






 本文详细介绍了Scrapy框架的各个组成部分,包括爬虫、引擎、调度器、下载器、中间件(包括爬虫中间件和下载中间件)以及管道,阐述了它们的功能和工作流程。此外,还涵盖了环境准备、项目结构和配置选项,为Scrapy项目的开发提供全面指南。
本文详细介绍了Scrapy框架的各个组成部分,包括爬虫、引擎、调度器、下载器、中间件(包括爬虫中间件和下载中间件)以及管道,阐述了它们的功能和工作流程。此外,还涵盖了环境准备、项目结构和配置选项,为Scrapy项目的开发提供全面指南。
scrapy介绍:
scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可应用在包括数据挖掘,信息处理或存储历史数据等一系列的需求之中,我们只需要实现少量的代码,就能够快速的抓取,Scrapy使用了Twisted异步网络框架,可以加快我们的下载速度。
scrapy的数据流图片:
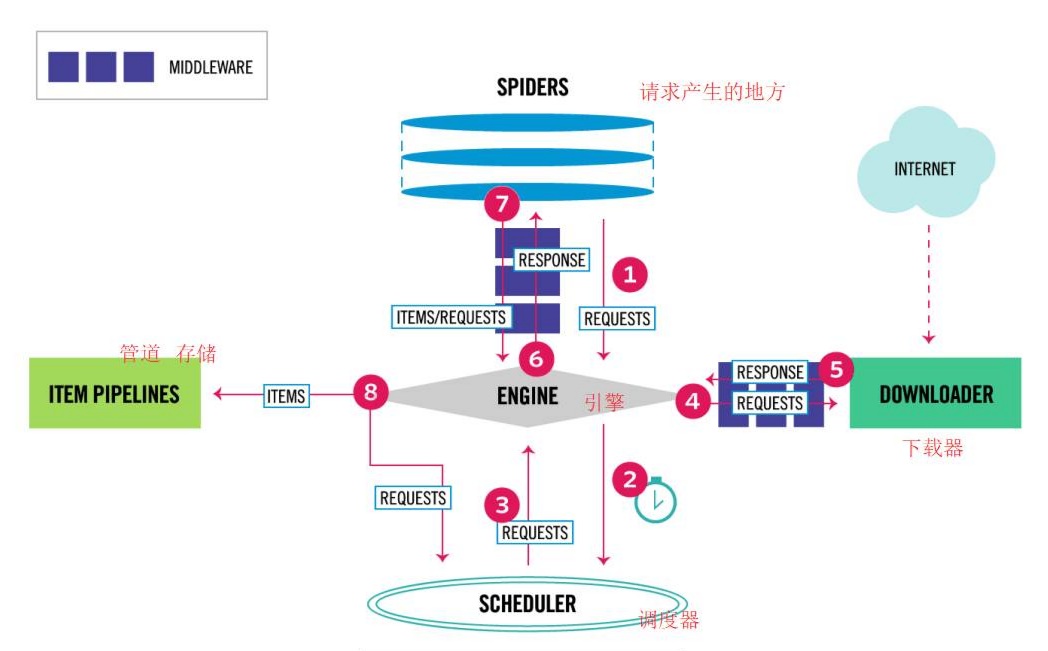
scrapy的基本模块:
爬虫
爬虫主要就发起起始请求,并通过回调函数,对响应数据进行提取,生成item给管道进行后续处理,或者生成新的请求。
引擎
从上图就能看出,引擎处于整个scrapy项目的核心位置,其主要处理整个系统的数据流,触发各种事件。
调度器
调度器其实就是维护了一个先进先出的队列,对于入队的请求会进行去重与过滤,可以保证请求出队的顺序,保证请求按顺序执行。其中请求顺序并不一定是固定的,可以通过在发起请求或在中间件中时设置priority来改变优先级,其中值越小越快。比如在发起的请求的参数中添加scrapy.Request(property= 目标优先级),或直接request.property=目标优先级。
下载器
下载器其实就是发送请求并接受保存响应数据,是基于twisted异步框架实现的,可以同时处理多个请求,在回调中将下载结果传递给引擎。在请求的过程中会处理重定向,保证获取最终数据;维护cookie与session数据,确保对于不同的请求能保存持久性对话。
中间件
中间件主要包括爬虫,下载和扩展中间件,其中爬虫中间件主要处理爬虫与引擎之间的非起始请求与响应,而下载中间件主要处理下载器和引擎之间的非起始请求与响应。旨在数据的传输过程中对其进行校验与增强。还有扩展的中间件。
管道
管道其作用主要用于处理item数据,进行过滤与提取,或者进行持久化,生成相应文件等操作
数据执行流程
-
通过运行的爬虫的start_urls或start_requests方法,通过爬虫中间件的process_start_requests()将起始请求发送给引擎。
-
引擎将请求传递给调度器进行构建,调度器根据调度策略,将构建好的请求返回和给引擎。
-
引擎将请求通过发送给下载器,下载器下载完成后,再将响应返回给引擎。在这期间请求与响应都会经过下载中间件。
-
引擎在接收到响应后,会将响应返回给爬虫的默认回调解析函数parse,在响应返回时会经过爬虫中间件的process_responses()
-
在回调解析函数中,会根据代码逻辑,重新发起请求给引擎,或者生成item并传给管道
-
重新发送请求,则会重复上述次序,继续执行;传给管道,对数据进行持久化或文本存储等
开始项目
-
环境准备 python3.6以上版本,注意安装scrapy前需要安装lxml,parsel,pyOpenSSL,Twisted,cryptography,w3lib,它们是scrapy项目的基础依赖。
-
在目标文件夹,执行下面命令,生成scrapy项目,并在项目的spider文件夹下生成对应的爬虫,并运行爬虫。可以观察到项目运行成功。
scrapy startproject 工程名 #生成项目
cd 工程名
scrapy genspider 爬虫文件名 待爬取的网站域名 #生成爬虫
scrapy crawl 爬虫名 #启动爬虫各文件功能具体的分析
项目整体结构
工程名/
scrapy.cfg
工程名/
__init__.py
items.py #item类文件,主要定义字段属性
middlewares.py #中间件文件,主要是自定义的爬虫与下载中间件
pipelines.py #管道类文件,主要是自定义的管道
settings.py #全局配置信息
spiders/
__init__.py
爬虫名.py #生成的爬虫文件spider文件
-
功能及常用的方法:
-
自定义的爬虫,都是继承自抽象类scrapy.Spider,其主要功能在于定义起始请求,创建请求,接收与解析响应,以及管理爬虫的基础属性。
-
start_requests(self),创建起始请求,发送给引擎。当没有start_requests方法时,spider将会以start_urls为基础构建请求。
-
parse(self, response),用于作为response的回调,解析处理response的数据,可能是从中响应中解析出数据并填入自定义item中,交由管道去处理。也可能是从响应中生成新的请求去交由下载器处理。
-
-
下载中间件文件
-
功能及常用的方法:
-
具体功能是在请求和响应于下载器中出入时,对其进行预先处理。
-
process_response(response, request, spider),下载器将响应发送给引擎之前执行,它的作用是对响应进行处理和修改,比如解析网页内容、提取数据、失败重试等。返回response,意味操作结束放行;返回request意味着重新发起请求,该请求直接传给下载器进行下载;返回none,意味着跳过该响应,也不会传递给后续中间件和爬虫;raise一个 IgnoreReques异常,则交由process_exception进行处理。
-
process_request(request,spider),在请求进入引擎之前执行,它的作用是对请求校验与增强等,比如添加身份验证信息,合并或添加cookie等。返回response,意味着不进行后续操作,直接返回response给爬虫;返回request,意味修改请求内容,并放行;返回none,意味不做任何处理并放行。raise一个 IgnoreReques异常,则直接使用request的errorback进行处理。
-
process_exception(request,exception,spider),对于错误请求进行处理,往往是进行日志记录。如果没有代码处理抛出的异常,则该异常会被忽略不记录。返回none,放行,将其交由其他中间件的process_exceptio去进行处理;返回request,则停止当前以及后续process_exceptio方法,对新的request进行调用与下载;返回response,停止当前以及后续的process_exceptio方法,改为执行process_response方法。
-
-
默认中间件:
-
HttpAuthMiddleware:处理HTTP身份验证;spider_opened()通过getattr判断spider中是否有密码账号,有则使用basic_auth_header生成身份验证信息; process_request() 请求发送前进行检查,判断是否需要http身份验证,若需要则添加身份验证信息于请求头。
-
DownloadTimeoutMiddleware:设置下载超时时间;如果meta中没有download_timeout,且self._timeout不为null,则将self._timeout设为meta[download_timeout]。使用的是request.meta.setdefault(key, default) key无值则置入,若有值,则不置入。
-
MetaRefreshMiddleware:处理HTML页面中的元标签刷新重定向;process_response()判断状态码,通过return self._retry(request, reason, spider) or response,进行重试成功返回新的响应,失败则返回原响应。优先级应设较高,离下载器近。
-
RedirectMiddleware:处理重定向;process_response(),判断是否需要重定向,判断是否能重定向,再构建重定向的url,调用return self._redirect()去执行。
-
CookiesMiddleware:处理请求和响应中的Cookie;就是使用self.jar来存储cookie,self.jar是defaultdict(访问不存在数据时,会自动创建),其结构为{key,cookiejar} , cookiejar类用来管理cookie,可以保存多个cookie。主要依据dont_merge_cookies,判断是否操作以及合并cookie。
-
DownloaderStats:收集下载统计信息 stats.inc_value(key,count,start ,spider),count默认为1,start默认为0。主要使用key和count。
-
DefaultHeadersMiddleware :添加默认的HTTP头部信息。
-
UserAgentMiddleware:设置用户代理;用于模拟不同的浏览器或设备。
-
HttpProxyMiddleware:处理HTTP代理。
-
RetryMiddleware:处理请求失败时的重试。
-
HttpCompressionMiddleware:处理HTTP压缩;主要是针对响应,检查响应是否被压缩,有则进行解压,并创建新的响应。
-
-
爬虫中间件
-
功能及常用的方法:
-
具体功能是对出入爬虫的请求与响应进行处理,在爬虫数据的出入口处。
-
process_spider_input(response,spider),在响应进入爬虫前,对其进行处理。返回none时,放行给后续中间件执行。返回异常时,将不会进行后续的process_spider_input,直接进入request的errback方法,errback返回的输出重新进入直接的process_spider_output方法执行,当再次出现异常时,由process_spider_exception进行处理。
-
process_spider_output(response,result,spider),处理经过爬虫的数据,result包括request和item。比如对item进行数据清洗与过滤等。返回可迭代的值。
-
process_start_request(start_request,spider),处理起始请求,必须返回request。
-
process_spider_exception(response,exception,spider),处理异常。返回none,则放行,由其他中间件的process_spider_exception进行处理;返回可迭代对象,则其他中间件的process_spider_output方法被调用,后续的process_spider_exception方法不会被调用。
-
-
默认中间件:
-
HttpErrorMiddleware:处理HTTP错误。 若状态码在200~300间则成功,并判断是否在配置范围内,反之报错。
-
OffsiteMiddleware:过滤Spider的非法域名的请求,根据allowed_domains判断请求的主机 是否在允许范围之内,进行统计并过滤。
-
RefererMiddleware:为请求设置引荐页(表示当前请求的来源页面)。
-
UrlLengthMiddleware:限制URL长度。 同过URLLENGTH_LIMIT设置最大长度,出现超长的,进行统计与记录并过滤。
-
DepthMiddleware:对于Spider的深度进行限制。
-
-
item文件
-
功能及结构
-
item作为数据爬取的基本单元,类似于一个存储爬取数据的容器。自定义的item需要继承自scrapy.Item
-
定义相应的字段,每个字段都是一个scrapy.Field对象。用于存储爬取数据中的目标数据。
-
-
pipelines
-
功能及常用的方法
-
当爬虫对响应解析完成,将item传给引擎后,item就将被传给pipelines,并按照优先级顺序依次执行,对其中的item完成数据清洗或持久化等。
-
process_item(self, item, spider),对爬出输出的item进行处理。其是必须实现的方法,会默认调用这个方法对于item进行处理。返回item,将item交由后续的管道进行处理;返回DropItem 异常,当前 Item 会被丢弃,不再进行处理。
-
open_spider(self, spider: Spider),在爬虫打开时进行,往往是进行初始化设置,数据库连接等。
-
close_spider(self, spider: Spider),在爬虫关闭时进行,一般是关闭数据库,删除临时文件等。
-
-
配置文件
-
全局配置文件
BOT_NAME 设置Scrapy项目的名称。
SPIDER_MODULES 指定包含爬虫代码的Python模块。
NEWSPIDER_MODULE 指定生成新爬虫的模块。
USER_AGENT 设置用户代理,用于发送HTTP请求时模拟浏览器。
ROBOTSTXT_OBEY 设置是否遵守robots.txt规则。
CONCURRENT_REQUESTS 设置同时进行的请求数量。 改多线程
DOWNLOAD_DELAY 设置每个请求之间的延迟时间。
COOKIES_ENABLED 设置是否启用cookies。
ITEM_PIPELINES 配置数据处理管道的优先级和启用状态。
LOG_LEVEL 设置日志输出的级别。
DOWNLOAD_TIMEOUT 设置下载超时时间。
AUTOTHROTTLE_ENABLED 设置是否启用自动限速。
HTTPCACHE_ENABLED 设置是否启用HTTP缓存。
HTTPCACHE_EXPIRATION_SECS 设置HTTP缓存的过期时间。
DNSCACHE_ENABLED 设置是否启用DNS缓存。
CONCURRENT_REQUESTS_PER_DOMAIN 设置每个域名同时进行的请求数量。
CONCURRENT_REQUESTS_PER_IP 设置每个 IP 地址同时进行的请求数量。
SPIDER_MIDDLEWARES 设置爬虫中间件
SPIDER_MIDDLEWARES_BASE 默认的爬虫中间件
DOWNLOADER_MIDDLEWARES 设置下载中间件
DOWNLOADER_MIDDLEWARES_BASE 默认的下载中间件,其中优先级越小离目标越近,none为关闭中间件优先级的补充,优先级值越小,执行顺序越靠前。不过在在下载中间件中比较特别涉及到请求往返,优先级越小,越先执行其中的process_request方法,但其process_reponse方法越后执行。
2.爬虫级别的配置,可以在爬虫中进行设置。
name = 爬虫名
allowed_domains = 允许的发起请求的域名
start_urls = [urls] #起始请求
custom_settings = { #爬虫级配置中间件
'ITEM_PIPELINES': {
'爬虫项目.pipelines.爬虫Pipeline': 优先级,
},
'DOWNLOADER_MIDDLEWARES':{
},
}

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









