




 本文深入探讨软件测试与质量保证中的黑盒测试策略,包括边界值、健壮性、最坏情况及决策表测试,解析等价类测试的不同类型,如弱一般、强一般、弱健壮和强健壮等价类测试,以及积极测试与消极测试的比例分配。
本文深入探讨软件测试与质量保证中的黑盒测试策略,包括边界值、健壮性、最坏情况及决策表测试,解析等价类测试的不同类型,如弱一般、强一般、弱健壮和强健壮等价类测试,以及积极测试与消极测试的比例分配。
软件测试与质量保证之黑盒测试
黑盒测试
根据需求进行测试
- Boundary Value Testing(边界值测试)
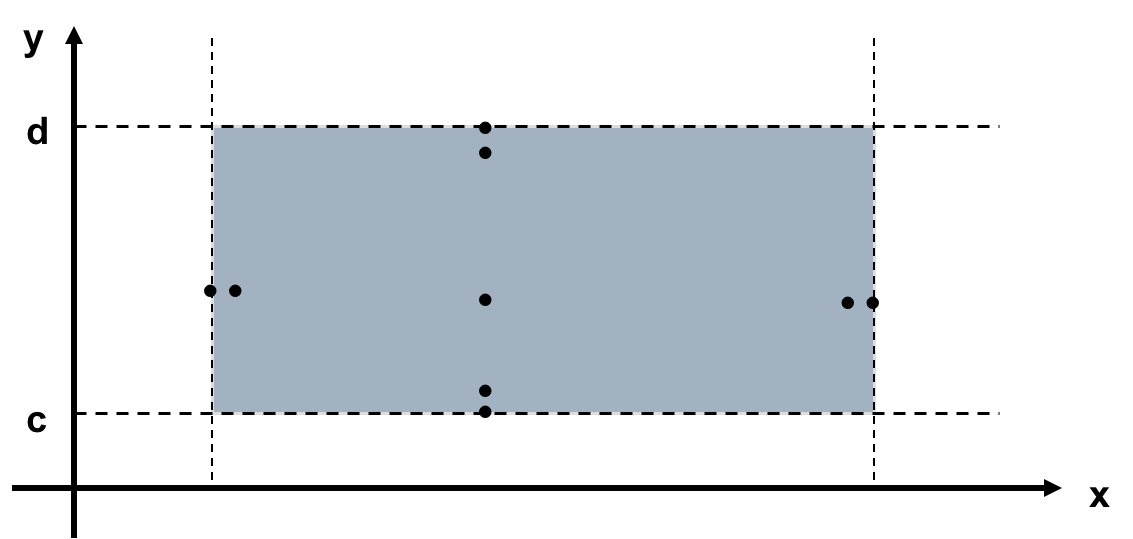
至少需要4n+1个测试用例
- Robustness Testing (健壮性测试)
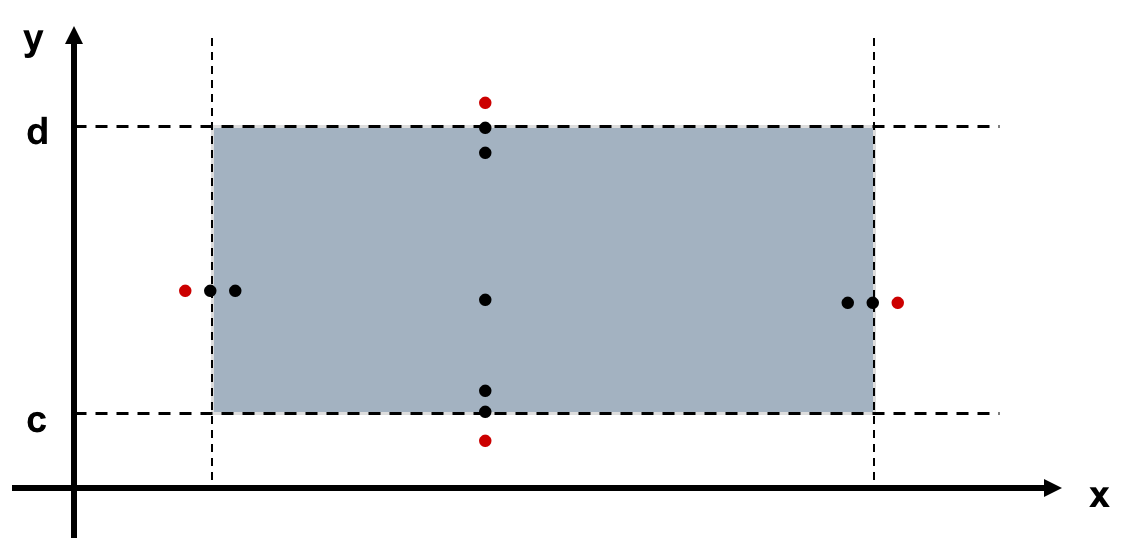
至少需要6n+1个测试用例
- Worst-Case Testing (最坏情况测试)
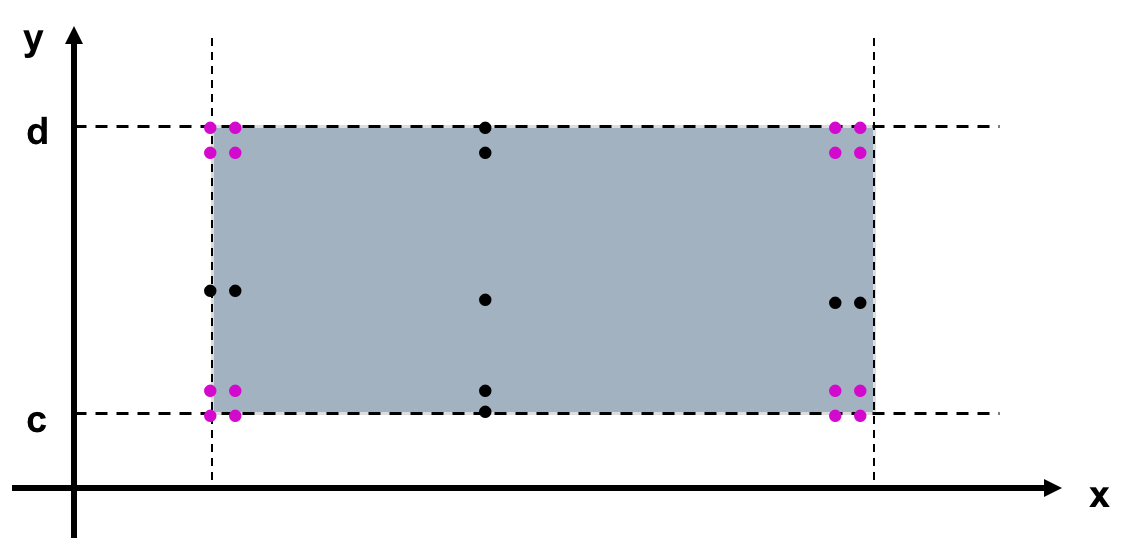
至少需要5^n个测试用例
- Robust Worst-Case Testing (健壮性最坏情况测试)
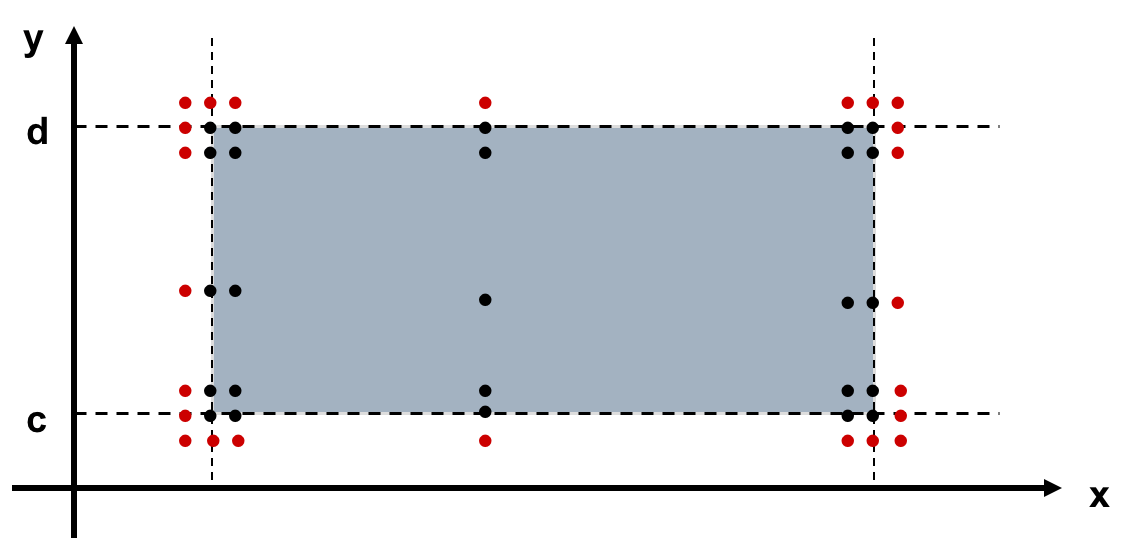
至少需要7^n个测试用例
- Positive And Negative Testing(积极测试和消极测试)
积极测试采用合法输入,消极测试采用非法输入,一般的测试中消极占80%,积极占20%
- Range Testing(范围测试)
节省时间
- Equivalence Class Testing(等价类测试)
PS:下面的强弱是指每次测多个参数还是一个参数。一般和健壮是指是否测试边界外的值。- Weak Normal Equivalence Class Testing (弱一般等价类测试)
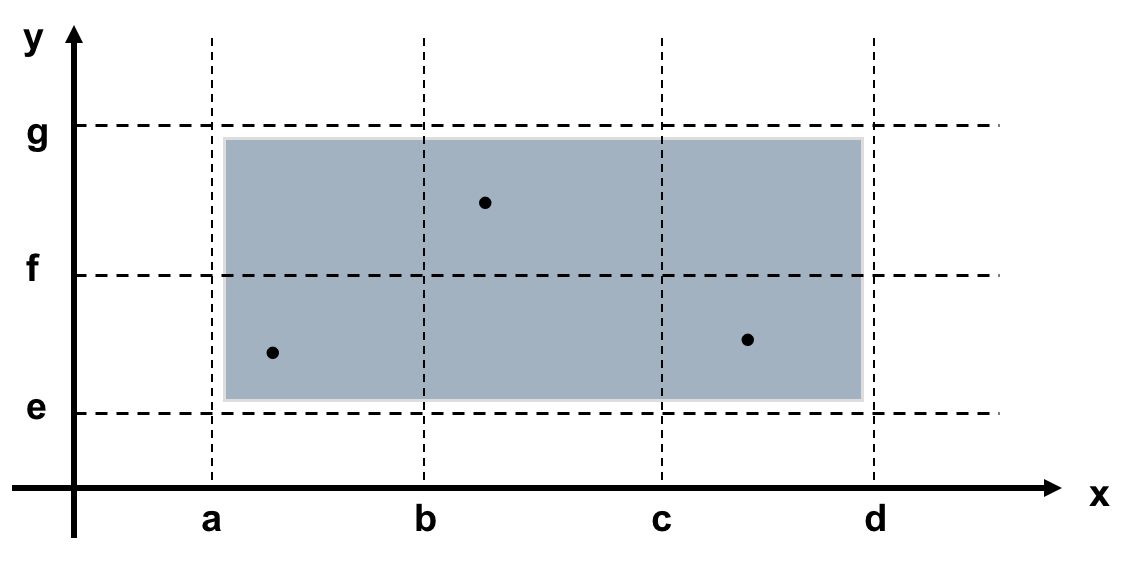
- Strong Normal Equivalence Class Testing (强一般等价类测试)
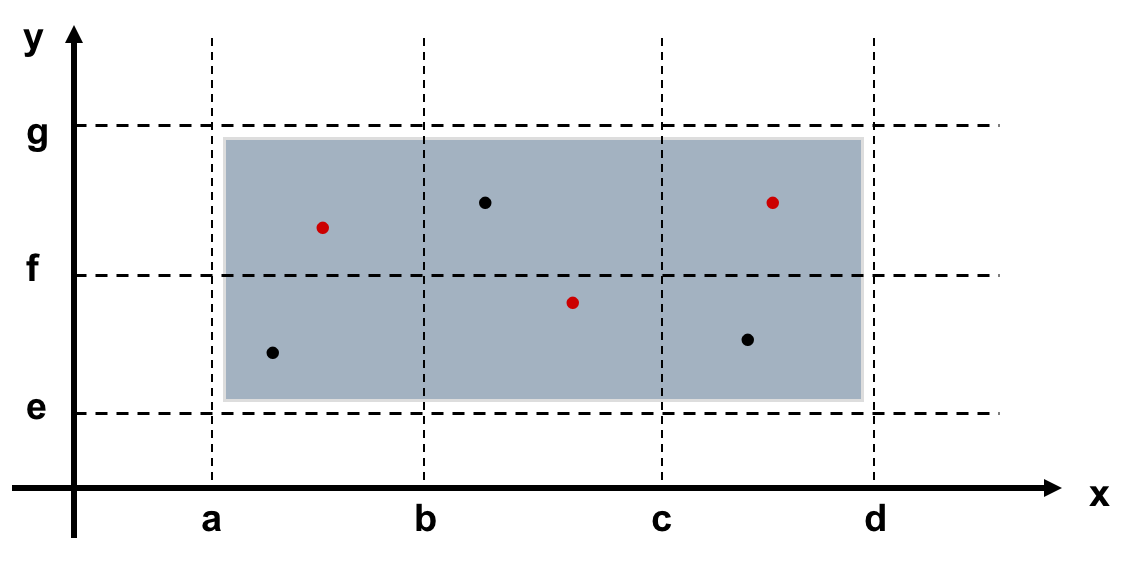
- Weak Robust Equivalence Class Testing (弱健壮等价类测试)
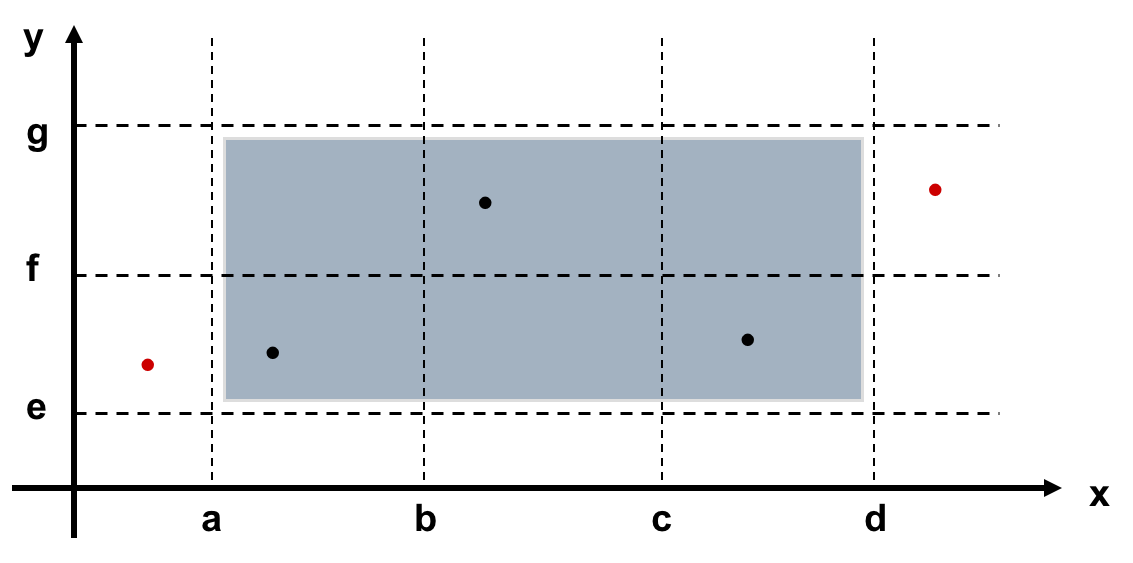
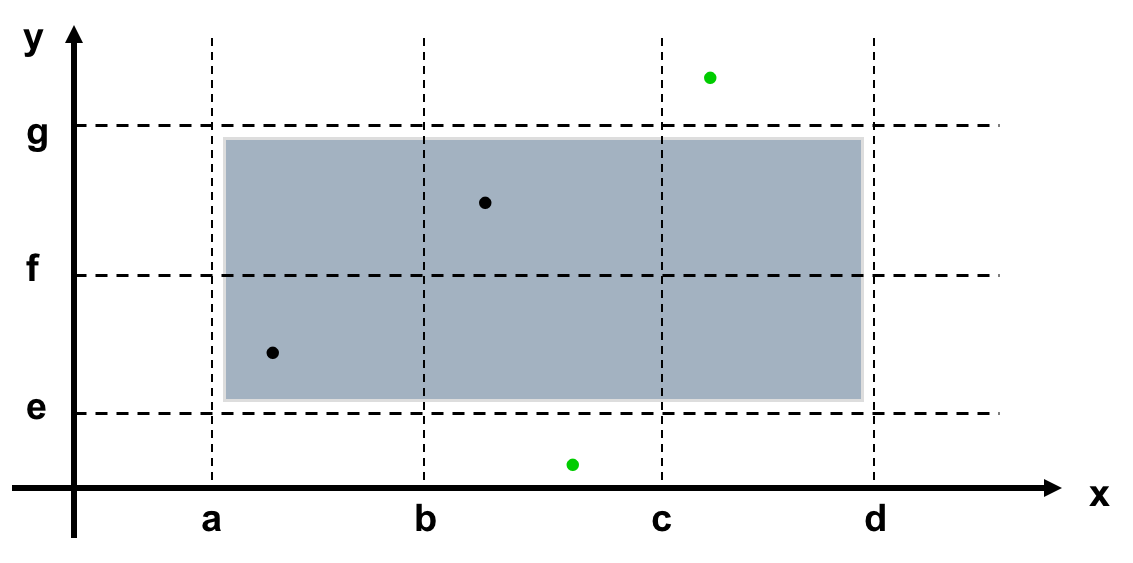
- Strong Robust Equivalence Class Testing (强健壮等价类测试)
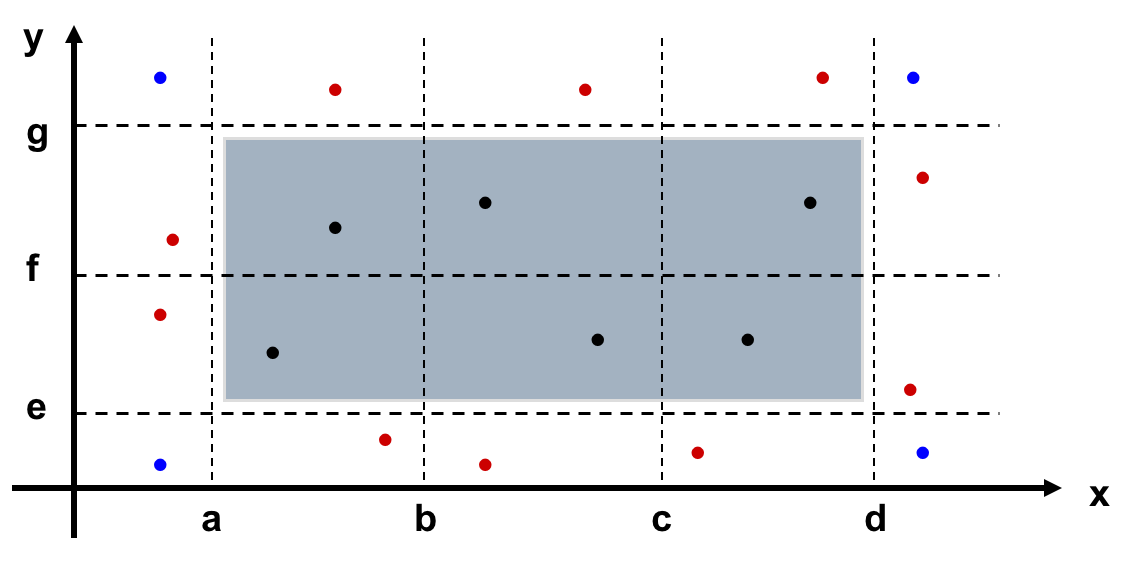
- Weak Normal Equivalence Class Testing (弱一般等价类测试)
- Decision Table-Based Testing(基于决策表的测试)
实体部分每一列都是一条规则,它定义了采取什么行动时系统的行为。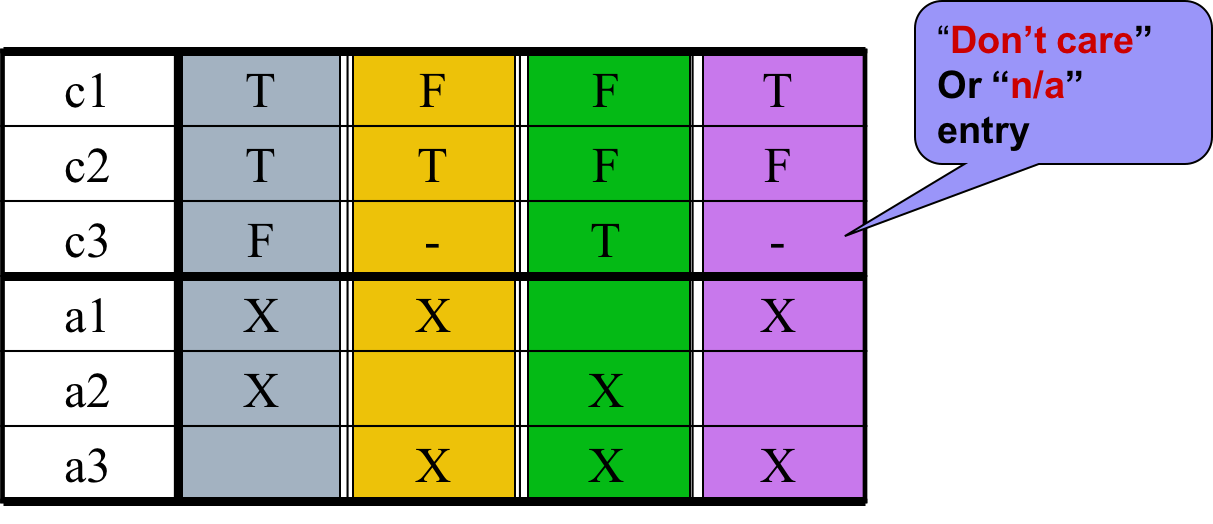



























 1201
1201

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









