




Python运算符和编码
一、格式化输出
现在有以下需求,让⽤户输入name, age, job,hobby 然后输出如下所⽰:
----------info of dogfa----------
name: dogfa
age: 18
job: 嫖客
hobby: 嫖娼
---------------------------------
如果用字符串拼接的话会很繁琐,所以我们可以采用这样的方法来实现:
--------------------------------------------------------------------
注:如果你对python感兴趣,我这有个学习Python基地,里面有很多学习资料,感兴趣的+Q群:895817687
--------------------------------------------------------------------
name = input("请输入姓名:")
age = input("请输入年龄:")
job = input("请输入工作:")
hobby = input("请输入爱好:")
info = '''----------info of dogfa----------
name: %s
age: %s
job: %s
hobby: %s
---------------------------------
''' % (name, age, job, hobby)
print(info)

二、基本运算符
计算机可以进⾏的运算有很多种,可不只加减乘除这么简单,运算按种类可分为:
- 算术运算
- 逻辑运算
- 比较运算
- 赋值运算
- 位运算
- 成员运算
- 身份运算
在此我就着重介绍以上前四大基本运算
1、算术运算
以下假设变量:a=10,b=20

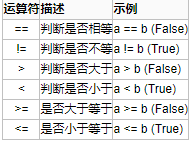
2、比较运算
以下假设变量:a=10,b=20
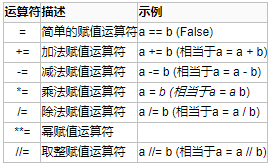
3、赋值运算
4、逻辑运算
假设a = True ,b = False

逻辑运算的优先级:()>not>and>or,从左往右依次计算。
扩展:
x or y , x为真,值就是x,x为假,值是y;
x and y, x为真,值是y,x为假,值是x
3>4 or 4<3 and 1==1 (False)
1 < 2 and 3 < 4 or 1>2 (True)
2 > 1 and 3 < 4 or 4 > 5 and 2 < 1 (True)
not 2 > 1 and 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6 (False)
1 and 2 (2)
1 or 2 (1)
1 and 0 (0)
1 or 0 (1)
5、成员运算
- in
- not in
判断子元素是否在原字符串(字典,列表,集合)中:
temp = "dogfa is a dsb!"
print("dsb" in temp)
print("dsb" not in temp)
三、编码
python2解释器在加载 .py ⽂件中的代码时,会对内容进⾏编码(默认ascill),⽽python3对内容进⾏编码的默认为utf8。
早期. 计算机是美国发明的. 普及率不⾼, ⼀般只是在美国使⽤. 所以. 最早的编码结构就是按照美国⼈的习惯来编码
的. 对应数字+字⺟+特殊字符⼀共也没多少. 所以就形成了最早的编码ASCII码. 直到今天ASCII依然深深的影响着我们.
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字⺟的⼀套电
脑编码系统,主要⽤于显示现代英语和其他⻄欧语⾔,其最多只能⽤ 8 位来表示(⼀个字节),即:2**8 = 256,所
以,ASCII码最多只能表示 256 个符号。
例如:
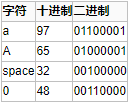
随着计算机的发展. 以及普及率的提⾼. 流⾏到欧洲和亚洲. 这时ASCII码就不合适了. ⽐如: 中⽂汉字有⼏万个. ⽽ASCII
最多也就256个位置. 所以ASCII不⾏了. 怎么办呢? 这时, 不同的国家就提出了不同的编码⽤来适⽤于各⾃的语⾔环境.
⽐如, 中国的GBK, GB2312, BIG5, ISO-8859-1等等. 这时各个国家都可以使⽤计算机了.
GBK, 国标码占⽤2个字节. 对应ASCII码 GBK直接兼容. 因为计算机底层是⽤英⽂写的. 你不⽀持英⽂肯定不⾏. ⽽英
⽂已经使⽤了ASCII码. 所以GBK要兼容ASCII.
这⾥GBK国标码. 前⾯的ASCII码部分. 由于使⽤两个字节. 所以对于ASCII码⽽⾔. 前9位都是0
字⺟A:0100 0001 # ASCII
字⺟A:0000 0000 0100 0001 # 国标码
国标码的弊端: 只能中国⽤. ⽇本就垮了. 所以国标码不满⾜我们的使⽤. 这时提出了⼀个万国码Unicode. unicode⼀
开始设计是每个字符两个字节. 设计完了. 发现我⼤中国汉字依然⽆法进⾏编码. 只能进⾏扩充. 扩充成32位也就是4个字
节. 这回够了. 但是. 问题来了. 中国字9万多. ⽽unicode可以表⽰40多亿. 根本⽤不了. 太浪费了. 于是乎, 就提出了新的
UTF编码.可变⻓度编码
UTF-8: 每个字符最少占8位. 每个字符占⽤的字节数不定.根据⽂字内容进⾏具体编码. 比如. 英⽂. 就⼀个字节就够了. 汉
字占3个字节. 这时即满⾜了中⽂. 也满⾜了节约. 也是⽬前使⽤频率最⾼的⼀种编码。
ascii:用8位,一个字节表示字符
gbk:用16位,两个字节表示字符
unicode:万国码,用32位,4个字节表示字符
urf-8:万国码的压缩版
- 英文:8位,一个字节
- 汉字:24位,3个字节
- 欧洲文字:16位,2个字节
utf-16:每个字符至少占16位,即两个字节
单位转换:
8bit = 1byte
1024byte = 1KB
1024KB = 1MB
1024MB = 1GB
1024GB = 1TB
1024TB = 1PB
1024TB = 1EB
1024EB = 1ZB
通常用到TB就够了。

















 320
320

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









