









 本文详细描述了Transformer模型在翻译任务中的工作流程,涉及编码器处理输入、嵌入层转换、多头注意力机制、解码器生成输出序列的过程,强调了上下文理解和自注意力机制的作用。
本文详细描述了Transformer模型在翻译任务中的工作流程,涉及编码器处理输入、嵌入层转换、多头注意力机制、解码器生成输出序列的过程,强调了上下文理解和自注意力机制的作用。
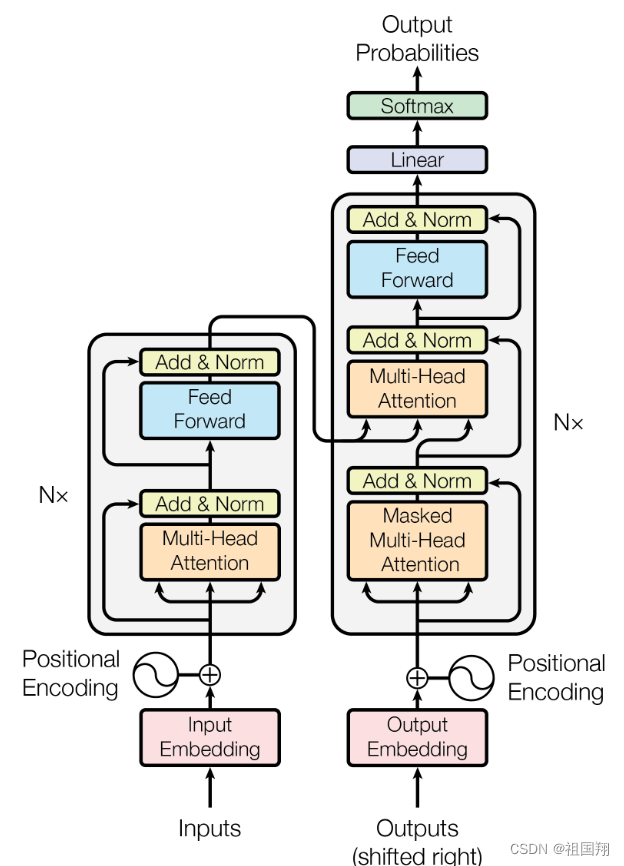
我们看到很多文章讲了transformer架构的概述,包括其中一些主要组件。但大部分文章没有讲整个预测过程是如何一步步进行的。让我们通过一个简单的例子来详细了解一下。在这个例子中,你将会看到一个翻译任务或者序列到序列任务,这恰好是transformer架构设计者最初的目标。
你将使用一个transformer模型将法语短语翻译成英语。首先,你将使用与训练网络相同的分词器对输入单词进行标记。这些标记然后被添加到网络的编码器端的输入中,通过嵌入层(嵌入层通常用于将词语或字符转换为密集的向量表示,这些向量在连续空间中捕捉了词语之间的语义和语法关系),然后传递到多头注意力层。多头注意力层的输出通过前馈网络传递到编码器的输出。这时,离开编码器的数据是输入序列结构和含义的深度表示。这个表示被插入到解码器的中间,影响解码器的自注意机制。接下来,在解码器的输入中添加了一个序列开始标记。这会触发解码器预测下一个标记,它会基于来自编码器的上下文理解来进行预测。解码器的自注意力层的输出通过解码器前馈网络和最终的softmax输出层。这时,我们得到了第一个标记。你将继续这个循环,将输出标记传递回解码器的输入,触发生成下一个标记,直到模型预测出一个序列结束标记。这时,最终的输出序列可以被还原成单词,你就得到了输出。
让我们总结一下上面的内容。完整的transformer架构包括编码器和解码器组件。编码器将输入序列编码为输入结构和含义的深度表示。解码器在接收到输入标记触发后,利用编码器的上下文理解生成新的标记。它会在循环中进行,直到达到某个停止条件。
阅读上面内容,要对照Transformer 模型图,边读边看边理解,因此我们把模型图放一下:

















 40
40

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









