







文章转载------------------------------点击打开链接
iptables是用户态的配置工具,用于实现网络层的防火墙,用户可以通过iptables命令设置一系列的过滤规则,来截获特定的数据包并进行过滤或其他处理。
iptables命令通过与内核中的netfilter交互来起作用。我们知道netfilter通过挂在每个hook点上的hook函数来过滤数据包,并且将过滤规则存放在几个表中供hook函数使用。相应的,iptables工具也定义了同样的几张规则表来对应netfilter中的表,以及定义了不同的链(chain)来对应netfilter中的hook点。这样,通过iptables命令生成的规则可以很容易的作用到内核中的netfilter模块,netfilter根据这些规则做真正的过滤工作。
netfilter模块中,不同的协议族定义了各自的一套hook点,例如,IPv4、IPv6、ARP、BRIDGE等协议族都分别定义了各自的netfilter处理流程以及各自的hook点,我们比较常见的就是IPv4协议定义的5个hook点(PRE_ROUTING,LOCAL_IN,LOCAL_OUT,FORWARD和POST_ROUTING)。同样的,为了和netfilter交互,在用户态分别有iptables、ip6tables、arptables、ebtables等命令来定义各协议族的过滤规则。
要使用iptables命令,则必须将netfilter模块编进内核。本文内容基于内核版本2.6.31。
1. 数据结构
netfilter中的每个表都定义成一个struct xt_table类型的结构体。例如下面定义的表:
struct xt_table *iptable_filter;
struct xt_table *iptable_mangle;
struct xt_table *iptable_raw;
struct xt_table *nat_table;
xt_table结构定义如下,表中的实际规则就放在其中的private成员中。
-
struct xt_table
-
{
-
struct list_head list;
-
/* 在哪些hook点上注册了hook函数,是一个位图 */
-
unsigned int valid_hooks;
-
/*表的实际数据 */
-
struct xt_table_info *private;
-
struct module *me;
-
/* 所属协议族 */
-
u_int8_t af;
-
/*表名,供用户空间设置iptables规则,或者内核匹配iptables规则 */
-
const char name[XT_TABLE_MAXNAMELEN];
-
};
而private里的内容是:
-
/* The table itself */
-
struct xt_table_info
-
{
-
/* 表的大小 */
-
unsigned int size;
-
/* Number of entries,即规则的数量 */
-
unsigned int number;
-
/* Initial number of entries,一般为上一次修改规则时的number */
-
unsigned int initial_entries;
-
-
/* 在每个hook点作用的entry的偏移(注意是相对于最后一个参数entry的偏移,即第一个hook的第一个ipt_entry的hook_entry为0) */
-
unsigned int hook_entry[NF_INET_NUMHOOKS];
-
-
/* 规则表的最大下界 */
-
unsigned int underflow[NF_INET_NUMHOOKS];
-
-
/* 规则表入口,即真正的规则存储结构. 在遍历一个规则表时,以此作为表的起始(即第一个ipt_entry)。由定义可知这是一个数组,每个元素对应每个CPU上的规则 入口。 */
-
void *entries[ 1];
-
};
所以,通过private就可以定位到规则的实际内容了。
例如NAT表的定义如下,可知在定义时初始化好了下面4个成员。而在注册时会赋值list成员,在添加新规则时会给private赋值。-
static struct xt_table nat_table = {
-
.name = "nat",
-
.valid_hooks = ( 1 << NF_INET_PRE_ROUTING) | \
-
( 1 << NF_INET_POST_ROUTING) | \
-
( 1 << NF_INET_LOCAL_OUT),
-
.me = THIS_MODULE,
-
.af = AF_INET,
-
};
一条iptables规则包括三个部分:ipt_entry、ipt_entry_matches、ipt_entry_target。
ipt_entry_matches由多个ipt_entry_match组成,ipt_entry结构主要保存标准匹配的内容,ipt_entry_match 结构主要保存扩展匹配的内容,ipt_entry_target结构主要保存规则的动作。
-
struct ipt_entry
-
{
-
/* ipt_ip结构:将要进行匹配动作的IP数据报报头的描述 */
-
struct ipt_ip ip;
-
/* 经过这个规则后数据报的状态:未改变,已改变,不确定 */
-
unsigned int nfcache;
-
/* Size of ipt_entry + matches,target在matches的后面 */
-
u_int16_t target_offset;
-
/* Size of ipt_entry + matches + target,即下一个ipt_entry的开始 */
-
u_int16_t next_offset;
-
/* 指向数据报所经历的上一个规则地址。还可以作为hook mask表示规则作用于那个
-
hook点上 */
-
unsigned int comefrom;
-
/* 匹配这个规则的数据报的计数以及字节计数 */
-
struct xt_counters counters;
-
/* 存放matches(一条规则可有0到多个match)和一个target */
-
unsigned char elems[ 0];
-
};
结构体中的elems成员用于定位规则的matches,target_offset用于定位规则的target,next_offset指向下一条规则入口即下一个ipt_entry。这样,只要定位到一个表中第一个规则的ipt_entry,就可以找到这个表中的所有规则了。
一个表中可以有多条规则,下图以IPV4上注册的表以及nat表的规则为例,说明了表中规则的存放形式,该图显示了IPv4协议有filter和nat等规则表,并显示了nat表的规则的存放位置。
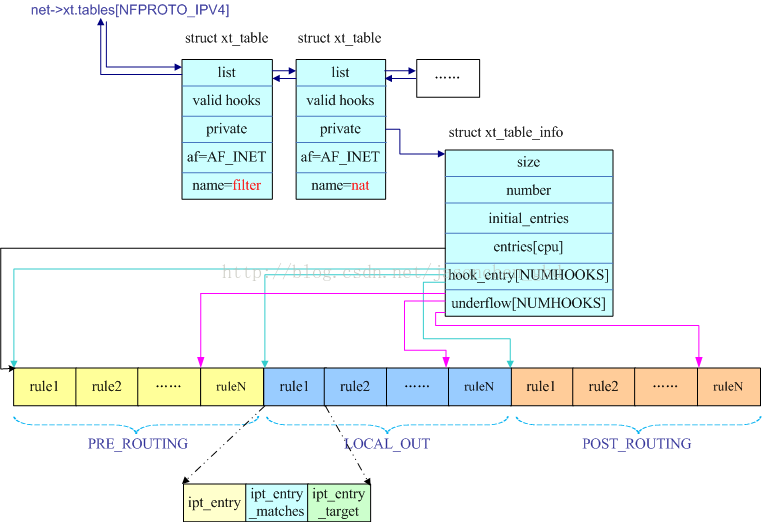
NAT表允许在PRE_ROUTING、LOCAL_OUT、POST_ROUTING三个链上设置规则,所以,struct xt_table_info的hook_entry[]和underflow[]成员分别有三个数组元素,用来定位每个链(即hook点)上的第一条规则和最后一条规则。
每个链可以有多条规则,每条规则都是由entry+matches+target组成的,所以在遍历每个链上的规则时,就根据struct ipt_entry来定位每条规则的位置。
用iptables命令还可以创建自定义的子链,例如用户新建一个自定义链NEW_PRE_CHAIN:
iptables -N NEW_PRE_CHAIN
然后设置了两条规则添加到NEW_PRE_CHAIN链上。
接着在PREROUTING链(对应netfilter的hook点NF_INET_PRE_ROUTING)上追加一条跳转到NEW_PRE_CHAIN子链的规则,并将这条规则放到NAT表中,例如:
iptables -t nat -A PREROUTING -i eth1 -p tcp -s 192.168.2.0/24 -d 192.168.2.1 --dport 8080 -j NEW_PRE_CHAIN
上面这条规则的意思是在nat表中添加一条规则:从eth1进来的TCP包,在经过在PREROUTING链时进行判断,如果源IP是192.168.2.x网段,目的IP是192.168.2.1,目的端口为8080,则跳转到NEW_PRE_CHAIN链上继续匹配规则。
说是子链,实际上仍然和原有规则放在一起。例如上面在子链中新添加两条规则后,netfilter的NAT表的规则就变成了:

可以看到两条新的PRE_ROUTING规则被紧跟在原有规则后面存放,并且在内核中的NAT表中并没有关于子链NEW_PRE_CHAIN的信息,因为“子链”的概念是用户态的iptables命令才使用的,iptables做一些处理后将规则传到内核,而内核中netfilter的工作就不会那么复杂。
用户态的iptables命令传入的match和target在内核都要有对应的match和target。内核中所有的match和target都注册在全局数组xt中,该数组每个元素是一个struct xt_af结构,存储一类地址族的matches和targets,如NFPROTO_IPV4。
static struct xt_af *xt;
-
struct xt_af {
-
struct mutex mutex;
-
struct list_head match; //该协议的match集合
-
struct list_head target; //该协议的taget集合
-
};
注册函数为xt_register_match(struct xt_match *match)和xt_register_target(struct xt_target *target)。
find_check_entry()函数中可以看到内核如何根据用户态传过来的规则中match和target的name来匹配内核支持的match和target。struct xt_match 和struct xt_target结构都有name成员,用户态传入的name必须是内核已注册的,才能找到对应项添加到一条规则中去。例如,iptables命令想要使用DNAT这个target,则内核中必须要定义了对应“DNAT”的target函数。
2. 用户态使用iptables添加一条规则的流程
用iptables -vxnL或iptables –t filter -vxnL命令可以看到filter表上的所有规则。用iptables –t nat -vxnL命令可以看到nat表中的所有规则。
iptables工具是用户空间和内核的netfilter模块通信的手段,因此iptables中也有“表”和“hook点”的概念,只是hook点被称为内建chain。
Iptables命令中的内建链与Netfilter中hook点的对应关系如下:
-
static const char *hooknames[] = {
-
[HOOK_PRE_ROUTING] = "PREROUTING",
-
[HOOK_LOCAL_IN] = "INPUT",
-
[HOOK_FORWARD] = "FORWARD",
-
[HOOK_LOCAL_OUT] = "OUTPUT",
-
[HOOK_POST_ROUTING] = "POSTROUTING",
-
#ifdef HOOK_DROPPING
-
[HOOK_DROPPING] = "DROPPING"
-
#endif
-
};
用户配置完iptables规则之后,传给内核的是一个ipt_replace结构,其中包含了内核所需要的所有内容:
-
/* The argument to IPT_SO_SET_REPLACE. */
-
struct ipt_replace
-
{
-
/* 表名 */
-
char name[IPT_TABLE_MAXNAMELEN];
-
-
/* hook mask */
-
unsigned int valid_hooks;
-
-
/* 新规则的entry数 */
-
unsigned int num_entries;
-
-
/* Total size of new entries */
-
unsigned int size;
-
-
/* Hook entry points. */
-
unsigned int hook_entry[NF_INET_NUMHOOKS];
-
-
/* Underflow points. */
-
unsigned int underflow[NF_INET_NUMHOOKS];
-
-
/* 旧规则的entry数 */
-
unsigned int num_counters;
-
-
/* The old entries' counters. */
-
struct xt_counters __user *counters;
-
-
/* 规则本身 */
-
struct ipt_entry entries[0];
-
};
该结构包含了表名,规则挂载的hook点,ipt entry的数目等信息,该结构的最后为实际的规则内容,基本包含了内核中struct xt_table和struct xt_table_info结构所需要的内容。传递的过程通过getsockopt()和setsockopt()系统调用来完成,这两个系统调用的函数原型为:
int getsockopt(int s, int level, int optname, void *optval, socklen_t *optlen);
int setsockopt(ints, int level, int optname, const void *optval, socklen_t optlen);
其中getsockopt的参数optname可取的值为IPT_SO_GET_INFO、IPT_SO_GET_ENTRIES、IPT_SO_GET_REVISION_MATCH和IPT_SO_GET_REVISION_TARGET。
setsockopt的参数optname可取的值为IPT_SO_SET_REPLACE和IPT_SO_SET_ADD_COUNTERS,所有修改规则的动作(添加、修改、删除等)都通过IPT_SO_SET_REPLACE完成,而IPT_SO_SET_ADD_COUNTERS更新表中每个ipt_entry的counters成员。
当然这些都是iptables工具做的事情,我们只要会使用iptables命令即可。而我们知道可以自定义链,这也是iptables工具所的要处理的事情,实际上内核是不知道有自定义链的。
在ip_tables_init函数中调用nf_register_sockopt(&ipt_sockopts)注册get和set方法,如下:
-
ipt_sockopts-> set = do_ipt_set_ctl;
-
ipt_sockopts->get = do_ipt_get_ctl;
用户改变iptables规则时,通过ipt_sockopts注册的这两个函数进行进一步工作,例如set方法就是将用户空间传过来的ipt_replace来替换旧的iptables规则。这个工作在do_replace()函数中完成。
do_replace()处理流程如下:
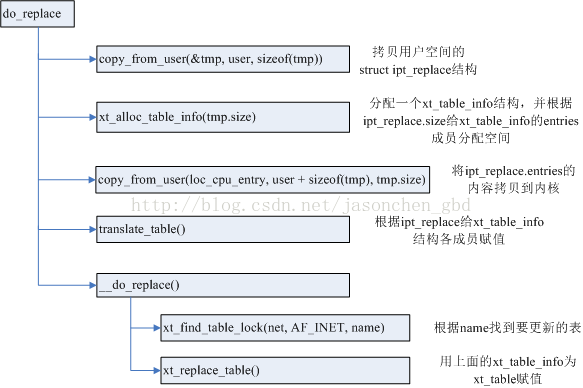
该函数流程比较清晰,最终结果是更新了内核中的某个xt_table表,如NAT表。图中未列出一系列的合法性检查,如size和valid_hook的检查,以及对entry/match/target的匹配和检查等。
3. netfilter进行规则匹配的流程
3.1 ipt_do_table()
前面一直讲到根据ipt_do_table()来匹配match并执行target,那我们就从ipt_do_table()开始分析。hook点上的hook函数就是通过这个ipt_do_table()来查找表中规则并将规则作用于数据包的。
-
unsigned int
-
ipt_do_table (struct sk_buff *skb,
-
unsigned int hook,
-
const struct net_device *in,
-
const struct net_device *out,
-
struct xt_table *table)
-
{
-
-
static const
-
char nulldevname[IFNAMSIZ] __attribute__((aligned( sizeof( long))));
-
const struct iphdr *ip;
-
u_int16_t datalen;
-
bool hotdrop = false;
-
/* Initializing verdict to NF_DROP keeps gcc happy. */
-
unsigned int verdict = NF_DROP;
-
const char *indev, *outdev;
-
void *table_base;
-
struct ipt_entry *e, *back;
-
struct xt_table_info *private;
-
struct xt_match_param mtpar;
-
struct xt_target_param tgpar;
-
-
ip = ip_hdr(skb);
-
-
/* 是否挂在正确的hook点 */
-
IP_NF_ASSERT(table->valid_hooks & ( 1 << hook));
-
xt_info_rdlock_bh();
-
-
/* 获取规则内容 */
-
private = table-> private;
-
-
/* 获得表的规则总入口 */
-
table_base = private->entries[smp_processor_id()];
-
-
/* 获得表在该hook点定义的规则的入口 */
-
e = get_entry(table_base, private->hook_entry[hook]);
-
-
/* 如果没有match部分也没有target函数,直接根据verdict的值返回 */
-
if (e->target_offset <= sizeof(struct ipt_entry) &&
-
(e->ip.flags & IPT_F_NO_DEF_MATCH)) {
-
struct ipt_entry_target *t = ipt_get_target(e);
-
if (!t->u.kernel.target->target) {
-
int v = ((struct ipt_standard_target *)t)->verdict;
-
if ((v < 0) && (v != IPT_RETURN)) {
-
ADD_COUNTER(e->counters, ntohs(ip->tot_len), 1);
-
xt_info_rdunlock_bh();
-
return ( unsigned)(-v) - 1; /****finish****/
-
}
-
}
-
}
-
-
/* Initialization */
-
datalen = skb->len - ip->ihl * 4;
-
indev = in ? in->name : nulldevname;
-
outdev = out ? out->name : nulldevname;
-
-
/* 初始化match的参数 */
-
mtpar.fragoff = ntohs(ip->frag_off) & IP_OFFSET;
-
mtpar.thoff = ip_hdrlen(skb);
-
mtpar.hotdrop = &hotdrop;
-
mtpar.in = tgpar.in = in;
-
mtpar.out = tgpar.out = out;
-
mtpar.family = tgpar.family = NFPROTO_IPV4;
-
mtpar.hooknum = tgpar.hooknum = hook;
-
-
/* For return from builtin chain */
-
back = get_entry(table_base, private->underflow[hook]);
-
-
do {
-
struct ipt_entry_target *t;
-
-
/* 匹配规则的entry部分和match部分 */
-
IP_NF_ASSERT(e);
-
IP_NF_ASSERT(back);
-
/* skb相应字段是否和规则匹配,即匹配entry部分 */
-
if (!ip_packet_match(ip, indev, outdev,
-
&e->ip, mtpar.fragoff) ||
-
/* 将skb放在e的所有match函数中依次进行match */
-
IPT_MATCH_ITERATE(e, do_match, skb, &mtpar) != 0) {
-
/* 如果entry或match匹配失败,就不再走下一个match,直接
-
跳到下一个entry,依次匹配matches。 */
-
e = ipt_next_entry(e);
-
continue;
-
}
-
-
/* 经过上面的匹配,e指向了匹配成功的ipt_entry */
-
-
/* 增加统计计数(数据报的字节总数不包含链路层数据长度) */
-
ADD_COUNTER(e->counters, ntohs(ip->tot_len), 1);
-
-
/* 获得target部分 */
-
t = ipt_get_target(e);
-
IP_NF_ASSERT(t->u.kernel.target);
-
-
/* 如果target函数为NULL,则根据verdict判断是否返回 */
-
if (!t->u.kernel.target->target) {
-
int v;
-
-
v = ((struct ipt_standard_target *)t)->verdict;
-
if (v < 0) {
-
/* Pop from stack? */
-
if (v != IPT_RETURN) {
-
verdict = ( unsigned)(-v) - 1;
-
break; /****finish****/
-
}
-
/* 如果返回的是IPT_RETURN,则要返回到父链 */
-
e = back;
-
back = get_entry(table_base, back->comefrom);
-
continue;
-
}
-
/* 没有target且verdict>0时,verdict为自定义链起始位置的相对偏移量 */
-
if (table_base + v != ipt_next_entry(e)
-
&& !(e->ip.flags & IPT_F_GOTO)) {
-
/* Save old back ptr in next entry */
-
struct ipt_entry *next = ipt_next_entry(e);
-
next->comefrom = ( void *)back - table_base;
-
/* set back pointer to next entry */
-
back = next;
-
}
-
/* 跳到下一个entry */
-
e = get_entry(table_base, v);
-
continue;
-
}
-
-
/* Targets which reenter must return
-
abs. verdicts */
-
/* 初始化target的参数 */
-
tgpar.target = t->u.kernel.target;
-
tgpar.targinfo = t->data;
-
-
/* 为skb执行target函数,返回处理结果verdict */
-
verdict = t->u.kernel.target->target(skb, &tgpar);
-
-
/* Target might have changed stuff. */
-
ip = ip_hdr(skb);
-
datalen = skb->len - ip->ihl * 4;
-
-
/* 如果返回continue,接着走下一个entry。
-
返回其他的则处理结束,直接返回verdict */
-
if (verdict == IPT_CONTINUE)
-
e = ipt_next_entry(e);
-
else
-
/* 返回target函数本身的处理结果 */
-
/* Verdict */
-
break; /****finish****/
-
} while (!hotdrop);
-
xt_info_rdunlock_bh();
-
-
if (hotdrop)
-
return NF_DROP;
-
else return verdict;
-
-
-
}
注意,找到一个匹配成功的规则,执行target之后就不再遍历下一条规则了,无论target结果怎样。
代码中最主要的内容就是while循环中遍历表中规则,匹配entry和match并执行target。该函数的返回值为规则的处理结果,代码中有三处会停止遍历并返回结果,已用注释/****finish****/标出,返回值都是存放在一个名为verdict的变量中,这个值有多重含义:
1. 如果规则指定了target函数,例如配置iptables命令时指定-j SNAT,verdict就是target函数(如ipt_snat_target)的返回值,如NF_ACCEPT等。
2. 如果规则没有指定target函数,例如配置iptables命令时指定-j ACCEPT。这时如果verdict<0,并且verdict != IPT_RETURN,就把(unsigned)(-v) – 1作为返回值。
3. 如果规则没有指定target函数,且verdict<0,verdict == IPT_RETURN,则需要返回到父链继续匹配后续规则,例如上面设置的NEW_PRE_CHAIN子链规则匹配完成后需要跳回父链。
4. 如果规则没有指定target函数,且verdict>0,则verdict的值是子链相对于表规则入口的偏移,即后续应该跳到该子链去匹配规则,例如上面设置的NEW_PRE_CHAIN子链规则入口。
对于前两种取值,verdict是作为ipt_do_table()的返回值返回到调用者的,对于后两种取值,则需要继续while循环。
对于第二种取值,如果verdict<0,那需要通过计算来得出返回结果,例如,如果verdict = 0xfffffffe,则(unsigned)(-v) – 1就是1,即NF_ACCEPT,同样的,verdict = 0xffffffff即NF_DROP,等等。
IPT_CONTINUE 和IPT_RETURN定义如下:-
/* CONTINUE verdict for targets */
-
-
/* For standard target */
-
在一个链中还可以设置默认规则,即如果所有规则都不匹配,就走默认规则。默认规则一般设置为NF_ACCEPT或NF_DROP等。默认规则的target在iptables命令中被称为policy。
例如,我们在NAT表中设置PRE_ROUTING链上的policy是ACCEPT:
iptables -t nat -P PREROUTING ACCEPT
那在这条链上的最后一条规则不是我们自己手动添加的,而是一条没有match和target的默认规则,verdict被设置为0xfffffffe。
-
# iptables -t nat -L
-
Chain PREROUTING (policy ACCEPT)
-
••••••
注意,只能设置内建链的policy,不能设置自定义链,因为policy是内核中要使用的,内核并不知道自定义链的存在。另外,NAT表的各链的policy都不能为DROP,因为NAT表本来就不是用来过滤的,想要DROP的规则可以放到filter表中。
3.2 以NAT举例规则匹配流程
我们以下面的规则为例来说明规则匹配过程:
iptables -t nat -I POSTROUTING 3 -o eth1 -j MASQUERADE
这条规则作用在POST_ROUTING链,从eth1发出的数据包,去执行MASQUERADE动作,规则放在NAT表中。所以在NAT的POST_ROUTING的hook函数中会去执行该规则,即nf_nat_out()。
先说一下struct ipt_entry结构中,有一个成员ip,它是一个struct ipt_ip类型的结构体,用来匹配一些基本信息,所以规则的匹配工作并不完全在match中进行,ipt_entry也负责匹配一些内容。
-
struct ipt_ip {
-
/* Source and destination IP addr */
-
struct in_addr src, dst;
-
/* Mask for src and dest IP addr */
-
struct in_addr smsk, dmsk;
-
char iniface[IFNAMSIZ], outiface[IFNAMSIZ];
-
unsigned char iniface_mask[IFNAMSIZ], outiface_mask[IFNAMSIZ];
-
-
/* Protocol, 0 = ANY */
-
u_int16_t proto;
-
-
/* Flags word */
-
u_int8_t flags;
-
/* Inverse flags */
-
u_int8_t invflags;
-
};
可以看到这个结构可以完成源IP和目的IP、入口和出口设备、协议类型等的匹配。负责匹配ipt_entry部分的函数为ip_packet_match()。
上面的nat规则只要出口是eth1即可,所以该规则并没有match部分。在ipt_do_table()函数中找到target为MASQUERADE,对应到内核的masquerade_tg()函数,该函数负责将skb对应的其关联的nf_conn结构实例进行NAT转换,在下次数据包经过该hook点时,masquerade_tg()会判断conntrack状态而直接返回,从而达到只有第一个包需要查找NAT表,后续skb可以根据conntrack来做NAT的效果。
3.3 SNAT和masquerade
这是两个iptables规则的target,实际上他俩没有区别,只是nat配置规则的两种写法而已。我们先来看一下规则的写法:
iptables -t nat-I POSTROUTING 1 -o $wan_if -jMASQUERADE
iptables -t nat-I POSTROUTING 2 -s $lan_ip/$lan_mask -d$lan_ip/$lan_mask -j SNAT --to-source $wan_ip
规则中的-j选项指定target,这两个target分别对应内核的下面两个函数:
masquerade_tg(structsk_buff *skb, const struct xt_target_param *par);
ipt_snat_target(structsk_buff *skb, const struct xt_target_param *par);
snat规则指定了应该将源ip变成什么地址,而masquerade需要在出口设备的IP列表中选择一个合适的作为转换IP。二者都会调用nf_nat_setup_info()对ct进行转换。
注意,一般情况下路由器只允许内网到外网的NAT,所以必须做完SNAT后,外网的数据包才可以通过转换后的conntrack条目到达内网,所以我们通常不会设置DNAT规则。
同样的,REDIRECT和DNAT这两个target的作用一样,都是修改数据包的目的地址。

















 2494
2494

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









