







网上关于sqlserver的数据新增同步方案很少,参考了github上的一位作者,链接在此,在此基础上做了些修改,可以同时监控多张表的数据新增,并加上了表名,列名信息
话不多说,直接上代码
package org.keedio.flume.source;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.hibernate.Session;
import org.hibernate.SessionFactory;
import org.hibernate.boot.registry.StandardServiceRegistryBuilder;
import org.hibernate.cfg.Configuration;
import org.hibernate.service.ServiceRegistry;
import org.hibernate.transform.Transformers;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* Helper class to manage hibernate sessions and perform queries
*
* @author <a href="mailto:mvalle@keedio.com">Marcelo Valle</a>
* @author tianqin
*/
public class HibernateHelper {
private static final Logger LOG = LoggerFactory
.getLogger(HibernateHelper.class);
private static SessionFactory factory;
private Session session;
private Configuration config;
private SQLSourceHelper sqlSourceHelper;
/**
* Constructor to initialize hibernate configuration parameters
*
* @param sqlSourceHelper Contains the configuration parameters from flume config file
*/
public HibernateHelper(SQLSourceHelper sqlSourceHelper) {
this.sqlSourceHelper = sqlSourceHelper;
config = new Configuration()
.setProperty("hibernate.connection.url", sqlSourceHelper.getConnectionURL())
.setProperty("hibernate.connection.username", sqlSourceHelper.getUser())
.setProperty("hibernate.connection.password", sqlSourceHelper.getPassword());
if (sqlSourceHelper.getHibernateDialect() != null)
config.setProperty("hibernate.dialect", sqlSourceHelper.getHibernateDialect());
if (sqlSourceHelper.getHibernateDriver() != null)
config.setProperty("hibernate.connection.driver_class", sqlSourceHelper.getHibernateDriver());
}
/**
* Connect to database using hibernate
*/
public void establishSession() {
LOG.info("Opening hibernate session");
ServiceRegistry serviceRegistry = new StandardServiceRegistryBuilder()
.applySettings(config.getProperties()).build();
factory = config.buildSessionFactory(serviceRegistry);
session = factory.openSession();
}
/**
* Close database connection
*/
public void closeSession() {
LOG.info("Closing hibernate session");
session.close();
}
/**
* Execute the selection query in the database
*
* @return 这里做了较大的修改,原作者的查询结果不含列名,这对业务人员很不友好,我修改成返回一个map集合,key是表名,value是
* 每张表数据组成的list集合,包含列名
*/
@SuppressWarnings("unchecked")
public Map<String, List<List<Object>>> executeQuery(String[] tables) {
//返回的 表名-数据 map对象
Map<String, List<List<Object>>> tableRowsList = new HashMap<>();
//得到每张表的查询语句集合
Map<String, String> querys = sqlSourceHelper.getQuery();
//得到每张表的当前index集合
Map<String, Integer> currentIndexMap = sqlSourceHelper.getCurrentIndex();
for (String table : tables) {
List<List<Object>> tableRows = new ArrayList<>();
List<Object> listObject = new ArrayList<>();
/**
* 这儿原作者是 .setResultTransformer(Transformers.TO_LIST()).list() 不包含列名信息
* 取列名信息需要 List<Map<String, Object>>类型
*/
List<Map<String, Object>> rowsList = session
.createSQLQuery(querys.get(table))
.setFirstResult(currentIndexMap.get(table))
.setMaxResults(sqlSourceHelper.getMaxRows())
.setResultTransformer(Transformers.ALIAS_TO_ENTITY_MAP).list();
//类型转换,将List<Map<String, Object>>转换成List<List<Object>>
for (Map<String, Object> rows : rowsList) {
for (String column : rows.keySet()) {
listObject.add("table:" + table + "," + column + ":" + String.valueOf(rows.get(column)));
}
tableRows.add(listObject);
}
//给每行数据加上表名信息
for (int i = 0; i < tableRows.size(); i++) {
tableRows.get(i).add("table:"+table);
}
sqlSourceHelper.setCurrentIndex(table, currentIndexMap.get(table) + rowsList.size());
tableRowsList.put(table, tableRows);
}
return tableRowsList;
}
}/*******************************************************************************
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing,
* software distributed under the License is distributed on an
* "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
* KIND, either express or implied. See the License for the
* specific language governing permissions and limitations
* under the License.
*******************************************************************************/
package org.keedio.flume.source;
import java.io.File;
import java.io.IOException;
import java.io.Writer;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.EventDeliveryException;
import org.apache.flume.PollableSource;
import org.apache.flume.conf.Configurable;
import org.apache.flume.event.SimpleEvent;
import org.apache.flume.source.AbstractSource;
import org.keedio.flume.metrics.SqlSourceCounter;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import au.com.bytecode.opencsv.CSVWriter;
/**
* A Source to read data from a SQL database. This source ask for new data in a table each configured time.<p>
*
* @author <a href="mailto:mvalle@keedio.com">Marcelo Valle</a>
* @author tianqin
*/
public class SQLSource extends AbstractSource implements Configurable, PollableSource {
private static final Logger LOG = LoggerFactory.getLogger(SQLSource.class);
protected SQLSourceHelper sqlSourceHelper;
private SqlSourceCounter sqlSourceCounter;
private CSVWriter csvWriter;
private HibernateHelper hibernateHelper;
private String[] tables;
private Map<String, Integer> currentIndexMap;
private Map<String, File> files;
/**
* Configure the source, load configuration properties and establish connection with database
*/
@Override
public void configure(Context context) {
LOG.info("Reading and processing configuration values for source " + getName());
/* Initialize configuration parameters */
sqlSourceHelper = new SQLSourceHelper(context);
tables = sqlSourceHelper.getTables();
currentIndexMap = sqlSourceHelper.getCurrentIndex();
files = sqlSourceHelper.getFiles();
/* Initialize metric counters */
sqlSourceCounter = new SqlSourceCounter("SOURCESQL." + this.getName());
/* Establish connection with database */
hibernateHelper = new HibernateHelper(sqlSourceHelper);
hibernateHelper.establishSession();
/* Instantiate the CSV Writer */
csvWriter = new CSVWriter(new ChannelWriter());
}
/**
* Process a batch of events performing SQL Queries
*/
@Override
public Status process() throws EventDeliveryException {
try {
sqlSourceCounter.startProcess();
Map<String, List<List<Object>>> results = hibernateHelper.executeQuery(tables);
int size = 0;
if (!results.isEmpty()) {
for (String table : tables) {
List<List<Object>> result = results.get(table);
csvWriter.writeAll(sqlSourceHelper.getAllRows(result));
sqlSourceHelper.updateStatusFile(files.get(table), table, currentIndexMap.get(table));
size += result.size();
}
csvWriter.flush();
sqlSourceCounter.incrementEventCount(size);
}
sqlSourceCounter.endProcess(size);
if (size < sqlSourceHelper.getMaxRows()) {
Thread.sleep(sqlSourceHelper.getRunQueryDelay());
}
return Status.READY;
} catch (IOException | InterruptedException e) {
LOG.error("Error procesing row", e);
return Status.BACKOFF;
}
}
/**
* Starts the source. Starts the metrics counter.
*/
@Override
public void start() {
// LOG.info("Starting sql source {} ...", getName());
// sqlSourceCounter.start();
super.start();
}
/**
* Stop the source. Close database connection and stop metrics counter.
*/
@Override
public void stop() {
LOG.info("Stopping sql source {} ...", getName());
try {
hibernateHelper.closeSession();
csvWriter.close();
} catch (IOException e) {
LOG.warn("Error CSVWriter object ", e);
} finally {
// this.sqlSourceCounter.stop();
super.stop();
}
}
private class ChannelWriter extends Writer {
private List<Event> events = new ArrayList<>();
@Override
public void write(char[] cbuf, int off, int len) throws IOException {
Event event = new SimpleEvent();
String s = new String(cbuf);
event.setBody(s.substring(off, len - 1).getBytes());
Map<String, String> headers;
headers = new HashMap<String, String>();
headers.put("timestamp", String.valueOf(System.currentTimeMillis()));
event.setHeaders(headers);
events.add(event);
if (events.size() >= sqlSourceHelper.getBatchSize())
flush();
}
@Override
public void flush() {
getChannelProcessor().processEventBatch(events);
events.clear();
}
@Override
public void close() throws IOException {
flush();
}
}
}package org.keedio.flume.source;
import java.io.File;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.io.Writer;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.apache.flume.conf.ConfigurationException;
import org.apache.flume.Context;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* Helper to manage configuration parameters and utility methods <p>
* <p>
* Configuration parameters readed from flume configuration file:
* <tt>type: </tt> org.keedio.flume.source.SQLSource <p>
* <tt>connection.url: </tt> database connection URL <p>
* <tt>user: </tt> user to connect to database <p>
* <tt>password: </tt> user password <p>
* <tt>table: </tt> table to read from <p>
* <tt>columns.to.select: </tt> columns to select for import data (* will import all) <p>
* <tt>incremental.value: </tt> Start value to import data <p>
* <tt>run.query.delay: </tt> delay time to execute each query to database <p>
* <tt>status.file.path: </tt> Directory to save status file <p>
* <tt>status.file.name: </tt> Name for status file (saves last row index processed) <p>
* <tt>batch.size: </tt> Batch size to send events from flume source to flume channel <p>
* <tt>max.rows: </tt> Max rows to import from DB in one query <p>
* <tt>custom.query: </tt> Custom query to execute to database (be careful) <p>
*
* @author <a href="mailto:mvalle@keedio.com">Marcelo Valle</a>
* @author <a href="mailto:lalazaro@keedio.com">Luis Lazaro</a>
* @author tianqin
*/
public class SQLSourceHelper {
private static final Logger LOG = LoggerFactory.getLogger(SQLSourceHelper.class);
private File file, directory;
private int runQueryDelay, batchSize, maxRows, currentIndex;
private String statusFilePath, statusFileName, connectionURL, table,
columnsToSelect, user, password, customQuery, query, hibernateDialect,
hibernateDriver;
private static final String DEFAULT_STATUS_DIRECTORY = "/var/lib/flume";
private static final int DEFAULT_QUERY_DELAY = 10000;
private static final int DEFAULT_BATCH_SIZE = 1000;
private static final int DEFAULT_MAX_ROWS = 10000;
private static final int DEFAULT_INCREMENTAL_VALUE = 0;
/**
* 添加map存放多张表数据,key为表名
*/
private Map<String, File> files;
private Map<String, String> querys;
private Map<String, Integer> currentIndexMap;
private String[] tables;
/**
* Builds an SQLSourceHelper containing the configuration parameters and
* usefull utils for SQL Source
*
* @param context Flume source context, contains the properties from configuration file
*/
public SQLSourceHelper(Context context) {
statusFilePath = context.getString("status.file.path", DEFAULT_STATUS_DIRECTORY);
statusFileName = context.getString("status.file.name");
connectionURL = context.getString("connection.url");
table = context.getString("table");
columnsToSelect = context.getString("columns.to.select", "*");
runQueryDelay = context.getInteger("run.query.delay", DEFAULT_QUERY_DELAY);
user = context.getString("user");
password = context.getString("password");
directory = new File(statusFilePath);
customQuery = context.getString("custom.query");
batchSize = context.getInteger("batch.size", DEFAULT_BATCH_SIZE);
maxRows = context.getInteger("max.rows", DEFAULT_MAX_ROWS);
hibernateDialect = context.getString("hibernate.dialect");
hibernateDriver = context.getString("hibernate.connection.driver_class");
checkMandatoryProperties();
//配置文件中表名英文逗号隔开
tables = table.split(",");
if (!(isStatusDirectoryCreated())) {
createDirectory();
}
files = new HashMap<>();
querys = new HashMap<>();
currentIndexMap = new HashMap<>();
//给每张表对应的value赋值
for (String table1 : tables) {
file = new File(statusFilePath + "/" + statusFileName + "_" + table1);
files.put(table1, file);
currentIndex = getStatusFileIndex(context.getInteger("incremental.value", DEFAULT_INCREMENTAL_VALUE), file, table1);
currentIndexMap.put(table1, currentIndex);
query = buildQuery(table1);
querys.put(table1, query);
}
}
private String buildQuery(String tableName) {
if (customQuery == null)
return "SELECT " + columnsToSelect + " FROM " + tableName;
else
return customQuery;
}
private boolean isStatusFileCreated(File file) {
return file.exists() && !file.isDirectory() ? true : false;
}
private boolean isStatusDirectoryCreated() {
return directory.exists() && !directory.isFile() ? true : false;
}
/**
* Converter from a List of Object List to a List of String arrays <p>
* Useful for csvWriter
*
* @param queryResult Query Result from hibernate executeQuery method
* @return A list of String arrays, ready for csvWriter.writeall method
*/
public List<String[]> getAllRows(List<List<Object>> queryResult) {
List<String[]> allRows = new ArrayList<String[]>();
if (queryResult == null || queryResult.isEmpty())
return allRows;
String[] row = null;
for (int i = 0; i < queryResult.size(); i++) {
List<Object> rawRow = queryResult.get(i);
row = new String[rawRow.size()];
for (int j = 0; j < rawRow.size(); j++) {
if (rawRow.get(j) != null)
row[j] = rawRow.get(j).toString();
else
row[j] = "";
}
allRows.add(row);
}
return allRows;
}
/**
* Update status file with last read row index
*/
public void updateStatusFile(File file, String table, int currentIndex) {
/* Status file creation or update */
try {
Writer writer = new FileWriter(file, false);
writer.write(connectionURL + " ");
writer.write(table + " ");
writer.write(Integer.toString(currentIndex) + " \n");
writer.close();
} catch (IOException e) {
LOG.error("Error writing incremental value to status file!!!", e);
}
}
private int getStatusFileIndex(int configuredStartValue, File file, String table) {
if (!isStatusFileCreated(file)) {
LOG.info("Status file not created, using start value from config file");
return configuredStartValue;
} else {
try {
FileReader reader = new FileReader(file);
char[] chars = new char[(int) file.length()];
reader.read(chars);
String[] statusInfo = new String(chars).split(" ");
if (statusInfo[0].equals(connectionURL) && statusInfo[1].equals(table)) {
reader.close();
LOG.info(statusFilePath + "/" + statusFileName + "_" + table + " correctly formed");
return Integer.parseInt(statusInfo[2]);
} else {
LOG.warn(statusFilePath + "/" + statusFileName + "_" + table + " corrupt!!! Deleting it.");
reader.close();
deleteStatusFile(file);
return configuredStartValue;
}
} catch (NumberFormatException | IOException e) {
LOG.error("Corrupt index value in file!!! Deleting it.", e);
deleteStatusFile(file);
return configuredStartValue;
}
}
}
private void deleteStatusFile(File file) {
if (file.delete()) {
LOG.info("Deleted status file: {}", file.getAbsolutePath());
} else {
LOG.warn("Error deleting file: {}", file.getAbsolutePath());
}
}
private void checkMandatoryProperties() {
if (statusFileName == null) {
throw new ConfigurationException("status.file.name property not set");
}
if (connectionURL == null) {
throw new ConfigurationException("connection.url property not set");
}
if (table == null && customQuery == null) {
throw new ConfigurationException("property table not set");
}
if (password == null) {
throw new ConfigurationException("password property not set");
}
if (user == null) {
throw new ConfigurationException("user property not set");
}
}
/*
* @return String connectionURL
*/
String getConnectionURL() {
return connectionURL;
}
/*
* @return boolean pathname into directory
*/
private boolean createDirectory() {
return directory.mkdir();
}
/*
* @return 最新的 table-index 键值对
*/
Map<String, Integer> getCurrentIndex() {
return currentIndexMap;
}
/**
* @void set incrementValue
* @param table 表名
* @param newValue 新的index
*/
void setCurrentIndex(String table, int newValue) {
currentIndexMap.replace(table, newValue);
}
/*
* @return String user for database
*/
String getUser() {
return user;
}
/*
* @return String password for user
*/
String getPassword() {
return password;
}
/*
* @return int delay in ms
*/
int getRunQueryDelay() {
return runQueryDelay;
}
int getBatchSize() {
return batchSize;
}
int getMaxRows() {
return maxRows;
}
Map<String, String> getQuery() {
return querys;
}
String getHibernateDialect() {
return hibernateDialect;
}
String getHibernateDriver() {
return hibernateDriver;
}
//返回 table-file 键值对
Map<String, File> getFiles() {
return files;
}
//返回 table数组
String[] getTables() {
return tables;
}
}就这三个文件做了些许改动,其他的用原作者的就行了
演示效果
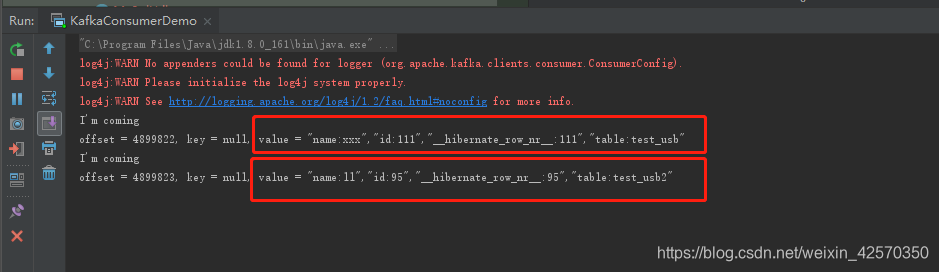
我用的kafka sink作接收数据,监听的test_usb、test_usb2两张表
两张表同时插入数据

kafka消费到数据
附上flume配置文件
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
# The configuration file needs to define the sources,
# the channels and the sinks.
# Sources, channels and sinks are defined per agent,
# in this case called 'agent'
agent.sources = sqlsSource
agent.channels = memoryChannel
agent.sinks = kafkaSink
# For each one of the sources, the type is defined
agent.sources.sqlsSource.type = org.keedio.flume.source.SQLSource
#读取sqlserver2008的配置
agent.sources.sqlsSource.connection.url = jdbc:sqlserver://0.0.0.0:1433;DatabaseName=test
agent.sources.sqlsSource.user = sa
agent.sources.sqlsSource.password = 123456
agent.sources.sqlsSource.hibernate.connection.autocommit = true
agent.sources.sqlsSource.hibernate.connection.provider_class = org.hibernate.connection.C3P0ConnectionProvider
agent.sources.sqlsSource.hibernate.connection.driver_class = com.microsoft.sqlserver.jdbc.SQLServerDriver
agent.sources.sqlsSource.hibernate.c3p0.min_size=1
agent.sources.sqlsSource.hibernate.c3p0.max_size=10
#根据sqlserver版本作修改
agent.sources.sqlsSource.hibernate.dialect = org.hibernate.dialect.SQLServer2008Dialect
agent.sources.sqlsSource.max.rows = 1000000
agent.sources.sqlsSource.table = test_usb,test_usb2 #多张表的表名要用逗号隔开
agent.sources.sqlsSource.columns.to.select = *
agent.sources.sqlsSource.column.name = id
agent.sources.sqlsSource.incremental.value = 0
agent.sources.sqlsSource.delimiter.entry = ,
agent.sources.sqlsSource.enclose.by.quotes = false
agent.sources.sqlsSource.run.query.delay=5000
agent.sources.sqlsSource.status.file.path = D:/ChromeDownload/apache-flume-1.7.0-bin/status
agent.sources.sqlsSource.status.file.name = status
# The channel can be defined as follows.
agent.sources.sqlsSource.channels = memoryChannel
# Each sink's type must be defined
agent.sinks.kafkaSink.type = org.apache.flume.sink.kafka.KafkaSink
agent.sinks.kafkaSink.kafka.bootstrap.servers=wind-bd-test02:9092,wind-bd-test03:9092,wind-bd-test04:9092
agent.sinks.kafkaSink.kafka.topic=test
#Specify the channel the sink should use
agent.sinks.kafkaSink.channel = memoryChannel
# Each channel's type is defined.
agent.channels.memoryChannel.type = memory
# Other config values specific to each type of channel(sink or source)
# can be defined as well
# In this case, it specifies the capacity of the memory channel
agent.channels.memoryChannel.capacity = 100以上就是初步做的修改,还有很多可以改进的地方,欢迎交流!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









