







 本文深入探讨了MySQL的体系结构,包括连接层、SQL层和存储引擎层,重点讲解了InnoDB存储引擎。InnoDB采用单进程多线程模型,其内存结构包括缓冲池、日志缓冲和查询缓存等。InnoDB的存储结构由表空间、段、区和页组成,数据通过插入缓冲、双写缓冲和自适应哈希索引来优化性能。此外,文章还介绍了事务日志(redo log)和二进制日志(binlog)的刷新机制以及两阶段提交过程,确保数据一致性。
本文深入探讨了MySQL的体系结构,包括连接层、SQL层和存储引擎层,重点讲解了InnoDB存储引擎。InnoDB采用单进程多线程模型,其内存结构包括缓冲池、日志缓冲和查询缓存等。InnoDB的存储结构由表空间、段、区和页组成,数据通过插入缓冲、双写缓冲和自适应哈希索引来优化性能。此外,文章还介绍了事务日志(redo log)和二进制日志(binlog)的刷新机制以及两阶段提交过程,确保数据一致性。
MySQL的体系结构
分为两层,MySQL Server层和存储引擎层。在MySQL Server层中又包括连接层和SQL层。

各层详解
- 应用程序通过接口(如ODBC、JDBC)来连接MySQL。
最先连接处理的是连接层,连接层包括通信协议、线程处理、用户名密码认证三个部分。
通信协议负责检测客户端版本是否兼容MySQL服务端。
线程处理是指每一个连接请求都会分配一个对应的线程,相当于一条SQL对应一个线程,一个线程对应一个逻辑CPU,并会在多个逻辑CPU之间进行切换。
用户名密码认证验证创建的账号和密码,以及host主机授权是否可以连接到MySQL服务器。 - SQL层包含权限判断、查询缓存、解析器、预处理、查询优化器、缓存和执行计划。
权限判断可以审核用户有没有访问某个库、某个表,或者表里某行的权限。
查询缓存通过Query Cache进行操作,如果数据在Query Cache中,则直接返回结果给客户端。
Query Cache在生产中建议关闭,因为它只能缓存静态数据信息,一旦数据发生变化,经常读写,Query Cache就成了摆设。一般像数据仓库之类的可能会考虑开启Query Cache。
MySQL5.6之后默认是关闭的。
查询解析器针对SQL语句进行解析,判断语法是否正确。
预处理器对解析器无法解析的语义进行处理。
优化器对SQL进行改写和相应的优化,并生成最优的执行计划,就可以调用程序的API接口,通过存储引擎层访问数据。 - 存储引擎层也是MySQL数据库区别于其他数据库最核心的一点。
MySQL数据库及其分支版本主要的存储引擎有InnoDB、MyISAM、Memory、blackhole、TokuDB和MariaDB columnstore。
InnoDB和MyISAM是最主流的两个存储引擎,现在数据库版本默认的存储引擎是InnoDB,并且MySQL8.0宣布InnoDB存储数据字典,MyISAM彻底从MySQL数据库中剥离开被废弃。

InnoDB体系结构
MySQL数据库是一个单进程多线程模型的数据库。
数据库实例:进程+内存,操作数据时,在数据库实例里面进行,也就是内存。
数据库:存放数据。
内存中的数据通过线程将数据从内存刷新到磁盘上。
InnoDB体系结构实际上由内存结构、线程、磁盘文件这三层组成。 InnoDB体系结构图如下: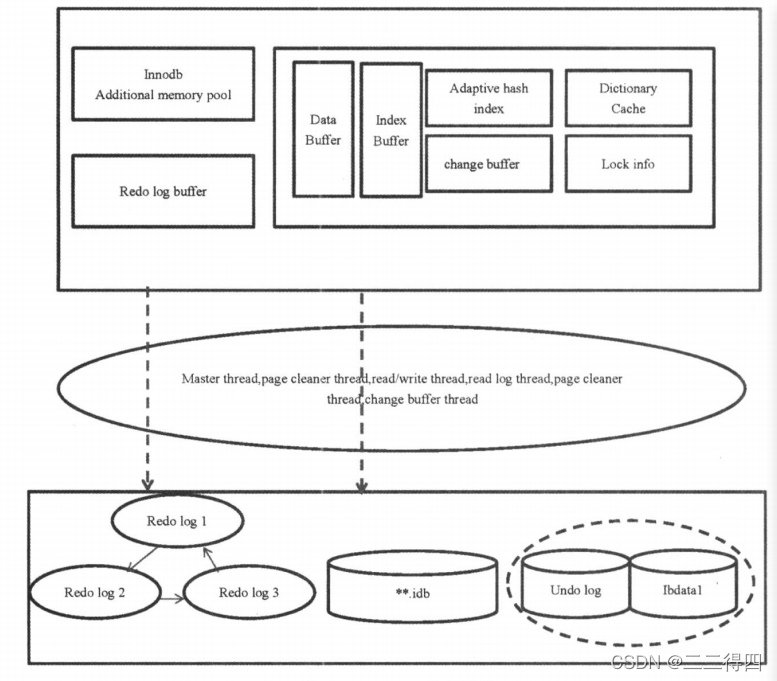
InnoDB存储结构
InnoDB逻辑存储单元主要分为表空间、段、区和页。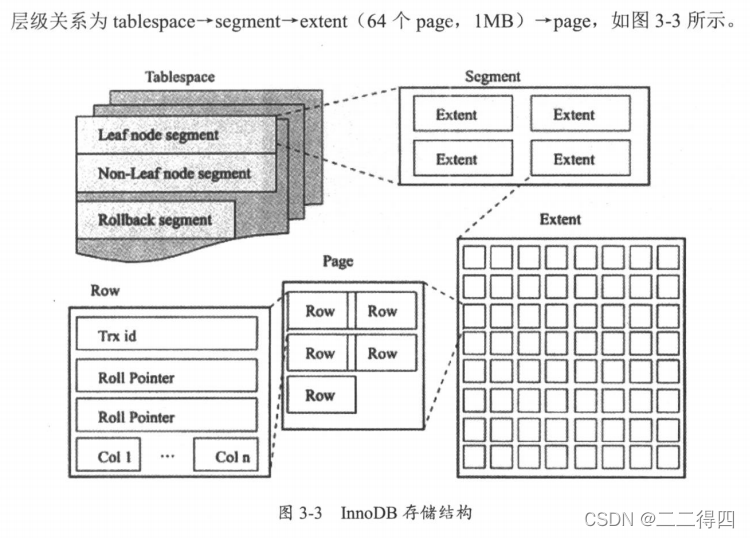 1.表空间
1.表空间
系统表空间
InnoDB存储引擎表中所有数据都是存储在表空间中的,表空间又分为系统表空间,它以ibdatal来命名,在安装数据库初始化数据时就是系统在创建一个ibdatal的表空间文件,它会存储所有数据的信息以及回滚段(undo)的信息。Innodb data file path负责定义系统表空间的路径、初始化大小、自动扩展策略。数据库默认的自动扩展大小是64MB。
数据库默认的bdata1的大小是10MB,建议不要使用10MB的默认大小,在遇到高并发事务时,会受到不小的影响。建议把ibdatal的初始数值大小调整为1GB。show variables like '%innodb data%';
独立表空间
设置参数innodb file per table=1。目前MySQL版本中,默认使用的都是独立表空间文件,就是每个表就有自己的表空间文件,而不用存储在ibdatal中。独立表空间文件存储对应表的B+树数据、索引和插入缓冲等信息,其余信息还是存储在默认表空间中。
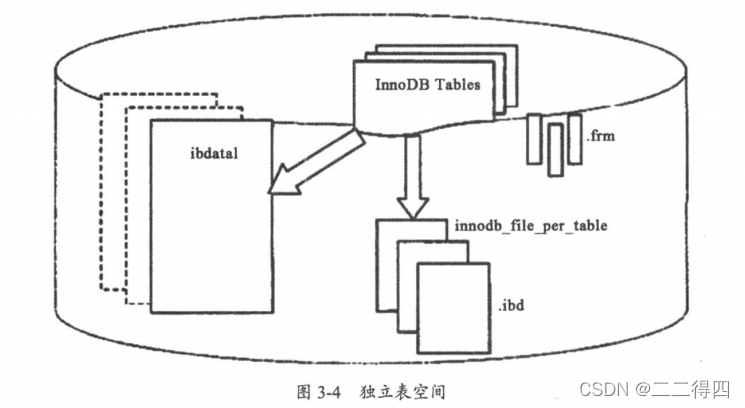
区别?
独立表空间的每个表都有自己的表空间,并且可以实现表空间的转移,回收表空间也很方便,使用alter table tablename engine-=innodb命令。但有它每个表文件都有.frm和bd文件两个文件描述符,如果单表增长过快就容易出现性能问题。
系统表空间的数据和文件放在一起方便管理。但是共享表空间无法在线回收空间,共享表空间想要回收,需要将全部InnoDB表中的数据备份、删除原表,然后再把数据导回到与原表结构一样的新表中。特别是统计分析、日志类系统不太适合共享表空间。
2.段
表空间是由段组成的,也可以把一个表理解为一个段。通常有数据段、回滚段、索引段等。每个段由N个区和32个零散的页组成,段空间扩展是以区为单位进行扩展的。通常情况下,创建一个索引的同时就会创建两个段,分别为非叶子节点和叶子节点段。那一个表有4个段是索引个数的2倍.
3.区
区是由连续的页组成的,是物理上连续分配的一段空间,每个区的大小固定是1MB。
4.页
InnoDB的最小物理存储分配单位是page,有数据页回滚页等。一般情况下,一个区由64个连续的页组成,页默认大小是16KB。一般情况下,一个page页会默认预留1/16的空间用于更新数据。真正使用的是15/16的空间。一个页最少可以存两行数据,虚拟最小行(infimum records)和虚拟最大行(infimum records),用来限定行记录的范围,以此来保证B+tree节点是双向链表。
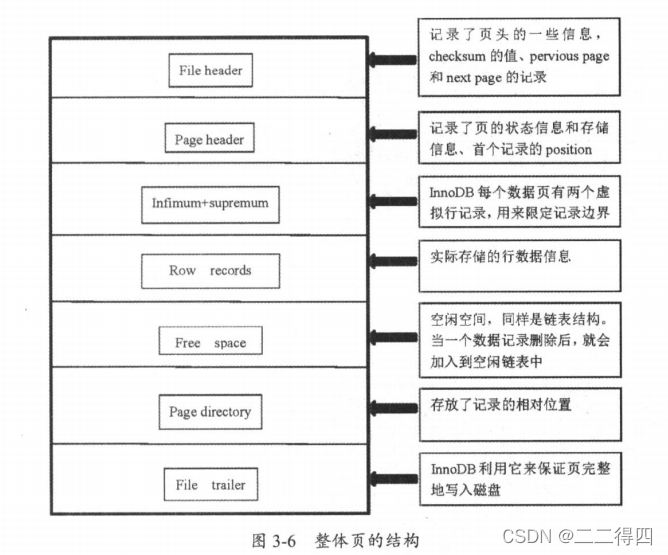
5.行
页里面又记录着行记录的信息,InnoDB存储引擎是面向列的,也就是数据是按照行存储的。行记录数据又是按照行格式进行存放的。
InnoDB存储引擎有两种文件格式,一种叫Antelope,另外一种叫Barracuda。
在Antelope文件格式下,有compact和redundant两种行记录格式。
而在Barracuda文件格式下,有compressed和dynamic两种行记录格式。
行记录格式可以分为四种:Compact、.dynamic、redundant、compressed。目前最多使用的就是Compact行记录格式show variables like '%row_format%';
innodb 内存结构
MySQL内存的组成和Oracle类似,也可以分为SGA(系统全局区)和PGA(程序缓存区)。数据库内存参数分配,通过show variables like %buffer?%查看配置参数
系统全局区(SGA)主要内存区域。
(1)innodb buffer_pool.用途:用来缓存InnoDB表的数据、索引、插入缓冲、数据字典等信息。
(2)innodb_log buffer。用途:事务在内存中的缓冲,即redo log buffer的大小。
(3)Query Cache.用途:高速查询缓存,前面已经介绍过,在生产环境中建议关闭。
(4)key buffer size.用途:只用于MyISAM存储引擎表,缓存MyISAM存储。引擎表的索引文件(区别于innodb buffer pool数据和索引都缓存)。
(5)innodb_additional mem pool size.用途:用来保存数据字典信息和其他内部数据结构的内存池的大小。
程序缓存区(PGA)中包含的内存区域。
(1)sort buffer_size。用途:主要用于SQL语句在内存中的临时排序。
(2)join_buffer_size。用途:表连接使用,用于BKA。MySQL5.6之后开始支持。后面的章节中会介绍。
(3)read buffer_size。用途:表顺序扫描的缓存,只能应用于MyISAM表存储引擎。
(4)read rnd buffer_size.用途:MySQL随机读缓冲区大小,用于做mrr,mr是MySQL5.6之后才有的特性。
(5)tmp_table_size。用途:SQL语句在排序或者分组时没有用到索引,就会使用临时表空间。
(6)max_heap_table_size.用途:管理heap、memory存储引擎表。
Buffer状态及其链表结构
page是InnoDB磁盘I/O的最小单位,数据是存放在page中的,那么对应到内存中就是一个个的buffer。每个buffer又分为三种状态。
free buffer:此状态下的buffer从未被使用,像一张白纸。但在实际生产中,数据库很繁忙的情况下,free buffer的状态基本是不存在的。
clean buffer:内存中buffer里面的数据和磁盘page的数据一致。
dirty buffer:内存中新写入的数据还没有刷新到磁盘,跟磁盘中数据不一致。
buffer在内存中是需要被组织起来的,由chain来管理,也就是链。InnoDB是双向链表结构,由三种不同的buffer状态衍生出了三条链表。
free list:把那些free状态的buffer都串联起来。在数据库真正跑起来的时候,每次把page调到内存中,都先会判断free buffer的使用情况,如果不够用了,就会从lru list和flush list链表中释放free buffer,以获得新的空buffer。
Iru list:lru list会把那些与磁盘数据一致,并且最近最少被使用的buffer串联起来,释放出free buffer,page调到内存中便于使用新的可用buffer。
flush list:把那些dirty buffer串联起来,为了方便刷新线程把脏数据刷到磁盘。推进checkpoint Lsn,使实例崩溃之后,可以快速恢复。其实flush list中也隐藏着一个lu的规则。举个例子,假如目前有条数据是19,下一秒变成了29,再下一秒又变成了39,这样的数据情况就是经常被访问、被使用到,暂时不能把它串起来。我们要把那
些最近最少被“弄脏”的数据串起来,刷新到磁盘之后,释放出更多free buffer供我们使用。
innodb 线程结构
InnoDB存储引擎属于多线程的模型,后台有多种线程,负责处理不同的任务。
- 先来介绍master thread线程,它是后台线程中的主线程,优先级别最高。其内部有四个循环,分别为主循环loop、后台循环background loop、刷新循环flush loop和暂停循环suspend loop。
根据数据的运行状态会在这四个循环之间进行切换。在loop主循环中又包含两种操作,分别为每1s和每10s的操作。
每1s操作:
(1)日志缓冲刷新到磁盘,即使这个事务还没有提交。
(2)刷新脏页到磁盘。
(3)执行合并插入缓冲的操作。
(4)产生checkpoint。
(5)清除无用的table cache。
(6)如果当前没有用户活动,就可能切换到background loop.。
每10s操作:
(1)日志缓冲刷新到磁盘,即使事务还没有提交。
(2)执行合并插入缓冲的操作。
(3)刷新脏页到磁盘。
(4)删除无用的undo页。
(5)产生checkpoint。. - 接下来就是四大I/O线程,分别是read thread、write thread、redo log thread和change buffer thread。
redo log thread负责把日志缓冲中的内容刷新到redo log文件中。
change buffer thread负责把插入缓冲(change buffer)中的内容刷新到磁盘,
read/write thread是数据库的读写请求线程,默认值都是4个。如果使用高转速磁盘,可以适当调大该值。 - page cleaner thread是负责脏页刷新的线程,MySQL5.7之后可以增加多个。
- purge thread负责删除无用的undo页。由于进行DML语句的操作都会生成undo,系统需要定期对undo页进行清理,这时就需要purge操作。从MySQL5.6开始把purge thread单独从master thread中分离出来,通过innodb_purge_thread参数来控制purge的线程个数,默认是I个,最大值可调为32个。
- checkpoint线程的作用是在redo log发生切换时,执行checkpoint。redo log发生切换或者文件快写满时,会触发把脏页刷新到磁盘。还有就是可以确保redo log刷新到磁盘,实现真正持久化,避免数据丢失。
error monitor thread是负责数据库报错的监控线程。
lock monitor thread是负责锁的监控线程。
内存刷新机制
内存中的数据会刷新到磁盘,那么它的刷新机制是怎样的呢?我们主要来看三个内存部分的刷新情况,redo log buffer、data buffer和binlog cache的刷新机制。
在Oracle和MySQL这种关系型数据库中,讲究日志先行策略,就是一条DML语句进入数据库之后,都会先写日志,再写数据文件。
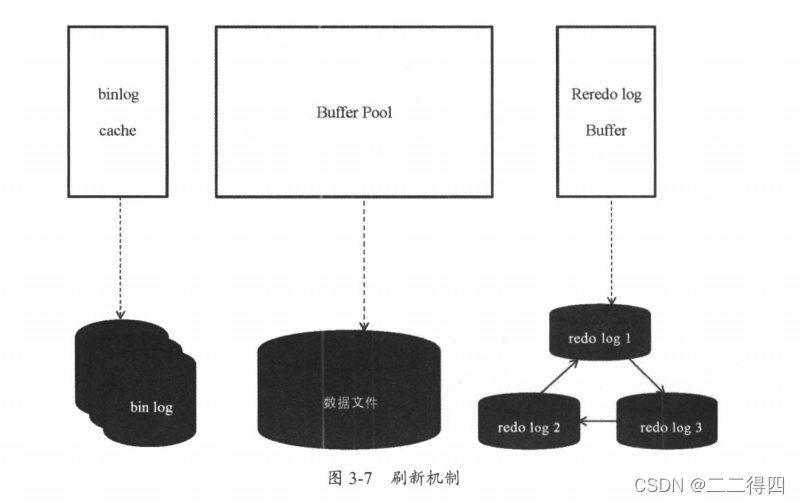
-
redo log
redo log又称重做日志文件,用于记录事务操作的变化,记录的是数据修改之后的值,不管事务是否提交都会记录下来。在实例和介质失败时,重做日志文件就能派上用场,如数据库掉电,InnoDB存储引擎会使用重做日志恢复到掉电前的时刻,以此来保证数据的完整性。默认情况下至少两个redo log文件。
redo log写的方式是顺序写、循环写。第一个文件写满之后,会按顺序写第二个,第二个写满之后,会继续写第三个。当写满最后一个文件时,会重新从第一个文件开始写。写满日志文件会产生切换操作,并执行checkpoint,.触发脏页的刷新。MySQL数据库重启过程中,如果参数文件中的redo log值大小与当前redo log值不一致,会把现有redo log删除,并按照参数文件中设置的大小,重新生成新的redo log文件。在磁盘中生成redo log文件之前,数据是先写在redo log buffer中的。下面讲一下Redo log buffer刷到磁盘的条件有哪些。
(1) 通过innodb_flush_log_at_trx_commit参数来控制。该参数有三个值,分别为0、l、2。
0的含义:redo log thread每隔ls会将redo log buffer中的数据写入redo log文件,同时进行刷盘操作,保证数据确实已经写入磁盘。但在该参数值下,每次事务提交并不会触发redo log thread将日志缓冲中的数据写入redo log文件。
1的含义:每次事务提交时,都会触发redo log thread将日志缓冲中的数据写入文件,并“flush”到磁盘。该设置下是最安全的模式。保证数据库在主机断电、OS crash下不会丢失任何已经提交的数据。。
2的含义:每次事务提交时,都会把redo log buffer的数据写入redo log文件,但是不会同时刷新到磁盘。
三种模式下,0是性能最好,但是不太安全,MySQL进程一旦崩溃会导致丢失一秒的数据。
1是安全性最高,但数据库性能最慢。
2是介于两者之间。生产中应该根据公司的业务情况来设置更合理的数值。
(2) master thread:每秒进行刷新。
(3) redo log buffer:使用超过一半的时候会触发刷新。 -
binlog
DML语句既会写redo log文件,也会写binlog文件。binlog在MySQL数据库中至关重要,叫作MySQL的二进制日志文件。功能应用于备份恢复和主从复制。那么从binlog cache刷新到磁盘的binlog文件中,需要的刷新条件是什么呢?
通过sync binlog参数来决定,该参数有N个值,sync_binlog=0,当事务提交之后,MySQL不做fsync之类的磁盘同步指令刷新binlog cache中的信息到磁盘,而让Filesystem自行决定什么时候来做同步,或者cache满了之后才同步到磁盘。sync_binlog=n,每进行n次事务提交之后,MySQL将进行一次fsync之类的磁盘同步指令来将binlog cache中的数据强制写入磁盘。为了确保安全性,我们可以将sync binlog设置为1,为了获得最佳性能,我们可以将sync_binlog设置为0。sync_binlog=1,innodb_flush log at trx commit=l,这就是数据库中的双一模式,可以确保数据库更加安全。
在了解最后一部分脏页刷新之前,我们有没有这样的疑问,既然redo log和binlog都记录了对数据真实修改的语句,那它们为什么要并存呢?有一个不就行了吗?面对这样的疑问,我们来看看它们到底有什么区别。
第一:记录内容的不同。
.binlog是逻辑日志,记录所有数据的改变信息。
·redo log是物理日志,记录所有InnoDB表数据的变化。
第二:记录内容的时间不同。
binlog记录commit完毕之后的DML和DDL SQL语句。
redo log记录事务发起之后的DML和DDL SQL语句。
第三:文件使用方式的不同。
binlog不是循环使用,在写满或者实例重启之后,会生成新的binlog文件。
redo log是循环使用,最后一个文件写满之后,会重新写第一个文件。
第四:作用不同。
binlog可以作为恢复数据使用,主从复制搭建。
redo log作为异常宕机或者介质故障后的数据恢复使用。
了解了binlog和redo log的区别之后,想一想它们之间有没有什么关联性呢?还有就是如何保证InnoDB存储引擎的日志文件(redo、undo)和二进制日志文件保持一致呢?我们都知道MySQL主从环境中,从库需要通过二进制日志来应用主库提交的事务,但如果主库redo log已经提交而二进制日志没有保持一致,那么就会造成从库数据丢失,主从数据不一致的情况。接下来我们讲一下两阶段提交的过程。
MySQL两阶段提交过程:
两阶段提交分别为prepare和commit阶段。
准备阶段(transaction prepare):事务SQL语句先写入redo log buffer,.然后做一个事务准备标记,再将log buffer中的数据刷新到redo log。
提交阶段(commit):将事务产生的binlog写入文件,刷入磁盘。再在redo log中做一个事务提交的标记,并把binlog写成功的标记也一并写入redo log文件。
总结一下:其实只要binlog写入完成,那么在主从复制环境中,都会正常完成事务。
脏页的刷新条件。
(1)重做日志ib logfile文件写满后,在切换的过程中会执行checkpoint,会触发脏页的刷新。
(2)通过innodb_max_dirty_pages_pct参数的值控制。该参数是指在buffer pool中dirty page所占的百分比,达到设置的值,就会触发脏页的刷新。
(3)由innodb adaptive flushing参数控制。该参数影响每秒刷新脏页的数目,它使用一种新的算法,通过buf flush get desired flush reate函数判断重做日志产生的速度,来确定需要刷新脏页的最合适数量,替换了之前的innodb_max_dirty_pages_pct,刷新至多l00个脏页到磁盘。这样即使脏页比例小于innodb_max_.dirty pages pct参数设置的值,也会刷新一定量的脏页。innodb_adaptive flushing参数默认是开启的。
3.4.7 InnoDB的三大特性
插入缓冲(change buffer)、两次写(double write)、自适应哈希索引(adaptive hash index)构成了InnoDB的三大特性,这些特性让InnoDB存储引擎有了更好的性能和可靠性。
(1)插入缓冲。
影响数据库最主要的性能问题就是I/O,而插入缓冲的作用就是把普通索引上的DML操作从随机I/O变成顺序I/O,提高I/O效率。它的工作原理也很简单,就是先判断插入的普通索引页是否在缓冲池中,如果在就可以直接插入,如果不在就要先放到change buffer中,然后进行change buffer和普通索引的合并操作,可以将多个插入合并到一个操作中,一下子就提高了普通索引的插入性能。涉及以下参数:
innodb change buffer max size的含义:占innodb buffer pool的最大比例,默认是25%,最大占buffer pool1/4的大小。建议调整为50。
innodb_change buffering:change buffer的类型。有如下几种类型:
all:buffer inserts,delete-marking operations,and purges:缓冲全部inserts、.delete标记操作和purges操作。
none:Do not buffer any operations:关闭insert buffer。
inserts:Buffer insert operations:insert标记操作。
deletes:Buffer delete-marking operations:delete标记操作。
changes:Buffer both inserts and delete-marking:未进行实际insert和delete,只是标记,等待后续purge。
purges:Buffer the physical deletion operations that happen in the background:缓冲后台进程的purges(物理删除)操作。建议选择默认的all就可以了。
(2)两次写(double write)。
插入缓冲带来的是针对普通索引插入性能上的提升,而double write就是保证写入的安全性,防止在MySQL实例发生宕机时,InnoDB发生数据页部分页写(partial page write)的问题。有些读者会说,数据库实例崩溃,我们可以通过redo log进行恢复,不会有任何问题。但redo log文件记录的是页的物理操作,如果页都损坏了,是无法进行任何恢复操作的,巧妇难为无米之炊就是这个道理。所以我们需要页的一个副本,如果实例宕机了,可以先通过副本把原来的页还原出来,再通过redo log进行恢复、重做。这就是double write的作用。
双写缓冲是一个位于系统表空间中的存储区域,InnoDB缓冲池中刷出的脏页在被写入数据文件之前,都先会写入double write buffer。然后从两次写缓冲区分两次,每次将lMB大小的数据写入磁盘共享表空间(double write),最后再从double write buffer写入数据文件。虽然数据总是写两次,但两次写缓冲并不需要两倍的I/O开销,或者两倍的其他/O操作。数据写入双写缓冲后,其本身是一个大型的连续块,会通过一次fsync(通知操作系统。双写缓冲在大多数场景下都是默认有效的。可以通过设置innodb doublewrite为0来关闭双写缓冲。从MySQL5.7.4
开始,如果系统表空间文件ibdata位于Fusion-io设备(支持原子写),双写缓冲自动失效并且Fusion-io原子写会被用于所有数据文件。由于双写缓冲设置是全局的,双写缓冲也会在位于非Fusion-io硬件的数据文件上失效。该特性仅支持Fusion-io硬件,并且只能通过Linux系统上的Fusion-io NVMFS启用。为了充分利用该特性,O DIRECT推荐使用innodb flush method设置。
(3)自适应哈希索引(自适应哈希索引)
InnoDB存储引擎有一个机制,可以监控索引的搜索,如果InnoDB注意到查询可以通过建立哈希索引得到优化,那么就会自动完成这件事。可以通过innodb adaptive hash index参数来控制。默认情况下是开启的。
压力测试
MySQL数据库的压力测试软件sysbench,用它来进行基准测试。sysbench是一个开源的、模块化的、跨平台的多线程性能测试工具,可以用来进行CPU、内存、磁盘I/O、线程、数据库的性能测试。目前支持的数据库有MySQL、Oracle和PostgreSQL。

















 53
53

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









