






前言
本文基于2021年发表在Science上的聚类算法《Clustering by fast search and find of density peaks》的实现,并采用Python语言实现了该聚类算法。采用的Python语言版本为3.8,除去读取GIS数据所用的ogr库和绘图所用的matplotlib、pandas、seaborn库,真正运行算法所必要的库仅为numpy。
PS:想先了解原理的可以看我的博文《【分享】发表在Science上的一种实用聚类算法-基于快速搜索和发现密度峰值的聚类方法》,我对该论文做了全文的翻译。
数据准备
为验证所写代码是否能正确分类点集,使用ArcGIS软件准备了两份点要素测试集,对于图1所示的测试集1,一共有31个点,可以用人眼清楚的分辨出两个聚类簇,即意味着有两个聚类中心。

对于图2所示的测试集2,一共有2022个点,可以用人眼较为明显的分辨出四个聚类簇,即意味着有四个聚类中心。

算法核心参数的确定
1. 确定距离d_c
采用论文中所建议的经验值,即d_c使得每个数据点的平均邻居个数约为数据点总数的1%至2%。在代码中以百分比的形式作为一个可选参数,用于计算d_c值。本文设置为2%。
2. 确定聚类中心及其个数
论文中指定能确定聚类中心的方式有两种,一种是决策图,另一种是降序排列的γ值分布图。经过实验,发现决策图在其实并不好判断聚类中心,具有较大的主观性。但对于降序排列的γ值分布图而言,可以较为轻松的辨别出聚类中心,且主观依赖性较小。下面分别对两个测试数据集绘制决策图和降序排列的γ值分布图,以判断两个数据集的聚类中心。
如图3所示的测试集1的决策图,从决策图中可以明显的看出图形右上角所在点为测试点集的一个聚类中心,但另一个聚类中心便无法从决策图中判断了。反观测试集1降序排列的γ值分布图,即如图4所示,可以明显的看出有两个点易于其他点,即从非聚类中心的平滑点集过渡到聚类中心时γ值有一个明显的跳跃。因此,通过降序排列的γ值分布图判断出测试点集共有两个聚类中心,即代表聚类算法将有两个聚类簇(不考虑噪声点为聚类簇)。

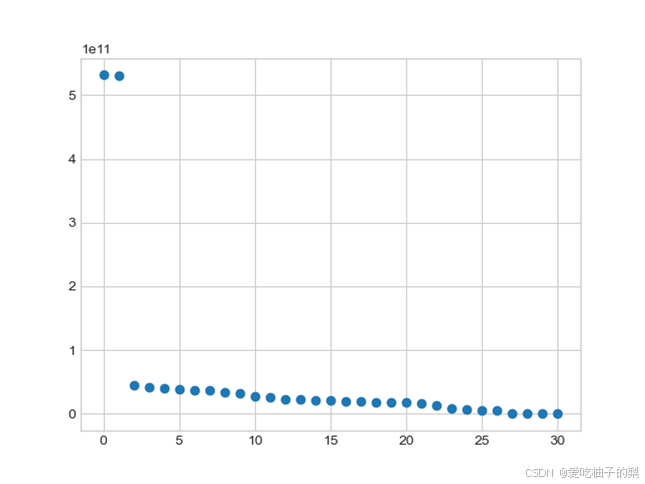
如图5所示,对于测试数据集2的决策图可以判断出数值异常大的点的个数为5个,即聚类中心的个数为5个,但如此判断主观性较强,因此必须结合降序排列的γ值分布图,即图6来判断。如图6所示,可以判断,前5个点与其他点的γ值有明显的跳跃,到第6个点的γ值与其他点集的γ值之间的间隔已较难以区分,因此可以判断该数据集的聚类中心个数为5个。
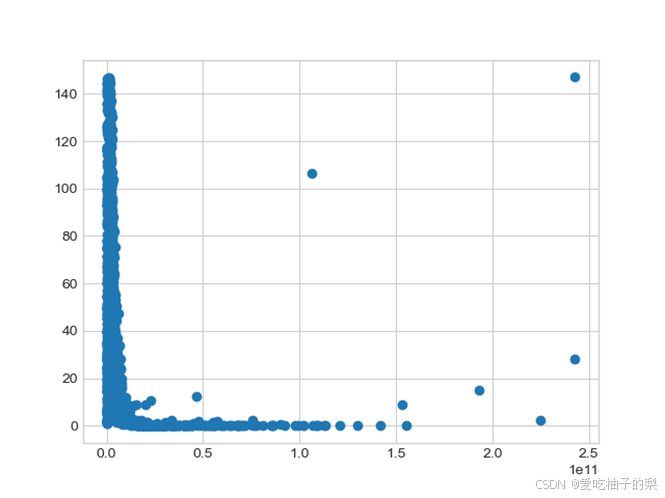
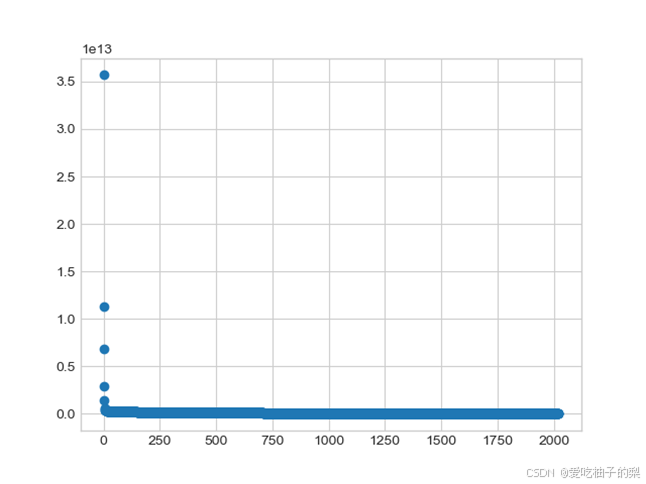
文章作者提到,对于人工随机生成的数据集γ的分布满足幂次定律。我认为从实验结果来看,γ值的分布确实是近似与幂次定律,类似于幂函数的图像。
代码实现
import math
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
import pandas as pd
from osgeo import ogr
import seaborn as sns
def CutoffKernel(x):
if x < 0:
return 1
else:
return 0
def GaussianKernel(x):
return math.exp(-1 * x * x)
# 读取数据
points_fn = r'DataSource\SamplePoints2.shp'
dataSource = ogr.Open(points_fn, 1)
layer = dataSource.GetLayer()
featureCount = layer.GetFeatureCount()
N = featureCount
pt_list = []
for feature in layer:
geom = feature.GetGeometryRef()
pt_list.append([geom.GetX(), geom.GetY()])
# 可选参数(建议的数值区间为[1,2])
percent = 2.0
# 计算各点之间的距离
dist_mat = np.zeros((N, N))
dist_list = []
for i in range(0, N):
for j in range(i + 1, N):
dist_mat[i][j] = math.dist(pt_list[i], pt_list[j])
dist_mat[j][i] = dist_mat[i][j]
dist_list.append(dist_mat[i][j])
# 确定截断距离dc
dist_list.sort()
d_c = dist_list[round(len(dist_list) * percent / 100) - 1]
# 计算局部密度,并生成其降序排列下标序
local_density_list = []
for i in range(0, N):
local_density_list.append(0)
for j in range(0, N):
if i != j:
# local_density_list[i] += CutoffKernel(dist_mat[i][j] - d_c)
local_density_list[i] += GaussianKernel(dist_mat[i][j] / d_c)
local_density_list = np.array(local_density_list)
sort_index_density_list = np.argsort(local_density_list)
sort_index_density_list = sort_index_density_list[::-1]
q_list = sort_index_density_list
# 计算距离delta_i
# 注:在局部密度比i大的点集中找与点i的距离最小的点,该点与点i的距离即为所求值
delta_list = np.zeros(N)
# n_i表示排序意义下点集中所有局部密度比点i大的数据点中与点i距离最近的数据点的编号
nearest_pts_sorted = np.zeros(N)
n_list = nearest_pts_sorted.astype(int)
for i in range(1, N):
delta_list[q_list[i]] = dist_list[-1]
for j in range(0, i):
if dist_mat[q_list[i]][q_list[j]] < delta_list[q_list[i]]:
delta_list[q_list[i]] = dist_mat[q_list[i]][q_list[j]]
n_list[q_list[i]] = q_list[j]
delta_list[q_list[0]] = np.amax(delta_list[1:])
# 确定聚类中心(此步暂需要人工看图确定具体的中心个数)
y_list = local_density_list * delta_list
sort_index_y_list = np.argsort(y_list)[::-1]
plt.style.use('seaborn-whitegrid')
plt.plot(delta_list,local_density_list,'o') # 决策图(有些情况难以判断聚类中心)
plt.show()
plt.plot(np.arange(0, N), np.sort(y_list)[::-1], 'o') # 降序排列的γ值分布图(更好判断)
plt.show()
cluster_num = 5
# 标记聚类中心
cluster_labels = np.full(N, -1)
for i in range(0, cluster_num):
cluster_labels[sort_index_y_list[i]] = i
# 对非聚类中心数据点进行归类
for i in range(0, N):
if cluster_labels[q_list[i]] == -1:
cluster_labels[q_list[i]] = cluster_labels[n_list[q_list[i]]]
# 标记噪声点(区分cluster core和cluster halo)
h_list = np.zeros(N)
avg_density_bounds = np.zeros(len(np.unique(cluster_labels))) # 平均局部密度上界
for i in range(0, N-1):
for j in range(i+1, N):
if cluster_labels[i] != cluster_labels[j] and dist_mat[i][j] < d_c:
avg_density = (local_density_list[i] + local_density_list[j]) / 2
if avg_density > avg_density_bounds[cluster_labels[i]]:
avg_density_bounds[cluster_labels[i]] = avg_density
if avg_density > avg_density_bounds[cluster_labels[j]]:
avg_density_bounds[cluster_labels[j]] = avg_density
# 标识噪声点(cluster halo)
for i in range(0, N):
if local_density_list[i] < avg_density_bounds[cluster_labels[i]]:
h_list[i] = 1
cluster_labels[np.nonzero(h_list)] = -1
# 将聚类结果写入输入shp格式的点集中
for i in range(0, N):
feature = layer.GetFeature(i)
feature.SetField('Label', int(cluster_labels[i]))
layer.SetFeature(feature)
# 绘制结果
pt_list = np.array(pt_list)
pts_df = pd.DataFrame({'x': pt_list[:, 0],'y':pt_list[:, 1], 'label':cluster_labels})
g = sns.scatterplot(data=pts_df, x='x', y='y', hue='label', palette='tab10')
plt.grid(False)
plt.legend(bbox_to_anchor=(1.02, 1), loc='upper left', borderaxespad=0,title='Classes')
plt.tight_layout()
plt.show()
print('Finished!')
结果验证
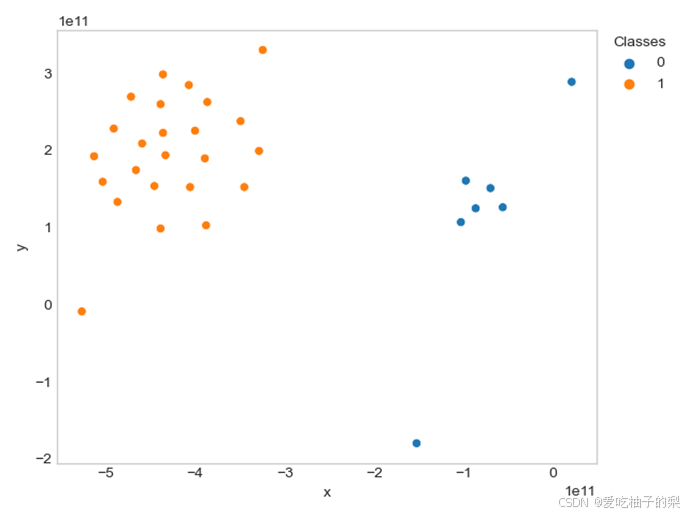
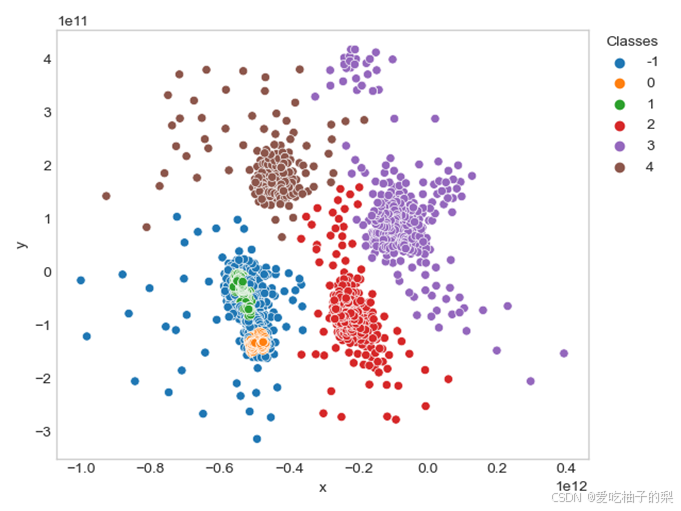
如图7所示为测试数据集1的聚类结果图,将数据集按左右两侧进行了划分。如图8所示为测试数据集2的聚类结果图,可以看出密度较高的区域都被归为一个类别,其中对于0和1两个类别通过噪声点(标记为-1的点)进行了分隔。总体而言,实验结果能够证明所写算法代码的正确性。
参考资料
- Rodriguez A, Laio A. Clustering by fast search and find of density peaks. science. 2014 Jun 27;344(6191):1492-6.
- https://blog.youkuaiyun.com/itplus/article/details/38926837
写在最后
如果你需要获取论文原文翻译以及本文实验数据,欢迎在我的微信公众号社区(公众号名称“爱吃柚子的梨”)上回复“聚类算法论文”进行下载,期待在微信上与你相遇,一起继续探索更多有价值的信息!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











