







 本文介绍了Squeeze-and-Attention Networks (SANet) 结构,该结构通过压缩注意力模型强化分割任务的表征能力。SANet结合分组像素注意和像素级预测,通过注意力卷积通道引入空间-通道相互依赖,提升模型精度。在COCO数据集上达到83.2%的精度,PASCAL上达到54.4%的精度。相比传统方法,SA模型更高效,解决了通道注意力的参数问题,并引入像素组注意力,提高了目标像素级预测的准确性。
本文介绍了Squeeze-and-Attention Networks (SANet) 结构,该结构通过压缩注意力模型强化分割任务的表征能力。SANet结合分组像素注意和像素级预测,通过注意力卷积通道引入空间-通道相互依赖,提升模型精度。在COCO数据集上达到83.2%的精度,PASCAL上达到54.4%的精度。相比传统方法,SA模型更高效,解决了通道注意力的参数问题,并引入像素组注意力,提高了目标像素级预测的准确性。
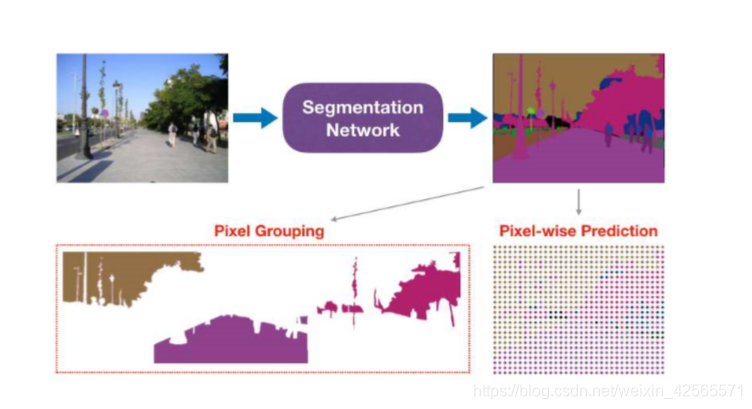
最近将注意力机制整合到分割任务通过强调特征里面的信息中来提升模型的表征能力。但是这些注意力机制忽略了一个暗含的分割子任务并且被卷积核的方格型形状所限制。我们提出了一个新颖的压缩注意力网络(SANet)结构,利用了一个高效的压缩注意力(SA)模型去计算两个分割图突出的特征:1)分组像素注意 2)像素级预测。特别指出,我们提出的压缩注意力模型通过引入注意力卷积通道在常规卷积上加了像素组注意力,所以以有效的方式引入一个空间-通道相互依赖。最终的分割结果由网络输出和四个阶段的多尺度上下文目标像素级预测增强融合所得。我们的SANEet在coco数据集上取得83.2%的精度,在PASCAL取得54.4%的精度。
以前的工作:
1)多尺度上下文,一般包含金字塔或者多尺度通道,通过融合多尺度的上下文信息达到增强分割的目的。一个聚集激活模型被提出通过长范围的上下文信息来缓解普通卷积的特征的位置限制。我们的方法用融合主干残差网络不同阶段的输出来提高稠密连接的多尺度预测。
2)通道注意力,一般就是给特定的通道分配不同的权重达到强调重要通道的目的。缺点:带来额外的参数。而我们的压缩注意模型带有下采样但是并不完全压缩卷积通道,使得网络更灵活。特别是增加的通道
3)像素组注意力,自然语言处理中
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2888
2888

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









