







一、概述
集合类和数组?
数组元素既可以是基本类型的值,也可以是对象(实际上是对象的引用变量) 而集合里只能保存对象(实际上只是保存对象的引用变量)。
所有集合类都在java.util包下
体系结构
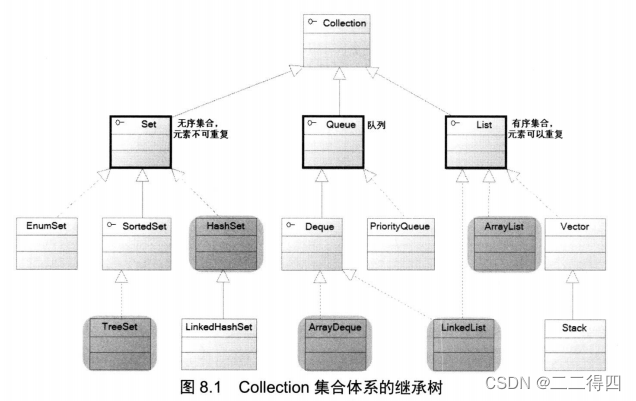
Java集合类由两个接口派生:Collection和Map
二、Collection和Iterator接口
Collection接口是List、Set和Queue接口的父接口,该接口里定义的方法既可用于操作Set集合,也可用于操作List和Queue集合。
2.1 基本使用
public class CollectionTest {
public static void main(String[] args) {
Collection c = new ArrayList();
Collection a = new ArrayList();
// 添加
c.add("java");
a.add("python");
c.add(66); //虽然集合不能放基本类型的值,但Java支持自动装箱
System.out.println("c集合的元素个数为:"+c.size()); //2
System.out.println("a集合的元素个数为:"+a.size()); //1
System.out.println("-------------------------------------");
// a加入c中
c.addAll(a);
System.out.println("c集合的元素个数为:"+c.size()); //3
System.out.println("a集合的元素个数为:"+a.size()); //1
System.out.println("-------------------------------------");
// 删除指定
c.remove(66);
System.out.println("c集合的元素个数为:"+c.size()); //2
System.out.println("-------------------------------------");
// 是否包含python
System.out.println("c集合是否包含python:"+c.contains("python")); //true
System.out.println("-------------------------------------");
// c是否包含a的元素
System.out.println("c集合是否包含a:"+c.containsAll(a)); //true
System.out.println("-------------------------------------");
// a是否为空
System.out.println(" a是否为空:"+a.isEmpty()); //false
System.out.println("-------------------------------------");
// 清空
c.clear();
System.out.println("c集合的元素个数为:"+c.size()); //0
System.out.println("-------------------------------------");
}
}
2.2 遍历集合
2.2.1 Lambda表达式
public class CollectionEach {
public static void main(String[] args) {
Collection books = new HashSet();
books.add("java");
books.add("python");
//1. 用lambda表达式:调用foreach
books.forEach(o -> System.out.println("迭代集合:"+o));
System.out.println("--------------------------------");
}
}
2.2.2 Iterator迭代器
public class IteratorTest {
public static void main(String[] args) {
Collection books = new HashSet();
books.add("java");
books.add("python");
books.add("c");
//获取迭代器
Iterator it = books.iterator();
//集合元素没被遍历完
while (it.hasNext()){
String book = (String) it.next();//it.hasNext()返回的是object类型,要强制类型转换
System.out.println(book); //打印出python、Java、c
if(book.equals("c")){
it.remove();
}
book = "javascript"; //不会影响外面
}
System.out.println(books); //[python, java]
}
}
2.2.3 使用Lambda表达式遍历Iterator
public class IteratorEach {
public static void main(String[] args) {
Collection books = new HashSet();
books.add("java");
books.add("python");
books.add("c");
Iterator it = books.iterator();
it.forEachRemaining(o -> System.out.println(o));
}
}
2.2.4 使用foreach循环遍历集合元素
public class ForeachTest {
public static void main(String[] args) {
Collection books = new HashSet();
books.add("java");
books.add("python");
books.add("c");
for (Object obj: books) {
String book = (String) obj;
System.out.println(book);
}
}
}
2.3 removeIf(Predicate filter)
Java8为Collection集合新增了一个removelf(Predicate filter)方法,该方法将会批量删除符合filter条件的所有元素。
public class ForeachTest {
public static void main(String[] args) {
Collection books = new HashSet();
books.add("java");
books.add("python");
books.add("c");
books.removeIf(o -> ((String)o).equals("c")); //过滤掉C
System.out.println(books); //[python, java]
}
}
2.4 Stream操作集合
public class PredicateTest2 {
public static void main(String[] args) {
Collection books = new HashSet();
books.add("java");
books.add("python");
books.add("c");
books.add("ajax");
System.out.println(books.stream().filter(o -> ((String)o).contains("aj")).count()); //记录包含aj
System.out.println(books.stream().filter(o -> ((String)o).contains("java")).count());//记录包含aj
System.out.println(books.stream().filter(o -> ((String)o).length()>4).count());//记录大于四
books.stream().filter(o -> ((String)o).length()>4).forEach(System.out::println); //打印
}
}
三、Set集合
3.1 HashSet类
3.1.1 特点
不能保证元素的排列顺序,顺序可能与添加顺序不同,顺序也有可能发生变化。
HashSet不是同步的,多个线程同时访问一个HashSet,假设有两个或者两个以上线程同时修改了HashSet集合时,则必须通过代码来保证其同步。
集合元素值可以是null
3.1.2 流程
向HashSet集合中存入一个元素时,HashSet会调用该对象的hashCode()得到该对象的hashCode值,然后根据该hashCode值决定该对象在HashSet中的存储位置.如果有两个元素通过equals()比较返回true,但它们的hashCode()方法返回值不相等,HashSet将会把它们存储在不同的位置,依然可以添加成功。
3.1.3hashcode()对Hashset重要性
hash算法的功能是,它能保证快速查找被检索的对象,hash算法的价值在于速度。
当需要查询集合中某个元素时,hash算法可以直接根据该元素的hashCode值计算出该元素的存储位置,从而快速定位该元素。
表面上看起来,HashSet集合里的元素都没有素引,实际上程序向HashSet集合中添加元素时,HashSet会根据该元素的hashCode值来计算它的存储位置,这样也可快速定位该元素。
3.1.4不用数组?用HashSet
因为数组元素的索引是连续的,而且数组的长度是固定的,无法自由增加数组的长度。而HashSet就不一样了,HashSet采用每个元素的hashCode值来计算其存储位置,从而可以自由增加HashSet的长度,并可以根据元素的hashCode值来访问元素。因此,省去从HashSet中访问元素时,HashSet先计算该元素hashCode值,然后直接到该hashCode值对应的位置去取出该元素—这就是HashSet速度
很快的原因。
也就是说,HashSet集合判断两个元素相等的标准是两个对象通过equals()比较相等,并且两个对象的hashCode()返回值也相等。
3.1.5 重写equals()和hashcode()
//类A的equals()方法总是返回true,但没有重写其hashCode()方法
class A{
public boolean equals(Object obj){
return true;
}
}
//类B的hashCode()方法总是返回1,但没有重写其equals()方法
class B{
public int hashCode(){
return 1;
}
}
//类C的equals()方法总是返回2,重写其hashCode()方法
class C{
public boolean equals(Object obj){
return true;
}
public int hashCode(){
return 2;
}
}
public class HashSetTest {
public static void main(String[] args) {
HashSet books = new HashSet();
books.add(new A());
books.add(new A());
books.add(new B());
books.add(new B());
books.add(new C());
books.add(new C());
System.out.println(books); //B@1, B@1, C@2, A@74a14482, A@1540e19d]
//A通过equals()比较返回true,hashset当成2个对象
//B通过hashcode()都返回1,hashset当成2个对象
//C返回2,hashset当成1个对象
}
}
3.2 LinkedHashSet类
HashSet还有一个子类LinkedHashSet,LinkedHashSet集合也是根据元素的hashCode值来决定元素的存储位置,但它同时使用链表维护元素的次序,这样使得元素看起来是以插入的顺序保存的。也就是说,当遍历LinkedHashSet集合里的元素时,LinkedHashSet将会按元素的添加顺序来访问集合里的元素。
LinkedHashSet需要维护元素的插入顺序,因此性能略低于HashSet的性能,但在迭代访问Set里的全部元素时将有很好的性能,因为它以链表来维护内部顺序。
public class LinkedHashSetTest {
public static void main(String[] args) {
LinkedHashSet book = new LinkedHashSet();
book.add("java");
book.add("python");
System.out.println(book); //[java, python]
book.remove("python");
System.out.println(book); //[java]
}
}
3.3 TreeSet类
TreeSet是SortedSet接口的实现类,TreeSet可以确保集合元素处于排序状态。
如果希望TreeSet能正常运作,TreeSet只能添加同一种类型的对象
public class TreeSetTest {
public static void main(String[] args) {
TreeSet ts = new TreeSet();
ts.add(-1);
ts.add(7);
ts.add(-8);
ts.add(4);
ts.add(10);
System.out.println(ts.first()); //-8
System.out.println(ts.last()); //10
System.out.println(ts.headSet(4)); //[-8, -1] 小于不包含4
System.out.println(ts.tailSet(8)); //[10] 大于8
}
}
3.3.1 自然排序
TreeSet会调用集合元素的compare To(Object obj)方法来比较元素之间的大小关系,然后将集合元素按升序排列,这种方式就是自然排序。默认也是。
Java提供了一个Comparable接口,该接口里定义了一个compareTo(Object obj)方法,该方法返回一个整数值,实现该接口的类必须实现该方法,实现了该接口的类的对象就可以比较大小。
3.3.2 定制排序
如果需要实现定制排序,则需要在创建TreeSet集合对象时,提供一Comparator对象与该TreeSet集合关联,由该Comparator对象负责集合元素的排序逻辑。由于Comparator是一个函数式接口,因此可使用Lambda表达式来代替Comparator对象。
3.4 EnumSet类
EnumSet是一个专为枚举类设计的集合类,EnumSet中的所有元素都必须是指定枚举类型的枚举值,该枚举类型在创建EnumSet时显式或隐式地指定。
EnumSet的集合元素也是有序的,在Enum类内的定义顺序来决定集合元素的顺序。
EnumSet在内部以位向量的形式存储,这种存储形式非常紧凑、高效,因此EnumSet对象占用内存很小,而且运行效率很好。尤其是进行批量操作(如调用containsAll()和retainAll()方法)时,如果其参数也是EnumSet集合,则该批量操作的执行速度也非常快。
EnumSet集合不允许加入null元素,如果试图插入null元素,EnumSet将抛出NullPointerException异常。如果只是想判断EnumSet是否包含null元素或试图删除null元素都不会抛出异常,只是删除操作将返回false,因为没有任何null元素被删除。
EnumSet类没有暴露任何构造器来创建该类的实例,程序应该通过它提供的类方法来创建EnumSet对象。
enum Season{
spring,summer,fall,winter;
}
public class EnumSetTest {
public static void main(String[] args) {
//创建一个EnumSet集合,集合元素是Season枚举类全部枚举值
EnumSet es1 = EnumSet.allOf(Season.class);
System.out.println(es1); //[spring, summer, fall, winter]
//创建一个EnumSet空集合,指定集合元素是Season枚举类
EnumSet es2 = EnumSet.noneOf(Season.class);
System.out.println(es2); //[]
es2.add(Season.winter);
es2.add(Season.spring);
System.out.println(es2); //[spring, winter]
//创建EnumSe中Season枚举类
EnumSet es3 = EnumSet.of(Season.summer,Season.spring);
System.out.println(es3); //[spring, summer]
//创建EnumSe中Season枚举类
EnumSet es4 = EnumSet.range(Season.spring,Season.fall);
System.out.println(es4); //[spring, summer, fall]
//创建EnumSe中Season枚举类
EnumSet es5 = EnumSet.complementOf(es4);
System.out.println(es5); //[winter]
//创建EnumSe中Season枚举类
EnumSet es6 = EnumSet.copyOf(es4);
System.out.println(es6); //[spring, summer, fall]
}
}
3.5 各Set实现类的性能分析
HashSet的性能总是比TreeSet好(特别是最常用的添加、查询元素等操作),因为TreeSet需要额外的红黑树算法来维护集合元素的次序。只有当需要一个保持排序的Set时,才应该使用TreeSet,否则都应该使用HashSet。
HashSet还有一个子类:LinkedHashSet,对于普通的插入、删除操作LinkedHashSet比HashSet要略微慢一点,这是由维护链表所带来的额外开销造成的,但由于有了链表,遍历LinkedHashSet会更快。
EnumSet是所有Set实现类中性能最好的,但它只能保存同一个枚举类的枚举值作为集合元素。
必须指出的是,Set的三个实现类HashSet、TreeSet和EnumSet都是线程不安全的。如果有多个线程同时访问一个Set集合,并且有超过一个线程修改了该Set集合,则必须手动保证该Set集合的同步性。通常可以通过Collections工具类的synchronizedSortedSet方法来“包装”该Set集合。此操作最好在创建时进行,以防止对Set集合的意外非同步访问。
四、List集合
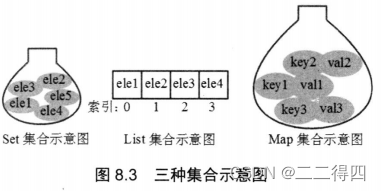
List集合代表一个元素有序、可重复的集合,集合中每个元素都有其对应的顺序索引。List集合允许使用重复元素,可以通过索引来访问指定位置的集合元素。Ls集合默认按元素的添加顺序设置元素的索引,例如第一次添加的元素索引为0,第二次添加的元素索引为1…
public class ListTest {
public static void main(String[] args) {
List books = new ArrayList();
books.add(new String("python"));
books.add(new String("java"));
System.out.println(books); //[python, java]
books.add(1,new String("ajax")); //在1的位置添加Ajax
System.out.println(books); //[python, ajax, java]
books.remove(2); //删除2位置元素
System.out.println(books); //[python, ajax]
books.set(1,new String("java")); //修改1位置
System.out.println(books); //[python, java]
System.out.println(books.subList(0,1)); //[python] 截取0-1,不包括1
System.out.println(books.indexOf("python")); //0 python在集合第一次出现的位置
}
}
public class ListTest2 {
public static void main(String[] args) {
List books = new ArrayList();
books.add(new String("python"));
books.add(new String("java"));
books.add(new String("ajax"));
books.sort(((o1, o2) -> ((String)o1).length()-((String)o2).length()));
System.out.println(books); //[java, ajax, python] 先比较字符串越长越大,一样长则看插入顺序
}
}
既可正向迭代也可反向迭代
public class ListIteratorTest {
public static void main(String[] args) {
String[] books={"python","java"};
List booklist = new ArrayList();
for (int i = 0;i<books.length;i++){
booklist.add(books[i]);
}
ListIterator listIterator = booklist.listIterator();
while (listIterator.hasNext()){
System.out.println(listIterator.next());
listIterator.add("=================");
}
System.out.println("---------------");
while (listIterator.hasPrevious()){
System.out.println(listIterator.previous());
}
}
}
4.1 ArrayList和Vector实现类
ArrayList和Vector类都是基于数组实现的List类,所以ArrayList和Vector类封装了一个动态的、允许再分配的Object()数组。ArrayList或Vector对象使用initialCapacity参数来设置该数组的长度,当向ArrayList或Vector中添加元素超出了该数组的长度时,它们的initialCapacity会自动增加。
4.1.1 ArrayList和Vector的显著区别是?
ArrayList是线程不安全的,当多个线程访问同一个ArrayList集合时,如果有超过一个线程修改了ArrayList集合,则程序必须手动保证该集合的同步性;
Vector集合则是线程安全的,无须程序保证该集合的同步性。因为Vector是线程安全的,所以Vector的性能比ArrayList的性能要低。实际上,即使需要保证List集合线程安全,也同样不推荐使用Vector实现类。
4.1.2 固定长度的List
public class FixedsizeList {
public static void main(String[] args) {
List fixedList = Arrays.asList("java","java ee");
System.out.println(fixedList.getClass()); //class java.util.Arrays$ArrayList 获取fixedList实现类
fixedList.forEach(System.out::println); //遍历集合元素 java java ee
// fixedList.add("ajax"); //报错:java.lang.UnsupportedOperationException 因为是固定长度不能加
}
}
五、Queue集合
Queue用于模拟队列这种数据结构,队列的头部保存在队列中存放时间最长的元素,队列的尾部保存在队列中存放时间最短的元素。新元素插入(offr)到队列的尾部,访问元素(poll)操作会返回队列头部的元素。通常,队列不允许随机访问队列中的元素。
5.1、PriorityQueue实现类
priorityQueue保存队列元素的顺序并不是按加入队列的顺序,而是按队列元素的大小进行重新排序。当调用peek()方法或者poll()方法取出队列中的元素时,取出队列中最小的元素。
public class PriorityQueueTest {
public static void main(String[] args) {
PriorityQueue pq = new PriorityQueue();
pq.offer(6);
pq.offer(-3);
pq.offer(20);
pq.offer(18);
System.out.println(pq); //[-3, 6, 20, 18]
System.out.println(pq.poll()); //-3
}
}
5.2、Deque接口与ArrayDeque实现类
Deque接口是Queue接口的子接口,它代表一个双端队列,允许从两端来操作队列的元素
public class ArrayDequestack {
public static void main(String[] args) {
ArrayDeque stack = new ArrayDeque(); //模拟栈
stack.push("python");
stack.push("java");
System.out.println(stack); //[java, python]
System.out.println(stack.peek()); //java
System.out.println(stack); //[java, python]
System.out.println(stack.pop()); //java
System.out.println(stack); //[python]
ArrayDeque queue = new ArrayDeque(); //模拟队列
queue.offer("python");
queue.offer("java");
System.out.println(queue); //[python, java]
System.out.println(queue.peek()); //python
System.out.println(queue); //[python, java]
System.out.println(queue.pop()); //python
System.out.println(queue); //[java]
}
}
5.3、LinkedList实现类
LinkedList类是List接口的实现类一一这意味着它是一个List集合,可以根据索引来随机访问集合中的元素。除此之外,LinkedList还实现了Deque接口,可以被当成双端队列来使用,因此既可以被当成“栈”来使用,也可以当成队列使用。
public class LinkedListTest {
public static void main(String[] args) {
LinkedList books = new LinkedList();
books.offer("python"); //加到队列尾部
books.push("java"); //加到栈的顶部
books.offerFirst("c"); //加到队列头部,相当于栈的顶部
for (int i =0;i<books.size();i++){
System.out.println(books.get(i)); //C JAVA PYTHON
}
System.out.println(books.peekFirst()); //c
System.out.println(books.peekLast()); //python
}
}
LinkedList与ArrayList、ArrayDeque的实现机制完全不同,ArrayList、ArrayDeque内部以数组的形式来保存集合中的元素,因此随机访问集合元素时有较好的性能:而LinkedList内部以链表的形式来保存集合中的元素,因此随机访问集合元素时性能较差,但在插入、删除元素时性能比较出色(只需改变指针所指的地址即可)。虽然Vector也是以数组的形式来存储集合元素的,但因为它实现了线程同步功能(而且实现机制也不好),所以各方面性能都比较差。
5.4、线性表性能分析
Java提供的List就是一个线性表接口,而ArrayList、LinkedList又是线性表的两种典型实现:基于数组的线性表和基于链的线性表。Queue代表了队列,Deque代表了双端队列
LinkedList集合不仅提供了List的功能,还提供了双端队列、栈的功能就行,由于数组以一块连续内存区来保存所有的数组元素,所以数组在随机访问时性能最好,所有的内部以数组作为底层实现的集合在随机访问时性能都比较好:而内部以链表作为底层实现的集合在执行插入、删除操作时有较好的性能。但总体来说,ArrayList的性能比LinkedList的性能要好
关于使用List集合有如下建议。
如果需要遍历List集合元素,对ArrayList、.Vector集合,应该使用随机访问方法(get)来遍历集合元素,这样性能更好;对于LinkedList集合,则应该采用迭代器(Iterator)来遍历集合元素。
如果需要经常执行插入、删除操作来改变包含大量数据的Lst集合的大小,可考虑使用LinkedList集合。使用ArrayList、Vector集合可能需要经常重新分配内部数组的大小,效果可能较差。
如果有多个线程需要同时访问List集合中的元素,开发者可考虑使用Collections将集合包装成线程安全的集合。
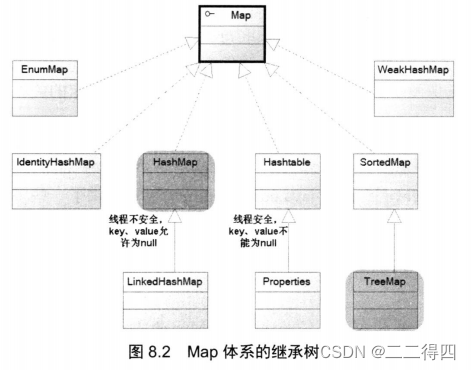
六、Map集合
Map用于保存具有映射关系的数据,key和value都可以是任何引用类型的数据。Map的key不允许重复,即同一个Map对象的任何两个key通过equals方法比较总是返回false.
public class MapTest {
public static void main(String[] args) {
Map map = new HashMap();
map.put("java",109);
map.put("python",12);
map.put("c",56);
System.out.println(map); //{python=12, java=109, c=56}
System.out.println("重新加一个python的值:"+ map.put("python",58)); //12, 若是和之前一样,返回原来值
System.out.println("是否包含Java:" + map.containsKey("java")); //是否包含Java:true
System.out.println("是否包含58的值:" + map.containsValue(58)); //是否包含58的值:true,虽然覆盖掉,但是值还在
for (Object key : map.entrySet()){
System.out.println("遍历key:" + key + ":"+map.get(key)); //python=58 java=109 c=56
}
map.remove("c");
System.out.println(map); //{python=58, java=109} 删除c
map.replace("xml",99);
System.out.println(map); //{python=58, java=109} 没有不做修改
map.merge("python",10,(old,param) -> (Integer)old + (Integer) param);
System.out.println(map); //{python=68, java=109} python+10了
map.computeIfPresent("java",(key,value) ->(Integer)value*(Integer) value);
System.out.println(map); //{python=68, java=11881} 109*109
}
}
6.1、HashMap和Hashtable实现类
HashMap和Hashtable都是Map接口的典型实现类,它们之间的关系完全类似于ArrayList和Vector的关系
Hashtable是一个线程安全的Map实现,但HashMap是线程不安全的实现,所HashMap比Hashtable的性能高一点;但如果有多个线程访问同一个Map对象时,使用Hashtable实现类会更好。
Hashtable不允许使用null作为key和value,如果试图把null值放进Hashtable中,将会引发NullPointerException异常;但HashMap可以使用null作为key或value。
public class MapTest1 {
public static void main(String[] args) {
HashMap map = new HashMap();
map.put(null,null);
map.put(null,null);
System.out.println(map); //不报错,但只出现一个{null=null},
map.put("a",null);
System.out.println(map); //{null=null, a=null} ,value可以多个null
}
}
6.2、LinkedHashMap实现类
HashSet有一个LinkedHashSet子类,HashMap也有一个LinkedHashMap子类,LinkedHashMap也使用双向链表来维护key-value对的次序,顺序与key-value对的插入顺序保持一致。
LinkedHashMap可以避免对HashMap、Hashtable里的key-value对进行排序,同时又可避免使用TreeMap所增加的成本。
LinkedHashMap需要维护元素的插入顺序,因此性能略低于HashMap的性能;但因为它以链表来维护内部顺序,所以在迭代访问Map里的全部元素时将有较好的性能。
public class LinkedHashMapTest {
public static void main(String[] args) {
LinkedHashMap score = new LinkedHashMap();
score.put("java",12);
score.put("c",20);
score.put("python",33);
score.forEach((key,value) -> System.out.println(key + ":" + value));
// java:12
//c:20
//python:33
}
}
6.3、使用Properties读写属性文件
Properties类是Hashtable类的子类,Properties类可以把Map对象和属性文件关联起来,从而可以把Map对象中的key-value对写入属性文件中,也可以把属性文件中的“属性名=属性值”加载到Map对象中。
public class PropertiesTest {
public static void main(String[] args) throws IOException {
Properties p = new Properties();
p.setProperty("username","ll");
p.setProperty("password","qw"); //必须字符串型
p.store(new FileOutputStream("a.ini"),"comment line"); //写入文件中
System.out.println(p);
}
}
6.4、SortedMap接口和TreeMap实现类
Map接口也派生出一个SortedMap子接口,SortedMap接口也有一个TreeMap实现类。
TreeMap就是一个红黑树数据结构,每个key-value对即作为红黑树的一个节点。TreeMap存储key-value对(节点)时,需要根据key对节点进行排序。TreeMap可以保证所有的key-value对处于有序状态。TreeMap也有两种排序方式:自然排序,定制排序
自然排序
class R implements Comparable{
int count;
public R(int count){
this.count = count;
}
@Override
public String toString() {
return "R{" +
"count=" + count +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
R r = (R) o;
return count == r.count;
}
@Override
public int compareTo(Object o) {
R r = (R)o;
return count > r.count ? 1: count < r.count ? -1:0;
}
}
public class TreeMapTest {
public static void main(String[] args) {
java.util.TreeMap tm = new java.util.TreeMap();
tm.put(new R(3),"spring");
tm.put(new R(-5),"java");
System.out.println(tm); //{R{count=-5}=java, R{count=3}=spring}
System.out.println("返回第一个entry对象:"+tm.firstEntry()); //返回第一个entry对象:R{count=-5}=java
System.out.println("返回最后一个key值:"+tm.lastKey()); //返回最后一个key值:R{count=3}
System.out.println("返回比new(2)大的值:"+tm.higherKey(new R(2))); //返回比new(2)大的值:R{count=3}
System.out.println("返回比new(2)小的值:"+tm.lowerKey(new R(2))); //返回比new(2)小的值:R{count=-5}
System.out.println(tm.subMap(new R(-1),new R(4))); //{R{count=3}=spring} 子map
}
}
6.5、WeakHashMap实现类
WeakHashMap与HashMap的用法基本相似。
与HashMap的区别在于,HashMap的key保留了对实际对象的强引用,这意味着只要该HashMap对象不被销毁,该HashMap的所有key所引用的对象就不会被垃圾回收,HashMap也不会自动删除这些key所对应的key-value对;但WeakHashMap的key只保留了对实际对象的弱引用,这意味着如果WeakHashMap对象的key所引用的对象没有被其他强引用变量所引用,则这些key所引用的对象可能被垃圾回收,WeakHashMap也可能自动删除这些key所对应的key-value对。
public class WeakHashMapTest {
public static void main(String[] args) {
WeakHashMap whm = new WeakHashMap();
//没被其他引用
whm.put(new String("java"),new String("58"));
whm.put(new String("c"),new String("51"));
whm.put(new String("python"),new String("22"));
//该key是一个系统缓存的字符串对象
whm.put("xml",new String("46"));
System.out.println(whm); //{xml=46, java=58, c=51, python=22}
//垃圾回收
System.gc();
System.runFinalization();
System.out.println(whm); //{xml=46}
}
}
6.6、IdentityHashMap实现类
在IdentityHashMap中,当且仅当两个key严格相等(keyl=key2)时,IdentityHashMap才认为两个key相等;对于普通的HashMap而言,只要keyl和key2通过equals()方法比较返回true,且它们的hashCode值相等即可。
public class IdentityHashMapTest {
public static void main(String[] args) {
IdentityHashMap ihm = new IdentityHashMap();
ihm.put(new String("语文"),89);
ihm.put(new String("语文"),79);
ihm.put("java",90);
ihm.put("java",22);
System.out.println(ihm); //{语文=89, java=22, 语文=79} new出来会当成2个处理,后面的会被当成1个
}
}
6.7、EnumMap实现类
EnumMap在内部以数组形式保存,所以这种实现形式非常紧凑、高效。
EnumMap根据key的定义顺序来维护key-value对的顺序。当程序通过keySet()、entrySet()、values()等方法遍历EnumMap时可以看到这种顺序。
.
EnumMap不允许使用nul作为key,但允许使用null作为value。使用null作为key时将抛出NullPointerException异常。如果只是查询是否包含值为null的key,或只是删除值为null的key,都不会抛出异常。
enum Season1{
spring,summer,fall,winter;
}
public class EnumMapTest {
public static void main(String[] args) {
EnumMap em = new EnumMap(Season1.class);
em.put(Season1.summer,"夏日炎炎");
em.put(Season1.spring,"春光明媚");
System.out.println(em); //{spring=春光明媚, summer=夏日炎炎}
}
}
6.8、各Map实现类的性能分析
HashMap和Hashtable的实现机制几乎一样,但由于Hashtable是一个古老的、线程安全的集合,因此HashMap通常比Hashtable要快。
TreeMap通常比HashMap、Hashtable要慢(尤其在插入、删除key-value对时更慢),因为TreeMap底层采用红黑树来管理key-value对(红黑树的每个节点就是一个key-value对)。TreeMap中的key-value对总是处于有序状态,无须专门进行排序操作。
当TreeMap被填充之后,就可以调用keySet(),取得由key组成的Set,然后使用toArray()方法生成key的数组,接下来使用Arrays的binarySearch()方法在已排序的数组中快速地查询对象。
程序应该多考虑使用HashMap,因为HashMap正是为快速查询设计的(HashMap底层其实也是采用数组来存储key-value对)。但如果程序需要一个总是排好序的Map时,则可以考虑使用TreeMap。
LinkedHashMap比HashMap慢一点,因为它需要维护链表来保持Map中key-value时的添加顺序。
EnumMap的性能最好,但它只能使用同一个枚举类的枚举值作为key。
6.9、HashSet和HashMap的性能选项
hash表里可以存储元素的位置被称为“桶(bucket)”,在通常情况下,单个“桶”里存储一个元素,此时有最好的性能:hash算法可以根据hashCode值计算出“桶”的存储位置,接着从“桶”中取出元素。但hash表的状态是open的:在发生“hash冲突”的情况下,单个桶会存储多个元素,这些元素以链表形式存储,必须按顺序搜索
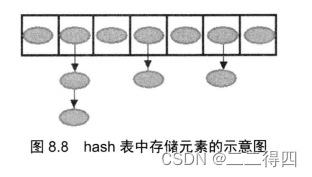
hash表里还有一个“负载极限”,“负载极限”是一个0-1的数值,“负载极限”决定了hash表的最大填满程度。当hash表中的负载因子达到指定的“负载极限”时,hash表会自动成倍地增加容量(桶的数量),并将原有的对象重新分配,放入新的桶内,这称为rehashing。
HashSet和HashMap、Hashtable的构造器允许指定一个负载极限,HashSet和HashMap、Hashtable默认的“负载极限”为0.75,这表明当该hash表的3/4已经被填满时,hash表会发生rehashing。
“负载极限”的默认值(0.75)是时间和空间成本上的一种折中:较高的“负载极限”可以降低hash表所占用的内存空间,但会增加查询数据的时间开销,而查询是最频繁的操作,较低的“负载极限”会提高查询数据的性能,但会增加hash表所占用的内存开销。
七、Collections工具类
public class SortTest {
public static void main(String[] args) {
ArrayList nums = new ArrayList();
nums.add (2);
nums.add (-5);
nums.add (3);
nums.add(0);
System.out.println(nums);//输出:[2, -5, 3, 0]
Collections.reverse(nums);
System.out.println("次序反转:"+ nums); // 次序反转:[0, 3, -5, 2]
Collections.sort(nums);
System.out.println("排序:"+ nums); // 排序:[-5, 0, 2, 3]
Collections.shuffle(nums);
System.out.println("混洗:"+ nums); //混洗:[3, -5, 0, 2]
System.out.println("最大元素:"+ Collections.max(nums)); //最大元素:3
System.out.println("nums中0用1代替:"+ nums); //nums中0用1代替:[3, 2, -5, 1]
Collections.replaceAll(nums,0,1);
System.out.println("nums中0用1代替:"+ nums); //nums中0用1代替:[3, 2, -5, 1]
System.out.println("-5出现的次数:"+Collections.frequency(nums,-5)); //-5出现的次数:1
Collections.sort(nums); //只有排序才可二分
System.out.println("二分法查-5位置:"+ Collections.binarySearch(nums,-5)); //二分法查-5位置:0
}
}
7.1、线程同步
Java中常用的集合框架中的实现类HashSet、TreeSet、ArrayList、ArrayDeque、LinkedList、HashMap和TreeMap都是线程不安全的。如果有多个线程访问它们,而且有超过一个的线程试图修改它们,则存在线程安全的问题。Collections类中提供了多个synchronizedXxx()方法,该方法可以将指定集合包装成线程同步的集合,从而可以解决多线程并发访问集合时的线程安全问题。
public class SynchronizedTest {
public static void main(String[] args) {
Collection c = Collections.synchronizedCollection(new ArrayList());
List list = Collections.synchronizedList(new ArrayList());
Set set = Collections.synchronizedSet(new HashSet());
Map map = Collections.synchronizedMap(new HashMap());
}
}
7.2、设置不可变集合
public class UnmodifiableTest {
public static void main(String[] args) {
List l = Collections.emptyList(); //1.创建一个空的,不可变的list对象
Set s = Collections.singleton("java"); //2.创建一个,不可变的set对象
Map m = new HashMap();
m.put("c",11);
m.put("python",20);
Map map = Collections.unmodifiableMap(m); //3.map对象不可变的版本
// l.add("1"); //java.lang.UnsupportedOperationException
//s.add("1"); //java.lang.UnsupportedOperationException
// map.put("1",1); //java.lang.UnsupportedOperationException
}
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









