










 本文介绍了一种使用Softmax回归算法预测红酒产地的方法,通过对178个样本的13个特征进行分析,实现了对三种不同产地红酒的有效区分。文章详细记录了实验过程,包括数据预处理、模型训练和评估,以及与Logistic回归算法的对比。
本文介绍了一种使用Softmax回归算法预测红酒产地的方法,通过对178个样本的13个特征进行分析,实现了对三种不同产地红酒的有效区分。文章详细记录了实验过程,包括数据预处理、模型训练和评估,以及与Logistic回归算法的对比。
一、问题描述
红酒产地预测问题的任务是:根据红酒的各项指标,鉴定红酒的产地。
数据:sklearn工具库。
样本数178,每个样本表示1瓶红酒,13个特征,如红酒颜色、蒸馏度等。
类标签:3个。
导入数据,利用Softmax回归算法预测红酒产地,并输出accuracy,画出ROC曲线。
二、实验目的
学习softmax回归函数,用于实践
三、实验内容
1. 数据导入
rwine = load_wine() #导入红酒数据
x = rwine.data
y = rwine.target
2.数据预处理
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.8, random_state=4)
x_train = process_features(x_train)
x_test = process_features(x_test)
encode = OneHotEncoder()
y_train = encode.fit_transform(y_train.reshape(-1,1)).toarray()
model = softReg.SoftmaxRegression()
model.fit(x_train, y_train) #训练模型
proba = model.predict_proba(x_test) #预处理四、实验结果及分析
1. 使用Softmax回归算法的结果:
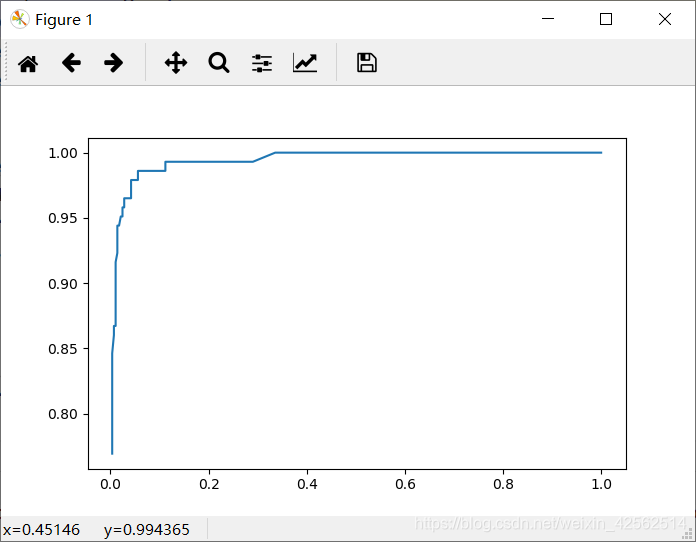
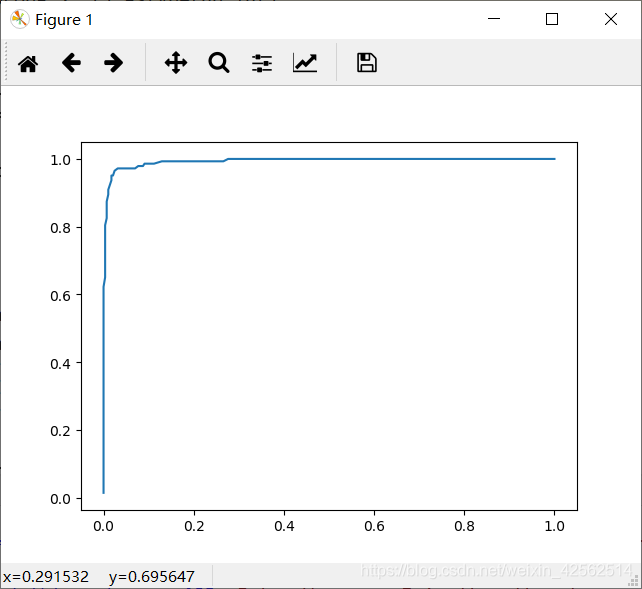
2. 使用sklearn的LogisticRegression算法的结果:
五、完整代码
机器学习GitHub:https://github.com/wanglei18/machine_learning
classification_metrics.py
import numpy as np
def cross_entropy(y_true, y_pred):
return np.average(-y_true * np.log(y_pred) - (1 - y_true) * np.log(1 - y_pred))
def accuracy_score(y_true, y_pred):
correct = (y_pred == y_true).astype(np.int)
return np.average(correct)
def precision_score(y, z):
tp = (z * y).sum()
fp = (z * (1 - y)).sum()
if tp + fp == 0:
return 1.0
else:
return tp / (tp + fp)
def recall_score(y, z):
tp = (z * y).sum()
fn = ((1 - z) * y).sum()
if tp + fn == 0:
return 1
else:
return tp / (tp + fn)softmax_regression_gd.py
import numpy as np
def softmax(scores):
e = np.exp(scores)
s = e.sum(axis=1)
for i in range(len(s)):
e[i] /= s[i]
return e
class SoftmaxRegression:
def fit(self, X, y, eta=0.1, N=2000):
m, n = X.shape
m, k = y.shape
w = np.zeros(n * k).reshape(n,k)
for t in range(N):
proba = softmax(X.dot(w))
g = X.T.dot(proba - y) / m
w = w - eta * g
self.w = w
def predict_proba(self, X):
return softmax(X.dot(self.w))
def predict(self, X):
proba = self.predict_proba(X)
return np.argmax(proba, axis=1)import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import OneHotEncoder
import machine_learning.homework.week6.softmax_regression_gd as softReg
import machine_learning.homework.week6.classification_metrics as classMe
#格式化数据
def process_features(X):
scaler = MinMaxScaler(feature_range=(0,1))
X = scaler.fit_transform(1.0*X)
m, n = X.shape
X = np.c_[np.ones((m, 1)), X]
return X
def threshold(t,proba):
return (proba >= t).astype(np.int)
#绘制图形
def plot_roc_curve(proba,y):
fpr,tpr = [],[]
for i in range(80):
z = threshold(0.01*i,proba)
tp = (y*z).sum()
fp = ((1-y)*z).sum()
tn = ((1-y)*(1-z)).sum()
fn = (y*(1-z)).sum()
fpr.append(1.0*fp/(fp+tn))
tpr.append(1.0*tp/(tp+fn))
plt.plot(fpr,tpr)
plt.show()
rwine = load_wine() #导入红酒数据
x = rwine.data
y = rwine.target
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.8, random_state=5)
x_train = process_features(x_train)
x_test = process_features(x_test)
encode = OneHotEncoder()
y_train = encode.fit_transform(y_train.reshape(-1,1)).toarray()
model = softReg.SoftmaxRegression()
model.fit(x_train, y_train) #训练模型
proba = model.predict_proba(x_test) #预处理
y_pred = model.predict(x_test) #预测数据
accuracy = classMe.accuracy_score(y_test, y_pred) #获得accuracy
print("accuracy = {}".format(accuracy))
y_test = encode.fit_transform(y_test.reshape(-1,1)).toarray()
plot_roc_curve(proba, y_test)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import OneHotEncoder
from sklearn.linear_model.logistic import LogisticRegression
import machine_learning.homework.week6.classification_metrics as classMe
#格式化数据
def process_features(X):
scaler = MinMaxScaler(feature_range=(0,1))
X = scaler.fit_transform(1.0*X)
m, n = X.shape
X = np.c_[np.ones((m, 1)), X]
return X
def threshold(t,proba):
return (proba >= t).astype(np.int)
#绘制图形
def plot_roc_curve(proba,y):
fpr,tpr = [],[]
for i in range(80):
z = threshold(0.01*i,proba)
tp = (y*z).sum()
fp = ((1-y)*z).sum()
tn = ((1-y)*(1-z)).sum()
fn = (y*(1-z)).sum()
fpr.append(1.0*fp/(fp+tn))
tpr.append(1.0*tp/(tp+fn))
plt.plot(fpr,tpr)
plt.show()
rwine = load_wine() #导入红酒数据
x = rwine.data
y = rwine.target
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.8, random_state=5)
x_train = process_features(x_train) #格式化数据
x_test = process_features(x_test)
encode = OneHotEncoder()
model = LogisticRegression() #建立模型
model.fit(x_train, y_train) #训练模型
proba = model.predict_proba(x_test)
y_pred = model.predict(x_test) #预测数据
accuracy = classMe.accuracy_score(y_test, y_pred)
print("accuracy={}".format(accuracy))
y_test = encode.fit_transform(y_test.reshape(-1,1)).toarray()
print(proba.shape, y_test.shape)
plot_roc_curve(proba, y_test)


















 594
594

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











