




 本文深入探讨了Java集合框架中的HashSet和TreeSet类。详细解释了HashSet如何利用哈希码和equals方法避免重复元素,以及TreeSet如何通过compareTo方法实现元素的排序存储。通过实例演示了两种集合的使用方法。
本文深入探讨了Java集合框架中的HashSet和TreeSet类。详细解释了HashSet如何利用哈希码和equals方法避免重复元素,以及TreeSet如何通过compareTo方法实现元素的排序存储。通过实例演示了两种集合的使用方法。
HashSet类——依据HashCode值分配空间
此类实现 Set 接口,由哈希表(实际上是一个 HashMap 实例)支持。它不保证 set 的迭代顺序;特别是它不保证该顺序恒久不变。此类允许使用 null 元素
构造方法摘要
-
HashSet()
构造一个新的空 set,其底层 HashMap 实例的默认初始容量是 16,加载因子是 0.75。 -
HashSet(Collection<? extends E> c)
构造一个包含指定 collection 中的元素的新 set。
方法摘要
-
boolean add(E e)
如果此 set 中尚未包含指定元素,则添加指定元素。 -
void clear()
从此 set 中移除所有元素。 -
Object clone()
返回此 HashSet 实例的浅表副本:并没有复制这些元素本身。 -
boolean contains(Object o)
如果此 set 包含指定元素,则返回 true。 -
boolean isEmpty()
如果此 set 不包含任何元素,则返回 true。 -
Iterator iterator()
返回对此 set 中元素进行迭代的迭代器。 -
boolean remove(Object o)
如果指定元素存在于此 set 中,则将其移除。 -
int size()
返回此 set 中的元素的数量(set 的容量)。 -
HashSet的存储过程
首先,我们要了解一点:Set散列表内部的元素都不能重复,而HashSet是如何实现剔除重复元素的呢?Set<E>中的泛型E表征传入Set对象的一个类型,这个类必定会具有hashcode方法(Object里面就有)
明确一点:Java中原则上hashcode不同的两对象一定不能是同一对象(指的是主观意识的相同),而Hashcode相同的两个对象可能不是同一对象(指的是主观意识的相同)——这是hashcode算法的缺陷:不能确保两个不同对象计算哈希码一定不一样
具体到存储过程:我们的set对象调用add(E e)时,
- 1.首先将计算e对象的Hashcode值,据此对应到一个存储空间,
- 2.倘若这个空间未被占用,那么必定这个set中是第一次添加这个对象(Hashcode不同必定不是同一对象),否则空间被占用了,则需要进一步判断(两个不同对象可能得出相同hashcode)
- 3.这个时候于是调用equals()方法判断该空间内的对象是否与e相同,若相同的,就说明确实是同一对象,否则就需要再次计算hashcode,重复上述步骤直至找到了空闲的存储空间或者得出结论equals返回了false不能添加重复元素
//假设我们如是设计equals和hashCode方法,即Person类的hashcode和equals只关联age变量
public boolean equals(Object obj) {
Person p = (Person)obj;
return p.age == this.age ;
}
@Override
public int hashCode() {
return this.age*35;
}
- 我们发现marry 20 这个Person对象并没有成功添加至HashSet中,也就是它被判定为同一个对象了
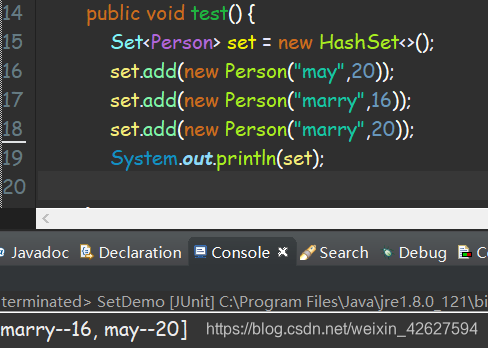
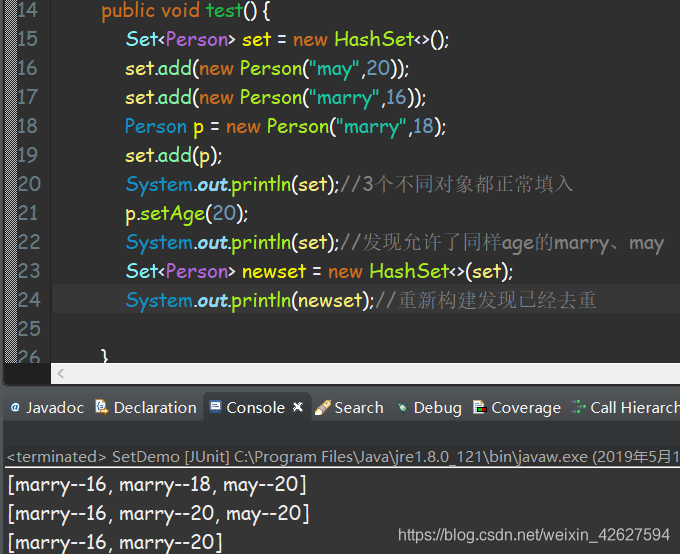
- 正常添加后修改发现了重复,这是由于此时已经以不同的hashcode位置存在于set中,而再次构建newset会发现已经去重,这是由于经过重新计算hashcode、equals对比认为重复的元素被去除了
TreeSet ——基于传入类对象的CompareTo()实现存储的树状散列表
该类型的Set模型类似于一个二叉搜索树BST(Binary Search Tree)模型, 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值; 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值
public void test2() {
Set<Integer> set = new TreeSet<>();
set.add(12);
set.add(7);
set.add(25);
set.add(18);
set.add(5);
set.add(6);
System.out.println(set);//[5, 6, 7, 12, 18, 25]
}//可见无序填入而输出时却能按递增排序
public void test2() {
//对于字符串也能自动排序
Set<String> set = new TreeSet<>();
set.add("Hello");
set.add("Alen");
set.add("Jenny");
set.add("Bob");
set.add("Alen1");
set.add("alen");
System.out.println(set);//[Alen, Alen1, Bob, Hello, Jenny, alen]
}
public void test2() {
Set<Person> set = new TreeSet<>();
set.add(new Person("may",20));////java.lang.ClassCastException:
set.add(new Person("marry",16));
set.add(new Person("Kate",21));
System.out.println(set);
}
-
归根结底:我们观察无论是String还是Integer亦或是其他类,TreeSet能在存储对象的过程实现排序是因为对象对应的类实现了Comparable这一接口,而未实现该接口的类对象在存储时第一时间抛出ClassCastException异常
-
TreeSet存储过程:也即构建二叉搜索树的过程
-
若根节点为空,插入
-
小于等于根节点,递归插入左子树
-
大于根节点,递归插入右子树
-
而在Java中对应对比的步骤便是CompareTo方法所为
//C++递归模拟 TreeNode* SortBinaryTree(TreeNode* root, const T& val) { if (root == NULL) { root = new TreeNode(val); //根节点为空,插入,返回。 return root; } else { if (val <= root->data) //小于等于根节点,递归插入左子树 { root->lchild = SortBinaryTree(root->lchild, val); } else //大于根节点,递归插入右子树 { root->rchild = SortBinaryTree(root->rchild, val); } } return root; }
倘若我们这样实现compareTo方法
@Override
public int compareTo(Emp o) {
return this.age - o.age;//仅仅只针对年龄升序排序
}
public static void test2() {
Set<Emp> set = new TreeSet<>();
set.add(new Emp("Jack",23,"男",5000,"2006-02-15"));
set.add(new Emp("Marry",23,"女",6000,"2007-12-24"));
set.add(new Emp("Alice",23,"女",5000,"2009-12-28"));
set.add(new Emp("Jack",23,"男",6000,"2007-02-15"));
System.out.println(set);//结果只有Jack被添加进去了,因为compareTo方法只针对年龄
}
我们重新在Person类规范实现Comparable接口
//实现Comparable接口中CompareTo方法
@Override
public int compareTo(Person o) {
if( ! this.name.equals(o.name)) {
return this.name.compareTo(o.name);
}else{
return age - o.age;
}
}
//不再抛出异常,且按方法内规则排序
public void test2() {
Set<Person> set = new TreeSet<>();
set.add(new Person("may",20));
set.add(new Person("marry",16));
set.add(new Person("Kate",21));
set.add(new Person("Kate",18));
System.out.println(set);//[Kate--18, Kate--21, marry--16, may--20]
}

















 1145
1145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









