




简介:编译原理是计算机科学的核心课程之一,主要研究如何将高级语言转换为机器指令。本课程设计项目通过完整的编译器实现流程,帮助学生掌握词法分析、语法分析、语义分析、中间代码生成、代码优化及目标代码生成等关键技术。项目包含源代码与可执行文件,并结合设计报告,提升学生的实践与分析能力,是理解编译机制、提升系统级编程能力的重要实践内容。
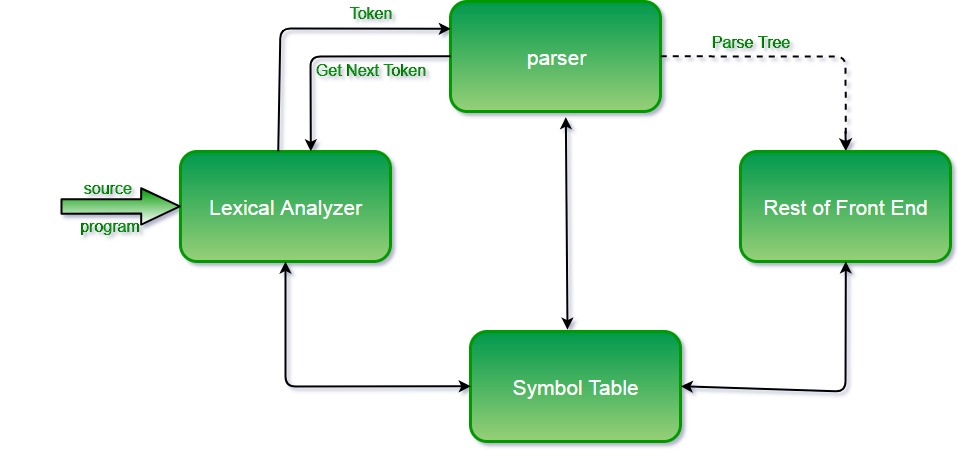
1. 编译器基本结构
编译器是将高级语言程序翻译为目标机器代码的核心工具。其整体结构通常划分为多个阶段: 词法分析、语法分析、语义分析、中间代码生成、代码优化和目标代码生成 。每个阶段紧密衔接,协同完成程序的解析与转换。
从流程上看,词法分析将字符序列转换为标记(Token),语法分析则基于这些标记构建语法结构树,语义分析负责类型检查与含义验证,随后生成中间表示,为后续优化和目标代码生成提供基础。理解这一结构体系,是深入编译技术的关键起点。
2. 词法分析器设计与实现
词法分析是编译过程的第一阶段,其主要任务是从字符序列中识别出具有语义意义的记号(token),例如标识符、关键字、运算符、常量等。本章将围绕词法分析器的设计与实现展开,从基本原理出发,深入探讨其技术实现路径,并通过基于Flex的实践案例帮助读者掌握实际开发技巧。
2.1 词法分析的基本原理
词法分析的核心在于将输入字符序列转换为一组有意义的记号,为后续的语法分析提供基础。要实现这一目标,必须理解正则表达式、有限自动机以及词法生成工具的工作机制。
2.1.1 正则表达式与模式匹配
正则表达式(Regular Expression)是一种用于描述字符串模式的工具,广泛应用于词法分析中的模式匹配。它提供了一种简洁的方式来定义语言中各种记号的结构。
例如,标识符的正则表达式通常可以表示为:
[a-zA-Z_][a-zA-Z0-9_]*
该表达式表示以字母或下划线开头,后跟零个或多个字母、数字或下划线的字符串。
正则表达式可以组合使用,形成复杂的模式,以匹配不同类型的词法单元。例如,整数常量的正则表达式可以表示为:
[0-9]+
正则表达式在词法分析器中用于定义每个记号的识别规则,词法分析器将输入字符流与这些规则进行匹配,从而识别出对应的记号。
表格:常见词法单元及其正则表达式示例
| 词法单元类型 | 示例 | 正则表达式 |
|---|---|---|
| 标识符 | var_name , _x | [a-zA-Z_][a-zA-Z0-9_]* |
| 整数常量 | 123 , -456 | -?[0-9]+ |
| 关键字 | if , while | if|while|for|return |
| 运算符 | + , == , && | \+|\-|\*|/|==|!=|&&|\|\| |
| 分隔符 | ( , ; , { | $|$|;|{|} |
2.1.2 有限自动机(DFA与NFA)
有限自动机(Finite Automaton, FA)是词法分析器实现的基础,常见的两种形式为 确定有限自动机(DFA) 和 非确定有限自动机(NFA) 。
- NFA :在某一状态下,输入一个字符可以导致多个状态转移。NFA通常更容易构造,但效率较低。
- DFA :每个状态对每个输入字符只有一个确定的转移路径。DFA执行效率高,但构造相对复杂。
构建词法分析器的过程通常包括以下步骤:
- 为每个记号编写正则表达式。
- 将正则表达式转换为NFA。
- 将NFA转换为DFA。
- 构造DFA的状态转移表,用于实现词法分析器。
示例:识别关键字 if 的NFA与DFA
NFA示意图:
graph TD
A[开始] -->|i| B
B -->|f| C
C[接受状态]
DFA示意图:
graph TD
A[开始] -->|i| B
B -->|f| C
A -->|其他| D
B -->|非f| D
C[接受状态]
D[错误状态]
2.1.3 词法分析器的生成工具(如Lex/Flex)
手动实现词法分析器较为复杂,通常借助工具如Lex或Flex来自动生成。Flex是Lex的增强版本,支持更强大的模式匹配能力,并广泛用于C/C++项目中。
Flex工具通过一个规则文件(通常以 .l 为扩展名)来定义词法规则。Flex会将该规则文件编译为一个C语言程序,其中包含一个基于DFA的词法分析器。
示例:一个简单的Flex规则文件( lexer.l )
%{
#include <stdio.h>
%}
"if" { printf("KEYWORD: if\n"); }
"else" { printf("KEYWORD: else\n"); }
[0-9]+ { printf("NUMBER: %s\n", yytext); }
[a-zA-Z]+ { printf("IDENTIFIER: %s\n", yytext); }
[+\-*/=] { printf("OPERATOR: %s\n", yytext); }
[ \t\n] ; // 忽略空白字符
. { printf("UNKNOWN: %s\n", yytext); }
int main(int argc, char **argv) {
yylex();
return 0;
}
编译与运行步骤:
-
使用Flex生成C代码:
bash flex lexer.l -
编译生成的C代码:
bash gcc lex.yy.c -o lexer -
运行词法分析器:
bash ./lexer -
输入测试文本(例如):
if x = 100 else y = 200
输出结果:
KEYWORD: if
IDENTIFIER: x
OPERATOR: =
NUMBER: 100
KEYWORD: else
IDENTIFIER: y
OPERATOR: =
NUMBER: 200
Flex规则结构解析:
-
%{ ... %}:C语言代码区,用于包含头文件或声明变量。 -
%% ... %%:规则区,每条规则由模式和动作组成。 -
yytext:当前匹配的字符串。 -
yylex():主函数中调用的词法分析函数。
2.2 词法分析器的具体实现
在理解了词法分析的基本原理后,接下来将深入探讨如何具体实现一个词法分析器,包括输入处理、记号识别、错误处理等内容。
2.2.1 输入处理与字符流管理
词法分析器需要从输入源(如文件或标准输入)读取字符流,并将其缓存以便逐个字符进行处理。通常使用缓冲区(buffer)来管理输入字符流,以提高读取效率。
示例:基于Flex的输入处理流程
Flex内部使用 yyin 变量指向输入文件,默认为 stdin 。可以通过以下方式指定输入文件:
yyin = fopen("input.txt", "r");
Flex内部通过 input() 函数读取字符,或通过 YY_INPUT 宏进行自定义输入方式。
2.2.2 标识符、关键字与运算符的识别
在实际开发中,标识符、关键字与运算符是最常见的词法单元。它们的识别依赖于正则表达式与状态机的结合。
示例:识别运算符的扩展规则
"==" { return EQ; }
"!=" { return NE; }
"<=" { return LE; }
">=" { return GE; }
"+" { return PLUS; }
"-" { return MINUS; }
"*" { return TIMES; }
"/" { return DIVIDE; }
上述规则使用了返回记号类型的方式,适用于与语法分析器(如Bison)集成的场景。
2.2.3 错误处理与词法错误恢复
在词法分析过程中,可能会遇到无法匹配任何规则的字符序列,此时需要进行错误处理。常见的策略包括:
- 输出错误信息并跳过错误字符。
- 尝试恢复并继续分析后续输入。
示例:错误处理规则
. {
fprintf(stderr, "Lexical error at line %d: unexpected character '%s'\n", yylineno, yytext);
yyless(1); // 只保留第一个字符,其余退回输入流
}
yyless(n) 函数用于控制已读取字符的回退,有助于实现更灵活的错误恢复机制。
2.3 实践:基于Flex的词法分析器开发
在理论基础上,本节将指导读者完成一个基于Flex的词法分析器开发流程,涵盖环境配置、规则编写、测试与调试等关键步骤。
2.3.1 配置开发环境
确保系统中已安装Flex工具,可以通过以下命令检查:
flex --version
如果没有安装,可在Linux系统上使用包管理器安装:
sudo apt install flex
Windows用户可使用WinFlexBison工具包。
2.3.2 编写规则文件并生成词法分析器
创建一个名为 lexer.l 的规则文件,并编写如前所述的规则。然后使用Flex生成C代码:
flex -o lex.yy.c lexer.l
该命令将生成 lex.yy.c 文件,其中包含基于DFA的词法分析器实现。
2.3.3 测试与调试词法分析模块
编写一个简单的测试文件 input.txt ,内容如下:
if x = 100 + y else error_char
运行生成的词法分析器:
./lexer < input.txt
预期输出:
KEYWORD: if
IDENTIFIER: x
OPERATOR: =
NUMBER: 100
OPERATOR: +
IDENTIFIER: y
KEYWORD: else
UNKNOWN: e
UNKNOWN: r
UNKNOWN: r
UNKNOWN: o
UNKNOWN: r
UNKNOWN: _
UNKNOWN: c
UNKNOWN: h
UNKNOWN: a
UNKNOWN: r
UNKNOWN: r
可以看到,对于无法识别的“error_char”,词法分析器逐个字符报告为未知字符。
调试建议:
- 使用
-d选项启用Flex的调试模式:
bash flex -d lexer.l - 在规则中插入
printf语句,观察当前状态与匹配结果。 - 使用
yylineno变量跟踪当前行号,辅助定位错误位置。
至此,本章完成了对词法分析器设计与实现的全面讲解,涵盖了基本原理、具体实现方法以及基于Flex的实践开发流程。下一章节将进入语法分析器的设计与实现阶段,继续深入编译器的构建之旅。
3. 语法分析器设计与实现
在编译器开发中,语法分析是连接词法分析与后续处理的关键桥梁。如果说词法分析是将字符流转换为标记(Token)序列的过程,那么语法分析则是将这些标记按照语言的语法规则组织成具有结构意义的语法树的过程。本章将从语法分析的基本方法入手,深入讲解如何设计和实现一个语法分析器,并通过实际案例演示如何使用Bison工具进行开发。
3.1 语法分析的基本方法
语法分析器的核心任务是根据语言的文法规则,判断输入的标记序列是否符合语法结构,并构建出相应的语法树。为了实现这一目标,通常采用两种基本分析策略: 自顶向下分析 和 自底向上分析 。
3.1.1 上下文无关文法(CFG)
上下文无关文法(Context-Free Grammar, CFG)是描述编程语言语法的基础工具。CFG由四元组(V, T, P, S)组成:
- V :非终结符集合(Variables)
- T :终结符集合(Terminals)
- P :产生式规则(Productions)
- S :开始符号(Start Symbol)
例如,一个简单的表达式文法可以定义为:
E → E + T | T
T → T * F | F
F → ( E ) | id
该文法描述了表达式的结构,其中 E 表示表达式,T 表示项,F 表示因子,id 表示标识符。
CFG 的特性
- 递归性 :允许规则中出现自身,便于描述嵌套结构。
- 无上下文限制 :某个非终结符的产生规则不依赖于其上下文环境。
CFG 的局限性
- 无法描述某些语义约束(如变量声明后才能使用)。
- 对于某些文法结构,如左递归,可能会影响分析效率。
3.1.2 自顶向下分析与递归下降分析
自顶向下分析(Top-Down Parsing)是从起始符号出发,尝试通过一系列替换推导出输入序列的过程。递归下降分析(Recursive Descent Parsing)是一种常见的自顶向下分析方法,它为每个非终结符编写一个递归函数来匹配输入。
示例:递归下降分析器的结构
void parse_E() {
parse_T();
while (lookahead == '+') {
match('+');
parse_T();
}
}
void parse_T() {
parse_F();
while (lookahead == '*') {
match('*');
parse_F();
}
}
void parse_F() {
if (lookahead == '(') {
match('(');
parse_E();
match(')');
} else if (lookahead == ID) {
match(ID);
} else {
error("Unexpected token");
}
}
代码分析:
-
lookahead表示当前读取的输入标记。 -
match(token)函数用于匹配当前标记与预期标记。 - 该结构清晰地反映了文法规则,但需要处理左递归问题。
参数说明:
-
lookahead:当前预读的输入标记,用于决定下一步操作。 -
match():匹配并消费当前标记,推进输入指针。 - 递归调用:每个函数对应一个非终结符,递归地调用其他函数进行匹配。
3.1.3 自底向上分析与LR分析
自底向上分析(Bottom-Up Parsing)是从输入标记序列出发,逐步归约为起始符号的过程。LR分析(Left-to-right, Rightmost derivation)是其中最常用的一种,适用于大多数上下文无关文法。
LR分析器的结构
LR分析器由四个主要部分组成:
- 状态栈(State Stack)
- 符号栈(Symbol Stack)
- 动作表(Action Table)
- 转移表(Goto Table)
LR分析流程图(mermaid格式)
graph TD
A[读取输入标记] --> B{是否有动作?}
B -->|Shift| C[状态入栈,符号入栈]
B -->|Reduce| D[根据产生式归约]
D --> E[查找Goto表,跳转新状态]
C --> F[继续读取下一个标记]
D --> F
F --> A
表格:LR分析器核心结构示例
| 状态 | 输入符号 | 动作(Action) | 转移(Goto) |
|---|---|---|---|
| 0 | id | Shift 3 | E: 1, T: 2 |
| 1 | + | Shift 4 | - |
| 2 | * | Shift 5 | - |
| 3 | ) | Reduce F → id | - |
优势与挑战:
- 优势 :支持更广泛的文法结构,处理效率高。
- 挑战 :构造分析表复杂,需要借助工具如Yacc/Bison。
3.2 语法分析器的构建
构建一个高效的语法分析器,需要从文法优化、分析表构造到错误处理等多个方面进行设计。
3.2.1 文法的消除左递归与左因子提取
左递归会导致递归下降分析器陷入无限递归,必须进行消除。
左递归示例:
E → E + T | T
消除左递归后的文法:
E → T E'
E' → + T E' | ε
左因子提取示例:
Stmt → if ( Expr ) Stmt
| if ( Expr ) Stmt else Stmt
提取左因子后的文法:
Stmt → if ( Expr ) Stmt ElsePart
ElsePart → else Stmt | ε
逻辑分析:
- 消除左递归:通过引入新非终结符避免无限递归。
- 左因子提取:减少预测分析时的歧义,提升分析效率。
3.2.2 构建预测分析表
预测分析表用于递归下降分析器的控制逻辑。构建步骤如下:
- 计算 FIRST 和 FOLLOW 集合
- 为每个产生式填充分析表
- 处理冲突(如FIRST/FIRST或FIRST/FOLLOW冲突)
示例:预测分析表构造
| 非终结符 | 输入符号 | 产生式 |
|---|---|---|
| E | id, ( | E → TE’ |
| E’ | + | E’ → +TE’ |
| E’ | $, ) | E’ → ε |
| T | id, ( | T → FT’ |
| T’ | *, +, ) | T’ → *FT’ |
| T’ | $, +, ) | T’ → ε |
说明:
-
FIRST(E')包含+和ε。 - 当输入符号在
FOLLOW(E')中时,选择 ε 产生式。
3.2.3 语法错误的检测与恢复
错误处理是语法分析器健壮性的关键。常见的错误类型包括:
- 语法错误 :如缺少分号、括号不匹配。
- 词法错误 :如非法字符、未识别的标识符。
错误恢复策略:
- 恐慌模式恢复(Panic Mode Recovery) :跳过错误符号,直到找到同步符号。
- 短语级恢复(Phrase-Level Recovery) :替换错误部分为合法结构。
- 错误产生式(Error Productions) :在文法中显式加入错误处理规则。
示例代码片段(Bison):
stmt:
IF '(' expr ')' stmt
| IF '(' expr ')' stmt ELSE stmt
| error { yyerrok; }
;
参数说明:
-
error:表示在此位置发生错误。 -
yyerrok:清除错误状态,继续分析。 -
yyclearin:丢弃当前输入标记,防止进一步错误。
3.3 实践:基于Bison的语法分析器开发
Bison 是 GNU 提供的语法分析器生成工具,能够将上下文无关文法转换为 C/C++ 代码。本节将通过一个完整的示例展示如何使用 Bison 构建语法分析器。
3.3.1 Bison语法文件编写规范
Bison 文件通常由三个部分组成:
%{
#include <stdio.h>
#include <stdlib.h>
void yyerror(char *s);
int yylex(void);
%}
%token ID NUM
program: stmt_list ;
stmt_list: stmt
| stmt_list stmt
;
stmt: ID '=' expr ';' { printf("Assignment: %s = ...\n", $1); }
;
expr: expr '+' term
| term
;
term: term '*' factor
| factor
;
factor: '(' expr ')'
| ID
| NUM
;
void yyerror(char *s) {
fprintf(stderr, "Error: %s\n", s);
}
int main(void) {
yyparse();
return 0;
}
代码分析:
-
%token:声明终结符。 -
%%:分隔文法部分。 - 动作块
{}:在归约时执行的 C 代码。 -
yyerror():错误处理函数。 -
main():调用yyparse()启动分析器。
3.3.2 与词法分析器的集成
Bison 需要与 Flex 生成的词法分析器配合使用。在 Flex 文件中定义标记的识别规则:
[a-zA-Z][a-zA-Z0-9]* { yylval.str = strdup(yytext); return ID; }
[0-9]+ { yylval.num = atoi(yytext); return NUM; }
"+" { return '+'; }
"*" { return '*'; }
"=" { return '='; }
";" { return ';'; }
"(" { return '('; }
")" { return ')'; }
[ \t\n] { /* ignore whitespace */ }
. { return yytext[0]; }
编译流程:
flex lexer.l
bison -d parser.y
gcc lex.yy.c parser.tab.c -o parser
./parser
参数说明:
-
-d:生成头文件供词法分析器使用。 -
lex.yy.c:Flex 生成的词法分析器。 -
parser.tab.c:Bison 生成的语法分析器。
3.3.3 语法树的初步构建与测试
语法分析的最终目标是构建语法树(Parse Tree)或抽象语法树(AST)。在 Bison 中,可以通过语义动作构建树节点。
示例:构建表达式节点
expr: expr '+' term {
$$ = new_node('+', $1, $3);
}
函数 new_node 示例:
struct Node* new_node(char op, struct Node* left, struct Node* right) {
struct Node* node = malloc(sizeof(struct Node));
node->type = OP_NODE;
node->op = op;
node->left = left;
node->right = right;
return node;
}
测试输入:
x = 3 + 4 * 5;
输出结构:
Assignment: x = ...
+
├── 3
└── *
├── 4
└── 5
说明:
- 每个节点代表一个语法结构。
- 树结构可用于后续的语义分析和代码生成。
本章通过理论与实践相结合,详细介绍了语法分析器的设计与实现方法,包括文法优化、分析器构造、错误处理及工具使用等内容,为构建完整编译器奠定了坚实基础。
4. 抽象语法树(AST)构建
抽象语法树(Abstract Syntax Tree,AST)是编译过程中极为关键的一个中间表示形式,它以树状结构反映程序的语法结构,是后续语义分析、优化和代码生成的基础。本章将从AST的基本概念出发,逐步深入到节点设计、表示方式以及在实际语法分析中如何构建AST,并通过代码示例和流程图说明构建过程,帮助读者掌握其核心实现机制。
4.1 AST的基本概念与作用
4.1.1 AST与语法树的区别
在语法分析阶段,编译器通常会生成两种树形结构:语法树(Parse Tree)和抽象语法树(AST)。两者的主要区别在于:
| 对比项 | 语法树(Parse Tree) | 抽象语法树(AST) |
|---|---|---|
| 表示内容 | 包含所有语法细节,如括号、运算符等 | 抽象掉冗余信息,仅保留程序结构核心元素 |
| 节点数量 | 相对较多,包含所有文法规则 | 较少,仅保留语义上有意义的结构 |
| 用途 | 用于理解语法分析过程 | 用于后续的语义分析和代码生成 |
| 可读性 | 稍差,结构复杂 | 更清晰,便于处理 |
例如,考虑以下表达式:
a = (b + c) * d;
语法树会包含括号、赋值符号等,而AST则会简化结构,仅保留变量、操作符和表达式结构。
4.1.2 AST在语义分析与代码生成中的作用
AST在编译流程中承担着承上启下的作用,主要体现在以下几个方面:
- 语义分析 :通过AST可以更高效地进行变量类型检查、函数调用合法性验证等操作。
- 代码优化 :AST便于识别冗余计算、常量折叠等优化机会。
- 代码生成 :AST可以直接映射为中间代码(IR)或目标代码,结构清晰、逻辑明确。
下图展示了AST在整个编译流程中的位置与作用:
graph TD
A[词法分析] --> B[语法分析]
B --> C[AST生成]
C --> D[语义分析]
D --> E[中间代码生成]
E --> F[代码优化]
F --> G[目标代码生成]
G --> H[可执行程序]
4.2 AST的节点设计与表示
4.2.1 节点类型与数据结构定义
AST的基本构建单位是“节点(Node)”。一个典型的AST节点结构通常包含以下信息:
- 节点类型 :如表达式节点、语句节点、声明节点等。
- 子节点指针 :用于构建树状结构。
- 属性信息 :如变量名、常量值、操作符类型等。
以下是一个用C语言定义的简单AST节点结构示例:
typedef enum {
NODE_EXPR,
NODE_STMT,
NODE_DECL
} NodeType;
typedef struct ASTNode {
NodeType type;
char* value; // 节点值(如变量名、操作符)
struct ASTNode* left;
struct ASTNode* right;
} ASTNode;
逐行解析说明:
-
NodeType枚举定义了节点的类型,便于后续处理。 -
value保存节点的值,如变量名或操作符字符串。 -
left和right是左右子节点,用于构建二叉树结构(适用于表达式)。
4.2.2 表达式、语句与声明的节点表示
AST节点通常分为三类:表达式节点、语句节点和声明节点。以下是一些常见结构的表示方式:
表达式节点(Expression Node)
例如,表达式 a + b * c 可以表示为:
graph TD
A[+] --> B[a]
A --> C[*]
C --> D[b]
C --> E[c]
语句节点(Statement Node)
如赋值语句 a = b + c; :
graph TD
Assign[=] --> Var[a]
Assign --> Add[+]
Add --> B[b]
Add --> C[c]
声明节点(Declaration Node)
如变量声明 int x = 5; :
graph TD
Decl[int] --> Var[x]
Var --> Init[=]
Init --> Val[5]
4.2.3 属性的存储与访问
AST节点中常需要存储一些附加属性,如变量的类型、常量的数值、操作符优先级等。这些属性可以通过结构体扩展或附加字段实现。
例如,扩展AST节点以支持类型信息:
typedef enum {
TYPE_INT,
TYPE_FLOAT,
TYPE_STRING
} ValueType;
typedef struct ASTNode {
NodeType type;
ValueType valType;
union {
int intVal;
float floatVal;
char* strVal;
} value;
struct ASTNode* left;
struct ASTNode* right;
} ASTNode;
这种设计使得每个节点不仅能够保存结构信息,还能携带语义信息,为后续的语义分析提供了基础。
4.3 AST的构建实践
4.3.1 在语法分析过程中嵌入AST构造逻辑
在使用工具如Bison进行语法分析时,可以通过在语法规则中嵌入构造AST的逻辑来实现AST的生成。以下是一个简单的Bison规则示例:
expr:
expr '+' term {
$$ = create_ast_node(NODE_EXPR, "+", $1, $3);
}
| term {
$$ = $1;
}
;
term:
term '*' factor {
$$ = create_ast_node(NODE_EXPR, "*", $1, $3);
}
| factor {
$$ = $1;
}
;
factor:
NUMBER {
$$ = create_ast_leaf(NODE_EXPR, TYPE_INT, $1);
}
| '(' expr ')' {
$$ = $2;
}
| ID {
$$ = create_ast_leaf(NODE_EXPR, TYPE_VAR, $1);
}
;
逐行解释:
-
expr '+' term:表示加法表达式。 -
$$ = create_ast_node(...):创建一个新的AST节点,左子节点为$1(expr的结果),右子节点为$3(term的结果)。 -
create_ast_leaf(...):用于创建叶子节点,如数字或变量。
4.3.2 AST的遍历与打印
构建完AST后,为了验证其结构是否正确,通常需要进行遍历并打印节点信息。常见的遍历方式包括前序、中序和后序遍历。
以下是一个前序遍历的示例函数:
void print_ast(ASTNode* node, int depth) {
if (node == NULL) return;
for (int i = 0; i < depth; i++) printf(" ");
printf("%s\n", node->value);
print_ast(node->left, depth + 1);
print_ast(node->right, depth + 1);
}
逐行解析:
-
depth控制缩进,使输出结构更清晰。 - 先打印当前节点,再递归打印左右子节点。
- 输出结果将呈现树状结构,便于调试和验证。
4.3.3 AST的验证与调试方法
为了确保AST的结构正确,应采用以下调试策略:
- 单元测试 :为每个语法结构编写对应的测试用例,验证AST是否生成正确。
- 可视化工具 :使用图形化工具(如Graphviz)将AST转换为可视化的树状图。
- 日志输出 :在构建AST时输出详细的构建过程日志,便于追踪错误。
例如,使用Graphviz生成AST图像:
digraph AST {
"+" -> "a";
"+" -> "*" -> "b";
"+" -> "*" -> "c";
}
将上述代码保存为 .dot 文件,运行 dot -Tpng ast.dot -o ast.png 即可生成图像。
本章系统地介绍了AST的基本概念、节点设计方法以及构建与验证的实际操作。通过代码示例与流程图展示,读者可以掌握如何在语法分析过程中构建AST,并理解其在整个编译流程中的关键作用。
5. 语义分析与类型检查
5.1 语义分析的基本任务
5.1.1 变量与函数的声明检查
语义分析是编译过程中的关键阶段,其主要任务是在语法结构正确的基础上,进一步验证程序的语义是否符合语言规范。变量和函数的声明检查是语义分析中的基础任务之一。
变量的声明检查主要涉及以下方面:
- 是否存在重复声明 :确保在同一个作用域内,变量名不重复。
- 是否在使用前声明 :变量必须在使用之前被声明,否则会引发“未声明”错误。
- 作用域规则 :变量的作用域是否符合语言规范,例如局部变量是否在函数体内声明,全局变量是否在合适的位置声明。
函数的声明检查则包括:
- 函数参数类型匹配 :调用函数时传递的参数类型必须与函数定义的参数类型匹配。
- 返回类型一致性 :函数返回值的类型必须与声明的返回类型一致。
- 函数重载处理 :若语言支持函数重载,则需要根据参数类型选择正确的函数版本。
例如,在C语言中,以下代码会触发变量未声明错误:
int main() {
printf("%d\n", x); // x未声明
return 0;
}
语义分析器在此阶段会遍历AST,检查每个变量和函数的使用是否满足上述条件,并记录相应的符号信息。
5.1.2 类型推导与类型匹配
类型推导(Type Inference)是现代编译器中常见的一项功能,尤其在具有类型推导机制的语言中,如C++11、Rust、TypeScript等。语义分析阶段需要根据上下文推断表达式的类型,并与预期类型进行匹配。
类型匹配的基本规则包括:
- 赋值兼容性 :左侧变量的类型必须能接受右侧表达式的类型。
- 运算符类型检查 :例如加法运算符两边的类型必须相同或可转换。
- 函数参数类型匹配 :函数调用时,参数类型必须与函数定义的参数类型一致或可隐式转换。
以如下C++代码为例:
auto x = 10; // 类型推导为int
auto y = 3.14; // 类型推导为double
int z = x + y; // 类型匹配:int + double → double → 赋值给int,可能触发警告
在语义分析过程中,编译器首先推导出 x 为 int 、 y 为 double ,然后在 x + y 表达式中进行类型提升( int 提升为 double ),最终结果为 double 。由于 z 是 int 类型,因此赋值操作会引发类型不匹配警告。
5.1.3 作用域与符号表管理
作用域管理是语义分析的重要组成部分,它决定了变量和函数在程序中的可见性和生命周期。编译器通过符号表(Symbol Table)来记录和管理作用域中的符号信息。
符号表的结构通常采用 栈式作用域结构 ,每个作用域对应一个符号表条目,例如:
graph TD
A[全局作用域] --> B[函数main]
B --> C[函数main内的块作用域]
符号表中每个条目包含以下信息:
| 字段名 | 描述 |
|---|---|
| 名称(Name) | 变量或函数名 |
| 类型(Type) | 数据类型(如int、double) |
| 作用域级别 | 所在作用域的嵌套深度 |
| 内存偏移量 | 在栈帧中的偏移位置 |
| 是否已初始化 | 是否在定义时被初始化 |
符号表的构建通常与AST遍历同步进行。每当进入一个新的作用域(如函数体、if语句块),就创建一个新的符号表层级;退出作用域时则弹出该层级。
例如,在如下C代码中:
int x = 10; // 全局变量
void foo() {
int x = 20; // 局部变量
printf("%d\n", x); // 输出20
}
语义分析器会识别出两个不同的 x 变量,并在符号表中分别记录它们的作用域信息。
5.2 类型系统的实现
5.2.1 基本类型与复合类型的定义
类型系统是编译器的核心部分之一,用于确保程序在运行时不会出现类型错误。类型系统通常分为基本类型和复合类型。
基本类型(Primitive Types) 包括:
-
int(整数) -
float/double(浮点数) -
char(字符) -
bool(布尔值)
复合类型(Composite Types) 包括:
- 数组(Array)
- 结构体(Struct)
- 联合体(Union)
- 指针(Pointer)
- 枚举(Enum)
例如,在C语言中,定义一个结构体并使用:
struct Point {
int x;
int y;
};
int main() {
struct Point p;
p.x = 10;
p.y = 20;
return 0;
}
在语义分析阶段,编译器会为 struct Point 构建类型描述,并在访问 p.x 和 p.y 时验证字段是否存在以及类型是否匹配。
5.2.2 类型转换与类型兼容性判断
类型转换是程序中常见的操作,分为 隐式类型转换 (自动转换)和 显式类型转换 (强制转换)。语义分析需要判断类型转换是否合法。
例如:
int a = 10;
double b = a; // 隐式转换:int → double
int c = (int)b; // 显式转换:double → int
类型兼容性判断规则包括:
- 数值类型之间的转换 :如int→float、float→double等。
- 指针与void指针之间的转换 :允许将任意指针转换为
void*,反之亦然。 - 枚举与整型之间的转换 :枚举值可以隐式转换为整数,反之需显式转换。
在语义分析过程中,编译器会对每个表达式进行类型检查,并在遇到不兼容的转换时报告错误。例如:
int *p = (int*)malloc(10);
char *q = p; // 错误:int* → char* 不允许隐式转换
5.2.3 错误检测与类型错误报告
类型错误是编译器最常见的错误之一,语义分析阶段必须准确检测并报告这些错误。常见的类型错误包括:
- 类型不匹配 :如将
int赋值给char*。 - 无效的操作符使用 :如对指针进行乘法运算。
- 函数参数类型不匹配 :如传递
float给需要int的函数参数。
错误报告机制通常包括以下信息:
- 错误位置 :文件名、行号。
- 错误类型 :类型不匹配、未定义变量等。
- 错误描述 :详细的错误信息,例如“不能将int赋值给char*”。
例如,以下代码将触发类型不匹配错误:
int main() {
char *p = 100; // 错误:int → char* 不合法
return 0;
}
语义分析器在遍历时会检测到赋值操作中类型不匹配,并输出类似如下错误信息:
error: invalid conversion from 'int' to 'char*' [-fpermissive]
5.3 实践:基于AST的语义分析模块实现
5.3.1 符号表的构建与管理
符号表的实现是语义分析模块的核心部分。我们可以使用栈结构来管理不同作用域的符号表,每个作用域对应一个符号表层级。
下面是一个符号表的简化实现(使用C++):
#include <iostream>
#include <stack>
#include <unordered_map>
#include <string>
struct Symbol {
std::string name;
std::string type;
int scope_level;
};
class SymbolTable {
private:
std::stack<std::unordered_map<std::string, Symbol>> scopes;
public:
void enter_scope() {
scopes.push(std::unordered_map<std::string, Symbol>());
}
void exit_scope() {
if (!scopes.empty()) scopes.pop();
}
void add_symbol(const std::string& name, const std::string& type) {
if (scopes.empty()) enter_scope();
Symbol s = {name, type, (int)scopes.size()};
scopes.top()[name] = s;
}
bool lookup_symbol(const std::string& name, Symbol& out) {
for (auto it = scopes.rbegin(); it != scopes.rend(); ++it) {
auto found = it->find(name);
if (found != it->end()) {
out = found->second;
return true;
}
}
return false;
}
};
代码解释:
-
enter_scope()和exit_scope():用于进入和退出作用域,维护栈结构。 -
add_symbol():将变量或函数添加到当前作用域的符号表中。 -
lookup_symbol():从当前作用域开始查找变量或函数的定义。
5.3.2 类型检查的遍历策略
类型检查通常通过对AST的递归遍历实现。每个AST节点代表一个表达式或语句,语义分析器需要递归地访问每个节点并执行类型检查。
以下是一个简化版的类型检查函数(C++):
struct ASTNode {
virtual std::string type_check() = 0;
};
struct BinaryOpNode : public ASTNode {
ASTNode* left;
ASTNode* right;
std::string op;
BinaryOpNode(ASTNode* l, ASTNode* r, const std::string& o)
: left(l), right(r), op(o) {}
std::string type_check() override {
std::string t1 = left->type_check();
std::string t2 = right->type_check();
if (t1 != t2) {
std::cerr << "Type mismatch: " << t1 << " vs " << t2 << std::endl;
exit(1);
}
if (op == "+" || op == "-" || op == "*" || op == "/") {
if (t1 != "int" && t1 != "float") {
std::cerr << "Invalid operand type for arithmetic: " << t1 << std::endl;
exit(1);
}
return t1; // 返回结果类型
}
return "unknown";
}
};
代码解释:
-
BinaryOpNode表示二元操作表达式(如加法、减法)。 -
type_check()方法递归检查左右操作数的类型,并验证操作符是否适用于该类型。 - 若类型不匹配或操作符不适用,则输出错误信息并终止编译。
5.3.3 语义错误的处理与提示机制
语义错误处理机制需要在类型检查过程中集成错误提示逻辑。可以设计一个统一的错误报告类,用于收集和输出错误信息。
示例代码如下:
#include <vector>
#include <string>
#include <iostream>
struct SemanticError {
int line_number;
std::string message;
};
class ErrorReporter {
private:
std::vector<SemanticError> errors;
int current_line;
public:
void set_line(int line) { current_line = line; }
void report_error(const std::string& msg) {
errors.push_back({current_line, msg});
}
bool has_errors() const { return !errors.empty(); }
void print_errors() const {
for (const auto& err : errors) {
std::cerr << "Line " << err.line_number << ": " << err.message << std::endl;
}
}
};
使用方式:
在类型检查过程中,每当发现错误,调用 report_error() 方法记录错误信息。最后在编译结束前调用 print_errors() 输出所有语义错误。
例如:
ErrorReporter reporter;
reporter.set_line(42);
reporter.report_error("Type mismatch in assignment");
reporter.print_errors();
输出:
Line 42: Type mismatch in assignment
通过上述机制,我们可以构建一个完整的语义分析模块,为后续的代码生成提供准确的类型信息和符号信息。
6. 中间代码生成技术
在编译器的构建过程中,中间代码生成是一个承上启下的关键阶段。它承接了前端的语义分析结果(如AST),为后端的代码优化与目标代码生成提供统一的中间表示(Intermediate Representation, IR)。本章将深入探讨中间代码的基本形式、生成策略,并通过具体实践展示如何基于AST生成IR。
6.1 中间表示(IR)的基本形式
中间表示(IR)是编译器内部用于表示程序结构的一种抽象形式,其设计直接影响后续的优化和代码生成效率。
6.1.1 三地址码与控制流图
三地址码(Three-Address Code, TAC)是一种常见的低级IR形式,每条指令最多有三个操作数,形式如下:
t1 = a + b
t2 = t1 * c
TAC的优点在于结构清晰,便于进行控制流分析和优化。
控制流图(Control Flow Graph, CFG)则用于表示程序的执行路径。每个节点代表一个基本块(Basic Block),边表示控制转移。
graph TD
A[入口] --> B[基本块1]
B --> C[基本块2]
B --> D[基本块3]
C --> E[出口]
D --> E
6.1.2 SSA形式与控制流分析
静态单赋值形式(Static Single Assignment, SSA)是一种增强的IR形式,要求每个变量只被赋值一次。例如:
x1 = a + b
x2 = x1 * c
SSA形式便于进行数据流分析和优化,如常量传播、死代码消除等。
6.1.3 IR的表示与存储方式
IR通常以结构体或类的形式在内存中表示。例如,使用C++定义TAC结构如下:
struct Instruction {
std::string dest; // 目标寄存器或变量
std::string op; // 操作符,如 "+", "*", "=", etc.
std::string arg1; // 第一个操作数
std::string arg2; // 第二个操作数(可选)
};
所有指令可组织为一个列表或基本块集合,便于后续处理。
6.2 中间代码生成的策略
中间代码的生成需要遵循一定的翻译规则,将AST中的节点转换为IR指令。
6.2.1 表达式的翻译规则
以表达式 a + b * c 为例,翻译过程如下:
- 先翻译
b * c,生成临时变量t1。 - 再翻译
a + t1,生成最终结果t2。
对应IR:
t1 = b * c
t2 = a + t1
每个表达式节点在遍历时生成相应的指令,并返回其结果变量名。
6.2.2 控制结构的中间代码生成
以 if-else 结构为例,其IR生成需考虑跳转标签和条件判断:
if (a > b) {
x = 1;
} else {
x = 2;
}
生成的IR可能如下:
if a > b goto L1
goto L2
L1:
x = 1
goto L3
L2:
x = 2
L3:
在遍历AST时,需为每个分支生成唯一的标签,并插入相应的 goto 指令。
6.2.3 函数调用与返回值的处理
函数调用需要处理参数传递与返回值接收。例如:
int result = add(a, b);
生成IR如下:
param a
param b
call add, 2
result = return_val
其中, param 表示参数入栈, call 表示调用函数, return_val 存储返回值。
6.3 实践:基于AST生成中间代码
接下来我们通过一个具体的实践步骤,展示如何基于AST生成中间代码。
6.3.1 设计中间代码的数据结构
我们首先定义中间代码的表示结构:
enum class Opcode {
ADD, SUB, MUL, DIV, ASSIGN,
IF, GOTO, LABEL, CALL, RETURN
};
struct IRInstruction {
Opcode op;
std::string dest;
std::string src1;
std::string src2;
std::string label; // 用于跳转指令
};
每条IR指令根据操作类型决定使用哪些字段。
6.3.2 实现代码生成函数
我们编写一个递归函数来遍历AST并生成IR:
std::string generateIR(ASTNode* node, std::vector<IRInstruction>& ir, int& tempCounter) {
switch (node->type) {
case NodeType::BinaryOp: {
std::string left = generateIR(node->left, ir, tempCounter);
std::string right = generateIR(node->right, ir, tempCounter);
std::string temp = "t" + std::to_string(tempCounter++);
Opcode opCode;
switch (node->op) {
case OpType::Add: opCode = Opcode::ADD; break;
case OpType::Sub: opCode = Opcode::SUB; break;
case OpType::Mul: opCode = Opcode::MUL; break;
case OpType::Div: opCode = Opcode::DIV; break;
default: throw std::runtime_error("Unsupported operator");
}
ir.push_back({opCode, temp, left, right, ""});
return temp;
}
case NodeType::Number:
return node->value;
case NodeType::Identifier:
return node->name;
case NodeType::Assign: {
std::string rhs = generateIR(node->right, ir, tempCounter);
ir.push_back({Opcode::ASSIGN, node->left->name, rhs, "", ""});
return rhs;
}
// 其他节点类型可继续扩展
default:
throw std::runtime_error("Unsupported node type");
}
}
此函数返回当前表达式的结果变量名,并将生成的IR指令存入 ir 向量中。
6.3.3 生成并测试中间代码输出
我们以表达式 a = b + c * d 为例,构造AST并调用上述函数:
// 构建AST示例:a = b + c * d
ASTNode* root = new ASTNode(NodeType::Assign);
root->left = new ASTNode(NodeType::Identifier, "a");
root->right = new ASTNode(NodeType::BinaryOp, OpType::Add);
root->right->left = new ASTNode(NodeType::Identifier, "b");
root->right->right = new ASTNode(NodeType::BinaryOp, OpType::Mul);
root->right->right->left = new ASTNode(NodeType::Identifier, "c");
root->right->right->right = new ASTNode(NodeType::Identifier, "d");
std::vector<IRInstruction> ir;
int tempCounter = 0;
generateIR(root, ir, tempCounter);
// 打印生成的IR
for (const auto& instr : ir) {
std::cout << opcodeToString(instr.op) << " " << instr.dest << " = " << instr.src1;
if (!instr.src2.empty()) std::cout << " " << instr.src2;
std::cout << std::endl;
}
输出结果应为:
MUL t0 = c d
ADD t1 = b t0
ASSIGN a = t1
这表明我们成功地从AST中生成了对应的三地址码形式的中间代码。
在下一章中,我们将进一步探讨中间代码的优化技术,如常量折叠、公共子表达式消除等,以提升程序性能。
简介:编译原理是计算机科学的核心课程之一,主要研究如何将高级语言转换为机器指令。本课程设计项目通过完整的编译器实现流程,帮助学生掌握词法分析、语法分析、语义分析、中间代码生成、代码优化及目标代码生成等关键技术。项目包含源代码与可执行文件,并结合设计报告,提升学生的实践与分析能力,是理解编译机制、提升系统级编程能力的重要实践内容。


















 1507
1507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









