNode* searchBST(TreeNode* node, int value) {
if (node == nullptr || node->value == value) {
return node;
}
return value < node->value ? searchBST(node->left, value) : searchBST(node->right, value);
}
};
- 在二叉搜索树的实现中,我们定义了一个
BinarySearchTree类,其中包含插入(insert)和查找(search)操作。插入操作中,我们将新值插入为叶子节点,并保持BST的性质。查找操作则在树中递归地寻找一个值。 - 平衡策略对于维持BST的性能至关重要。在最坏的情况下,BST可能退化为链表,导致查找时间复杂度变为O(n)。为了保持树的平衡,可以使用AVL树或红黑树等自平衡二叉搜索树。
4.1.3 平衡树如AVL树的实现
AVL树是一种自平衡的二叉搜索树,任何节点的两个子树的高度最大差别为1,这使得AVL树在增加、删除和查找元素时,都能保持相对的平衡状态,从而保证了操作的时间复杂度为O(log n)。
class AVLTree : public BinarySearchTree {
public:
void insert(int value) override {
root = insertIntoAVL(root, value);
}
TreeNode* remove(int value) {
root = removeNode(root, value);
}
private:
TreeNode* insertIntoAVL(TreeNode* node, int value) {
// Insert as usual and update height of ancestors
if (node == nullptr) return new TreeNode(value);
if (value < node->value) {
node->left = insertIntoAVL(node->left, value);
} else {
node->right = insertIntoAVL(node->right, value);
}
// Update height of this ancestor node
node->height = 1 + std::max(height(node->left), height(node->right));
// Rebalance if needed
return balance(node);
}
TreeNode* balance(TreeNode* node) {
// Balance according to AVL tree balance factors
int balanceFactor = getBalance(node);
if (balanceFactor > 1) {
if (getBalance(node->left) < 0) {
node->left = rotateLeft(node->left);
}
return rotateRight(node);
}
if (balanceFactor < -1) {
if (getBalance(node->right) > 0) {
node->right = rotateRight(node->right);
}
return rotateLeft(node);
}
return node;
}
// Other AVL operations and helper functions...
};
- 在这段代码中,我们继承了
BinarySearchTree类并重写了插入和删除方法。在每次插入或删除节点后,我们更新节点的高度,并检查是否需要进行平衡操作。 - 平衡操作包括旋转,通过旋转可以调整子树的高度差,维持AVL树的平衡性质。AVL树的旋转有四种类型:左旋、右旋、左右双旋和右左双旋。这些旋转操作通过
rotateLeft和rotateRight函数实现。 - 通过保持树的平衡,AVL树确保了所有基本操作(插入、删除、查找)的高效性,尤其在面对大量动态数据时。
在本节中,我们介绍了二叉树的基础概念,包括定义、遍历方法,以及二叉搜索树和AVL树的实现和平衡策略。这些高级数据结构在实际应用中对数据的高效管理至关重要,如数据库索引、语言处理中的解析树等。下一节中,我们将探讨图算法的C++实现,包括图的表示方法和基本的图算法。
5. 排序与搜索算法的C++实现
5.1 排序算法的C++实现
5.1.1 基本排序算法:冒泡、选择和插入排序
冒泡排序(Bubble Sort)
冒泡排序是最简单直观的排序算法之一,它重复地遍历要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。遍历数列的工作是重复进行直到没有再需要交换,也就是说该数列已经排序完成。这种算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
void bubbleSort(int arr[], int n) {
for (int i = 0; i < n-1; i++) {
for (int j = 0; j < n-i-1; j++) {
if (arr[j] > arr[j+1]) {
std::swap(arr[j], arr[j+1]);
}
}
}
}
上述代码中,我们进行了两层循环。外层循环决定冒泡排序的轮数,内层循环进行相邻元素的比较和可能的交换操作。每一轮排序后,最大的元素会被放置在它最终的位置上。
选择排序(Selection Sort)
选择排序算法是一种原址比较排序算法。首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
void selectionSort(int arr[], int n) {
int min_idx;
for (int i = 0; i < n-1; i++) {
min_idx = i;
for (int j = i+1; j < n; j++) {
if (arr[j] < arr[min_idx]) {
min_idx = j;
}
}
std::swap(arr[i], arr[min_idx]);
}
}
在选择排序中,每一轮迭代都会找到未排序部分的最小元素,并将其与未排序部分的起始位置交换。这个过程会持续到整个数组被排序完成。
插入排序(Insertion Sort)
插入排序的工作方式像许多人排序一副扑克牌。开始时,我们的左手为空,牌面朝下放在桌上。接着,我们每次从桌上拿走一张牌,将它插入到左手的手指之间。为了找到合适的插入位置,我们从右到左将手指之间的牌逐步向右移动,直到找到一张牌面小于插入牌的牌。
void insertionSort(int arr[], int n) {
int key, j;
for (int i = 1; i < n; i++) {
key = arr[i];
j = i - 1;
while (j >= 0 && arr[j] > key) {
arr[j + 1] = arr[j];
j = j - 1;
}
arr[j + 1] = key;
}
}
插入排序中,我们从数组的第二个元素开始,因为第一个元素默认是已经排序的。对于每个元素,我们将其插入到已排序的数组部分中适当的位置。通过不断与左边的元素比较,直到找到一个小于或等于它的元素,然后将该元素放到当前位置。
5.1.2 高级排序算法:快速排序、归并排序和堆排序
快速排序(Quick Sort)
快速排序是一种分而治之的排序算法,其基本步骤包括选择一个“基准”元素,然后将数组分成两个子数组,一个包含所有小于基准的元素,另一个包含所有大于基准的元素。递归地对这两个子数组进行快速排序,然后将结果合并。
int partition(int arr[], int low, int high) {
int pivot = arr[high];
int i = (low - 1);
for (int j = low; j <= high - 1; j++) {
if (arr[j] < pivot) {
i++;
std::swap(arr[i], arr[j]);
}
}
std::swap(arr[i + 1], arr[high]);
return (i + 1);
}
void quickSort(int arr[], int low, int high) {
if (low < high) {
int pi = partition(arr, low, high);
quickSort(arr, low, pi - 1);
quickSort(arr, pi + 1, high);
}
}
快速排序的性能在最坏情况下是O(n^2),但平均情况下它的效率很高,时间复杂度为O(nlogn)。
归并排序(Merge Sort)
归并排序是建立在归并操作上的一种有效的排序算法,这种排序算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。
void merge(int arr[], int l, int m, int r) {
int i, j, k;
int n1 = m - l + 1;
int n2 = r - m;
int L[n1], R[n2];
for (i = 0; i < n1; i++)
L[i] = arr[l + i];
for (j = 0; j < n2; j++)
R[j] = arr[m + 1 + j];
i = 0;
j = 0;
k = l;
while (i < n1 && j < n2) {
if (L[i] <= R[j]) {
arr[k] = L[i];
i++;
} else {
arr[k] = R[j];
j++;
}
k++;
}
while (i < n1) {
arr[k] = L[i];
i++;
k++;
}
while (j < n2) {
arr[k] = R[j];
j++;
k++;
}
}
void mergeSort(int arr[], int l, int r) {
if (l < r) {
int m = l + (r - l) / 2;
mergeSort(arr, l, m);
mergeSort(arr, m + 1, r);
merge(arr, l, m, r);
}
}
归并排序的稳定性能较好,且时间复杂度始终是O(nlogn),但其空间复杂度较高,因为需要额外的内存空间用于合并。
堆排序(Heap Sort)
堆排序是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子节点的键值或索引总是小于(或者大于)它的父节点。
void heapify(int arr[], int n, int i) {
int largest = i; // Initialize largest as root
int l = 2 * i + 1; // left = 2*i + 1
int r = 2 * i + 2; // right = 2*i + 2
if (l < n && arr[l] > arr[largest])
largest = l;
if (r < n && arr[r] > arr[largest])
largest = r;
if (largest != i) {
std::swap(arr[i], arr[largest]);
heapify(arr, n, largest);
}
}
void heapSort(int arr[], int n) {
for (int i = n / 2 - 1; i >= 0; i--)
heapify(arr, n, i);
for (int i = n - 1; i > 0; i--) {
std::swap(arr[0], arr[i]);
heapify(arr, i, 0);
}
}
堆排序的时间复杂度在最坏、平均和最佳情况下均为O(nlogn)。堆排序不是稳定的排序算法。
5.1.3 各排序算法的时间复杂度分析
排序算法的时间复杂度分析通常涉及以下三个方面:
- 最佳情况(Best Case):需要进行的比较次数最少。
- 平均情况(Average Case):随机排列的元素需要的比较次数。
- 最坏情况(Worst Case):数组已经排序好或者逆序时,需要进行的比较次数最多。
下面是一个表格展示这三种情况下的时间复杂度:
| 排序算法 | 最佳情况 | 平均情况 | 最坏情况 | |-----------|----------|----------|----------| | 冒泡排序 | O(n) | O(n^2) | O(n^2) | | 选择排序 | O(n^2) | O(n^2) | O(n^2) | | 插入排序 | O(n) | O(n^2) | O(n^2) | | 快速排序 | O(nlogn) | O(nlogn) | O(n^2) | | 归并排序 | O(nlogn) | O(nlogn) | O(nlogn) | | 堆排序 | O(nlogn) | O(nlogn) | O(nlogn) |
如表格所示,归并排序和堆排序在各种情况下均具有较好的性能。而快速排序在平均情况下性能最佳,但在最坏情况下会退化到O(n^2)。冒泡排序和插入排序在最佳情况下能达到线性时间复杂度,但在最坏情况下性能较差。选择排序在任何情况下均保持不变,即总是O(n^2)。
6. 算法思想在C++中的应用
6.1 递归与分治策略的应用
6.1.1 递归的基本概念和典型问题
递归是一种在解决问题时经常使用的编程技术,它允许一个函数直接或间接调用自身。递归函数通常包含两个基本部分:基本情况(base case)和递归情况(recursive case)。基本情况是递归调用的出口,它定义了问题的最简单形式;递归情况则将原问题分解为更小的子问题,并递归调用函数本身来解决这些子问题。
在C++中实现递归时,必须仔细定义基本情况以避免无限递归,同时确保每次递归调用都在向基本情况靠拢。递归非常适合解决分治策略可以应用的问题,例如树的遍历、汉诺塔问题、快速排序等。
让我们以计算阶乘为例来深入理解递归的概念。阶乘函数 n! 定义为n乘以所有小于n的正整数的乘积。用递归方式计算阶乘可以定义为:
int factorial(int n) {
if (n <= 1) {
return 1; // 基本情况
} else {
return n * factorial(n - 1); // 递归情况
}
}
在这个例子中,基本情况是 n <= 1 时返回1,因为0!和1!都等于1。递归情况是 n > 1 时,函数调用自身来计算 (n-1)! ,并将结果乘以 n 。
6.1.2 分治策略的基本原理及其应用实例
分治策略是一种递归式的问题解决方法。它的基本思想是将一个难以直接解决的大问题分解成一些规模较小的相同问题,递归解决这些子问题,然后合并这些子问题的解以得出原问题的解。
分治策略的一般步骤如下: 1. 分解 :将原问题分解成若干个规模较小的同类问题。 2. 解决 :若子问题足够小,则直接求解;否则递归求解各个子问题。 3. 合并 :将子问题的解合并成原问题的解。
分治策略在C++中的典型应用包括快速排序和归并排序算法。快速排序的基本步骤包括: 1. 选择一个“基准”元素。 2. 将数组分为两个子数组:小于基准的元素和大于基准的元素。 3. 递归地对这两个子数组进行快速排序。 4. 合并排序好的子数组。
下面是一个递归实现的快速排序示例代码:
void quicksort(int arr[], int low, int high) {
if (low < high) {
int pivot = partition(arr, low, high); // 分区操作
quicksort(arr, low, pivot - 1); // 递归排序左子数组
quicksort(arr, pivot + 1, high); // 递归排序右子数组
}
}
在快速排序的代码中, partition 函数负责根据基准值将数组分为两部分,而 quicksort 函数递归地对左右两部分进行排序。
6.1.3 分治与递归的性能分析和优化
虽然分治策略和递归是解决复杂问题的强大工具,但它们也可能导致性能问题,特别是在递归深度较大时。递归函数通常会占用较多的调用栈空间,而频繁的函数调用也可能导致性能开销。此外,如果递归调用没有有效地将问题规模减小,则可能导致重复工作和不必要的性能损失。
为了优化分治策略和递归的性能,我们可以采取以下措施:
-
尾递归优化 :在某些编译器和语言中,如果递归函数是函数体中的最后一个动作,则编译器可以优化这个递归调用,减少栈空间的使用。C++标准尚未强制要求实现尾递归优化,但一些编译器实现了该优化。
-
迭代替代递归 :对于某些可以容易地转换为循环的递归算法,将递归转换为迭代可以减少调用栈的开销。例如,用循环实现的快速排序往往比递归版本更高效。
-
记忆化(Memoization) :这是一种缓存技术,它存储递归函数的中间结果,避免重复计算。例如,在计算斐波那契数列时,通过存储已经计算过的值,可以显著减少递归调用次数。
-
剪枝(Pruning) :在递归过程中,有时可以通过逻辑判断跳过一些不必要的子问题的求解,这称为剪枝。这在一些搜索算法中特别有用,可以减少不必要的计算量。
下面是一个带有记忆化的斐波那契数列计算的例子:
#include <iostream>
#include <map>
std::map<int, long long> memo;
long long fibonacci(int n) {
if (n == 0) return 0;
if (n == 1) return 1;
if (memo.find(n) != memo.end()) return memo[n]; // 查找缓存
memo[n] = fibonacci(n - 1) + fibonacci(n - 2); // 递归计算并存储结果
return memo[n];
}
在这个例子中,我们使用了一个 map 作为缓存来存储已经计算过的斐波那契数值。当我们再次需要计算一个已经计算过的值时,我们直接从缓存中取结果,避免了重复计算。这种方法特别适合于具有大量重复子问题的递归算法。
通过这些性能优化技术,我们可以更高效地利用分治策略和递归方法来解决复杂的算法问题。
7. 设计模式与软件架构优化
在软件开发过程中,设计模式是为了解决特定问题而总结出来的一套行之有效的解决方案模板。它们是软件设计中常见问题的典型解决方案,有助于提升代码的可维护性、可扩展性和可重用性。本章将探讨设计模式在C++中的应用,并结合软件架构优化的实践。
7.1 设计模式的分类和C++实现
设计模式通常被分为三大类:创建型模式、结构型模式和行为型模式。每种类型包含若干个模式,比如工厂模式、单例模式、策略模式等。
7.1.1 创建型模式
创建型模式关注对象的创建过程,提供了灵活的实例化接口。在C++中,常见的创建型模式有:
单例模式
单例模式确保一个类只有一个实例,并提供一个全局访问点。这是实现共享资源控制的常见手段。
class Singleton {
private:
static Singleton *instance;
protected:
Singleton() {}
public:
static Singleton *getInstance() {
if (instance == nullptr) {
instance = new Singleton();
}
return instance;
}
};
Singleton *Singleton::instance = nullptr;
int main() {
// 使用单例
Singleton *s1 = Singleton::getInstance();
Singleton *s2 = Singleton::getInstance();
// s1 和 s2 实际指向的是同一个对象
return 0;
}
工厂模式
工厂模式通过定义一个创建对象的接口,但让实现这个接口的类来决定实例化哪一个类。
class Product {
public:
virtual void operation() = 0;
virtual ~Product() {}
};
class ConcreteProductA : public Product {
public:
void operation() override {
std::cout << "Product A Operation" << std::endl;
}
};
class ConcreteProductB : public Product {
public:
void operation() override {
std::cout << "Product B Operation" << std::endl;
}
};
class Creator {
public:
virtual Product* factoryMethod() = 0;
Product* operation() {
Product* product = factoryMethod();
product->operation();
return product;
}
};
class ConcreteCreatorA : public Creator {
public:
Product* factoryMethod() override {
return new ConcreteProductA();
}
};
class ConcreteCreatorB : public Creator {
public:
Product* factoryMethod() override {
return new ConcreteProductB();
}
};
int main() {
Creator *creatorA = new ConcreteCreatorA();
creatorA->operation();
Creator *creatorB = new ConcreteCreatorB();
creatorB->operation();
return 0;
}
7.1.2 结构型模式
结构型模式涉及如何组合类和对象以获得更大的结构。典型模式包括适配器模式、装饰器模式、代理模式等。
适配器模式
适配器模式允许将一个类的接口转换成客户端期望的另一个接口。它使原本接口不兼容的类可以在一起工作。
class Target {
public:
virtual void request() = 0;
virtual ~Target() {}
};
class Adaptee {
public:
void specificRequest() {
std::cout << "Adaptee::specificRequest()" << std::endl;
}
};
class Adapter : public Target {
private:
Adaptee *adaptee;
public:
Adapter() {
adaptee = new Adaptee();
}
virtual void request() override {
adaptee->specificRequest();
}
virtual ~Adapter() {
delete adaptee;
}
};
int main() {
Target *adapter = new Adapter();
adapter->request();
return 0;
}
7.1.3 行为型模式
行为型模式专注于对象之间的通信。常见的行为型模式包括策略模式、观察者模式、命令模式等。
策略模式
策略模式定义一系列算法,封装每个算法,并使它们可互换。策略模式让算法的变化独立于使用算法的客户。
class Strategy {
public:
virtual void algorithmInterface() = 0;
virtual ~Strategy() {}
};
class ConcreteStrategyA : public Strategy {
public:
void algorithmInterface() override {
std::cout << "Algorithm A" << std::endl;
}
};
class ConcreteStrategyB : public Strategy {
public:
void algorithmInterface() override {
std::cout << "Algorithm B" << std::endl;
}
};
class Context {
private:
Strategy *strategy;
public:
Context(Strategy *strategy) {
this->strategy = strategy;
}
void contextInterface() {
strategy->algorithmInterface();
}
};
int main() {
Strategy *strategyA = new ConcreteStrategyA();
Strategy *strategyB = new ConcreteStrategyB();
Context *context = new Context(strategyA);
context->contextInterface();
context = new Context(strategyB);
context->contextInterface();
return 0;
}
7.2 软件架构优化
软件架构优化是确保软件系统的性能、可维护性和可扩展性的重要环节。一个好的架构可以让软件在面临需求变更时更加灵活和稳定。
7.2.1 代码重构
代码重构是提高软件质量、优化性能的一种常见手段。它通过重新组织代码结构,消除冗余和复杂性,以达到简化代码和提高可读性的目的。
7.2.2 设计模式的应用
设计模式的应用能够有效解决软件开发过程中遇到的常见问题,使系统更加模块化,便于扩展和维护。
7.2.3 架构设计原则
在进行软件架构设计时,应该遵循一些基本原则,比如单一职责原则、开闭原则、里氏替换原则等,以确保设计的合理性和系统的稳定性。
在本章中,我们探讨了设计模式的分类和在C++中的应用,并强调了软件架构优化的重要性。通过使用这些设计模式,我们可以创建出更加健壮、灵活和可维护的软件系统。同时,本章也介绍了一些基本的架构设计原则,以帮助开发者构建出高性能和易于扩展的软件架构。
简介:本资源集合提供一本涵盖数据结构与算法应用书籍的所有C++源代码实例,帮助学习者通过实践理解并掌握这些重要概念。内容包含各类链表、栈与队列、数组与向量、排序与搜索算法、树结构、图算法、哈希表、递归与分治策略、动态规划和贪心算法的实现,旨在提升C++编程技巧,为实际问题解决提供坚实基础。

















 2203
2203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









