




回想一下联邦学习(FL)中的FedAvg,这个算法是将每个参与方的模型的所有参数进行加权平均聚合,包括Batch Normalization(BN)的参数。
再回顾一下BN。式中µ和 σ 2 σ^2 σ2为BN统计量,是通过每个channel的空间和批次维度计算而得的running mean和running variances。γ和β为实现"变换重构"的超参数。ε用于预防分母为零。
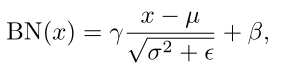
我们知道FL的一个重要意义就在
Batch Normalization在联邦学习中的应用
 联邦学习中BatchNormalization处理
联邦学习中BatchNormalization处理
最新推荐文章于 2025-08-23 23:37:15 发布
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 717
717





 到【灌水乐园】发言
到【灌水乐园】发言









