







 本文介绍了如何使用Scrapy框架创建一个项目,编写爬虫文件,利用CSS选择器解析网页,以及运行和查看爬取结果。在创建Scrapy项目后,需在spiders目录下编写蜘蛛代码,解析网页数据。最后通过命令行运行爬虫并观察输出结果。
本文介绍了如何使用Scrapy框架创建一个项目,编写爬虫文件,利用CSS选择器解析网页,以及运行和查看爬取结果。在创建Scrapy项目后,需在spiders目录下编写蜘蛛代码,解析网页数据。最后通过命令行运行爬虫并观察输出结果。
注意:
使用前请安装cmd、pycharm、anaconda
Anaconda安装教程https://blog.youkuaiyun.com/u012318074/article/details/77075209
一、创建一个scrapy项目
在开始爬取之前,我们首先要创建一个scrapy项目,在命令行输入一下命令即可创建
scrapy startproject mingyan
如果你输入命令之后,出现了下面的显示:
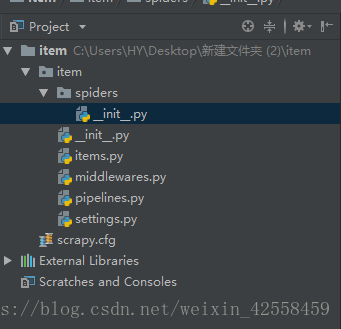
二、创建一个scrapy蜘蛛文件
上面我们已经成功创建了一个scrapy 项目,那我们该在哪里写我们的蜘蛛呢?
在spiders目录下面,这一个scrapy 文档,我们就来创造一只scrapy蜘蛛
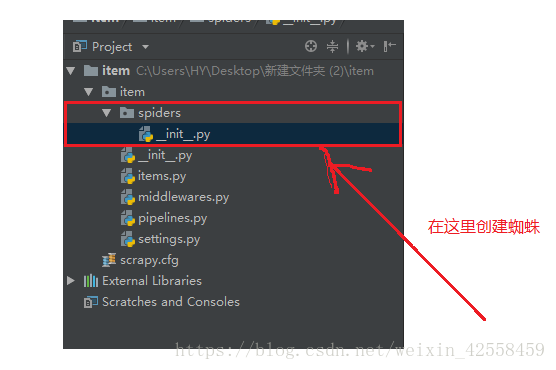
创建的肯定是我们的.py文件。怎么创建呢?你可以用记事本,也可以用pycharm,建议使用pycharm因为方便!首先你需要把你创建的项目mingyan2在pycharm里面打开,然后右键点击spiders,选中New再选中python File即可,如下图:
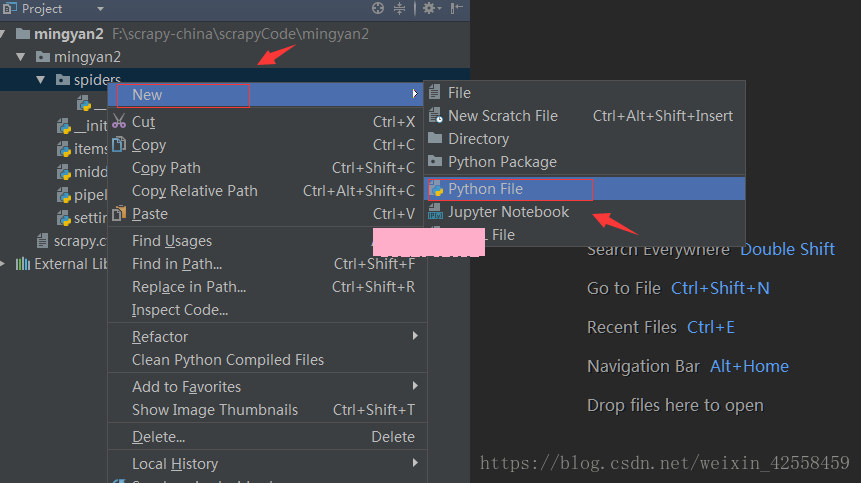
文件名的话你随意,尽量见名知意,这里我就取名为:mingyan_spider.py (保存在mingyan2/spiders目录下),再看一下创建好文件后的目录结构:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1757
1757

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









