






常用的前端数据结构与算法
1. 递归
递归就是自己调自己,递归在前端里面算是一种比较常用的算法。假设现在有一堆数据要处理,要实现上一次请求完成了,才能去调下一个请求。一个是可以用Promise,但是有时候并不想引入Promise,能简单处理先简单处理。这个时候就可以用递归,如下代码所示:
var ids = [34112, 98325, 68125];
(function sendRequest(){
var id = ids.shift();
if(id){
$.ajax({url: "/get", data: {id}}).always(function(){
//do sth.
console.log("finished");
sendRequest();
});
} else {
console.log("finished");
}
})();
上面代码定义了一个sendRequest的函数,在请求完成之后再调一下自己。每次调之前先取一个数据,如果数组已经为空,则说明处理完了。这样就用简单的方式实现了串行请求不堵塞的功能。
再来讲另外一个场景:DOM树。
由于DOM是一棵树,而树的定义本身就是用的递归定义,所以用递归的方法处理树,会非常地简单自然。例如用递归实现一个查DOM的功能document.getElementById。
function getElementById(node, id){
if(!node) return null;
if(node.id === id) return node;
for(var i = 0; i < node.childNodes.length; i++){
var found = getElementById(node.childNodes[i], id);
if(found) return found;
}
return null;
}
getElementById(document, "d-cal");
document是DOM树的根结点,一般从document开始往下找。在for循环里面先找document的所有子结点,对所有子结点递归查找他们的子结点,一层一层地往下查找。如果已经到了叶子结点了还没有找到,则在第二行代码的判断里面返回null,返回之后for循环的i加1,继续下一个子结点。如果当前结点的id符合查找条件,则一层层地返回。所以这是一个深度优先的遍历,每次都先从根结点一直往下直到叶子结点,再从下往上返回。
最后在控制台验证一下,执行结果如下图所示:
使用递归的优点是代码简单易懂,缺点是效率比不上非递归的实现。Chrome浏览器的查DOM是使用非递归实现。非递归要怎么实现呢?

使用递归的优点是代码简单易懂,缺点是效率比不上非递归的实现。Chrome浏览器的查DOM是使用非递归实现。非递归要怎么实现呢?
如下代码:
function getByElementId(node, id){
//遍历所有的Node
while(node){
if(node.id === id) return node;
node = nextElement(node);
}
return null;
}
还是依次遍历所有的DOM结点,只是这一次改成一个while循环,函数nextElement负责找到下一个结点。所以关键在于这个nextElement如何非递归实现,如下代码所示:
function nextElement(node){
if(node.children.length) {
return node.children[0];
}
if(node.nextElementSibling){
return node.nextElementSibling;
}
while(node.parentNode){
if(node.parentNode.nextElementSibling) {
return node.parentNode.nextElementSibling;
}
node = node.parentNode;
}
return null;
}
还是用深度遍历,先找当前结点的子结点,如果它有子结点,则下一个元素就是它的第一个子结点,否则判断它是否有相邻元素,如果有则返回它的下一个相邻元素。如果它既没有子结点,也没有下一个相邻元素,则要往上返回它的父结点的下一个相邻元素,相当于上面递归实现里面的for循环的i加1.
在控制台里面运行这段代码,同样也可以正确地输出结果。不管是非递归还是递归,它们都是深度优先遍历,这个过程如下图所示。
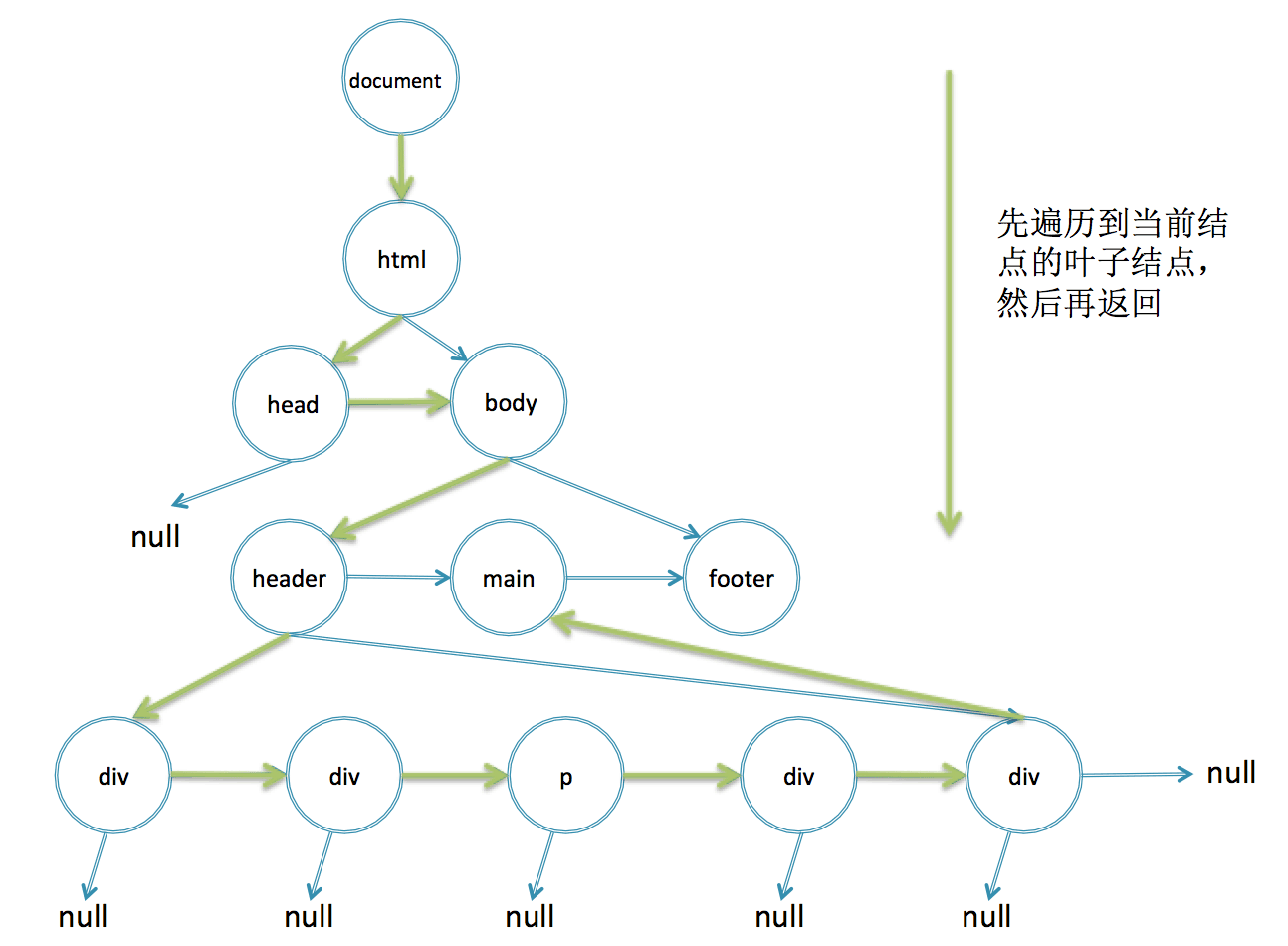
实际上getElementById浏览器是用的一个哈希map存储的,根据id直接映射到DOM结点,而getElementsByClassName就是用的这样的非递归查找。
上面是单个选择器的查找,按id,按class等,多个选择器应该如何查找呢?
2. 复杂选择器的查DOM
如实现一个document.querySelector:
document.querySelector(".mls-info > div .copyright-content")
首先把复杂选择器做一个解析,序列为以下格式:
//把selector解析为
var selectors = [
{relation: "descendant", matchType: "class", value: "copyright-content"},
{relation: "child", matchType: "tag", value: "div"},
{relation: "subSelector", matchType: "class", value: "mls-info"}];
从右往左,第一个selector是.copyright-content,它是一个类选择器,所以它的matchType是class,它和第二个选择器是祖先和子孙关系,因此它的relation是descendant;同理第二个选择器的matchType是tag,而relation是child,表示是第三个选择器的直接子结点;第三个选择器也是class,但是它没有下一个选择器了,relation用subSelector表示。
matchType的作用就在于用来比较当前选择器是否match,如下代码所示:
function match(node, selector){
if(node === document) return false;
switch(selector.matchType){
//如果是类选择器
case "class":
return node.className.trim().split(/ +/).indexOf(selector.value) >= 0;
//如果是标签选择器
case "tag":
return node.tagName.toLowerCase() === selector.value. toLowerCase();
default:
throw "unknown selector match type";
}
}
根据不同的matchType做不同的匹配。
在匹配的时候,从右往左,依次比较每个选择器是否match. 在比较下一个选择器的时候,需要找到相应的DOM结点,如果当前选择器是下一个选择器的子孙时,则需要比较当前选择器所有的祖先结点,一直往上直到document;而如果是直接子元素的关系,则比较它的父结点即可。所以需要有一个找到下一个目标结点的函数:
function nextTarget(node, selector){
if(!node || node === document) return null;
switch(selector.relation){
case "descendant":
return {node: node.parentNode, hasNext: true};
case "child":
return {node: node.parentNode, hasNext: false};
case "sibling":
return {node: node.previousSibling, hasNext: true};
default:
throw "unknown selector relation type";
//hasNext表示当前选择器relation是否允许继续找下一个节点
}
}
有了nextTarge和match这两个函数就可以开始遍历DOM,如下代码所示:

最外层的while循环和简单选择器一样,都是要遍历所有DOM结点。对于每个结点,先判断第一个选择器是否match,如果不match的话,则继续下一个结点,如果不是标签选择器,对于绝大多数结点将会在这里判断不通过。如果第一个选择器match了,则根据第一个选择器的relation,找到下一个target,判断下一个targe是否match下一个selector,只要有一个target匹配上了,则退出里层的while循环,继续下一个选择器,如果所有的selector都能匹配上说明匹配成功。如果有一个selecotr的所有target都没有match,则说明匹配失败,退出selector的for循环,直接从头开始对下一个DOM结点进行匹配。
这样就实现了一个复杂选择器的查DOM。写这个的目的并不是要你自己写一个查DOM的函数拿去用,而是要明白查DOM的过程是怎么样的,可以怎么实现,浏览器又是怎么实现的。还有可以怎么遍历DOM树,当明白这个过程的时候,遇到类似的问题,就可以举一反三。
最后在浏览器上运行一下,如下图所示:
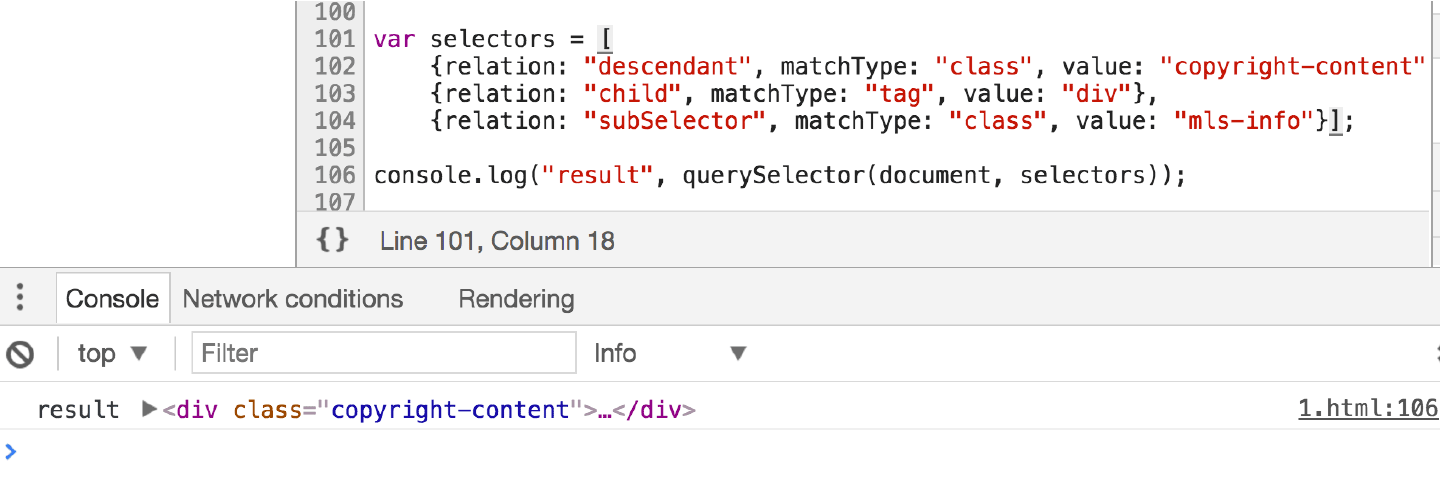
3. 重复值处理
现在有个问题,如下图所示:
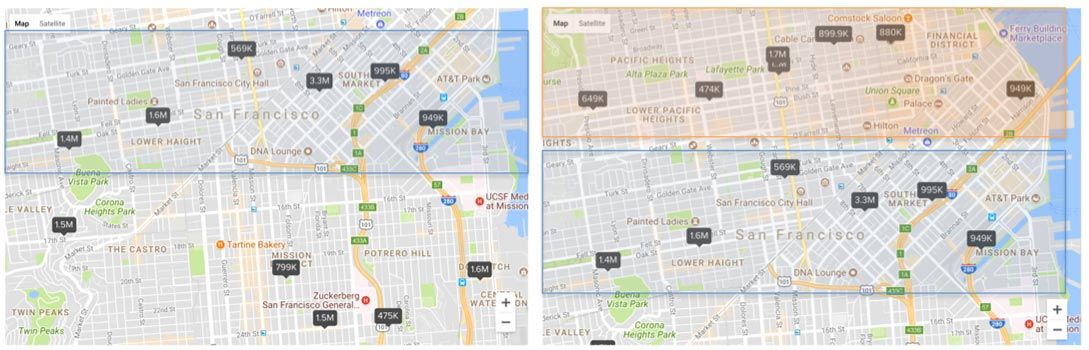
当地图往下拖的时候要更新地图上的房源标签数据,上图绿框表示不变的标签,而黄框表示新加的房源。
—后端每次都会把当前地图可见区域的房源返回给我,当用户拖动的时候需要知道哪些是原先已经有的房源,哪些是新加的。把新加的房源画上,而把超出区域的房源删掉,已有的房源保持不动。因此需要对比当前房源和新的结果哪些是重复的。因为如果不这样做的话,改成每次都是全部删掉再重新画,已有的房源标签就会闪一下。因此为了避免闪动做一个增量更新。
把这个问题抽象一下就变成:—给两个数组,需要找出第一个数组里面的重复值和非重复值。即有一个数组保存上一次状态的房源,而另一个数组是当前状态的新房源数据。找到的重复值是需要保留,找到非重复值是要删掉的。
最直观的方法是使用双重循环。
(1)双重循环
如下代码所示:
var lastHouses = [];
filterHouse: function(houses){
if(lastHouses === null){
lastHouses = houses;
return {
remainsHouses: [],
newHouses: houses
};
}
var remainsHouses = [],
newHouses = [];
for(var i = 0; i < houses.length; i++){
var isNewHouse = true;
for(var j = 0; j < lastHouses.length; j++){
if(houses[i].id === lastHouses[j].id){
isNewHouse = false;
remainsHouses.push(lastHouses[j]);
break;
}
}
if(isNewHouse){
newHouses.push(houses[i]);
}
}
lastHouses = remainsHouses.concat(newHouses);
return {
remainsHouses: remainsHouses,
newHouses: newHouses
};
}
上面代码有一个双重for循环,对新数据的每个元素,判断老数据里面是否已经有了,如果有的话则说明是重复值,如果老数据循环了一遍都没找到,则说明是新数据。由于用到了双重循环,所以这个算法的时间复杂度为O(N*N)),对于百级的数据还好,对于千级的数据可能会有压力,因为最坏情况下要比较1000000次。
(2)使用Set
如下代码所示:
var lastHouses = new Set();
function filterHouse(houses){
var remainsHouses = [],
newHouses = [];
for(var i = houses.length - 1; i >= 0; i--){
if(lastHouses.has(houses[i].id)){
remainsHouses.push(houses[i]);
} else {
newHouses.push(houses[i]);
}
}
for(var i = 0; i < newHouses.length; i++){
lastHouses.add(newHouses[i].id);
}
return {remainsHouses: remainsHouses,
newHouses: newHouses};
}
老数据的存储lastHouses从数组改成set,但如果一开始就是数组呢,就像问题抽象里面说的给两个数组?那就用这个数组的数据初始化一个Set.
使用Set和使用Array的区别在于可以减少一重循环,调用Set.prototype.has的函数。Set一般是使用红黑树实现的,红黑树是一种平衡查找二叉树,它的查找时间复杂度为O(logN)。所以时间上进行了改进,从O(N)变成O(logN),而总体时间从O(N*N))变成O(NlogN)。实际上,Chrome V8的Set是用哈希实现的,它是一个哈希Set,查找时间复杂度为O(1),所以总体的时间复杂度是O(N).
不管是O(NlogN)还是O(N),表面上看它们的时间要比O(N*N))的少。但实际上需要注意的是它们前面还有一个系数。使用Set在后面更新lastHouses的时候也是需要时间的:
for(var i = 0; i < newHouses.length; i++){
lastHouses.add(newHouses[i].id);
}
如果Set是用树的实现,这段代码是时间复杂度为O(NlogN),所以总的时间为O(2NlogN),但是由于大O是不考虑系数的,O(2NlogN) 还是等于O(NlogN),当数据量比较小的时侯,这个系数会起到很大的作用,而数据量比较大的时候,指数级增长的O(N*N)将会远远超过这个系数,哈希的实现也是同样道理。所以当数据量比较小时,如只有一两百可直接使用双重循环处理即可。
上面的代码有点冗长,我们可以用ES6的新特性改写一下,变得更加的简洁:
function filterHouse(houses){
var remainsHouses = [],
newHouses = [];
houses.map(house => lastHouses.has(house.id) ? remainsHouses.push(house)
: newHouses.push(house));
newHouses.map(house => lastHouses.add(house.id));
return {remainsHouses, newHouses};
}
代码从16行变成了8行,减少了一半。
(3)使用Map
使用Map也是类似的,代码如下所示:
var lastHouses = new Map();
function filterHouse(houses){
var remainsHouses = [],
newHouses = [];
houses.map(house => lastHouses.has(house.id) ? remainsHouses.push(house)
: newHouses.push(house));
newHouses.map(house => lastHouses.set(house.id, house));
return {remainsHouses, newHouses};
}
哈希的查找复杂度为O(1),因此总的时间复杂度为O(N),Set/Map都是这样,代价是哈希的存储空间通常为数据大小的两倍
(4)时间比较
最后做下时间比较,为此得先造点数据,比较数据量分别为N = 100, 1000, 10000的时间,有N/2的id是重复的,另外一半的id是不一样的。用以下代码生成:
var N = 1000;
var lastHouses = new Array(N);
var newHouses = new Array(N);
var data = new Array(N);
for(var i = 0; i < N / 2; i++){
var sameNumId = i;
lastHouses[i] = newHouses[i] = {id: sameNumId};
}
for(; i < N; i++){
lastHouses[i] = {id: N + i};
newHouses[i] = {id: 2 * N + i};
}
然后需要—将重复的数据随机分布,可用以下函数把一个数组的元素随机分布:
//打散
function randomIndex(arr){
for(var i = 0; i < arr.length; i++){
var swapIndex = parseInt(Math.random() * (arr.length - i)) + i;
var tmp = arr[i];
arr[i] = arr[swapIndex];
arr[swapIndex] = tmp;
}
}
randomIndex(lastHouses);
randomIndex(newHouses);
Set/Map的数据:
var lastHousesSet = new Set();
for(var i = 0; i < N; i++){
lastHousesSet.add(lastHouses[i].id);
}
var lastHousesMap = new Map();
for(var i = 0; i < N; i++){
lastHousesMap.set(lastHouses[i].id, lastHouses[i]);
}
分别重复100次,比较时间:
console.time("for time");
for(var i = 0; i < 100; i++){
filterHouse(newHouses);
}
console.timeEnd("for time");
console.time("Set time");
for(var i = 0; i < 100; i++){
filterHouseSet(newHouses);
}
console.timeEnd("Set time");
console.time("Map time");
for(var i = 0; i < 100; i++){
filterHouseMap(newHouses);
}
console.timeEnd("Map time");
使用Chrome 59,当N = 100时,时间为: for < Set < Map,如下图所示,执行三次:

当N = 1000时,时间为:Set = Map < for,如下图所示:

当N = 10000时,时间为Set = Map << for,如下图所示:

可以看出,Set和Map的时间基本一致,当数据量小时,for时间更少,但数据量多时Set和Map更有优势,因为指数级增长还是挺恐怖的。这样我们会有一个问题,究竟Set/Map是怎么实现的。
4. Set和Map的V8哈希实现
我们来研究一下Chrome V8对Set/Map的实现,源码是在chrome/src/v8/src/js/collection.js这个文件里面,由于Chrome一直在更新迭代,所以有可能以后Set/Map的实现会发生改变,我们来看一下现在是怎么实现的。
如下代码初始化一个Set:
var set = new Set();
//数据为20个数
var data = [3, 62, 38, 42, 14, 4, 14, 33, 56, 20, 21, 63, 49, 41, 10, 14, 24, 59, 49, 29];
for(var i = 0; i < data.length; i++){
set.add(data[i]);
}
这个Set的数据结构到底是怎么样的呢,是怎么进行哈希的呢?
哈希的一个关键的地方是哈希算法,即对一堆数或者字符串做哈希运算得到它们的随机值,V8的数字哈希算法是这样的:
function ComputeIntegerHash(key, seed) {
var hash = key;
hash = hash ^ seed; //seed = 505553720
hash = ~hash + (hash << 15); // hash = (hash << 15) - hash - 1;
hash = hash ^ (hash >>> 12);
hash = hash + (hash << 2);
hash = hash ^ (hash >>> 4);
hash = (hash * 2057) | 0; // hash = (hash + (hash << 3)) + (hash << 11);
hash = hash ^ (hash >>> 16);
return hash & 0x3fffffff;
}
把数字进行各种位运算,得到一个比较随机的数,然后对这个数对行散射,如下所示:
var capacity = 64;
var indexes = [];
for(var i = 0; i < data.length; i++){
indexes.push(ComputeIntegerHash(data[i], seed) & (capacity - 1)); //去掉高位
}
console.log(indexes)
散射的目的是得到这个数放在数组的哪个index。
由于有20个数,容量capacity从16开始增长,每次扩大一倍,到64的时候,可以保证capacity > size * 2,因为只有容量是实际存储大小的两倍时,散射结果重复值才能比较低。
计算结果如下:
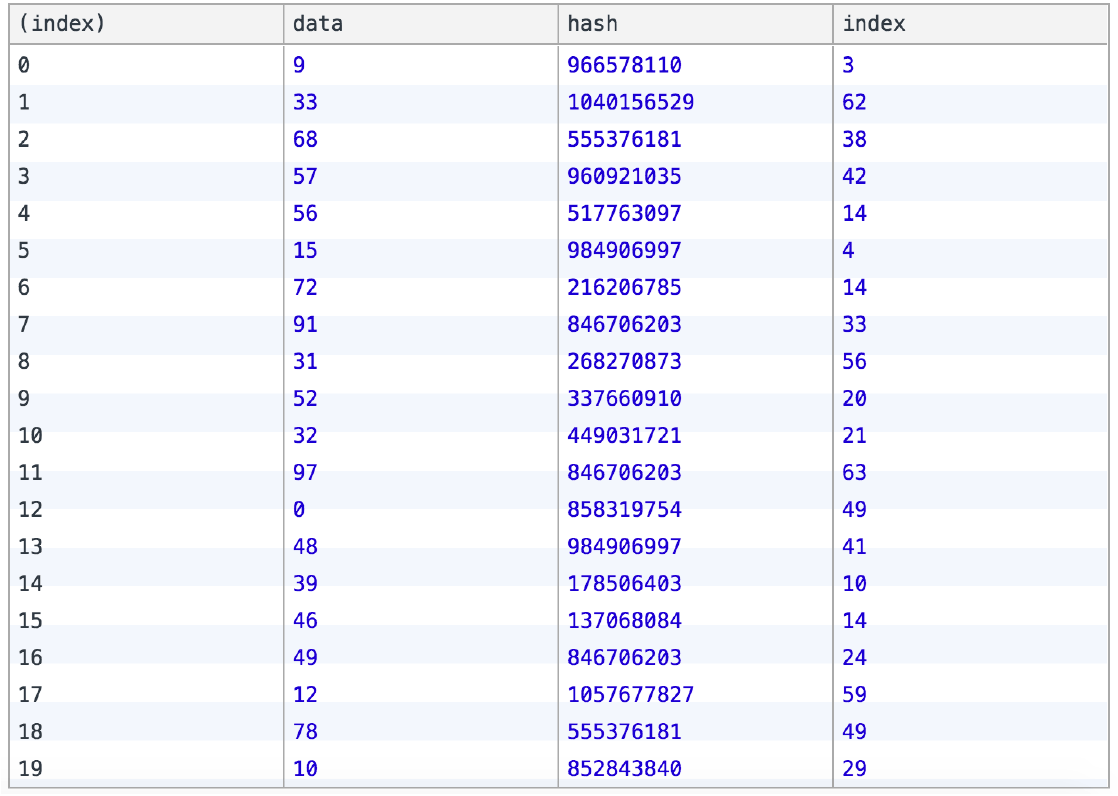
可以看到散射的结果还是比较均匀的,但是仍然会有重复值,如14重复了3次。
然后进行查找,例如现在要查找key = 56是否存在这个Set里面,先把56进行哈希,然后散射,按照存放的时候同样的过程:
function SetHas(key){
var index = ComputeIntegerHash(56, seed) & this.capacity;
//可能会有重复值,所以需要验证命中的index所存放的key是相等的
return setArray[index] !== null && setArray[index] === key;
}
上面是哈希存储结构的一个典型实现,但是Chrome的V8的Set/Map并不是这样实现的,略有不同。
哈希算法是一样的,但是散射的时候用来去掉高位的并不是用capacity,而是用capacity的一半,叫做buckets的数量,用以下面的data做说明:
var data = [9, 33, 68, 57];
由于初始化的buckets = 2,计算的结果如下:

由于buckets很小,所以散射值有很多重复的,4个数里面1重复了3次。
现在一个个的插入数据,观察Set数据结构的变化。
(1)插入过程
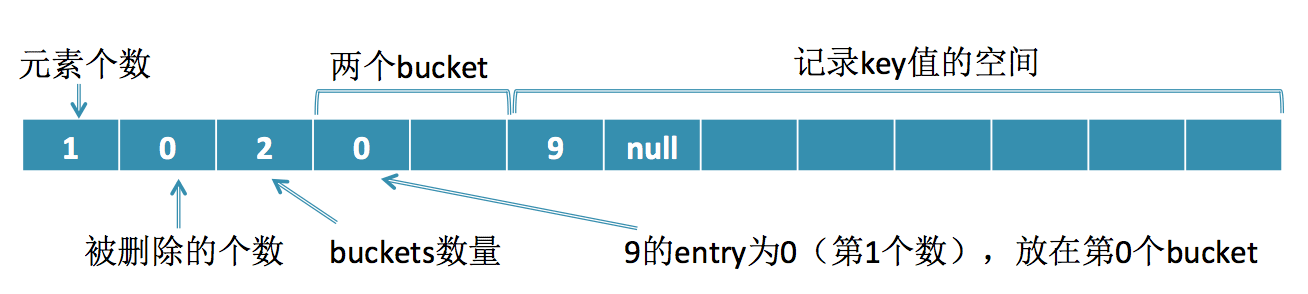
a)插入9
如下图所示,Set的存储结构分成三部分,第一部分有3个元素,分别表示有效元素个数、被删除的个数、buckets的数量,前两个数相加就表示总的元素个数,插入9之后,元素个数加1变成1,初始化的buckets数量为2. 第二部分对应buckets,buckets[0]表示第1个bucket所存放的原始数据的index,源码里面叫做entry,9在data这个数组里面的index为0,所以它在bucket的存放值为0,并且bucket的散射值为0,所以bucket[0] = 0. 第三部分是记录key值的空间,9的entry为0,所以它放在了3 + buckets.length + entry * 2 = 5的位置,每个key值都有两个元素空间,第一个存放key值,第二个是keyChain,它的作用下面将提到。
b) 插入33
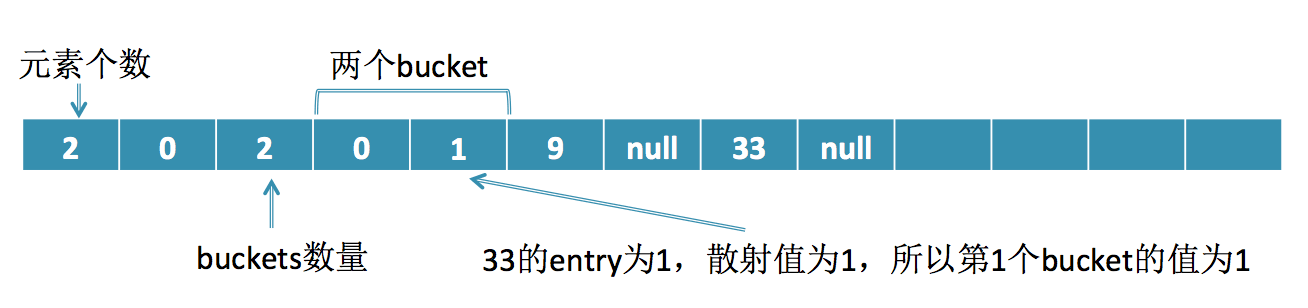
现在要插入33,由于33的bucket = 1,entry = 1,所以插入后变成这样:
c) 插入68
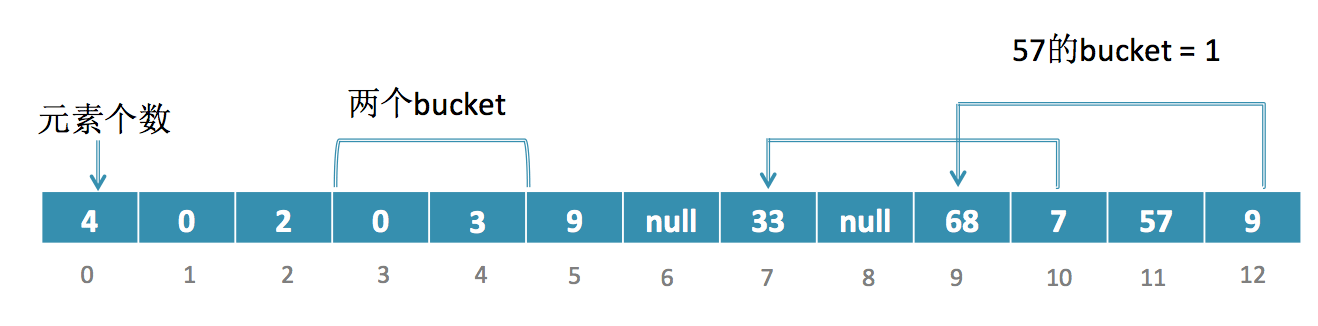
68的bucket值也为1,和33重复了,因为entry = buckets[1] = 1,不为空,说明之前已经存过了,entry为1指向的数组的位置为3 + buckets.length + entry * 2 = 7,也就是说之前的那个数是放在数组7的位置,所以68的相邻元素存放值keyChain为7,同时bucket[1]变成68的entry为2,如下图所示:

c) 插入57
插入57也是同样的道理,57的bucket值为1,而bucket[1] = 2,因此57的相邻元素存放3 + 2 + 2 * 2 = 9,指向9的位置,如下图所示:
(2)查找
现在要查找33这个数,通过同样的哈希散射,得到33的bucket = 1,bucket[1] = 3,3指向的index位置为11,但是11放的是57,不是要找的33,于是查看相邻的元素为9,非空,可继续查找,位置9存放的是68,同样不等于33,而相邻的index = 10指向位置7,而7存放的就是33了,通过比较key值相等,所以这个Set里面有33这个数。
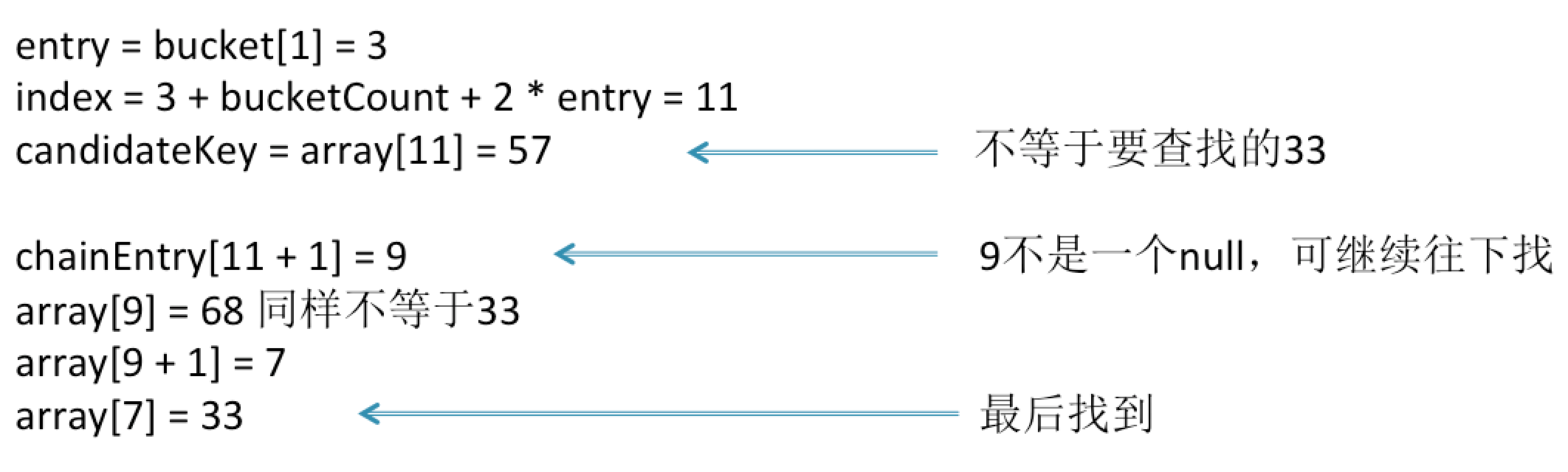
这里的数据总共是4个数,但是需要比较的次数比较多,key值就比较了3次,key值的相邻keyChain值比较了2次,总共是5次,比直接来个for循环还要多。所以数据量比较小时,使用哈希存储速度反而更慢,但是当数据量偏大时优势会比较明显。
(3)扩容
再继续插入第5个数的时候,发现容量不够了,需要继续扩容,会把容量提升为2倍,bucket数量变成4,再把所有元素再重新进行散射。
Set的散射容量即bucket的值是实际元素的一半,会有大量的散射冲突,但是它的存储空间会比较小。假设元素个数为N,需要用来存储的数组空间为:3 + N / 2 + 2 * N,所以占用的空间还是挺大的,它用空间换时间。
(4)Map的实现
和Set基本一致,不同的地方是,map多了存储value的地方,如下代码:
var map = new Map();
map.set(9, "hello");
生成的数据结构为:

当然它不是直接存的字符串“hello”,而是存放hello的指针地址,指向实际存放hello的内存位置。
(5)和JS Object的比较
JS Object主要也是采用哈希存储,具体我在这篇文件章里面已经讨论过。
和JS Map不一样的地方是,JSObject的容量是元素个数的两倍,就是上面说的哈希的典型实现。存储结构也不一样,有一个专门存放key和一个存放value的数组,如果能找到key,则拿到这个key的index去另外一个数组取出value值。当发生散列值冲突时,根据当前的index,直接计算下一个查找位置:
inline static uint32_t FirstProbe(uint32_t hash, uint32_t size) {
return hash & (size - 1);
}
inline static uint32_t NextProbe(
uint32_t last, uint32_t number, uint32_t size) {
return (last + number) & (size - 1);
}
同样地,查找的时候在下一个位置也是需要比较key值是否相等。
上面讨论的都是数字的哈希,实符串如何做哈希计算呢?

















 1096
1096

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









