







传送门: redis中文网地址
注:redis注重的是速度,所以在做技术选型的时候因为一些其他原因而牺牲掉redis的速度,那还不如不用
- redis 是单进程的
- 系统中可以有多个 redis 实例,每个实例中可以有多个库,库中存的都是键值对。
- key 可以设置过期时间,但过期时间不会随着访问而延长,如果有效期内发生写,会剔除过期时间
一、数据类型
- key是个对象,包含
type类型、字节长度和encoding
type 用来快速判断接下来的命令 vlaue 的数据类型是否可行,而不是真的用数据参与计算然后再报异常
encoding 用来拿字节做计算

1. String类型
| 字符串 | set、get、append、setrange、getrange、strlen、msetnx(原子性操作) | |
|---|---|---|
| String 、 byte | 数值 | incr、incrby、decr、decrby、incrbyfloat |
| bitmap | setbit 、bitcount、bitpos、bitop |
1)字符串
--设置 key value
set k1 hello; get k1; --hello
-- key没有的时候生效,可用在分布式,多个线程操作一个,只会有一个操作成功,其余返回nil
set k1 ooxx nx; -- nil
get k1; -- hello
-- 只能更新,没值不能设
set k2 hello xx; -- nil
get k2; -- nil
-- 设置多个值
mset k3 a k4 b; -- OK
get k3; -- a
get k4; -- b
-- 获取多个
mget k3 k4; -- 'a' 'b'
-- 追加 append
get k1; -- hello
append k1 " world"; -- (integer)11
get k1; -- hello world
-- 截取 getrange
getrange k1 6 10; -- world
-- 正反向索引
getrange k1 6 -1; -- world
getrange k1 0 -1; -- hello world
-- setrange 覆盖
setrange k1 6 zjh -- (integer)9
get k1; -- hello zjh
-- 获取字符串长度 strlen
strlen k1; -- (integer) 9
-- getset : 替换 value 并返回旧值,减少io通信
set k1 hello; -- ok
getset k1 zjh; -- hello
get k1; -- zjh
-- msetnx 设置多个不存在的键值 原子性操作
msetnx k1 a k2 b; -- 1
mget k1 k2; -- a b
msetnx k2 c k3 b; -- 0
mget k1 k2 k3; -- a b
--通过 key 查看 value 类型 (key 中有描述 value 类型的 type)
type k1; -- string
--- 注意
get k1; -- hello zjh
set k1 99; -- ok
set k2 hello; -- ok
type k1; -- string
type k2; -- string
object encoding k2; -- embstr
object encoding k1; -- int
2)数值
可用于抢购、秒杀、详情页、点赞、评论数等,规避并发下,对数据库的事务操作,完全由redis内存操作代替
--- incrby
get k1; -- 99
incr k1; -- (integer)100
get k1; -- 100
incrby k1 22; -- (integer)122
get k1; -- 122
-- decrby
get k1; -- 122
decr k1; -- 121
decrby k1 22; -- 99
-- incrbyfloat
get k1; -- 99
incrbyfloat k1 0.5 -- 99.5
注:类型转换
二进制安全:只取字节流
set k2 9; -- ok
object encoding k2; -- int
strlen k2; -- (integer)1
append k2 999; -- (integer)4
get k2; -- 9999
object encoding k2 -- raw
incr k2; -- (integer)10000
object encoding k2 -- int
strlen k2 -- (integer)5
3)bitmap
-- setbit
setbit k1 1 1; --0
strlen k1; -- 1
get k1; -- @
setbit k1 7 1; -- 0
strlen k1; -- 1
get k1; -- A
setbit k1 9 1; -- 0
strlen k1; -- 2
get k1; -- A@

-- bitpos 二进制字节索引 返回全量的二进制位
bitpos k1 1 0 0; -- (integer)1 0 0 是字节索引
bitpos k1 1 1 1; -- (integer)9
bitpos k1 1 0 1; -- (integer)1 在k1当中,二进制 1 在 0~1 字节中的二进制位置
-- bitcount
bitcount k1 0 1; -- (integer)3 k1 里 0~1 字节中间 二进制 1 的数量
-- bitop 二进制字节操作,与或非
setbit k1 1 1; -- (integer)0
setbit k1 7 1; -- (integer)0
get k1; -- A 0100 0001
setbit k2 1 1;
setbit k2 6 1;
get k2; -- b 0100 0010
bitop and andkey k1 k2 -- 按位与(全一为一)
get andkey; -- @ 0100 0000
bitop or orkey k1 k2 -- 按位或(有一则一)
get orkey -- C 0100 0011
解决需求
- 有用户系统,统计用户登录天数,且窗口随机
---- 人员做为 key 将365天对应到二进制位,-2 -1 表示16个二进制位里 1 的个数,
setbit sean 1 1
setbit sean 7 1
setbit sean 364 1
strlen sean
bitcouny sean -2 -1
| 01 | 02 | 03 | 04 | … | |
|---|---|---|---|---|---|
| 人员01 | 0 | 1 | 0 | 1 | 01010101… |
| 人员02 | 0 | 1 | 0 | 1 | 011111… |
- 活跃用户统计,窗口随机。比如说 1号 - 3号 连续登录要去重
---- 将人员对应二进制位,日期做为 key
setbit 20190101 1 1
setbit 20190102 1 1
setbit 20190102 7 1
bitop or destkey 20190101 20190102
bitcount destkey 0 -1
| u1 | u2 | u3 | … | |
|---|---|---|---|---|
| 20190101 | 0 | 1 | 0 | 00110… |
| 20190102 | 1 | 1 | 0 | 10101… |
2.list
-- lpush rpush
lpush k1 a b c d e f -- (integer)6 fedcba
rpush k2 a b c d e f -- (integer)6 abcdef
lpop k1 -- f
lpop k1 -- e
lpop k1 -- d
rpop k2 -- f
rpop k1 -- a
lrange k1 0 -1 -- c b
-- lindex 根据下标取出
lrange k1 0 -1 -- f e d c b a
lindex k1 2 -- d
lindex k1 -1 -- a
-- lset 根据下标替换
lset k1 3 xxxx -- ok
lrange k1 0 -1 -- f e d xxxx b a
-- lrem linsert
lpush k3 1 a 2 b 3 a 4 c 5 a 6 d -- (integer)12
lrange k3 0 -1 -- d 6 a 5 c 4 a 3 b 2 a 1
lrem k3 2 a -- (integer)2 移除 k3 里的 2 个 a,正数从左往右删除
lrange k3 0 -1 -- d 6 5 c 4 3 b 2 a 1
linsert k3 after 6 a -- (integer)11 在 6 的后面插入 a
lrange k3 0 -1 -- d 6 a 5 c 4 3 b 2 a 1
linsert k3 before 3 a -- (integer)12 在 3 的前面插入 a
lrange k3 0 -1 -- d 6 a 5 c 4 a 3 b 2 a 1
lrem k3 -2 a -- (integer)2 负数从右往左删除
lrange k3 0 -1 -- d 6 a 5 c 4 3 b 2 1
llen k3 -- 10 统计元素个数
三个客户端连接同一端口同一进程的redis

-- trim 删除两边
lpush k4 a b c d e d f d fs sdf sdf sdf sd f
lrange k4 0 -1 -- f sd sdf sdf sdf fs d f d e d c b a
ltrim k4 2 -2 -- ok
lrange k4 2 -2 -- sdf sdf sdf fs d f d e d c b
3.hash
-- 引
set sean::name 'zjh' -- ok
get sean::name -- zjh
set sean::age 18 -- ok
get sean::age -- 18
keys sean* -- sean::name sean::age
-- hash
hset sean name zjh -- (integer)1
hmset sean age 18 address sy -- ok
hget sean name -- zjh
hmget sean name age -- zjh 18
hkeys sean -- name age address
hvals sean -- zjh 18 sy
hgetall sean -- name zjh age 18 address sy
hincrbyfloat sean age 0.5 -- 18.5
hget sean age -- 18.5
hincrbyfloat sean age -1 -- 17.5
4.set
smembers很耗费网络的吞吐量sinter交集 ,sinterstore将交集存在给定的 key 里
sunion并集 ,sunionstore同理srandmember key countcount 为正数,取出一个去重的结果集(不能超过已有集)
如果是负数,取出一个带重复的结果集,一定满足你要的数量。
0 不返回
-- smembers
sadd k1 tom sean peter ooxx tom xxoo -- (integer) 5
smembers k1 -- sean tom ooxx peter xxoo tom被去重
srem k1 ooxx xxoo -- (integer) 2
smembers k1 -- tom peter sean
-- sinter sinterstore
sadd k2 1 2 3 4 5
sadd k3 4 5 6 7 8
sinter k2 k3 -- 4 5 交集
sinterstore dest k2 k3 -- (integer) 2 将交集存到 dest 里,节省IO
smembers dest -- 4 5
--- 差集 想取数据的放左面,右面放参考
sdiff k2 k3 -- 1 2 3
sdiff k3 k2 -- 6 7 8
-- srandmember 随机
sadd k1 tom ooxx xxoo xoxo oxox xoox oxxo
srandmember k1 3 -- tom xoox oxox -- 不重复随机结果
srandmember k1 -3 -- oxox ooxx oxox 包含重复结果
srandmember k1 -10 -- tom oxox oxox xoxo xxoo ooxx tom xoox xxoo tom
-- spop 随机取出不放回 取出一个
spop k1 -- oxox
spop k1 -- xxoo
spop k1 -- xoxo
.
.
.
spop k1 -- tom
spop k1 -- nil
5.sorted set
物理内存,排序方式左小右大,且不随命令发生变化
zadd k1 8 apple 2 banana 3 orange -- (integer)3
zrange k1 0 -1 -- banana orange apple
zrange k1 0 -1 withscores -- banana 2 orange 3 apple 8
-- 按分值取
zrangebyscore k1 3 8 -- orange apple
-- 价格由低到高取出前两名
zrange k1 0 1 -- banana orange
-- 价格由高到低取出前两名
zrevrange k1 0 1 -- apple orange
-- 根据元素取出分值
zscore k1 apple -- 8
-- 取出排名
zrank k1 apple -- 2
-- 数值计算
zrange k1 0 -1 withscores -- banana 2 orange 3 apple 8
zincrby k1 2.5 banana -- 4.5
zrange k1 0 -1 withscores -- orange 3 banana 4.5 apple 8
| zunionstore | 目标key | 参与并集的key的数量 | key的名称 | 权重 | 聚合 |
|---|---|---|---|---|---|
| zunionstore | unkey1 | 2 | k1 k2 | weights 1 0.5 | 默认为相加 |
zadd k1 80 tom 60 sean 70 baby -- (integer)3
zadd k2 60 tom 100 sean 40 yiming -- (integer)3
-- 取 k1 k2 并集,其余参数默认
zunionstore unkey 2 k1 k2 -- (integer) 4
zrange unkey 0 -1 withscores -- yiming 40 baby 70 tom 140 sean 160 默认情况下相同项相加
zunionstore unkey1 2 k1 k2 weights 1 0.5 -- (integer) 4 权重: 1 分值不变 0.5 分值除以2
zrange unkey1 0 -1 withscores -- yiming 20 baby 70 sean 110 tom 110
-- 并集取最大值
zunionstore unkey2 2 k1 k2 aggregate max -- (integer) 4
zrange unkey2 0 -1 withscores -- yiming 40 baby 70 tom 80 sean 100
二、发布订阅
Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。
Redis 客户端可以订阅任意数量的频道。
下图展示了频道 channel1 , 以及订阅这个频道的三个客户端 —— client2 、 client5 和 client1 之间的关系:
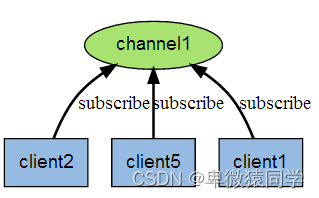
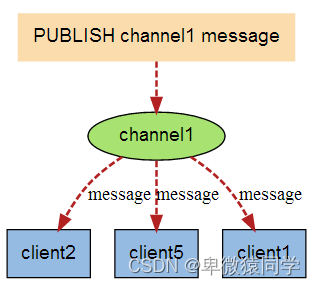
当有新消息通过 PUBLISH 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端:
-- 创建订阅频道
redis 127.0.0.1:6379> SUBSCRIBE redisChat
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "redisChat"
3) (integer) 1
-- 向订阅频道发送消息
redis 127.0.0.1:6379> PUBLISH redisChat "Redis is a great caching technique"
(integer) 1
redis 127.0.0.1:6379> PUBLISH redisChat "Learn redis by w3cschool.cc"
(integer) 1
# 订阅者的客户端会显示如下消息
1) "message"
2) "redisChat"
3) "Redis is a great caching technique"
1) "message"
2) "redisChat"
3) "Learn redis by w3cschool.cc"
三、事务
redis 为速度服务,所以并没有真正的事务,它可以将命令绑在一起一股脑的执行,如果中间有命令失败,就进行撤销,但不会百分百成功
MULTI 标记一个事务块的开始。
EXEC 执行所有事务块内的命令。
如下图,因 redis 是单线程,若客户端01 的 exec 命令先到达,就先执行客户端01 的命令块,若客户端02 的 exec 命令先到达,就先执行客户端 02 的命令块

但如果客户端 2 的指令先执行,会将 k1 删除,客户端 1 执行的时候会报错。redis 提供了 WATCH 命令,可以对 key 进行监控。但这个监控是 CAS 的,如果 k1 的 value 被修改,那么 WATCH 后的命令块不会执行。
四、布隆过滤器
将检索要素映射到二进制位,用到的二进制位变为 1。搜索的时候如果对应的二进制位有返回 0 的,那么就可以明确没有相应的搜索项。这么做可以增加防穿透的概率,但不能100%
- 确定自己有什么
- 有的向bitmap中标记
- 请求的可能被勿标记
- 会减少大量的放行:穿透
- 成本低
五、持久化
当数据量很大,并发很高的时候,想要将数据存到磁盘必然会有一个持续时间,在这段时间中数据肯定会有修改,假如想要备份 24 点整的数据,不阻塞的话很难保证不会有脏数据。
以下为单机
1. 基本知识
了解 redis 持久化之前,需要先掌握几个知识:
- RDB AOF
- 管道
- 父子进程
- fork()
缓存:数据可以丢,急速
数据库:数据绝对不能丢 速度+持久性 掉电易失
存储层:
- 快照 / 副本 (备份数据)
- 日志 (数据丢失后可根据日志找回)
RDB : 快照
AOF : 日志
Linux系统:管道
- 衔接,前一个命令的输出做为后一个命令的输入
- 管道会触发创建【子进程】
echo $$ | more
echo $BASHPID | more
$$ 高于 |
父子进程:
- Linux中,export的环境变量,子进程的修改不会破坏父进程;父进程的修改也不会破坏子进程
子进程修改变量,不会影响父进程
#!/bin/bash -- 写一个脚本,定义被谁运行,
echo $$ -- 获取当前进程
echo $num -- 定义变量 num
num=999
echo num:$num -- 取值验证是否修改成功
sleep 20
echo $num -- 验证有没有被父进程修改
[root@bash ~]# ./test.sh & -- 让脚本在后台运行
[1] 114155 -- 子进程运行结果
[root@bash ~]# 114155 -- 子进程运行结果
1 -- 子进程运行结果
num:99 -- 子进程运行结果
[root@bash ~]# echo $$ -- 当前为父进程
114017
[root@bash ~]# echo $num -- 获取 num 为 1
1
[root@bash ~]# 999 -- 20秒结束,子进程变量为 99
[1]+ Done ./test.sh
父进程修改变量,不会影响子进程
echo $$ #当前为父进程
114017
echo $num #获取num
1
./test.sh & #运行脚本
[1] 114158 #子进程运行结果
114158 #子进程运行结果
1 #子进程运行结果
num:999 #子进程运行结果
echo $num #获取父进程 num
1
num=888 # 修改父进程 num 变量
echo $num # 查看父进程 num
888
999 #等待20秒,子进程为999
fork() 快速创建一个子进程
利用父子进程的特点进行数据备份, 创建子进程时不发生复制,这使得创建子进程的速度变快,数据是写时备份(copy on write),也就是进程中数据修改时再进行备份,先创建变量,然后修改指针。
redis 持久化数据,利用 fork()命令 copy on write 一个子进程,父进程数据的修改不会影响子进程,以此保证时点正确
2. RDB
特性:
- 时点性
- save (阻塞存储,比如关机维护)
- bgsave (fork创建子进程)
- 配置文件中给出bgsave规则,save这个表示
注意文件名和存储位置,在配置文件中是分开的
文件名 :dbfilename dump.rdb
存储路径:dir /var/lib/redis/6379
弊端:
不支持拉链,仅有一个 dump.rdb
3. AOF
- redis的写操作记录到文件中
- 丢失数据少
- redis 中,RDB 和 AOF 可以同时开启,如果开启了 AOF ,只会用 AOF 恢复数据,
redis 4.0 以后,AOF 中包含 RDB 全量,增加记录新的写操作
缺点:体谅无限变大,恢复慢
对缺点进行优化:
- 4.0以前,重写,删除抵消的命令,合并重复的命令,最终也是一个纯指令的日志文件
- 4.0以后,重写,将老的数据 RDB 到 AOF 文件中,将增量的以指令的方式 append 到 AOF,这样 AOF 是一个混合体,利用了 RDB 的快,利用了日志的全量
但是,redis 是内存数据库,写操作会触发IO
appendonly yes # 打开异步RDB到磁盘,会造成数据丢失
appendfilename*appendonly.aof* # 文件名称
appendfsync always # 每一次io 都调用一次 flush,数据可靠
appendfsync everysec # 每秒,丢的少,丢的最多的时候就是空间差一点点满,1秒时间到了,从这一秒开始往后进行磁盘写入,不过这种情况概率小
appendfsync no # io以后不进行 flush 操作,内核数据满了以后往磁盘写,但会残留
验证时需要调整的配置文件项:
ps -fe | grep redis # 验证是否关闭所有 redis
vi /etc/redis/6379.conf # 修改配置文件
# daemonize no 不在后台运行,在前台阻塞运行
# #logfile /var/log/redis_6379.log 关闭日志文件,输出到屏幕
# appendonly yes 开启追加
# aof-use-rdb-preamble no 关闭混合
redis-server /etc/redis/6379.conf # 通过配置文件启动 redis

















 520
520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









